Foundation models and intelligent decision making
基础模型与智能决策:进展、挑战与展望¶
PII: S2666-6758(25)00151-1 DOI: https://doi.org/10.1016/j.xinn.2025.100948 Reference: XINN 100948
To appear in: The Innovation
Received Date: 10 February 2025 Revised Date: 8 May 2025 Accepted Date: 8 May 2025
© 2025 Published by Elsevier Inc. on behalf of Youth Innovation Co., Ltd.
Jincai Huang \({ }^{16,17,44}\), Yongjun Xu \({ }^{1,36,37,44}\), Qi Wang \({ }^{1,36,37,44}\), Qi (Cheems) Wang \({ }^{2,44}\), Xingxing Liang \({ }^{17,44}\), Fei Wang \({ }^{1,36,37,44}\), Zhao Zhang \({ }^{1,12,44}\), Wei Wei \({ }^{3,44}\), Boxuan Zhang \({ }^{4,44}\), Libo Huang \({ }^{1,44}\), Jingru Chang \({ }^{5,44}\), Liantao Ma \({ }^{6,44}\), Ting Ma \({ }^{7,44}\), Yuxuan Liang \({ }^{8,44}\), Jie Zhang \({ }^{9,41,44}\), Jian Guo \({ }^{10,44}\), Xuhui Jiang \({ }^{10,44}\), Xinxin Fan \({ }^{1,36,37,44}\), Zhulin An \({ }^{1,36,37,44}\), Tingting Li \({ }^{1,44}\), Xuefei Li \({ }^{1,36}\), Zezhi Shao \({ }^{1}\), Tangwen Qian \({ }^{1}\), Tao Sun \({ }^{1}\), Boyu Diao \({ }^{1,36,37}\), Chuanguang Yang \({ }^{1,36}\), Chenqing Yu \({ }^{1,36}\), Yiqing Wu \({ }^{1}\), Mengxian \(\mathrm{Li}^{1,36}\), Haifeng Zhang \({ }^{11,36}\), Yongcheng Zeng \({ }^{11,36}\), Zhicheng Zhang \({ }^{12,36}\), Zhengqiu Zhu \({ }^{16}\), Yiqin Lv \({ }^{13}\), Aming Li \({ }^{14,38}\), Xu Chen \({ }^{15}\), Bo An \({ }^{18}\), Wei Xiao \({ }^{4}\), Chenguang Bai \({ }^{19}\), Yuxing Mao \({ }^{19}\), Zhigang Yin \({ }^{19}\), Sheng Gui \({ }^{20,39}\), Wentao Su \({ }^{21}\), Yinghao Zhu \({ }^{6}\), Junyi Gao \({ }^{22,40}\), Xinyu He \({ }^{23}\), Yizhou \(\mathrm{Li}^{24}\), Guangyin Jin \({ }^{25}\), Xiang Ao \({ }^{1,36,37}\), Xuehao Zhai \({ }^{26}\), Haoran Tan \({ }^{27}\), Lijun Yun \({ }^{28}\), Hongquan Shi \({ }^{29}\), Jun \(\mathrm{Li}^{30}\), Changjun Fan \({ }^{16,17}\), Kuihua Huang \({ }^{17}\), Ewen Harrison \({ }^{22}\), Victor C. M. Leung \({ }^{31,42,43}\), Sihang Qiu \(^{16, *}\), Yanjie Dong \({ }^{31, *}\), Xiaolong Zheng \({ }^{12,36, *}\), Gang Wang \({ }^{4, *}\), Yu Zheng \({ }^{32, *}\), Yuanzhuo Wang \({ }^{1,36,37, *}\), Jiafeng Guo \({ }^{1,37, *}\), Lizhe Wang \({ }^{30, *}\), Xueqi Cheng \({ }^{1,37, *}\), Yaonan Wang \({ }^{27, *}\), Shanlin Yang \({ }^{33, *}\), Mengyin \(\mathrm{Fu}^{34, *}\), Aiguo \(\mathrm{Fei}^{35, *}\)
\({ }^{1}\) Institute of Computing Technology, Chinese Academy of Sciences, Beijing 100190, China
\({ }^{2}\) Department of Automation, Tsinghua University, Beijing 100084, China
\({ }^{3}\) Huazhong University of Science and Technology, Wuhan 430074, China
\({ }^{4}\) School of Automation, Beijing Institute of Technology, Beijing 100081, China
\({ }^{5}\) School of Information Science and Engineering, Dalian Polytechnic University, Dalian 116034, China
\({ }^{6}\) National Engineering Research Center for Software Engineering, Peking University, Beijing 100871, China
\({ }^{7}\) Department of Oral Implantology, Peking University School and Hospital of Stomatology, Beijing 100081, China
\({ }^{8}\) The Hong Kong University of Science and Technology (Guangzhou), Guangzhou 511453, China
\({ }^{9}\) College of Information and Electrical Engineering, China Agricultural University, Beijing 100083, China
\({ }^{10}\) IDEA Research, International Digital Economy Academy, Shenzhen 518057, China
\({ }^{11}\) Institute of Automation, Chinese Academy of Sciences, Beijing 100190, China
\({ }^{12}\) The State Key Laboratory of Multimodal Artificial Intelligence Systems, Institute of Automation, Chinese Academy of Sciences, Beijing 100190, China
\({ }^{13}\) College of Science, National University of Defense Technology, Changsha 410073, China
\({ }^{14}\) Center for Systems and Control, College of Engineering, Peking University, Beijing 100871, China
\({ }^{15}\) Gaoling School of Artificial Intelligence, Renmin University of China, Beijing 100872, China
\({ }^{16}\) College of Systems Engineering, National University of Defense Technology, Changsha 410073, China
\({ }^{17}\) Laboratory for Big Data and Decision, National University of Defense Technology, Changsha 410073,China
\({ }^{18}\) College of Computing and Data Science, Nanyang Technological University, Singapore 639798, Singapore
\({ }^{19}\) School of Electrical Engineering, Chongqing University, Chongqing 400044, China
\({ }^{20}\) Department of Mathematics, The University of Hong Kong, Hong Kong SAR 999077, China
\({ }^{21}\) School of Food Science and Technology, Dalian Polytechnic University, Dalian 116034, China
\({ }^{22}\) Centre for Medical Informatics, University of Edinburgh, Edinburgh EH16 4UX, UK
\({ }^{23}\) Department of Stomatology, Peking Union Medical College Hospital, Chinese Academy of Medical Sciences and Peking Union Medical College, Beijing 100730, China
\({ }^{24}\) Department of Stomatology, Yuquan Hospital, School of Clinical Medicine, Tsinghua University, Beijing 100040, China
\({ }^{25}\) National Innovative Institute of Defense Technology, Beijing 100091, China
\({ }^{26}\) Department of civil and environmental engineering, Imperial College London, London SW7 2AZ, UK
\({ }^{27}\) College of Electrical and Information Engineering, Hunan University, Changsha 410082, China
\({ }^{28}\) HUA-Innovation High-Tech(Hangzhou) Co., Ltd. , Hangzhou 311100, China
\({ }^{29}\) Dalian Naval Academy, Dalian 116018, China
\({ }^{30}\) School of Computer Science, China University of Geosciences, Wuhan 430078, China
\({ }^{31}\) Shenzhen MSU-BIT University, Shenzhen 518172, China
\({ }^{32}\) JD Technology & JD Intelligent Cities Research, Beijing 101111, China
\({ }^{33}\) School of Management, Hefei University of Technology, Hefei 230009, China
\({ }^{34}\) Nanjing University of Science and Technology, Nanjing 210094, China
\({ }^{35}\) School of Computer Science, National Pilot Software Engineering School, Beijing University of Posts and Telecommunications, Beijing 100876, China
\({ }^{36}\) University of Chinese Academy of Sciences, Beijing 100049, China
\({ }^{37}\) Key Lab of AI Safety, Chinese Academy of Sciences, Beijing 100190, China
\({ }^{38}\) Center for Multi-Agent Research, Institute for Artificial Intelligence, Peking University, Beijing 100871, China
\({ }^{39}\) LSEC, Academy of Mathematics and Systems Science, Chinese Academy of Sciences, Beijing 100190, China
\({ }^{40}\) Health Data Research UK, London NW1 2BE, UK
\({ }^{41}\) State Key Laboratory of Efficient Utilization of Agricultural Water Resources, Beijing 100083, China
\({ }^{42}\) Shenzhen University, Shenzhen 518060, China
\({ }^{43}\) The University of British Columbia, Vancouver V6T1Z4, Canada
\({ }^{44}\) These authors contributed equally
*Correspondence: qiusihang11@nudt.edu.cn (S. Q.), ydong@smbu.edu.cn (Y. D.), xiaolong.zheng@ia.ac.cn (X. Z.), gangwang@bit.edu.cn (G. W.), msyuzheng@outlook.com (Y. Z.), wangyuanzhuo@ict.ac.cn (Y. W.), guojiafeng@ict.ac.cn (J. G.), lizhe.wang@gmail.com (L. W.), cxq@ict.ac.cn (X. C.), yaonan@hnu.edu.cn (Y. W.), yangsl@hfut.edu.cn (S. Y.), fumy@bit.edu.cn (M. F.), aiguofei@bupt.edu.cn (A. F.)
摘要¶
智能决策(Intelligent Decision-Making,IDM)是人工智能(AI)的基石,旨在自动化或增强决策过程。现代IDM范式整合先进框架,使智能体能够做出有效且自适应的选择,并将复杂任务分解为可管理的步骤,如AI代理和高阶强化学习。近期基于多模态基础模型的方法统一了视觉、语言及传感数据等多种输入模态,形成统一的决策过程。基础模型(Foundation Models,FMs)已成为科学与工业中的关键技术,变革了决策与研究能力。它们在大规模多模态数据处理上的能力促进了适应性和跨学科的突破,涵盖医疗、生命科学和教育等领域。本文综述了IDM的发展历程、基于基础模型的先进范式及其在各类科学和工业领域中对决策的变革性影响,重点分析了构建高效、自适应且具伦理性的决策系统所面临的挑战与机遇。
关键词:人工智能,智能决策,基础模型,智能体,大型语言模型。
1. 引言¶
决策理论经过数百年发展,融合了数学、统计学、哲学、经济学、心理学和计算机科学等多学科知识。从概率论和期望值的早期概念发展到包含心理因素的复杂模型。20世纪40年代,冯·诺依曼和摩根斯坦关于期望效用的工作奠定了决策的数学基础和概念框架。\({ }^{1}\) 赫伯特·西蒙的《行政行为》是现代决策理论的重要里程碑,强调了决策的认知方面。\({ }^{2,3}\) 后来,丹尼尔·卡尼曼和阿莫斯·特沃斯基提出了前景理论及双系统思维概念,更准确地解释了决策过程。\({ }^{4}\) 总之,决策是一个复杂的问题解决过程,不是单一事件,而是包含一系列步骤的过程。一个广泛接受的多步骤决策框架是OODA循环,\({ }^{5}\) 即观察(Observe)、定向(Orient)、决策(Decide)和行动(Act)阶段的循环。直观上,OODA描述了感知数据收集与呈现、提取有效证据、执行逻辑推理,最终以顺序或非顺序方式确定最优行动的过程。IDM作为人工智能的基石,旨在替代某些OODA阶段或辅助人类评估选项、做出选择或通过主动干预复杂动态环境来操控结果。\({ }^{6}\) 它是计算机科学、心理学与认知科学、经济学与博弈论、运筹学、控制理论和统计学等多学科交叉领域。区别于传统决策过程,IDM的实现依赖模型集合、优化算法和概率推断工具,实现过程自动化,并在机器人学,\({ }^{7}\) 金融,\({ }^{8}\) 医疗,\({ }^{9}\) 及其他工业应用中长期受关注。
综上,本文旨在促进IDM在不同领域的应用。为此,我们介绍IDM概念,综述IDM所需技术,总结典型IDM范式的最新进展,并展示部分基于基础模型的有前景的IDM方法。
1.1 决策要素¶
IDM包括四个要素:(1) 供智能体交互、采集观测和反馈的环境;(2) 在可行动作空间内执行计划和策略的智能体或决策者;(3) 用于指定目标或目的的奖励或效用函数;(4) 智能工具,如启发式规则构建、学习或挖掘模型及其他优化策略。环境有时是交互式且涉及动力系统的状态转移,当系统转移仅依赖上一个时间步观察到的状态时,可构成马尔可夫决策过程(MDP)\({ }^{10}\);否则环境为非马尔可夫。另一方面,根据系统状态在决策中的可观测性,可将决策过程划分为完全观测决策过程与部分观测决策过程。例如,部分机械臂无法感知某些关节位置,但可通过摄像头图像推断自身准确状态,决策环境可抽象为部分观测马尔可夫决策过程(POMDP)。\({ }^{11}\) 当系统动力学和统计特征随时间变化时,可定义环境为非平稳。关于智能工具,近百年来涌现多种,包括规则构建、启发式搜索策略、机器学习方法及基础模型(FMs)的应用。
1.2 基础模型概念¶
文献中通常将用于多种下游任务的大规模预训练机器学习模型称为基础模型(FM)。典型模型如BERT,\({ }^{12}\) GPT,\({ }^{13}\) 以及CLIP,\({ }^{14}\) 训练于海量语言、视觉、音频或多模态数据集,旨在捕捉有效模式并提取通用表示。基础模型的发展依赖多种学习范式的融合,如自监督学习,\({ }^{15,16}\) 元学习,\({ }^{17,18,19}\) 及多任务学习。\({ }^{20,21,22}\)
1.3 决策遇见基础模型¶
基础模型的诞生使得通过微调快速适配具体应用成为可能,\({ }^{23,24}\) 避免了部署时从零学习的需求。鉴于传统决策范式中计算和数据成本高昂的成分,如基础强化学习,亟需借助基础模型技术革新决策,探索从中受益的路径。
同时,本工作区别于其他关于基础模型的综述,主要聚焦IDM发展趋势,并探讨利用基础模型最新进展助力IDM模型在更广泛应用场景中的开发潜力。
1.4 决策技术谱系¶
决策技术可分为传统决策技术与智能决策技术。传统决策多依赖专家经验和直觉,智能决策则依赖算法驱动和数据支持。智能决策解决了传统决策在大规模状态动作空间面临的算法爆炸问题,以及传统决策算法在不同领域中泛化能力差的问题。传统技术包括基于博弈论的决策技术,\({ }^{25}\) 基于启发式优化的决策技术,\({ }^{26}\) 及基于知识的决策技术。\({ }^{27}\) 智能决策涵盖基于深度强化学习(DRL)、大型语言模型及基础大模型的决策技术。\({ }^{28}\) 传统技术在处理简单线性决策问题时高效,但面对多维非线性复杂决策空间仍有限制。基于大型模型的智能决策在面对高维复杂非线性状态动作空间时具备卓越决策能力。IDM不同发展阶段如图1所示。
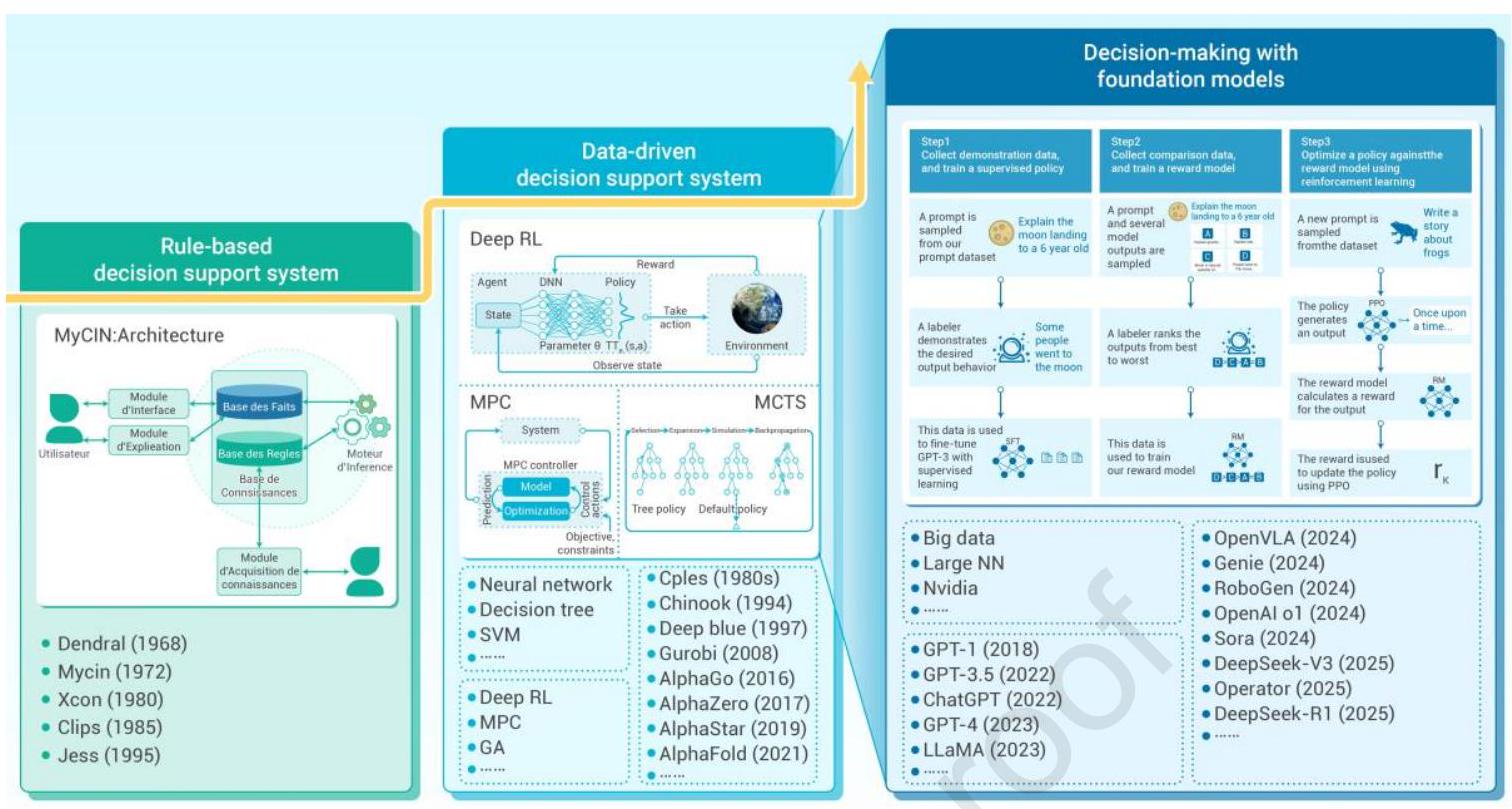
图1:智能决策的发展历史。基于规则的决策支持系统通过规则库和事实库实现决策支持,适用于规则明确驱动的场景。数据驱动的决策支持系统结合神经网络、决策树等技术,应用于深蓝和AlphaGo等项目,并在多个领域超越人类。基于基础模型的决策作为数据驱动决策的新兴技术,通过演示数据收集、数据标注和奖励模型训练等步骤,利用大型模型(如GPT系列和LLaMA)实现决策优化,典型应用案例包括OpenVLA、RoboGen等。
IDM与专家规则。智能决策系统(Intelligent Decision Systems,IDS)发展史上,决策支持系统(Decision Support System,DSS)在学术界和工业界均发挥了关键作用。建立DSS的主要目的是复制领域专家的决策模式,并通过自动化程序执行判断。\({ }^{29}\) 早期,结构化数据集稀缺且难以获取,因此采用规则集合和常识作为知识库,识别场景并运用推理实现决策。此方法能快速处理决策查询且具备良好解释性,但局限于特定领域,严重依赖昂贵的专家知识,且难以处理超出既有知识库的情况。
随着数据库中可学习的实例增多,机器学习和数据挖掘工具在系统开发中日益重要。它们促进了数据驱动模型的创建,捕捉有效模式,从而增强决策过程。有效的算法和学习模型通过预测在不同策略下的结果和趋势,提升数据驱动DSS的优势,同时支持自动知识发现。强化学习(DRL)\({ }^{10}\) 是该领域的重要方法,涉及与环境交互、收集奖励信号,并在序列决策过程中对行为进行赋值。DRL在实时策略游戏,\({ }^{30,31}\) 无人机竞速,\({ }^{32}\) 围棋游戏等领域取得显著成功。\({ }^{33}\) 为提高样本效率,出现了离线强化学习(offline RL)范式,从静态大规模转移数据集中学习。\({ }^{34,35}\) 尽管数据驱动DSS随着数据量和质量的提升,增强了泛化能力并减少了对精心设计专家知识的依赖,但其本质仍较为静态,仅在有限复杂场景中有效,尚未实现真正的即插即用功能。
IDM与浅层及深度学习方法。传统决策技术包括基于博弈论的决策方法、基于启发式优化算法的方法以及基于知识的决策技术。传统方法针对不同问题设计,依据具体决策问题选择合适算法。智能体间的博弈模式包括囚徒困境、赌徒博弈和纳什均衡。为实现各智能体最大累积收益,基于智能体收益的规则驱动智能决策被采用。
启发式优化算法包括遗传算法(GA)、粒子群优化(PSO)、蚁群算法(ACO)、禁忌搜索(TS)和模拟退火(SA),各自针对不同优化问题并应用于特定领域。GA、PSO、ACO属于群体优化算法,TS和SA属于个体优化算法。GA和ACO仅适用于离散优化,其余三种算法可用于离散及连续优化。GA核心在选择阶段保留优良解,交叉和变异阶段生成新解。PSO核心利用局部和全局最优解更新解。ACO通过信息素的沉积与挥发更新和优化路径。TS通过禁忌表避免重复搜索,局部邻域搜索的扩展为全局邻域搜索。SA模拟固体退火原理,通过邻域搜索逐步达到基态。GA应用于优化设计、机器学习参数优化和图像处理;PSO用于神经网络权重优化、无线传感器网络节点部署、机器学习参数优化、图像处理和智能控制。ACO应用于旅行商问题(最短路径)、资源调度和网络优化。TS适用于组合优化问题、模型参数优化和通信网络拓扑结构优化。SA应用于旅行商问题及参数优化。
基于知识的决策方法包括贝叶斯推断、专家系统等,利用先验知识或知识库实现从环境状态到行动的推理决策和动作执行。贝叶斯推断技术和专家决策系统利用先验知识及预定义规则库实现特定问题的决策和行动选择。传统决策技术通常用于简单线性低维决策问题,依据具体环境和应用选择对应算法。但面对高维大规模状态空间的复杂决策时,传统方法存在规模爆炸和复杂度指数增长问题。基于强化学习(RL)和大型模型的智能决策在大规模状态空间和高维状态动作空间中表现优异,实现更高奖励的动作执行。
趋势显示AI技术具备重塑决策框架的潜力,决策先验的来源从硬编码的专家知识或人类技能向大规模数据集提取转变。智能决策技术分为基于RL的决策、基于大型模型的决策,以及基于基础模型(FM,指在广泛数据集(文本、图像、音频和视频)上训练且能应用于多下游任务的模型)的决策。\({ }^{36}\) RL方法一般用于状态到动作的选择,而基于FM的决策可用于序列决策、群体决策及多模态决策。
RL方法包含基于价值的、价值分布的、基于策略的和演员-评论家(actor-critic)方法,已应用于Atari游戏及众多决策场景和状态动作选择环境,提升多种应用环境的决策性能。
最初的RL是基于表格学习的Q-learning,后DQN算法用深度神经网络替代表格,扩展状态动作至更高维度和更复杂表示。此外,Double DQN使用价值网络与目标网络更新Q值(回报或累计奖励),Dueling DQN采用包含状态价值和优势价值的对决架构。价值分布基RL方法包括C51,\({ }^{37}\) QR-DQN,IQN,FQF,利用价值分布提升决策能力。基于策略的RL方法直接输出动作生成最优策略,涵盖深度策略梯度(DPG)、DDPG、PPO。演员-评论家RL算法包含SAC、AC、A2C、A3C,其中A3C利用异步优势演员-评论家提升决策效率和累积奖励。
相比RL方法,基于FM的决策具有更强泛化和适应能力。FM可作为智能体(规划者、决策者、感知者和执行者)、环境、设计者、编码器、条件生成模块及人机交互者。目前主流FM包括Transformer、BERT、T5、GPT系列,以及LLaMA、PaLM等,可用于基于FM的序列决策、群体决策和多模态决策。重要的是,FM与RL方法的结合已成为更流行的IDM范式。
基于单智能体RL的进展,多智能体强化学习(MARL)将RL扩展至包含多个智能体的环境,智能体需通过合作或竞争进行交互。MARL带来非平稳性、信用分配和智能体间通信等新挑战,并通过多种训练和执行范式加以解决。\({ }^{38}\)
去中心化训练与去中心化执行(DTDE)\({ }^{39}\) 使智能体无需集中协调即可独立学习和行动,适用于完全分布式系统。中心化训练与去中心化执行(CTDE)\({ }^{40,41,42}\) 允许智能体在训练阶段利用集中信息提升学习效率,执行阶段保持去中心化策略以保证现实应用的可扩展性和适应性。分组训练与去中心化执行(GTDE)\({ }^{43}\) 将智能体分组,训练阶段组内协调,执行阶段组间去中心化。这些范式为应对多智能体系统复杂性提供了坚实框架,使MARL能优化合作、竞争及混合环境下的决策。
基于大型模型的智能决策技术以大型模型输入作为状态输入,输出作为动作执行,利用链式思维(chain-of-thought)、思维树、思维图等提示工程技术,形成基于大型模型的决策过程。目前主流大型模型包括Transformer、BERT、T5、GPT系列,以及LLaMA、PaLM等,可用于序列决策和群体决策。
基于基础模型的智能决策(FM-based IDM)。借助计算平台,数据经过优化整合为模型参数,成为知识的载体。
认识到数据集、计算能力和模型容量的重要性,\({ }^{44}\) 先驱研究者将关注点转向开发基础决策模型(Foundation Decision-Making Models,FDMM)。不同于传统针对具体决策场景开发智能模型的范式,FDMM的初衷是捕捉场景的通用表示,实现零样本或少样本的快速适应,\({ }^{45,46}\) 并在开放决策环境中动态进化。如此,我们可在测试阶段实现计算效率,并以极少的学习资源无缝适应环境变化,这在实时控制问题(如自动驾驶)中尤为关键。
FDMM区别于以往数据驱动决策支持系统(DSS)的核心在于面向场景分布的学习范式。为以更低的计算和数据成本实现跨场景决策,智能决策者需从序列数据集中捕捉内在结构,例如通过自监督学习预测下一个标记作为最优决策动作,\({ }^{47}\) 同时以多任务方式处理多个请求,\({ }^{48}\) 并有时借助少量示例进行元学习。\({ }^{49}\) 诚然,FDMM成功的关键要素包括充足的场景、多样且紧凑的神经推理模块,以及大规模计算资源。
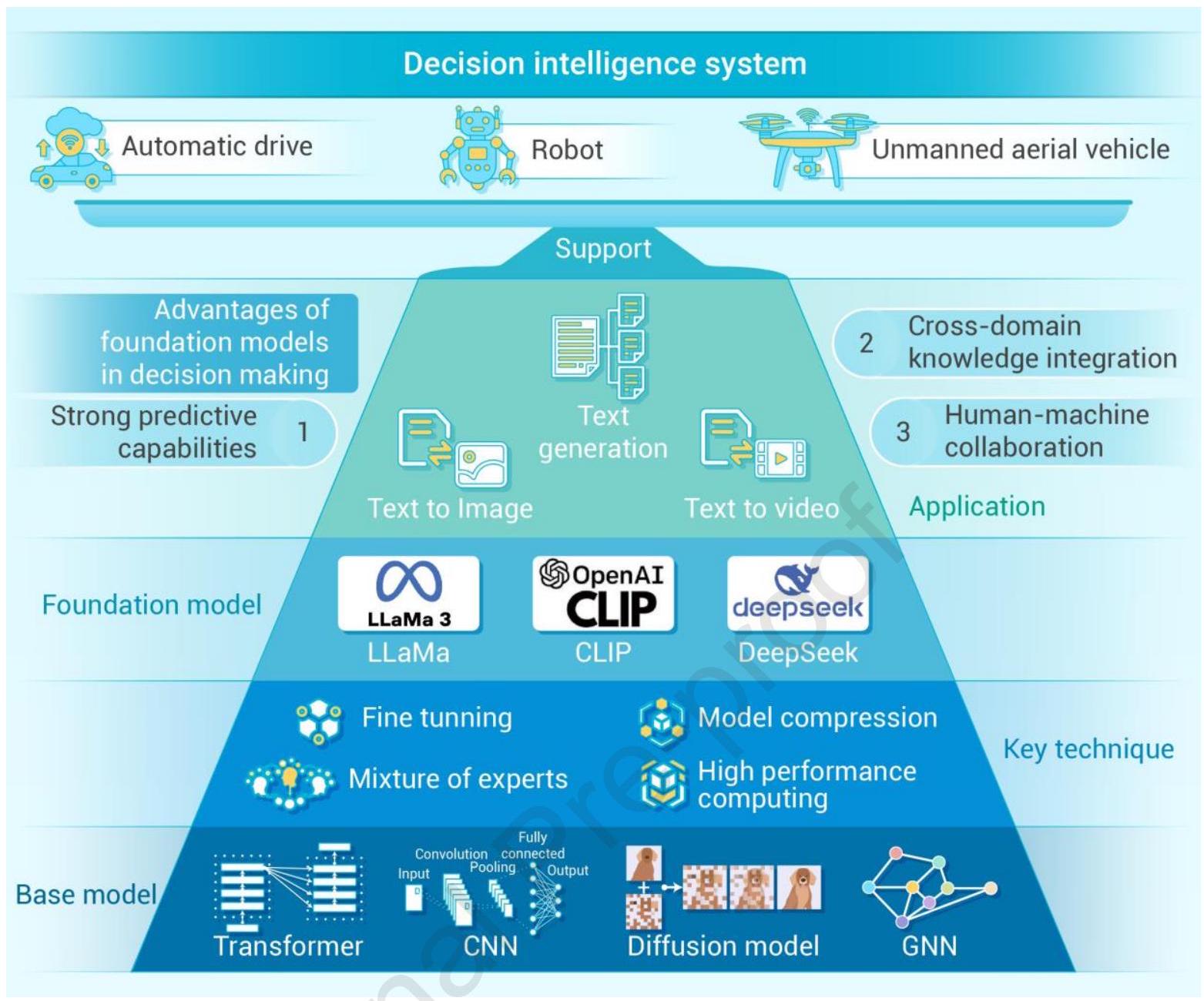
图2:基础模型的概览与发展
总体而言,开发FDMM的必要性在于其广泛的应用目标,旨在覆盖广泛的决策场景,而非局限于特定场景。重要的是,FDMM将以往的数据驱动模型从特定场景扩展为多场景适用,并将大规模决策序列压缩为大规模模型参数,作为先验的主要来源,获得可迁移的表示以支持下游任务。同时,当前的决策先验趋于全面,为策略搜索提供有效约束。
2. 基础模型的概述与发展¶
基础模型(Foundation Models),如大型语言模型和多模态人工智能系统,因其能够处理并整合跨多领域的大量数据,已成为智能决策的强大工具。这些模型通过大规模数据集训练,擅长识别模式、生成洞见并提供情境感知的推荐,这对于在复杂动态环境中做出明智决策至关重要。凭借其广泛的知识和适应能力,基础模型可辅助从战略规划、风险评估到实时问题解决及个性化决策支持的多样任务。它们在决策框架中的整合提升了效率、准确性和可扩展性,使组织和个人能够应对以往难以解决的挑战。为更好地介绍基于基础模型的决策智能,本节将介绍基础模型的发展,具体包括基础模型的基础知识、大型语言模型(LLMs)及多模态基础模型的发展,最后介绍基础模型的优化。
2.1 基础模型基础知识¶
基础模型指的是在广泛数据(通常采用大规模自监督学习)上训练的模型,能够适应(如微调)多种下游任务。\({ }^{50}\) 基础模型的特点是规模庞大、参数众多,具备出色的迁移学习能力,能够轻松适应新任务。\({ }^{51}\) 它们展现出“涌现能力”,即常常表现出意想不到的功能。这些特性使基础模型在各行各业产生变革性影响,显著推动人工智能技术进步。\({ }^{52,50,53,54,55}\)
基础模型的发展与智能决策的进步密切相关,始于词嵌入技术,如Word2Vec \({ }^{56}\) 和GloVe \({ }^{57}\),为理解数据中的语义关系奠定基础。Transformer架构的引入,\({ }^{58}\) 利用自注意力机制促进了更复杂的决策,随后BERT \({ }^{59}\) 革新了自然语言处理,实现了上下文感知的预测。随后,GPT-2 \({ }^{60}\) 和GPT-3 \({ }^{61}\) 等大型语言模型迅速发展,展现了前所未有的语言理解与生成能力,使系统能做出更精准和细腻的决策。多模态模型如DALL-E \({ }^{62}\) 和CLIP \({ }^{14}\) 进一步融合视觉与语言,实现更丰富的决策语境,而Swin Transformer \({ }^{63}\) 将类似原理应用于计算机视觉,增强视觉推理和决策。最新发展如GPT-4 \({ }^{13}\) 不断推动规模和精细度极限,实现跨领域更准确、上下文感知和自适应的决策。这一进程标志着从专用单模态模型向功能更强大、多样且多模态系统的转变,根本重塑了人工智能及其智能决策能力。\({ }^{64,65,66}\) 基础模型已彻底革新自然语言处理(NLP)、计算机视觉(CV)和图学习等领域的学术研究,使得之前难以实现的复杂数据驱动决策过程成为可能。
自然语言处理(NLP)。基础模型最初在NLP领域流行。NLP的基础模型始于ELMo \({ }^{67}\),采用双向LSTM \({ }^{68}\) 学习上下文相关词表示。Transformer的引入促使NLP基础模型迅猛发展,涌现出多种模型。它们大致可分为两类:(1) 自回归语言基础模型,(2) 上下文语言基础模型。自回归模型通过逐词生成文本,利用已生成词作为上下文预测下一个词,典型代表为GPT系列。\({ }^{69,60,61}\) 该方法在文本生成任务中表现优异,能产出连贯且富有创造性的文本。自回归模型仅利用单方向信息(左或右),非同时双向。相对地,上下文语言模型着重捕捉语言的复杂语义和上下文信息,典型模型包括BERT \({ }^{61}\)、UniLM \({ }^{70}\) 和T5 \({ }^{71}\)。它们通过双向编码器架构或深度上下文表示提升文本分类、问答、情感分析等任务表现,优势在于理解并生成更具上下文相关性的语言输出。
计算机视觉(CV)。计算机视觉基础模型起步于卷积神经网络(CNN),如ResNet。\({ }^{72}\) 通过大量图像训练,它们能提取图像特征并促进迁移学习。\({ }^{73,74}\) 受Transformer在NLP成功启发,部分研究将Transformer作为新骨干。视觉Transformer(Vision Transformer,ViT)\({ }^{75}\) 实现重要转变,将图像视为序列块处理,捕获远程依赖,实现更细致的特征提取。Swin Transformer \({ }^{63}\) 进一步完善此方法。另一发展为扩散模型(Diffusion Models),\({ }^{76,77,78,79}\) 通过迭代去噪随机高斯噪声图像,逐步逼近目标分布,生成高质量、多样化图像。代表模型有Stable Diffusion 3.0 \({ }^{80}\)、DiT \({ }^{81}\)、Sora \({ }^{82}\) 等。\({ }^{78,83,84,85}\) 多模态模型如CLIP \({ }^{14}\) 和MiniGPT-4 \({ }^{87}\) 等,将图像与文本对齐于共享空间,实现多样化零样本分类。\({ }^{86,87,88}\)
图学习。图学习旨在理解与分析图结构数据,关注节点分类、链接预测和图分类任务。\({ }^{89,90,91,92,93,94,95}\) 基础模型在图学习领域亦日渐成为新兴研究方向,旨在创建适用于多种图任务和领域的通用模型。图学习基础模型可分为三类:基于图神经网络(GNN)的模型、大型语言模型(LLM)驱动模型及二者结合的GNN+LLM模型。\({ }^{96,97}\) (1) 基于GNN的模型:着重利用现有图学习范式,创新基础GNN架构、预训练技术及任务适配。\({ }^{98,99,100}\) 如GCC \({ }^{101}\) 采用对比学习预训练图节点嵌入,“All in one”\({ }^{102}\) 提出图提示,助力GNN适配多种下游任务。(2) LLM驱动模型:将图数据转换为文本或令牌格式,利用语言模型处理图问题。其中TextForGraph \({ }^{103}\) 通过精心设计提示模板将图数据转为文本,应用LLM处理;InstructGLM \({ }^{104}\) 将图节点令牌纳入LLM词汇表,通过指令调优适配图学习任务。(3) GNN+LLM模型:结合GNN与LLM优势提升图学习性能。如\(\mathrm{GraD}^{105}\) 用LLM编码节点文本属性,再用经典GNN编码图结构。
其他领域。基础模型在时间序列分析、代码生成、语音处理等领域亦取得显著进展。\({ }^{106,107,108,109}\) 时间序列分析中,基础模型旨在通过捕捉复杂时间模式提升预测和异常检测能力。\({ }^{110,111,112,113}\) 研究尝试利用LLM知识构建基于LLM的基础模型。\({ }^{114,115,116}\) 单模态时间序列基础模型\({ }^{117,118,119}\) 仅基于时间序列数据训练,亦有多模态模型\({ }^{120,121}\) 融合文本和时间序列信息。代码生成领域,OpenAI的Codex \({ }^{122}\) 和Google的AlphaCode \({ }^{123}\) 能根据自然语言描述理解并生成代码片段,自动化编程任务,提高生产力并减少错误。\({ }^{124,125}\) 语音处理涵盖语音识别、合成及翻译,通常涉及语音与文本模态。早期模型如Speech-Transformer \({ }^{126}\) 适配Transformer处理语音任务,利用注意力机制融合音频和文本信息,提升转录准确率和上下文理解。近期研究试图复制语音处理中的规模定律,如Vall-E \({ }^{127}\) 引入Transformer编码音频特征,并尝试利用LLM能力实现更自然的文本转语音合成。
基础模型的应用已成为推动智能决策的重要基石。在基于知识的问答中,GPT \({ }^{61}\) 展现多样性响应能力,BERT \({ }^{59}\) 优于阅读理解,支持更准确、上下文感知的决策。在推理任务中,思维链(Chain of Thought, CoT)\({ }^{128}\) 通过提示中间推理步骤增强LLM复杂推理能力,显著提升算术、常识和符号推理表现。思维树(Tree of Thought, ToT)\({ }^{129}\) 进一步让LLM探索多条推理路径并评估选择,促进更强健自适应的推理。在自主系统中,LanguageMPC \({ }^{130}\) 将LLM作为决策者,通过结构化思维流程生成可执行指令,并与模型预测控制(MPC)等低层控制器无缝集成。LLM在多智能体系统的引入\({ }^{131}\) 促进代理间通信、推理与学习,提升复杂决策场景中的集体智能。医疗领域,ChatGPT在放射科临床决策辅助中的潜力已被评估,\({ }^{132}\) 展示LLM在高风险决策中的变革作用。类似地,将LLM整合至自动驾驶车辆,借助自然语言交互、上下文理解和持续学习,提升决策能力。\({ }^{133}\) Expel \({ }^{134}\) 提出一种代理,通过试错收集经验,提炼见解,并结合经验改进新任务决策,且无需更新模型参数,展现自适应经验驱动决策潜力。这些进展凸显基础模型在实现更准确、上下文感知和自适应决策中的关键作用,根本改变智能系统的运行及其与世界的交互方式。
2.2 基础模型的发展¶
基础模型最初在自然语言处理(NLP)领域引起广泛关注,随后迅速扩展到多模态领域。本节将分别介绍大型语言模型(LLMs)和多模态基础模型(MMFMs)的发展。基础模型的关键发展节点如图2所示。
大型语言模型的发展。LLMs代表人工智能领域的重要进展,旨在理解、处理和生成类人文本。通过在海量语料上的广泛预训练,LLMs不仅展现出卓越的语言理解能力,还达到了通用智能水平,使其成为智能决策的核心工具。它们分析复杂数据、生成洞见和预测结果的能力,使其成为提升各领域决策过程的重要组成部分。本章将详细介绍LLMs的主干模型、主流架构、预训练策略、微调与对齐技术,以及应用。
Transformer:主干架构。LLMs是一类先进的机器学习模型,设计用于理解和生成自然语言。其庞大的参数规模使其在文本生成、翻译和摘要等任务中表现优异。Transformer \({ }^{58,135}\) 架构核心由编码器和解码器组成,每个编码器包含多个相同层,具备多头自注意力机制和简单前馈网络;解码器额外加入跨注意力层以处理编码器输出。\({ }^{136,137}\) 自注意力机制允许远距离输入间的直接上下文关联,有效捕获长程依赖。\({ }^{138,139}\) 其层次化设计与并行处理能力加速训练,支持大规模数据和模型。\({ }^{140,141}\) 这些特点使Transformer成为构建灵活、可扩展LLMs的首选架构。
主流LLM架构。基于Transformer架构,语言模型主要有四种结构:编码器(如BERT \({ }^{59}\))、因果解码器(如GPT \({ }^{13}\)、LLaMA \({ }^{142}\))、前缀解码器(Prefix-LM \({ }^{71}\))和编码器-解码器(如Google的T5 \({ }^{71}\))。尽管编码器结构在早期模型中广泛使用,但因生成能力有限且难以扩展大规模,逐渐被后三者取代。这些结构支持从零样本学习到大规模知识整合的多种应用。
- 因果解码器:采用单向注意力机制,确保生成时每个输出仅访问先前输出以维护因果关系。擅长生成自然流畅文本,常用于聊天机器人、故事续写等任务。
- 前缀解码器:将固定前缀与自由生成后缀结合,前缀部分采用双向注意力,后缀自由生成。适合条件生成任务,允许在给定上下文中灵活生成内容。
- 编码器-解码器:经典结构,编码器处理输入文本生成中间表示,解码器基于此生成输出。优势在于有效处理复杂输入输出关系,但需大量训练数据。
预训练策略。预训练阶段在大量无标签数据上训练模型,为后续具体任务学习打基础。\({ }^{143}\) 该阶段对LLMs至关重要,使其从广泛文本中学习通用语言模式与结构。不同预训练策略聚焦不同语言能力,如语法理解、语义提取或文本生成。目前主流LLMs如GPT系列和T5主要采用自回归预训练方法。自回归框架中,预测内容分为语言建模和去噪自编码两类。
- 语言建模:最常见自回归预训练策略,旨在给定上下文预测下一个词,捕捉语言生成的自然序列。此策略训练的模型在文本生成、续写和对话生成等任务中表现强劲,如GPT系列。\({ }^{13}\)
- 去噪自编码:输入数据被故意破坏,模型需恢复原始数据。许多LLMs如GLM \({ }^{144}\)、Google T5 \({ }^{71}\) 和BART \({ }^{145}\) 采用此方法。部分模型如UL2 \({ }^{146}\) 结合两者,将语言建模视为掩码下的去噪自编码。
鉴于语言建模的有效性与可扩展性,主流LLMs如GPT \({ }^{13}\)、LLaMA \({ }^{142}\) 和QWen \({ }^{147}\) 仍主要采用该策略。
微调与对齐。微调用于将预训练模型适配特定任务或需求,但完整训练计算资源消耗巨大。参数高效微调(PEFT)\({ }^{148}\) 通过只调整少量参数显著降低成本和时间。支持方法包括适配器(在模型中添加可训练层)、前缀调优(通过调整输入提示引导输出)、低秩适配(优化参数矩阵秩)。同时,对齐技术确保模型响应符合人类价值和偏好,保证输出符合用户期望和伦理标准。关键技术包括基于人类反馈的强化学习(RLHF)\({ }^{149}\),通过融合人类反馈有效调整模型行为。
大型语言模型的应用。尽管LLMs能力出众,但仍面临准确性、知识更新及可解释性挑战。为解决,开发了提示学习、知识增强和工具学习等框架。提示学习通过明确指令调整LLMs以适应特定任务,先进方法如CoT \({ }^{128}\) 模仿人类推理逐步演进。然单靠LLMs内部知识常导致不准确信息、过时知识及透明度不足。知识增强(如检索增强生成RAG \({ }^{150}\) 和知识图谱)通过外部资源提升准确性和领域知识。工具学习 \({ }^{151}\) 使LLMs动态调用外部工具,提升问题解决能力和整体表现。
多模态基础模型的发展。随着AI快速进步,多模态基础模型(MMFM)技术成为研究和应用热点。MMFM能够处理和理解多种数据类型(如文本、图像、音频、视频)。\({ }^{64,65,66}\) 通过融合不同模态信息,生成更全面准确的洞见,为决策智能提供坚实的数据基础和认知支持。例如在商业场景,多模态模型可分析客户反馈(文本)、产品图片(视觉)和市场趋势(时间序列),为决策者提供全方位市场视角。
模型架构。MMFM架构多基于Transformer,因其灵活高效。但随着研究深入,出现多样架构以适应不同数据和任务,主要包括:
- 基于Transformer的编码器:核心组件,提取文本、图像、音频等多样输入特征。\({ }^{152}\) 如Vision-and-Language Transformer(ViLT)\({ }^{153}\) 直接融合视觉与文本,提升多模态理解。
- 序列生成模型:常用于图像描述和对话系统,生成连贯且上下文相关输出。\({ }^{154,83}\)
- 扩散模型:通过逐步去噪生成高质量样本,提供多模态生成新途径。\({ }^{155,156}\)
- 自回归解码器:配合编码器,逐步生成输出序列,适用于对话生成和文本补全。\({ }^{157,158}\)
- 图神经网络(GNN):处理图结构数据,建模多模态数据间关系和结构信息,适用于社交网络和知识图谱。\({ }^{159,160}\)
- 混合架构:结合卷积神经网络和Transformer,强化视觉特征提取及信息整合,提升复杂数据理解。\({ }^{161,162,163,164}\)
- 生成对抗网络(GAN):应用于多模态生成任务,通过对抗训练提升图像或文本生成的真实感。\({ }^{165,166}\)
- 多任务学习框架:同时处理多任务,共享知识,提升泛化和鲁棒性,适合复杂多模态理解应用。\({ }^{167,168}\)
这些多样架构极大增强了MMFM性能和应用范围,使其更好地应对复杂现实任务。
关键技术。以下关键技术推动MMFM性能和适用性提升:
- 对齐技术:确保不同模态特征空间一致性,通过对齐模型更好理解图像与描述关系,增强生成与识别能力。常见方法包括对比学习和注意力机制。\({ }^{169,170}\)
- 预训练数据收集:数据丰富度和多样性决定模型表现。预训练通常利用来自社交媒体、图像库和开源出版物的海量标注与非标注数据,涵盖多领域知识。\({ }^{171,165}\)
- 自监督学习与模型优化训练:自监督学习使模型能从无标签数据自主学习,提升下游任务表现。模型优化训练则通过超参数调优和架构改进提升性能。\({ }^{172,173,174}\)
- 下游任务微调:预训练后利用标注数据对特定任务微调,提高准确率和效率。\({ }^{155,175}\)
- 模态融合技术:通过有效融合不同模态数据,增强多模态信息理解,常用注意力机制或特征拼接。\({ }^{176,177}\)
- 知识蒸馏:将大模型知识迁移至小模型,降低计算负担,提高资源受限环境下的运行效率。\({ }^{178,179}\)
- 增量学习:支持模型动态更新,避免重训,对动态数据流处理至关重要。\({ }^{180,181}\)
这些技术的结合与创新为MMFM的实用性和灵活性提供了强大支持,推动其在各领域广泛应用。
代表性模型。目前,众多代表性多模态基础模型(MMFMs)来自工业界或学术界:
- 工业界模型:如OpenAI的GPT-4 \({ }^{13}\) 和谷歌的MUM \({ }^{182}\),利用强大的计算资源和专用硬件,通常部署于云平台,支持大规模用户请求的实时处理。这些模型侧重于生产环境中的可扩展性和稳定性,应用于虚拟助手、内容生成和数据分析等场景。
- 学术界模型:如对比语言-图像预训练(CLIP)\({ }^{14}\) 和DALL-E \({ }^{183}\),主要面向理论探索和算法创新的研究。学术模型常运行于较小硬件平台,重点在算法开发而非大规模计算。
- 计算与硬件差异:工业基础模型依赖大规模分布式计算架构和专用硬件(如TPU、GPU)以处理海量数据并支持高效推理;而学术模型多在小型硬件上运行,更注重算法新颖性而非庞大计算规模。\({ }^{184,64}\)
近年来,MMFMs取得显著进展,推动AI多个领域发展。从模型架构到关键技术及典型应用,MMFMs展示出巨大潜力与灵活性。随着计算能力提升及算法持续优化,该领域未来有望实现更广泛应用和理论突破。
2.3 基础模型的训练、微调与部署优化¶
基础模型训练阶段需使用高性能GPU集群,训练周期可能长达数周或数月。微调过程中需考虑超参数优化及防止过拟合。部署时,根据不同计算资源调整模型规模,确保及时响应。本节先介绍基础模型训练的优化策略,接着介绍微调的主要优化方法,最后介绍基础模型推理优化策略。
基础模型训练优化。基础模型通常利用海量数据并采用无监督预训练方法。根据预训练模型架构,可分为编码器结构、解码器结构及编码器-解码器结构三类。编码器结构的基础模型通常采用掩码语言模型,如BERT \({ }^{59}\) 和RoBERTa \({ }^{185}\)。解码器结构的基础模型一般采用自回归训练,最大化给定输入序列预测下一个词的概率,代表模型包括GPT系列 \({ }^{69,61,60}\)、PaLM \({ }^{186}\) 和LLaMA \({ }^{142,187}\)。编码器-解码器混合结构结合前两种预训练方法,随机遮蔽字符序列,随后通过自回归恢复遮蔽内容,代表模型为T5 \({ }^{71}\) 和BART \({ }^{145}\)。
基础模型微调优化。参数高效微调是基础模型适应下游任务的有效方法,近年来成为研究热点。LoRA(低秩适配)\({ }^{189}\) 是高效微调的典范,通过为适配特定任务引入低秩矩阵近似,不直接修改原模型权重,而是对受影响层的输出应用低秩矩阵变换。一系列基于LoRA的改进提升了其性能和适用性。QLoRA(量化低秩适配)极大减少内存占用,同时保持微调性能,可在单块48GB GPU上微调65亿参数模型,远低于传统16位微调的内存需求。\({ }^{190}\) LoRA-Flow \({ }^{191}\) 在生成任务中每步动态计算融合权重,通过门控机制的softmax函数实现更灵活适配,性能优于标准LoRA。MoSLoRA(子空间混合LoRA)\({ }^{192}\) 将权重分解为两个子空间并混合,等效于使用固定混合器融合子空间,且与原LoRA权重联合学习,提升了常识推理、视觉指令调优及主题驱动文本到图像生成等任务表现。
LoRA、QLoRA和Adapter-based方法在参数效率、训练速度和任务性能上各具特色。LoRA通过低秩分解显著减少可训练参数,实现高参数效率和较快训练速度,任务表现接近全微调;QLoRA基于LoRA引入量化,进一步提升参数效率和训练速度,但因量化可能稍有精度损失,任务表现略低于LoRA,适合资源受限环境;Adapter-based方法插入小型适配模块,仅训练少量参数,参数效率适中、训练速度较快,但通常慢于LoRA,任务性能接近全微调,但在部分复杂任务上稍逊于LoRA。总体来看,LoRA和QLoRA在参数效率和训练速度方面表现优异,Adapter-based方法则在灵活性和任务适应性上有优势。
性能表现见表1。
表1:基础模型优化方法比较 | 方法 | 参数效率 | 训练速度 | 任务性能 | | ------------- | ---- | ---- | ------- | | LoRA | 高 | 较快 | 接近全参数微调 | | QLoRA | 非常高 | 非常快 | 略低于LoRA | | Adapter-based | 中等 | 较快 | 接近全参数微调 |
基础模型部署优化。模型压缩和量化是缩减基础模型规模而不显著影响性能的关键策略。此过程包括剪枝技术,通过删除不重要的神经元以简化模型;\({ }^{193}\) 知识蒸馏,\({ }^{194,195,196,197}\) 即将复杂模型学得的知识迁移至更紧凑模型。此外,量化通过降低模型计算所需的数值精度,\({ }^{198}\) 大幅缩减模型体积并加速推理时间。这些优化对提升基础模型在资源受限环境中的效率和可部署性至关重要。经过优化的模型在有限资源条件下表现出色。SANA-0.6B模型变体,与现代大型扩散模型如Flux-12B相比,体积小20倍,吞吐量快100倍以上,可部署于16GB笔记本GPU,生成1024×1024分辨率图像耗时不到1秒。\({ }^{199}\) LLaMA 3.2 3B针对边缘计算和移动设备优化,支持128K令牌上下文,在业内表现卓越,擅长摘要、指令执行及文本重写等设备端任务,推动基础模型在需本地处理与隐私保护的应用中更高效便捷。\({ }^{200,201}\)
随着基础模型的发展,其在智能决策中的作用日益重要。基础模型在决策中的优势体现在:
- 强大的预测能力。通过深度学习和大规模数据训练,基础模型能捕捉数据中复杂模式和非线性关系,提升预测准确性。例如,在金融领域预测市场趋势;在医疗领域辅助诊断和制定治疗方案。
- 跨领域知识整合。基础模型具备融合多领域知识的能力,支持跨学科决策。例如,在气候变化研究中,基础模型可整合气象学、经济学、社会学等多学科数据,助力制定综合应对策略。
- 人机协作。传统决策模型通常作为辅助工具,交互方式有限。而基础模型能通过自然语言交互(如ChatGPT)与人类协作,提供更直观灵活的决策支持。
3. 基于基础模型的决策范式及关键技术¶
先进的决策范式结合复杂模型与框架,使智能体能在动态环境中做出有效选择。AI智能体倾向于利用大型语言模型(LLM)中整合的规则与经验,促进更高效的决策。高级强化学习(RL)模型通过试错学习策略,优化多任务中的长期奖励,并将决策分解为易执行步骤。\({ }^{202,203}\) 例如,多智能体系统和层级强化学习架构应运而生,以应对更复杂的协同和任务分解场景。此外,基于多模态基础模型的决策将视觉、语言和感知数据等多种输入模态整合到统一的决策流程中。通过融合不同类型的信息(如视觉线索与文本描述),多模态决策方法增强了鲁棒性与适应性,使智能体能处理需要细致理解或推理的任务。
本节系统讨论现有先进决策范式。基础模型与先进决策框架的结合使AI更接近人类式决策,尤其在不确定的现实环境中体现出认知灵活性和效率。
3.1 基础模型在智能决策中的重要角色¶
在决策过程中,基础模型(FM)能赋能全新决策范式。除了作为智能体,FM还能充当环境、设计者、编码器、条件生成模块及人机交互者。采用这些新决策范式可进一步增强基础大规模模型在多领域的泛化与决策能力。基于FM的智能决策技术能生成最优策略、动作、规划方案等。决策范式可分为三种模式。图3展示了FM在智能体模块中可作为规划者、感知者、决策者和执行者等角色。
在环境与设计者模块,FM可作为动作执行目标、环境组成或环境状态转移的桥梁,提升策略有效性。编码器模块中,FM生成状态编码或优化策略编码;在条件生成模块和人机交互模块,FM分别用于条件生成和人机交互。基于FM的多决策范式有效提升了决策模式和应用环境的适应性,显著优化了决策性能和泛化能力。
基于FM的智能体,FM可作为环境与设计者、编码器、条件生成及人机交互者。作为环境与设计者时,策略获得的动作在FM中执行以更新状态,FM设计奖励、转移、状态与环境。作为编码器,FM对状态进行编码形成表示和策略,规范状态信息。结合条件,FM使用任务、状态与提示输出行为生成、世界生成及动作内容。作为人机交互者,FM接收对话形式的人类指令,输出策略和动作以解读指令。多种FM决策范式极大优化决策性能,拓展至自然科学和社会科学领域。表2列出了三种FM类型的基本内容及比较属性,包括主要建模技术和应用领域。
表2:基础模型范式概念框架——功能角色映射、核心建模技术、跨领域应用及优缺点对比
| FM功能 | 主要建模技术 | 应用领域 | 优势 | 缺点 |
|---|---|---|---|---|
| 智能体 | LLM思维链(CoT);强化学习;专家规则 | 机器人、金融交易等 | 通用决策到复杂环境、实时响应 | 推理效率低,安全验证与人类价值对齐难,生成质量与延迟问题 |
| 环境 | 生成式仿真(GenSim) | 城市规划、医学仿真等 | 低成本生成多样场景,高风险任务预训练 | 仿真与现实差距大,多模态动态建模复杂 |
| 交互者 | 检索增强生成(RAG) | 教育辅助、智能客服等 | 自然语言交互,用户友好,个性化需求匹配 | 高幻觉风险,隐私保护与伦理对齐挑战 |
作为智能体的FM。任务及其提示输入至FM规划器,生成对应策略 \(1,2,\ldots,n\),选择最优动作执行。作为感知者,FM收集来自多个环境 \(1,2,\ldots,n\) 的多模态信息(文本、图像、音频、视频),形成当前状态。作为决策者,FM \({ }^{204,205}\) 利用状态及状态提示获得最优策略与相应动作,动作执行后产生环境反馈奖励,用于优化FM决策策略。此外,作为执行者,FM通过工具、API、Web GPT、Python生成动作表现并根据当前状态执行。\({ }^{206}\) 基于FM的智能决策代理改进决策场景与范式,提升决策能力。
作为环境与设计者的FM。在非智能体模块中,FM可充当环境与设计者 \({ }^{36}\),将状态信息形式化为马尔可夫决策过程(MDP),包含状态转移、奖励函数、策略、动作等。FM可作为动作执行目标、环境组成或环境状态转移桥梁,增强策略效果。\({ }^{207}\) 进一步地,FM设计并形式化环境状态格式与动作空间,提升策略生成能力。例如,FM的微调参数矩阵 \({ }^{208,209,210}\) 可视为环境,借助微调方法训练,用于生成对应策略与动作以更新FM参数。作为环境设计者,FM可设计相应状态编码 \({ }^{211}\)、奖励函数及状态转移函数 \({ }^{212}\),即用于形式化环境,如图3所示。作为条件生成模块,基于FM的条件生成表现模块 \({ }^{36}\) 可结合任务描述和条件输出行为生成(动作)与世界模型生成(环境动力学)。\({ }^{205}\) 此生成模型还可应用于文本或图像数据,建模行为、环境及长期轨迹。\({ }^{205,213}\) 行为与世界模型可视为策略,生成对应动作及MDP轨迹。生成的行为与世界模型可用于执行和形式化环境,勾勒环境条件生成信息。此外,在FM编码器模块中,FM用于将环境状态信息编码成提取表示,生成策略与动作。FM编码器模块可视为环境数据的多模态编码器,例如将视频数据转换为音频与图像数据,音频再编码成对应编码信息。非数值状态信息编码为数值向量,如将文本或图像编码为向量形式,便于输入大型模型。向量化 \({ }^{214}\) 是将非数值信息转为向量的有效方法,因此编码器模块是将状态信息转换为高效策略与动作生成形式的工具。FM架起状态表示形式转换的桥梁,将状态编码为更便于计算机处理的形式。
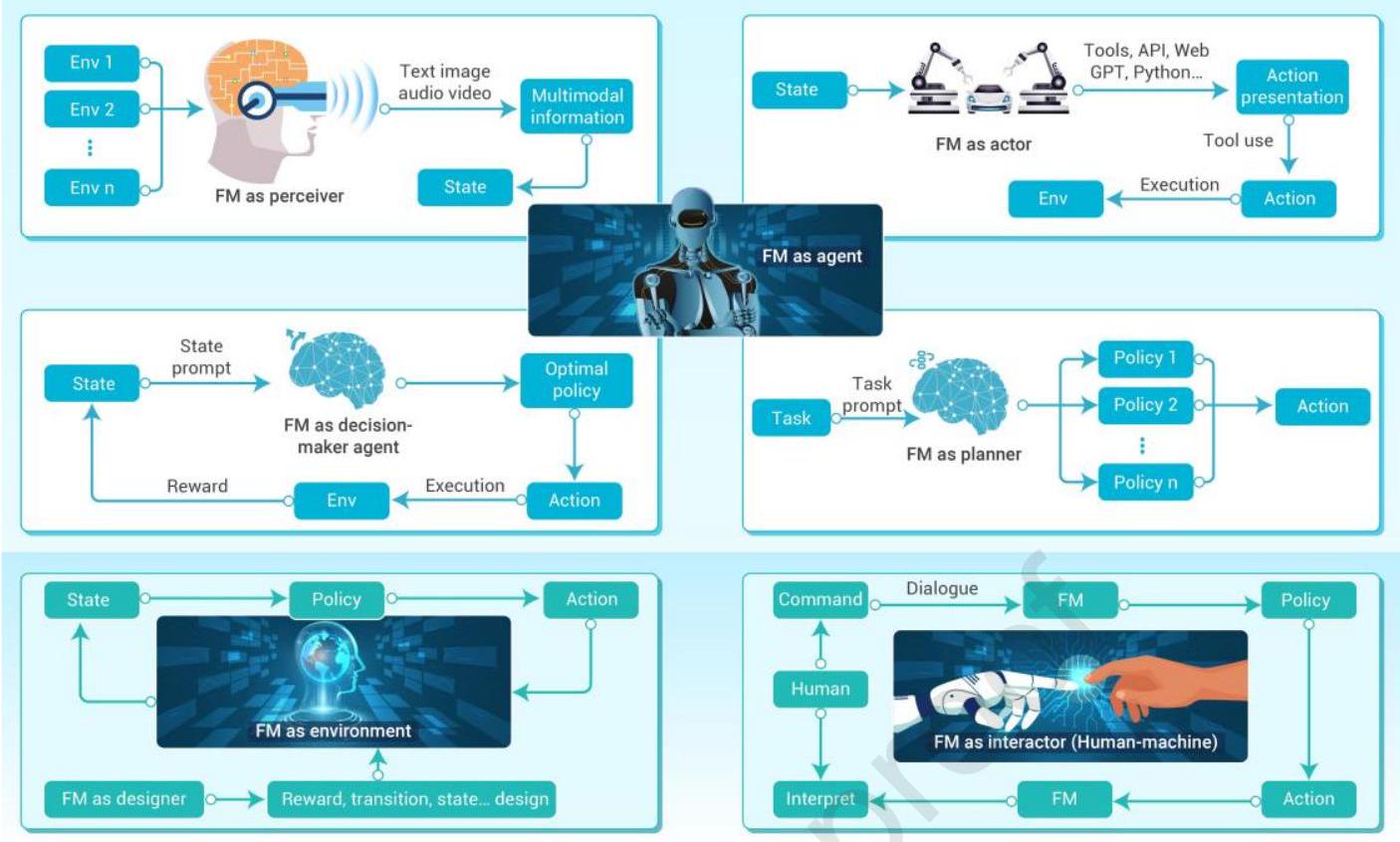
图3:基础模型在智能决策中的关键角色
作为人机交互者的FM。在基于FM的人机交互模块中,FM能根据人类以对话形式发出的指令生成相应策略、动作及解释。\({ }^{205}\) 通过基于文本、图像和音频的对话,FM实现人机智能交互。故FM可视为人机交互桥梁,可部署于机器人或无人车辆 \({ }^{215}\),提供智能问答服务。基于FM的多种决策范式有效促进决策模式及应用环境的适应性,多模态FM决策范式极大优化决策性能与泛化能力。
3.2 基于大型语言模型赋能的智能决策AI智能体¶
随着大型语言模型(LLMs)赋能的AI智能体出现,智能决策正经历深刻变革。不同于传统依赖手工规则、从头规划或调度算法的决策方法,LLM驱动的智能体利用大规模预训练模型,能实时处理和响应多样且动态的输入。这些智能体不仅擅长理解复杂任务与语境,还促进知识迁移,支持跨领域策略的快速适应。基于LLM的智能体一大优势是无需大量再训练即可迅速调整决策、优化动作,应对变化环境。借助思维链(Chain of Thought, CoT)\({ }^{216}\) 等机制,LLM智能体展现高度透明且可解释的决策流程,将复杂推理拆解为清晰步骤。此能力使其在复杂动态环境中优于传统决策模型,提供更灵活透明的决策框架,适合需要快速响应和实时决策的场景。
提升AI智能体决策能力的技术。LLM赋能的AI智能体显著提升决策能力,依托强化学习与人类反馈(RLHF)、检索增强生成(RAG)、搜索算法及高级推理方法等先进技术。RLHF已被证明在使LLM行为与人类价值对齐方面极为有效。\({ }^{217,149,218,219,187}\) 这类方法通常依赖人工标注的偏好数据集训练奖励模型,再通过强化学习引导LLM训练。传统RLHF采用近端策略优化(PPO)算法\({ }^{220}\) 进行对齐微调,但资源消耗巨大。为提高资源利用率,近年兴起直接优化LLM自身的方法。\({ }^{221,222,223,224,225,226}\) RAG通过检索相关外部信息改善知识获取,使LLM智能体能基于实时数据生成更准确、语境敏感的回答,特别适合需最新知识或跨领域复杂决策任务。\({ }^{150}\) 搜索算法,如束搜索和蒙特卡洛树搜索(MCTS),\({ }^{227,228}\) 通过探索多个候选解或模拟不同决策路径,提升复杂长期决策任务(如博弈论、战略规划)中的决策效率与鲁棒性。\({ }^{229}\) 先进推理方法如CoT \({ }^{216}\)、思维树(Tree of Thought, ToT)\({ }^{129}\) 和思维图(Graph of Thought, GoT)\({ }^{230}\) 深化推理能力。CoT通过拆解复杂推理步骤提高决策透明度,ToT和GoT则通过层级或图形结构帮助智能体处理复杂多步决策任务。上述技术共同赋能LLM智能体在多种动态环境中实现自适应、透明且信息充分的决策。
AI智能体的应用场景。LLM智能体广泛应用于战略推理,\({ }^{231}\) 博弈论,\({ }^{232}\) 实时决策,\({ }^{233,234,235,236,237}\) 以及跨任务知识迁移,\({ }^{238,239,240,241,242,243}\) 展现了其在复杂环境中的强大能力。在战略推理中,LLM智能体能预测动态且高度不确定环境中的对手行为,实时调整策略,尤其在多智能体博弈中,博弈论集成增强了决策效果。例如,在《星际争霸》等复杂策略游戏中,LLM智能体不仅预测敌方行动,还能适时调整策略以获取优势。随着LLM在实时决策中的应用日益广泛,诸如LLM-PySC2 \({ }^{233}\) 和SC-Phi2 \({ }^{234}\) 等测试平台成为评估LLM智能体宏观决策与战术协作能力的重要工具,解决多模态观测与实时反馈等挑战,推动复杂决策背景下LLM研究。在演绎推理任务中,LLM智能体表现同样亮眼。如在狼人杀游戏中,LLM能模拟人类欺骗、信任建立与策略沟通,增强对复杂动态环境的适应力。\({ }^{236,237}\) 在创造性任务中,LLM展现生成新颖定义的能力,如Minecraft \({ }^{244,245,246}\)、Balderdash \({ }^{247}\) 等游戏中体现其战略逻辑和创新思维,凸显其在推理与创造任务的潜力及广泛适用性。LLM智能体还应用于自动驾驶 \({ }^{241}\) 和机器人领域,\({ }^{240,242}\) 证明其在实时决策与战略推理中的实力。自动驾驶中,LLM智能体处理车辆及环境实时数据,快速识别潜在风险,制定应急策略,提供高效准确的决策支持。\({ }^{241}\) 机器人任务要求LLM接收自然语言指令,转化为机器人可执行的具体动作,需有效桥接语言理解与控制系统。\({ }^{240,242}\) 在复杂多智能体环境中,LLM智能体在合作与竞争中展现独特优势。TMGBench平台 \({ }^{248}\) 测试LLM智能体在多种游戏类型中的战略推理与决策能力,推进竞争场景下理性决策的应用。基于LLM的社会推理游戏日益受AI研究关注,AdaSociety \({ }^{249}\) 和AI Metropolis \({ }^{250}\) 等平台支持LLM智能体模拟和优化复杂社会动态与协作任务,提高决策效率和系统适应性。LLM智能体在经济决策领域的应用也在扩展,通过模拟真实经济交互,帮助研究者更好理解与预测经济行为,推动经济学、社会学等领域研究。\({ }^{238,239}\) 总体而言,LLM智能体技术的发展及其在复杂领域的多样应用,不仅提升了实时决策能力,也推动了战略推理、社会推理和创造性思维等创新。
AI智能体的限制与挑战。尽管LLM赋能智能体在多个领域表现出色,仍存在若干挑战和瓶颈。一大限制是其处理多模态数据的能力,尤其整合图像、音频或传感器信号时的不足。由于LLM主要针对文本输入设计,往往难以高效处理非符号数据,影响该类环境中的决策。此外,LLM智能体面临可扩展性和实时决策的挑战,尤其在低级控制任务中。尽管推理复杂,但在要求精确即时响应的动态环境中常显不足。在高频率、低延迟场景下,决策延迟可能削弱系统响应与效率。安全性依然是关键问题,特别是在高风险应用中。若缺乏与人类价值和安全协议的有效对齐,LLM智能体可能做出意外且潜在有害的决策。确保LLM智能体在复杂环境中做出稳健、安全的选择,并在不确定性下保持稳定,将是推动AI智能体技术发展的重要方向。
3.3 基于高级深度强化学习的智能决策¶
传统强化学习(Vanilla RL)将决策环境视为典型的马尔可夫决策过程(MDP),其完整元素在现实世界中很少完全存在。技术层面上,仍存在效率、泛化和可扩展性等瓶颈。同时,强化学习的成功高度依赖于基于非平凡专家知识的奖励设计。为此,研究者探讨了若干高级强化学习主题,以缩小理论与实践间的差距,使深度强化学习更易于应用。总体而言,这些研究聚焦样本效率、策略迁移、信用分配、不完全环境和安全性等问题。强化学习的不同范式如图4所示。
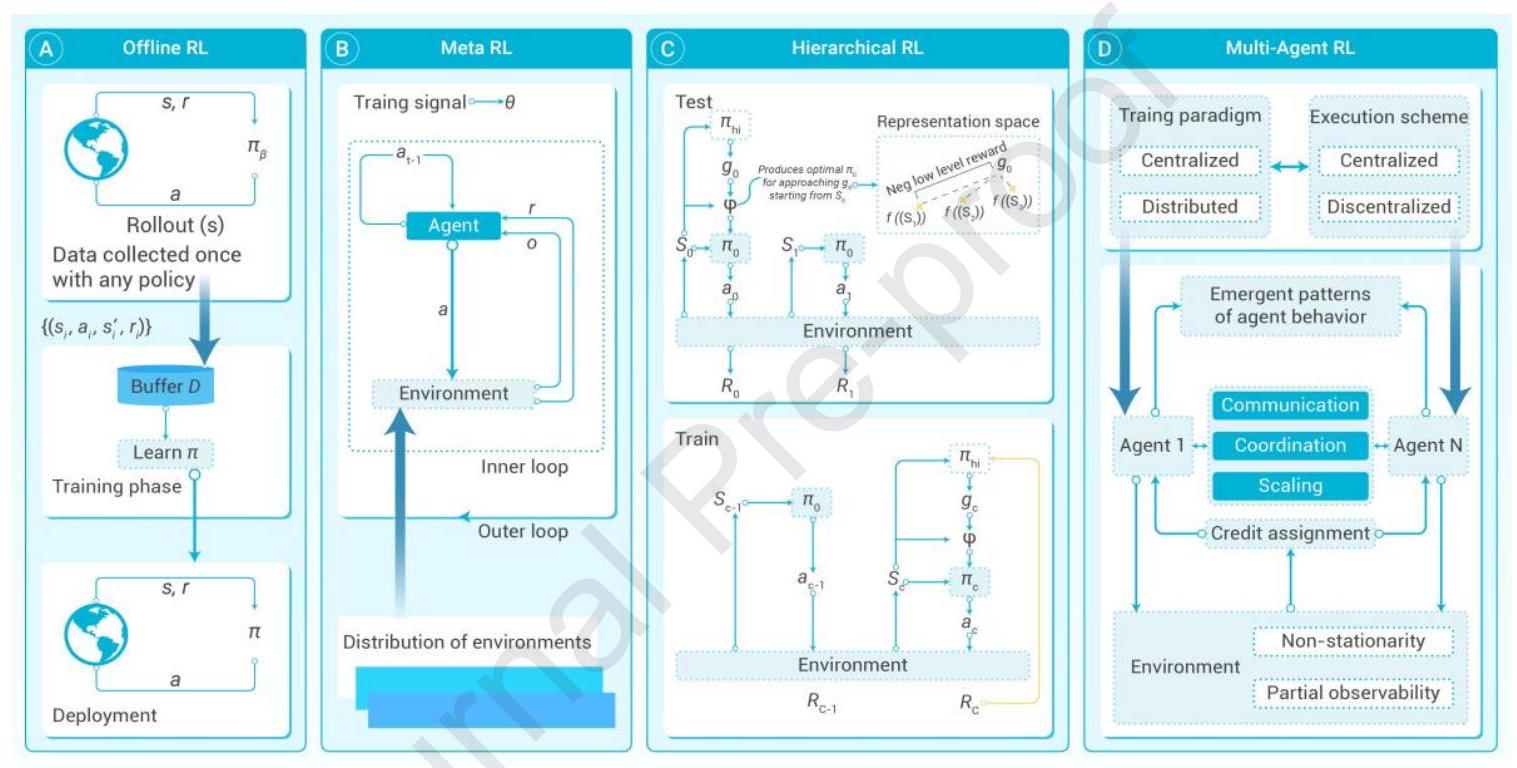
图4:强化学习的不同范式 (A) 离线强化学习:仅利用现有历史数据,无需或极少在线交互,学习最优或近似最优策略。 (B) 元强化学习:赋予智能体“学习如何学习”的能力,快速适应新任务。 (C) 层级强化学习:引入层级结构,将复杂任务分解为高层“元动作”或子任务及低层具体执行策略,简化学习过程。 (D) 多智能体强化学习:研究多个智能体通过协作或竞争学习最优策略的强化学习范式。
离线强化学习(Offline RL)。离线强化学习\({ }^{34}\) 指完全依赖静态历史数据集学习最优策略,摒弃在线交互中的试错模式。简言之,离线RL旨在提取并泛化历史数据中的知识,归纳出在类似环境下表现良好的策略。离线RL的实际需求源自风险敏感领域中探索不可行或高风险(如金融市场百万次自动交易),并涉及复用珍贵昂贵的数据集,降低数据采集成本。常用策略包括:(1) 行为正则化,将学习策略约束在行为策略附近,降低遭遇分布外(OOD)状态风险;\({ }^{251,252}\) (2) 带不确定性量化的Q学习及离线策略评估,抑制数据稀少区域的值估计过高,保障安全;\({ }^{253,254}\) (3) 隐式策略优化,利用序列或生成建模学习表达力强的决策器,如决策Transformer或扩散策略。\({ }^{255,256}\) 最新进展提供了较宽松的策略学习支持约束 \({ }^{35}\) 和价值学习方法 \({ }^{257}\),促进策略在行为策略支持范围内优化,取得业界领先表现。尽管前景广阔,离线RL仍面临实际挑战,包括OOD状态和动作的存在,\({ }^{258,259}\) 静态数据集的多样性与质量,\({ }^{260}\) 以及鲁棒的策略评估技术。此外,值得关注的挑战还有有效子目标定位、多效信用分配、子目标探索策略设计以及层级执行者间的协调。
元强化学习(Meta RL)。元强化学习考虑MDP分布上的泛化,训练智能体利用过往经验快速适应未见但相似任务。直观动机是打造通用智能体,具备学习能力,避免部署时从零训练。元RL的核心技术是编码元知识以快速适应,或从少量样本推断任务特征,使其适应变化环境,如多样地形的机器人控制和多场景自动驾驶,避免部署中的计算成本和样本效率瓶颈。现有典型方法包括基于优化的 \({ }^{17,261}\) 和基于上下文的 \({ }^{262,263,264,45}\)。MAML \({ }^{17}\) 是基于优化的方法,寻求元策略,通过梯度更新适配新MDP。PEARL \({ }^{262}\) 是基于上下文的方法,学习任务嵌入以实现任务特定策略的摊销。然而,元RL在元训练阶段计算和采样成本高,泛化能力严重依赖于任务分布设计(类似领域随机化)。作为创建可适应智能体的有希望方向,元RL仍需在任务分布设计、高效元训练和鲁棒性方面取得突破,以确保更广泛的适用性。
层级强化学习(Hierarchical RL)。复杂决策中任务结构清晰,层级强化学习(HRL)管理决策过程,将任务分解为多个层级。在高层策略中制定子目标,低层策略执行并达成这些子目标,从而将复杂的长时域任务拆分为一系列易管理子任务。例如,在自动驾驶系统中,导航智能体为高层策略,指挥低层控制器执行具体转向操作。此类分解促进模块化策略学习,通过跨任务指定多样组合技能提高样本效率。同时,HRL利用任务中的时间抽象,适应不同时间尺度的决策需求。常见方法为不同选项框架,选项为具有自身策略和终止条件的时序扩展动作。例如,MAXQ框架递归分解价值函数为更简单层级组成部分。\({ }^{265}\) 类似选项机制扩展至DQN形成H-DQN。\({ }^{266}\) HRL通过探索子目标代替具体动作提升探索效率,类似人类追求长远目标的战略规划。
多智能体强化学习(Multi-agent RL, MARL)。多智能体强化学习涉及多个自主智能体在共享环境中学习与交互,实现合作、竞争或混合目标。智能体决策非孤立,需适应环境动态及其他智能体策略变化。MARL适用于复杂实际领域,如群体机器人、实时战略游戏 \({ }^{267}\)、分布式控制系统 \({ }^{268}\) 及智能交通 \({ }^{269}\)。但MARL带来额外复杂性,需专门技术处理交互、通信、资源分配及战略决策。智能体可能存在目标冲突,需实现群体智能决策。MARL建模为随机博弈或马尔可夫博弈,旨在多智能体协调、竞争或混合环境中求稳健解。智能体需处理部分可观测性、多样交互,并实践去中心化学习。常用策略为中心化训练、去中心化执行(CTDE),训练阶段利用共享信息,执行阶段独立行动。独立学习将MARL降解为多个单智能体策略,缺乏训练阶段协调机制,难应对其他智能体策略变化引发的非平稳问题。\({ }^{270}\) 基于价值的方法将联合价值分解为个体价值,实现有效信用分配促进合作。\({ }^{271,272,31}\) 尽管如此,通信机制设计、信用分配、环境非平稳性等挑战依旧存在。\({ }^{273}\)
过去十年深度强化学习理论和应用均有突破,尤其上述高阶深度RL范式提升了复杂序列决策的可行性。然而,将深度RL扩展至更多实际场景仍不易,面临技术、安全和效率瓶颈,源于昂贵的环境交互、不稳定的策略学习动态及奖励设计。幸运的是,部分新兴AI智能体及先进生成模型展现出缓解这些限制的潜力,如世界模型逼近 \({ }^{274}\)、子目标设计 \({ }^{275}\) 和时间及多智能体层面的信用分配。\({ }^{276,277}\) 基础模型与高级RL方法在大规模决策模型中日益融合,以平衡效率与准确性。随着决策模型规模扩大,基础模型与RL的协同变得实现先进智能的关键。
3.4 基于高级基础模型的智能决策范式¶
在理解决策中的神经网络扩展规律时,必须覆盖足够丰富的决策场景进行预训练和元训练。然而,这一过程常伴风险,尤其是机器人可能执行危险动作,形成典型的“鸡生蛋还是蛋生鸡”困境。针对这一挑战,收集多样且高质量的数据集、开发反事实预测器,以及利用Sim2Real或Real2Sim2Real模块\({ }^{278}\),成为解决决策场景限制的有效策略。总体而言,图5概述了构建基础决策模型(FDMM)的有前景方法。
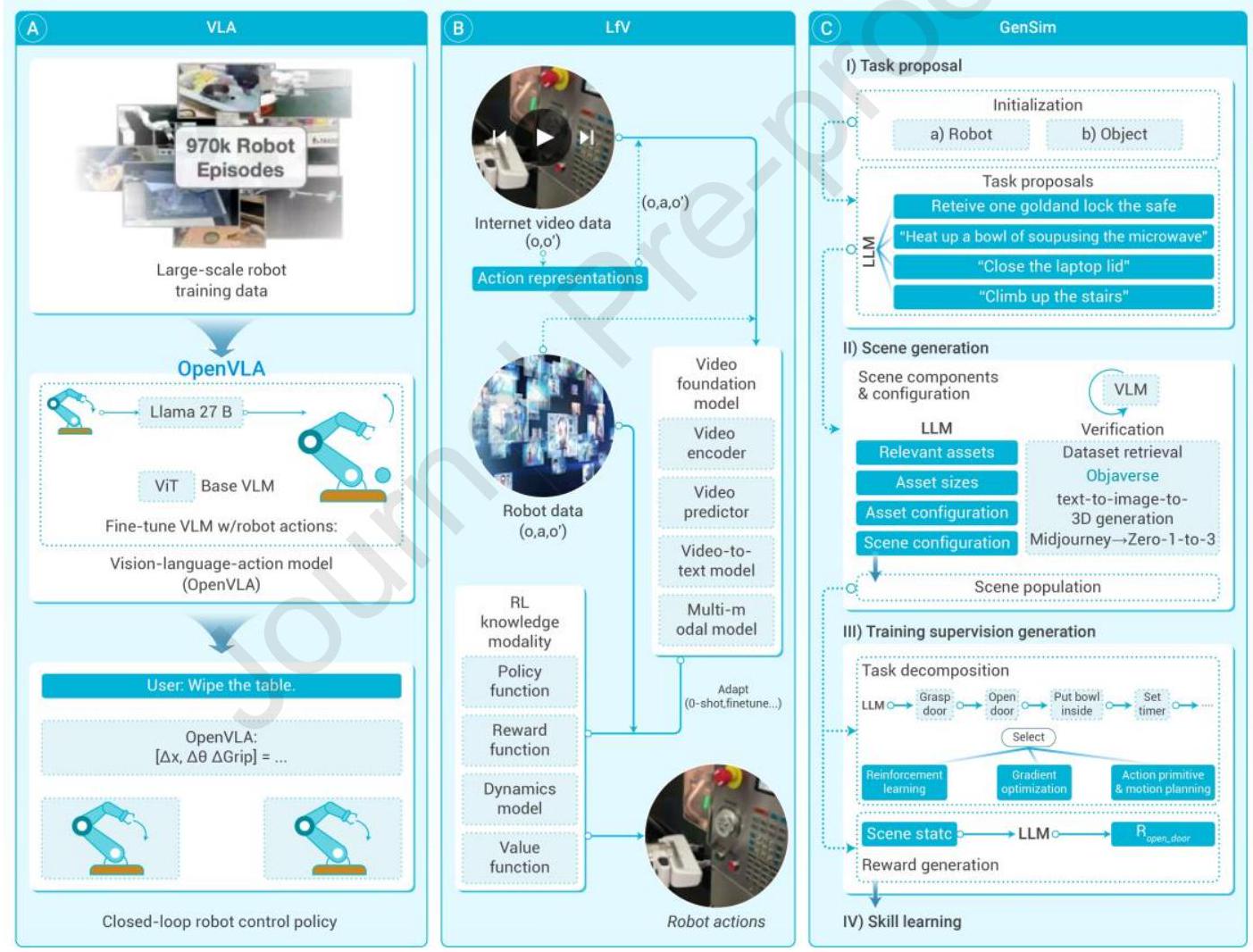
图5:基于基础模型的高级智能决策范式 (A) 视觉-语言-动作(VLA)结合LLM的层级推理与视觉模型的感知能力,将高阶任务拆解为可执行子任务,应对场景多样性和部分可观测性带来的计算与数据瓶颈。 (B) 视频学习(LfV)利用大规模廉价在线视频数据,将原始视频转化为结构化转移轨迹,实现通用智能体训练,挖掘现实世界中多样、嘈杂视频中的上下文信息。 (C) 生成式仿真(GenSim)结合仿真环境与提示引导的任务提案模块和智能体模块,创造多样决策场景并优化自适应策略,减少对昂贵真实数据的依赖,适用于机器人和自主系统等复杂任务。
示范学习(Learning from Demonstrations, LfD)与视觉-语言-动作(Vision-Language-Action, VLA)。人工智能决策的自然范式是示范学习\({ }^{279}\),即构建由专家策略指导的多样技能决策序列,供模型学习。LfD利用示范作为丰富监督源,提供环境中理想行为样例。LfD的离线设置支持概率模型生成场景特定序列,实现上下文依赖的策略学习。此概率框架可细致理解决策中的变异与不确定性,支持部分可观测环境的鲁棒策略开发。但随着场景多样性增加,所需交互序列呈指数增长,带来巨大计算和数据需求。部分可观测性进一步阻碍准确策略推导。VLA多模态基础模型作为有力替代,通过融合LLM的层级推理能力和视觉模型的感知能力,应对复杂决策任务。利用语言内在结构,VLA模型将高阶任务拆解为易管理子任务。行为克隆技术\({ }^{280}\) 直接将视觉输入(如图像或视频标记)映射至低阶执行动作。典型模型包括RT-2 \({ }^{281}\)、UniPi \({ }^{282}\) 和OpenVLA \({ }^{283}\),展示了示范在训练通用智能体中的价值。这些模型借助编码于语言中的人类决策先验,通过示范提升多模态理解与动作执行能力。示范学习随时间成为下游任务不可或缺的资源,增强模型在多样环境中的泛化能力。然而,VLA模型面临关键限制,包括对大规模视觉-语言-动作数据集和多模态决策序列的依赖,限制了其在未知场景中的扩展性和泛化潜力,成为发挥其全部能力的瓶颈。未来研究需攻克数据与计算挑战,确保其在实际任务中的广泛适用性和鲁棒性。
视频学习(Learning from Videos, LfV)。高质量多样示范是训练鲁棒决策智能体的关键,但通常需大量时间和资金。培养通用决策者,关键在于寻找成本效益高的交互序列来源。互联网提供了丰富廉价的视频资源,记录了现实中对象交互,环境自身可视为生成模型。基于此,LfV\({ }^{284,285}\) 利用大规模视频数据集构建综合视频基础模型,推断隐式动作。LfV侧重将原始视频转化为结构化转移轨迹。借助弱监督和无监督学习技术,LfV间接标注动作和奖励,降低人工标注需求,实现从未整理嘈杂数据集中提取有效任务示范。生成的序列作为策略学习数据集,桥接感知与决策。LfV优势在于利用海量在线廉价数据,显著降低训练样本生成成本。视频中丰富多样的场景提供了支持复杂任务泛化策略学习的上下文信息。关键进展包括采用自监督学习和对比学习技术,解决动作分割与状态表示难题。但LfV仍面临重要挑战:视频数据的部分可观测性(关键状态可能不可见)妨碍准确策略推导;无关物体和环境干扰产生噪声,导致轨迹次优;动作空间不完整或不精确,因视频可能缺少任务所有可能转移的完整覆盖。即便最新交互式生成决策模型Genie-2依赖大量专家视频注释。\({ }^{284}\) 未来需通过精炼动作空间、多模态信号表示与鲁棒数据过滤机制,解决这些瓶颈,确保扩展性与可靠性。
生成式仿真(Generative Simulation, GenSim)人工智能。为降低数据采集成本,GenSim\({ }^{286,287,288,289}\) 利用仿真环境促进决策与策略学习。其框架包含两个关键组件:任务提案模块,基于提示生成多样仿真场景;智能体模块,学习适应或优化跨场景策略。该范式无需完全依赖昂贵真实数据,即可探索复杂多样的决策环境。在RoboGen等实现中,\({ }^{287}\) LLM集成任务提案机制,将高层任务分解为子任务,使智能体能调用仿真API、检索知识并通过强化学习训练低层策略。此模块化框架提升扩展性与适应性,适合机器人与自主系统等现实应用。OMNI \({ }^{289,290}\) 通过模拟涵盖广泛现实条件的决策环境即为典范。在GenSim中,“生成”涵盖两个关键维度:决策场景创造与具备跨任务鲁棒适应能力策略开发。\({ }^{286}\) 这些仿真场景支持策略测试与改进,缩小合成与现实环境差距。该迭代反馈环加速策略学习,减少对真实数据依赖,并支持高风险场景的主动实验。
然而,GenSim面临关键挑战。其有效性依赖于仿真器的准确性与保真度,仿真与现实动力学差异导致策略性能下降,称为Sim2Real差距。\({ }^{291}\) 此外,Real2Sim2Real框架指出,策略在仿真与现实间迁移的复杂性增加难度。确保策略的鲁棒泛化、设计高保真仿真器以及验证动态现实环境中的策略表现,是GenSim亟待攻克的研究方向。通过整合LLM指导任务设计、可扩展仿真模块与强化学习技术,GenSim如Genesis代表了低成本自适应决策研究的有力方向。\({ }^{286}\) 然而,解决其技术与理念瓶颈是充分发挥潜力的关键。
3.5 大规模智能决策的关键技术¶
本节介绍大规模智能决策的关键技术。为清晰展示这些技术的协同工作机制,首先提出一个框架,如图6所示\({ }^{292}\)。该框架勾勒了智能体决策过程中的核心技术组件及其相互关系,提供了理解各技术元素在智能决策中作用的直观视角。
通过“记忆”(Memory)、“规划”(Planning)、“工具”(Tools)与“动作”(Action)的集成应用,大规模智能决策系统能高效处理复杂任务,实现决策流程的自动化与优化。下文将详细讨论各技术模块及其在智能决策中的作用。
大规模智能决策系统整体可视为一个智能体,通过多个技术模块协同实现高效决策。图6中将这些技术归为四类:“记忆”、“规划”、“工具”和“动作”。该框架展示了智能体决策过程中的关键技术组成及相互联系,帮助理解这些技术如何支撑大规模智能决策。
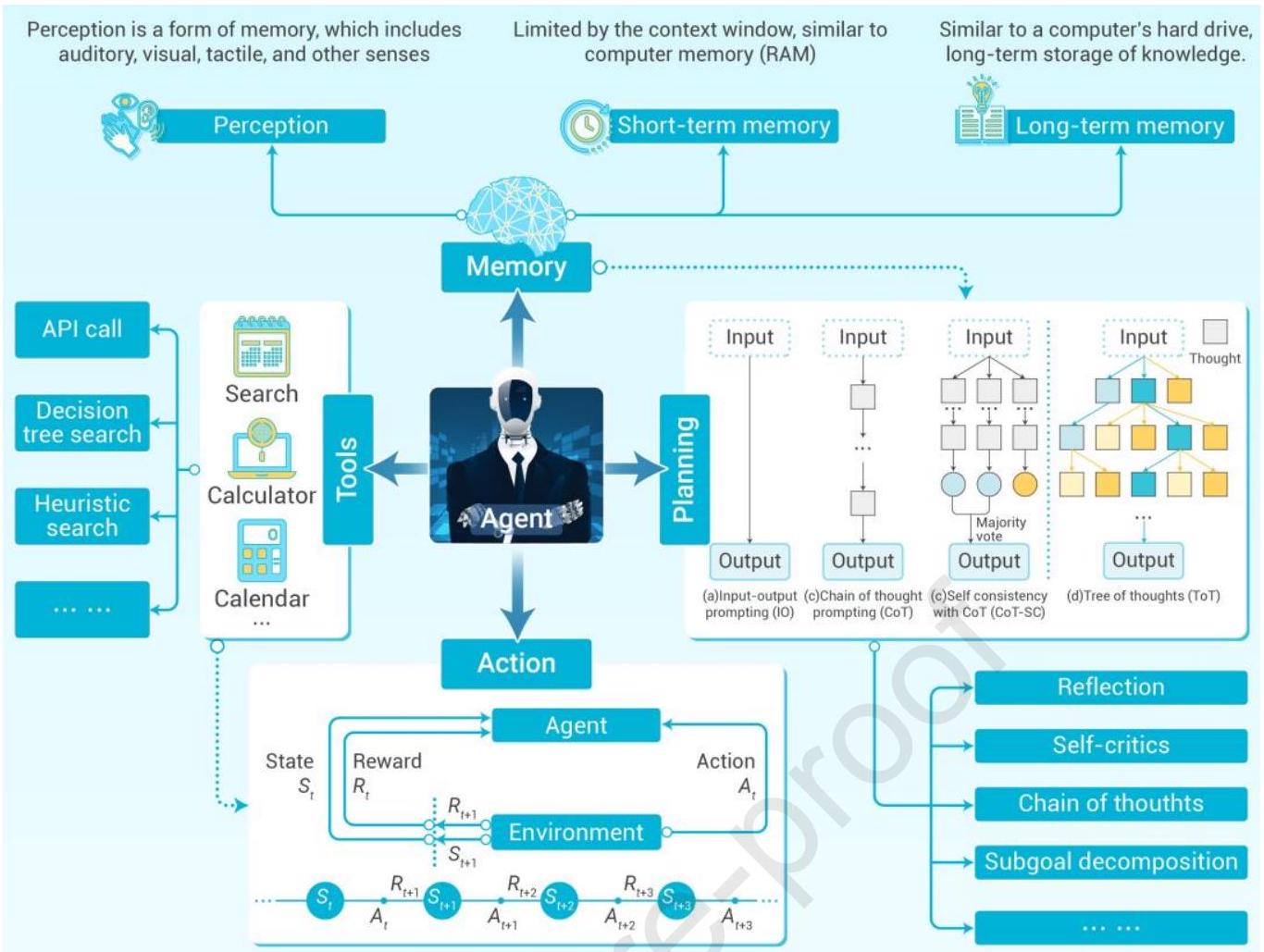
图6:智能决策关键技术示例 大规模智能决策系统可视为一个“智能体”,其核心技术框架大致分为四个模块:记忆、规划、工具与动作。智能体通过感知模块获取外部环境信息,并存储于短期与长期记忆中。规划模块基于当前环境状态和历史信息生成决策方案,工具模块提供计算和搜索等外部资源辅助决策。最终,智能体根据规划结果执行相应动作,影响环境状态,并通过环境反馈进一步调整行为策略。
通过整合“记忆”、“规划”、“工具”和“动作”,大规模智能决策系统能够有效应对复杂任务,实现决策自动化与优化。例如,在自动驾驶中,智能体利用记忆模块回忆交通规则和历史信息,规划路径,实时应用传感器和地图数据等工具,制定最佳驾驶策略。在智能电网管理中,智能体基于历史数据和实时电网状态进行电力调度和优化,确保电网高效稳定运行。接下来将具体探讨各技术模块及其在智能决策中的作用。
记忆模块。在大规模智能决策技术中,记忆技术通过积累历史经验优化决策过程,提高效率,减少错误。它使系统能在复杂环境中学习与改进,通过经验回放加速学习,支持个性化和上下文感知的决策。此外,记忆增强系统的稳定性与可解释性,使决策轨迹可回溯,提升透明度。在多智能体系统中,记忆促进知识共享和协同决策,提升整体性能。它还帮助系统及时发现异常、诊断问题并调整策略,增强系统鲁棒性和适应性。
早期对记忆机制的探索多聚焦于模型设计与算法优化,寻求高效存储和利用历史信息的方法以提升任务表现。\({ }^{293,294}\) 经典且具代表性的方法之一是循环神经网络(RNNs)\({ }^{295}\),通过跨时间步隐状态循环传递信息,使模型具备记忆能力。然而,梯度消失问题导致RNN难以有效学习长期依赖,限制其仅在短期范围内保持信息,长依赖任务表现不佳。
为此,学者提出多种改进方法。\({ }^{296,297,298}\) 其中,长短时记忆网络(LSTM)\({ }^{296}\) 在RNN基础上引入门控机制,部分缓解梯度消失问题,显著提升短期记忆建模能力,广泛应用于时间序列分析和自然语言处理(NLP)任务。\({ }^{299,300}\) 但LSTM仍面临并行能力差、长距离依赖建模能力有限等挑战,处理长序列任务时效率较低。
然而,上述方法难以满足长期记忆需求。为应对这一挑战,研究者广泛探索提升长期依赖建模和利用的方法。\({ }^{301,302,303}\) 其中,记忆网络(Memory Networks)\({ }^{301}\) 提出带显式长期存储的神经网络架构,实现知识的存储与检索,开创了显式长期记忆建模的成功尝试,为后续增强记忆神经网络奠定基础。通过引入外部记忆组件,记忆网络使模型更有效访问和利用存储信息,提升处理长期依赖和复杂推理任务的能力。另一方面,Transformer\({ }^{58}\) 利用自注意力机制动态分配权重,捕捉输入序列内部依赖,突破传统序列时间步限制,极大增强模型的并行计算能力。注意力机制动态筛选与当前任务相关的关键信息,减少计算冗余,使智能体能在短时间内快速决策。该架构奠定了大量大规模预训练模型(如GPT、BERT)的基础,确立了现代机器学习研究与应用中广泛采用的预训练-微调范式。
自Transformer问世以来,基于其架构的改进方法层出不穷。\({ }^{304,305,306,307}\) 其中,2020年提出的压缩Transformer(Compressive Transformer)\({ }^{304}\) 结合短期与压缩记忆,保持长序列任务中的历史上下文,提升Transformer的记忆建模能力。同年,检索增强生成(RAG)\({ }^{308}\) 提出语言模型结合外部数据库检索的框架,弥补模型知识有限问题,促进长期依赖建模与知识增强任务生成,有效突破语言模型知识记忆瓶颈。近年,Mamba\({ }^{309}\) 等工作通过引入选择性状态空间模型(SSM)与线性递归机制,提出新颖记忆建模框架,实现低复杂度高效状态更新,对序列任务性能提升和长期依赖建模具有潜力。
规划与控制技术。智能决策的关键技术依赖合理的规划方法、工具使用和动作执行。规划技术通过分析任务需求和约束设计最优动作方案,确保决策有效且可行;工具使用技术为智能体提供必要辅助资源,支持信息高效处理、问题解决及任务完成;动作执行技术保障智能体根据规划准确快速地执行具体操作,实现预期目标。三者有机结合,使智能决策高效且精准。
过去,规划问题受广泛关注。\({ }^{310,311,312}\) 其中,分层任务网络(HTN)\({ }^{310}\) 通过层级分解任务,将高层目标逐步细化为具体操作步骤,形成可执行规划路径,作为早期规划技术经典代表,数十年广泛应用。
随着机器学习与环境建模融合,2018年提出的世界模型(World Models)\({ }^{313}\) 引入智能体通过学习环境潜在表示进行规划与决策,模拟环境状态,突破动态环境中复杂决策难题,显著提升任务规划的泛化能力与效率,广泛应用于策略游戏和强化学习任务。
此外,研究者开始探索“工具使用”方法,旨在赋能智能体学会有效利用现有外部工具,提升规划与执行能力。部分研究\({ }^{314,315}\) 将神经网络与模块化工具结合,支持逻辑推理与复杂任务分解,展示模型利用工具完成任务的潜力。近期提出的Toolformer\({ }^{316}\) 通过自监督学习,训练模型自主决定调用API的时机、传递参数及整合结果,显著提升模型零样本学习能力。但Toolformer存在工具调用机制固定、上下文适应性不足、复杂任务泛化能力有限等缺陷。ToolLLM\({ }^{317}\) 构建了名为ToolBench的工具使用指令调优数据集,提出深度优先搜索决策树(DFSDT)方法,使开放式LLM能调用超过1.6万个真实API,显著提升推理和泛化能力。然而,ToolLLM仅在窄领域任务(如特定类别工具操作)表现优异,难以应对多任务、多领域复杂交互。相比之下,最新提出的OS-Copilot\({ }^{318}\) 构建通用框架,实现与操作系统的全面交互,使智能体能在网页、终端、文件、多媒体及第三方应用等多领域自主操作,解决当前智能体任务范围和工具适应性限制,为构建通用操作系统级智能体提供技术基础,推动其从工具调用向开放环境多任务、多领域适应性进化。
随着GPT-4等LLM发展,融合推理与行动的规划技术成为研究热点。谷歌DeepMind提出的ReAct\({ }^{319}\) 结合基于自然语言的思维链推理与工具使用,实现高效规划。该方法利用LLM推理能力拆解复杂任务,直接与工具或环境交互执行动作,为更高级多功能规划系统铺路。近年提出的世界知识模型(WKN)\({ }^{320}\) 集成先验任务知识与动态状态知识,显著增强智能体在复杂环境中的全局规划与动态适应能力,在多任务中取得性能突破。此外,ReAct\({ }^{319}\) 提出结合思维链推理与动态工具使用的方法,有效整合LLM推理与执行能力,实现决策任务中高效动作执行。Voyager\({ }^{321}\) 进一步推进开放世界环境中的探索与技能复用,借助LLM通过自然语言生成行动计划与代码,动态适应任务目标,并引入长期记忆机制存储与复用技能,展现了在开放世界游戏Minecraft中的自主探索与任务执行能力,解决了开放环境中的自主探索、技能获取和持续学习挑战,显著提升智能体在动态环境中生成与优化动作的能力。
3.6 仿真技术及其在智能决策中的关键作用¶
仿真技术通过数学公式、物理模型、机器学习算法、计算机生成的表示或其组合,复制现实世界的过程或系统,使得研究复杂行为、底层特征和涌现现象成为可能。\({ }^{322}\) 仿真凭借探索因果关系和基于模型的情景分析能力,这类“假设性”分析成为评估潜在结果和指导未来决策的宝贵工具。\({ }^{323}\) 除了直接支持决策,仿真技术在智能决策范式中(如强化学习和基础模型)也发挥着不可或缺的作用,承担优化学习环境、生成海量数据、实现全面测试评估等多重关键功能。因此,该技术已广泛应用于交通、社会系统、经济、军事行动、能源管理等复杂系统的分析和决策。\({ }^{324}\) 尽管基于仿真的方法在支持决策时具备可控分析优势,现实应用中仍面临若干限制:(1)计算效率与仿真精度难以平衡;(2)提升模型在未知场景中泛化能力的仿真环境设计存在挑战;(3)决策变量耦合机制尚不明确。幸运的是,仿真作为跨学科解决方案,持续融合前沿信息通信技术(ICT)和人工智能技术,推动自身发展。例如,知识-数据联合驱动建模、多模态与多任务仿真、计算实验方法\({ }^{325}\)催生了平行智能\({ }^{326}\)、生成式仿真\({ }^{286}\)、数字孪生\({ }^{327}\)等创新仿真理念。尤其是将大型语言模型(LLMs)引入建模与仿真,焕发新活力,备受关注,推动复杂系统智能决策进步。
基于仿真的智能决策。美国国防部将仿真定义为利用物理、数学或其他逻辑模型对系统、实体、现象或过程进行时间上的复制,以支持管理或技术决策。\({ }^{328}\) 仿真支持实验、假设检验与情景分析,为多领域系统行为在不同条件下的理解与决策提供有价值见解。技术进步推动仿真发展,诞生平行智能\({ }^{326}\)、基于LLM的智能体建模与仿真\({ }^{329}\)、仿真智能决策生成\({ }^{324,330}\)等创新概念,均紧密关联智能决策。根据支持决策的方式,仿真动机可分为:(1)基于仿真的预测——通过分析一个或多个变量未来趋势,探索解空间,辅助未来决策。例如,在COVID-19疫情期间,开发了基于多源信息融合的交互式个体模拟器,用以预测疫情传播。\({ }^{331}\)(2)因果推理——通过改变外部干预进行假设实验,基于实验结果调整决策,支持干预管理。例如,朱等人\({ }^{332}\)提出细粒度人工社会结合功能数据模型的通用计算实验框架,评估不同干预措施效果,旨在达到效益与成本的帕累托最优。(3)涌现发现——利用多尺度仿真研究涌现行为与要素耦合机制,获取新知识,提升决策效果。以大型交通枢纽疫情防控为例,开发个体级移动模型与接触网络,精准模拟传染病传播。\({ }^{333}\) 研究发现累积发病率呈线性增长,区别于城市静态网络的指数增长模式,为制定更有效控制策略提供依据。
仿真增强智能决策。仿真在多智能体强化学习与具身智能体的训练、学习与评估中发挥重要作用。它提供安全、高效、可定制的环境,生成大规模训练数据,实现模型性能和泛化能力的全面评估。此外,仿真为模型优化和部署前测试(Sim2Real)提供关键支持,保障真实应用。\({ }^{334}\) 根据辅助强化学习和基础模型等智能决策范式,仿真动机可细分为:(1)提供安全、低成本、可定制的测试或交互环境,生成训练和测试数据,加速学习过程。例如,自动驾驶与机器人领域的真实环境测试存在安全风险和高昂实验成本,仿真环境可按需定制多样条件,安全、经济地模拟各种罕见、危险或难以复现的实际情景,全面测试模型鲁棒性与适应性。典型平台包括TongVerse\({ }^{335}\)、Isaac Sim\({ }^{336}\)和Genesis。(2)评估模型泛化能力,支持多样评估指标。仿真允许模型在多样化且贴近现实的场景中测试,验证其从仿真到现实的泛化能力。生成式仿真\({ }^{286}\)使此过程更具成本效益与高效性。仿真环境还支持平均奖励、最佳单实例奖励、样本效率等多种评估指标,帮助全面可靠地衡量模型表现。例如,RL-CycleGAN在仿真训练并在真实机器人抓取任务中验证,表现卓越。\({ }^{337}\)(3)通过人类反馈优化强化学习,实现人机价值对齐。RLHF中,仿真可生成后验反馈,评估模型行为是否真正有益。例如,引入的基于回顾性仿真的强化学习(RLHS)模拟合理结果并诱导反馈,评估行为的实际效用,降低模型行为与人类价值不一致的风险。\({ }^{338}\) 实验表明,RLHS在帮助用户达成目标及满意度评价上持续优于RLHF。
开放挑战与未来方向。本文探讨基于仿真的智能决策面临的挑战与未来研究方向:(1)数据与知识联合驱动的建模与仿真。仿真与真实环境差异意味着仿真中表现优异的模型在真实部署时可能效果大打折扣,如何结合不同尺度信息构建仿真环境尤为关键。基于知识的方法受限于当时认知能力,往往难以精准捕捉复杂系统演化机制;数据驱动方法依赖数据量与质量,观测数据缺失时效果大幅下降。因此,充分利用两者优势,研究数据与知识联合驱动建模与仿真是未来重要趋势。(2)大规模仿真系统中计算效率与仿真精度的权衡。大规模复杂场景的仿真面临效率、扩展性和资源消耗等挑战,如何优化仿真系统支持大规模训练与测试,尤其针对基于API的商业LLM模型,是亟需解决的问题。故系统层面(如计算任务优化)与提示层面(创新提示策略)的优化,以保证结果准确同时缩短运行时间,是未来研究重点。除此之外,构建开放可扩展仿真平台、大模型赋能建模与仿真工作流、实现仿真环境中的持续学习、多模态多任务仿真等问题,也引起广泛关注,值得深入探讨。
通过应对上述挑战并探索未来方向,仿真技术有望显著提升智能决策能力,推动人工智能领域进一步发展。
4. 基于基础模型的科学智能决策¶
随着人工智能技术的持续进步,基础模型(Foundation Models,简称FM)在科学领域中日益成为核心力量,显著推动了科学研究和决策能力的提升。本章探讨了基础模型在信息科学、数学科学、生命科学、医疗健康、牙科、城市科学、农业科学、经济科学和教育科学等多学科领域的应用,详细阐述了它们在增强科研能力和提升决策质量方面的作用。相关内容结构如图7所示。

图7:基础模型驱动的多学科科学智能决策(展示了FM在智能决策中的核心作用,支持多样数据类型训练,并展示其在信息科学、数学科学、生命科学、医疗健康、牙科、城市科学、农业科学、经济科学和教育科学等关键科学领域的应用)。
4.1 信息科学¶
基础模型(FM)通过大规模自监督学习预训练,在信息科学的多种下游任务中表现出强大的泛化能力。\({ }^{50}\) 它们的迁移学习能力使其在推理\({ }^{339}\)、控制\({ }^{340}\)、规划\({ }^{341}\)和搜索\({ }^{50}\)等领域取得成功,涵盖机器人学、自动化、遥感、通信和电力系统等应用。例如,基于FM的模型赋能机器人在现实世界中操作,并通过数据驱动洞见支持人类决策。与特定任务模型不同,FM通过共享任务间的特征实现对未知问题的泛化,支持上下文学习和跨模态处理。\({ }^{48}\) 例如,Gato\({ }^{342}\)作为通用代理,能进行聊天、图像描述、游戏和机器人控制。\({ }^{339}\) 通过整合多样数据集,FM增强了Atari游戏\({ }^{11}\)、棋盘游戏\({ }^{343}\)和机器人任务\({ }^{344,345}\)中的序列决策,展现了未来智能系统的巨大潜力。
通用机器人与自主系统。 在FM出现之前,机器人领域的深度学习高度依赖特定任务数据集,限制了其灵活性和可扩展性。\({ }^{346}\) 传统机器人系统需要手工策划特定任务的数据集,难以应对复杂或陌生环境。FM通过在多样数据集上的大规模预训练,结合特定任务微调,改变了这一范式。这使得FM能够学习可迁移的表征,机器人能从原始传感输入中提取高级语义特征,并应用于多样决策过程。特别地,上下文学习和指令微调技术使机器人能从自然语言提示或多模态信号推断任务目标,无需显式重训。FM最具变革性的特性之一是其零样本学习能力,依托对比学习和基于提示的适应机制,使机器人能够无需针对任务训练即泛化到未知任务,大幅提升其在非结构化或新颖环境中的适应性。\({ }^{347}\) 典型FM模型如BERT\({ }^{59}\)、GPT-3\({ }^{61}\)、GPT-4\({ }^{13}\)、CLIP\({ }^{14}\)、DALL-E\({ }^{62}\)和PaLM-E\({ }^{240}\)展示了其在机器人领域的多样性。BERT起初设计用于自然语言处理,帮助机器人解码复杂语义信息,尤其适合多步骤语言指令。GPT-3和GPT-4以其自然语言推理和生成能力著称,使机器人能够处理用户命令并制定多步骤行动计划。CLIP实现文本与视觉表示对齐,支持机器人基于文本描述识别与交互对象。DALL-E通过生成合成环境支持任务演练和路径规划。在多模态推理方面,FM整合异构传感数据为统一表征,提升机器人的感知、推理和决策能力。\({ }^{348,349,350,351,352,353,354}\) 这些能力使机器人能将文本命令关联至对象、位置和动作,促进空间推理及实际任务执行。例如,PaLM-E整合视觉、语言和传感输入,赋予机器人处理复杂场景的强大推理能力。\({ }^{240}\) 机器人群智能的最新进展进一步体现了FM的影响力。传统群机器人依赖预定义通信协议和特定任务规划策略,而利用大型语言模型DeepSeek进行推理与交流则催生了类人群体行为。\({ }^{355}\) 在去中心化的多机器人系统中,个体仅掌握局部信息,FM使机器人能够发现同伴、交换信息并通过自然语言动态协调。零样本实验结果显示,合作、协商与互纠错等社会行为涌现,模拟了人类团队协作的部分特征。这一创新路径展示了FM驱动代理构建互动社会的可能性,推动了“机器人人类学”研究并揭示自主系统中协作结构的涌现机制。
FM从预训练中迁移知识的能力,显著缩短训练时间并减少计算资源需求。模仿学习中,FM利用视觉或文本形式的专家示范生成高质量策略。\({ }^{356}\) 强化学习中,FM通过语言驱动的奖励机制优化策略,减少迭代次数提升任务表现。\({ }^{357}\) 此外,大型视觉语言模型(VLM)支持机器人视觉问答(VQA)和视觉内容描述生成,简化数据标注和任务执行。\({ }^{358}\) 通过微调,FM适应多样机器人应用,如自主系统、家用助理、工业自动化及多机器人协调。\({ }^{359}\)
这些进展突显了FM在增强跨模态推理和连接用户意图与机器行动方面的变革性影响。FM在机器人领域的集成标志着自主系统发展的重要里程碑。不同于传统基于规则或特定任务学习方法,FM利用多模态数据上的大规模预训练实现跨场景泛化。通过Transformer架构和自监督学习,FM能解析自然语言指令并推断用户意图,确保自主系统与人类目标高度契合。具体而言,提示工程和指令微调技术使FM能基于上下文线索动态调整响应,提升动态环境中的决策能力。
除了理解命令,FM还通过结构化推理和少样本学习提升机器人智能决策。它们利用跨模态嵌入,使自主系统能够关联视觉、语言和运动等感知输入,做出上下文感知决策。\({ }^{360}\) 例如,GPT-4\({ }^{13}\)和PaLM-E\({ }^{240}\)展示了处理复杂语言指令并高精度转化为机器人可执行动作的能力。对比学习和强化学习技术使模型响应模式通过真实反馈不断优化。此外,这些模型的可靠性取决于学习表征质量和提示结构优化,强化了下游任务微调策略的重要性。FM与机器人深度整合,奠定了未来自主系统的基础技术地位。
遥感领域的多模态理解。 近年来,遥感技术取得显著进展,多样传感器(光学、热成像、雷达等)促进了地表高分辨率数据采集。光学传感器捕捉可见光和近红外光用于植被与地貌分析,热成像传感器监测火山活动和气候变化,雷达传感器则在极端天气条件下为土壤水分估计和城市基础设施测绘提供关键数据。\({ }^{361,362,61}\) 基础模型通过自监督学习整合大规模多光谱和多时相数据,显著提升遥感能力。与需特定任务特征工程的传统模型不同,FM利用Transformer架构学习跨传感器模态的时空相关性。例如,基于卫星影像与地理空间描述预训练的视觉语言模型,实现了无需大量标注数据的零样本地表变化分类和分割。此外,对比学习使FM能对齐卫星图像与文本描述,提升从异构遥感数据中提取有意义模式的能力。这些能力极大提升了森林砍伐监测、灾害响应和气候建模等任务的效率和准确性,体现了FM在遥感应用中的变革性影响。
FM在遥感任务中的应用,如场景分类、语义分割、目标检测和变化检测,显著提升了性能并设定了新标杆。最初,卷积神经网络(CNN)如ResNet\({ }^{72}\)被用于提升图像识别和分类任务。随后,Transformer利用自注意力机制建模长距离依赖,更有效处理大规模图像数据。\({ }^{58,363}\) 在遥感领域,FM通过自监督学习技术即使无大量标注数据也能学习鲁棒表征,提升其多样性和适用性。\({ }^{364}\) 卫星掩码自编码器(SatMAE)作为专为时序和多光谱卫星图像设计的模型,在变化检测任务中表现突出,因其学习了空间和时间特征。\({ }^{365}\) Scale-MAE将尺度感知学习融入自编码器框架,捕获多尺度地理空间表征,适用于城市规划中宏观与微观细节并重的基础设施测绘和土地利用分类。\({ }^{366}\) 此外,DINO-MC通过自监督学习改进了FM的全局与局部对齐能力,将对比学习扩展到全局特征与局部图像块的对齐,提升了目标检测和场景分类的性能。\({ }^{367}\) 这些模型利用FM的强大能力显著推进了复杂遥感数据处理,推动环境监测和城市发展规划的进步。尽管面临高质量多样化数据集需求和大量计算资源等挑战,FM的进步标志着遥感领域迈入新纪元,设定了准确率和效率的新标准。
智能制造的高效决策。 传统机器学习方法在智能制造系统中处理多模态数据时面临重大挑战,因其通常依赖特定任务的特征工程和针对生产线或制造过程设计的专门模型。这不仅带来巨大计算和人力成本,也限制了模型在工业多样化场景中的泛化能力。此外,传统ML模型往往难以有效整合异构数据源,限制了其跨模态推理和自适应决策的能力。相比之下,FM利用跨模态嵌入表示学习将多模态数据映射至统一向量空间,促进不同模态间的信息融合与协同决策。通过对多样数据集的大规模预训练,FM获得强大的零样本和少样本学习能力,使其能以极少调整泛化到未见任务。这些特性显著提升了其在动态复杂工业环境中的可扩展性、适应性和整体性能,为智能数据驱动制造系统的发展提供了有力方向。传统深度学习模型在预测性维护(PHM)中常面临泛化能力有限、多模态数据处理困难和多任务执行不足等问题,阻碍其在动态工业环境中的应用。GPT类模型凭借捕捉长期依赖的能力,在处理多样传感器数据流如振动\({ }^{368}\)、声音\({ }^{369}\)、电流\({ }^{370}\)、电压\({ }^{371}\)、温度\({ }^{372}\)和压力\({ }^{372}\)等方面表现突出。例如,时间序列Transformer(TST)集成了时间序列标记和Transformer架构,在旋转机械故障模式识别上显著优于传统CNN和RNN。\({ }^{373}\) 此外,通过提示工程融入领域知识,FM无需改变模型架构即可提升输出质量和准确度。\({ }^{374}\) VS-LLaVA流程\({ }^{375}\)将大型语言模型应用于信号参数识别和故障诊断,显著提升了性能。
智能制造范式正从机器中心向人机协作转型,后者在多品种小批量生产中提升了灵活性和效率。\({ }^{376}\) 尽管具备潜力,人机协作仍受限于任务特异性以及遇到新物体时需重新训练。基础模型以其强大的推理和泛化能力应对这些限制,使其成为多样化人机协作任务的理想选择。早期研究利用计算机视觉技术提升机器人感知,如手势识别和运动模式编码,\({ }^{377,378,379,380}\) 近期研究转向通用任务执行框架。例如,机器人Transformer基于大规模、任务无关数据集训练,实现跨多样机器人任务的泛化。\({ }^{381}\) 此外,FM结合视觉基础模型(VFM)进行场景感知和大型语言模型(LLM)进行任务推理,形成生成执行控制代码的流水线,使机器人能够通过语言和视觉指导完成先前未见的任务。
推动下一代通信智能化。 通信网络技术挑战源于其动态性、复杂性及日益多样的需求,涵盖网络配置和安全增强等方面。\({ }^{382,383}\) 基础模型凭借其强大的多模态数据处理、泛化和上下文理解能力,有望在这些领域协同解决问题,为未来通信网络的智能高效运行提供关键技术支持。
网络配置涉及为交换机、路由器、服务器和网络接口等设备设置参数,确保数据从源头到目标可靠传输。灵活高效的网络配置框架是支持下一代通信中资源调度、流量管理和服务优化的关键技术。CloudEval-YAML\({ }^{384}\)作为云原生应用YAML配置的基准工具,分析了12个大型语言模型的生成质量、任务性能和成本效率,解决了缺乏标准化基准的问题,有助于LLM在云环境中的应用与优化。利用自回归生成(如GPT-4)或扩散模型(如DiffusionBERT\({ }^{385}\))等生成机制,Verified Prompt Programming(VPP)\({ }^{386}\)通过结合GPT-4生成能力、结构化提示及人工验证,提高了网络配置准确性。该方法通过提示工程和人工校正迭代优化模型生成的代码,确保自动化配置过程更加精确可靠。随着大型模型的发展,基于LLM的端到端网络配置方法逐渐成为智能配置的关键。同时,提出了全自动网络管理系统的通用框架,免除人工验证。\({ }^{387}\) 该方法利用自然语言和LLM生成代码,通过提示工程结合领域知识和通用程序合成技术,保证高质量网络配置代码的生成。
通信技术进步带来更高复杂度和互联性,网络攻击种类和手段日益多样化,令网络安全与攻击检测尤为重要。\({ }^{388}\) 研究者开发了高质量网络安全数据集,并提出特定领域语言模型作为基础组件,增强对专业知识和技术术语的理解。此外,SecureBERT专为捕捉网络安全文本如网络威胁情报(CTI)语义设计。\({ }^{389}\) 它基于大量网络安全相关内容训练,兼顾通用语义理解并针对各类网络安全任务进行评估。与微调预训练LLM的方法不同,SecurityBERT从零开始构建特定安全领域的大型语言模型。\({ }^{390}\) 该模型基于BERT架构,采用隐私保护的定长编码(PPFLE)和字节级字节对编码(BBPE)分词器处理网络流量数据。模型体积仅16.7MB,标准CPU推理时间不足0.15秒,展现出卓越效率。它在识别14种不同攻击类型方面优于传统机器学习和深度学习方法,整体准确率达98.2%。
电力系统的发展。 电力作为能源系统的关键组成部分,深刻影响我们的日常生活。为推动全球电气化和实现碳中和,构建高效、灵活和互联的电力系统势在必行。目前,物联网(IoT)和人工智能(AI)等新技术突破为电力行业的数字化智能化转型带来了机遇与挑战。
近年来,以大型语言模型(LLMs)为代表的AI大模型技术取得显著进展,在全球多个行业展现出广阔潜力。\({ }^{391}\) 以OpenAI的生成式预训练Transformer(GPT)系列为代表,最新的GPT-4通过深化Transformer架构和创新预训练策略,有效提升了大模型性能,推动其在广泛领域的应用。LLM技术的迭代发展深刻影响电力行业,促进了潜在电力大模型的研发与应用。
在电力系统中,传统数据采集多依赖以往经验选择特征,效率低且带有主观性。相比之下,基于AI大模型的自动化数据分析突破了手工选择的局限,通过学习大量多变量数据,提取由智能终端汇聚至云端的数据特征,提升分析模型的预测精度。当前,大模型智能决策技术已初步应用于电气设备的智能诊断、运行与维护。其强大的数据处理能力、自主学习能力和分析预警功能,有效解决传统技术中的诊断准确率不足、响应滞后和运维成本高等问题。同时,通过深入挖掘设备运行数据,基于大模型的智能决策能够提前预警潜在故障,实现故障源精准定位,优化运行策略,提高运维效率。
例如,中国国家电网基于大量基础数据和评估模型,推出了AI辅助电力决策系统。\({ }^{392}\) 该系统以配电网设备评估标准为依据,整合静态设备参数与动态运行数据,建立全面评估框架,实现对站内或线路主设备的评估,从而为站点巡检、运行和维护策略提供智能决策支持。中国南方电网开发了多模态电力模型“Big Watt”,利用AI技术分析电网运行信息、用户负荷、天气预报和终端检测等多源数据,提供详细的电力系统运行维护分析与预测信息。\({ }^{393}\) 该大模型能够识别配电电网中的典型缺陷隐患,在突发事件和意外情况下快速准确地给出响应建议,大幅提升电网和系统的韧性与适应性。此外,ABB Ability数据平台结合云计算、大数据和5G等技术,构建了信息交叉赋能电力辅助系统,实现电力设备的故障分析与远程诊断,提高电力系统智能运维效率。\({ }^{394}\) 瑞士Alpiq公司推出的Grid Sense系统,利用AI技术分析电力系统的负载、电网故障和电力检测,紧密结合先进信息技术与电力系统,解决了传统人工巡检存在的人力成本高、工作强度大和巡检效果差等问题。以上成功案例彰显了AI大模型智能决策能力在状态监测、故障预测等方面的强大功能,显著提升了电力系统的安全性与可靠性。
随着AI技术的不断深化和普及,电力系统运行和能源管理的智能决策辅助技术正朝着精细化、实时化和协同化方向发展。最新进展表明,未来电力系统将紧密依赖AI大模型对海量复杂数据进行深度融合与智能分析,从而实现运行维护效率与电网韧性的双重提升。预计大模型将在推动电力系统向更智能、可靠和绿色方向发展中发挥重要作用。
挑战与展望。
- 数据质量与数据可用性: 在计算机与信息科学领域,特别是工业系统与下一代通信领域,数据(如设备故障记录、传感器测量、网络延迟\({ }^{396,397}\))常常难以获取且含大量噪声\({ }^{398}\)、缺失值或时间戳错误。此外,下一代通信中的现有数据集通常体量不足且任务特异,因现有数据多为特定任务(如流量预测或网络优化)构建,缺乏对通信网络复杂场景的全面覆盖。FM训练严重依赖大规模、多样化数据,这给上述领域带来挑战。数据稀缺、低质量和任务特异性极大限制了工业系统和下一代通信中模型的训练和应用。因此,关键挑战之一是如何利用生成型FM(如合成数据生成技术)进行数据扩充,或采用少样本学习方法(如迁移学习和元学习)实现有限数据下的高效学习。
- 部署问题: 工业机器人和下一代通信领域中,平台资源通常有限,尤其是边缘设备或移动终端。FM部署通常需要强大计算硬件,尤其是GPU或TPU集群,在资源受限环境下部署成为难题。此外,工业运营和下一代通信网络要求实时或近实时数据处理能力,对模型推理速度提出更高要求。因此,有效压缩FM模型(如剪枝和量化)和优化低延迟推理是实际应用中的关键挑战。
4.2 数学科学¶
基础模型(FM)利用大规模预训练,从多样化数据集中提取通用的数学模式,从而为传统问题如优化、统计推断和模式识别提供新颖的方法。\({ }^{36,399}\) 它们的有效性源自核心数学原理:线性代数通过矩阵运算和高维变换构建神经网络结构;\({ }^{400,401}\) 微积分支持基于梯度的优化和概率积分;\({ }^{402,403}\) 概率统计通过贝叶斯推断和假设检验支撑不确定性量化。\({ }^{404,405}\) 这些数学基础不仅促进了基础模型的发展,同时也从基础模型带来的洞见中受益——形成理论进展指导模型架构,模型表现揭示新数学问题的良性循环。我们将系统性地考察这一互动,通过基础模型的模型架构与训练、优化技术、应用及挑战四个方面展开。
模型架构与训练。 理解基础模型的架构选择和训练范式,对发挥其在数学科学领域处理复杂结构和提取有意义模式的潜力至关重要。神经网络由相互连接的神经元层组成,\({ }^{406}\) 提供了逼近非线性和高维函数的灵活且强大的框架。
在神经网络框架内,专用架构如卷积神经网络(CNN)、循环神经网络(RNN)和前馈神经网络针对特定数据结构和问题领域设计。CNN善于处理类似网格的数据结构,提取局部特征,是图像分析或空间数据处理等任务不可或缺的工具。RNN设计用于序列数据,捕获时间依赖性并揭示跨时步的模式,尽管其长程依赖常因梯度消失面临挑战。\({ }^{407}\) 前馈网络作为最简单变体,在处理静态输入输出映射问题时表现出高度效率,体现了神经网络架构的多样性。\({ }^{408}\) 相比之下,Transformer通过解决传统序列模型(如RNN)限制革新了基础模型领域。\({ }^{409}\) Transformer的核心是自注意力机制,使其能够并行处理整个序列,高效捕获长距离依赖并具备良好扩展性。\({ }^{410,411}\) 这一创新在数学科学中价值非凡,Transformer擅长解析符号数据、求解复杂方程以及识别大型数据集中复杂模式,其精准处理多样任务的能力使其成为推进计算方法的基石。\({ }^{412}\)
优化技术。 优化在基础模型开发中同样重要,决定了模型学习与泛化的效率。优化技术通过最小化损失函数来调整模型参数,是促使模型收敛和提升性能的关键。随机梯度下降(SGD)\({ }^{413}\) 作为基础方法,采用数据的随机子集逐步更新参数,平衡计算效率与学习稳定性。\({ }^{414}\) 在此基础上,自适应矩估计(Adam)引入自适应学习率和动量,加速收敛、提升高维空间性能。\({ }^{415}\) 更高级算法如二阶方法和梯度裁剪技术应对梯度消失与爆炸问题,增强优化过程的稳定性和精确度。在数学科学背景下,优化需更高的精度与稳定性,因为数值计算通常涉及求解方程或分析多维数据,要求严格。针对这些独特需求微调优化算法,研究者可释放基础模型的全部潜力,解决更复杂的问题,推动数学研究的边界。通过稳健架构与先进训练技术的无缝融合,基础模型持续变革我们解决数学科学问题的方式。
应用。 基础模型正在革新科学应用,在数学建模与仿真、应用科学、符号数学及不确定性决策等方面带来变革性进展。
在数学建模与仿真领域,基础模型通过数据驱动方法优化流程,特别是在传统解析方法难以应对的领域。\({ }^{417}\) 例如,物理信息神经网络(PINNs)被广泛用于通过将物理定律直接融入神经网络架构,解决流体动力学和气候建模中的复杂非线性偏微分方程。图神经网络(GNN)通过捕获交通网络的空间依赖性和动态特征,模拟交通流。\({ }^{418}\) 在应用科学中,基础模型提升了对复杂系统的理解,如气候动态和材料科学。CNN分析卫星影像等气候数据以预测天气模式,RNN建模材料性能的时间演变,助力新材料的发现。\({ }^{419,420}\) 这些数据驱动模型补充了传统框架,弥合了理论与经验观察的差距。\({ }^{421}\) 在符号数学方面,基础模型通过符号积分和定理证明等任务复制并扩展人类推理。基于Transformer的架构,如DeepMind的AlphaTensor,通过学习数学表达式结构实现复杂符号操作自动化。\({ }^{422,423}\) 此外,基础模型在不确定性决策方面表现突出,这在流行病学和金融等领域至关重要。贝叶斯神经网络(BNN)提供疾病传播的概率推理,强化学习(RL)优化不确定市场环境下的交易策略。\({ }^{424,425}\)
挑战与展望。 尽管基础模型具备变革性应用潜力,但其仍面临显著限制,尤其是计算需求和可解释性问题。训练和部署这类模型需庞大的计算资源,包括高性能计算设施和大量内存。随着模型规模和复杂度呈指数增长,资源需求成为研究机构的重要门槛。此外,基础模型“黑箱”特性使其决策过程难以解释,尤其是在涉及复杂数学推理与验证的任务中。这一点在金融、医疗等高风险领域尤为关键,信任、透明度和问责制不可或缺,理解模型推理至关重要。\({ }^{426}\) 从复杂架构中挖掘模型输出的理据仍是深刻且持续的挑战,凸显了提升可解释性和可用性创新方法的必要性。\({ }^{427}\)
4.3 生命科学¶
生命科学致力于探索生物活动的本质及其发展规律。近年来,人工智能技术显著推动了生命科学的应用,尤其是在药物设计、合成生物学和健康干预等领域(见图7)。随着基于基础模型(FM)的技术进步,生命科学在分析精度、预测能力和智能决策方面有望实现质的飞跃。
新药设计与决策。 人工智能技术的快速发展催生了具有海量参数的大型模型,代表性系统如ChatGPT和AlphaFold。在新药设计领域,研究者利用大型模型技术设计了多种具有显著生物活性的药物分子,包括小分子、大环、肽、蛋白质及核酸。利用大型语言模型(LLM),这些模型不仅自主学习序列特征,还能快速生成配体小分子。例如,混合生成化学语言模型(CLM)在设计PI3Kγ配体方面表现出亚微摩尔至纳摩尔的活性,并展示了骨架跳跃潜力。\({ }^{428}\) 此外,基于LLM的方法可生成候选生物活性肽。Chen等人设计了无毒副作用的新型生物活性肽序列。\({ }^{429}\) 尽管LLM方法高效且精准地生成生物分子序列,但仍面临数据依赖性和可解释性挑战。受AlphaFold蛋白质结构预测的启发,基于深度学习的基础模型能准确设计和预测大环肽结构。Rettie等人提出“环化编码”作为位置编码,以基于序列信息预测天然环肽结构,拓展了大环药物分子的结构空间。\({ }^{430}\)
除了利用预训练的基础模型,另一种方法是应用标准强化学习(RL)代理优化药物分子的从头设计。David Baker团队提出了利用蒙特卡洛树搜索的RL方法设计蛋白纳米材料,克服了从碎片构建蛋白的自下而上方法无法解决的挑战。\({ }^{431}\) 由于蛋白质结构空间的爆炸性增长,深度强化学习(DRL)方法高度依赖计算预测,通过策略网络和值网络的优化,有望提升效率和应用范围。例如,Frederic等人训练了基于DRL的策略型基础模型,结合神经架构搜索、超参数调优及序贯决策过程的联合优化,设计RNA药物分子。\({ }^{432}\) 总之,作为前沿先进的技术手段,AI智能决策模型已广泛应用于新药研发过程中的科学问题和技术挑战。
合成生物学规划与工程。 随着AI与生物学的深度融合,合成生物学领域迅速发展。例如,AI与植物合成生物技术结合,催生了颠覆性且可持续的农业应用。\({ }^{25}\) 通过训练先进的基础模型,传统的生物合成周期被转化为多维的“设计-构建-测试-学习-预测”工作流程,\({ }^{25}\) 提高了合成效率并降低了成本。近期AI辅助的合成生物学进展聚焦于基因组注释、蛋白质工程、代谢途径预测和合成路线规划等关键领域。例如,Zhou等人提出了结合元迁移学习、排序和参数微调的少样本学习方法,优化多种蛋白语言模型,在极度数据稀缺条件下提升预测性能。\({ }^{26}\) 尽管该方法通过聚合酶湿实验验证有效,但蛋白质LLM的优化仍受数据分布影响显著,表明需进一步完善。
此外,针对耗时的生物合成过程,AI模型可分析并规划合成路线,优化反应条件,最终找到更快更高效的合成路径,有效缩短生物化学合成周期。例如,Vaucher等人从自然语言处理角度出发,利用定制规则的NLP模型将化学反应规则构建视为文本提取问题。\({ }^{27}\) 虽然该方法预测准确且易解释,但需大量计算资源且在基础模型中泛化性较差。传统优化生物合成反应条件的方法依赖化学家手工枚举所有可能组合并独立决策,既耗时又昂贵。优化生物合成反应条件是实现AI辅助化学合成的关键步骤。例如,Zhou等人将强化学习与化学知识结合,迭代记录化学反应结果并选择新反应条件,以提升结果,实现优化化学反应的动态交互决策过程。\({ }^{28}\) AI必将成为提升合成反应条件的有力工具。
生命健康干预与管理。 利用基础模型强大的数据处理、预测与自适应学习能力,可制定更科学、精细的生命与健康干预方案,提高干预效果,降低医疗成本,促进健康管理普及。尤其是AI在精准营养领域的应用带来深远变革。基于自然语言处理的基础模型不仅能提取和预测饮食模式,\({ }^{433}\) 还能提供可解释的饮食相关疾病预测,探索饮食模式与代谢健康结果间的关系,证明NLP方法在提升疾病预测模型中的有效性。\({ }^{59}\) 基于NLP的基础模型构建了分子水平的营养分析与饮食推荐模型,根据遗传、环境和生活方式等因素为个体提供定制化、精准的饮食建议。\({ }^{71}\)
通过构建高效模型,强化学习能动态平衡多重目标,提升食物的感官属性和营养价值。Amiri等人提出结合协同过滤与用户评分、偏好和营养数据的多层次实时奖励机制。\({ }^{69}\) 该算法不仅兼顾营养与健康因素,还能动态适应用户潜在饮食习惯,大幅提升用户接受度和依从性。此外,传统饮食推荐方法通常基于用户历史偏好推荐食物,但难以满足实时健康需求。Liu等人利用强化学习的连续决策和交互能力,结合协同过滤算法,开发出自适应饮食决策模型。\({ }^{434}\) 该模型不仅满足营养与健康要求,还动态调整用户口味偏好和个人满意度。强化学习技术能通过反馈机制迭代优化食谱配方,实现对不断变化的消费者需求的响应。尽管强化学习在餐饮推荐领域取得一定成功,但仍存在显著不足。现有文献往往仅将食物成分归类,未充分考虑食物组成及饮食结构对健康的具体影响。此外,个体遗传数据常被忽视,导致健康特征评估不全面。未来研究应将季节变化、特定场合和原料供应等动态因素纳入餐饮推荐方案。通过整合知识图谱,可更动态地展现用户偏好,提升饮食推荐算法的泛化能力和效果。
挑战与展望。 智能决策模型在生命科学中的应用,尤其是在药物开发、合成生物学和健康干预方面,正推动革命性变革。然而,这些进展也面临数据、算法、伦理和法律等多方面挑战,主要体现在以下三点:(1)数据挑战:相较于基础模型所需的大规模数据,生命科学数据规模相对较小,且常含噪声和缺失值,影响智能决策模型的准确性。未来可通过数据增强与预处理、多源数据融合及敏感性分析等方法解决此类数据问题;(2)大模型预训练数据稀缺:生物医药数据(如化合物、靶点、分子相互作用、临床试验数据)稀缺且难以获得,给大模型预训练带来巨大挑战。未来可结合跨域迁移学习、少样本学习和自监督学习等技术,从有限数据中提取有价值信息,最大化模型泛化和性能;(3)健康干预中的隐私与合规:健康干预领域需大量包含敏感信息的个人健康数据。确保数据隐私保护及合规性是一大挑战。未来生命科学中的智能决策模型可通过数据匿名化、差分隐私、联邦学习、加密技术及法律伦理标准的综合策略保障数据安全与合规,最大限度降低隐私泄露与误用风险。
4.4 医疗健康¶
医学是人类进步与福祉的基石。基础模型(FM)如今为早期疾病筛查、手术规划等复杂任务提供了高效且智能的决策支持,能够实现文本、影像与基因组数据的统一解决方案,且对任务特定数据需求极低。\({ }^{435,165,436}\) 以下内容讨论了基础模型如何在诊断、医学影像等多领域重塑医疗健康。
通过多模态和基因组数据整合推进诊断。 基础模型通过结合丰富的医学知识与先进推理能力,在临床诊断中展现出巨大潜力。大型语言模型(LLM)如GPT-4在医学问答和病例分析等任务中表现出近乎专家的水平。\({ }^{437,438,439}\) 多次评估表明,基于LLM的决策支持系统在专科诊断环境中与临床医生不相上下甚至更优,凸显其多功能性及广泛应用潜力。\({ }^{440}\)
尽管取得进展,可靠性挑战依然存在。例如,部分知名模型偶尔会输出事实错误的回答,凸显诊断流程中人工监管的重要性。基于检索的增强方法为输出结果提供可信依据,有效降低错误率并提升模型可信度。\({ }^{441,442}\) 此外,多模态模型现已融合文本与实时影像或视频,实现更全面的诊断。这对外科病理和视网膜影像等领域尤为重要,能够借助多数据流的上下文线索提升诊断准确度。\({ }^{443,444}\)
除了文本和影像,基础模型还拓展至波形数据、放射学和组织病理学数据的诊断应用。例如,已有基础模型用于基于心电图(ECG)数据诊断心血管疾病。\({ }^{445}\) MedSAM在通用分割领域表现优异,能准确识别多模态的解剖区域和病变,\({ }^{446}\) 视觉语言模型可生成合成放射影像,用于资源受限场景的数据增强。\({ }^{447}\) 肿瘤学领域中,MUSK等模型结合病理图像和患者数据识别分子生物标志物、评估治疗反应,从而提升诊断特异性。\({ }^{448}\) 大规模组织病理学应用能够精准分类常见与罕见癌症,且适应不同染色协议。\({ }^{449,450}\)
此外,新兴的基因组和多组学基础模型进一步扩展了诊断能力。\({ }^{451}\) Nucleotide Transformer捕获DNA序列的有意义表示,适用于低数据环境下的特定变异检测,\({ }^{452}\) scGPT结合单细胞转录组和蛋白质组数据用于细胞类型识别。\({ }^{453}\) GET利用染色质可及性数据揭示与疾病状态相关的未知调控元素。\({ }^{454}\) 基因组基础模型\({ }^{455}\)提升了基于DNA序列的个性化基因表达预测。以上成果展现了大模型在诊断中的协同效应,借助多模态数据提高诊断准确性,减轻临床负担。
优化治疗策略与药物管理。 基础模型在引导治疗策略中作用日益显著。通过提炼广泛的临床数据,这些系统可辅助选择治疗方案、管理药物及处理复杂医疗决策。例如,近期研究强调LLM通过关联基因组数据与标准化治疗方案,为肿瘤科医生生成可行指导的实用价值。\({ }^{440,438}\)
在手术等高风险环境中,集成的大型多模态模型通过解析文本记录、影像乃至实时手术视频,提供患者状态的全貌。\({ }^{443}\) 这种整体视角有助于提高手术中决策的准确性,但仍需严格的领域特定验证以保障患者安全。肿瘤学尤其受益于视觉语言方法,如MUSK结合影像证据与患者历史,提供更精准的治疗方案。\({ }^{448}\)
治疗支持还涵盖药物基因组学和靶向治疗,多组学基础模型能够预测药物疗效与毒副作用风险。\({ }^{453,454}\) 通过整合基因变异到蛋白组特征等多种数据,这些模型能发现传统孤立系统难以捕捉的个体化治疗路径。尽管应用初见成效,仍需通过真实世界验证不断完善,以确保模型安全有效部署。
提升个性化预后预测和治疗反应。 预后评估是基础模型影响力日益增长的另一重要领域。其融合影像、病理及多组学数据的能力,使临床结果预测更为细致,如生存率和复发风险。肿瘤学中,LLM不仅提供具体诊断见解,还能预测疾病进展时间线,指导医生与患者讨论治疗目标及临终关怀。\({ }^{440}\)
多模态方法加强预后建模,综合影像特征、遗传信息和电子健康记录。视觉语言系统由诊断转向治疗反应风险评估,揭示靶向疗法的成功可能性。\({ }^{446,447}\) 多组学模型如GET精准预测基因表达变化,为疾病轨迹及干预点提供线索。\({ }^{454}\) 这些能力亦可扩展至更广泛的群体健康问题,包括公共健康监测和慢性病风险分层。
此外,基于大规模临床文本训练的LLM有助预测住院时长、再入院率及并发症概率。\({ }^{456,457}\) 通过将纵向临床数据与患者历史关联,模型能识别出预后较差的高风险患者。与诊断和治疗一样,模型在真实世界的稳健表现依赖于针对数据偏移和潜在偏见的细致校准,需持续监督和验证。
借助基础模型优化临床工作流程和资源管理。 高效的临床流程管理与自动化是现代医疗的重中之重,行政负担常常影响患者护理质量。基础模型擅长患者数据摘要、文档自动化及关键临床概念标记。例如,GatorTron通过大规模临床语料训练,在医学问答和语义相似度任务上达到了先进水平,体现了规模优势在减轻重复性文档工作中的价值。\({ }^{458}\)
除了信息提取,领域微调的LLM还能高精度完成分类任务,如肌肉骨骼疼痛的分类,从而简化分诊和转诊流程。\({ }^{459}\) 这些模型亦能生成患者记录、病理报告及影像检查的简明临床摘要,其摘要质量在部分指标上可媲美甚至优于人类专家。\({ }^{460}\)
资源管理是另一重要应用领域。大模型在预测医院运营指标方面表现出色,包括再入院率、住院时长和护理质量指标。\({ }^{456,457}\) 通过自动整合来自不同渠道的患者数据,这些系统能实现更主动的排班优化、床位分配及支持成本效益的医疗服务。尽管自动化优势明显,数据隐私、模型可解释性及公平性问题仍需成为临床应用的关注重点。
挑战与展望。 尽管潜力巨大,基础模型在医疗领域的应用仍面临诸多实施障碍。伦理问题主要源于训练数据的偏见——特别是模型多以西方数据为主,可能导致其他人口群体或地区的结果欠佳或不公平。\({ }^{461,462}\) 临床可靠性同样是难题,标准化评测表现优异的模型,在现实多变的临床实践中并非总能无缝适用。\({ }^{463,464}\)
监管因素增加了复杂性,医疗机构、临床医生及AI开发者需面对不断变化的责任风险。虽然AI辅助系统可能降低个体医生的法律风险,制造商和组织则需应对不确定的监管框架及创新AI解决方案的报销模式。\({ }^{465}\) 未来发展需透明模型架构、持续多样化训练数据以及强调安全与问责的人机协作指南。\({ }^{466}\) 持续的临床评估,包括自动专家评价和前瞻性试验,对于验证诊断和治疗效果至关重要。\({ }^{467}\) 通过这些努力,基础模型能够强化——而非取代——临床医生的专业知识,提供可扩展的数据驱动见解,提升患者疗效,同时遵循严格的医疗护理标准。
4.5 口腔医学¶
基于医疗健康数据训练的人工智能(AI)模型在疾病诊断、治疗规划和健康管理方面展现出显著潜力,尤其是在口腔医学领域。在这一领域,基础模型(FM)和智能决策系统有望通过提升精准诊断、优化治疗策略及改善患者疗效,变革临床工作流程。本文将探讨基础模型及智能决策系统在牙科实践中的机遇、现有应用、关键挑战与未来发展方向。
口腔医疗中基础模型与智能决策的基本原理。 通用的医疗健康基础模型(HFM)能够灵活应用于多种医疗任务,处理多模态医疗数据。与专注于特定医疗任务或数据模态的传统专用AI模型不同,医疗基础模型在语言、视觉、生物信息学和多模态等相关医疗AI子领域表现出卓越成功。\({ }^{468}\) FM在学习了大量医学语言数据后,在医学文本处理和讨论任务中表现优异。\({ }^{437,469}\) 视觉基础模型(VFM)在医学图像处理上显示出极大潜力。不同模态、器官、任务及特定VFM均展现了其在多种医疗情境下的通用性和灵活性。\({ }^{470}\) 生物信息学基础模型(BFM)则为蛋白质序列、DNA、RNA及其他元素的分析提供了机会。\({ }^{471,472}\) 多模态基础模型(MFM)通过融合多种数据模态,实现了对不同医疗模态的解读及基于多模态的任务执行,效率更高。\({ }^{165,473}\) 因此,这些模型为解决复杂临床问题提供了基础,提升了医疗及牙科操作的效率和效能,涵盖自由文本或护士记录、电子健康档案、报告、放射影像、实验室检测、牙科影像、审计、数字扫描信息、整合基因组数据及临床研究档案等。\({ }^{474}\) 在医疗决策中,临床医生会综合考虑患者的既往及现病史、当前可用的医学文献证据,以及其专业能力和经验。\({ }^{475}\)
基础模型在牙科诊断与预后中的进展。 医学诊断对于预防疾病进展和改善治疗效果至关重要。基于FM的医学诊断能够根据医学检查及患者陈述预测最可能的疾病,有助于及时治疗和避免不良后果。\({ }^{476}\) 近年来,FM已被用于提升医学诊断,展现出在包括牙科问题在内的多种疾病上的通用能力。\({ }^{477,478,479}\) 一项研究评估了ChatGPT-4在口腔外科领域作为智能虚拟助理的能力。一位专业口腔外科医生对ChatGPT-4回答的30个口腔外科相关问题进行了评估,发现存在差异,准确率为71.7%。\({ }^{480}\) 该结果凸显ChatGPT-4作为牙科临床决策辅助工具的作用,同时强调其无法取代熟练口腔外科医生的专业水平。VFM可对选定的低风险影像自动进行疾病筛查,辅助检测和识别模糊的靶解剖结构,减轻放射科医师负担并提升诊断准确率。传统龋齿诊断主要依赖牙医的视觉和触觉检查。治疗策略前,需迅速而全面地评估口腔健康状况。牙科疾病诊断往往耗费专家大量时间和精力,有时需借助X光扫描和CBCT以做出有效判断。多项研究探讨了AI辅助模型在诊断龋齿、牙周炎、药物相关骨坏死、颌面骨折、口腔鳞状细胞癌及颞下颌关节疾病等方面的有效性。\({ }^{481,482,483,484,485,486}\) 这些疾病可通过医学影像识别。VFM的分割与识别为医学影像中的定位提供信息,帮助放射科医师将图像划分为语义区域并识别关注区域。\({ }^{487,488}\)
部分VFM在疾病预后方面表现出良好成果,能够提供生物标志物预测疾病概率或预期进展。例如,Tooth GenAI通过支持向量回归模型,评估患者数据,预测牙周炎等疾病的牙骨流失,帮助早期干预,预测三个月及六个月的骨流失情况。模型利用用户提供的个人数据进行预测,并配合图示支持治疗设计及疾病过程追踪。\({ }^{489}\)
通过基础模型推进个性化治疗规划。 FM通常提供即插即用的医学图像处理工具,无需额外采集数据或训练模型,即可用于手术规划或辅助,这是一种传统范式,在外科领域具潜在应用。随着数字牙科的发展,个性化治疗规划成为提升患者疗效的关键策略。HFM能协助制定个体化方案。外科医生可借助三维分割VFM,从CT及MRI等医学影像中区分三维结构以进行手术规划。分割VFM还能识别手术过程中内窥镜视野中的器械或相关区域,有助提高手术效果。\({ }^{490}\)
在牙种植设计与植入规划中,AI可基于患者CBCT数据自动生成最优植入设计与方案,综合考虑骨密度、邻牙位置和咬合关系等因素,从而提升种植成功率。\({ }^{491,492}\) AI的主要应用在于解剖标志物的分割,这也是构建虚拟患者的重要步骤。虚拟植入仍需开发并科学验证全自动数字化方案。\({ }^{493}\) 在正畸治疗计划中,是否需要颌骨手术是另一个关键决策。不同医生对是否需做颌骨手术意见不一,\({ }^{494}\) 且缺乏统一标准判定手术必要性。但已有方法尝试通过AI算法辅助临床医生。\({ }^{495,496}\) Choi等人报告AI不仅能预测颌骨手术指征,还能以约91%的成功率预测拔除前磨牙的指征。\({ }^{497}\) 这类创新无疑将帮助外科医生和牙科专家更顺利完成可预测、及时的术前规划阶段。
牙科中的智能决策技术。 随着数字时代的到来,智能决策技术的整合逐渐显示出显著优势,现已广泛应用于正畸学、活动局部义齿设计、复杂颌面重建术后预后预测等多个领域。\({ }^{498,499}\) 近期,PUMCH疗法(光声蒸汽联合微创化学机械制备水动力封填治疗)为牙髓治疗带来创新理念。\({ }^{500}\) 自动化牙髓器械的引入进一步拓展了该专科智能决策的范畴,提升治疗便利性和可预测性。
随着临床数据积累与机器学习能力的提升,先进建模工具使临床医生能通过将牙齿形态与特定治疗参数对齐来优化治疗方案,推动更具证据支持、以患者为中心的决策。\({ }^{501}\) 此外,这些建模系统增强了术后抗力损失的预测能力,助力长期疗效评估。工具集成还强化了临床医师与患者之间的沟通,促进更充分的治疗预期及长期效果讨论。\({ }^{502}\) 此外,这些系统的预测功能支持早期干预策略,提升临床决策的精准度和时效性。
挑战与展望。 HFM的训练需大量医疗数据,因此如何在确保隐私和安全的同时实现数据整合与共享,是亟需解决的伦理问题。医疗数据必须合乎伦理地获取。身体扫描能提供医疗数据,但CT成像可能对身体造成损伤。\({ }^{503}\) 虽然这种损伤对疾病治疗可能较小,但将人体扫描用于AI训练数据集是违反伦理的。这类数据难以大规模获取,正如当前某些数据采集模式所见,限制了HFM任务的训练。此外,伦理还限制医疗数据的使用和分发。医疗健康数据包含敏感甚至危险的身体信息,包括基因数据。数据使用与分发受法律和数据所有者严格监管。未经规范积累和使用于基础模型训练存在安全风险。外部环境的不确定性也加大了HFM使用风险。\({ }^{504,505,506}\)
HFM需跨多模态数据操作,\({ }^{507}\) 然而,不同机构健康数据的来源多样,导致数据格式和质量存在显著差异。不同人群、地区和医疗机构的健康数据特征各异,实用中导致HFM数据异质性。\({ }^{508}\) 基础模型的发展标志着从专用任务向通用任务的转变,使AI具备更广泛的能力,以应对现实世界中多样需求和复杂环境。FM亦具备革新医疗的潜力。先进的HFM能无缝分析多种数据模态,动态学习新任务,利用领域知识,在广泛医疗工作中展现前景。尽管潜力巨大,HFM模型仍面临明显挑战。其卓越的适应性增加了全面验证的难度,且规模庞大带来更高的计算成本。HFM为医疗提供了前所未有的机遇,助力临床医生完成多项关键任务,减轻临床工作负担,使其能有更多时间关注患者。
4.6 城市科学¶
基础模型(FM)通过处理海量数据、识别模式并生成可操作的洞察,显著推动了城市科学中城市规划、政策制定和管理的各个方面的决策进展。\({ }^{509}\) 以下介绍了它们在城市科学中从预测到决策的多种贡献方式,并配以相关文献或论文。
基础模型提升城市预测建模能力。 FM赋能城市科学家以高精度预测城市事件,\({ }^{510}\) 如交通拥堵、污染水平和能源需求。通过利用历史和实时数据,FM促进了短期和长期规划中的改进决策。近期文献表明,大型语言模型(LLM)可以作为零样本预测器应用于预测学习任务,\({ }^{116,511}\) 尤其是在城市场景中。通过设计新型分词器和上下文学习技术,LLM在预测表现上优于传统统计方法如ARIMA。然而,由于LLM在解读复杂数值数据模式时面临挑战,研究人员探索了对LLM进行时间序列分析\({ }^{512,120,513}\) 和城市时空预测的微调方法。\({ }^{514,515}\) 主要策略包括微调LLM中的特定模块,如层归一化和位置编码,或训练额外神经层(如嵌入层和预测头)以更好地匹配下游应用。其他方法\({ }^{516}\) 研究通过缩放和量化等技术将时间序列数据转换为固定词汇表,从而对序列值进行分词,支持在经过分词的序列上用交叉熵损失训练现有LLM架构。
除了利用预训练的LLM,另一种方法是使用跨域城市数据(交通、能源、气候、空气污染等)从零开始训练基础模型。这一趋势由UniST模型\({ }^{517}\)体现,UniST是一种面向广泛城市场景的通用时空预测模型。其核心理念是利用多样化的城市时空数据进行有效预训练,以捕捉复杂的时空动态,并通过引入知识引导的提示增强下游应用的泛化能力。后续研究将类似方法扩展到更广泛的城市数据,如人类轨迹数据\({ }^{518,519}\) 和遥感数据。\({ }^{520,521}\)
基础模型融合多模态数据以加速城市科学的可解释透明决策。 FM在推动城市科学中决策的可解释性和透明性方面发挥了变革性作用。通过利用大量文本、数值和空间数据,LLM能够促进更明晰、数据驱动的决策,使专家和公众都更易理解。这些模型通过为复杂决策提供清晰解释,增强了透明度并提升公众信任。尤其是,FM支持高效且可访问的决策过程,无论是通过人机交互、参与式规划,还是评估/验证框架。
举例说明第一类,交通信号灯控制应用中,LLM促成基于实时环境和交通模式的自适应数据驱动交通灯系统,优化交通流。\({ }^{522}\) 该模型能分析传感器数据、天气条件和城市出行趋势,动态调整信号时序,旨在减少拥堵、提升交通安全。通过解释为何触发特定信号变化,LLM推动交通管理更透明。这种解释性确保城市规划者和公众理解交通控制措施背后的逻辑,增强对系统及其应变能力的信任。
第二类中,FM作为模拟人类行为的代理,辅助城市决策。例如,在参与式城市规划中,这些模型整合城市规划、社区反馈和环境报告等多样数据源,以数据驱动且透明的方式指导决策。通过处理大规模公众输入,FM识别社区内的关键趋势、优先事项和关切,帮助规划者使城市发展符合公众需求。此外,FM生成易懂的规划决策解释,确保复杂政策向公众清晰传达。这种透明性赋能公民更有意义地参与规划过程,确信其声音被倾听、观点被考虑。近期研究\({ }^{523}\)提出一种创新的参与式城市规划方法,使用FM代理模拟多样化的规划者和居民角色。流程从规划者草拟初步土地利用方案开始,随后居民进行模拟讨论,根据其需求反馈意见。为提升讨论效率,采用“鱼缸机制”,允许部分居民参与对话,其他居民旁听。规划者据此调整方案,形成更包容、响应性强的规划过程。
第三类中,FM利用自然语言理解和推理能力,对政策评估与验证贡献显著。它们辅助情境分析,提供简洁的政策摘要和相关文献检索,支持知情决策。\({ }^{61}\) LLM支持场景模拟,生成假设性结果和利益相关方视角,预测社会反应。\({ }^{13}\) 同时,它们分析调查或社交媒体中的公众情绪,使政策与舆论保持一致。验证阶段,FM识别逻辑矛盾,交叉比较政策最佳实践,评估包容性确保公平。通过揭示偏见和意外影响,支持公平政策制定。常规任务如文档解析、数据提取及评价报告撰写实现自动化,提高效率。\({ }^{524}\) 通过促进迭代改进,LLM作为动态工具帮助优化政策、监控更新,确保政策过程的适应性和稳健性。\({ }^{525}\)
挑战与展望。 FM在未来城市治理和决策中的应用将带来深远社会影响。FM为城市精准智能治理及去中心化可持续发展奠定坚实基础。例如,基于FM的智能交通系统有望实现城市交通状况的实时全面感知,并根据道路状况灵活控制交通信号,大幅缓解大都市区交通拥堵,从而显著降低汽车排放。基于FM的智能城市规划系统可显著减少专家知识偏见,为城市发展提供去中心化科学决策支持。此外,虚拟环境中的仿真实验有效避免了现实中因短视规划造成的不必要物资和能源浪费。总体而言,基于FM的应用将引领传统城市向智慧城市转型,显著减轻城市管理决策部门的工作负担,使其更专注于城市中的人文关怀。
除了上述积极的社会影响,FM在城市中的应用也可能引发一些担忧。例如,强大FM应用需收集大量数据用于训练,其中包括城市区域的个人轨迹数据,这引发数据隐私问题。必须对数据进行匿名化和保护,以防大量个人隐私泄露。另一挑战是将FM技术与城市治理中的社会价值观对齐。大都市区复杂的人口结构导致基于性别、种族、收入等因素的多样化城市生活需求。这种多样性可能导致理论上的最优方案未必符合现实社会文化状况。因此,解决FM应用与社会价值观的对齐问题,对其在城市不同群体中的广泛采用至关重要。
4.7 农业科学¶
农业是保障粮食安全、维护社会稳定和促进经济增长的基石。
基于基础模型(FM)的智能决策为农民提供更明智的选择,优化资源配置,提升整体农场管理水平,有望通过提高生产力、可持续性和决策效能,彻底改变农业领域。
基于FM的作物管理:洞察精准决策。 精准农业和智能农业的核心理念是利用高科技手段实现农业生产的精细化管理。\({ }^{526}\) 人工智能正逐步改变传统农业的生产方式,提高农业的生产效率和可持续性。在此背景下,FM通过提供智能决策支持和优化资源配置,成为智慧作物管理的关键方法。\({ }^{527}\) 结合农业遥感数据\({ }^{528}\)与地面传感器数据,FM在作物生长监测、精准农业技术以及病虫害监测与防控领域,通过精细调优模型展现出巨大潜力。
具体而言,FM通过整合气象模式、土壤性质和遥感数据,实现作物生长状况的实时监测,从而及时识别潜在作物问题并提供调整方案。\({ }^{529}\) 结合历史产量数据,FM还能准确预测作物产量,辅助农业规划和粮食安全保障。\({ }^{530,531}\) 在精准农业技术中,FM能够准确分析天气和土壤数据,做出个性化施肥和灌溉决策。\({ }^{532}\) 这种智能资源管理确保作物生长所需的养分和水分得到最优配给,避免过度施肥和灌溉。对于病虫害监测与防控,传统视觉方法通常依赖单一图像数据,受限于数据质量,难以有效支持病害传播预测和防控措施的决策。\({ }^{533}\) FM凭借强大的多模态学习能力,能够快速识别作物病虫害的类型和严重程度,并提供针对性的防治建议。\({ }^{534}\) FM在高效处理和理解多模态数据方面的优势,使其能够在复杂农业生产环境中进行全面分析和决策,促进智慧作物管理的进一步发展。FM的应用不仅优化了农业生产流程,还为农业的可持续发展提供了有力支持。\({ }^{535}\)
FM赋能植物育种。 植物育种在作物改良中起着关键作用,其主要目标是选择性提升产量、抗病性和抗逆性等性状。\({ }^{536}\) 传统植物育种依赖于表型选择和基因型分析,通常通过田间试验、育种和后代筛选完成。然而,该方法存在育种周期长、资源消耗高及环境因素复杂等限制,成为提高育种效率的瓶颈。基于此,结合AI领域最新进展,智能植物育种作为一种方法论应运而生,能够结合多维数据,利用人工智能、大数据和先进基因组学技术优化作物品种。\({ }^{537}\) 然而,传统机器学习方法常常难以处理时空组学数据的复杂性。多模态基础模型(MFM)为此提供了有希望的解决方案。\({ }^{538}\)
作为一类新型基础模型,MFM能够同时处理多种数据模态,如文本、图像、视频、音频及结构化数据(例如基因组序列或传感器数据)。\({ }^{165}\) 这使得它们能够有效捕捉和分析基因型、表型与环境之间的相互作用。此外,MFM还支持跨模态任务,应用范围更广,例如从文本生成图像(如根据基因型描述生成预测作物表型图像)。该领域著名模型包括对比语言-图像预训练(CLIP)\({ }^{14}\)和引导式语言-图像预训练(BLIP)。\({ }^{539}\) 通过高效处理异构数据集,MFM显著提升了表型预测的准确性,使育种者能够更精确地预测作物表现并优化性状选择,从而加快遗传增益。未来,MFM预计将在作物育种中发挥越来越关键的作用,改变农业创新格局。
基于FM的现代畜牧业:从健康监测到全链路优化。 AI与FM技术的持续发展推动现代畜牧业迈向更高的智能化、精准化与高效化。\({ }^{540,541}\) AI在畜牧业中的应用,尤其是在动物健康监测、疾病预测和资源配置优化方面,\({ }^{542,543,544}\) 展现出巨大潜力。卷积神经网络(CNN)通过处理和分析动物图像及视频数据,实现对异常动物行为的检测与预警。图神经网络(GNN)将每只牲畜视为图中的一个节点,将它们之间的交互或传播路径视为边,有效捕捉复杂的关联结构,从而提高健康监测的准确性。通过提升管理效率和优化资源分配,AI显著助力降低生产和运营成本。目前,畜牧业中的深度学习决策模型多聚焦于特定场景,如基于体温、活动水平和食欲变化预测动物健康状况。\({ }^{545}\) 然而,这些决策模型通常依赖人类专家知识和历史数据进行训练,限制了其应对跨学科知识整合和复杂数据挑战的能力。\({ }^{546}\) 相较于传统模型,FM通过整合多学科知识和从大规模多模态数据中学习,有效解决了这些问题。\({ }^{547}\) FM能够处理和整合来自不同领域的多维复杂信息,从而提供更准确、更全面的智能决策。FM不仅提升了畜牧业健康监测和疾病预测的准确度,也优化了资源配置,推动农业生产管理的精准化与智能化。因此,FM已成为当前智慧畜牧业中提升管理效率和优化资源配置的关键工具。
挑战与展望。 未来十年,我们将持续见证新兴人工智能方法与物联网(IoT)技术的发展。这些进步将有助于实现最优决策,提升农业生产和管理的智能化水平。目前,我们在有效整合这些前沿技术进农业生产中面临诸多挑战,尤其是在跨学科系统解决方案以及农业低成本AI应用的实现方面。农业、计算机科学与环境科学等领域的跨学科融合仍存在技术壁垒。如何结合农业实际需求与AI技术,设计既高效又适应生产规律的智能系统,亟需大量创新与研究。同时,AI技术成本较高且小规模农业经济体的需求各异,低成本应用成为推动智慧农业的核心难题。为克服这些挑战,除了技术创新,还需开发更具成本效益的硬件设备和简化接口,并针对不同地区量身定制应用方案。政府政策支持、行业标准制定以及农业企业与科技公司的合作,也将在推动技术采纳和降低成本方面发挥关键作用。随着技术进步和成本下降,智慧农业将实现精准化、智能化和可持续发展,提升全球农业产业效率,促进粮食安全和农村经济的可持续增长。
4.8 经济科学¶
在经济科学领域,基础模型融合异构的市场信号,实现更快速的风险评估、更精准的投资洞察以及更灵敏的合规监控,\({ }^{548,549,550,551,552,553}\) 如图7所示。它们在资产类别和场景上的广泛泛化能力超越了基于规则的工具,推动了信用评分、普惠金融和战略决策的创新。
FM赋能信用评估与普惠金融。 传统的信用评估往往依赖人工经验和线下数据采集,导致流程繁琐、信息不对称和覆盖范围有限。相比之下,基于FM的决策智能能够高效整合并语义分析大量异构数据源,如文本、图像、交易记录和社交媒体信息,从而构建更精准且动态的信用档案。\({ }^{554}\) 凭借自动因子发现、生成式对话以及对借款人信用行为的持续监控等能力,基础模型帮助金融机构降低运营成本,加快贷款决策流程,并向小微企业及其他服务不足的客户群体提供定制化金融服务,提升了普惠金融的覆盖率和可及性。\({ }^{555,556}\)
FM在投资决策支持和市场分析中的应用。 基础模型在证券投资和资产配置领域的应用日益增多。除传统的量化策略外,融入FM的决策智能促进了对多元信息来源的整合,包括宏观经济指标、行业报告、公司披露、市场新闻和情绪数据。通过先进的自然语言理解和多模态学习技术,基础模型能够更全面地描绘市场动态和风险特征。\({ }^{557,558,559}\) 此外,生成式人工智能技术还能产生丰富的交易策略建议和预警信号,使分析师、投资组合经理和交易员能够更精准地优化资产配置和定价决策。\({ }^{560}\)
FM在风险控制与监管技术中的应用。 加强风险防范和确保监管合规对于维护金融市场稳定至关重要。基础模型决策智能利用深度学习、基于图的知识表示和异常检测算法,提升了对异常交易、欺诈披露和非法融资活动的早期发现和实时监控能力。\({ }^{561,562}\) 此外,监管机构能够借助基础模型实施“智能监管”,自动化合规检查、跟踪政策执行,并快速调整监管策略以应对行业新动态。\({ }^{563}\) 新加坡金融管理局(MAS)、英国金融行为监管局(FCA)以及美国证券交易委员会(SEC)等国际机构均积极试验基础模型和人工智能驱动的监管技术,为完善国内监管框架提供了宝贵借鉴。
4.9 教育科学¶
基础模型正在重塑教育科学,通过支持自适应辅导、数据驱动的学习分析及公平获取优质内容,\({ }^{50}\) 如图7所示。其多模态推理和庞大的知识库助力个性化学习路径和实时反馈,显著提升学习者参与度和学习效果。
个性化与自适应学习中的基础模型应用¶
基础模型在教育中的一大优势是实现个性化学习推荐。通过分析大量学生数据,如学习表现记录、互动历史和评估结果,这些模型能够推断个体学习者画像,推荐定制化的教学材料。例如,基于语言的基础模型可以根据学生当前水平动态调整阅读材料或题目,保持最佳挑战度,减少挫败感。\({ }^{61,570}\) 此外,模型还能识别学生理解上的薄弱环节,主动提供针对性练习或解释内容,从而提高补救效率和知识保持率。
基础模型支持差异化教学,满足不同学习风格和偏好。视觉学习者可借助模型生成的信息图或交互模拟,听觉学习者则可接收带解说的内容或播客。这种个性化确保教育内容对更广泛学生群体均具吸引力与可访问性,促进包容性教育。
同时,基础模型提升了多语言和方言支持,跨越语言障碍,使非母语学生及多语言背景学习者能够访问教育资源。它们还能生成盲文、音频描述和手语翻译等多样内容格式,满足不同学生需求。\({ }^{571}\) 基于基础模型的自适应技术提供定制学习路径和辅助工具,促进公平学习环境,使所有学生无论面对何种挑战均有成功机会。\({ }^{572}\)
例如,最近的DeepSeek-v3模型可分析学生学习模式,提供实时反馈,实现个性化辅导。通过数据驱动评估识别学生知识盲点,模型调整内容传递和练习设计,促进教师的精准干预。此举不仅提升整体学习效率和参与度,也推动教育公平,满足个体需求。
智能辅导与反馈系统中的基础模型¶
智能辅导系统(ITS)与自动反馈机制是另一关键应用领域。传统上,高质量个性化反馈规模化供给面临挑战。基础模型赋能的ITS能够提供更丰富、细致的指导,评估学生开放式问题回答,实时指出误区并提出替代解法。系统还基于决策智能判断反馈内容、时间和方式,最大化教学效果。\({ }^{573}\)
基于基础模型的先进ITS能模拟一对一辅导,运用苏格拉底式提问和结构化学习,促进深度理解。例如数学教育中,系统引导学生攻克复杂问题,提供提示和反思,鼓励批判性思维与自我调节。自动评分系统不仅评估答案正确性,还考察推理过程,支持形成性评价。
自动反馈覆盖多学科,实时个性化反馈帮助学生理解并改正错误,形成即时强化循环,提升学习效果和成绩保持率。\({ }^{574}\)
教师与机构决策支持中的基础模型¶
基础模型在教育中的潜力还体现在辅助教师与教育管理者决策。基于大模型的智能系统可分析现有教材,发现知识覆盖不足,推荐补充资源;支持学生分班与风险预测,促使早期干预。\({ }^{575,573}\)
它们还助力教师专业发展,提供个性化培训资源,识别提升领域,推荐循证教学策略。对于管理者,基础模型简化排课、资源分配与政策制定等运营任务,通过分析机构数据与预测趋势,提高管理效率。
此外,基础模型促进教育者间协作,提供共享最佳实践、资源和创新教学方法的平台,推动教学和学习持续改进。
挑战与展望¶
未来,基础模型在教育应用中具备巨大创新与研究潜力。发展重点包括提升模型的可解释性,使教师能理解并信赖AI推荐与反馈;集成多模态数据(行为分析、生物特征、上下文信息)以提供更全面支持。
融合教育学、认知科学和人工智能的跨学科研究,将推动设计更先进、符合教育理论和最佳实践的AI系统。
此外,缩小数字鸿沟、保障公平接入AI教育技术是实现基础模型社会效益最大化的关键。开发低成本、可扩展解决方案,提升师生数字素养,将促进技术的广泛应用和包容性普及。
总之,基础模型融入教育环境将催生更自适应、包容且数据驱动的学习体系。借助其决策智能,教师与教育机构可显著提升教学质量、个性化服务及整体教育成效。然而,解决相关挑战和伦理问题是实现这些先进AI系统教育潜力的必要条件。
5. 风险与挑战¶
5.1. 基于大型语言模型(LLM)代理的决策安全性¶
近年来,随着大型语言模型(LLM)的快速发展,基于LLM的代理技术逐渐渗透到决策领域。然而,现有研究\({ }^{576,577,578}\)揭示了LLM代理存在的安全问题,这些问题对决策过程带来了潜在风险,如图8所示。结合近期对基于LLM代理\({ }^{576}\)和智能算法安全性的调查\({ }^{579}\),我们了解到基于LLM的决策框架通常包含多个组成部分:用户、预定义系统提示、记忆检索、外部环境(即一组工具集)等,因此潜在的脆弱性和安全威胁可能来自这些方面;另一方面,安全问题也可能源自LLM模型本身的内部。接下来,我们将分别从外部风险和内部风险两个方面揭示决策安全问题。
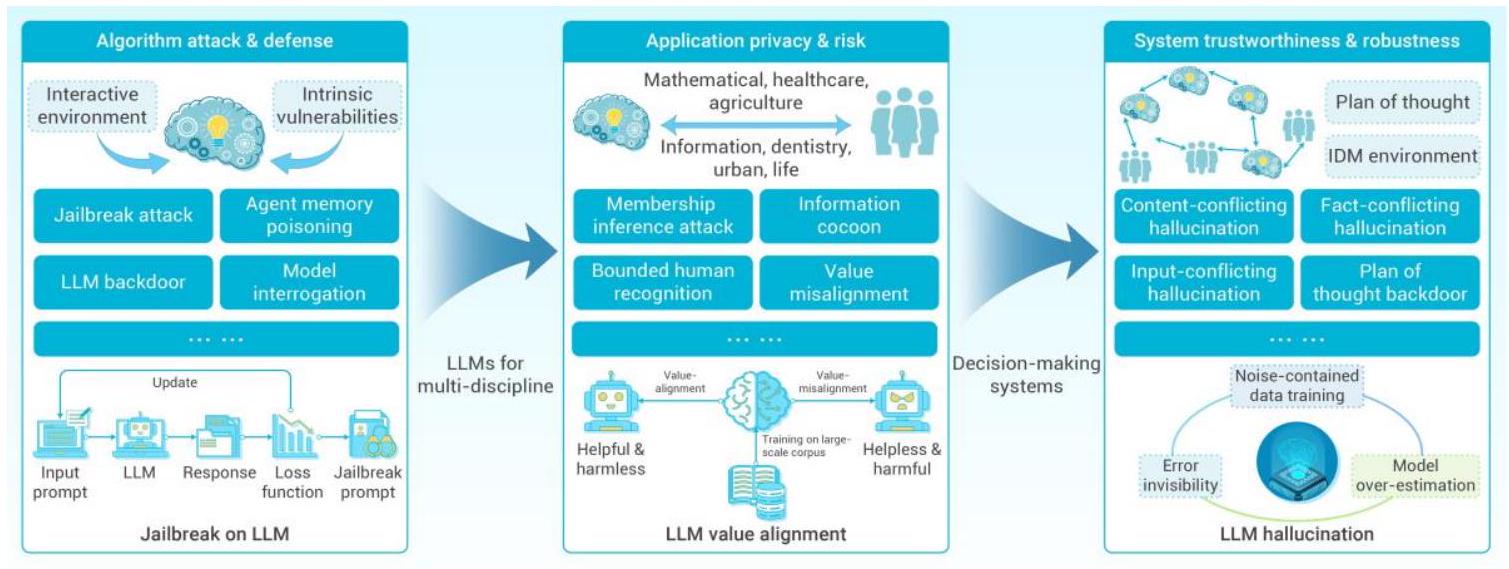
图8:LLM代理中的风险与挑战。 左侧三张子图展示了算法层面基于内在脆弱性和交互环境的攻击与防护,如越狱、后门、模型审查等。中间展示了应用层面从不同学科视角的隐私风险,如成员推断攻击、信息茧房等。右侧展示了系统层面基于PoT和智能决策环境的LLM可信度和鲁棒性问题,如内容冲突幻觉、事实冲突幻觉等。
来自LLM代理的外部风险。 在决策链过程中,LLM代理可能遭遇以下攻击: i) 提示注入攻击(Prompt Injection Attacks):攻击者向原始提示注入特殊指令,操纵模型的理解,导致错误输出。\({ }^{580,581,582}\) 此外,这类提示注入攻击还可能通过操纵可访问的外部环境(即各种辅助工具)破坏规划过程。\({ }^{583,584}\) ii) 代理记忆中毒(Agent Memory Poisoning):与传统深度学习训练中的数据中毒攻击不同,这里指的是向用于检索的数据库注入恶意或误导性数据,使代理生成不合理的决策规划或动作。\({ }^{585,586}\) iii) LLM代理后门攻击(Backdoor Attacks on LLM Agent):针对思维规划(Plan-of-Thought, PoT),攻击者先对部分规划示范进行中毒,包含带有后门的规划步骤和对抗目标动作,然后在查询提示中注入触发器。\({ }^{587,588,589,590}\)
来自LLM的内部风险。 LLM自身也存在多种安全问题,可能导致决策失败: i) 越狱攻击(Jailbreak Attacks):类似传统的对抗样本,通过特定的提示工程策略绕过LLM的安全防护,使其生成意料之外的内容。\({ }^{591,592,593,594}\) ii) 模型审查(Model Interrogation):一种针对LLM对齐问题的新威胁,与越狱攻击不同,模型审查无需精心设计提示,而是通过强制模型输出低概率词汇,迫使其泄露有害或未对齐的响应。攻击者需具备访问LLM每个输出位置的Top-k词汇预测的前提。\({ }^{595}\) iii) LLM后门攻击(Backdoor Attacks on LLM):类似传统深度学习中的后门风险,攻击者通过微调指令,秘密嵌入触发器至LLM模型中。\({ }^{596,597,598,599}\) 这种隐蔽的后门攻击可使LLM生成符合攻击者意图的规划或行动响应,对决策者构成严重威胁。
上述内外部风险均对决策过程构成严峻威胁。为促进LLM在决策中的实际应用,接下来我们将从两个角度介绍防御对策。
基于LLM代理的防护措施。 由于决策任务通常包含多个推断规划/动作的阶段,因此对应多种防御策略: i) 定界符(Delimiters):决策者可使用定界符封装查询,确保仅执行查询内容。\({ }^{576}\) ii) 改写(Paraphrasing):防御者可通过重新措辞查询,破坏恶意指令或触发器中的特殊字符序列。\({ }^{600}\) iii) 打乱顺序(Shuffle):针对PoT后门,随机打乱PoT示范流程。 iv) 记忆中毒检测(Memory-Poisoning Detection):通过测量文本困惑度或使用LLM识别被破坏的记忆。\({ }^{582}\)
针对LLM模型的防护。 鉴于LLM的复杂性,防护通常需要综合策略,我们总结了代表性防御机制: i) 无偏训练(Unbiased Training):越狱攻击与对抗攻击具有相似性,\({ }^{601}\) 一种有效防御是增强和平衡多模态模型的训练数据,甚至将恶意指令纳入联合训练。例如,对抗训练通过引入对抗样本作为训练数据,提高模型对抗攻击的鲁棒性。\({ }^{602,603}\) ii) 系统提示增强(System Prompt Enhancement):研究指出,较短的系统提示会增加攻击成功率,因此系统提示也需增强鲁棒性。\({ }^{604}\) iii) 恶意内容过滤(Malicious-Content Filtration):部分攻击绕过输入阶段的安全防护,但在输出阶段失败,因此决策链中需增加输出检测和恶意内容过滤措施。
综上,基于LLM代理的决策体系现阶段较为复杂,其安全威胁既来自LLM本身,也源于其外部组件,这些风险在决策过程中可能带来严重后果。为促进LLM决策技术的实际应用,未来需要更加重视并投入更多精力解决相关安全问题。
5.2. 机器幻觉的成因与缓解¶
幻觉现象早在大型语言模型(LLM)出现之前就已在自然语言处理(NLP)领域被发现,通常指模型生成与所提供源内容不符或无意义的回答。\({ }^{605}\) 目前,鉴于LLM的多功能性,幻觉可大致分为三类\({ }^{606}\): i) 输入冲突型幻觉(Input-Conflicting Hallucination),指生成的内容或回应与用户输入不一致。此类情况通常发生在LLM对任务指令理解产生误解时; ii) 上下文冲突型幻觉(Context-Conflicting Hallucination),指LLM产生的内容与其之前生成的内容相冲突。这种情况往往因LLM无法追踪上下文或在对话中保持一致性,可能源自长期记忆不足;\({ }^{607}\) iii) 事实冲突型幻觉(Fact-Conflicting Hallucination),指LLM生成的内容与既有知识不符。此现象由LLM应用过程中多个阶段引入的多种原因造成。
LLM产生幻觉的原因包括: i) 训练数据中含噪声(Noise-Contained Training Data)。众所周知,LLM目前在数万亿token上进行预训练,但其中部分数据来源于伪造、过时或带有偏见的信息。\({ }^{608}\) 例如,研究指出LLM可能将与伪装相关的内容误解为事实知识。\({ }^{609}\) McKenna等人\({ }^{610}\)发现幻觉现象与训练数据分布密切相关,且LLM偏向于训练数据中出现频率较高的样本; ii) 错误隐蔽性(Error Invisibility)。由于LLM存储了庞大的知识量,即使错误信息通常显得合理,也加大了减少输入冲突型和上下文冲突型幻觉的难度; iii) LLM过度自信(Over-Estimation of LLM)。Kadavath的实验\({ }^{611}\)报告LLM对正确答案和错误答案的置信度相当。Yin等\({ }^{612}\)调查了代表性LLM区分未知问题的能力,结果显示即使是先进的LLM,其表现仍不及人类。换言之,LLM对事实知识的理解超出了知识边界,即存在过度自信问题。
针对幻觉问题,也存在多种缓解措施: i) 预训练语料的精心筛选(Curation of Pre-Training Corpora)。如前所述,噪声数据会损害LLM的知识质量,有效且直接的缓解方式是筛选预训练语料,确保训练数据可靠且真实。\({ }^{613}\) 例如,目前的LLM尝试从可信来源采集数据,Llama 2对维基百科数据进行过采样; ii) 监督微调(Supervised Fine-Tuning, SFT)。SFT通常包括两步:首先对大量任务指令数据进行标注,然后利用最大似然估计对预训练LLM在标注数据上进行微调。同样,精心筛选的指令微调数据集也有效。与幻觉相关的基准TruthfulQA\({ }^{614}\)验证显示,在经过筛选的指令数据集上进行SFT能显著提升模型的真实性和事实准确性; iii) 解码策略设计(Decoding Strategy Designing, DSD)。DSD旨在确定如何从模型生成的概率分布中选择输出token。\({ }^{615}\) Lee等\({ }^{616}\)提出“事实核采样(factual-nucleus sampling)”,结合“top-p”采样和贪婪解码,实现在多样性与事实性之间的合理平衡。Dhuliawala等\({ }^{617}\)开发了“链式验证(Chain-of-Verification)”解码框架以缓解幻觉。Li等\({ }^{618}\)提出推理时干预策略(Inference-Time Intervention)以提高LLM的真实性; iv) 不确定性估计(Uncertainty Estimation)。不确定性可作为判断何时信任LLM的标准,帮助用户过滤不确定的回答。目前提供三种不确定性估计视角\({ }^{619}\),分别基于模型logit、语言表达和逻辑一致性。
综上,以上内容阐明了幻觉产生的原因及相关缓解策略。鉴于幻觉可能发生于预训练、微调及推理阶段,决策生命周期中需要谨慎设计任务输入指令,辅以监督微调、解码策略和不确定性估计等措施。
5.3. 数据隐私泄露¶
在深度学习领域,通常将数据集隐私攻击称为成员推断攻击(Membership Inference Attacks,MIA),即给定某条记录 \(D\) 和基于训练数据集 \(D_{train}\) 训练的深度学习模型,攻击者试图推断该记录 \(D\) 是否属于训练数据集 \(D_{train}\)。在传统的MIA中,常用的方法是通过访问目标模型的黑箱反馈信息,重新训练一个替代模型\({ }^{620}\),也称为影子模型。
随着数据隐私攻击的快速发展,目前的LLM也面临类似的数据隐私泄露风险。例如,Carlini等人\({ }^{621}\)探讨了如何利用用于下一token预测的LSTM模型的对数困惑度(log-perplexity)推断训练数据中的敏感序列。随后,Carlini等人\({ }^{621}\)还提出了基于GPT-2(Transformer架构)结合困惑度查询和zlib熵进行数据提取的方法。此外,Mattern等人\({ }^{622}\)针对GPT-2提出了一种基于计算给定序列与邻近样本损失差异的邻域攻击方法。不同于此,Meeus等人近期针对拥有70亿参数以上的现代LLM提出了文档级别的MIA。迄今为止,关于数据集相关的隐私攻击研究仍然有限,部分原因是考虑到万亿token和数十亿参数的复杂性,生成替代模型的难度极大。然而,即便如此,在决策过程中,决策相关的训练数据集仍需防范各种成员推断攻击。
5.4. 社会管理与价值对齐风险¶
LLM已在多个领域,特别是自然语言处理和计算机视觉中广泛应用。然而,价值观错配导致了对用户和社会的严重问题,如刻板印象\({ }^{623}\)、社会偏见\({ }^{624}\)、非法指令\({ }^{625}\)、道德判断\({ }^{626}\)等。为实现与人类价值观的对齐,目前已建立一系列基准,用于测试不同LLM并从多个角度纠正其不当行为。例如,FLAMES\({ }^{627}\)针对无害性原则及具有中国特色的和谐价值观开展测试;ALI-Agent\({ }^{628}\)利用LLM驱动的智能体自主能力进行刻板印象、道德和合法性适应性评估;Lee等人\({ }^{629}\)提出针对韩国社会价值观和常识的对齐基准;Fu等人\({ }^{630}\)研究文化遗产领域的错配问题。综上所述,LLM正渗透日常生活,同时也带来了越来越多社会管理和价值观方面的挑战。
技术脆弱性。 随着信息技术和社交网络的发展,社会信息传播渠道和管理模式逐渐从传统的自上而下单一形式转向分散、灵活、多样化的模式。近年来,以LLM为代表的人工智能技术的出现,无疑极大地提升了信息传播的速度和广度,同时也增强了社会公共管理部门的行政效率。然而,LLM的快速发展也带来了诸多社会管理风险。首先,基于LLM的技术易大量生成欺骗性文本、图像乃至短视频,这些虚假信息通过发达的社交媒体网络迅速传播。尤其是扭曲或误解政策的虚假信息传播速度往往超过社会管理部门的响应速度,扰乱正常政策执行和社会秩序\({ }^{631}\)。其次,基于LLM和推荐系统的社交机器人加剧了“信息茧房”现象\({ }^{632}\),通过强大的决策能力精准投放信息,锁定目标受众,通过重复交互逐步固化人的认知边界,成为煽动网络极端用户群体种族主义和政治极化的催化剂,进而将网络暴力扩散至线下抗议、示威甚至骚乱,引发社会动荡\({ }^{633}\)。
监管空白。 此外,某些社会管理的伦理敏感领域,尤其是医疗健康领域,LLM存在诸多潜在风险。尽管诸如Med-PaLM\({ }^{634}\)的LLM在诊断准确率上已超过人类医生的八个临床维度中的九个,但其部署仍面临监管挑战。美国食品药品监督管理局(FDA)因LLM模型曾被发现无意中违反临床决策支持指南,迟迟不愿将其认证为医疗器械,凸显了对如欧盟人工智能法案等严格验证和透明度要求的监管机制与政策框架的紧迫需求。此外,LLM训练数据中的文化偏见进一步加剧了这些风险。比较分析表明,GPT-4在非西方医疗数据集上的诊断表现落后于西方中心的数据集,在资源匮乏环境中错误率提高了19%\({ }^{635}\)。总之,基于LLM的技术对未来社会管理带来一定风险与挑战,亟需填补监管机制和政策框架的空白,以促进LLM模型与主流价值观的对齐并主动防范潜在问题。
价值对齐关注。 当前AI价值对齐方法大致可分为三类:来自人类反馈的强化学习、监督微调方法和推理时对齐\({ }^{636}\)。这些方法在对齐的可解释性和对齐目标的多样性方面仍面临诸多挑战。近期,微软亚洲研究院牵头的“价值罗盘”(Value Compass)项目从伦理学和社会学理论的跨学科视角出发\({ }^{637}\),提出了基于基本人类价值理论的BaseAlign算法。BaseAlign基于社会心理学家Shalom H. Schwartz提出的多维人类基本价值构建了一个基本价值空间\({ }^{638}\),将对齐的目标价值表示为该空间中的一个向量。然后,利用判别模型推导当前大模型行为对应的价值向量,通过最小化两向量之间的距离实现对齐。在一定程度上,BaseAlign增强了大模型价值对齐的可解释性和透明性,以及对不断演变的社会文化背景和变化的社会规范的适应能力。然而,尽管AI价值对齐技术取得进展,实现大模型真正的价值对齐仍有较大差距。挑战包括“对齐税”(alignment tax)问题,即价值对齐可能削弱大模型的原有能力,以及监督的可扩展性问题,特别是在未来AI能力和知识远超人类的情形下,需有效的监管与控制。
因此,针对监管机制和政策,实施行业特定的合规框架、强制对LLM进行偏见审计,并开发跨文化的对齐与验证基准尤为重要。
6. 结论¶
综上所述,本文全面回顾了智能决策(IDM)技术的发展,重点强调了其通过模型、优化算法和概率推理工具整合而演进的过程。文章聚焦于以基础模型(FM)为核心的决策范式,探讨了其在各领域变革智能决策的潜力。尽管基础模型为推动多样化应用中的智能决策提供了前所未有的机遇,但其在安全性、数据隐私和部署成本等方面也带来了显著挑战。
未来智能决策的发展将聚焦于以下几个方面:首先,决策的可解释性和透明性。尽管诸如链式思维(Chain of Thought, CoT)等方法能够部分揭示大型模型的决策过程,但仍面临生成不稳定、粒度不可控以及与人类推理不一致等问题。因此,在军事、法律和医疗等高风险行业的智能决策应用中,亟需进一步研究以提升模型的可解释性并解决模型幻觉等问题。其次,跨学科智能决策需要深入探索。目前的智能决策方法大多基于通用模型或针对特定领域,但为了确保决策的合规性和经济可行性,往往需要融合法律、经济等多学科知识。因此,构建跨学科智能决策体系将成为未来研究的重要方向之一。最后,决策环境通常是动态变化的,现有模型的训练和部署方式难以使模型持续适应不断演变的决策环境。因此,研究模型在推理阶段自我进化和动态更新以应对环境变化,也是未来的关键探索领域。
智能决策的本质在于实现决策过程的自动化。它对人类社会和科学进步具有深远意义,为更明智、高效和智能的解决方案铺平道路。展望未来,需持续努力解决现有挑战,深入挖掘其在新兴领域的潜力,促进智能决策整体发展及其对世界的积极影响。
7. ACKNOWLEDGEMENT¶
This work was partially supported by the National Natural Science Foundation of China under Grants No. (62372470, 72225011, 62402414, U23B2059, 62173034, 32222070, 62402017, 72421002, 62206303, 62476264, 62406312, 62102266,
52173241, U23A20468), the National Key Research and Development Program of China (2023YFD1900604), the Strategic Priority Research Program of the Chinese Academy of Science (XDB0680301), the Youth Innovation Promotion Association CAS (2023112), the National High Level Hospital Clinical Research Funding (2022-PUMCH-A-014), the Beijing Natural Science Foundation (4244098), the Science and Technology Innovation Program of Hunan Province (2023RC3009), the Key Research and Development Program of Yunnan Province (202202AE090034), the MNR Key Laboratory for Geo- Environmental Monitoring of Greater Bay Area (GEMLab-2023001), the Science and Technology Innovation Key R&D Program of Chongqing (CSTB2024TIAD-STX0024), the China National Postdoctoral Program for Innovative Talents (BX20240385), and River Talent Recruitment Program of Guangdong Province (2019ZT08X603).
8. 作者贡献¶
J.H. 和 Y.X. 负责设计和组织本文综述。Q.W., Qi (Cheems) .W., T.L., X.L. 和 S.Q. 撰写了“引言”部分。Z.Z., Z.S., T.Q., T.S., B.D., Chuanguang.Y., Chengqing.Y., Y.W. 和 M.L. 撰写了“基础模型概述与发展”部分。X.L., W.W., H.Z., Y.Z., Zhicheng.Z., Zhengqiu.Z., Y.L., A.L., Xu.C., B.A. 和 X.Z. 撰写了“基于基础模型的决策范式与关键技术”部分。F.W., B.Z., L.H., J.C., L.M., T.M., Y.L., J.Z., Jian.G., X.J., W.X., C.B., Y.M., Z.Y., S.G., W.S., Yinghao.Z., Junyi.G., X.H., Y.L., G.J., X.A., X.Z., H.T., L.Y., H.S., J.L., E.H., V.M.L, Y.D, G.W., Yu.Z., Yuanzhuo.W., Jiafeng.G. 和 L.W. 撰写了“基础模型驱动的科学智能决策”部分。X.F., Qi (Cheems) .W. 和 G.J. 撰写了“大型模型智能决策的风险与挑战”部分。Z.A., C.F. 和 K.H. 撰写了“结论”部分。Xueqi.C., Yaonan.W., S.Y., M.F. 和 A.F. 对本文进行了指导和修改。
9. DECLARATION OF INTERESTS¶
The authors declare no competing interests.
REFERENCES¶
[1] David Hawkins. Theory of games and economic behavior. Philosophy of Science, 12(3):221-227, 1945.
[2] Herbert A Simon and Chester Irving Barnard. Administrative behavior: A study of decisionmaking processes in administrative organization. Macmillan, 1947.
[3] HA Simon. The new science of management decision, 1960.
[4] Daniel Kahneman and Amos Tversky. Prospect theory: An analysis of decision under risk Econometrica, 47(2):263-292, 1979.
[5] John Boyd. Destruction and creation. US Army Comand and General Staff College Leavenworth, WA, 1987.
[6] Jatinder ND Gupta, Guisseppi A Forgionne, Manuel Mora T, Alexandre Gachet, and Pius Haettenschwiler. Develop- ment processes of intelligent decision-making support systems: review and perspective. Intelligent Decision-making Support Systems: Foundations, Applications and Challenges, pages 97-121, 2006.
[7] Alejandro Agostini, Carme Torras, and Florentin Wo"rgo"tter. Efficient interactive decisionmaking framework for robotic applications. Artificial Intelligence, 247:187-212, 2017.
[8] Lean Yu, Shouyang Wang, and Kin Keung Lai. An intelligent-agent-based fuzzy group decision making model for finan- cial multicriteria decision support: The case of credit scoring. European journal of operational research, 195(3):942-959, 2009.
[9] Hui Yang, Erhun Kundakcioglu, Jing Li, Teresa Wu, J Ross Mitchell, Amy K Hara, William Pavlicek, Leland S Hu, Alvin C Silva, Christine M Zwart, et al. Healthcare intelligence: turning data into knowledge. IEEE Intelligent Systems, 29(3):54-68, 2014.
[10] Richard S Sutton. Reinforcement learning: An introduction. A Bradford Book, 2018.
[11] Volodymyr Mnih. Playing atari with deep reinforcement learning. arXiv preprint arXiv:1312.5602, 2013.
[12] Ganesh Jawahar, Beno^1t Sagot, and Djame' Seddah. What does bert learn about the structure of language? In ACL 2019-57th Annual Meeting of the Association for Computational Linguistics, 2019.
[13] Josh Achiam, Steven Adler, Sandhini Agarwal, Lama Ahmad, Ilge Akkaya, Florencia Leoni Aleman, Diogo Almeida, Janko Altenschmidt, Sam Altman, Shyamal Anadkat, et al. Gpt-4 technical report. arXiv preprint arXiv:2303.08774, 2023.
[14] Alec Radford, Jong Wook Kim, Chris Hallacy, Aditya Ramesh, Gabriel Goh, Sandhini Agarwal, Girish Sastry, Amanda Askell, Pamela Mishkin, Jack Clark, et al. Learning transferable visual models from natural language supervision. In International conference on machine learning, pages 8748-8763. PMLR, 2021.
[15] Ting Chen, Simon Kornblith, Mohammad Norouzi, and Geoffrey Hinton. A simple framework for contrastive learning of visual representations. In International conference on machine learning, pages 1597-1607. PMLR, 2020.
[16] Kaiming He, Xinlei Chen, Saining Xie, Yanghao Li, Piotr Dolla'r, and Ross Girshick. Masked autoencoders are scalable vision learners. In Proceedings of the IEEE/CVF conference on computer vision and pattern recognition, pages 16000-16009, 2022.
[17] Chelsea Finn, Pieter Abbeel, and Sergey Levine. Model-agnostic meta-learning for fast adaptation of deep networks. In International conference on machine learning, pages 1126-1135. PMLR, 2017.
[18] Jake Snell, Kevin Swersky, and Richard Zemel. Prototypical networks for few-shot learning. Advances in neural information processing systems, 30, 2017.
[19] Qi Wang, Marco Federici, and Herke van Hoof. Bridge the inference gaps of neural processes via expectation maxi- mization. In The Eleventh International Conference on Learning Representations, 2023.
[20] Bo Liu, Yihao Feng, Peter Stone, and Qiang Liu. Famo: Fast adaptive multitask optimization. Advances in Neural Information Processing Systems, 36, 2024.
[21] Jiayi Shen, Xiantong Zhen, Qi Wang, and Marcel Worring. Episodic multi-task learning with heterogeneous neural processes. Advances in Neural Information Processing Systems, 36:7521475228, 2023.
[22] Jiayi Shen, Cheems Wang, Zehao Xiao, Nanne Van Noord, and Marcel Worring. Go4align: Group optimization for multi-task alignment. arXiv preprint arXiv:2404.06486, 2024.
[23] Brian Lester, Rami Al-Rfou, and Noah Constant. The power of scale for parameter-efficient prompt tuning. arXiv preprint arXiv:2104.08691, 2021.
[24] Yuchen Yang, Yingdong Shi, Cheems Wang, Xiantong Zhen, Yuxuan Shi, and Jun Xu. Reducing fine-tuning memory overhead by approximate and memory-sharing backpropagation. arXiv preprint arXiv:2406.16282, 2024.
[25] Zeyu Ma, Shiyu Wang, Xinyang Deng, and Wen Jiang. An improved approach for adversarial decision making under uncertainty based on simultaneous game. In 2018 Chinese Control And Decision Conference (CCDC), pages 2499-2503. IEEE, 2018.
[26] Gerd Gigerenzer and Wolfgang Gaissmaier. Heuristic decision making. Annual review of psychology, 62(1):451-482, 2011.
[27] Natalya Kireeva, Irina Pozdnyak, and Nikolay Filippov. Development of a decision-making algorithm for expert system in information security. In 2020 IEEE International Conference on Problems of Infocommunications. Science and Technology (PIC S&T), pages 212-216. IEEE, 2020.
[28] Liting Chen, Lu Wang, Hang Dong, Yali Du, Jie Yan, Fangkai Yang, Shuang Li, Pu Zhao, Si Qin, Saravan Rajmohan, et al. Introspective tips: Large language model for in-context decision making. arXiv preprint arXiv:2305.11598, 2023.
[29] Marko Bohanec and V Rajkovic. Expert system for decision making. Sistemica, 1(1):145-157, 1990.
[30] Volodymyr Mnih, Koray Kavukcuoglu, David Silver, Andrei A Rusu, Joel Veness, Marc G Bellemare, Alex Graves, Martin Riedmiller, Andreas K Fidjeland, Georg Ostrovski, et al. Humanlevel control through deep reinforcement learning. nature, 518(7540):529-533, 2015.
[31] Jianzhun Shao, Yun Qu, Chen Chen, Hongchang Zhang, and Xiangyang Ji. Counterfactual conservative q learning for offline multi-agent reinforcement learning. Advances in Neural Information Processing Systems, 36, 2024.
[32] Elia Kaufmann, Leonard Bauersfeld, Antonio Loquercio, Matthias Mu"ller, Vladlen Koltun, and Davide Scaramuzza. Champion-level drone racing using deep reinforcement learning. Nature, 620(7976):982-987, 2023.
[33] Julian Schrittwieser, Ioannis Antonoglou, Thomas Hubert, Karen Simonyan, Laurent Sifre, Simon Schmitt, Arthur Guez, Edward Lockhart, Demis Hassabis, Thore Graepel, et al. Mastering atari, go, chess and shogi by planning with a learned model. Nature, 588(7839):604-609, 2020.
[34] Sergey Levine, Aviral Kumar, George Tucker, and Justin Fu. Offline reinforcement learning: Tutorial, review, and perspectives on open problems. arXiv preprint arXiv:2005.01643, 2020.
[35] Yixiu Mao, Hongchang Zhang, Chen Chen, Yi Xu, and Xiangyang Ji. Supported trust region optimization for offline reinforcement learning. In International Conference on Machine Learning, pages 23829-23851. PMLR, 2023.
[36] Sherry Yang, Ofir Nachum, Yilun Du, Jason Wei, Pieter Abbeel, and Dale Schuurmans. Foundation models for decision making: Problems, methods, and opportunities. arXiv preprint arXiv:2303.04129, 2023.
[37] Marc G. Bellemare, Will Dabney, and Rémi Munos. A distributional perspective on reinforcement learning. CoRR, abs/1707.06887, 2017.
[38] S. V. Albrecht, F. Christianos, and L. Scha"fer. Multi-Agent Reinforcement Learning: Foundations and Modern Ap- proaches. MIT Press, 2024.
[39] Christian Schro"der de Witt, Tarun Gupta, Denys Makoviichuk, Viktor Makoviychuk, Philip H. S. Torr, Mingfei Sun, and Shimon Whiteson. Is independent learning all you need in the starcraft multi-agent challenge? CoRR, abs/2011.09533, 2020.
[40] Frans A. Oliehoek, Matthijs T. J. Spaan, and Nikos Vlassis. Optimal and approximate q-value functions for decentral- ized pomdps. J. Artif. Intell. Res., 32:289-353, 2008.
[41] Landon Kraemer and Bikramjit Banerjee. Multi-agent reinforcement learning as a rehearsal for decentralized planning. Neurocomputing, 190:82-94, 2016.
[42] Chao Yu, Akash Velu, Eugene Vinitsky, Jiaxuan Gao, Yu Wang, Alexandre Bayen, and Yi Wu. The surprising effective- ness of PPO in cooperative multi-agent games. In Thirty-sixth Conference on Neural Information Processing Systems Datasets and Benchmarks Track, 2022.
[43] Mengxian Li, Qi Wang, and Yongjun Xu. Gtde: Grouped training with decentralized execution for multi-agent actor- critic. In Thirty-Ninth AAAI Conference on Artificial Intelligence, 2025.
[44] Jost Tobias Springenberg, Abbas Abdolmaleki, Jingwei Zhang, Oliver Groth, Michael Bloesch, Thomas Lampe, Phile- mon Brakel, Sarah Bechtle, Steven Kapturowski, Roland Hafner, et al. Offline actor-critic reinforcement learning scales to large models. arXiv preprint arXiv:2402.05546, 2024.
[45] Qi Wang and Herke Van Hoof. Model-based meta reinforcement learning using graph structured surrogate models and amortized policy search. In International Conference on Machine Learning, pages 23055-23077. PMLR, 2022.
[46] Fangchen Liu, Hao Liu, Aditya Grover, and Pieter Abbeel. Masked autoencoding for scalable and generalizable decision making. Advances in Neural Information Processing Systems, 35:1260812618, 2022.
[47] Ramanan Sekar, Oleh Rybkin, Kostas Daniilidis, Pieter Abbeel, Danijar Hafner, and Deepak Pathak. Planning to explore via self-supervised world models. In International conference on machine learning, pages 8583-8592. PMLR, 2020.
[48] Scott Reed, Konrad Zolna, Emilio Parisotto, Sergio Gomez Colmenarejo, Alexander Novikov, Gabriel Barth-Maron, Mai Gimenez, Yury Sulsky, Jackie Kay, Jost Tobias Springenberg, et al. A generalist agent. arXiv preprint arXiv:2205.06175, 2022.
[49] Jane X Wang, Zeb Kurth-Nelson, Dhruva Tirumala, Hubert Soyer, Joel Z Leibo, Remi Munos, Charles Blundell, Dhar- shan Kumaran, and Matt Botvinick. Learning to reinforcement learn. arXiv preprint arXiv:1611.05763, 2016.
[50] Rishi Bommasani, Drew A Hudson, Ehsan Adeli, Russ Altman, Simran Arora, Sydney von Arx, Michael S Bernstein, Jeannette Bohg, Antoine Bosselut, Emma Brunskill, et al. On the opportunities and risks of foundation models. arXiv preprint arXiv:2108.07258, 2021.
[51] Fuzhen Zhuang, Zhiyuan Qi, Keyu Duan, Dongbo Xi, Yongchun Zhu, Hengshu Zhu, Hui Xiong, and Qing He. A comprehensive survey on transfer learning. Proceedings of the IEEE, 109(1):4376, 2020.
[52] Yongjun Xu, Xin Liu, Xin Cao, Changping Huang, Enke Liu, Sen Qian, Xingchen Liu, Yanjun Wu, Fengliang Dong, Cheng-Wei Qiu, et al. Artificial intelligence: A powerful paradigm for scientific research. The Innovation, 2(4), 2021.
[53] Lu Yuan, Dongdong Chen, Yi-Ling Chen, Noel Codella, Xiyang Dai, Jianfeng Gao, Houdong Hu, Xuedong Huang, Boxin Li, Chunyuan Li, et al. Florence: A new foundation model for computer vision. arXiv preprint arXiv:2111.11432, 2021.
[54] Shashank Subramanian, Peter Harrington, Kurt Keutzer, Wahid Bhimji, Dmitriy Morozov, Michael W Mahoney, and Amir Gholami. Towards foundation models for scientific machine learning: Characterizing scaling and transfer behav- ior. Advances in Neural Information Processing Systems, 36, 2024.
[55] Yongjun Xu, Fei Wang, Zhulin An, Qi Wang, and Zhao Zhang. Artificial intelligence for sciencebridging data to wisdom. The Innovation, 4(6), 2023.
[56] Tomas Mikolov. Efficient estimation of word representations in vector space. arXiv preprint arXiv:1301.3781, 2013.
[57] Jeffrey Pennington, Richard Socher, and Christopher D Manning. Glove: Global vectors for word representation. In Proceedings of the 2014 conference on empirical methods in natural language processing (EMNLP), pages 1532-1543, 2014.
[58] A Vaswani. Attention is all you need. Advances in Neural Information Processing Systems, pages 5998-6008, 2017.
[59] Jacob Devlin Ming-Wei Chang Kenton and Lee Kristina Toutanova. Bert: Pre-training of deep bidirectional transform- ers for language understanding. In Proceedings of naacL-HLT, volume 1, page 2. Minneapolis, Minnesota, 2019.
[60] Alec Radford, Jeffrey Wu, Rewon Child, David Luan, Dario Amodei, Ilya Sutskever, et al. Language models are unsupervised multitask learners. OpenAI blog, 1(8):9, 2019.
[61] Tom Brown, Benjamin Mann, Nick Ryder, Melanie Subbiah, Jared D Kaplan, Prafulla Dhariwal, Arvind Neelakantan, Pranav Shyam, Girish Sastry, Amanda Askell, et al. Language models are few-shot learners. Advances in neural information processing systems, 33:1877-1901, 2020.
[62] Aditya Ramesh, Mikhail Pavlov, Gabriel Goh, Scott Gray, Chelsea Voss, Alec Radford, Mark Chen, and Ilya Sutskever. Zero-shot text-to-image generation. In International conference on machine learning, pages 8821-8831. Pmlr, 2021.
[63] Ze Liu, Yutong Lin, Yue Cao, Han Hu, Yixuan Wei, Zheng Zhang, Stephen Lin, and Baining Guo. Swin transformer: Hierarchical vision transformer using shifted windows. In Proceedings of the IEEE/CVF international conference on computer vision, pages 10012-10022, 2021.
[64] Shukang Yin, Chaoyou Fu, Sirui Zhao, Ke Li, Xing Sun, Tong Xu, and Enhong Chen. A survey on multimodal large language models. CoRR, abs/2306.13549, 2023.
[65] Peng Xu, Xiatian Zhu, and David A. Clifton. Multimodal learning with transformers: A survey. IEEE Trans. Pattern Anal. Mach. Intell., 45(10):12113-12132, 2023.
[66] Duzhen Zhang, Yahan Yu, Jiahua Dong, Chenxing Li, Dan Su, Chenhui Chu, and Dong Yu. Mmllms: Recent advances in multimodal large language models. In Lun-Wei Ku, Andre Martins, and Vivek Srikumar, editors, Findings of the Association for Computational Linguistics, ACL 2024, Bangkok, Thailand and virtual meeting, August 11-16, 2024, pages 12401-12430. Association for Computational Linguistics, 2024.
[67] Matthew E. Peters, Mark Neumann, Mohit Iyyer, Matt Gardner, Christopher Clark, Kenton Lee, and Luke Zettlemoyer. Deep contextualized word representations. In Marilyn Walker, Heng Ji, and Amanda Stent, editors, Proceedings of the 2018 Conference of the North American Chapter of the Association for Computational Linguistics: Human Lan- guage Technologies, Volume 1 (Long Papers), pages 2227-2237, New Orleans, Louisiana, June 2018. Association for Computational Linguistics.
[68] Alex Graves and Alex Graves. Long short-term memory. Supervised sequence labelling with recurrent neural networks, pages 37-45, 2012.
[69] Alec Radford, Karthik Narasimhan, Tim Salimans, Ilya Sutskever, et al. Improving language understanding by genera- tive pre-training. 2018.
[70] Li Dong, Nan Yang, Wenhui Wang, Furu Wei, Xiaodong Liu, Yu Wang, Jianfeng Gao, Ming Zhou, and Hsiao-Wuen Hon. Unified language model pre-training for natural language understanding and generation. Advances in neural information processing systems, 32, 2019.
[71] Colin Raffel, Noam Shazeer, Adam Roberts, Katherine Lee, Sharan Narang, Michael Matena, Yanqi Zhou, Wei Li, and Peter J Liu. Exploring the limits of transfer learning with a unified text-to-text transformer. Journal of machine learning research, 21(140):1-67, 2020.
[72] Kaiming He, Xiangyu Zhang, Shaoqing Ren, and Jian Sun. Deep residual learning for image recognition. In Proceed- ings of the IEEE conference on computer vision and pattern recognition, pages 770-778, 2016.
[73] Jason Yosinski, Jeff Clune, Yoshua Bengio, and Hod Lipson. How transferable are features in deep neural networks? Advances in neural information processing systems, 27, 2014.
[74] Mingsheng Long, Yue Cao, Jianmin Wang, and Michael Jordan. Learning transferable features with deep adaptation networks. In International conference on machine learning, pages 97-105. PMLR, 2015.
[75] Alexey Dosovitskiy. An image is worth \(16 \times 16\) words: Transformers for image recognition at scale. arXiv preprint arXiv:2010.11929, 2020.
[76] Jonathan Ho, Ajay Jain, and Pieter Abbeel. Denoising diffusion probabilistic models. Advances in neural information processing systems, 33:6840-6851, 2020.
[77] Jascha Sohl-Dickstein, Eric Weiss, Niru Maheswaranathan, and Surya Ganguli. Deep unsupervised learning using nonequilibrium thermodynamics. In International conference on machine learning, pages 2256-2265. PMLR, 2015.
[78] Yang Song and Stefano Ermon. Generative modeling by estimating gradients of the data distribution. Advances in neural information processing systems, 32, 2019.
[79] Weilun Feng, Chuanguang Yang, Zhulin An, Libo Huang, Boyu Diao, Fei Wang, and Yongjun Xu. Relational diffusion distillation for efficient image generation. In Proceedings of the 32nd ACM International Conference on Multimedia, pages 205-213, 2024.
[80] Patrick Esser, Sumith Kulal, Andreas Blattmann, Rahim Entezari, Jonas Mu"ller, Harry Saini, Yam Levi, Dominik Lorenz, Axel Sauer, Frederic Boesel, et al. Scaling rectified flow transformers for high-resolution image synthesis. In Forty-first International Conference on Machine Learning, 2024.
[81] William Peebles and Saining Xie. Scalable diffusion models with transformers. In Proceedings of the IEEE/CVF International Conference on Computer Vision, pages 4195-4205, 2023.
[82] Tim Brooks, Bill Peebles, Connor Holmes, Will DePue, Yufei Guo, Li Jing, David Schnurr, Joe Taylor, Troy Luhman, Eric Luhman, et al. Video generation models as world simulators. OpenAI Blog, 1:8, 2024.
[83] Quan Sun, Qiying Yu, Yufeng Cui, Fan Zhang, Xiaosong Zhang, Yueze Wang, Hongcheng Gao, Jingjing Liu, Tiejun Huang, and Xinlong Wang. Generative pretraining in multimodality. arXiv preprint arXiv:2307.05222, 2023.
[84] Robin Rombach, Andreas Blattmann, Dominik Lorenz, Patrick Esser, and Bjo"rn Ommer. Highresolution image syn- thesis with latent diffusion models. In Proceedings of the IEEE/CVF conference on computer vision and pattern recog- nition, pages 10684-10695, 2022.
[85] Aditya Ramesh, Prafulla Dhariwal, Alex Nichol, Casey Chu, and Mark Chen. Hierarchical textconditional image generation with clip latents. arXiv preprint arXiv:2204.06125, 1(2):3, 2022.
[86] Haotian Liu, Chunyuan Li, Qingyang Wu, and Yong Jae Lee. Visual instruction tuning. Advances in neural information processing systems, 36, 2024.
[87] Deyao Zhu, Jun Chen, Xiaoqian Shen, Xiang Li, and Mohamed Elhoseiny. Minigpt-4: Enhancing vision-language understanding with advanced large language models. arXiv preprint arXiv:2304.10592, 2023.
[88] Jean-Baptiste Alayrac, Jeff Donahue, Pauline Luc, Antoine Miech, Iain Barr, Yana Hasson, Karel Lenc, Arthur Mensch, Katherine Millican, Malcolm Reynolds, et al. Flamingo: a visual language model for few-shot learning. Advances in neural information processing systems, 35:2371623736, 2022.
[89] Xueqi Cheng, Xiaohui Yan, Yanyan Lan, and Jiafeng Guo. Btm: Topic modeling over short texts. IEEE Transactions on Knowledge and Data Engineering, 26(12):2928-2941, 2014.
[90] Xue-Qi Cheng and Hua-Wei Shen. Uncovering the community structure associated with the diffusion dynamics on networks. Journal of Statistical Mechanics: Theory and Experiment, 2010(04):P04024, 2010.
[91] Yujie Li, Tao Sun, Zezhi Shao, Yiqiang Zhen, Yongjun Xu, and Fei Wang. Trajectory-user linking via multi-scale graph attention network. Pattern Recognition, 158:110978, 2025.
[92] Yunke Zhang, Yuming Lin, Guanjie Zheng, Yu Liu, Nicholas Sukiennik, Fengli Xu, Yongjun Xu, Feng Lu, Qi Wang, Yuan Lai, et al. Metacity: Data-driven sustainable development of complex cities. The Innovation, 6(2):100775, 2025.
[93] Tangwen Qian, Yongjun Xu, Zhao Zhang, and Fei Wang. Trajectory prediction from hierarchical perspective. In Proceedings of the 30th ACM International Conference on Multimedia, pages 6822-6830, 2022.
[94] Tao Sun, Fei Wang, Zhao Zhang, Lin Wu, and Yongjun Xu. Human mobility identification by deep behavior relevant location representation. In International Conference on Database Systems for Advanced Applications, pages 439-454. Springer, 2022.
[95] Saiping Guan, Xiaolong Jin, Jiafeng Guo, Yuanzhuo Wang, and Xueqi Cheng. Neuinfer: Knowledge inference on n-ary facts. In Proceedings of the 58th annual meeting of the association for computational linguistics, pages 6141-6151, 2020.
[96] Zhuo Chen, Zhao Zhang, Zixuan Li, Fei Wang, Yutao Zeng, Xiaolong Jin, and Yongjun Xu. Selfimprovement program- ming for temporal knowledge graph question answering. In Proceedings of the 2024 Joint International Conference on Computational Linguistics, Language Resources and Evaluation (LREC-COLING 2024), pages 14579-14594, 2024.
[97] Ke Liang, Lingyuan Meng, Meng Liu, Yue Liu, Wenxuan Tu, Siwei Wang, Sihang Zhou, Xinwang Liu, Fuchun Sun, and Kunlun He. A survey of knowledge graph reasoning on graph types: Static, dynamic, and multi-modal. IEEE Transactions on Pattern Analysis and Machine Intelligence, 46(12):9456-9478, 2024.
[98] Chengqing Yu, Fei Wang, Zezhi Shao, Tangwen Qian, Zhao Zhang, Wei Wei, and Yongjun Xu. Ginar: An end-to-end multivariate time series forecasting model suitable for variable missing. In Proceedings of the 30th ACM SIGKDD conference on knowledge discovery and data mining, pages 3989-4000, 2024.
[99] Yujie Li, Zezhi Shao, Yongjun Xu, Qiang Qiu, Zhaogang Cao, and Fei Wang. Dynamic frequency domain graph convolutional network for traffic forecasting. In ICASSP 2024-2024 IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP), pages 52455249. IEEE, 2024.
[100] Ke Liang, Yue Liu, Sihang Zhou, Wenxuan Tu, Yi Wen, Xihong Yang, Xiangjun Dong, and Xinwang Liu. Knowl- edge graph contrastive learning based on relation-symmetrical structure. IEEE Transactions on Knowledge and Data Engineering, 36(1):226-238, 2023.
[101] Jiezhong Qiu, Qibin Chen, Yuxiao Dong, Jing Zhang, Hongxia Yang, Ming Ding, Kuansan Wang, and Jie Tang. Gcc: Graph contrastive coding for graph neural network pre-training. In Proceedings of the 26th ACM SIGKDD international conference on knowledge discovery & data mining, pages 1150-1160, 2020.
[102] Xiangguo Sun, Hong Cheng, Jia Li, Bo Liu, and Jihong Guan. All in one: Multi-task prompting for graph neural networks. In Proceedings of the 29th ACM SIGKDD Conference on Knowledge Discovery and Data Mining, pages 2120-2131, 2023.
[103] Frederik Wenkel, Guy Wolf, and Boris Knyazev. Pretrained language models to solve graph tasks in natural language. In ICML 2023 Workshop on Structured Probabilistic Inference backslash & Generative Modeling, 2023.
[104] Ruosong Ye, Caiqi Zhang, Runhui Wang, Shuyuan Xu, and Yongfeng Zhang. Language is all a graph needs. In Findings of the Association for Computational Linguistics: EACL 2024, pages 1955-1973, 2024.
[105] Costas Mavromatis, Vassilis N Ioannidis, Shen Wang, Da Zheng, Soji Adeshina, Jun Ma, Han Zhao, Christos Faloutsos, and George Karypis. Train your own gnn teacher: Graph-aware distillation on textual graphs. In Joint European Conference on Machine Learning and Knowledge Discovery in Databases, pages 157-173. Springer, 2023.
[106] Tianjie Zhao, Sheng Wang, Chaojun Ouyang, Min Chen, Chenying Liu, Jin Zhang, Long Yu, Fei Wang, Yong Xie, Jun Li, et al. Artificial intelligence for geoscience: Progress, challenges and perspectives. The Innovation, 2024.
[107] Tangwen Qian, Yile Chen, Gao Cong, Yongjun Xu, and Fei Wang. Adaptraj: a multi-source domain generalization framework for multi-agent trajectory prediction. In 2024 IEEE 40th International Conference on Data Engineering (ICDE), pages 5048-5060. IEEE, 2024.
[108] Yongjun Xu, Fei Wang, and Tangtang Zhang. Artificial intelligence is restructuring a new world. The Innovation, 5(6), 2024.
[109] Fei Wang, Di Yao, Yong Li, Tao Sun, and Zhao Zhang. Ai-enhanced spatial-temporal data-mining technology: New chance for next-generation urban computing. The Innovation, 4(2), 2023.
[110] Zezhi Shao, Zhao Zhang, Fei Wang, and Yongjun Xu. Pre-training enhanced spatial-temporal graph neural network for multivariate time series forecasting. In Proceedings of the 28th ACM SIGKDD conference on knowledge discovery and data mining, pages 1567-1577, 2022.
[111] Zezhi Shao, Zhao Zhang, Wei Wei, Fei Wang, Yongjun Xu, Xin Cao, and Christian S Jensen. Decoupled dynamic spatial-temporal graph neural network for traffic forecasting. Proceedings of the VLDB Endowment, 15(11):2733-2746, 2022.
[112] Zezhi Shao, Fei Wang, Yongjun Xu, Wei Wei, Chengqing Yu, Zhao Zhang, Di Yao, Tao Sun, Guangyin Jin, Xin Cao, et al. Exploring progress in multivariate time series forecasting: Comprehensive benchmarking and heterogeneity analysis. IEEE Transactions on Knowledge and Data Engineering, 2024.
[113] Zezhi Shao, Zhao Zhang, Fei Wang, Wei Wei, and Yongjun Xu. Spatial-temporal identity: A simple yet effective base- line for multivariate time series forecasting. In Proceedings of the 31st ACM International Conference on Information & Knowledge Management, pages 4454-4458, 2022.
[114] Defu Cao, Furong Jia, Sercan O Arik, Tomas Pfister, Yixiang Zheng, Wen Ye, and Yan Liu. Tempo: Prompt-based generative pre-trained transformer for time series forecasting. arXiv preprint arXiv:2310.04948, 2023.
[115] Ching Chang, Wen-Chih Peng, and Tien-Fu Chen. Llm4ts: Two-stage fine-tuning for time-series forecasting with pre-trained llms. arXiv preprint arXiv:2308.08469, 2023.
[116] Nate Gruver, Marc Finzi, Shikai Qiu, and Andrew G Wilson. Large language models are zero-shot time series forecast- ers. Advances in Neural Information Processing Systems, 36, 2024.
[117] Zhihan Yue, Yujing Wang, Juanyong Duan, Tianmeng Yang, Congrui Huang, Yunhai Tong, and Bixiong Xu. Ts2vec: Towards universal representation of time series. In Proceedings of the AAAI Conference on Artificial Intelligence, pages 8980-8987, 2022.
[118] Jiaxiang Dong, Haixu Wu, Haoran Zhang, Li Zhang, Jianmin Wang, and Mingsheng Long. Simmtm: A simple pre- training framework for masked time-series modeling. Advances in Neural Information Processing Systems, 36, 2024.
[119] Yuan Wang, Zezhi Shao, Tao Sun, Chengqing Yu, Yongjun Xu, and Fei Wang. Clusteringproperty matters: A cluster- aware network for large scale multivariate time series forecasting. In Proceedings of the 32nd ACM International Conference on Information and Knowledge Management, pages 4340-4344, 2023.
[120] Ming Jin, Shiyu Wang, Lintao Ma, Zhixuan Chu, James Y Zhang, Xiaoming Shi, Pin-Yu Chen, Yuxuan Liang, Yuan- Fang Li, Shirui Pan, et al. Time-llm: Time series forecasting by reprogramming large language models. arXiv preprint arXiv:2310.01728, 2023.
[121] Hao Xue and Flora D Salim. Promptcast: A new prompt-based learning paradigm for time series forecasting. IEEE Transactions on Knowledge and Data Engineering, 2023.
[122] Mark Chen, Jerry Tworek, Heewoo Jun, Qiming Yuan, Henrique Ponde De Oliveira Pinto, Jared Kaplan, Harri Edwards, Yuri Burda, Nicholas Joseph, Greg Brockman, et al. Evaluating large language models trained on code. arXiv preprint arXiv:2107.03374, 2021.
[123] Yujia Li, David Choi, Junyoung Chung, Nate Kushman, Julian Schrittwieser, Re'mi Leblond, Tom Eccles, James Keeling, Felix Gimeno, Agustin Dal Lago, et al. Competition-level code generation with alphacode. Science, 378(6624):1092-1097, 2022.
[124] Raymond Li, Loubna Ben Allal, Yangtian Zi, Niklas Muennighoff, Denis Kocetkov, Chenghao Mou, Marc Marone, Christopher Akiki, Jia Li, Jenny Chim, et al. Starcoder: may the source be with you! arXiv preprint arXiv:2305.06161, 2023.
[125] Carlos E Jimenez, John Yang, Alexander Wettig, Shunyu Yao, Kexin Pei, Ofir Press, and Karthik Narasimhan. Swe- bench: Can language models resolve real-world github issues? arXiv preprint arXiv:2310.06770, 2023.
[126] Linhao Dong, Shuang Xu, and Bo Xu. Speech-transformer: a no-recurrence sequence-to-sequence model for speech recognition. In 2018 IEEE international conference on acoustics, speech and signal processing (ICASSP), pages 5884-5888. IEEE, 2018.
[127] Chengyi Wang, Sanyuan Chen, Yu Wu, Ziqiang Zhang, Long Zhou, Shujie Liu, Zhuo Chen, Yanqing Liu, Huam- ing Wang, Jinyu Li, et al. Neural codec language models are zero-shot text to speech synthesizers. arXiv preprint arXiv:2301.02111, 2023.
[128] Jason Wei, Xuezhi Wang, Dale Schuurmans, Maarten Bosma, Fei Xia, Ed Chi, Quoc V Le, Denny Zhou, et al. Chain- of-thought prompting elicits reasoning in large language models. Advances in neural information processing systems, 35:24824-24837, 2022.
[129] Shunyu Yao, Dian Yu, Jeffrey Zhao, Izhak Shafran, Tom Griffiths, Yuan Cao, and Karthik Narasimhan. Tree of thoughts: Deliberate problem solving with large language models. Advances in Neural Information Processing Systems, 36, 2024.
[130] Hao Sha, Yao Mu, Yuxuan Jiang, Li Chen, Chenfeng Xu, Ping Luo, Shengbo Eben Li, Masayoshi Tomizuka, Wei Zhan, and Mingyu Ding. Languagempc: Large language models as decision makers for autonomous driving. arXiv preprint arXiv:2310.03026, 2023.
[131] T Guo, X Chen, Y Wang, R Chang, S Pei, NV Chawla, O Wiest, and X Zhang. Large language model based multi- agents: A survey of progress and challenges. In 33rd International Joint Conference on Artificial Intelligence (IJCAI 2024). IJCAI; Cornell arxiv, 2024.
[132] Arya Rao, John Kim, Meghana Kamineni, Michael Pang, Winston Lie, and Marc D Succi. Evaluating chatgpt as an adjunct for radiologic decision-making. MedRxiv, pages 2023-02, 2023.
[133] Can Cui, Yunsheng Ma, Xu Cao, Wenqian Ye, and Ziran Wang. Drive as you speak: Enabling human-like interaction with large language models in autonomous vehicles. In Proceedings of the IEEE/CVF Winter Conference on Applica- tions of Computer Vision, pages 902-909, 2024.
[134] Andrew Zhao, Daniel Huang, Quentin Xu, Matthieu Lin, Yong-Jin Liu, and Gao Huang. Expel: Llm agents are experiential learners. In Proceedings of the AAAI Conference on Artificial Intelligence, pages 19632-19642, 2024.
[135] Chengqing Yu, Guangxi Yan, Chengming Yu, and Xiwei Mi. Attention mechanism is useful in spatio-temporal wind speed prediction: Evidence from china. Applied Soft Computing, 148:110864, 2023.
[136] Chengqing Yu, Fei Wang, Yilun Wang, Zezhi Shao, Tao Sun, Di Yao, and Yongjun Xu. Mgsfformer: A multi-granularity spatiotemporal fusion transformer for air quality prediction. Information Fusion, 113:102607, 2025.
[137] Fang Cheng and Hui Liu. Multi-step electric vehicles charging loads forecasting: An autoformer variant with feature extraction, frequency enhancement, and error correction blocks. Applied Energy, 376:124308, 2024.
[138] Chengqing Yu, Fei Wang, Zezhi Shao, Tao Sun, Lin Wu, and Yongjun Xu. Dsformer: A double sampling transformer for multivariate time series long-term prediction. In Proceedings of the 32nd ACM international conference on information and knowledge management, pages 3062-3072, 2023.
[139] Yu Chengqing, Yan Guangxi, Yu Chengming, Zhang Yu, and Mi Xiwei. A multi-factor driven spatiotemporal wind power prediction model based on an ensemble deep graph attention reinforcement learning networks. Energy, 263:126034, 2023.
[140] Chengqing Yu, Guangxi Yan, Chengming Yu, Xinwei Liu, and Xiwei Mi. Mriformer: A multiresolution interactive transformer for wind speed multi-step prediction. Information Sciences, 661:120150, 2024.
[141] Chengming Yu, Ji Qiao, Chao Chen, Chengqing Yu, and Xiwei Mi. Tfeformer: A new temporal frequency ensemble transformer for day-ahead photovoltaic power prediction. Journal of Cleaner Production, 448:141690, 2024.
[142] Hugo Touvron, Thibaut Lavril, Gautier Izacard, Xavier Martinet, Marie-Anne Lachaux, Timothe'e Lacroix, Baptiste Rozie`re, Naman Goyal, Eric Hambro, and Faisal Azhar. Llama: Open and efficient foundation language models. arXiv preprint arXiv:2302.13971, 2023.
[143] Zezhi Shao, Tangwen Qian, Tao Sun, Fei Wang, and Yongjun Xu. Spatial-temporal large models: A super hub linking multiple scientific areas with artificial intelligence. The Innovation, page 100763, 2024.
[144] Team GLM, Aohan Zeng, Bin Xu, Bowen Wang, Chenhui Zhang, Da Yin, Diego Rojas, Guanyu Feng, Hanlin Zhao, Hanyu Lai, et al. Chatglm: A family of large language models from glm-130b to glm-4 all tools. arXiv preprint arXiv:2406.12793, 2024.
[145] M Lewis. Bart: Denoising sequence-to-sequence pre-training for natural language generation, translation, and compre- hension. arXiv preprint arXiv:1910.13461, 2019.
[146] Yi Tay, Mostafa Dehghani, Vinh Q Tran, Xavier Garcia, Jason Wei, Xuezhi Wang, Hyung Won Chung, Siamak Shakeri, Dara Bahri, Tal Schuster, et al. Ul2: Unifying language learning paradigms. arXiv preprint arXiv:2205.05131, 2022.
[147] Jinze Bai, Shuai Bai, Yunfei Chu, Zeyu Cui, Kai Dang, Xiaodong Deng, Yang Fan, Wenbin Ge, Yu Han, Fei Huang, et al. Qwen technical report. arXiv preprint arXiv:2309.16609, 2023.
[148] Edward J Hu, Phillip Wallis, Zeyuan Allen-Zhu, Yuanzhi Li, Shean Wang, Lu Wang, Weizhu Chen, et al. Lora: Low- rank adaptation of large language models. In International Conference on Learning Representations, 2022.
[149] Long Ouyang, Jeffrey Wu, Xu Jiang, Diogo Almeida, Carroll Wainwright, Pamela Mishkin, Chong Zhang, Sandhini Agarwal, Katarina Slama, Alex Ray, et al. Training language models to follow instructions with human feedback. Advances in Neural Information Processing Systems, 35:27730-27744, 2022.
[150] Patrick Lewis, Ethan Perez, Aleksandra Piktus, Fabio Petroni, Vladimir Karpukhin, Naman Goyal, Heinrich Küttler, Mike Lewis, Wen-tau Yih, Tim Rockta"schel, et al. Retrieval-augmented generation for knowledge-intensive nlp tasks. Advances in Neural Information Processing Systems, 33:9459-9474, 2020.
[151] Timo Schick, Jane Dwivedi-Yu, Roberto Dess`1, Roberta Raileanu, Maria Lomeli, Eric Hambro, Luke Zettlemoyer, Nicola Cancedda, and Thomas Scialom. Toolformer: Language models can teach themselves to use tools. Advances in Neural Information Processing Systems, 36, 2024.
[152] Wenqi Shao, Chonghe Jiang, Kaipeng Zhang, Yu Qiao, Ping Luo, et al. Foundation model is efficient multimodal multitask model selector. Advances in Neural Information Processing Systems, 36, 2024.
[153] Wonjae Kim, Bokyung Son, and Ildoo Kim. Vilt: Vision-and-language transformer without convolution or region supervision. In International conference on machine learning, pages 55835594. PMLR, 2021.
[154] Haiyang Xu, Qinghao Ye, Ming Yan, Yaya Shi, Jiabo Ye, Yuanhong Xu, Chenliang Li, Bin Bi, Qi Qian, Wei Wang, et al. mplug-2: A modularized multi-modal foundation model across text, image and video. In International Conference on Machine Learning, pages 38728-38748. PMLR, 2023.
[155] Chunyuan Li, Zhe Gan, Zhengyuan Yang, Jianwei Yang, Linjie Li, Lijuan Wang, Jianfeng Gao, et al. Multimodal foundation models: From specialists to general-purpose assistants. Foundations and Trends® in Computer Graphics and Vision, 16(1-2):1-214, 2024.
[156] Xingqian Xu, Zhangyang Wang, Gong Zhang, Kai Wang, and Humphrey Shi. Versatile diffusion: Text, images and variations all in one diffusion model. In Proceedings of the IEEE/CVF International Conference on Computer Vision, pages 7754-7765, 2023.
[157] Yin Zheng, Yu-Jin Zhang, and Hugo Larochelle. A deep and autoregressive approach for topic modeling of multimodal data. IEEE transactions on pattern analysis and machine intelligence, 38(6):1056-1069, 2015.
[158] AJ Piergiovanni, Isaac Noble, Dahun Kim, Michael S Ryoo, Victor Gomes, and Anelia Angelova. Mirasol3b: A mul- timodal autoregressive model for time-aligned and contextual modalities. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pages 26804-26814, 2024.
[159] Yanan Wang, Michihiro Yasunaga, Hongyu Ren, Shinya Wada, and Jure Leskovec. Vqa-gnn: Reasoning with multi- modal knowledge via graph neural networks for visual question answering. In Proceedings of the IEEE/CVF Interna- tional Conference on Computer Vision, pages 2158221592, 2023.
[160] Feiyu Chen, Jie Shao, Shuyuan Zhu, and Heng Tao Shen. Multivariate, multi-frequency and multimodal: Rethink- ing graph neural networks for emotion recognition in conversation. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pages 10761-10770, 2023.
[161] Chuanguang Yang, Zhulin An, Hui Zhu, Xiaolong Hu, Kun Zhang, Kaiqiang Xu, Chao Li, and Yongjun Xu. Gated convolutional networks with hybrid connectivity for image classification. In Proceedings of the AAAI conference on artificial intelligence, pages 12581-12588, 2020.
[162] Swalpa Kumar Roy, Ankur Deria, Danfeng Hong, Behnood Rasti, Antonio Plaza, and Jocelyn Chanussot. Multimodal fusion transformer for remote sensing image classification. IEEE Transactions on Geoscience and Remote Sensing, 61:1-20, 2023.
[163] Yikai Wang, Xinghao Chen, Lele Cao, Wenbing Huang, Fuchun Sun, and Yunhe Wang. Multimodal token fusion for vision transformers. In Proceedings of the IEEE/CVF conference on computer vision and pattern recognition, pages 12186-12195, 2022.
[164] Fang Cheng and Hui Liu. An adaptive hybrid deep learning-based reliability assessment framework for damping track system considering multi-random variables. Mechanical Systems and Signal Processing, 208:110981, 2024.
[165] Nanyi Fei, Zhiwu Lu, Yizhao Gao, Guoxing Yang, Yuqi Huo, Jingyuan Wen, Haoyu Lu, Ruihua Song, Xin Gao, Tao Xiang, et al. Towards artificial general intelligence via a multimodal foundation model. Nature Communications, 13(1):3094, 2022.
[166] Fei Ma, Yang Li, Shiguang Ni, Shao-Lun Huang, and Lin Zhang. Data augmentation for audiovisual emotion recogni- tion with an efficient multimodal conditional gan. Applied Sciences, 12(1):527, 2022.
[167] Zihao Wang, Shaofei Cai, Anji Liu, Yonggang Jin, Jinbing Hou, Bowei Zhang, Haowei Lin, Zhaofeng He, Zilong Zheng, Yaodong Yang, et al. Jarvis-1: Open-world multi-task agents with memory-augmented multimodal language models. IEEE Transactions on Pattern Analysis and Machine Intelligence, 2024.
[168] Wenjie Zheng, Jianfei Yu, Rui Xia, and Shijin Wang. A facial expression-aware multimodal multitask learning frame- work for emotion recognition in multi-party conversations. In Proceedings of the 61st Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), pages 15445-15459, 2023.
[169] Amanpreet Singh, Ronghang Hu, Vedanuj Goswami, Guillaume Couairon, Wojciech Galuba, Marcus Rohrbach, and Douwe Kiela. Flava: A foundational language and vision alignment model. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pages 15638-15650, 2022.
[170] Zhiqing Sun, Sheng Shen, Shengcao Cao, Haotian Liu, Chunyuan Li, Yikang Shen, Chuang Gan, Liang-Yan Gui, Yu- Xiong Wang, Yiming Yang, et al. Aligning large multimodal models with factually augmented rlhf. arXiv preprint arXiv:2309.14525, 2023.
[171] Sheng Zhang, Yanbo Xu, Naoto Usuyama, Hanwen Xu, Jaspreet Bagga, Robert Tinn, Sam Preston, Rajesh Rao, Mu Wei, Naveen Valluri, et al. Biomedclip: a multimodal biomedical foundation model pretrained from fifteen million scientific image-text pairs. arXiv preprint arXiv:2303.00915, 2023.
[172] Chuanguang Yang, Zhulin An, Linhang Cai, and Yongjun Xu. Mutual contrastive learning for visual representation learning. In Proceedings of the AAAI Conference on Artificial Intelligence, pages 3045-3053, 2022.
[173] Zhimin Chen, Longlong Jing, Yingwei Li, and Bing Li. Bridging the domain gap: Self-supervised 3d scene understand- ing with foundation models. Advances in Neural Information Processing Systems, 36, 2024.
[174] Abhinav Valada, Rohit Mohan, and Wolfram Burgard. Self-supervised model adaptation for multimodal semantic segmentation. International Journal of Computer Vision, 128(5):1239-1285, 2020.
[175] Hiroki Furuta, Kuang-Huei Lee, Ofir Nachum, Yutaka Matsuo, Aleksandra Faust, Shixiang Shane Gu, and Izzeddin Gur. Multimodal web navigation with instruction-finetuned foundation models. arXiv preprint arXiv:2305.11854, 2023.
[176] Dana Lahat, Tu"lay Adali, and Christian Jutten. Multimodal data fusion: an overview of methods, challenges, and prospects. Proceedings of the IEEE, 103(9):1449-1477, 2015.
[177] Jing Gao, Peng Li, Zhikui Chen, and Jianing Zhang. A survey on deep learning for multimodal data fusion. Neural Computation, 32(5):829-864, 2020.
[178] Yong Li, Yuanzhi Wang, and Zhen Cui. Decoupled multimodal distilling for emotion recognition. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pages 6631-6640, 2023.
[179] Shicai Wei, Chunbo Luo, and Yang Luo. Mmanet: Margin-aware distillation and modality-aware regularization for incomplete multimodal learning. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recog- nition, pages 20039-20049, 2023.
[180] Chaohui Yu, Qiang Zhou, Jingliang Li, Jianlong Yuan, Zhibin Wang, and Fan Wang. Foundation model drives weakly incremental learning for semantic segmentation. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pages 23685-23694, 2023.
[181] Yuxing Long, Binyuan Hui, Fulong Ye, Yanyang Li, Zhuoxin Han, Caixia Yuan, Yongbin Li, and Xiaojie Wang. Spring: Situated conversation agent pretrained with multimodal questions from incremental layout graph. In Proceedings of the AAAI Conference on Artificial Intelligence, pages 13309-13317, 2023.
[182] Pandu Nayak. Mum: A new ai milestone for understanding information. Google, May, 18, 2021.
[183] Mr D Murahari Reddy, Mr Sk Masthan Basha, Mr M Chinnaiahgari Hari, and Mr N Penchalaiah. Dall-e: Creating images from text. UGC Care Group I Journal, 8(14):71-75, 2021.
[184] Tadas Baltrus`aitis, Chaitanya Ahuja, and Louis-Philippe Morency. Multimodal machine learning: A survey and taxon- omy. IEEE transactions on pattern analysis and machine intelligence, 41(2):423-443, 2018.
[185] Yinhan Liu. Roberta: A robustly optimized bert pretraining approach. arXiv preprint arXiv:1907.11692, 2019.
[186] Aakanksha Chowdhery, Sharan Narang, Jacob Devlin, Maarten Bosma, Gaurav Mishra, Adam Roberts, Paul Barham, Hyung Won Chung, Charles Sutton, and Sebastian Gehrmann. Palm: Scaling language modeling with pathways. Journal of Machine Learning Research, 24(240):1-113, 2023.
[187] Hugo Touvron, Louis Martin, Kevin Stone, Peter Albert, Amjad Almahairi, Yasmine Babaei, Nikolay Bashlykov, Soumya Batra, Prajjwal Bhargava, Shruti Bhosale, et al. Llama 2: Open foundation and fine-tuned chat models. arXiv preprint arXiv:2307.09288, 2023.
[188] Yuren Mao, Yuhang Ge, Yijiang Fan, Wenyi Xu, Yu Mi, Zhonghao Hu, and Yunjun Gao. A survey on lora of large language models. arXiv preprint arXiv:2407.11046, 2024.
[189] Edward J Hu, yelong shen, Phillip Wallis, Zeyuan Allen-Zhu, Yuanzhi Li, Shean Wang, Lu Wang, and Weizhu Chen. LoRA: Low-rank adaptation of large language models. In International Conference on Learning Representations, 2022.
[190] Tim Dettmers, Artidoro Pagnoni, Ari Holtzman, and Luke Zettlemoyer. Qlora: Efficient finetuning of quantized llms. In A. Oh, T. Naumann, A. Globerson, K. Saenko, M. Hardt, and S. Levine, editors, Advances in Neural Information Processing Systems, volume 36, pages 10088-10115. Curran Associates, Inc., 2023.
[191] Hanqing Wang, Bowen Ping, Shuo Wang, Xu Han, Yun Chen, Zhiyuan Liu, and Maosong Sun. Lora-flow: Dynamic lora fusion for large language models in generative tasks. In Proceedings of the 62nd Annual Meeting of the Associa- tion for Computational Linguistics (Volume 1: Long Papers), pages 12871-12882, Bangkok, Thailand, August 2024. Association for Computational Linguistics.
[192] Taiqiang Wu, Jiahao Wang, Zhe Zhao, and Ngai Wong. Mixture-of-subspaces in low-rank adaptation. In Yaser Al- Onaizan, Mohit Bansal, and Yun-Nung Chen, editors, Proceedings of the 2024 Conference on Empirical Methods in Natural Language Processing, pages 7880-7899, Miami, Florida, USA, November 2024. Association for Computa- tional Linguistics.
[193] Xinyin Ma, Gongfan Fang, and Xinchao Wang. Llm-pruner: On the structural pruning of large language models. Advances in neural information processing systems, 36:21702-21720, 2023.
[194] Chuanguang Yang, Zhulin An, Libo Huang, Junyu Bi, Xinqiang Yu, Han Yang, Boyu Diao, and Yongjun Xu. Clip-kd: An empirical study of clip model distillation. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pages 15952-15962, 2024.
[195] Chuanguang Yang, Helong Zhou, Zhulin An, Xue Jiang, Yongjun Xu, and Qian Zhang. Crossimage relational knowl- edge distillation for semantic segmentation. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pages 12319-12328, 2022.
[196] Chuanguang Yang, Zhulin An, Linhang Cai, and Yongjun Xu. Hierarchical self-supervised augmented knowledge distillation. In International Joint Conference on Artificial Intelligence, pages 1217-1223, 2021.
[197] Chuanguang Yang, Zhulin An, Helong Zhou, Fuzhen Zhuang, Yongjun Xu, and Qian Zhang. Online knowledge dis- tillation via mutual contrastive learning for visual recognition. IEEE Transactions on Pattern Analysis and Machine Intelligence, 45(8):10212-10227, 2023.
[198] Yilong Zhao, Chien-Yu Lin, Kan Zhu, Zihao Ye, Lequn Chen, Size Zheng, Luis Ceze, Arvind Krishnamurthy, Tianqi Chen, and Baris Kasikci. Atom: Low-bit quantization for efficient and accurate llm serving. In P. Gibbons, G. Pekhi- menko, and C. De Sa, editors, Proceedings of Machine Learning and Systems, volume 6, pages 196-209, 2024.
[199] Enze Xie, Junsong Chen, Junyu Chen, Han Cai, Haotian Tang, Yujun Lin, Zhekai Zhang, Muyang Li, Ligeng Zhu, Yao Lu, and Song Han. Sana: Efficient high-resolution image synthesis with linear diffusion transformer, 2024.
[200] Markus J Buehler. Preflexor: Preference-based recursive language modeling for exploratory optimization of reasoning and agentic thinking. arXiv preprint arXiv:2410.12375, 2024.
[201] Yiqing Wu, Zhao Zhang, Fei Wang, Yongjun Xu, and Jincai Huang. Towards more economical large-scale foundation models : no longer a game for the few. The Innovation, page 100832, 2025.
[202] Hui Liu, Chengqing Yu, Haiping Wu, Zhu Duan, and Guangxi Yan. A new hybrid ensemble deep reinforcement learning model for wind speed short term forecasting. Energy, 202:117794, 2020.
[203] Xinwei Liu, Muchuan Qin, Yue He, Xiwei Mi, and Chengqing Yu. A new multi-data-driven spatiotemporal pm2. 5 forecasting model based on an ensemble graph reinforcement learning convolutional network. Atmospheric Pollution Research, 12(10):101197, 2021.
[204] Yongjun Xu, Fei Wang, Zhulin An, Qi Wang, and Zhao Zhang. Artificial intelligence for sciencebridging data to wisdom. The Innovation, 4(6), 2023.
[205] Sherry Yang. Foundation Models for Decision Making: Algorithms, Frameworks, and Applications. PhD thesis, EECS Department, University of California, Berkeley, Aug 2024.
[206] Qi Wang, Yanghe Feng, Jincai Huang, Yiqin Lv, Zheng Xie, and Xiaoshan Gao. Large-scale generative simulation artificial intelligence: The next hotspot. The Innovation, 4(6), 2023.
[207] Fei Wang, Di Yao, Yong Li, Tao Sun, and Zhao Zhang. Ai-enhanced spatial-temporal data-mining technology: New chance for next-generation urban computing. The Innovation, 4, 2023.
[208] Zihao Fu, Haoran Yang, Anthony Man-Cho So, Wai Lam, Lidong Bing, and Nigel Collier. On the Effectiveness of Parameter-Efficient Fine-Tuning. arXiv e-prints, page arXiv:2211.15583, November 2022.
[209] Zeyu Han, Chao Gao, Jinyang Liu, Jeff Zhang, and Sai Qian Zhang. Parameter-Efficient FineTuning for Large Models: A Comprehensive Survey. arXiv e-prints, page arXiv:2403.14608, March 2024.
[210] Ke Liang, Lingyuan Meng, Hao Li, Meng Liu, Siwei Wang, Sihang Zhou, Xinwang Liu, and Kunlun He. Mgksite: Multi-modal knowledge-driven site selection via intra and inter-modal graph fusion. IEEE Transactions on Multimedia, 2024.
[211] Pranav Ashar, Srinivas Devadas, and A. Richard Newton. State Encoding, pages 87-116. Springer US, Boston, MA, 1992.
[212] Hiroshi Higashi, Tetsuto Minami, and Shigeki Nakauchi. Cooperative update of beliefs and statetransition functions in human reinforcement learning. Scientific Reports, 9(1):17704, 2019.
[213] Siheng Chen, Yiyi Liao, Fei Wang, Gang Wang, Liang Wang, Yafei Wang, and Xichan Zhu. Toward the robustness of autonomous vehicles in the ai era. The Innovation, page 100780, 2024.
[214] Yang Zhou, Lifan Wu, Ravi Ramamoorthi, and Ling-Qi Yan. Vectorization for fast, analytic, and differentiable visibility. ACM Trans. Graph., 40(3), July 2021.
[215] Siva Sivamani Ganesh Kumar and Abhishek Gudipalli. A comprehensive review on payloads of unmanned aerial vehicle. The Egyptian Journal of Remote Sensing and Space Sciences, 27(4):637644, 2024.
[216] Jason Wei, Xuezhi Wang, Dale Schuurmans, Maarten Bosma, Brian Ichter, Fei Xia, Ed H. Chi, Quoc V. Le, and Denny Zhou. Chain-of-thought prompting elicits reasoning in large language models. In Advances in Neural Information Processing Systems 35, NeurIPS, 2022.
[217] Paul F Christiano, Jan Leike, Tom Brown, Miljan Martic, Shane Legg, and Dario Amodei. Deep reinforcement learning from human preferences. Advances in neural information processing systems, 30, 2017.
[218] Yuntao Bai, Andy Jones, Kamal Ndousse, Amanda Askell, Anna Chen, Nova DasSarma, Dawn Drain, Stanislav Fort, Deep Ganguli, Tom Henighan, et al. Training a helpful and harmless assistant with reinforcement learning from human feedback. arXiv preprint arXiv:2204.05862, 2022.
[219] Feifan Song, Bowen Yu, Minghao Li, Haiyang Yu, Fei Huang, Yongbin Li, and Houfeng Wang. Preference ranking optimization for human alignment. arXiv preprint arXiv:2306.17492, 2023.
[220] John Schulman, Filip Wolski, Prafulla Dhariwal, Alec Radford, and Oleg Klimov. Proximal policy optimization algo- rithms. arXiv preprint arXiv:1707.06347, 2017.
[221] Rafael Rafailov, Archit Sharma, Eric Mitchell, Stefano Ermon, Christopher D Manning, and Chelsea Finn. Direct preference optimization: Your language model is secretly a reward model. arXiv preprint arXiv:2305.18290, 2023.
[222] Mohammad Gheshlaghi Azar, Zhaohan Daniel Guo, Bilal Piot, Remi Munos, Mark Rowland, Michal Valko, and Daniele Calandriello. A general theoretical paradigm to understand learning from human preferences. In International Conference on Artificial Intelligence and Statistics, pages 4447-4455. PMLR, 2024.
[223] Kawin Ethayarajh, Winnie Xu, Niklas Muennighoff, Dan Jurafsky, and Douwe Kiela. Kto: Model alignment as prospect theoretic optimization. arXiv preprint arXiv:2402.01306, 2024.
[224] Yongcheng Zeng, Guoqing Liu, Weiyu Ma, Ning Yang, Haifeng Zhang, and Jun Wang. Tokenlevel direct preference optimization. arXiv preprint arXiv:2404.11999, 2024.
[225] Yu Meng, Mengzhou Xia, and Danqi Chen. Simpo: Simple preference optimization with a reference-free reward. arXiv preprint arXiv:2405.14734, 2024.
[226] Jiwoo Hong, Noah Lee, and James Thorne. Orpo: Monolithic preference optimization without reference model. In Proceedings of the 2024 Conference on Empirical Methods in Natural Language Processing, pages 11170-11189, 2024.
[227] Xidong Feng, Ziyu Wan, Muning Wen, Stephen Marcus McAleer, Ying Wen, Weinan Zhang, and Jun Wang. Alphazero- like tree-search can guide large language model decoding and training. arXiv preprint arXiv:2309.17179, 2023.
[228] Dan Zhang, Sining Zhoubian, Ziniu Hu, Yisong Yue, Yuxiao Dong, and Jie Tang. Rest-mcts*: Llm self-training via process reward guided tree search. arXiv preprint arXiv:2406.03816, 2024.
[229] David Silver, Aja Huang, Chris J Maddison, Arthur Guez, Laurent Sifre, George Van Den Driessche, Julian Schrit- twieser, Ioannis Antonoglou, Veda Panneershelvam, Marc Lanctot, et al. Mastering the game of go with deep neural networks and tree search. nature, 529(7587):484-489, 2016.
[230] Maciej Besta, Nils Blach, Ales Kubicek, Robert Gerstenberger, Michal Podstawski, Lukas Gianinazzi, Joanna Gajda, Tomasz Lehmann, Hubert Niewiadomski, Piotr Nyczyk, et al. Graph of thoughts: Solving elaborate problems with large language models. In Proceedings of the AAAI Conference on Artificial Intelligence, pages 17682-17690, 2024.
[231] Yadong Zhang, Shaoguang Mao, Tao Ge, Xun Wang, Adrian de Wynter, Yan Xia, Wenshan Wu, Ting Song, Man Lan, and Furu Wei. Llm as a mastermind: A survey of strategic reasoning with large language models. arXiv preprint arXiv:2404.01230, 2024.
[232] Wenyue Hua, Ollie Liu, Lingyao Li, Alfonso Amayuelas, Julie Chen, Lucas Jiang, Mingyu Jin, Lizhou Fan, Fei Sun, William Wang, et al. Game-theoretic llm: Agent workflow for negotiation games. arXiv preprint arXiv:2411.05990, 2024.
[233] Zongyuan Li, Yanan Ni, Runnan Qi, Lumin Jiang, Chang Lu, Xiaojie Xu, Xiangbei Liu, Pengfei Li, Yunzheng Guo, Zhe Ma, et al. Llm-pysc2: Starcraft ii learning environment for large language models. arXiv preprint arXiv:2411.05348, 2024.
[234] Muhammad Junaid Khan and Gita Sukthankar. Sc-phi2: A fine-tuned small language model for starcraft ii macroman- agement tasks. arXiv preprint arXiv:2409.18989, 2024.
[235] Weiyu Ma, Qirui Mi, Yongcheng Zeng, Xue Yan, Yuqiao Wu, Runji Lin, Haifeng Zhang, and Jun Wang. Large language models play starcraft ii: Benchmarks and a chain of summarization approach. arXiv preprint arXiv:2312.11865, 2023.
[236] Xuanfa Jin, Ziyan Wang, Yali Du, Meng Fang, Haifeng Zhang, and Jun Wang. Learning to discuss strategically: A case study on one night ultimate werewolf. arXiv preprint arXiv:2405.19946, 2024.
[237] Suma Bailis, Jane Friedhoff, and Feiyang Chen. Werewolf arena: A case study in llm evaluation via social deduction. arXiv preprint arXiv:2407.13943, 2024.
[238] Ayato Kitadai, Sinndy Dayana Rico Lugo, Yudai Tsurusaki, Yusuke Fukasawa, and Nariaki Nishino. Can ai with high reasoning ability replicate human-like decision making in economic experiments? arXiv preprint arXiv:2406.11426, 2024.
[239] Eilam Shapira, Omer Madmon, Itamar Reinman, Samuel Joseph Amouyal, Roi Reichart, and Moshe Tennenholtz. Glee: A unified framework and benchmark for language-based economic environments. arXiv preprint arXiv:2410.05254, 2024.
[240] Danny Driess, Fei Xia, Mehdi SM Sajjadi, Corey Lynch, Aakanksha Chowdhery, Brian Ichter, Ayzaan Wahid, Jonathan Tompson, Quan Vuong, Tianhe Yu, et al. Palm-e: An embodied multimodal language model. arXiv preprint arXiv:2303.03378, 2023.
[241] Tsun-Hsuan Wang, Alaa Maalouf, Wei Xiao, Yutong Ban, Alexander Amini, Guy Rosman, Sertac Karaman, and Daniela Rus. Drive anywhere: Generalizable end-to-end autonomous driving with multi-modal foundation models. In 2024 IEEE International Conference on Robotics and Automation (ICRA), pages 6687-6694. IEEE, 2024.
[242] Roya Firoozi, Johnathan Tucker, Stephen Tian, Anirudha Majumdar, Jiankai Sun, Weiyu Liu, Yuke Zhu, Shuran Song, Ashish Kapoor, Karol Hausman, et al. Foundation models in robotics: Applications, challenges, and the future. The International Journal of Robotics Research, page 02783649241281508, 2023.
[243] Lili Fan, Yutong Wang, Hui Zhang, Changxian Zeng, Yunjie Li, Chao Gou, and Hui Yu. Multimodal perception and decision-making systems for complex roads based on foundation models. IEEE Transactions on Systems, Man, and Cybernetics: Systems, 2024.
[244] Guanzhi Wang, Yuqi Xie, Yunfan Jiang, Ajay Mandlekar, Chaowei Xiao, Yuke Zhu, Linxi Fan, and Anima Anandkumar. Voyager: An open-ended embodied agent with large language models. arXiv preprint arXiv:2305.16291, 2023.
[245] Xizhou Zhu, Yuntao Chen, Hao Tian, Chenxin Tao, Weijie Su, Chenyu Yang, Gao Huang, Bin Li, Lewei Lu, Xiaogang Wang, et al. Ghost in the minecraft: Generally capable agents for open-world environments via large language models with text-based knowledge and memory. arXiv preprint arXiv:2305.17144, 2023.
[246] Sudha Rao, Weijia Xu, Michael Xu, Jorge Leandro, Ken Lobb, Gabriel DesGarennes, Chris Brockett, and Bill Dolan. Collaborative quest completion with llm-driven non-player characters in minecraft. arXiv preprint arXiv:2407.03460, 2024.
[247] Parsa Hejabi, Elnaz Rahmati, Alireza S Ziabari, Preni Golazizian, Jesse Thomason, and Morteza Dehghani. Evaluating creativity and deception in large language models: A simulation framework for multi-agent balderdash. arXiv preprint arXiv:2411.10422, 2024.
[248] Haochuan Wang, Xiachong Feng, Lei Li, Zhanyue Qin, Dianbo Sui, and Lingpeng Kong. Tmgbench: A systematic game benchmark for evaluating strategic reasoning abilities of llms. arXiv preprint arXiv:2410.10479, 2024.
[249] Yizhe Huang, Xingbo Wang, Hao Liu, Fanqi Kong, Aoyang Qin, Min Tang, Xiaoxi Wang, SongChun Zhu, Mingjie Bi, Siyuan Qi, et al. Adasociety: An adaptive environment with social structures for multi-agent decision-making. arXiv preprint arXiv:2411.03865, 2024.
[250] Zhiqiang Xie, Hao Kang, Ying Sheng, Tushar Krishna, Kayvon Fatahalian, and Christos Kozyrakis. Ai metropo- lis: Scaling large language model-based multi-agent simulation with out-of-order execution. arXiv preprint arXiv:2411.03519, 2024.
[251] Aviral Kumar, Justin Fu, Matthew Soh, George Tucker, and Sergey Levine. Stabilizing off-policy q-learning via boot- strapping error reduction. Advances in neural information processing systems, 32, 2019.
[252] Hoang Le, Cameron Voloshin, and Yisong Yue. Batch policy learning under constraints. In International Conference on Machine Learning, pages 3703-3712. PMLR, 2019.
[253] Aviral Kumar, Aurick Zhou, George Tucker, and Sergey Levine. Conservative q-learning for offline reinforcement learning. Advances in Neural Information Processing Systems, 33:11791191, 2020.
[254] Ilya Kostrikov, Ashvin Nair, and Sergey Levine. Offline reinforcement learning with implicit qlearning. arXiv preprint arXiv:2110.06169, 2021.
[255] Lili Chen, Kevin Lu, Aravind Rajeswaran, Kimin Lee, Aditya Grover, Misha Laskin, Pieter Abbeel, Aravind Srini- vas, and Igor Mordatch. Decision transformer: Reinforcement learning via sequence modeling. Advances in neural information processing systems, 34:15084-15097, 2021.
[256] Zhendong Wang, Jonathan J Hunt, and Mingyuan Zhou. Diffusion policies as an expressive policy class for offline reinforcement learning. arXiv preprint arXiv:2208.06193, 2022.
[257] Yixiu Mao, Hongchang Zhang, Chen Chen, Yi Xu, and Xiangyang Ji. Supported value regularization for offline rein- forcement learning. Advances in Neural Information Processing Systems, 36, 2024.
[258] Yixiu Mao, Cheems Wang, Chen Chen, Yun Qu, and Xiangyang Ji. Offline reinforcement learning with ood state correction and ood action suppression. arXiv preprint arXiv:2410.19400, 2024.
[259] Yixiu Mao, Qi Wang, Yun Qu, Yuhang Jiang, and Xiangyang Ji. Doubly mild generalization for offline reinforcement learning. arXiv preprint arXiv:2411.07934, 2024.
[260] Justin Fu, Aviral Kumar, Ofir Nachum, George Tucker, and Sergey Levine. D4rl: Datasets for deep data-driven rein- forcement learning. arXiv preprint arXiv:2004.07219, 2020.
[261] Jaesik Yoon, Taesup Kim, Ousmane Dia, Sungwoong Kim, Yoshua Bengio, and Sungjin Ahn. Bayesian model-agnostic meta-learning. Advances in neural information processing systems, 31, 2018.
[262] Kate Rakelly, Aurick Zhou, Chelsea Finn, Sergey Levine, and Deirdre Quillen. Efficient off-policy meta-reinforcement learning via probabilistic context variables. In International conference on machine learning, pages 5331-5340. PMLR, 2019.
[263] Qi Wang and Herke Van Hoof. Learning expressive meta-representations with mixture of expert neural processes. Advances in neural information processing systems, 35:26242-26255, 2022.
[264] Luisa Zintgraf, Kyriacos Shiarlis, Maximilian Igl, Sebastian Schulze, Yarin Gal, Katja Hofmann, and Shimon Whiteson. Varibad: A very good method for bayes-adaptive deep rl via meta-learning. arXiv preprint arXiv:1910.08348, 2019.
[265] Thomas G Dietterich. Hierarchical reinforcement learning with the max q-value function decomposition. Journal of artificial intelligence research, 13:227-303, 2000.
[266] Tejas D Kulkarni, Karthik Narasimhan, Ardavan Saeedi, and Josh Tenenbaum. Hierarchical deep reinforcement learn- ing: Integrating temporal abstraction and intrinsic motivation. Advances in neural information processing systems, 29, 2016.
[267] Yun Qu, Boyuan Wang, Jianzhun Shao, Yuhang Jiang, Chen Chen, Zhenbin Ye, Liu Linc, Yang Feng, Lin Lai, Hongyang Qin, et al. Hokoff: real game dataset from honor of kings and its offline reinforcement learning bench- marks. Advances in Neural Information Processing Systems, 36, 2024.
[268] Dong Chen, Kaian Chen, Zhaojian Li, Tianshu Chu, Rui Yao, Feng Qiu, and Kaixiang Lin. Powernet: Multi-agent deep reinforcement learning for scalable powergrid control. IEEE Transactions on Power Systems, 37(2):1007-1017, 2021.
[269] Jiawei Dong, Abdulsalam Yassine, Andy Armitage, and M Shamim Hossain. Multi-agent reinforcement learning for intelligent v2g integration in future transportation systems. IEEE Transactions on Intelligent Transportation Systems, 2023.
[270] Kaiqing Zhang, Zhuoran Yang, Han Liu, Tong Zhang, and Tamer Basar. Fully decentralized multiagent reinforcement learning with networked agents. In International conference on machine learning, pages 5872-5881. PMLR, 2018.
[271] Peter Sunehag, Guy Lever, Audrunas Gruslys, Wojciech Marian Czarnecki, Vinicius Zambaldi, Max Jaderberg, Marc Lanctot, Nicolas Sonnerat, Joel Z Leibo, Karl Tuyls, et al. Valuedecomposition networks for cooperative multi-agent learning. arXiv preprint arXiv:1706.05296, 2017.
[272] Tabish Rashid, Mikayel Samvelyan, Christian Schroeder De Witt, Gregory Farquhar, Jakob Foerster, and Shimon Whiteson. Monotonic value function factorisation for deep multi-agent reinforcement learning. Journal of Machine Learning Research, 21(178):1-51, 2020.
[273] Shengchao Hu, Li Shen, Ya Zhang, and Dacheng Tao. Communication learning in multi-agent systems from graph modeling perspective. arXiv preprint arXiv:2411.00382, 2024.
[274] Eloi Alonso, Adam Jelley, Vincent Micheli, Anssi Kanervisto, Amos Storkey, Tim Pearce, and Franc, ois Fleuret. Diffu- sion for world modeling: Visual details matter in atari. arXiv preprint arXiv:2405.12399, 2024.
[275] Yun Qu, Boyuan Wang, Yuhang Jiang, Jianzhun Shao, Yixiu Mao, Cheems Wang, Chang Liu, and Xiangyang Ji. Choices are more important than efforts: Llm enables efficient multi-agent exploration. arXiv preprint arXiv:2410.02511, 2024.
[276] Yun Qu, Yuhang Jiang, Boyuan Wang, Yixiu Mao, Cheems Wang, Chang Liu, and Xiangyang Ji. Latent reward: Llm-empowered credit assignment in episodic reinforcement learning. arXiv preprint arXiv:2412.11120, 2024.
[277] Yecheng Jason Ma, Joey Hejna, Ayzaan Wahid, Chuyuan Fu, Dhruv Shah, Jacky Liang, Zhuo Xu, Sean Kirmani, Peng Xu, Danny Driess, et al. Vision language models are in-context value learners. arXiv preprint arXiv:2411.04549, 2024.
[278] Vincent Lim, Huang Huang, Lawrence Yunliang Chen, Jonathan Wang, Jeffrey Ichnowski, Daniel Seita, Michael Laskey, and Ken Goldberg. Real2sim2real: Self-supervised learning of physical single-step dynamic actions for planar robot casting. In 2022 International Conference on Robotics and Automation (ICRA), pages 8282-8289. IEEE, 2022.
[279] Ajay Mandlekar, Danfei Xu, Josiah Wong, Soroush Nasiriany, Chen Wang, Rohun Kulkarni, Li Fei-Fei, Silvio Savarese, Yuke Zhu, and Roberto Mart'ın-Mart'ın. What matters in learning from offline human demonstrations for robot manipu- lation. arXiv preprint arXiv:2108.03298, 2021.
[280] Michael Bain and Claude Sammut. A framework for behavioural cloning. In Machine Intelligence 15, pages 103-129, 1995.
[281] Brianna Zitkovich, Tianhe Yu, Sichun Xu, Peng Xu, Ted Xiao, Fei Xia, Jialin Wu, Paul Wohlhart, Stefan Welker, Ayzaan Wahid, et al. Rt-2: Vision-language-action models transfer web knowledge to robotic control. In Conference on Robot Learning, pages 2165-2183. PMLR, 2023.
[282] Yilun Du, Sherry Yang, Bo Dai, Hanjun Dai, Ofir Nachum, Josh Tenenbaum, Dale Schuurmans, and Pieter Abbeel. Learning universal policies via text-guided video generation. Advances in Neural Information Processing Systems, 36, 2024.
[283] Moo Jin Kim, Karl Pertsch, Siddharth Karamcheti, Ted Xiao, Ashwin Balakrishna, Suraj Nair, Rafael Rafailov, Ethan Foster, Grace Lam, Pannag Sanketi, et al. Openvla: An open-source vision-language-action model. arXiv preprint arXiv:2406.09246, 2024.
[284] Jake Bruce, Michael D Dennis, Ashley Edwards, Jack Parker-Holder, Yuge Shi, Edward Hughes, Matthew Lai, Aditi Mavalankar, Richie Steigerwald, Chris Apps, et al. Genie: Generative interactive environments. In Forty-first Interna- tional Conference on Machine Learning, 2024.
[285] Robert McCarthy, Daniel CH Tan, Dominik Schmidt, Fernando Acero, Nathan Herr, Yilun Du, Thomas G Thuruthel, and Zhibin Li. Towards generalist robot learning from internet video: A survey. arXiv preprint arXiv:2404.19664, 2024.
[286] Qi Wang, Yanghe Feng, Jincai Huang, Yiqin Lv, Zheng Xie, and Xiaoshan Gao. Large-scale generative simulation artificial intelligence: The next hotspot. The Innovation, 4(6), 2023.
[287] Yufei Wang, Zhou Xian, Feng Chen, Tsun-Hsuan Wang, Yian Wang, Katerina Fragkiadaki, Zackory Erickson, David Held, and Chuang Gan. Robogen: Towards unleashing infinite data for automated robot learning via generative simu- lation. In Forty-first International Conference on Machine Learning, 2024.
[288] Yunsong Zhou, Michael Simon, Zhenghao Peng, Sicheng Mo, Hongzi Zhu, Minyi Guo, and Bolei Zhou. Simgen: Simulator-conditioned driving scene generation. arXiv preprint arXiv:2406.09386, 2024.
[289] Jenny Zhang, Joel Lehman, Kenneth Stanley, and Jeff Clune. Omni: Open-endedness via models of human notions of interestingness. In The Twelfth International Conference on Learning Representations, 2023.
[290] Maxence Faldor, Jenny Zhang, Antoine Cully, and Jeff Clune. Omni-epic: Open-endedness via models of human notions of interestingness with environments programmed in code. arXiv preprint arXiv:2405.15568, 2024.
[291] Abhishek Kadian, Joanne Truong, Aaron Gokaslan, Alexander Clegg, Erik Wijmans, Stefan Lee, Manolis Savva, Sonia Chernova, and Dhruv Batra. Sim2real predictivity: Does evaluation in simulation predict real-world performance? IEEE Robotics and Automation Letters, 5(4):66706677, 2020.
[292] Lilian Weng. Llm-powered autonomous agents. lilianweng.github.io, Jun 2023.
[293] Kevin J. Lang, Alex Waibel, and Geoffrey E. Hinton. A time-delay neural network architecture for isolated word recognition. Neural Networks, 3(1):23-43, 1990.
[294] Jeffrey L. Elman. Finding structure in time. Cogn. Sci., 14(2):179-211, 1990.
[295] Ronald J. Williams and David Zipser. A learning algorithm for continually running fully recurrent neural networks. Neural Comput., 1(2):270-280, 1989.
[296] Sepp Hochreiter and Jürgen Schmidhuber. Long short-term memory. Neural Comput., 9(8):17351780, 1997.
[297] Anthony J Robinson and Frank Fallside. The utility driven dynamic error propagation network, volume 11. University of Cambridge Department of Engineering Cambridge, 1987.
[298] C. Lee Giles, Clifford B. Miller, Dong Chen, Hsing-Hen Chen, Guo-Zheng Sun, and Yee-Chun Lee. Learning and extracting finite state automata with second-order recurrent neural networks. Neural Comput., 4(3):393-405, 1992.
[299] Ilya Sutskever, Oriol Vinyals, and Quoc V. Le. Sequence to sequence learning with neural networks. In Zoubin Ghahramani, Max Welling, Corinna Cortes, Neil D. Lawrence, and Kilian Q. Weinberger, editors, Advances in Neural Information Processing Systems 27: Annual Conference on Neural Information Processing Systems 2014, December 8-13 2014, Montreal, Quebec, Canada, pages 3104-3112, 2014.
[300] Sainbayar Sukhbaatar, Arthur Szlam, Jason Weston, and Rob Fergus. End-to-end memory networks. In Corinna Cortes, Neil D. Lawrence, Daniel D. Lee, Masashi Sugiyama, and Roman Garnett, editors, Advances in Neural Information Processing Systems 28: Annual Conference on Neural Information Processing Systems 2015, December 7-12, 2015, Montreal, Quebec, Canada, pages 2440-2448, 2015.
[301] Dzmitry Bahdanau, Kyunghyun Cho, and Yoshua Bengio. Neural machine translation by jointly learning to align and translate. In Yoshua Bengio and Yann LeCun, editors, 3rd International Conference on Learning Representations, ICLR 2015, San Diego, CA, USA, May 7-9, 2015, Conference Track Proceedings, 2015.
[302] Johan Westo", Patrick J. C. May, and Hannu Tiitinen. Memory stacking in hierarchical networks. Neural Comput., 28(2):327-353, 2016.
[303] Jason Weston. Memory networks for recommendation. In Paolo Cremonesi, Francesco Ricci, Shlomo Berkovsky, and Alexander Tuzhilin, editors, Proceedings of the Eleventh ACM Conference on Recommender Systems, RecSys 2017, Como, Italy, August 27-31, 2017, page 4. ACM, 2017.
[304] Jack W. Rae, Anna Potapenko, Siddhant M. Jayakumar, Chloe Hillier, and Timothy P. Lillicrap. Compressive trans- formers for long-range sequence modelling. In 8th International Conference on Learning Representations, ICLR 2020, Addis Ababa, Ethiopia, April 26-30, 2020. OpenReview.net, 2020.
[305] Zihang Dai, Zhilin Yang, Yiming Yang, Jaime G. Carbonell, Quoc Viet Le, and Ruslan Salakhutdinov. Transformer-xl: Attentive language models beyond a fixed-length context. In Anna Korhonen, David R. Traum, and Llu'is Ma`rquez, editors, Proceedings of the 57th Conference of the Association for Computational Linguistics, ACL 2019, Florence, Italy, July 28-August 2, 2019, Volume 1: Long Papers, pages 2978-2988. Association for Computational Linguistics, 2019.
[306] David R. So, Quoc V. Le, and Chen Liang. The evolved transformer. In Kamalika Chaudhuri and Ruslan Salakhutdinov, editors, Proceedings of the 36th International Conference on Machine Learning, ICML 2019, 9-15 June 2019, Long Beach, California, USA, volume 97 of Proceedings of Machine Learning Research, pages 5877-5886. PMLR, 2019.
[307] Mostafa Dehghani, Stephan Gouws, Oriol Vinyals, Jakob Uszkoreit, and Lukasz Kaiser. Universal transformers. In 7th International Conference on Learning Representations, ICLR 2019, New Orleans, LA, USA, May 6-9, 2019. OpenRe- view.net, 2019.
[308] Patrick S. H. Lewis, Ethan Perez, Aleksandra Piktus, Fabio Petroni, Vladimir Karpukhin, Naman Goyal, Heinrich Ku"ttler, Mike Lewis, Wen-tau Yih, Tim Rockta"schel, Sebastian Riedel, and Douwe Kiela. Retrieval-augmented gen- eration for knowledge-intensive NLP tasks. In Hugo Larochelle, Marc'Aurelio Ranzato, Raia Hadsell, Maria-Florina Balcan, and Hsuan-Tien Lin, editors, Advances in Neural Information Processing Systems 33: Annual Conference on Neural Information Processing Systems 2020, NeurIPS 2020, December 6-12, 2020, virtual, 2020.
[309] Albert Gu and Tri Dao. Mamba: Linear-time sequence modeling with selective state spaces. CoRR, abs/2312.00752, 2023.
[310] Earl D. Sacerdoti. The nonlinear nature of plans. In Advance Papers of the Fourth International Joint Conference on Artificial Intelligence, Tbilisi, Georgia, USSR, September 3-8, 1975, pages 206-214, 1975.
[311] Peter E. Hart, Nils J. Nilsson, and Bertram Raphael. A formal basis for the heuristic determination of minimum cost paths. IEEE Trans. Syst. Sci. Cybern., 4(2):100-107, 1968.
[312] Richard Fikes and Nils J. Nilsson. STRIPS: A new approach to the application of theorem proving to problem solving. In D. C. Cooper, editor, Proceedings of the 2nd International Joint Conference on Artificial Intelligence. London, UK, September 1-3, 1971, pages 608-620. William Kaufmann, 1971.
[313] David Ha and Jürgen Schmidhuber. World models. CoRR, abs/1803.10122, 2018.
[314] Jacob Andreas, Marcus Rohrbach, Trevor Darrell, and Dan Klein. Neural module networks. In Proceedings of the IEEE conference on computer vision and pattern recognition, pages 39-48, 2016.
[315] Scott E. Reed and Nando de Freitas. Neural programmer-interpreters. In Yoshua Bengio and Yann LeCun, editors, 4th International Conference on Learning Representations, ICLR 2016, San Juan, Puerto Rico, May 2-4, 2016, Conference Track Proceedings, 2016.
[316] Timo Schick, Jane Dwivedi-Yu, Roberto Dess`1, Roberta Raileanu, Maria Lomeli, Eric Hambro, Luke Zettlemoyer, Nicola Cancedda, and Thomas Scialom. Toolformer: Language models can teach themselves to use tools. In Alice Oh, Tristan Naumann, Amir Globerson, Kate Saenko, Moritz Hardt, and Sergey Levine, editors, Advances in Neural Information Processing Systems 36: Annual Conference on Neural Information Processing Systems 2023, NeurIPS 2023, New Orleans, LA, USA, December 10-16, 2023, 2023.
[317] Yujia Qin, Shihao Liang, Yining Ye, Kunlun Zhu, Lan Yan, Yaxi Lu, Yankai Lin, Xin Cong, Xiangru Tang, Bill Qian, Sihan Zhao, Lauren Hong, Runchu Tian, Ruobing Xie, Jie Zhou, Mark Gerstein, Dahai Li, Zhiyuan Liu, and Maosong Sun. Toolllm: Facilitating large language models to master 16000+ real-world apis. In The Twelfth International Conference on Learning Representations, ICLR 2024, Vienna, Austria, May 7-11, 2024. OpenReview.net, 2024.
[318] Zhiyong Wu, Chengcheng Han, Zichen Ding, Zhenmin Weng, Zhoumianze Liu, Shunyu Yao, Tao Yu, and Lingpeng Kong. Os-copilot: Towards generalist computer agents with self-improvement. CoRR, abs/2402.07456, 2024.
[319] Shunyu Yao, Jeffrey Zhao, Dian Yu, Nan Du, Izhak Shafran, Karthik R. Narasimhan, and Yuan Cao. React: Synergizing reasoning and acting in language models. In The Eleventh International Conference on Learning Representations, ICLR 2023, Kigali, Rwanda, May 1-5, 2023. OpenReview.net, 2023.
好的,这是从[320]开始继续整理的参考文献格式:
[320] Shuofei Qiao, Runnan Fang, Ningyu Zhang, Yuqi Zhu, Xiang Chen, Shumin Deng, Yong Jiang, Pengjun Xie, Fei Huang, and Huajun Chen. Agent planning with world knowledge model. CoRR, abs/2405.14205, 2024.
[321] Guanzhi Wang, Yuqi Xie, Yunfan Jiang, Ajay Mandlekar, Chaowei Xiao, Yuke Zhu, Linxi Fan, and Anima Anandkumar. Voyager: An open-ended embodied agent with large language models. Trans. Mach. Learn. Res., 2024, 2024.
[322] Huandong Wang, Huan Yan, Can Rong, Yuan Yuan, Fenyu Jiang, Zhenyu Han, Hongjie Sui, Depeng Jin, and Yong Li. Multi-scale simulation of complex systems: a perspective of integrating knowledge and data. ACM Computing Surveys, 56(12):1-38, 2024.
[323] Mohamed Amine Ben Rabia and Adil Bellabdaoui. Simulation-based analytics: A systematic literature review. Simu- lation Modelling Practice and Theory, 117:102511, 2022.
[324] Bin Chen, Runkang Guo, Zhengqiu Zhu, Yong Zhao, Yatai Ji, Aiguo Chen, and Guangquan Cheng. A novel research pattern for the simulation of complex systems sigd. Journal of System Simulation, 36(12):2993, 2024.
[325] Xiao Xue, Xiangning Yu, and Fei-Yue Wang. Chatgpt chats on computational experiments: From interactive intelli- gence to imaginative intelligence for design of artificial societies and optimization of foundational models. IEEE/CAA Journal of Automatica Sinica, 10(6):1357-1360, 2023.
[326] Yong Zhao, Zhengqiu Zhu, Bin Chen, Sihang Qiu, Jincai Huang, Xin Lu, Weiyi Yang, Chuan Ai, Kuihua Huang, Cheng He, et al. Towards parallel intelligence: An interdisciplinary solution for complex systems. The Innovation, 2023.
[327] Tianyuan Dai, Josiah Wong, Yunfan Jiang, Chen Wang, Cem Gokmen, Ruohan Zhang, Jiajun Wu, and Li Fei-Fei. Automated creation of digital cousins for robust policy learning. arXiv preprint arXiv:2410.07408, 2024.
[328] Thomas Allen. Us department of defense modeling and simulation: new approaches and initiatives. Information & Security an International Journal, 23(23):32-48, 2009.
[329] Xinyi Mou, Xuanwen Ding, Qi He, Liang Wang, Jingcong Liang, Xinnong Zhang, Libo Sun, Jiayu Lin, Jie Zhou, Xuanjing Huang, et al. From individual to society: A survey on social simulation driven by large language model-based agents. arXiv preprint arXiv:2412.03563, 2024.
[330] Alexander Lavin, David Krakauer, Hector Zenil, Justin Gottschlich, Tim Mattson, Johann Brehmer, Anima Anandku- mar, Sanjay Choudry, Kamil Rocki, Atılım Gu"nes, Baydin, et al. Simulation intelligence: Towards a new generation of scientific methods. arXiv preprint arXiv:2112.03235, 2021.
[331] Lin Wu, Lizhe Wang, Nan Li, Tao Sun, Tangwen Qian, Yu Jiang, Fei Wang, and Yongjun Xu. Modeling the covid-19 outbreak in china through multi-source information fusion. The Innovation, 1(2), 2020.
[332] Zhengqiu Zhu, Bin Chen, Hailiang Chen, Sihang Qiu, Changjun Fan, Yong Zhao, Runkang Guo, Chuan Ai, Zhong Liu, Zhiming Zhao, et al. Strategy evaluation and optimization with an artificial society toward a pareto optimum. The Innovation, 3(5), 2022.
[333] Bin Chen, Runkang Guo, Zhengqiu Zhu, Chuan Ai, and Xiaogang Qiu. Simulation of covid-19 outbreak in nanjing lukou airport based on complex dynamical networks. Complex System Modeling and Simulation, 3(1):71-82, 2023.
[334] Aleksei Petrenko, Erik Wijmans, Brennan Shacklett, and Vladlen Koltun. Megaverse: Simulating embodied agents at one million experiences per second. In International Conference on Machine Learning, pages 8556-8566. PMLR, 2021.
[335] Yandan Yang, Baoxiong Jia, Peiyuan Zhi, and Siyuan Huang. Physcene: Physically interactable 3d scene synthesis for embodied ai. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pages 16262-16272, 2024.
[336] Marcelo Jacinto, Joa~o Pinto, Jay Patrikar, John Keller, Rita Cunha, Sebastian Scherer, and António Pascoal. Pega- sus simulator: An isaac sim framework for multiple aerial vehicles simulation. In 2024 International Conference on Unmanned Aircraft Systems (ICUAS), pages 917922. IEEE, 2024.
[337] Kanishka Rao, Chris Harris, Alex Irpan, Sergey Levine, Julian Ibarz, and Mohi Khansari. Rlcyclegan: Reinforce- ment learning aware simulation-to-real. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pages 11157-11166, 2020.
[338] Kaiqu Liang, Haimin Hu, Ryan Liu, Thomas L Griffiths, and Jaime Ferna'ndez Fisac. Rlhs: Mitigating misalignment in rlhf with hindsight simulation. arXiv preprint arXiv:2501.08617, 2025.
[339] Jason Wei, Yi Tay, Rishi Bommasani, Colin Raffel, Barret Zoph, Sebastian Borgeaud, Dani Yogatama, Maarten Bosma, Denny Zhou, Donald Metzler, et al. Emergent abilities of large language models. arXiv preprint arXiv:2206.07682, 2022.
[340] Anthony Brohan, Noah Brown, Justice Carbajal, Yevgen Chebotar, Joseph Dabis, Chelsea Finn, Keerthana Gopalakr- ishnan, Karol Hausman, Alex Herzog, Jasmine Hsu, et al. Rt-1: Robotics transformer for real-world control at scale. arXiv preprint arXiv:2212.06817, 2022.
[341] Trevor Strohman, Donald Metzler, Howard Turtle, and W Bruce Croft. Indri: A language modelbased search engine for complex queries. In Proceedings of the international conference on intelligent analysis, pages 2-6. Washington, DC., 2005.
[342] David Silver, Thomas Hubert, Julian Schrittwieser, Ioannis Antonoglou, Matthew Lai, Arthur Guez, Marc Lanctot, Laurent Sifre, Dharshan Kumaran, Thore Graepel, et al. Mastering chess and shogi by self-play with a general rein- forcement learning algorithm. arXiv preprint arXiv:1712.01815, 2017.
[343] Gerald Tesauro. Td-gammon, a self-teaching backgammon program, achieves master-level play. Neural computation, 6(2):215-219, 1994.
[344] Dmitry Kalashnikov, Alex Irpan, Peter Pastor, Julian Ibarz, Alexander Herzog, Eric Jang, Deirdre Quillen, Ethan Holly, Mrinal Kalakrishnan, Vincent Vanhoucke, et al. Scalable deep reinforcement learning for vision-based robotic manip- ulation. In Conference on robot learning, pages 651-673. PMLR, 2018.
[345] Ilge Akkaya, Marcin Andrychowicz, Maciek Chociej, Mateusz Litwin, Bob McGrew, Arthur Petron, Alex Paino, Matthias Plappert, Glenn Powell, Raphael Ribas, et al. Solving rubik's cube with a robot hand. arXiv preprint arXiv:1910.07113, 2019.
[346] Jiankai Sun, De-An Huang, Bo Lu, Yun-Hui Liu, Bolei Zhou, and Animesh Garg. Plate: Visuallygrounded planning with transformers in procedural tasks. IEEE Robotics and Automation Letters, 7(2):4924-4930, 2022.
[347] Wenjie Liu, Jian Sun, Gang Wang, Francesco Bullo, and Jie Chen. Data-driven resilient predictive control under denial- of-service. IEEE Transactions on Automatic Control, 68(8):4722-4737, August 2023.
[348] Dingyuan Zhang, Dingkang Liang, Hongcheng Yang, Zhikang Zou, Xiaoqing Ye, Zhe Liu, and Xiang Bai. Sam3d: Zero-shot 3d object detection via segment anything model. arXiv preprint arXiv:2306.02245, 2023.
[349] Yining Hong, Haoyu Zhen, Peihao Chen, Shuhong Zheng, Yilun Du, Zhenfang Chen, and Chuang Gan. 3d-llm: Injecting the 3d world into large language models. Advances in Neural Information Processing Systems, 36:20482-20494, 2023.
[350] William Chen, Siyi Hu, Rajat Talak, and Luca Carlone. Leveraging large language models for robot 3d scene under- standing. arXiv preprint arXiv:2209.05629, 2022.
[351] Weipu Zhang, Gang Wang, Jian Sun, Yetian Yuan, and Gao Huang. STORM: Efficient stochastic transformer based world models for reinforcement learning. Advances in Neural Information Processing Systems, 36, 2024.
[352] Zhaohan Feng, Jie Chen, Wei Xiao, Jian Sun, Bin Xin, and Gang Wang. Learning hybrid policies for MPC with application to drone flight in unknown dynamic environments. Unmanned Systems, 12(02):429-441, 2024.
[353] Ziyu Zhou, Gang Wang, Jian Sun, Jikai Wang, and Jie Chen. Efficient and robust time-optimal trajectory planning and control for agile quadrotor flight. IEEE Robotics and Automation Letters, 8(12):7913-7920, December 2023.
[354] Yetian Yuan, Shuze Wang, Yunpeng Mei, Weipu Zhang, Jian Sun, and Gang Wang. Improving world models for robot arm grasping with backward dynamics prediction. International Journal of Machine Learning and Cybernetics, 15:3879-3891, April 2024.
[355] Yitao Jiang, Luyang Zhao, Alberto Quattrini Li, Muhao Chen, and Devin Balkcom. Exploring spontaneous social interaction swarm robotics powered by large language models.
[356] Zhao Mandi, Homanga Bharadhwaj, Vincent Moens, Shuran Song, Aravind Rajeswaran, and Vikash Kumar. Cacti: A framework for scalable multi-task multi-scene visual imitation learning. arXiv preprint arXiv:2212.05711, 2022.
[357] Norman Di Palo, Arunkumar Byravan, Leonard Hasenclever, Markus Wulfmeier, Nicolas Heess, and Martin Riedmiller. Towards a unified agent with foundation models. arXiv preprint arXiv:2307.09668, 2023.
[358] Minae Kwon, Sang Michael Xie, Kalesha Bullard, and Dorsa Sadigh. Reward design with language models. arXiv preprint arXiv:2303.00001, 2023.
[359] Yifan Du, Junyi Li, Tianyi Tang, Wayne Xin Zhao, and Ji-Rong Wen. Zero-shot visual question answering with language model feedback. arXiv preprint arXiv:2305.17006, 2023.
[360] Ramdane Tami, Boussaad Soualmi, Abdelkrim Doufene, Javier Ibanez, and Justin Dauwels. Machine learning method to ensure robust decision-making of avs. In 2019 IEEE Intelligent Transportation Systems Conference (ITSC), pages 1217-1222. IEEE, 2019.
[361] Shengxi Gui, Shuang Song, Rongjun Qin, and Yang Tang. Remote sensing object detection in the deep learning era—a review. Remote Sensing, 16(2):327, 2024.
[362] Ranganath R Navalgund, V Jayaraman, and PS Roy. Remote sensing applications: An overview. current science, pages 1747-1766, 2007.
[363] Philipe Dias, Abhishek Potnis, Sreelekha Guggilam, Lexie Yang, Aristeidis Tsaris, Henry Medeiros, and Dalton Lunga. An agenda for multimodal foundation models for earth observation. In IGARSS 2023-2023 IEEE International Geo- science and Remote Sensing Symposium, pages 1237-1240. IEEE, 2023.
[364] Yuchi Ma, Shuo Chen, Stefano Ermon, and David B Lobell. Transfer learning in environmental remote sensing. Remote Sensing of Environment, 301:113924, 2024.
[365] Yezhen Cong, Samar Khanna, Chenlin Meng, Patrick Liu, Erik Rozi, Yutong He, Marshall Burke, David Lobell, and Stefano Ermon. Satmae: Pre-training transformers for temporal and multispectral satellite imagery. Advances in Neural Information Processing Systems, 35:197-211, 2022.
[366] Colorado J Reed, Ritwik Gupta, Shufan Li, Sarah Brockman, Christopher Funk, Brian Clipp, Kurt Keutzer, Salvatore Candido, Matt Uyttendaele, and Trevor Darrell. Scale-mae: A scale-aware masked autoencoder for multiscale geospatial representation learning. In Proceedings of the IEEE/CVF International Conference on Computer Vision, pages 4088-4099, 2023.
[367] Xinye Wanyan, Sachith Seneviratne, Shuchang Shen, and Michael Kirley. Extending global-local view alignment for self-supervised learning with remote sensing imagery. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pages 2443-2453, 2024.
[368] Wade A. Smith and Robert B. Randall. Rolling element bearing diagnostics using the case western reserve university data: A benchmark study. Mechanical Systems and Signal Processing, 64-65:100-131, 2015.
[369] Yuma Koizumi, Shoichiro Saito, Hisashi Uematsu, Noboru Harada, and Keisuke Imoto. Toyadmos: A dataset of miniature-machine operating sounds for anomalous sound detection. In 2019 IEEE Workshop on Applications of Signal Processing to Audio and Acoustics (WASPAA), pages 313-317, 2019.
[370] Yunwei Zhang, Qiaochu Tang, Yao Zhang, Jiabin Wang, Ulrich Stimming, and Alpha Lee. Identifying degradation pat- terns of lithium ion batteries from impedance spectroscopy using machine learning. Nature Communications, 11:1706, 042020.
[371] Yinjiao Xing, Wei He, Michael Pecht, and Kwok Leung Tsui. State of charge estimation of lithiumion batteries using the open-circuit voltage at various ambient temperatures. Applied energy, 113:106-115, 2014.
[372] Erik Jakobsson, Erik Frisk, Mattias Krysander, and Robert Pettersson. A dataset for fault classification in rock drills, a fast oscillating hydraulic system. In Annual Conference of the PHM Society, 2022.
[373] Yuhong Jin, Lei Hou, and Yushu Chen. A time series transformer based method for the rotating machinery fault diagnosis. Neurocomputing, 494:379-395, 2022.
[374] Xiaohong Wang, Xudong Jiang, Henghui Ding, Yuqian Zhao, and Jun Liu. Knowledge-aware deep framework for collaborative skin lesion segmentation and melanoma recognition. Pattern Recognition, 120:108075, 2021.
[375] Qi Li, Jinfeng Huang, Hongliang He, Xinran Zhang, Feibin Zhang, Zhaoye Qin, and Fulei Chu. Vsllava: a pipeline of large multimodal foundation model for industrial vibration signal analysis, 2024.
[376] Arash Ajoudani, Andrea Maria Zanchettin, Serena Ivaldi, Alin Albu-Scha"ffer, Kazuhiro Kosuge, and Oussama Khatib. Progress and prospects of the human-robot collaboration. Autonomous Robots, 42, 062018.
[377] Maximilian Diehl, Chris Paxton, and Karinne Ramirez-Amaro. Automated generation of robotic planning domains from observations. In 2021 IEEE/RSJ International Conference on Intelligent Robots and Systems (IROS), pages 6732-6738, 2021.
[378] Keisuke Shirai, Cristian C. Beltran-Hernandez, Masashi Hamaya, Atsushi Hashimoto, Shohei Tanaka, Kento Kawa- harazuka, Kazutoshi Tanaka, Yoshitaka Ushiku, and Shinsuke Mori. Visionlanguage interpreter for robot task planning. In 2024 IEEE International Conference on Robotics and Automation (ICRA), pages 2051-2058, 2024.
[379] Meng-Lun Lee, Sara Behdad, Xiao Liang, and Minghui Zheng. Task allocation and planning for product disassembly with human-robot collaboration. Robotics and Computer-Integrated Manufacturing, 76:102306, 2022.
[380] Tian Yu, Jing Huang, and Qing Chang. Optimizing task scheduling in human-robot collaboration with deep multi-agent reinforcement learning. Journal of Manufacturing Systems, 60:487-499, 2021.
[381] Anthony Brohan, Noah Brown, Justice Carbajal, Yevgen Chebotar, Joseph Dabis, Chelsea Finn, Keerthana Gopalakrish- nan, Karol Hausman, Alex Herzog, Jasmine Hsu, Julian Ibarz, Brian Ichter, Alex Irpan, Tomas Jackson, Sally Jesmonth, Nikhil J Joshi, Ryan Julian, Dmitry Kalashnikov, Yuheng Kuang, Isabel Leal, Kuang-Huei Lee, Sergey Levine, Yao Lu, Utsav Malla, Deeksha Manjunath, Igor Mordatch, Ofir Nachum, Carolina Parada, Jodilyn Peralta, Emily Perez, Karl Pertsch, Jornell Quiambao, Kanishka Rao, Michael Ryoo, Grecia Salazar, Pannag Sanketi, Kevin Sayed, Jaspiar Singh, Sumedh Sontakke, Austin Stone, Clayton Tan, Huong Tran, Vincent Vanhoucke, Steve Vega, Quan Vuong, Fei Xia, Ted Xiao, Peng Xu, Sichun Xu, Tianhe Yu, and Brianna Zitkovich. Rt-1: Robotics transformer for real-world control at scale, 2023.
[382] Waleed Ejaz, Shree K. Sharma, Salman Saadat, Muhammad Naeem, Alagan Anpalagan, and N.A. Chughtai. A com- prehensive survey on resource allocation for cran in 5 g and beyond networks. Journal of Network and Computer Applications, 160:102638, 2020.
[383] Gerald Kelechi Ijemaru, Ibrahim Adeyanju, Kehinde Olusuyi, T Ofusori, E Ngharamike, and AA Sobowale. Security challenges of wireless communications networks: a survey. Int. J. Appl. Eng. Res, 13(8):5680-5692, 2018.
[384] Yifei Xu, Yuning Chen, Xumiao Zhang, Xianshang Lin, Pan Hu, Yunfei Ma, Songwu Lu, Wan Du, Zhuoqing Mao, Ennan Zhai, and Dennis Cai. Cloudeval-yaml: A practical benchmark for cloud configuration generation. In P. Gibbons, G. Pekhimenko, and C. De Sa, editors, Proceedings of Machine Learning and Systems, volume 6, pages 173-195, 2024.
[385] Zhengfu He, Tianxiang Sun, Kuanning Wang, Xuanjing Huang, and Xipeng Qiu. Diffusionbert: Improving generative masked language models with diffusion models, 2022.
[386] Rajdeep Mondal, Alan Tang, Ryan Beckett, Todd Millstein, and George Varghese. What do llms need to synthesize correct router configurations? In Proceedings of the 22nd ACM Workshop on Hot Topics in Networks, HotNets '23, page 189-195, New York, NY, USA, 2023. Association for Computing Machinery.
[387] Sathiya Kumaran Mani, Yajie Zhou, Kevin Hsieh, Santiago Segarra, Trevor Eberl, Eliran Azulai, Ido Frizler, Ranveer Chandra, and Srikanth Kandula. Enhancing network management using code generated by large language models. In Proceedings of the 22nd ACM Workshop on Hot Topics in Networks, HotNets '23, page 196-204, New York, NY, USA, 2023. Association for Computing Machinery.
[388] Markus Bayer, Philipp Kuehn, Ramin Shanehsaz, and Christian Reuter. Cysecbert: A domainadapted language model for the cybersecurity domain. ACM Transactions on Privacy and Security, 27(2):1-20, 2024.
[389] Ehsan Aghaei, Xi Niu, Waseem Shadid, and Ehab Al-Shaer. Securebert: A domain-specific language model for cy- bersecurity. In International Conference on Security and Privacy in Communication Systems, pages 39-56. Springer, 2022.
[390] Mohamed Amine Ferrag, Mthandazo Ndhlovu, Norbert Tihanyi, Lucas C Cordeiro, Merouane Debbah, Thierry Lestable, and Narinderjit Singh Thandi. Revolutionizing cyber threat detection with large language models: A privacy- preserving bert-based lightweight model for iot/iiot devices. IEEE Access, 2024.
[391] Luiz Rodrigues, Filipe Dwan Pereira, Luciano Cabral, Dragan Gas`evic', Geber Ramalho, and Rafael Ferreira Mello. As- sessing the quality of automatic-generated short answers using gpt-4. Computers and Education: Artificial Intelligence, 7:100248, 2024.
[392] Nan Wu, Jun Xu, Jinqing Linghu, and Jie Huang. Real-time optimal control and dispatching strategy of multi-microgrid energy based on storage collaborative. International Journal of Electrical Power & Energy Systems, 160:110063, 2024.
[393] L Huang. "big watt" to promote the application of power ai in the future., 2024.
[394] Tanveer Ahmad, Hongyu Zhu, Dongdong Zhang, Rasikh Tariq, A Bassam, Fasee Ullah, Ahmed S AlGhamdi, and Sultan S Alshamrani. Energetics systems and artificial intelligence: Applications of industry 4.0. Energy Reports, 8:334-361, 2022.
[395] Nils H van der Blij, Laura M Ramirez-Elizondo, Matthijs TJ Spaan, and Pavol Bauer. Grid sense multiple access: A decentralized control algorithm for dc grids. International Journal of Electrical Power & Energy Systems, 119:105818, 2020.
[396] Zohaib Jan, Farhad Ahamed, Wolfgang Mayer, Niki Patel, Georg Grossmann, Markus Stumptner, and Ana Kuusk. Artificial intelligence for industry 4.0: Systematic review of applications, challenges, and opportunities. Expert Systems with Applications, 216:119456, 2023.
[397] Tingting Chen, Vignesh Sampath, Marvin Carl May, Shuo Shan, Oliver Jonas Jorg, Juan Jose' Aguilar Mart'ın, Florian Stamer, Gualtiero Fantoni, Guido Tosello, and Matteo Calaon. Machine learning in manufacturing towards industry 4.0: From 'for now' to 'four-know'. Applied Sciences, 13(3), 2023.
[398] Senthil Kumar Jagatheesaperumal, Mohamed Rahouti, Kashif Ahmad, Ala Al-Fuqaha, and Mohsen Guizani. The duo of artificial intelligence and big data for industry 4.0: Applications, techniques, challenges, and future research directions. IEEE Internet of Things Journal, 9(15):12861-12885, 2022.
[399] National Research Council, Division on Engineering, Physical Sciences, Board on Mathematical Sciences, Their Ap- plications, Committee on Mathematical Foundations of Verification, and Uncertainty Quantification. Assessing the reliability of complex models: mathematical and statistical foundations of verification, validation, and uncertainty quantification. National Academies Press, 2012.
[400] Charu C Aggarwal, Lagerstrom-Fife Aggarwal, and Lagerstrom-Fife. Linear algebra and optimization for machine learning, volume 156. Springer, 2020.
[401] Guangchuang Yu. Thirteen years of clusterprofiler. The Innovation, 5(6), 2024.
[402] Iman Ahmadianfar, Omid Bozorg-Haddad, and Xuefeng Chu. Gradient-based optimizer: A new metaheuristic opti- mization algorithm. Information Sciences, 540:131-159, 2020.
[403] Haidong Li, Hongchuang Li, Ming Zhang, Chaolin Huang, and Xin Zhou. Direct imaging of pulmonary gas exchange with hyperpolarized xenon mri. The Innovation, 5(6), 2024.
[404] Matthias Seeger, Florian Steinke, and Koji Tsuda. Bayesian inference and optimal design in the sparse linear model. In Artificial Intelligence and Statistics, pages 444-451. PMLR, 2007.
[405] Kellie J Archer, Han Fu, Krzysztof Mro'zek, Deedra Nicolet, Alice S Mims, Geoffrey L Uy, Wendy Stock, John C Byrd, Wolfgang Hiddemann, Klaus H Metzeler, et al. Improving risk stratification for 2022 european leukemianet favorable-risk patients with acute myeloid leukemia. The Innovation, 5(6), 2024.
[406] Christof Koch and Idan Segev. The role of single neurons in information processing. Nature neuroscience, 3(11):1171-1177, 2000.
[407] Changyong Dou, Yunwei Tang, Nijun Jiang, Lin Yan, and Haifeng Ding. Analysis of sichuan wildfire based on the first synergetic observation from three payloads of sdgsat-1. The Innovation, 5(6), 2024.
[408] Simon Haykin and Neural Network. A comprehensive foundation. Neural networks, 2(2004):41, 2004.
[409] Salman Khan, Muzammal Naseer, Munawar Hayat, Syed Waqas Zamir, Fahad Shahbaz Khan, and Mubarak Shah. Transformers in vision: A survey. ACM computing surveys (CSUR), 54(10s):141, 2022.
[410] Yi Tay, Dara Bahri, Donald Metzler, Da-Cheng Juan, Zhe Zhao, and Che Zheng. Synthesizer: Rethinking self-attention for transformer models. In International conference on machine learning, pages 10183-10192. PMLR, 2021.
[411] Dandan Ma, Yuzhe Ma, Jinfu Ma, Qun Yang, Claudia Felser, and Guowei Li. Energy conversion materials need phonons. The Innovation, 5(6), 2024.
[412] Karl Cobbe, Vineet Kosaraju, Mohammad Bavarian, Mark Chen, Heewoo Jun, Lukasz Kaiser, Matthias Plappert, Jerry Tworek, Jacob Hilton, Reiichiro Nakano, et al. Training verifiers to solve math word problems. arXiv preprint arXiv:2110.14168, 2021.
[413] Le'on Bottou. Stochastic gradient descent tricks. In Neural Networks: Tricks of the Trade: Second Edition, pages 421-436. Springer, 2012.
[414] Yali Cui, Yi Wu, and Yingjin Yuan. Amplification editing empowers in situ large-scale dna duplication. The Innovation, 5(6), 2024.
[415] Peng Xiao, Yongfeng Yin, Bin Liu, Bo Jiang, and Yashwant K Malaiya. Adaptive testing based on moment estimation. IEEE Transactions on Systems, Man, and Cybernetics: Systems, 50(3):911922, 2017.
[416] Sujuan Xu, Runzhou Chen, Xinqi Zhang, Yufeng Wu, Liuyan Yang, Zongyi Sun, Zhitao Zhu, Aiping Song, Ze Wu, Ting Li, et al. The evolutionary tale of lilies: Giant genomes derived from transposon insertions and polyploidization. The Innovation, 5(6), 2024.
[417] George Em Karniadakis, Ioannis G Kevrekidis, Lu Lu, Paris Perdikaris, Sifan Wang, and Liu Yang. Physics-informed machine learning. Nature Reviews Physics, 3(6):422-440, 2021.
[418] Angran Li, Ruijia Chen, Amir Barati Farimani, and Yongjie Jessica Zhang. Reaction diffusion system prediction based on convolutional neural network. Scientific reports, 10(1):3894, 2020.
[419] Stephan Rasp, Michael S Pritchard, and Pierre Gentine. Deep learning to represent subgrid processes in climate models. Proceedings of the national academy of sciences, 115(39):9684-9689, 2018.
[420] Kamal Choudhary, Brian DeCost, Chi Chen, Anubhav Jain, Francesca Tavazza, Ryan Cohn, Cheol Woo Park, Alok Choudhary, Ankit Agrawal, Simon JL Billinge, et al. Recent advances and applications of deep learning methods in materials science. npj Computational Materials, 8(1):59, 2022.
[421] Nan Xu, Wenyu Li, Peng Gong, and Hui Lu. Satellite altimeter observed surface water increase across lake-rich regions of the arctic. The Innovation, 5(6), 2024.
[422] Samuel Kim, Peter Y Lu, Srijon Mukherjee, Michael Gilbert, Li Jing, Vladimir Ceperic', and Marin Soljacic'. Integration of neural network-based symbolic regression in deep learning for scientific discovery. IEEE transactions on neural networks and learning systems, 32(9):4166-4177, 2020.
[423] Guillaume Lample and Franc, ois Charton. Deep learning for symbolic mathematics. International Conference on Learning Representations, 2019.
[424] Jakub Voznica, Anna Zhukova, Veronika Boskova, E Saulnier, F Lemoine, Mathieu MoslonkaLefebvre, and Olivier Gascuel. Deep learning from phylogenies to uncover the epidemiological dynamics of outbreaks. Nature Communica- tions, 13(1):3896, 2022.
[425] Ahmet Murat Ozbayoglu, Mehmet Ugur Gudelek, and Omer Berat Sezer. Deep learning for financial applications: A survey. Applied soft computing, 93:106384, 2020.
[426] Eric Edelman, Fabian Tijssen, Popke Rein Munniksma, Wim Bast, Harold Ten Bohmer, Nicole van Eldik, Marieke Spreeuwenberg, Wolfgang Buhre, and Frits van Merode. Clinical knowledge modeling: An essential step in the digital transformation of healthcare. The Innovation, 5(6), 2024.
[427] Xiyi Yang, Jia Jia, Xiaoyu Zhou, and Shouyang Wang. The future of artificial intelligence: Time to embrace more international collaboration. The Innovation, 5(6), 2024.
[428] Muning Wen, Runji Lin, Hanjing Wang, Yaodong Yang, Ying Wen, Luo Mai, Jun Wang, Haifeng Zhang, and Weinan Zhang. Large sequence models for sequential decision-making: a survey. Frontiers of Computer Science, 17(6):176349, 2023.
[429] Weinan. Zhang. Large decision models. International Joint Conferences on Artificial Intelligence, pages 7062-7067, 2023.
[430] Xu Wang, Sen Wang, Xingxing Liang, Dawei Zhao, Jincai Huang, Xin Xu, Bin Dai, and Qiguang Miao. Deep re- inforcement learning: A survey. IEEE Transactions on Neural Networks and Learning Systems, 35(4):5064-5078, 2022.
[431] Emre Oral, Ria Chawla, Michel Wijkstra, Narges Mahyar, and Evanthia Dimara. From information to choice: A critical inquiry into visualization tools for decision making. IEEE Transactions on Visualization and Computer Graphics, 2023.
[432] Zheng Chu, Jingchang Chen, Qianglong Chen, Weijiang Yu, Tao He, Haotian Wang, Weihua Peng, Ming Liu, Bing Qin, and Ting Liu. A survey of chain of thought reasoning: Advances, frontiers and future. arXiv preprint arXiv:2309.15402, 2023.
[433] Tianyang Lin, Yuxin Wang, Xiangyang Liu, and Xipeng Qiu. A survey of transformers. AI open, 3:111-132, 2022.
[434] Tianyu Wu, Shizhu He, Jingping Liu, Siqi Sun, Kang Liu, Qing-Long Han, and Yang Tang. A brief overview of chatgpt: The history, status quo and potential future development. IEEE/CAA Journal of Automatica Sinica, 10(5):1122-1136, 2023.
[435] Michael Moor, Oishi Banerjee, Zahra Shakeri Hossein Abad, Harlan M Krumholz, Jure Leskovec, Eric J Topol, and Pranav Rajpurkar. Foundation models for generalist medical artificial intelligence. Nature, 616(7956):259-265, 2023.
[436] Tao Tu, Shekoofeh Azizi, Danny Driess, Mike Schaekermann, Mohamed Amin, Pi-Chuan Chang, Andrew Carroll, Charles Lau, Ryutaro Tanno, Ira Ktena, et al. Towards generalist biomedical ai. NEJM AI, 1(3):AIoa2300138, 2024.
[437] Karan Singhal, Shekoofeh Azizi, Tao Tu, S Sara Mahdavi, Jason Wei, Hyung Won Chung, Nathan Scales, Ajay Tanwani, Heather Cole-Lewis, Stephen Pfohl, et al. Large language models encode clinical knowledge. Nature, 620(7972):172-180, 2023.
[438] Karan Singhal, Tao Tu, Juraj Gottweis, Rory Sayres, Ellery Wulczyn, Le Hou, Kevin Clark, Stephen Pfohl, Heather Cole-Lewis, Darlene Neal, et al. Towards expert-level medical question answering with large language models. arXiv preprint arXiv:2305.09617, 2023.
[439] Xiaohong Liu, Hao Liu, Guoxing Yang, Zeyu Jiang, Shuguang Cui, Zhaoze Zhang, Huan Wang, Liyuan Tao, Yongchang Sun, Zhu Song, et al. A generalist medical language model for disease diagnosis assistance. Nature Medicine, pages 1-11, 2025.
[440] Nicholas R Rydzewski, Deepak Dinakaran, Shuang G Zhao, Eytan Ruppin, Baris Turkbey, Deborah E Citrin, and Krishnan R Patel. Comparative evaluation of llms in clinical oncology. NEJM AI, 1(5):AIoa2300151, 2024.
[441] Cyril Zakka, Rohan Shad, Akash Chaurasia, Alex R Dalal, Jennifer L Kim, Michael Moor, Robyn Fong, Curran Phillips, Kevin Alexander, Euan Ashley, et al. Almanac-retrieval-augmented language models for clinical medicine. NEJM AI, 1(2):AIoa2300068, 2024.
[442] Ozan Unlu, Jiyeon Shin, Charlotte J Mailly, Michael F Oates, Michela R Tucci, Matthew Varugheese, Kavishwar Wagholikar, Fei Wang, Benjamin M Scirica, Alexander J Blood, et al. Retrieval-augmented generation-enabled gpt-4 for clinical trial screening. NEJM AI, page AIoa2400181, 2024.
[443] Kyle Lam and Jianing Qiu. Foundation models: the future of surgical artificial intelligence? British Journal of Surgery, 111(4):znae090, 2024.
[444] Yuanyuan Peng, Aidi Lin, Meng Wang, Tian Lin, Linna Liu, Jianhua Wu, Ke Zou, Tingkun Shi, Lixia Feng, Zhen Liang, et al. Enhancing ai reliability: A foundation model with uncertainty estimation for optical coherence tomography-based retinal disease diagnosis. Cell Reports Medicine, 2024.
[445] Yuanyuan Tian, Zhiyuan Li, Yanrui Jin, Mengxiao Wang, Xiaoyang Wei, Liqun Zhao, Yunqing Liu, Jinlei Liu, and Chengliang Liu. Foundation model of ecg diagnosis: Diagnostics and explanations of any form and rhythm on ecg. Cell Reports Medicine, 5(12), 2024.
[446] Jun Ma, Yuting He, Feifei Li, Lin Han, Chenyu You, and Bo Wang. Segment anything in medical images. Nature Communications, 15(1):654, 2024.
[447] Christian Bluethgen, Pierre Chambon, Jean-Benoit Delbrouck, Rogier van der Sluijs, Małgorzata Połacin, Juan Manuel Zambrano Chaves, Tanishq Mathew Abraham, Shivanshu Purohit, Curtis P Langlotz, and Akshay S Chaudhari. A vision-language foundation model for the generation of realistic chest x-ray images. Nature Biomedical Engineering, pages 1-13, 2024.
[448] Jinxi Xiang, Xiyue Wang, Xiaoming Zhang, Yinghua Xi, Feyisope Eweje, Yijiang Chen, Yuchen Li, Colin Bergstrom, Matthew Gopaulchan, Ted Kim, et al. A vision-language foundation model for precision oncology. Nature, pages 1-10, 2025.
[449] Eugene Vorontsov, Alican Bozkurt, Adam Casson, George Shaikovski, Michal Zelechowski, Kristen Severson, Eric Zimmermann, James Hall, Neil Tenenholtz, Nicolo Fusi, et al. A foundation model for clinical-grade computational pathology and rare cancers detection. Nature medicine, pages 1-12, 2024.
[450] Xiyue Wang, Junhan Zhao, Eliana Marostica, Wei Yuan, Jietian Jin, Jiayu Zhang, Ruijiang Li, Hongping Tang, Kan- ran Wang, Yu Li, et al. A pathology foundation model for cancer diagnosis and prognosis prediction. Nature, 634(8035):970-978, 2024.
[451] Nadieh Khalili and Francesco Ciompi. Scaling data toward pan-cancer foundation models. Trends in Cancer, 2024.
[452] Hugo Dalla-Torre, Liam Gonzalez, Javier Mendoza-Revilla, Nicolas Lopez Carranza, Adam Henryk Grzywaczewski, Francesco Oteri, Christian Dallago, Evan Trop, Bernardo P de Almeida, Hassan Sirelkhatim, et al. Nucleotide trans- former: building and evaluating robust foundation models for human genomics. Nature Methods, pages 1-11, 2024.
[453] Haotian Cui, Chloe Wang, Hassaan Maan, Kuan Pang, Fengning Luo, Nan Duan, and Bo Wang. scgpt: toward building a foundation model for single-cell multi-omics using generative ai. Nature Methods, pages 1-11, 2024.
[454] Xi Fu, Shentong Mo, Alejandro Buendia, Anouchka P Laurent, Anqi Shao, Maria del Mar AlvarezTorres, Tianji Yu, Jimin Tan, Jiayu Su, Romella Sagatelian, et al. A foundation model of transcription across human cell types. Nature, pages 1-9, 2025.
[455] Pratik Ramprasad, Nidhi Pai, and Wei Pan. Enhancing personalized gene expression prediction from dna sequences using genomic foundation models. Human Genetics and Genomics Advances, 5(4), 2024.
[456] Lavender Yao Jiang, Xujin Chris Liu, Nima Pour Nejatian, Mustafa Nasir-Moin, Duo Wang, Anas Abidin, Kevin Eaton, Howard Antony Riina, Ilya Laufer, Paawan Punjabi, et al. Health systemscale language models are all-purpose prediction engines. Nature, 619(7969):357-362, 2023.
[457] Aaron Boussina, Rishivardhan Krishnamoorthy, Kimberly Quintero, Shreyansh Joshi, Gabriel Wardi, Hayden Pour, Nicholas Hilbert, Atul Malhotra, Michael Hogarth, Amy M Sitapati, et al. Large language models for more efficient reporting of hospital quality measures. NEJM AI, 1(11):AIcs2400420, 2024.
[458] Xi Yang, Aokun Chen, Nima PourNejatian, Hoo Chang Shin, Kaleb E Smith, Christopher Parisien, Colin Compas, Cheryl Martin, Anthony B Costa, Mona G Flores, et al. A large language model for electronic health records. npj Digital Medicine, 5(1):194, 2022.
[459] Akhil Vaid, Isotta Landi, Girish Nadkarni, and Ismail Nabeel. Using fine-tuned large language models to parse clinical notes in musculoskeletal pain disorders. The Lancet Digital Health, 5(12):e855-e858, 2023.
[460] Dave Van Veen, Cara Van Uden, Louis Blankemeier, Jean-Benoit Delbrouck, Asad Aali, Christian Bluethgen, Anuj Pareek, Malgorzata Polacin, Eduardo Pontes Reis, Anna Seehofnerova', et al. Adapted large language models can outperform medical experts in clinical text summarization. Nature medicine, 30(4):1134-1142, 2024.
[461] Hanzhou Li, John T Moon, Saptarshi Purkayastha, Leo Anthony Celi, Hari Trivedi, and Judy W Gichoya. Ethics of large language models in medicine and medical research. The Lancet Digital Health, 5(6):e333-e335, 2023.
[462] Zhuxin Xiong, Xiaofei Wang, Yukun Zhou, Pearse A. Keane, Yih Chung Tham, Ya Xing Wang, and Tien Yin Wong. How generalizable are foundation models when applied to different demographic groups and settings? NEJM AI, 0(0):AIcs2400497, 2024.
[463] Paul Hager, Friederike Jungmann, Robbie Holland, Kunal Bhagat, Inga Hubrecht, Manuel Knauer, Jakob Vielhauer, Marcus Makowski, Rickmer Braren, Georgios Kaissis, et al. Evaluation and mitigation of the limitations of large language models in clinical decision-making. Nature medicine, 30(9):2613-2622, 2024.
[464] Yinghao Zhu, Junyi Gao, Zixiang Wang, Weibin Liao, Xiaochen Zheng, Lifang Liang, Yasha Wang, Chengwei Pan, Ewen M Harrison, and Liantao Ma. Is larger always better? evaluating and prompting large language models for non-generative medical tasks. arXiv preprint arXiv:2407.18525, 2024.
[465] Agustina D Saenz, Zach Harned, Oishi Banerjee, Michael D Abra`moff, and Pranav Rajpurkar. Autonomous ai systems in the face of liability, regulations and costs. npj Digital Medicine, 6(1):185, 2023.
[466] Krishnamurthy Dvijotham, Jim Winkens, Melih Barsbey, Sumedh Ghaisas, Robert Stanforth, Nick Pawlowski, Patricia Strachan, Zahra Ahmed, Shekoofeh Azizi, Yoram Bachrach, et al. Enhancing the reliability and accuracy of ai-enabled diagnosis via complementarity-driven deferral to clinicians. Nature Medicine, 29(7):1814-1820, 2023.
[467] Shreya Johri, Jaehwan Jeong, Benjamin A Tran, Daniel I Schlessinger, Shannon Wongvibulsin, Leandra A Barnes, Hong-Yu Zhou, Zhuo Ran Cai, Eliezer M Van Allen, David Kim, et al. An evaluation framework for clinical use of large language models in patient interaction tasks. Nature Medicine, pages 1-10, 2025.
[468] Yuting He, Fuxiang Huang, Xinrui Jiang, Yuxiang Nie, Minghao Wang, Jiguang Wang, and Hao Chen. Foundation model for advancing healthcare: Challenges, opportunities, and future directions. arXiv preprint arXiv:2404.03264, 2024.
[469] Arun James Thirunavukarasu, Darren Shu Jeng Ting, Kabilan Elangovan, Laura Gutierrez, Ting Fang Tan, and Daniel Shu Wei Ting. Large language models in medicine. Nature medicine, 29(8):1930-1940, 2023.
[470] Zhao Wang, Chang Liu, Shaoting Zhang, and Qi Dou. Foundation model for endoscopy video analysis via large- scale self-supervised pre-train. In International Conference on Medical Image Computing and Computer-Assisted Intervention, pages 101-111. Springer, 2023.
[471] Hugo Dalla-Torre, Liam Gonzalez, Javier Mendoza-Revilla, Nicolas Lopez Carranza, Adam Henryk Grzywaczewski, Francesco Oteri, Christian Dallago, Evan Trop, Bernardo P de Almeida, Hassan Sirelkhatim, et al. Nucleotide trans- former: building and evaluating robust foundation models for human genomics. Nature Methods, pages 1-11, 2024.
[472] Nadav Brandes, Dan Ofer, Yam Peleg, Nadav Rappoport, and Michal Linial. Proteinbert: a universal deep-learning model of protein sequence and function. Bioinformatics, 38(8):2102-2110, 2022.
[473] Kai Zhang, Jun Yu, Eashan Adhikarla, Rong Zhou, Zhiling Yan, Yixin Liu, Zhengliang Liu, Lifang He, Brian Davison, Xiang Li, et al. Biomedgpt: A unified and generalist biomedical generative pretrained transformer for vision, language, and multimodal tasks. arXiv e-prints, pages arXiv-2305, 2023.
[474] Bobby Azad, Reza Azad, Sania Eskandari, Afshin Bozorgpour, Amirhossein Kazerouni, Islem Rekik, and Dorit Merhof. Foundational models in medical imaging: A comprehensive survey and future vision. CoRR, 2023.
[475] Glyn Elwyn, Dominick Frosch, Richard Thomson, Natalie Joseph-Williams, Amy Lloyd, Paul Kinnersley, Emma Cord- ing, Dave Tomson, Carole Dodd, Stephen Rollnick, et al. Shared decision making: a model for clinical practice. Journal of general internal medicine, 27:1361-1367, 2012.
[476] Hongjian Zhou, Fenglin Liu, Boyang Gu, Xinyu Zou, Jinfa Huang, Jinge Wu, Yiru Li, Sam S Chen, Peilin Zhou, Junling Liu, et al. A survey of large language models in medicine: Progress, application, and challenge. arXiv preprint arXiv:2311.05112, 2023.
[477] Guangyu Wang, Guoxing Yang, Zongxin Du, Longjun Fan, and Xiaohu Li. Clinicalgpt: large language models finetuned with diverse medical data and comprehensive evaluation. arXiv preprint arXiv:2306.09968, 2023.
[478] Weihao Gao, Zhuo Deng, Zhiyuan Niu, Fuju Rong, Chucheng Chen, Zheng Gong, Wenze Zhang, Daimin Xiao, Fang Li, Zhenjie Cao, et al. Ophglm: Training an ophthalmology large language-and-vision assistant based on instructions and dialogue. arXiv preprint arXiv:2306.12174, 2023.
[479] Masoumeh Farhadi Nia, Mohsen Ahmadi, and Elyas Irankhah. Transforming dental diagnostics with artificial intelli- gence: Advanced integration of chatgpt and large language models for patient care. arXiv preprint arXiv:2406.06616, 2024.
[480] Ana Sua'rez, Jaime Jime'nez, Mar'ıa Llorente de Pedro, Cristina Andreu-Va'zquez, V'ıctor D'ıazFlores Garc'ia, Mar- garita Go'mez Sa'nchez, and Yolanda Freire. Beyond the scalpel: Assessing chatgpt's potential as an auxiliary intelligent virtual assistant in oral surgery. Computational and Structural Biotechnology Journal, 24:46-52, 2024.
[481] Hossein Mohammad-Rahimi, Saeed Reza Motamedian, Mohammad Hossein Rohban, Joachim Krois, Sergio E Uribe, Erfan Mahmoudinia, Rata Rokhshad, Mohadeseh Nadimi, and Falk Schwendicke. Deep learning for caries detection: A systematic review. Journal of Dentistry, 122:104115, 2022.
[482] Marta Revilla-Leo'n, Miguel Go'mez-Polo, Abdul B Barmak, Wardah Inam, Joseph YK Kan, John C Kois, and Orhan Akal. Artificial intelligence models for diagnosing gingivitis and periodontal disease: A systematic review. The Journal of Prosthetic Dentistry, 130(6):816-824, 2023.
[483] Pongsapak Wongratwanich, Kiichi Shimabukuro, Masaru Konishi, Toshikazu Nagasaki, Masahiko Ohtsuka, Yoshikazu Suei, Takashi Nakamoto, Rinus G Verdonschot, Tomohiko Kanesaki, Pipop Sutthiprapaporn, et al. Do various imaging modalities provide potential early detection and diagnosis of medication-related osteonecrosis of the jaw? a review. Dentomaxillofacial Radiology, 50(6):20200417, 2021.
[484] Rasheed Omobolaji Alabi, Omar Youssef, Matti Pirinen, Mohammed Elmusrati, Antti A Ma"kitie, Ilmo Leivo, and Alhadi Almangush. Machine learning in oral squamous cell carcinoma: Current status, clinical concerns and prospects for future-a systematic review. Artificial intelligence in medicine, 115:102060, 2021.
[485] Kritsasith Warin, Wasit Limprasert, Siriwan Suebnukarn, Teerawat Paipongna, Patcharapon Jantana, and Sothana Vicharueang. Maxillofacial fracture detection and classification in computed tomography images using convolutional neural network-based models. Scientific reports, 13(1):3434, 2023.
[486] Nayansi Jha, Kwang-Sig Lee, and Yoon-Ji Kim. Diagnosis of temporomandibular disorders using artificial intelligence technologies: A systematic review and meta-analysis. PLoS One, 17(8):e0272715, 2022.
[487] Duy MH Nguyen, Hoang Nguyen, Nghiem Diep, Tan Ngoc Pham, Tri Cao, Binh Nguyen, Paul Swoboda, Nhat Ho, Shadi Albarqouni, Pengtao Xie, et al. Lvm-med: Learning large-scale selfsupervised vision models for medical imag- ing via second-order graph matching. Advances in Neural Information Processing Systems, 36, 2024.
[488] Weijia Feng, Lingting Zhu, and Lequan Yu. Cheap lunch for medical image segmentation by finetuning sam on few exemplars. In International MICCAI Brainlesion Workshop, pages 13-22. Springer, 2023.
[489] Anirudh Shankar, TR Monisha, Skanda S Kumar, Aishwary Anurag, Ashwath Narayan, et al. Advancements in ai- driven dentistry: Tooth genai's impact on dental diagnosis and treatment planning. In 2024 2nd International Conference on Networking, Embedded and Wireless Systems (ICNEWS), pages 1-7. IEEE, 2024.
[490] Wenxi Yue, Jing Zhang, Kun Hu, Qiuxia Wu, Zongyuan Ge, Yong Xia, Jiebo Luo, and Zhiyong Wang. Part to whole: Collaborative prompting for surgical instrument segmentation. arXiv preprint arXiv:2312.14481, 2023.
[491] Hsun-Liang Chan, Kelly Misch, and Hom-Lay Wang. Dental imaging in implant treatment planning. Implant dentistry, 19(4):288-298, 2010.
[492] Yuepeng Wu, Yukang Zhang, Mei Xu, Yuchen Zheng, et al. Effectiveness of various general large language models in clinical consensus and case analysis in dental implantology: A comparative study. 2024.
[493] Bahaaeldeen M Elgarba, Rocharles Cavalcante Fontenele, Mihai Tarce, and Reinhilde Jacobs. Artificial intelligence serving pre-surgical digital implant planning: A scoping review. Journal of Dentistry, page 104862, 2024.
[494] Sheldon Baumrind, Edward L Korn, Robert L Boyd, and Raymond Maxwell. The decision to extract: part ii. analysis of clinicians' stated reasons for extraction. American Journal of Orthodontics and Dentofacial Orthopedics, 109(4):393-402, 1996.
[495] Ye-Hyun Kim, Jae-Bong Park, Min-Seok Chang, Jae-Jun Ryu, Won Hee Lim, and Seok-Ki Jung. Influence of the depth of the convolutional neural networks on an artificial intelligence model for diagnosis of orthognathic surgery. Journal of Personalized Medicine, 11(5):356, 2021.
[496] WooSang Shin, Han-Gyeol Yeom, Ga Hyung Lee, Jong Pil Yun, Seung Hyun Jeong, Jong Hyun Lee, Hwi Kang Kim, and Bong Chul Kim. Deep learning based prediction of necessity for orthognathic surgery of skeletal malocclusion using cephalogram in korean individuals. BMC Oral Health, 21:1-7, 2021.
[497] Hyuk-Il Choi, Seok-Ki Jung, Seung-Hak Baek, Won Hee Lim, Sug-Joon Ahn, Il-Hyung Yang, and Tae-Woo Kim. Artificial intelligent model with neural network machine learning for the diagnosis of orthognathic surgery. Journal of Craniofacial Surgery, 30(7):1986-1989, 2019.
[498] Sreekanth Kumar Mallineni, Mallika Sethi, Dedeepya Punugoti, Sunil Babu Kotha, Zikra Alkhayal, Sarah Mubaraki, Fatmah Nasser Almotawah, Sree Lalita Kotha, Rishitha Sajja, Venkatesh Nettam, et al. Artificial intelligence in den- tistry: A descriptive review. Bioengineering, 11(12):1267, 2024.
[499] Hao Ding, Jiamin Wu, Wuyuan Zhao, Jukka P Matinlinna, Michael F Burrow, and James KH Tsoi. Artificial intelligence in dentistry—a review. Frontiers in Dental Medicine, 4:1085251, 2023.
[500] Dianhao Wu, Jingang Jiang, Jie Pan, Kun Qian, and Zhonghao Xue. Root canal preparation robot based on guiding strat- egy for safe remote therapy: System design and feasibility study (2023). IEEE/ASME Transactions on Mechatronics, 2024.
[501] T Shan, FR Tay, and L Gu. Application of artificial intelligence in dentistry. Journal of dental research, 100(3):232-244, 2021.
[502] Fet al Schwendicke, W Samek, and J Krois. Artificial intelligence in dentistry: chances and challenges. Journal of dental research, 99(7):769-774, 2020.
[503] Sergio Salerno, Andrea Laghi, Marie-Claire Cantone, Paolo Sartori, Antonio Pinto, and Guy Frija. Overdiagnosis and overimaging: an ethical issue for radiological protection. La radiologia medica, 124:714-720, 2019.
[504] Mikhail Kulyabin, Aleksei Zhdanov, Andrey Pershin, Gleb Sokolov, Anastasia Nikiforova, Mikhail Ronkin, Vasilii Borisov, and Andreas Maier. Segment anything in optical coherence tomography: Sam 2 for volumetric segmentation of retinal biomarkers. Bioengineering, 11(9):940, 2024.
[505] Jie Zhang and Zong-ming Zhang. Ethics and governance of trustworthy medical artificial intelligence. BMC medical informatics and decision making, 23(1):7, 2023.
[506] Yi-Da Tang, Er-Dan Dong, and Wen Gao. Llms in medicine: The need for advanced evaluation systems for disruptive technologies. The Innovation, 5(3), 2024.
[507] Yin Yang, Shuangbin Xu, Yifan Hong, Yantong Cai, Wenli Tang, Jiao Wang, Bairong Shen, Hui Zong, and Guangchuang Yu. Computational modeling for medical data: From data collection to knowledge discovery. The Innovation Life, 2(3):100079-1, 2024.
[508] Hao Guan and Mingxia Liu. Domain adaptation for medical image analysis: a survey. IEEE Transactions on Biomedical Engineering, 69(3):1173-1185, 2021.
[509] Weijia Zhang, Jindong Han, Zhao Xu, Hang Ni, Hao Liu, and Hui Xiong. Towards urban general intelligence: A review and outlook of urban foundation models. arXiv preprint arXiv:2402.01749, 2024.
[510] Yuxuan Liang, Haomin Wen, Yuqi Nie, Yushan Jiang, Ming Jin, Dongjin Song, Shirui Pan, and Qingsong Wen. Foun- dation models for time series analysis: A tutorial and survey. In Proceedings of the 30th ACM SIGKDD Conference on Knowledge Discovery and Data Mining, pages 65556565, 2024.
[511] Sarah Alnegheimish, Linh Nguyen, Laure Berti-Equille, and Kalyan Veeramachaneni. Large language models can be zero-shot anomaly detectors for time series? arXiv preprint arXiv:2405.14755, 2024.
[512] Tian Zhou, Peisong Niu, Liang Sun, Rong Jin, et al. One fits all: Power general time series analysis by pretrained lm. Advances in neural information processing systems, 36:43322-43355, 2023.
[513] Qingxiang Liu, Xu Liu, Chenghao Liu, Qingsong Wen, and Yuxuan Liang. Time-ffm: Towards lm-empowered federated foundation model for time series forecasting. arXiv preprint arXiv:2405.14252, 2024.
[514] Zhonghang Li, Lianghao Xia, Jiabin Tang, Yong Xu, Lei Shi, Long Xia, Dawei Yin, and Chao Huang. Urbangpt: Spatio- temporal large language models. In Proceedings of the 30th ACM SIGKDD Conference on Knowledge Discovery and Data Mining, pages 5351-5362, 2024.
[515] Chenxi Liu, Sun Yang, Qianxiong Xu, Zhishuai Li, Cheng Long, Ziyue Li, and Rui Zhao. Spatialtemporal large language model for traffic prediction. arXiv preprint arXiv:2401.10134, 2024.
[516] Abdul Fatir Ansari, Lorenzo Stella, Caner Turkmen, Xiyuan Zhang, Pedro Mercado, Huibin Shen, Oleksandr Shchur, Syama Sundar Rangapuram, Sebastian Pineda Arango, Shubham Kapoor, et al. Chronos: Learning the language of time series. arXiv preprint arXiv:2403.07815, 2024.
[517] Yuan Yuan, Jingtao Ding, Jie Feng, Depeng Jin, and Yong Li. Unist: A prompt-empowered universal model for urban spatio-temporal prediction. In Proceedings of the 30th ACM SIGKDD Conference on Knowledge Discovery and Data Mining, pages 4095-4106, 2024.
[518] Yan Lin, Tonglong Wei, Zeyu Zhou, Haomin Wen, Jilin Hu, Shengnan Guo, Youfang Lin, and Huaiyu Wan. Trajfm: A vehicle trajectory foundation model for region and task transferability. arXiv preprint arXiv:2408.15251, 2024.
[519] Yuanshao Zhu, James Jianqiao Yu, Xiangyu Zhao, Xuetao Wei, and Yuxuan Liang. Unitraj: Universal human trajectory modeling from billion-scale worldwide traces. arXiv preprint arXiv:2411.03859, 2024.
[520] Xixuan Hao, Wei Chen, Yibo Yan, Siru Zhong, Kun Wang, Qingsong Wen, and Yuxuan Liang. Urbanvlp: A multi-granularity vision-language pre-trained foundation model for urban indicator prediction. arXiv preprint arXiv:2403.16831, 2024.
[521] Congxi Xiao, Jingbo Zhou, Yixiong Xiao, Jizhou Huang, and Hui Xiong. Refound: Crafting a foundation model for urban region understanding upon language and visual foundations. In Proceedings of the 30th ACM SIGKDD Conference on Knowledge Discovery and Data Mining, pages 3527-3538, 2024.
[522] Siqi Lai, Zhao Xu, Weijia Zhang, Hao Liu, and Hui Xiong. Large language models as traffic signal control agents: Capacity and opportunity. arXiv preprint arXiv:2312.16044, 2023.
[523] Zhilun Zhou, Yuming Lin, Depeng Jin, and Yong Li. Large language model for participatory urban planning. arXiv preprint arXiv:2402.17161, 2024.
[524] Lincan Li, Jiaqi Li, Catherine Chen, Fred Gui, Hongjia Yang, Chenxiao Yu, Zhengguang Wang, Jianing Cai, Jun- long Aaron Zhou, Bolin Shen, et al. Political-llm: Large language models in political science. arXiv preprint arXiv:2412.06864, 2024.
[525] Menglin Liu and Ge Shi. Poliprompt: A high-performance cost-effective llm-based text classification framework for political science. arXiv preprint arXiv:2409.01466, 2024.
[526] Albaaji G F. SS V C, Hareendran A. Precision farming for sustainability: An agricultural intelligence model. Computers and Electronics in Agriculture, 2024.
[527] Jiajia Li, Mingle Xu, Lirong Xiang, Dong Chen, Weichao Zhuang, Xunyuan Yin, and Zhaojian Li. Foundation models in smart agriculture: Basics, opportunities, and challenges. Computers and Electronics in Agriculture, 222:109032, 2024.
[528] Zhiyu Zhang, Wenjian Ni, Shaun Quegan, Jingming Chen, Peng Gong, Luiz Carlos Estraviz Rodriguez, Huadong Guo, Jiancheng Shi, Liangyun Liu, Zengyuan Li, et al. Deforestation in latin america in the 2000s predominantly occurred outside of typical mature forests. The Innovation, 5(3), 2024.
[529] Matheus Thomas Kuska, Mirwaes Wahabzada, and Stefan Paulus. Ai for crop production-where can large language models (llms) provide substantial value? Computers and Electronics in Agriculture, 221:108924, 2024.
[530] Keong Tan. Large language models for crop yield prediction. 2024.
[531] Yujiao Lyu, Pengxin Wang, Xueyuan Bai, Xuecao Li, Xin Ye, Yuchen Hu, and Jie Zhang. Machine learning techniques and interpretability for maize yield estimation using time-series images of modis and multi-source data. Computers and Electronics in Agriculture, 222:109063, 2024.
[532] Federico Pallottino, Simona Violino, Simone Figorilli, Catello Pane, Jacopo Aguzzi, Giacomo Colle, Eugenio Nerio Nemmi, Alessandro Montaghi, Damianos Chatzievangelou, Francesca Antonucci, et al. Applications and perspectives of generative artificial intelligence in agriculture. Computers and Electronics in Agriculture, 230:109919, 2025.
[533] Hongyan Zhu, Shuai Qin, Min Su, Chengzhi Lin, Anjie Li, and Junfeng Gao. Harnessing large vision and language models in agriculture: A review. arXiv preprint arXiv:2407.19679, 2024.
[534] Yueyue Zhou, Hongping Yan, Kun Ding, Tingting Cai, and Yan Zhang. Few-shot image classification of crop diseases based on vision-language models. Sensors, 24(18):6109, 2024.
[535] Xutong Wu, Bojie Fu, Shuai Wang, Yanxu Liu, Ying Yao, Yingjie Li, Zhenci Xu, and Jianguo Liu. Three main dimensions reflected by national sdg performance. The innovation, 4(6), 2023.
[536] Wanchao Zhu, Weifu Li, Hongwei Zhang, and Lin Li. Big data and artificial intelligence-aided crop breeding: Progress and prospects. Journal of Integrative Plant Biology, 2024.
[537] Muhammad Amjad Farooq, Shang Gao, Muhammad Adeel Hassan, Zhangping Huang, Awais Rasheed, Sarah Hearne, Boddupalli Prasanna, Xinhai Li, and Huihui Li. Artificial intelligence in plant breeding. Trends in Genetics, 2024.
[538] Gengchen Mai, Weiming Huang, Jin Sun, Suhang Song, Deepak Mishra, Ninghao Liu, Song Gao, Tianming Liu, Gao Cong, Yingjie Hu, et al. On the opportunities and challenges of foundation models for geospatial artificial intelligence. arXiv preprint arXiv:2304.06798, 2023.
[539] Junnan Li, Dongxu Li, Caiming Xiong, and Steven Hoi. Blip: Bootstrapping language-image pretraining for unified vision-language understanding and generation. In International conference on machine learning, pages 12888-12900. PMLR, 2022.
[540] Guarino M. Tullo E, Finzi A. Environmental impact of livestock farming and precision livestock farming as a mitigation strategy. Science of the total environment, 2019.
[541] Xiao Yang, Haixing Dai, Zihao Wu, Ramesh Bist, Sachin Subedi, Jin Sun, Guoyu Lu, Changying Li, Tianming Liu, and Lilong Chai. Sam for poultry science. arXiv preprint arXiv:2305.10254, 2023.
[542] Xie Q. Bao J. Artificial intelligence in animal farming: A systematic literature review. Journal of Cleaner Production, 2022.
[543] Na Liu, Jingwei Qi, Xiaoping An, and Yuan Wang. A review on information technologies applicable to precision dairy farming: Focus on behavior, health monitoring, and the precise feeding of dairy cows. Agriculture, 13(10):1858, 2023.
[544] Wenjie Sun, Jie Zhang, Yujie Lei, and Danfeng Hong. Rsprotoseg: High spatial resolution remote sensing images segmentation based on non-learnable prototypes. IEEE Transactions on Geoscience and Remote Sensing, 2024.
[545] Sheik Arafat, C Priya, R Premkumar, Haji Nishath SM, et al. Real time cattle health monitoring and early disease detection using iot and machine learning. In 2024 5th International Conference on Electronics and Sustainable Com- munication Systems (ICESC), pages 450-455. IEEE, 2024.
[546] Md Mahfujul Islam, Shaharya Sourov Tonmoy, Sazzad Quayum, Al Russel Sarker, Sumaiya Umme Hani, and Moham- mad Abdul Mannan. Smart poultry farm incorporating gsm and iot. In 2019 International Conference on Robotics, Electrical and Signal Processing Techniques (ICREST), pages 277-280. IEEE, 2019.
[547] Rishi Bommasani, Drew A Hudson, Ehsan Adeli, Russ Altman, Simran Arora, Sydney von Arx, Michael S Bernstein, Jeannette Bohg, Antoine Bosselut, Emma Brunskill, et al. On the opportunities and risks of foundation models. arXiv preprint arXiv:2108.07258, 2021.
[548] Y Nie, Y Kong, X Dong, et al. A survey of large language models for financial applications: Progress, prospects and challenges. arXiv preprint arXiv:2406.11903, 2024.
[549] E Brynjolfsson and A McAfee. The second machine age: Work, progress, and prosperity in a time of brilliant technolo- gies. WW Norton & company, 2014.
[550] Wenhua Xu and Yuanqi Feng. Does fintech promote green economic growth in chinese cities? In 2024 7th International Conference on Humanities Education and Social Sciences (ICHESS 2024), pages 942-948. Atlantis Press, 2024.
[551] AM Qatawneh, A Lutfi, and T Al Barrak. Effect of artificial intelligence (ai) on financial decisionmaking: Mediating role of financial technologies (fin-tech). HighTech and Innovation Journal, 5(3):759-773, 2024.
[552] J Kriebel and L Stitz. Credit default prediction from user-generated text in peer-to-peer lending using deep learning. European Journal of Operational Research, 302(1):309-323, 2022.
[553] DW Arner, DA Zetzsche, RP Buckley, et al. Fintech and regtech: Enabling innovation while preserving financial stability. Georgetown Journal of International Affairs, pages 47-58, 2017.
[554] D Mhlanga. Financial inclusion in emerging economies: The application of machine learning and artificial intelligence in credit risk assessment. International journal of financial studies, 9(3):39, 2021.
[555] J Duarte, S Siegel, and L Young. Trust and credit: The role of appearance in peer-to-peer lending. The Review of Financial Studies, 25(8):2455-2484, 2012.
[556] Chunxiao Li, Hongchang Wang, Songtao Jiang, and Bin Gu. The effect of ai-enabled credit scoring on financial inclusion: Evidence from an underserved population of over one million. MIS Quarterly, 48(4), 2024.
[557] T Chen and C Guestrin. Xgboost: A scalable tree boosting system. In Proceedings of the 22nd acm sigkdd international conference on knowledge discovery and data mining, pages 785-794, 2016.
[558] J Delgadillo, J Kinyua, and C Mutigwe. Finsosent: Advancing financial market sentiment analysis through pretrained large language models. Big Data and Cognitive Computing, 8(8):87, 2024.
[559] B Li and C Duan. Construction and optimization of macroeconomic data forecasting model based on machine learning. Journal of Electrical Systems, 20(3s):436-447, 2024.
[560] S Takahashi, Y Chen, and K Tanaka-Ishii. Modeling financial time-series with generative adversarial networks. Physica A: Statistical Mechanics and its Applications, 527:121261, 2019.
[561] P Hajek and R Henriques. Mining corporate annual reports for intelligent detection of financial statement fraud-a comparative study of machine learning methods. Knowledge-Based Systems, 128:139-152, 2017.
[562] R Avacharmal. Leveraging supervised machine learning algorithms for enhanced anomaly detection in anti-money laundering (aml) transaction monitoring systems: A comparative analysis of performance and explainability. African Journal of Artificial Intelligence and Sustainable Development, 1(2):68-85, 2021.
[563] F Teichmann, S Boticiu, and BS Sergi. Regtech-potential benefits and challenges for businesses. Technology in Society, 72:102150, 2023.
[564] D Tapscott and A Tapscott. Blockchain Revolution: How the Technology Behind Bitcoin and Other Cryptocurrencies is Changing the World. Portfolio, 2017.
[565] LW Cong, Z He, and J Li. Decentralized mining in centralized pools. The Review of Financial Studies, 34(3):1191-1235, 2021.
[566] Q Yang, Y Liu, T Chen, et al. Federated machine learning: Concept and applications. ACM Transactions on Intelligent Systems and Technology (TIST), 10(2):1-19, 2019.
[567] BD Mittelstadt, P Allo, M Taddeo, et al. The ethics of algorithms: Mapping the debate. Big Data & Society, 3(2):2053951716679679, 2016.
[568] Luciano Floridi, Josh Cowls, Monica Beltrametti, Raja Chatila, Patrice Chazerand, Virginia Dignum, Christoph Luetge, Robert Madelin, Ugo Pagallo, Francesca Rossi, et al. Ai4people-an ethical framework for a good ai society: opportu- nities, risks, principles, and recommendations. Minds and machines, 28:689-707, 2018.
[569] MT Ribeiro, S Singh, and C Guestrin. Why should i trust you? explaining the predictions of any classifier. In Proceedings of the 22nd ACM SIGKDD international conference on knowledge discovery and data mining, pages 1135-1144, 2016.
[570] Hung Chau, Igor Labutov, Khushboo Thaker, Daqing He, and Peter Brusilovsky. Automatic concept extraction for domain and student modeling in adaptive textbooks. International Journal of Artificial Intelligence in Education, 31:820-846, 2021.
[571] Qingtang Liu, Xinxin Zheng, Yaoyao Liu, Linjing Wu, Si Zhang, Ni Zhang, and Qiyun Wang. Exploration of the characteristics of teachers' multimodal behaviours in problem-oriented teaching activities with different response levels. British Journal of Educational Technology, 55(1):181207, 2024.
[572] Tunde Toyese Oyedokun. Assistive technology and accessibility tools in enhancing adaptive education. In Advancing Adaptive Education: Technological Innovations for Disability Support, pages 125-162. IGI Global Scientific Publish- ing, 2025.
[573] Wadim Strielkowski, Veronika Grebennikova, Alexander Lisovskiy, Guzalbegim Rakhimova, and Tatiana Vasileva. Ai-driven adaptive learning for sustainable educational transformation. Sustainable Development, 2024.
[574] Tiffanie Zaugg. Future innovations for assistive technology and universal design for learning. Assistive Technology and Universal Design for Learning: Toolkits for Inclusive Instruction, page 275, 2024.
[575] Ismail Celik, Muhterem Dindar, Hanni Muukkonen, and Sanna Ja"rvela". The promises and challenges of artificial intelligence for teachers: A systematic review of research. TechTrends, 66(4):616-630, 2022.
[576] Hanrong Zhang, Jingyuan Huang, Kai Mei, Yifei Yao, Zhenting Wang, Chenlu Zhan, Hongwei Wang, and Yongfeng Zhang. Agent security bench (ASB): formalizing and benchmarking attacks and defenses in llm-based agents. CoRR, abs/2410.02644, 2024.
[577] Matthieu Meeus, Shubham Jain, Marek Rei, and Yves-Alexandre de Montjoye. Did the neurons read your book? document-level membership inference for large language models. In Davide Balzarotti and Wenyuan Xu, editors, 33rd USENIX Security Symposium, USENIX Security 2024, Philadelphia, PA, USA, August 14-16, 2024. USENIX Association, 2024.
[578] Nishant Vishwamitra, Keyan Guo, Farhan Tajwar Romit, Isabelle Ondracek, Long Cheng, Ziming Zhao, and Hongxin Hu. Moderating new waves of online hate with chain-of-thought reasoning in large language models. In IEEE Sympo- sium on Security and Privacy, SP 2024, San Francisco, CA, USA, May 19-23, 2024, pages 788-806. IEEE, 2024.
[579] Xueqi Cheng, Wei Chen, Huawei Shen, Shiguang Shan, Xilin Chen, and Guojie Li. Intelligent algorithm safety: Concepts, scientific problems and prospects. Bulletin of Chinese Academy of Sciences, 39, 2024.
[580] Fa'bio Perez and Ian Ribeiro. Ignore previous prompt: Attack techniques for language models. CoRR, abs/2211.09527, 2022.
[581] Xuchen Suo. Signed-prompt: A new approach to prevent prompt injection attacks against llmintegrated applications. CoRR, abs/2401.07612, 2024.
[582] Yupei Liu, Yuqi Jia, Runpeng Geng, Jinyuan Jia, and Neil Zhenqiang Gong. Formalizing and benchmarking prompt injection attacks and defenses. In Davide Balzarotti and Wenyuan Xu, editors, 33rd USENIX Security Symposium, USENIX Security 2024, Philadelphia, PA, USA, August 14-16, 2024. USENIX Association, 2024.
[583] Sahar Abdelnabi, Kai Greshake, Shailesh Mishra, Christoph Endres, Thorsten Holz, and Mario Fritz. Not what you've signed up for: Compromising real-world llm-integrated applications with indirect prompt injection. In Maura Pin- tor, Xinyun Chen, and Florian Trame`r, editors, Proceedings of the 16th ACM Workshop on Artificial Intelligence and Security, AISec 2023, Copenhagen, Denmark, 30 November 2023, pages 79-90. ACM, 2023.
[584] Jingwei Yi, Yueqi Xie, Bin Zhu, Keegan Hines, Emre Kiciman, Guangzhong Sun, Xing Xie, and Fangzhao Wu. Bench- marking and defending against indirect prompt injection attacks on large language models. CoRR, abs/2312.14197, 2023.
[585] Chong Xiang, Tong Wu, Zexuan Zhong, David A. Wagner, Danqi Chen, and Prateek Mittal. Certifiably robust RAG against retrieval corruption. CoRR, abs/2405.15556, 2024.
[586] Zhaorun Chen, Zhen Xiang, Chaowei Xiao, Dawn Song, and Bo Li. Agentpoison: Red-teaming LLM agents via poisoning memory or knowledge bases. CoRR, abs/2407.12784, 2024.
[587] Yifei Wang, Dizhan Xue, Shengjie Zhang, and Shengsheng Qian. Badagent: Inserting and activating backdoor attacks in LLM agents. In Lun-Wei Ku, Andre Martins, and Vivek Srikumar, editors, Proceedings of the 62nd Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), ACL 2024, Bangkok, Thailand, August 11-16, 2024, pages 9811-9827. Association for Computational Linguistics, 2024.
[588] Wenkai Yang, Xiaohan Bi, Yankai Lin, Sishuo Chen, Jie Zhou, and Xu Sun. Watch out for your agents! investigating backdoor threats to llm-based agents. CoRR, abs/2402.11208, 2024.
[589] Tian Dong, Minhui Xue, Guoxing Chen, Rayne Holland, Yan Meng, Shaofeng Li, Zhen Liu, and Haojin Zhu. The philosopher's stone: Trojaning plugins of large language models. In Network and Distributed System Security Sympo- sium, NDSS 2025. The Internet Society, 2025.
[590] Evan Hubinger, Carson Denison, Jesse Mu, Mike Lambert, Meg Tong, Monte MacDiarmid, Tamera Lanham, Daniel M. Ziegler, Tim Maxwell, Newton Cheng, Adam S. Jermyn, Amanda Askell, Ansh Radhakrishnan, Cem Anil, David Duvenaud, Deep Ganguli, Fazl Barez, Jack Clark, Kamal Ndousse, Kshitij Sachan, Michael Sellitto, Mrinank Sharma, Nova DasSarma, Roger Grosse, Shauna Kravec, Yuntao Bai, Zachary Witten, Marina Favaro, Jan Brauner, Holden Karnofsky, Paul F. Christiano, Samuel R. Bowman, Logan Graham, Jared Kaplan, So"ren Mindermann, Ryan Greenblatt, Buck Shlegeris, Nicholas Schiefer, and Ethan Perez. Sleeper agents: Training deceptive llms that persist through safety training. CoRR, abs/2401.05566, 2024.
[591] Zhiyuan Yu, Xiaogeng Liu, Shunning Liang, Zach Cameron, Chaowei Xiao, and Ning Zhang. Don't listen to me: Understanding and exploring jailbreak prompts of large language models. In Davide Balzarotti and Wenyuan Xu, edi- tors, 33rd USENIX Security Symposium, USENIX Security 2024, Philadelphia, PA, USA, August 14-16, 2024. USENIX Association, 2024.
[592] Jiahao Yu, Xingwei Lin, Zheng Yu, and Xinyu Xing. Llm-fuzzer: Scaling assessment of large language model jail- breaks. In Davide Balzarotti and Wenyuan Xu, editors, 33rd USENIX Security Symposium, USENIX Security 2024, Philadelphia, PA, USA, August 14-16, 2024. USENIX Association, 2024.
[593] Yi Liu, Gelei Deng, Zhengzi Xu, Yuekang Li, Yaowen Zheng, Ying Zhang, Lida Zhao, Tianwei Zhang, and Yang Liu. Jailbreaking chatgpt via prompt engineering: An empirical study. CoRR, abs/2305.13860, 2023.
[594] Alexander Wei, Nika Haghtalab, and Jacob Steinhardt. Jailbroken: How does LLM safety training fail? In Alice Oh, Tristan Naumann, Amir Globerson, Kate Saenko, Moritz Hardt, and Sergey Levine, editors, Advances in Neural Information Processing Systems 36: Annual Conference on Neural Information Processing Systems 2023, NeurIPS 2023, New Orleans, LA, USA, December 10-16, 2023, 2023.
[595] Zhuo Zhang, Guangyu Shen, Guanhong Tao, Siyuan Cheng, and Xiangyu Zhang. On large language models' resilience to coercive interrogation. In IEEE Symposium on Security and Privacy, SP 2024, San Francisco, CA, USA, May 19-23, 2024, pages 826-844. IEEE, 2024.
[596] Jiashu Xu, Mingyu Derek Ma, Fei Wang, Chaowei Xiao, and Muhao Chen. Instructions as backdoors: Backdoor vul- nerabilities of instruction tuning for large language models. In Kevin Duh, Helena Go'mez-Adorno, and Steven Bethard, editors, Proceedings of the 2024 Conference of the North American Chapter of the Association for Computational Lin- guistics: Human Language Technologies (Volume 1: Long Papers), NAACL 2024, Mexico City, Mexico, June 1621, 2024, pages 3111-3126. Association for Computational Linguistics, 2024.
[597] Shuai Zhao, Jinming Wen, Anh Tuan Luu, Junbo Zhao, and Jie Fu. Prompt as triggers for backdoor attack: Examining the vulnerability in language models. In Houda Bouamor, Juan Pino, and Kalika Bali, editors, Proceedings of the 2023 Conference on Empirical Methods in Natural Language Processing, EMNLP 2023, Singapore, December 6-10, 2023, pages 12303-12317. Association for Computational Linguistics, 2023.
[598] Xiangrui Cai, Haidong Xu, Sihan Xu, Ying Zhang, and Xiaojie Yuan. Badprompt: Backdoor attacks on continuous prompts. In Sanmi Koyejo, S. Mohamed, A. Agarwal, Danielle Belgrave, K. Cho, and A. Oh, editors, Advances in Neural Information Processing Systems 35: Annual Conference on Neural Information Processing Systems 2022, NeurIPS 2022, New Orleans, LA, USA, November 28 - December 9, 2022, 2022.
[599] Yanzhou Li, Tianlin Li, Kangjie Chen, Jian Zhang, Shangqing Liu, Wenhan Wang, Tianwei Zhang, and Yang Liu. Badedit: Backdooring large language models by model editing. In The Twelfth International Conference on Learning Representations, ICLR 2024, Vienna, Austria, May 7-11, 2024. OpenReview.net, 2024.
[600] Neel Jain, Avi Schwarzschild, Yuxin Wen, Gowthami Somepalli, John Kirchenbauer, Ping-yeh Chiang, Micah Gold- blum, Aniruddha Saha, Jonas Geiping, and Tom Goldstein. Baseline defenses for adversarial attacks against aligned language models. CoRR, abs/2309.00614, 2023.
[601] Xinxin Fan, Mengfan Li, Jia Zhou, Quanliang Jing, Chi Lin, Yunfeng Lu, and Jingping Bi. GCSA: A new adversarial example-generating scheme toward black-box adversarial attacks. IEEE Trans. Consumer Electron., 70(1):2038-2048, 2024.
[602] Baoli Wang, Xinxin Fan, Quanliang Jing, Yueyang Su, Jingwei Li, and Jingping Bi. GTAT: adversarial training with generated triplets. In International Joint Conference on Neural Networks, IJCNN 2022, Padua, Italy, July 18-23, 2022, pages 1-8. IEEE, 2022.
[603] Quanliang Jing, Shuo Liu, Xinxin Fan, Jingwei Li, Di Yao, Baoli Wang, and Jingping Bi. Can adversarial training benefit trajectory representation?: An investigation on robustness for trajectory similarity computation. In Mohammad Al Hasan and Li Xiong, editors, Proceedings of the 31st ACM International Conference on Information & Knowledge Management, Atlanta, GA, USA, October 17-21, 2022, pages 905-914. ACM, 2022.
[604] Tong Liu, Yingjie Zhang, Zhe Zhao, Yinpeng Dong, Guozhu Meng, and Kai Chen. Making them ask and answer: Jailbreaking large language models in few queries via disguise and reconstruction. In Davide Balzarotti and Wenyuan Xu, editors, 33rd USENIX Security Symposium, USENIX Security 2024, Philadelphia, PA, USA, August 14-16, 2024. USENIX Association, 2024.
[605] Ziwei Ji, Nayeon Lee, Rita Frieske, Tiezheng Yu, Dan Su, Yan Xu, Etsuko Ishii, Yejin Bang, Andrea Madotto, and Pascale Fung. Survey of hallucination in natural language generation. ACM Comput. Surv., 55(12):248:1-248:38, 2023.
[606] Yue Zhang, Yafu Li, Leyang Cui, Deng Cai, Lemao Liu, Tingchen Fu, Xinting Huang, Enbo Zhao, Yu Zhang, Yulong Chen, Longyue Wang, Anh Tuan Luu, Wei Bi, Freda Shi, and Shuming Shi. Siren's song in the AI ocean: A survey on hallucination in large language models. CoRR, abs/2309.01219, 2023.
[607] Nelson F. Liu, Kevin Lin, John Hewitt, Ashwin Paranjape, Michele Bevilacqua, Fabio Petroni, and Percy Liang. Lost in the middle: How language models use long contexts. Trans. Assoc. Comput. Linguistics, 12:157-173, 2024.
[608] Guilherme Penedo, Quentin Malartic, Daniel Hesslow, Ruxandra Cojocaru, Hamza Alobeidli, Alessandro Cappelli, Baptiste Pannier, Ebtesam Almazrouei, and Julien Launay. The refinedweb dataset for falcon LLM: outperforming curated corpora with web data only. In Alice Oh, Tristan Naumann, Amir Globerson, Kate Saenko, Moritz Hardt, and Sergey Levine, editors, Advances in Neural Information Processing Systems 36: Annual Conference on Neural Information Processing Systems 2023, NeurIPS 2023, New Orleans, LA, USA, December 10-16, 2023, 2023.
[609] Shaobo Li, Xiaoguang Li, Lifeng Shang, Zhenhua Dong, Chengjie Sun, Bingquan Liu, Zhenzhou Ji, Xin Jiang, and Qun Liu. How pre-trained language models capture factual knowledge? A causal-inspired analysis. In Smaranda Muresan, Preslav Nakov, and Aline Villavicencio, editors, Findings of the Association for Computational Linguistics: ACL 2022, Dublin, Ireland, May 22-27, 2022, pages 1720-1732. Association for Computational Linguistics, 2022.
[610] Nick McKenna, Tianyi Li, Liang Cheng, Mohammad Javad Hosseini, Mark Johnson, and Mark Steedman. Sources of hallucination by large language models on inference tasks. In Houda Bouamor, Juan Pino, and Kalika Bali, editors, Findings of the Association for Computational Linguistics: EMNLP 2023, Singapore, December 6-10, 2023, pages 2758-2774. Association for Computational Linguistics, 2023.
[611] Saurav Kadavath, Tom Conerly, Amanda Askell, Tom Henighan, Dawn Drain, Ethan Perez, Nicholas Schiefer, Zac Hatfield-Dodds, Nova DasSarma, Eli Tran-Johnson, Scott Johnston, Sheer El Showk, Andy Jones, Nelson Elhage, Tristan Hume, Anna Chen, Yuntao Bai, Sam Bowman, Stanislav Fort, Deep Ganguli, Danny Hernandez, Josh Jacobson, Jackson Kernion, Shauna Kravec, Liane Lovitt, Kamal Ndousse, Catherine Olsson, Sam Ringer, Dario Amodei, Tom Brown, Jack Clark, Nicholas Joseph, Ben Mann, Sam McCandlish, Chris Olah, and Jared Kaplan. Language models (mostly) know what they know. CoRR, abs/2207.05221, 2022.
[612] Zhangyue Yin, Qiushi Sun, Qipeng Guo, Jiawen Wu, Xipeng Qiu, and Xuanjing Huang. Do large language models know what they don't know? In Anna Rogers, Jordan L. Boyd-Graber, and Naoaki Okazaki, editors, Findings of the As- sociation for Computational Linguistics: ACL 2023, Toronto, Canada, July 9-14, 2023, pages 8653-8665. Association for Computational Linguistics, 2023.
[613] Claire Gardent, Anastasia Shimorina, Shashi Narayan, and Laura Perez-Beltrachini. Creating training corpora for NLG micro-planners. In Regina Barzilay and Min-Yen Kan, editors, Proceedings of the 55th Annual Meeting of the Association for Computational Linguistics, ACL 2017, Vancouver, Canada, July 30 - August 4, Volume 1: Long Papers, pages 179-188. Association for Computational Linguistics, 2017.
[614] Stephanie Lin, Jacob Hilton, and Owain Evans. Truthfulqa: Measuring how models mimic human falsehoods. In Smaranda Muresan, Preslav Nakov, and Aline Villavicencio, editors, Proceedings of the 60th Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), ACL 2022, Dublin, Ireland, May 22-27, 2022, pages 3214-3252. Association for Computational Linguistics, 2022.
[615] Sina Zarrieß, Henrik Voigt, and Simeon Schu"z. Decoding methods in neural language generation: A survey. Inf., 12(9):355, 2021.
[616] Nayeon Lee, Wei Ping, Peng Xu, Mostofa Patwary, Pascale Fung, Mohammad Shoeybi, and Bryan Catanzaro. Factu- ality enhanced language models for open-ended text generation. In Sanmi Koyejo, S. Mohamed, A. Agarwal, Danielle Belgrave, K. Cho, and A. Oh, editors, Advances in Neural Information Processing Systems 35: Annual Conference on Neural Information Processing Systems 2022, NeurIPS 2022, New Orleans, LA, USA, November 28 - December 9, 2022, 2022.
[617] Shehzaad Dhuliawala, Mojtaba Komeili, Jing Xu, Roberta Raileanu, Xian Li, Asli Celikyilmaz, and Jason Weston. Chain-of-verification reduces hallucination in large language models. In LunWei Ku, Andre Martins, and Vivek Sriku- mar, editors, Findings of the Association for Computational Linguistics, ACL 2024, Bangkok, Thailand and virtual meeting, August 11-16, 2024, pages 3563-3578. Association for Computational Linguistics, 2024.
[618] Kenneth Li, Oam Patel, Fernanda B. Vie'gas, Hanspeter Pfister, and Martin Wattenberg. Inferencetime intervention: Eliciting truthful answers from a language model. In Alice Oh, Tristan Naumann, Amir Globerson, Kate Saenko, Moritz Hardt, and Sergey Levine, editors, Advances in Neural Information Processing Systems 36: Annual Conference on Neural Information Processing Systems 2023, NeurIPS 2023, New Orleans, LA, USA, December 10-16, 2023, 2023.
[619] Miao Xiong, Zhiyuan Hu, Xinyang Lu, YIFEI LI, Jie Fu, Junxian He, and Bryan Hooi. Can llms express their uncer- tainty? an empirical evaluation of confidence elicitation in llms. In The Twelfth International Conference on Learning Representations, 2024.
[620] Reza Shokri, Marco Stronati, Congzheng Song, and Vitaly Shmatikov. Membership inference attacks against machine learning models. In 2017 IEEE symposium on security and privacy (SP), pages 3-18, 2017.
[621] Nicholas Carlini, Florian Trame`r, Eric Wallace, Matthew Jagielski, Ariel Herbert-Voss, Katherine Lee, Adam Roberts, Tom B. Brown, Dawn Song, Ú lfar Erlingsson, Alina Oprea, and Colin Raffel. Extracting training data from large language models. In Michael D. Bailey and Rachel Greenstadt, editors, 30th USENIX Security Symposium, USENIX Security 2021, August 11-13, 2021, pages 2633-2650. USENIX Association, 2021.
[622] Justus Mattern, Fatemehsadat Mireshghallah, Zhijing Jin, Bernhard Scho"lkopf, Mrinmaya Sachan, and Taylor Berg- Kirkpatrick. Membership inference attacks against language models via neighbourhood comparison. In Anna Rogers, Jordan L. Boyd-Graber, and Naoaki Okazaki, editors, Findings of the Association for Computational Linguistics: ACL 2023, Toronto, Canada, July 914, 2023, pages 11330-11343. Association for Computational Linguistics, 2023.
[623] Boxin Wang, Weixin Chen, Hengzhi Pei, Chulin Xie, Mintong Kang, Chenhui Zhang, Chejian Xu, Zidi Xiong, Ritik Dutta, Rylan Schaeffer, Sang T. Truong, Simran Arora, Mantas Mazeika, Dan Hendrycks, Zinan Lin, Yu Cheng, Sanmi Koyejo, Dawn Song, and Bo Li. Decodingtrust: A comprehensive assessment of trustworthiness in GPT models. In Alice Oh, Tristan Naumann, Amir Globerson, Kate Saenko, Moritz Hardt, and Sergey Levine, editors, Advances in Neural Information Processing Systems 36: Annual Conference on Neural Information Processing Systems 2023, NeurIPS 2023, New Orleans, LA, USA, December 10-16, 2023, 2023.
[624] Dan Hendrycks, Collin Burns, Steven Basart, Andrew Critch, Jerry Li, Dawn Song, and Jacob Steinhardt. Aligning AI with shared human values. In 9th International Conference on Learning Representations, ICLR 2021, Virtual Event, Austria, May 3-7, 2021. OpenReview.net, 2021.
[625] Yi Liu, Gelei Deng, Zhengzi Xu, Yuekang Li, Yaowen Zheng, Ying Zhang, Lida Zhao, Tianwei Zhang, and Yang Liu. Jailbreaking chatgpt via prompt engineering: An empirical study. CoRR, abs/2305.13860, 2023.
[626] Zhijing Jin, Sydney Levine, Fernando Gonzalez Adauto, Ojasv Kamal, Maarten Sap, Mrinmaya Sachan, Rada Mihalcea, Josh Tenenbaum, and Bernhard Scho"lkopf. When to make exceptions: Exploring language models as accounts of human moral judgment. In Sanmi Koyejo, S. Mohamed, A. Agarwal, Danielle Belgrave, K. Cho, and A. Oh, editors, Advances in Neural Information Processing Systems 35: Annual Conference on Neural Information Processing Systems 2022, NeurIPS 2022, New Orleans, LA, USA, November 28 - December 9, 2022, 2022.
[627] Kexin Huang, Xiangyang Liu, Qianyu Guo, Tianxiang Sun, Jiawei Sun, Yaru Wang, Zeyang Zhou, Yixu Wang, Yan Teng, Xipeng Qiu, Yingchun Wang, and Dahua Lin. Flames: Benchmarking value alignment of llms in chinese. In Kevin Duh, Helena Go'mez-Adorno, and Steven Bethard, editors, Proceedings of the 2024 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies (Volume 1: Long Papers), NAACL 2024, Mexico City, Mexico, June 16-21, 2024, pages 4551-4591. Association for Computational Linguistics, 2024.
[628] Jingnan Zheng, Han Wang, An Zhang, Tai D. Nguyen, Jun Sun, and Tat-Seng Chua. Ali-agent: Assessing llms’ align- ment with human values via agent-based evaluation. In Amir Globersons, Lester Mackey, Danielle Belgrave, Angela Fan, Ulrich Paquet, Jakub M. Tomczak, and Cheng Zhang, editors, Advances in Neural Information Processing Sys- tems 38: Annual Conference on Neural Information Processing Systems 2024, NeurIPS 2024, Vancouver, BC, Canada, December 10-15, 2024, 2024.
[629] Jiyoung Lee, Minwoo Kim, Seungho Kim, Junghwan Kim, Seunghyun Won, Hwaran Lee, and Edward Choi. Kornat: LLM alignment benchmark for korean social values and common knowledge. In Lun-Wei Ku, Andre Martins, and Vivek Srikumar, editors, Findings of the Association for Computational Linguistics, ACL 2024, Bangkok, Thailand and virtual meeting, August 11-16, 2024, pages 11177-11213. Association for Computational Linguistics, 2024.
[630] Fan Bu, Zheng Wang, Siyi Wang, and Ziyao Liu. An investigation into value misalignment in llmgenerated texts for cultural heritage. CoRR, abs/2501.02039, 2025.
[631] Soroush Vosoughi, Deb Roy, and Sinan Aral. The spread of true and false news online. science, 359(6380):1146-1151, 2018.
[632] Yizhou Zhang, Karishma Sharma, Lun Du, and Yan Liu. Toward mitigating misinformation and social media manipu- lation in llm era. In Companion Proceedings of the ACM on Web Conference 2024, pages 1302-1305, 2024.
[633] Adam DI Kramer, Jamie E Guillory, and Jeffrey T Hancock. Experimental evidence of massivescale emotional conta- gion through social networks. Proceedings of the National Academy of Sciences, 111(24):8788-8790, 2014.
[634] Karan Singhal, Tao Tu, Juraj Gottweis, Rory Sayres, Ellery Wulczyn, Mohamed Amin, Le Hou, Kevin Clark, Stephen R Pfohl, Heather Cole-Lewis, et al. Toward expert-level medical question answering with large language models. Nature Medicine, pages 1-8, 2025.
[635] Yikai Chen, Xiujie Huang, Fangjie Yang, Haiming Lin, Haoyu Lin, Zhuoqun Zheng, Qifeng Liang, Jinhai Zhang, and Xinxin Li. Performance of chatgpt and bard on the medical licensing examinations varies across different cultures: a comparison study. BMC Medical Education, 24(1):1372, 2024.
[636] Jiaming Ji, Tianyi Qiu, Boyuan Chen, Borong Zhang, Hantao Lou, Kaile Wang, Yawen Duan, Zhonghao He, Jiayi Zhou, Zhaowei Zhang, et al. Ai alignment: A comprehensive survey. arXiv preprint arXiv:2310.19852, 2023.
[637] Jing Yao, Xiaoyuan Yi, Shitong Duan, Jindong Wang, Yuzhuo Bai, Muhua Huang, Peng Zhang, Tun Lu, Zhicheng Dou, Maosong Sun, et al. Value compass leaderboard: A platform for fundamental and validated evaluation of llms values. arXiv preprint arXiv:2501.07071, 2025.
[638] Shalom H Schwartz. An overview of the schwartz theory of basic values. Online readings in Psychology and Culture, 2(1):11, 2012.