MARLlib¶
MARLlib: 一个可扩展且高效的多智能体强化学习库¶
摘要¶
多智能体强化学习(MARL)研究人员面临的一个重大挑战在于,如何找到一个能够为多智能体任务和算法组合提供快速且兼容开发的库,而无需考虑兼容性问题。在本文中,我们提出了MARLlib,这一库旨在通过以下三种关键机制来解决上述挑战:1)标准化的多智能体环境封装器,2)基于智能体级别的算法实现,3)灵活的策略映射策略。通过利用这些机制,MARLlib能够有效地解耦多智能体任务与算法学习过程之间的交织关系,并能够根据当前任务的属性自动调整训练策略。MARLlib库的源代码已在GitHub上公开获取:https://github.com/Replicable-MARL/MARLlib。
Keywords: Multi-agent Reinforcement Learning, Software, Open-Source, Ray, RLlib
关键词: 多智能体强化学习, 软件, 开源, Ray, RLlib
1. 引言¶
多智能体强化学习(MARL)因其在现实世界应用中的潜力以及增强集体智能的能力而受到了广泛关注(Busoniu et al., 2008; Yang and Wang, 2020; Zhang et al., 2021)。早期的研究表明,智能体能够学习出超越人类专家的策略,并以逆向方式辅助人类决策(Vinyals et al., 2019; Baker et al., 2020)。
尽管在单智能体强化学习方面已经取得了显著进展(Dhariwal et al., 2017; Liang et al., 2018; Weng et al., 2022),但开发一个全面且高质量的MARL库仍面临独特的挑战。一个主要的挑战在于缺乏用于评估新思想的标准数据集,不同于图像分类等领域可以使用ImageNet这样的代表性数据集(Deng et al., 2009)。MARL数据集涵盖了可定制的场景,包括不同的智能体数量、地图大小、奖励函数和单元状态,这使得难以建立统一的研究起点。为MARL社区创建统一且可扩展的测试套件的努力已经出现,例如PettingZoo(Terry et al., 2021)和Melting Pot(Leibo et al., 2021)。然而,实际挑战仍然存在,包括底层数据结构的差异,这需要对学习流程进行调整,从而影响算法的性能和可靠性。
另一个重要挑战源于多智能体环境与算法之间的内在不兼容性。例如,在单一环境中共存的合作和竞争学习目标,阻碍了仅为合作设计的算法的直接应用。此外,某些算法可能需要额外的任务信息(如全局状态),从而使其无法在缺乏此类数据的环境中使用。因此,现有的库(Papoudakis et al., 2021; Hu et al., 2023; Yu et al., 2022)在任务覆盖范围有限、缺乏算法统一性,导致可扩展性差、代码结构臃肿(见表1)。
因此,开发一个能够有效解耦环境与算法、确保兼容性并为MARL提供标准测试套件的通用学习框架至关重要。本文介绍的MARLlib,结合了Ray(Moritz et al., 2018)和RLlib(Liang et al., 2018)的核心优势,并引入了新的特性。这些特性包括标准化的多智能体环境封装器、基于智能体级别的算法实现和灵活的策略映射策略。MARLlib为MARL研究社区提供了一个可扩展且高效的框架,使其能够在多样化的多智能体环境中构建、训练和评估MARL算法。
表1:当前MARL库与我们提出的MARLlib的对比。
| 库 | 支持的环境 | 算法 | 参数共享 | 智能体结构 | 框架 |
|---|---|---|---|---|---|
| PyMARL | 1 合作 | 5 | 共享 | GRU | PyMARL |
| PyMARL2 | 2 合作 | 11 | 共享 | MLP+GRU | PyMARL |
| MARLAlgorithms | 1 合作 | 9 | 共享 | MLP+GRU | MARL-Algorithms |
| EPyMARL | 4 合作 | 9 | 共享 + 分离 | GRU | PyMARL |
| MAlib | 4 自博弈 | 9 | 共享 + 分组 + 分离 | MLP+LSTM | MAlib |
| MAPPO | 4 合作 | 1 | 共享 + 分离 | MLP+GRU+CNN | pytorch-a2c-ppo-acktr -gail (Kostrikovk, 2018) |
| MARLlib | 15+ 无限制 | 18 | 共享+分组+分离 可定制 | MLP+LSTM+GRU +CNN | Ray (Moritz et al., 2018) RLlib (Liang et al., 2018) |
2. MARLlib的设计¶
MARLlib的架构由三个关键组成部分构成:1)用于统一多智能体环境的标准化封装器;2)在智能体级别实现的算法数据流;3)用于解决任务与多智能体学习过程之间可能出现的兼容性问题的灵活策略映射策略。
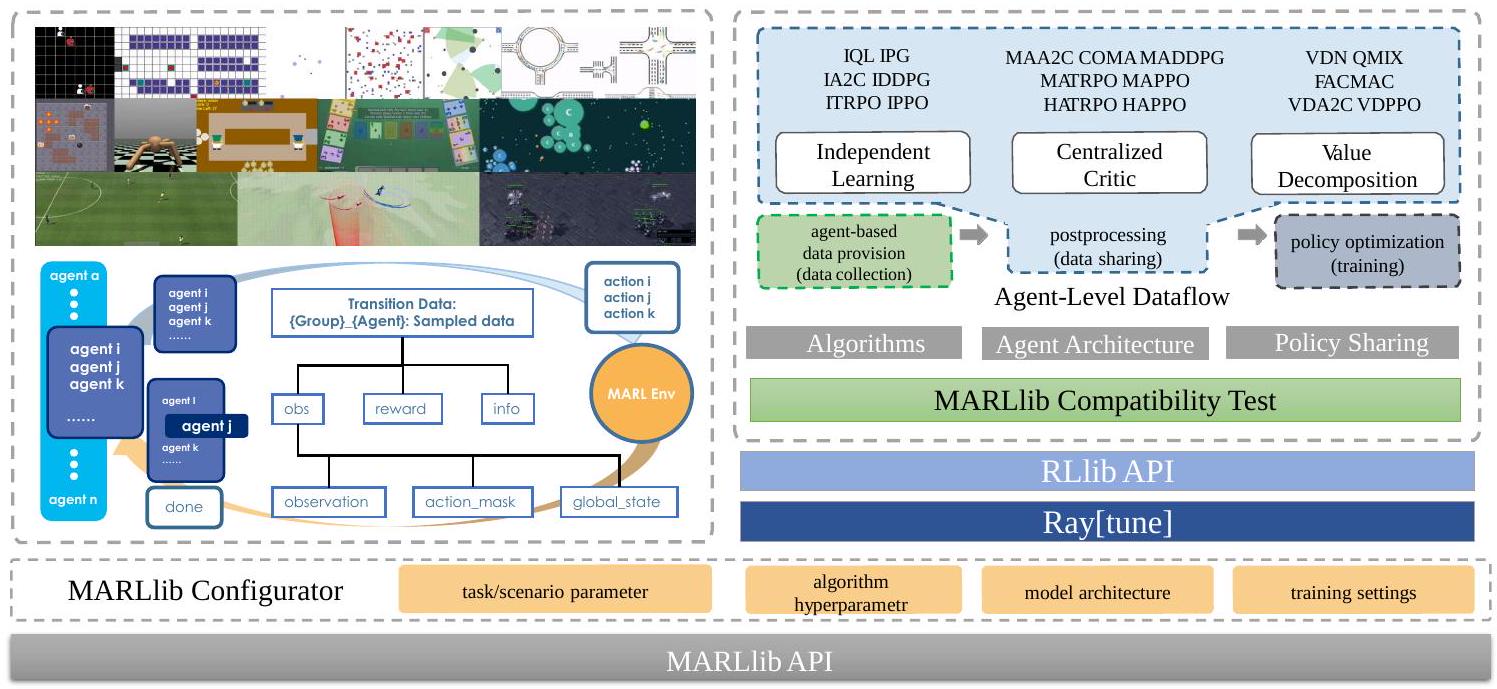
图1:MARLlib概览——一个将算法与任务集成到统一框架中的框架。
多智能体环境封装器。 标准化的智能体-环境交互方式,例如Gym(Brockman et al., 2016),能够有效地将环境与算法分离,从而使学习过程与任务保持解耦。然而,将这种方法扩展到多智能体场景并非易事。具体而言,必须解决两个主要问题。首先,多智能体环境返回的数据结构可能存在显著差异,这给算法侧学习流程的设计带来了挑战。其次,由于智能体可能需要同时或异步行动,因此必须具备灵活的数据收集过程。鉴于此,开发一个新的多智能体环境封装器成为当务之急。
为了解决第一个问题,有必要考虑多智能体任务中的通用数据提供方式。在检查其数据结构时,我们发现了以下显著差异: 1) 数据提供的不一致,一些非普遍必需的信息可能缺失(如全局状态和动作掩码); 2) 奖励提供的格式,既可能是标量(如团队奖励),也可能是集合(每个智能体获得自身的奖励); 3) 每个智能体的数据是带有智能体ID标记,还是集中收集而无标记。
为解决这些差异,我们提出了一个通用的环境封装器,可以有效地缓解不同多智能体任务之间的差异,并使其对齐为相似的数据提供方式。这包括三个关键步骤: 1) 将非普遍数据(如全局状态)纳入观测; 2) 复制并分配奖励给每个智能体以确保公平性; 3) 为所有收集的数据加上智能体ID标记,使每个智能体能够管理自己的数据并与其他智能体保持一致。
针对第二个问题,我们利用了RLlib提供的高级数据收集机制。在这种方法中,每个智能体独立收集数据,并将采样数据保存在其各自的缓冲区中。智能体之间不需要在同一时间点完成数据采样。当完成信号(done)转变为True时,表示所有智能体的采样过程完成,一个采样回合结束。通过解决这两个问题,MARLlib的任务侧被精心设计为能够灵活但标准化地收集数据,从而为算法侧提供清晰且一致的源数据风格。通过整合这一方法,MARLlib使算法侧能够有效利用任务侧提供的优势,从而实现可扩展的多智能体学习。
智能体级别数据流。 新的环境封装器在智能体级别统一了数据提供方式,如果算法侧也能以这种方式实现,就能实现无缝数据流。关键问题在于,MARL算法是否能够转化为智能体级别的学习过程。在MARLlib中,我们主要关注去中心化部分可观测马尔可夫决策过程(Dec-POMDP)(Oliehoek and Amato, 2016)以及三种典型的学习风格:独立学习(IL)、集中式评价器(CC)和价值分解(VD)。其他算法可以从这三种扩展,以满足不同的训练需求。图3展示了MARL过程在智能体级别的视角。对于IL,学习过程可以自然地分解为智能体级数据流,因为一个智能体将其他智能体视为环境的一部分,从而保持独立性。对于CC,在后处理阶段共享信息以形成集中式输入,可以将CC流程转化为智能体级数据流。对于VD,在进入训练阶段之前交换预测的\(\mathrm{Q}\)/评价值,可以使混合价值函数在单个智能体上运行,从而将VD流程转化为智能体级数据流。关于集中式与智能体级数据流等价性的更详细讨论见附录H.4。
策略映射策略。 在环境侧建立了基于智能体的数据提供方式,并在算法侧建立了智能体级别的数据流之后,就有必要设计一种机制来管理两者之间的数据流,确保智能体正确地分配到各自的学习目标。在这方面,我们利用并扩展了RLlib的策略映射API,并将策略构建标准化为三个步骤:(i)由环境侧提供策略映射字典,用于描述任务抽象、智能体分组和参数共享的限制;(ii)从默认设置中选择合适的策略,包括全共享、不共享和分组共享,或由用户自定义;(iii)由算法侧验证所选择的策略映射策略的合法性。
其他值得注意的特性包括自动化模型构建、彻底解耦的配置框架、方便的插件式策略切换,以及自动兼容性评估。值得注意的是,MARLlib配套提供了完整的文档,涵盖四个不同部分:MARLlib手册、面向MARL领域新手的指导、算法文档,以及对MARL方法的广泛综述。此外,还开展了多种基于MARLlib的实验性工作。
3. 结论¶
在本文中,我们提出了MARLlib,一个统一的库套件,涵盖了MARL领域中的大量算法和任务。这个全面的库套件旨在为训练、评估和比较MARL算法提供一个可靠而完整的工具集。MARL社区可以利用MARLlib构建多样化的多智能体应用。此外,MARLlib还可以作为新研究人员的教育平台,并为MARL研究领域的发展作出贡献。
致谢¶
本工作由以下项目资助:中国国家重点研发计划(2022ZD0114900)、北京市科学技术委员会(Z221100003422004)、中国科协青年人才托举工程(2022QNRC002)、山东省杰出青年基金(ZR2021YQ44)、山东省“泰山学者青年专家计划”。
附录¶
附录A. 安装¶
MARLlib的安装分为两部分:常规安装和外部环境安装。我们已在Python 3.8、Ubuntu 18.04和Ubuntu 20.04上测试过安装。
A.1 安装依赖(基础)¶
我们强烈建议使用conda来管理依赖并避免版本冲突。以下是基于Python 3.8构建conda环境的示例。
$ conda create -n marllib python=3.8
$ conda activate marllib
$ git clone https://github.com/Replicable-MARL/MARLlib.git
$ cd MARLlib
$ pip install --upgrade pip
$ pip install -r requirements.txt
# 建议始终保持gym版本为0.21.0
$ pip install gym==0.21.0
# 向MARLlib添加补丁文件
$ python patch/add_patch.py -y
A.2 安装环境(可选)¶
外部环境不会自动集成。但你可以通过参考该链接进行安装。我们建议始终保持gym版本为0.21.0,这是所有集成任务的兼容版本。
附录B. 库的使用¶
from marllib import marl
# 准备环境
env = marl.make_env(environment_name="mpe", map_name="simple_spread")
# 使用指定的超参数初始化算法
mappo = marl.algos.mappo(hyperparam_source="mpe")
# 基于环境+算法+用户偏好构建智能体模型
model = marl.build_model(env, mappo, {"core_arch": "mlp", "encode_layer": "128-256"})
# 开始训练
mappo.fit(
env, model,
stop={"timesteps_total": 1000000},
checkpoint_freq=100,
share_policy="group"
)
# 渲染
mappo.render(
env, model,
local_mode=True,
restore_path={'params_path': "checkpoint_000010/params.json",
'model_path': "checkpoint_000010/checkpoint-10"}
)
MARLlib提供了一个API,具有用户友好的编程接口,在简化库使用的同时,仍保持高度的可扩展性,以便用户自定义。这使研究人员能够专注于他们的具体研究目标,而不会被实现细节所困扰。
附录C. 训练效率¶
我们进行了实验,以展示MARLlib相较于EPyMARL和基线(官方MAPPO (Yu et al., 2022))的效率。实验在一台本地服务器上进行,配置为NVIDIA RTX A6000 GPU和AMD Ryzen Threadripper PRO 5945WX 12核CPU。测试场景为SMAC (Samvelyan et al., 2019)中的MMM2,测试算法为MAPPO。总采样步数为\(10^{6}\)。
从表2可以明显看出,MARLlib在时钟时间上显著优于其他框架。然而,训练速度的提升伴随着相对更高的内存使用和GPU显存使用。这部分归因于Ray/RLlib的调度机制,其中数据会在GPU上缓存,只要GPU仍有可用内存。此外,由于在MARLlib中要求每个智能体维护自己的数据缓冲区(这是处理竞争和混合等任务模式的前提),因此其内存使用高于其他两个框架。
表2:EPyMARL、MAPPO和MARLlib在效率与硬件使用上的比较
| 框架 | 时钟时间 (分:秒) | 内存 (GB) | GPU显存 (MB) |
|---|---|---|---|
| EPyMARL (thread=5/10/15) | 5:29/3:14/2:24 | 8.4/12.3/15.8 | 2245/2309/2329 |
| MAPPO (thread=5/10/15) | 5:12/3:13/2:42 | 8.9/12.3/16.3 | 2157/2277/2389 |
| MARLlib (worker=5/10/15) | 3:29/2:16/1:24 | 11.2/15.4/20.4 | 5025/5327/5351 |
附录D. 参数¶
在MARLlib中,初始化算法时可选择三类超参数:common、finetuned和test。
- common: 适用于在新任务上进行常规训练,此时最优超参数未知。
- finetuned: 建议用于与其他算法在常用MARL任务(如MPE和SMAC)上进行公平比较。
- test: 用于开发和测试新算法,或引入新的多智能体环境。
你可以通过访问该链接找到所有可用参数。
附录E. 与RLlib的关系¶
MARLlib与RLlib关系紧密,MARLlib建立在RLlib提供的基础之上。MARLlib专门在多智能体强化学习(MARL)领域扩展和增强了RLlib的能力。它利用了RLlib的基础设施,包括其多智能体任务接口,从而为MARL实验创建了统一且兼容的智能体-环境接口。这种关系使研究人员和开发者既能受益于RLlib的通用性与功能性,又能利用MARLlib为MARL任务提供的专门特性和优化。
在下文中,我们将讨论RLlib在多智能体学习中的挑战,以及MARLlib提出的重大改进,使其不仅仅是RLlib的“即插即用”扩展,而是一个全面的库。
E.1 RLlib多智能体场景的挑战¶
虽然RLlib为强化学习提供了强大的基础设施,但其多智能体场景存在一些挑战,导致使用起来并不十分高效。这些挑战主要源于:
- 缺乏标准化和统一的智能体-环境接口:多智能体强化学习涉及多个智能体与环境的交互,这增加了接口设计的复杂性。而RLlib的多智能体场景缺乏统一的接口,缺少清晰的规范来表示和交换智能体与环境间的信息,从而阻碍了不同MARL算法的开发和比较。
- 复杂性与新手可访问性差:在RLlib中,多智能体场景\({ }^{1}\)通常需要对底层框架有深入理解,这使得它对多智能体强化学习的新手而言不够友好。有效利用RLlib的多智能体功能需要先掌握高级RL概念,这对新入门的研究人员和实践者形成了障碍。
- 缺乏统一的算法集成点:RLlib的多智能体场景在设计上没有针对不同算法的统一集成点。这导致在RLlib中有效比较和结合不同的MARL算法变得困难。研究人员和实践者在实现和评估自己的算法时缺乏标准化方式,从而阻碍了该领域的进展与合作。
解决这些挑战对推动多智能体强化学习研究至关重要,需要努力简化并提升RLlib多智能体场景的可用性,为研究人员和开发者提供一个更易访问、更高效的实验框架。
1
示例见此链接: https://github.com/ray-project/ray/blob/master/rllib/examples/multi_agent_custom_policy.py
E.2 MARLlib vs RLlib¶
MARLlib基于RLlib的基础,并解决了RLlib在多智能体场景中的不足,为多智能体强化学习领域带来了显著改进。
表3:MARLlib与RLlib在多智能体场景下的比较
| 特性 | MARLlib | RLlib |
|---|---|---|
| 任务接口与转移数据 | 结构化 | 模糊且灵活 |
| 多智能体算法支持 | 标准CTDE | 简单扩展RL |
| 策略映射与共享 | 自动 | 手动 |
| 可扩展性与互操作性 | 继承 | \(\checkmark\) |
| 新手可访问性 | 简单 | 困难 |
| 自动适配与兼容性测试 | \(\checkmark\) | \(\times\) |
| 实验与基准测试 | \(\checkmark\) | 有限 |
| 文档与教程 | 全面 | 有限 |
MARLlib与RLlib的关系类似于TensorFlow(Abadi et al., 2016)与Keras(Chollet et al., 2015)的集成与功能互补。Keras作为高级神经网络API,利用TensorFlow作为高效后端执行与优化。同样,MARLlib利用RLlib的强化学习基础设施,通过其用户友好的API高效开发多智能体系统。这种关系简化了开发流程,在抽象复杂性的同时,仍能充分利用强大的机器学习与强化学习能力。
MARLlib对RLlib的主要贡献包括:
1. 提供统一且兼容的智能体-环境接口,简化了多智能体算法的数据使用,覆盖更广泛的任务,从而提升效率和实现便利性。
2. 利用RLlib的智能体抽象与分类能力,通过改进信息共享阶段,确保算法间的有效共享与兼容性,推动在统一框架下的算法集成。它基于RLlib可靠的单智能体RL实现,只需在多智能体场景下进行必要调整。
3. 为新手提供友好的学习途径,通过简化的API处理多智能体任务与算法之间的兼容性,使用户能够专注于核心组件(如算法、任务和模型选择)。同时,这种易用性并不限制MARLlib学习流程的扩展或修改,用户仍可引入新环境\({ }^{2}\)、自定义策略共享\({ }^{3}\),或修改信息共享阶段,以定义不同的观测共享方式。这些特性使用户能够根据MARLlib的灵活性来定制自己的实验。
此外,MARLlib还为用户提供了新的功能,包括流程自动适配与训练兼容性测试,并配备了关于多智能体强化学习的完整文档。
附录F. 相关工作¶
在机器学习领域,人们普遍认为评估一个新想法需要使用合适的数据集。常见的方法是采用一个具有代表性或广泛接受的数据集,遵循其既定的评估流程,并将新方法的性能与现有算法进行比较。一个显著的例子是ImageNet数据集(Deng et al., 2009),它作为图像分类这一计算机视觉基本任务的基准,在深度学习兴起后的近十年里一直发挥着核心作用。
然而,这种范式并不容易直接应用于多智能体强化学习(MARL)。在MARL的语境中,数据集对应于构成多智能体任务的一系列场景。多智能体任务具有高度的可定制性,涵盖了智能体数量、地图大小、奖励函数和单元状态等多方面。多智能体任务或环境的可能调整范围极为广泛,而且不断有新的任务和环境出现。因此,对于该领域的新手而言,选择一个合适的研究起点至关重要:首先需要确定一组广泛使用的多智能体数据集,然后尝试在现有成果的基础上进行改进。这一方法已在近期的MARL论文中普遍采用,常见的标准化基准与测试套件包括MPE、SMAC和MAMuJoCo。
然而,需要指出的是,一个算法的优劣不应仅通过其在特定任务上的表现来衡量。事实上,围绕MARL算法究竟应专注于在单一任务中表现出色,还是在多个任务中均保持较强性能的讨论一直存在,这一困境通常被称为“算法优先还是任务优先”的难题。MARLlib倾向于“算法优先”的观点,因为我们认为这种方式更便于其他用户复现和比较算法,从而促进可信的解决方案推动该领域的发展。
遵循“算法优先”的原则,亟需构建一个全面的标准化多智能体任务集合,并配套一个统一的算法学习流程。在这里,我们从任务侧和算法侧两个角度回顾MARL社区所做的贡献。
在任务侧,一些值得注意的工作如PettingZoo(Terry et al., 2021)和Melting Pot(Leibo et al., 2021),旨在为MARL社区创建统一且可扩展的测试套件。然而,实际挑战依然存在。例如,在PettingZoo中,接口在高层(智能体-环境接口)看似统一,但在低层(内部数据结构)却存在差异。因此,无法直接将返回的数据输入学习流程,必须调整学习流程以适应每个任务的特性。这些调整的实现方式在算法性能中发挥着关键作用,从而显著影响算法学习曲线的可靠性。另一个重要挑战在于PettingZoo等接口与常见的MARL任务(如SMAC (Samvelyan et al., 2019),即完整游戏StarCraft II (Silver et al., 2018)的轻量化版本)之间存在不兼容性,这使得跨不同测试套件评估算法变得困难。
尽管如此,已有的库通过放弃任务侧接口的统一性来支持多任务。例如,MAPPO官方实现为每个不同任务创建了单独的runner。截至目前,MAPPO基准支持四个环境,并因此准备了超过六个runner文件,包括共享和非共享模式\({ }^{4}\)。然而,这种方法存在局限性,因为新任务不断涌现,使得维护大量runner变得不切实际。
在讨论了任务侧的当前进展后,我们将注意力转向算法侧。我们的目标不是在算法层面比较孰优孰劣,而是探讨过去将尽可能多的算法纳入统一框架的努力。表1展示了部分相关框架的对比。在此我们对每个框架做简要介绍:
- PyMARL (Samvelyan et al., 2019) 是第一个也是最知名的MARL库。PyMARL中的所有算法均针对SMAC (Samvelyan et al., 2019)构建,在该环境中智能体通过合作获得更高的团队奖励。然而,PyMARL已长期未更新,无法跟上最新进展。为此,提出了PyMARL的扩展版本,包括PyMARL2 (Hu et al., 2023)和EPyMARL (Papoudakis et al., 2021)。
- PyMARL2 (Hu et al., 2023) 是PyMARL的扩展,仍然专注于信用分配机制。它提供了一个经过调优的QMIX (Rashid et al., 2018),在SMAC上达到了最新的性能表现。可用算法数量增加到十个,并引入了更多代码层面的技巧。
- MARL-Algorithms (MARL-Algorithms, 2019) 是一个涵盖范围比PyMARL更广的库,包括更优信用分配、基于通信的学习、基于图的学习和多任务课程学习等主题。每个主题至少有一个算法,共实现了九个算法。其测试环境仍局限于SMAC,一个合作型多智能体基准。
- EPyMARL (Papoudakis et al., 2021) 是PyMARL的另一个扩展,旨在提供关于如何统一合作型MARL算法的全面视角。它首次提出了独立学习、价值分解和集中式评价器的分类,但仅限于合作设置。EPyMARL中实现了九个算法,并引入了三个合作环境LBF (Christianos et al., 2020)、RWARE (Christianos et al., 2020)和MPE (Lowe et al., 2017),用于评估合作型MARL算法。
- MAPPO基准 (Yu et al., 2022) 是MAPPO的官方代码库,专注于合作型MARL,涵盖了包括SMAC、MPE、Hanabi (Bard et al., 2020)和Google Research Football (Kurach et al., 2020)在内的四个环境。其目标是构建强大的基线,仅包含MAPPO。
- MAlib (Zhou et al., 2023) 是一个较新的面向种群的MARL库,它结合博弈论与MARL来解决元博弈范围内的多智能体任务。
现有的库与基准为在不同环境中开发和比较MARL算法提供了良好平台。然而,这些工作仍存在关键局限。首先,由于缺乏统一的智能体-环境接口,它们在任务覆盖方面受到限制,如前所述。其次,现有研究对算法组织方式关注较少,主要专注于实现已有算法。这导致算法侧学习流程的可扩展性较差,代码结构臃肿。
附录G. MARLlib在任务侧统一化的解决方案¶
社区的一个重要经验教训是,统一化必须建立在标准化任务套件接口的基础上,该接口需要标准化采样阶段,同时确保与不同任务及其相应数据结构的内在特性兼容。
正如本文主体所强调的,MARLlib的智能体-环境接口成功实现了多样化多智能体任务与多种MARL算法类型的无缝集成。在接下来的部分中,我们将深入探讨MARLlib接口的能力,展示其在处理不同任务和数据格式的复杂需求时如何保持数据一致性。
G.1 对任务特性的支持¶
MARLlib的接口支持广泛的任务特性,包括多种学习模式(合作、协作、竞争、混合)、可观测性水平(完全、部分)、动作空间(离散、连续、多离散)、观测空间维度(1D、2D)、动作掩码、是否存在全局状态以及奖励类型(稠密、稀疏)。通过涵盖这些多样化特性,MARLlib为在广泛的多智能体任务中开展实验提供了灵活的框架。更重要的是,这些任务特性由算法学习流程自动检测,无需手动处理兼容性。在训练启动后,如果存在不兼容的组合(如在MAgent中的simple_adversary场景中使用仅限合作的VDA2C (Su et al., 2021)),MARLlib会基于兼容性测试触发错误。
| 学习模式 | 合作 + 协作 + 竞争 + 混合 |
|---|---|
| 可观测性 | 完全 + 部分 |
| 动作空间 | 离散 + 连续 + 多离散 |
| 观测空间维度 | 1D-3D |
| 动作掩码 | 支持 |
| 全局状态 | 支持 |
| 奖励 | 稠密 + 稀疏 |
| 智能体-环境交互模式 | 同步 + 异步 |
G.2 数据内部对齐¶
现有的多智能体任务套件(如PettingZoo)在代码层面上标准化了数据采样过程。但所谓“代码层面”,是指在多智能体场景下,智能体-环境接口返回的数据未必与变量名称所暗示的含义一致。例如,包含全局信息的观测不应直接输入到像MAPPO或VDA2C这样的算法的actor网络中,因为这会违反集中式训练与分布式执行(CTDE)的原则。
为应对这一挑战,MARLlib在所有集成的环境中都确保了严格的数据对齐。这种对齐保证了环境返回的数据能够被算法侧正确使用。例如,在许多任务中,自然的全局状态并不直接可得。然而,可以从原始观测中提取全局信息(如MAgent),或通过将所有智能体的观测拼接为一个全局观测(如MPE)。这一过程由MARLlib自动完成。
附录H. MARLlib在算法侧统一化的解决方案¶
MARLlib通过更好的算法统一与分类,有效解决了困境,既在数量上也在多样性上实现了更多算法的实现,不受任务模式限制,支持15个环境套件,并允许灵活的参数共享。其核心思想是智能体级数据流,这一点已在正文中讨论。还有两个主要特性需要进一步说明:
第一个特性是,MARLlib如何将MARL算法的复杂性分解,并迈向一个现有MARL库无法实现的全任务模式框架。从前文列出的库来看,一个主要挑战是打破适用任务模式的限制。大多数库最初专注于合作任务,因此在技术上无法纳入新的任务模式,如竞争任务(例如Pommerman (Resnick et al., 2018))和混合任务(例如MAgent (Zheng et al., 2018))。在MARLlib中,智能体级数据流通过将每个智能体的学习过程独立于其他智能体来解决这一问题。这意味着学习目标可以分解到个体层面,从而使智能体能够以任何任务模式和风格学习(集体、分组或单独)。然而,这并非最终的解决方案,因为不同算法类型的本质限制了其应用范围。以下列举了几个常见情况:
- 价值分解(VD)算法仅适用于合作任务。
- 多智能体信赖域学习(HATRPO和HAPPO (Kuba et al., 2022))仅适用于合作任务,其中评价器模型共享但actor模型独立。
- COMA (Foerster et al., 2018) 仅适用于离散动作空间的任务。
- MADDPG (Lowe et al., 2017) 和 FACMAC (Peng et al., 2021) 仅适用于连续动作空间的任务。
还有一些情况偏离了“一个学习流程适用于所有任务”的目标。换句话说,尽管智能体级数据流为MARLlib中的算法统一提供了工具,但缺乏如何高效使用该工具的指导。为此,我们引入了兼容性测试与自动适配机制,作为MARLlib的重要组成部分,旨在实现算法的最终统一。
H.1 自动适配¶
MARLlib的自动适配机制是一项多功能特性,它能够根据用户选择的算法和具体的环境或任务,智能选择最优模块。该机制会智能分析算法的特性与给定环境,动态确定最适合的学习流程模块。通过利用这种自适应能力,MARLlib能够确保高效而有效的性能表现,使用与算法需求及任务复杂性相匹配的模块。这种灵活性使用户能够无缝集成不同的算法,并以更强的适应性处理各种任务,从而提升MARLlib学习流程的整体有效性。
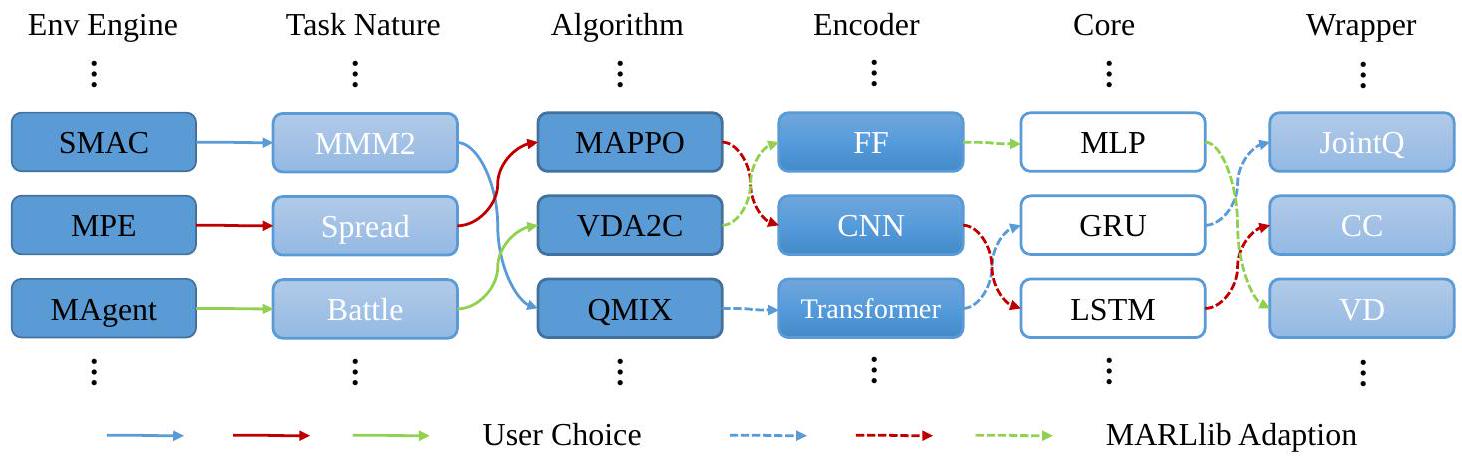
图2:数据流始于用户选择一个任务和算法来运行。MARLlib随后会在剩余的学习流程中自动适配所需模块。值得注意的是,MARLlib的模块化设计使得其能够自动选择和组合更小的模块组件,从而提升学习流程的整体适应性与效率。
H.2 兼容性测试¶
兼容性测试接口结合了来自四个关键组件的配置信息:1)训练信息,2)环境实例,3)模型信息,4)停止条件。这四部分共同启动一个MARL过程。兼容性评估首先通过检索环境特征(如智能体数量、智能体名称和策略共享限制)开始,然后验证用户定义的策略共享设置在给定任务下的合法性。例如,默认选项会在智能体数量较大的任务中禁用策略共享以节省内存。如果尝试切换到不共享策略模式,则会触发错误。
除了在任务侧评估策略共享的兼容性外,算法侧也会被检查,以确保其适用于当前任务。例如,如果某个算法是为离散动作空间设计的,那么为连续控制构建的任务会被排除。如果某个算法需要在特定参数共享方式下进行训练,而任务强制要求跨智能体共享参数,则会触发错误。
需要注意的是,MARLlib将不同类型的算法分为不同的兼容性测试套件。MARLlib中共有三种兼容性测试:独立学习(run_il)、集中式评价器(run_cc)和价值分解(run_vd)。这种组织方式使同一组内的算法能够共享更多的相似性,从而降低了基于给定任务/算法组合来评估特定训练需求是否可满足的复杂性。
H.3 智能体级数据流的流程统一¶
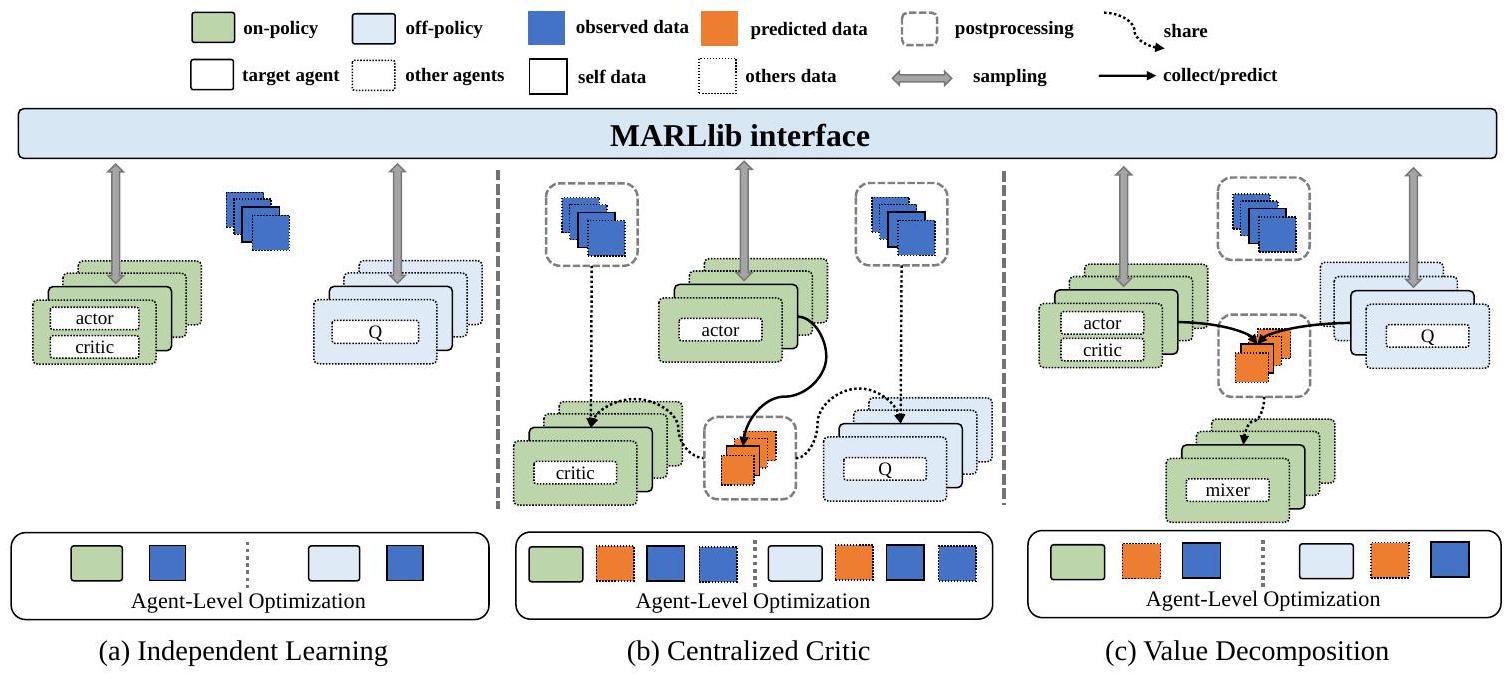
图3:MARLlib的智能体级数据流。观测数据与预测数据的收集和共享分为三种不同的学习风格:独立学习、集中式评价器和价值分解。
MARLlib遵循集中式训练与分布式执行(CTDE)框架来处理多智能体问题。在该框架下,智能体在独立执行和优化时保持各自的策略,而在训练阶段则可以利用集中式信息来协调智能体的更新方向。
现有库通常将整个学习流程分为两个阶段:数据采样与模型优化。在模型优化阶段,采样阶段的所有数据均可用于实现集中式训练。然而,这种方法将“选择合适数据”和“利用这些数据优化模型”耦合在同一阶段。结果是,当需要扩展某个算法以适应其他任务模式(如同时处理合作和竞争场景)时会变得困难,并可能需要重新设计整个学习流程。
为解决这一问题,MARLlib将原有的分组数据流分解为智能体级的分布式数据流。在多智能体训练过程中,每个智能体在采样和优化时均被视为独立单元,但在后处理阶段会共享集中式信息以确保等价性。在这一阶段,智能体会共享观测数据(来自环境的采样数据)和预测数据(策略选择的动作或Q值)。所有智能体维护独立的数据缓冲区,用于存储自身经验和从其他智能体获取的必要信息。一旦进入学习阶段,智能体之间不再需要进一步共享信息,它们可以独立完成优化。通过将数据流分配到智能体,并完全解耦数据共享与优化,同一实现就能够处理多种任务模式。
此外,尽管所有基于CTDE的算法在总体上共享类似的智能体级数据流,但它们仍具有独特的数据处理逻辑。受EPyMARL (Papoudakis et al., 2021)的启发,算法进一步被分类为独立学习、集中式评价器和价值分解,以实现模块共享和可扩展性。独立学习算法使智能体独立学习;集中式评价器算法利用共享信息优化评价器,再由其指导分布式actor的优化;价值分解算法学习联合价值函数及其分解,智能体在执行时据此选择动作。根据不同的算法特性,在后处理阶段实现合适的数据共享策略,如图3所示。
总而言之,MARLlib的智能体级分布式数据流在统一多样化学习范式的同时,保留了各算法的独特属性。这种实现方式使得一个单一的流程能够处理所有任务模式,并与原始实现保持等价。
H.4 数据流等价性¶
在本节中,我们旨在证明所有多智能体学习范式都可以无缝转化为合并后的单智能体学习过程。我们的目标是展示:用于优化目标实体的数据在本质上保持完全一致。为此,我们将利用已被广泛采用的PyMARL和EPyMARL学习框架,该框架以其有效性而闻名。该框架包含三个核心部分:采样、集中式数据收集和单步训练。我们将其与MARLlib采用的独特方法进行比较,该方法由采样技术、共享机制(后处理)和智能体级训练构成。接下来,我们将仔细分析三种不同的学习方式。
独立学习:图4与图5的左侧部分突出展示了(E)PyMARL与MARLlib独立学习流程的差异。在训练之前,(E)PyMARL中的智能体以分组形式采样数据,并将所有数据放入集中式数据缓冲区。在训练阶段,(E)PyMARL的智能体从集中缓冲区中选择数据;而MARLlib的智能体无需选择,因为每个智能体维护自己的独立缓冲区。最终,优化当前智能体策略所用的数据是相同的。因此,这两种学习流程是等价的。
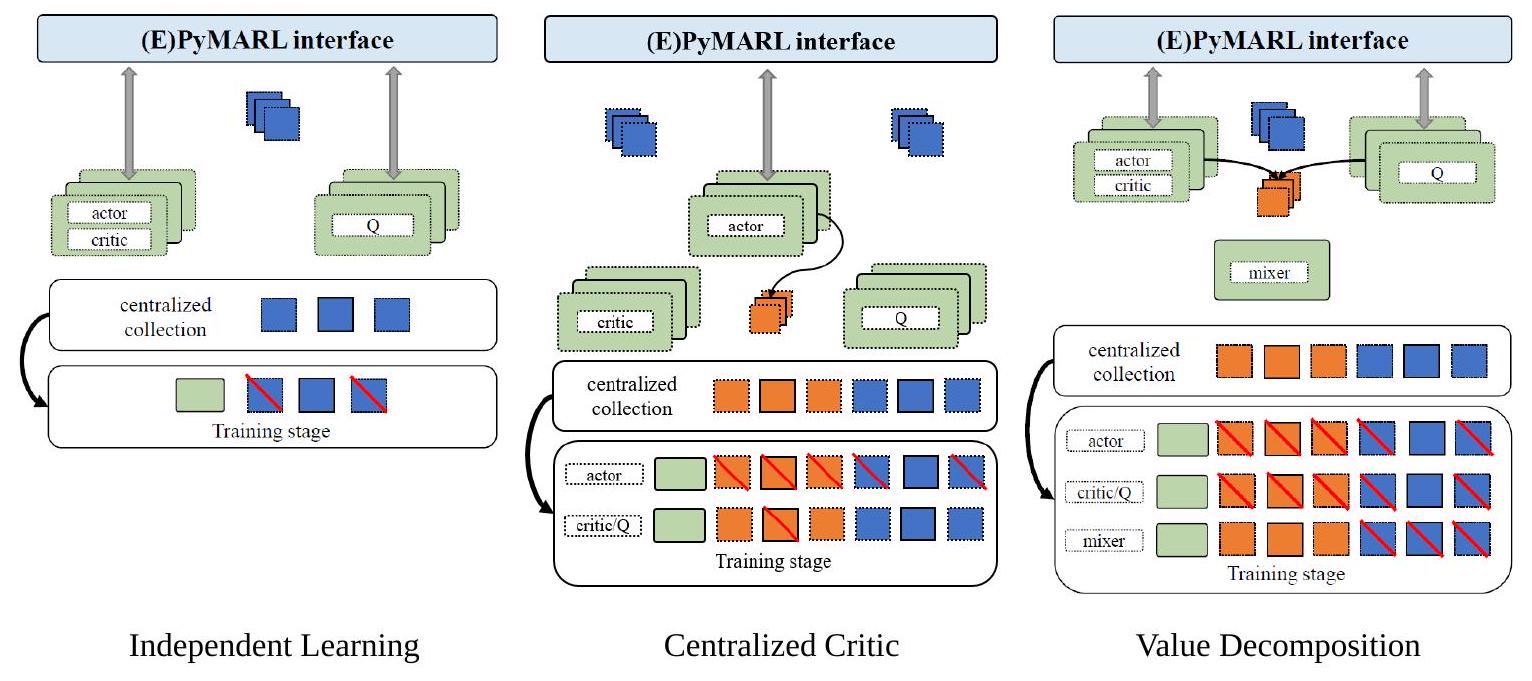
图4:(E)PyMARL在独立学习、集中式评价器和价值分解中的学习流程。请注意,为了更好地展示,训练阶段仅绘制了一个智能体,这并非(E)PyMARL的真实情况,因为所有智能体应当同时训练。
集中式评价器:图4与图5的中间部分展示了(E)PyMARL和MARLlib在集中式评价器学习流程上的差异。与独立学习类似,(E)PyMARL的流程在训练阶段会将所有采集的数据输入到智能体中,智能体随后筛选出不必要的数据,只优化相关部分,例如必须忽略自身预测动作的评价器/Q函数。相比之下,MARLlib的智能体级流程在训练阶段之前的后处理阶段就准备好优化不同模型部分所需的全部数据。这使得优化过程更易于执行,并且独立于具体的学习风格(例如,独立PPO与MAPPO使用相同的目标函数)。最终,如训练部分所示,两者均使用相同的数据来优化每个智能体,因此(E)PyMARL与MARLlib的学习流程在本质上是等价的。
价值分解:图4与图5的右侧部分展示了PyMARL与MARLlib在价值分解学习流程上的差异。与集中式评价器类似,在(E)PyMARL的学习流程中,智能体会接收所有采集的数据,选择所需部分并优化模型的不同部分。而在MARLlib的学习流程中,所有必要数据(包括\(\mathrm{Q}\)/评价值)在后处理阶段被共享。此时,一个智能体可以简单地利用自己维护的全部数据独立优化,而无需考虑其他智能体。我们同样可以发现,两种学习流程均使用相同的数据更新策略。因此,在价值分解学习方式下,二者的等价性也得以成立。
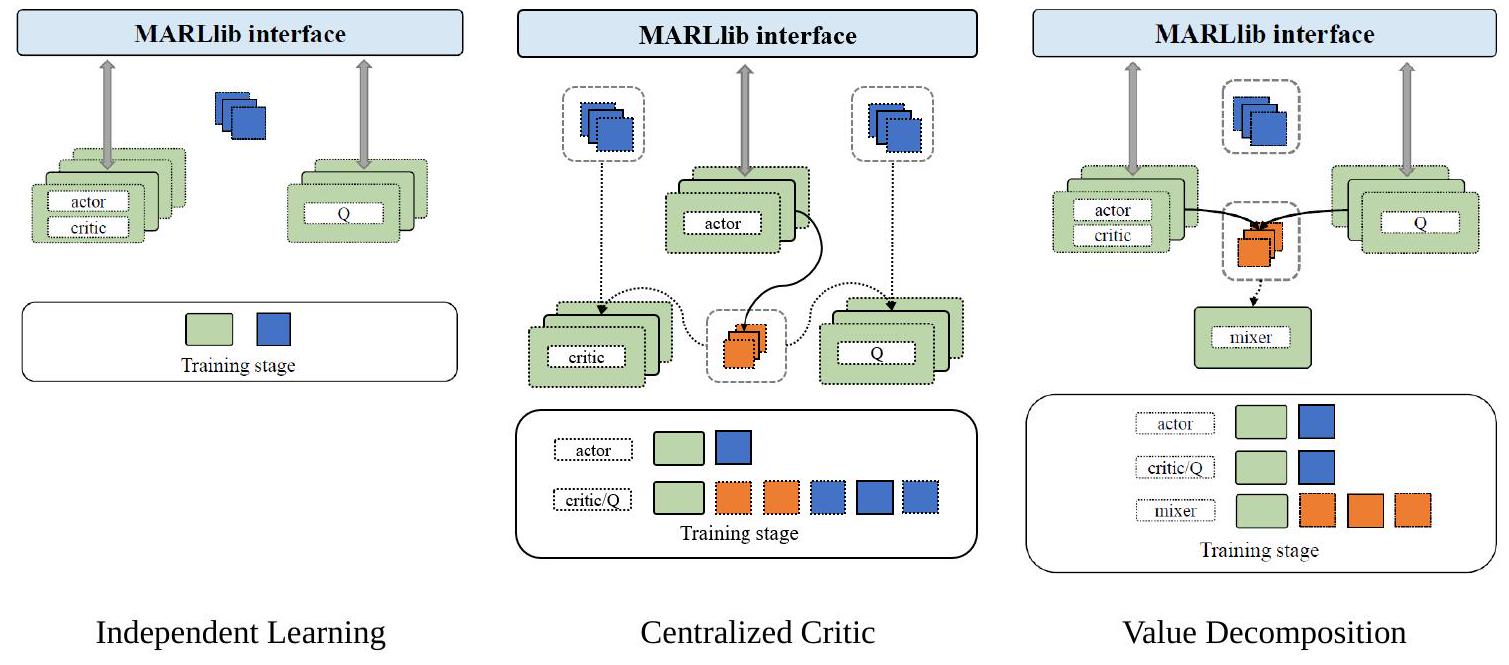
图5:MARLlib在独立学习、集中式评价器和价值分解中的学习流程。
附录I. 可扩展性¶
MARLlib的可扩展性得益于其高度抽象的架构,该架构由五个主要部分组成:配置、训练脚本、算法、模型和环境。每个部分都在文档中提供了相应的API、方法或说明,便于用户进行自定义和扩展。以下简要描述MARLlib的可扩展性如何应用于MARL研究的不同方面:
- 扩展算法以处理更多任务模式:例如,从仅合作场景过渡到混合场景,可以关注
marl/algo/scripts目录下的脚本部分。例如,使某个算法能够处理额外的任务模式,可能涉及在脚本中重组策略映射函数。 - 使算法能够处理复杂任务数据结构或部分可观测设置:可以关注
marl/models目录。例如,对于一个知名的大规模多智能体任务Neural-MMO (Suarez et al., 2021),其观测同时包含3D观测和1D状态,可以在该目录下进行相应调整。 - 开发全新的算法:应关注算法部分,并基于
marl/algos/core目录和marl/utils目录中的已有基本算法实现构建新函数。例如,可以在marl/algos/utils/centralized_critic.py中自定义全局信息的表示方式,以实现新的信息共享机制。 - 快速为新提出的未包含的多智能体任务构建基线:应关注
envs目录。通过遵循第2节与附录G中介绍的MARLlib智能体-环境接口,可以轻松集成一个新任务,并在该任务上评估MARLlib中所有可用算法。
总之,MARLlib的可扩展性覆盖了开展多样化MARL实验的各个方面,使其成为MARL研究中的一款强大工具。更多示例可在MARLlib仓库的examples目录中找到。
附录J. 基准测试¶
在本节中,我们对五个广泛使用的MARL测试环境(SMAC (Samvelyan et al., 2019)、MPE (Lowe et al., 2017)、GRF (Kurach et al., 2020)、MAMuJoCo (Peng et al., 2021) 和 MAgent (Zheng et al., 2018))中的23个任务上共17个算法进行了全面评估。我们选择这些环境是因为它们在MARL研究中的普及性以及在任务模式、观测形态、附加信息、动作空间、稀疏或稠密奖励、同质或异质智能体类型上的多样性。
评估过程涉及在每个任务上运行每个算法,并使用四个不同的随机种子,总实验次数超过一千次。我们测量了每个算法在这些实验中的平均回报。实验结果展示在表4和图6中。基于这些结果,我们验证了实现的质量,并进行了有意义的分析。
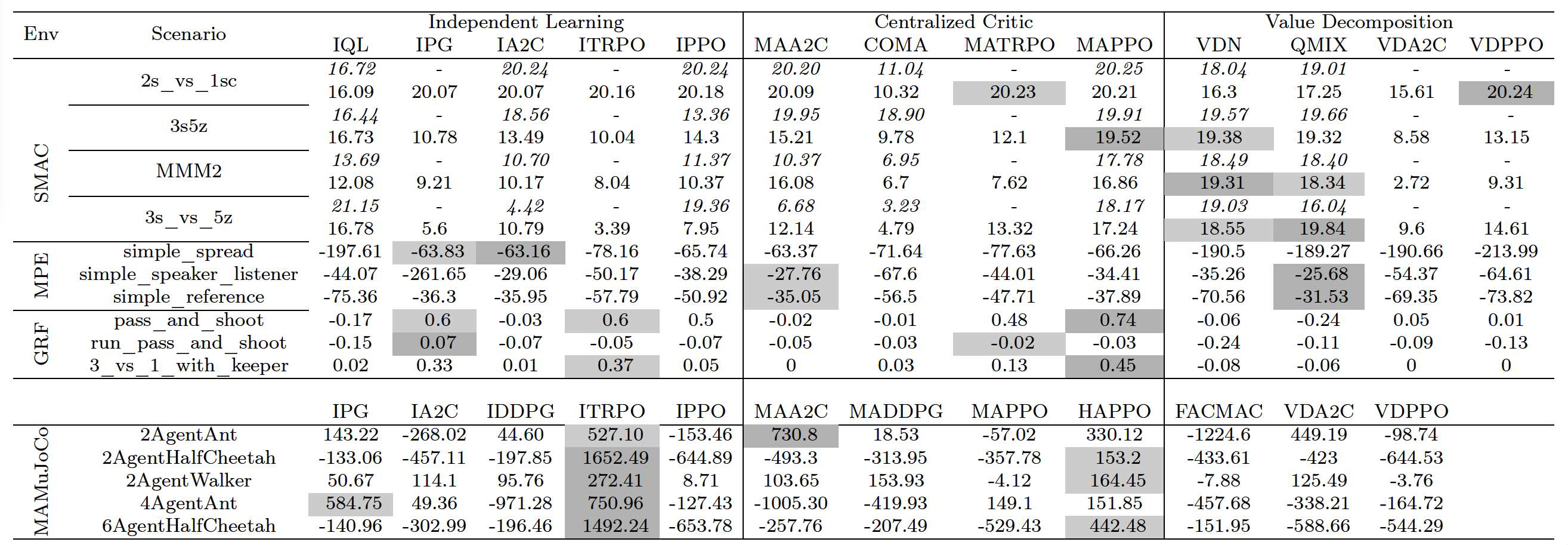
为验证MARLlib的正确性,我们在SMAC环境上将其实现与EPyMARL报告的性能进行了比较,同时保持关键超参数一致。EPyMARL的结果基于策略梯度算法的4000万步训练和非策略算法的400万步训练。相比之下,MARLlib仅使用了一半的训练步数,因为我们发现这已经足够收敛。尽管训练步数更少,MARLlib仍在大多数场景中达到了与EPyMARL相当的性能,如表4所示。
在可对比的性能对比中,MARLlib在63%的结果中表现相近(总回报差异小于1.0),在25%的结果中优于EPyMARL,在其余12%的结果中稍逊。由于各算法在未依赖任务特定技巧的情况下表现符合预期,我们的实现展示了通用性和稳定性。这些实验结果有效验证了MARLlib实现的正确性。
此外,表格还首次呈现了5个算法在SMAC和MPE上的性能、12个算法在GRF上的性能,以及10个算法在MAMuJoCo上的性能,为社区提供了宝贵的参考点。
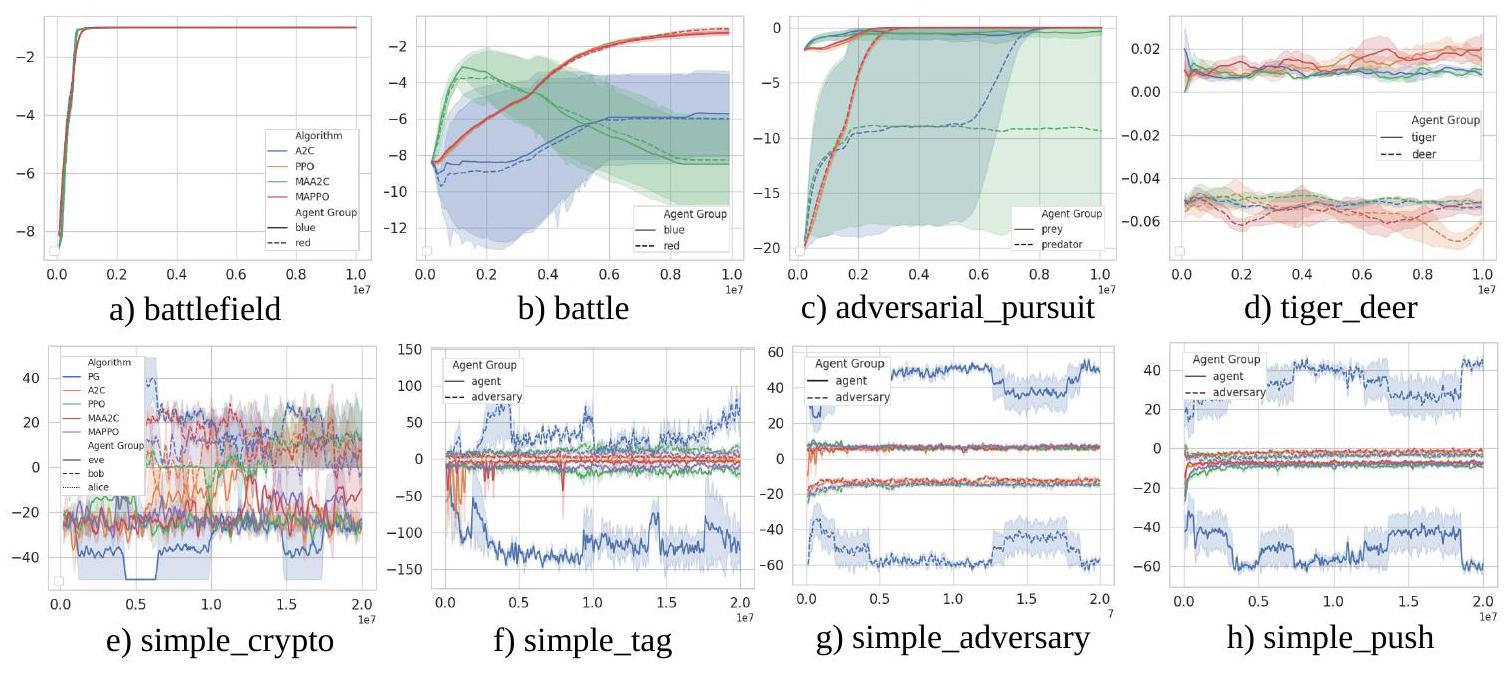
图6:图中展示了8个混合场景的回报曲线,其中智能体以小组形式竞争,来自MAgent环境的四个场景(a-d)和MPE环境的四个场景(e-h)。每条曲线对应一个不同的智能体组。竞争组的回报曲线在学习过程中呈现出动态平衡,平衡点因算法与任务的不同而有所变化。为便于观察,图中进行了放大,以突出学习过程的细节。
表4:算法在合作任务上的性能表现(以回报衡量),覆盖了离散控制任务(MPE、SMAC、GRF)和连续控制任务(MAMuJoCo)。评估包含四个环境套件,其中SMAC的每个场景有两行:第一行(斜体)为EPyMARL报告的性能,第二行为使用MARLlib得到的性能。对于其他环境,仅包含MARLlib的结果。表格中“-”表示该场景未报告数据。深色单元格表示该场景下的前两名表现。
附录K. 未来发展:迈向真实应用¶
MARLlib在多智能体强化学习中的现实应用潜力已经引起了研究人员和实践者的广泛关注。为了进一步提升其实用性和应用价值,有几个关键的未来发展方向值得探索。
- 可扩展性与效率:随着MARLlib扩展到更大规模的场景中,解决可扩展性与效率问题变得尤为重要。未来的工作应着重优化MARLlib内部的算法与数据结构,以适应更多数量的智能体、更大的状态与动作空间以及更复杂的交互。这将使MARLlib能够有效应对诸如交通管理、无人机蜂群机器人、大规模工业系统等现实挑战。
- 可解释性与可理解性:增强MARLlib决策过程的可解释性与可理解性,对于其融入现实应用至关重要。未来的研究应聚焦于开发技术,使其能够对智能体行为进行可视化、对学习到的策略提供洞察,并解释智能体行为背后的推理逻辑。这些进展将提高MARLlib的透明性与可理解性,尤其适用于医疗、金融和自主系统等对可解释性有较高要求的领域。
- 鲁棒性与安全性:确保MARLlib在现实应用中的鲁棒性与安全性至关重要。应对不确定性与对抗性环境是其实际部署的关键。未来的发展应集中于设计能够处理部分可观测性、非平稳环境以及智能体之间通信失败的机制。通过增强MARLlib的韧性,它能够在现实场景中表现出可靠与可信赖的行为。
总而言之,MARLlib的未来发展应优先关注其在现实系统集成中的可扩展性、可解释性与鲁棒性。通过在这些方面的努力,MARLlib能够从一个研究工具逐步演进为一个实用框架,从而应用于多个领域,并推动多智能体强化学习的进一步发展。
References¶
M. Abadi, P. Barham, J. Chen, Z. Chen, A. Davis, J. Dean, M. Devin, S. Ghemawat, G. Irving, M. Isard, et al. Tensorflow: a system for large-scale machine learning. In OSDI, 2016.
B. Baker, I. Kanitscheider, T. M. Markov, Y. Wu, G. Powell, B. McGrew, and I. Mordatch. Emergent tool use from multi-agent autocurricula. In ICLR, 2020.
N. Bard, J. N. Foerster, S. Chandar, N. Burch, M. Lanctot, H. F. Song, E. Parisotto, V. Dumoulin, S. Moitra, E. Hughes, et al. The hanabi challenge: A new frontier for ai research. Artificial Intelligence, 2020.
G. Brockman, V. Cheung, L. Pettersson, J. Schneider, J. Schulman, J. Tang, and W. Zaremba. Openai gym, 2016.
L. Busoniu, R. Babuska, and B. De Schutter. A comprehensive survey of multiagent reinforcement learning. IEEE TSMC, 2008.
F. Chollet et al. Keras. https://github.com/fchollet/keras, 2015.
F. Christianos, L. Schäfer, and S. Albrecht. Shared experience actor-critic for multi-agent reinforcement learning. In NIPS, 2020.
J. Deng, W. Dong, R. Socher, L.-J. Li, K. Li, and L. Fei-Fei. Imagenet: A large-scale hierarchical image database. In CVPR, 2009.
P. Dhariwal, C. Hesse, O. Klimov, A. Nichol, M. Plappert, A. Radford, J. Schulman, S. Sidor, Y. Wu, and P. Zhokhov. Openai baselines, 2017.
J. N. Foerster, G. Farquhar, T. Afouras, N. Nardelli, and S. Whiteson. Counterfactual multi-agent policy gradients. In AAAI, 2018.
J. Hu, S. Wang, S. Jiang, and W. Wang. Rethinking the implementation tricks and monotonicity constraint in cooperative multi-agent reinforcement learning. In ICLR Blogposts, 2023.
I. Kostrikovk. https://github.com/ikostrikov/pytorch-a2c-ppo-acktr-gail, 2018.
J. G. Kuba, R. Chen, M. Wen, Y. Wen, F. Sun, J. Wang, and Y. Yang. Trust region policy optimisation in multi-agent reinforcement learning. In ICLR, 2022.
K. Kurach, A. Raichuk, P. Stanczyk, M. Zajac, O. Bachem, L. Espeholt, C. Riquelme, D. Vincent, M. Michalski, O. Bousquet, and S. Gelly. Google research football: A novel reinforcement learning environment. In AAAI, 2020.
J. Z. Leibo, E. D. nez Guzmán, A. S. Vezhnevets, J. P. Agapiou, P. Sunehag, R. Koster, J. Matyas, C. Beattie, I. Mordatch, and T. Graepel. Scalable evaluation of multi-agent reinforcement learning with melting pot. PMLR, 2021.
E. Liang, R. Liaw, R. Nishihara, P. Moritz, R. Fox, K. Goldberg, J. Gonzalez, M. Jordan, and I. Stoica. Rllib: Abstractions for distributed reinforcement learning. In ICML, 2018.
R. Lowe, Y. Wu, A. Tamar, J. Harb, P. Abbeel, and I. Mordatch. Multi-agent actor-critic for mixed cooperative-competitive environments. In NIPS, 2017.
MARL-Algorithms. https://github.com/starry-sky6688/MARL-Algorithms, 2019.
P. Moritz, R. Nishihara, S. Wang, A. Tumanov, R. Liaw, E. Liang, M. Elibol, Z. Yang, W. Paul, M. I. Jordan, et al. Ray: A distributed framework for emerging AI applications. In OSDI, 2018.
F. A. Oliehoek and C. Amato. A concise introduction to decentralized POMDPs. Springer, 2016.
G. Papoudakis, F. Christianos, L. Schäfer, and S. V. Albrecht. Benchmarking multi-agent deep reinforcement learning algorithms in cooperative tasks. In NIPS Track on Datasets and Benchmarks, 2021.
B. Peng, T. Rashid, C. Schroeder de Witt, P.-A. Kamienny, P. Torr, W. Böhmer, and S. Whiteson. Facmac: Factored multi-agent centralised policy gradients. NIPS, 2021.
T. Rashid, M. Samvelyan, C. S. de Witt, G. Farquhar, J. N. Foerster, and S. Whiteson. QMIX: monotonic value function factorisation for deep multi-agent reinforcement learning. In ICML, 2018.
C. Resnick, W. Eldridge, D. Ha, D. Britz, J. N. Foerster, J. Togelius, K. Cho, and J. Bruna. Pommerman: A multi-agent playground. In J. Zhu, editor, AAAI, 2018.
M. Samvelyan, T. Rashid, C. S. de Witt, G. Farquhar, N. Nardelli, T. G. J. Rudner, C. Hung, P. H. S. Torr, J. N. Foerster, and S. Whiteson. The starcraft multi-agent challenge. In AAMAS, 2019.
D. Silver, T. Hubert, J. Schrittwieser, I. Antonoglou, M. Lai, A. Guez, M. Lanctot, L. Sifre, D. Kumaran, T. Graepel, T. Lillicrap, K. Simonyan, and D. Hassabis. A general reinforcement learning algorithm that masters chess, shogi, and go through self-play. Science, 2018.
J. Su, S. Adams, and P. A. Beling. Value-decomposition multi-agent actor-critics. In AAAI, 2021.
J. Suarez, Y. Du, C. Zhu, I. Mordatch, and P. Isola. The neural MMO platform for massively multiagent research. NIPS, 2021.
J. K. Terry, B. Black, N. Grammel, M. Jayakumar, A. Hari, R. Sullivan, L. S. Santos, C. Dieffendahl, C. Horsch, R. Perez-Vicente, N. L. Williams, Y. Lokesh, and P. Ravi. Pettingzoo: Gym for multi-agent reinforcement learning. In M. Ranzato, A. Beygelzimer, Y. N. Dauphin, P. Liang, and J. W. Vaughan, editors, NIPS, 2021.
O. Vinyals, I. Babuschkin, W. M. Czarnecki, M. Mathieu, A. Dudzik, J. Chung, D. H. Choi, R. Powell, T. Ewalds, P. Georgiev, et al. Grandmaster level in starcraft ii using multi-agent reinforcement learning. Nature, 2019.
J. Weng, H. Chen, D. Yan, K. You, A. Duburcq, M. Zhang, Y. Su, H. Su, and J. Zhu. Tianshou: A highly modularized deep reinforcement learning library. JMLR, 2022.
Y. Yang and J. Wang. An overview of multi-agent reinforcement learning from game theoretical perspective. CoRR, abs/2011.00583, 2020.
C. Yu, A. Velu, E. Vinitsky, J. Gao, Y. Wang, A. Bayen, and Y. Wu. The surprising effectiveness of PPO in cooperative multi-agent games. In NIPS Datasets and Benchmarks Track, 2022.
K. Zhang, Z. Yang, and T. Başar. Multi-agent reinforcement learning: A selective overview of theories and algorithms. Handbook of Reinforcement Learning and Control, 2021.
L. Zheng, J. Yang, H. Cai, M. Zhou, W. Zhang, J. Wang, and Y. Yu. Magent: A many-agent reinforcement learning platform for artificial collective intelligence. In AAAI, 2018.
M. Zhou, Z. Wan, H. Wang, M. Wen, R. Wu, Y. Wen, Y. Yang, Y. Yu, J. Wang, and W. Zhang. Malib: A parallel framework for population-based multi-agent reinforcement learning. JMLR, 2023.