Air Dominance Through Machine Learning¶
A Preliminary Exploration of Artificial Intelligence Assisted Mission Planning¶
通过机器学习实现空中优势¶
人工智能辅助任务规划的初步探索¶
LI ANG ZHANG, JIA XU, DARA GOLD, JEFF HAGEN, AJAY K. KOCHHAR, ANDREW J. LOHN, OSONDE A. OSOBA

ISBN: 978-1-9774-0515-9
Published by the RAND Corporation, Santa Monica, Calif. © Copyright 2020 RAND Corporation
前言¶
本项目原型验证了一种概念验证(proof of concept)的人工智能(AI)系统,用于帮助开发和评估空域中的新作战概念(concepts of operations)。具体而言,我们采用当代统计学习技术,在具有作战相关性的仿真环境中训练计算型空战规划智能体。其目标是利用AI系统通过大规模回放进行学习、从经验中泛化并在多次重复中改进的能力,以加速并丰富作战概念的发展。测试问题是一个简化的打击任务规划:在给定若干配备不同传感器、武器、诱饵和电子战载荷的无人机的情况下,必须找到使用这些无人机攻击孤立防空系统的方法。尽管所提出的测试问题位于空域领域,但我们预期经过修改的类似技术也可应用于其他作战问题与领域。我们发现,通过使用近端策略优化(Proximal Policy Optimization, PPO)技术,可以充分训练神经网络,使其作为作战规划智能体在一组不断变化的复杂场景中发挥作用。
资金来源¶
本项目的资金由RAND公司与美国国防部签订的联邦资助研究与开发中心合同中的独立研究与开发条款提供。
摘要¶
长期以来,美国的空中优势一直是其战争方式和威慑战略的基石,但如今正日益受到竞争对手发展的挑战。机器学习(Machine Learning, ML)的普及带来了无数潜在的颠覆性机遇。一种可能的改进作战能力并强化威慑力的途径是更有效地利用自动化,而自动化反过来可能促成新的作战概念(Concepts of Operations, CONOPs)的规划与发展。通过亲身实验建立对AI辅助规划优缺点的基础理解,美国防务界将能更好地为战略突发与颠覆性变革做好准备。
在本报告中,我们构建了一个AI系统的概念验证原型,用于帮助开发和评估空域领域的新CONOPs。我们测试了多种学习技术与算法,以训练能够在作战相关仿真环境中运行的空战智能体。其目标是利用AI系统能够在大规模环境中反复“博弈”、从经验中泛化、并在多次训练中改进的能力,从而加速并丰富作战概念的发展。
为实现这一目标,我们将开源深度学习框架与美国国防部标准作战仿真工具——高级仿真、集成与建模框架(Advanced Framework for Simulation, Integration, and Modeling, AFSIM)——进行了集成。AFSIM为机器学习智能体提供学习环境,而深度学习框架则提供了测试多种前沿学习算法的平台,包括生成对抗网络(Generative Adversarial Networks, GANs)、Q学习(Q-learning)、异步优势行为者-评论家算法(Asynchronous Advantage Actor-Critic, A3C)以及近端策略优化算法(Proximal Policy Optimization, PPO)。
我们的结论¶
- 在简单的“玩具”问题上(如一维任务),规划过程较为直接。Q-learning与GANs均成功生成了有效的任务规划方案。
- 二维(2-D)任务规划显著更难,因为学习算法必须处理连续动作空间(如移动幅度、转向角度)以及时间策略(如与干扰机或诱饵效果协同)。
- 我们开发了一个快速、低保真版本的AFSIM,称为AFGYM:由于二维任务训练需要成千上万次仿真,因此必须构建AFSIM的低保真版本以加速环境模拟。
- 当前的强化学习算法在实践中实现困难。算法需要人工调整超参数,且容易出现“学习塌陷”(learning collapse)现象,即神经网络陷入输出无意义动作值的局部最优状态。在二维任务中,只有PPO算法能够提供有效的策略。
我们的建议¶
- 尽管任务规划问题复杂,但我们展示了利用AI算法生成时空协调飞行路线的可行性。这类算法若能在更大规模上实施并进行更优调参,或可为美国国防部带来实际价值。
- 针对真实威胁开发此类算法所需的计算能力与时间尚不明确。然而,一旦训练完成,AI任务规划器相较于现有人类或自动化规划方法具有显著优势:速度。
- 奖励函数在仿真中会显著且常常意外地改变AI行为。设计此类函数时必须谨慎,确保准确反映风险与意图。
- 与现代AI系统训练所用的大规模数据相比,现实世界的任务数据十分稀缺。类似AFSIM的仿真引擎将成为规划开发的主要依托。即便算法在仿真中表现完美,现实中的表现也可能不佳(如自动驾驶汽车的经验所示)。因此,在将AI应用于安全关键问题前,必须在测试方法与算法可验证性方面取得进展。
致谢¶
我们感谢RAND Ventures对本次探索性研究的支持。特别感谢Howard Shatz和Susan Marquis对项目的支持及帮助完善研究提案。我们还感谢Ted Harshberger和Jim Chow对项目执行过程的监督与支持。
缩略语¶
| 1-D | 一维 (one-dimensional) |
|---|---|
| 2-D | 二维 (two-dimensional) |
| 3-D | 三维 (three-dimensional) |
| A3C | 异步优势行为者-评论家(Asynchronous Advantage Actor Critic) |
| AFSIM | 高级仿真、集成与建模框架(Advanced Framework for Simulation, Integration, and Modeling) |
| AI | 人工智能(artificial intelligence) |
| CGAN | 条件生成对抗网络(conditional generative adversarial network) |
| CONOP | 作战概念(concept of operations) |
| CPU | 中央处理器(central processing unit) |
| DoD | 美国国防部(U.S. Department of Defense) |
| DOTA | 《刀塔》(Defense of The Ancients) |
| EW | 电子战(electronic warfare) |
| GAN | 生成对抗网络(generative adversarial network) |
| KL | Kullback–Leibler(KL) |
| MDP | 马尔可夫决策过程(Markov decision process) |
| ML | 机器学习(machine learning) |
| PPO | 近端策略优化(Proximal Policy Optimization) |
| RL | 强化学习(reinforcement learning) |
| SAM | 地对空导弹(surface-to-air missile) |
| SEAD | 压制敌方防空(suppression of enemy air defenses) |
| TRPO | 信赖域策略优化(Trust Region Policy Optimization) |
| UAV | 无人机(unmanned aerial vehicle) |
| V\&V | 验证与确认(verification and validation) |
| VM | 虚拟机(virtual machine) |
1. 引言¶
长期以来,美国的空中优势——长期作为美国战争方式与威慑的基石——正日益受到竞争对手发展的挑战。与此同时,机器学习(ML,machine learning)的普及提供了无数潜在的颠覆性机会。例如,中国正通过在人工智能(AI,artificial intelligence)方面的战略性投入改造其军事力量,以进行“智能化”战争。\({ }^{1}\)
一种可能的途径是通过更有效地利用自动化来改进作战能力并强化威慑力,而自动化反过来又可能使得规划与作战概念(CONOP,concept of operations)开发出现新的方法。通过亲身实验建立对AI辅助规划优劣的基层理解,美国防务界将能更好地为战略突发与颠覆性变局做好准备。
本项目的目标是原型化一个概念验证(proof-of-concept)的AI系统,以帮助开发和评估空域领域的新CONOPs。具体而言,我们部署当代的生成对抗网络(GANs,generative adversarial networks)与深度强化学习(RL,reinforcement learning)技术来训练能够在作战相关仿真环境中运行的空战智能体。目标是利用AI系统能够在大规模下反复“对弈”、从经验中泛化并在重复训练中改进的能力,从而加速并丰富作战概念的发展。
该原型平台将开源深度学习框架、当代算法与美国国防部标准的作战仿真工具——高级仿真、集成与建模框架(AFSIM)集成在一起。AFSIM为机器学习智能体提供仿真环境与评估器。本模型被用作ML智能体学习的“现实”环境。测试问题是一个简化的打击任务规划问题:给定一组配备不同传感器、武器、诱饵和电子战(EW,electronic warfare)载荷的无人机(UAV,unmanned aerial vehicle),ML智能体必须寻找将这些平台用于对付防空系统的方法。该问题具有至少两个方面的挑战:
- 最优控制问题的决策空间巨大——涵盖了飞行器航线、运动学与排序,以及在仿真每个时间步上的传感器和武器战术与策略。
- 智能体的动作既可能产生即时效应,也可能产生长期延迟效应。智能体必须在近期与远期效用之间取得恰当的平衡。
尽管所提出的测试问题位于空域领域,但我们预计类似的技术(经适当修改)也适用于其他仿真环境。此处所讨论的所有问题都可以用其他方法的组合来解决,例如简单的射程与时机计算、针对各种威胁情形的经验法则,或基于风险最小化的路线规划器。然而,从长远看,此处使用的技术可能比这些方法更具可扩展性——后者通常也依赖于简化情形或计算上代价高昂。
动机¶
国防部(DoD)正在探索将自主性、AI与人机协同引入其武器与作战中的可能性。无论是作为情报分析人员的数据挖掘工具、规划者的决策辅助,还是支持自主平台的能力使能者,这些系统都有可能比传统工具提供更高的准确性、速度与敏捷性。\({ }^{2}\) 然而,作战级AI与认知自主系统也面临操作员信任与接受度、计算效率、验证与确认(V\&V,verification and validation)、对抗性攻击下的鲁棒性与弹性,以及人机界面与决策可解释性等严峻挑战。理解基于AI的规划的潜力与局限,并将现实与围绕AI系统的炒作区分开来,均至关重要。\({ }^{3}\)
具体来说,随着国防部开始开发与采购更复杂、分布式且互联的载有人与无人“系统-系统”(system-of-systems)架构,它将需要新的分析工具来增强与扩展作战概念的开发与评估。例如,美国空军的规划人员可能希望了解如何最好地对一组协同且异构的无人机(配备互补的传感、干扰或打击载荷)进行任务规划与利用。一个规划系统需要回答诸如:应有多少平台携带哪种载荷?平台之间的相对间隔与时序应如何设定?它们相对于载人飞机应飞行在哪里?这些正是我们预期软件可帮助回答的问题类型。
国防科学委员会(Defense Science Board)在其2015年关于自主性的夏季研究中,将“自主空中作战规划”(autonomous air operations planning)与通过自主性实现的“蜂群作战”(swarm operations)列为优先研究领域。\({ }^{4}\) 空军在其2016年的《自主前沿》(Autonomous Horizons)愿景中,也将“在任务规划、再规划、监视与协调活动中提供援助”作为关键的自主应用之一。\({ }^{5}\) 然而,尽管对复杂国防规划中的AI/ML技术兴趣广泛,解决有意义的空中作战规划问题所需的AI系统开发范围与复杂性仍不明朗。这一限制至少部分源于缺乏将问题复杂性相对于当代连接主义(connectionist)AI系统形式化表征的方法。深度学习技术总体上理论化不足且学术社群偏向经验性研究,这意味着难以先验判断当代算法能否解决给定的复杂规划问题。本报告旨在通过探索性实验——即路径探索实验(pathfinding experimentation)——弥合这一差距,检验我们能否将当代“第二波”AI/ML技术部署到空中任务规划中。\({ }^{6}\)
自主性、传感网络与数据链的持续进步意味着空中作战的复杂性可能增长速度远超人类推理能力的提升。鉴于当今规划的复杂性以及未来可能面临的更大挑战,本项目旨在探索将ML方法用于任务规划。关键研究问题包括:
- 能否在不需要在数十亿种可能情形上训练数据的前提下,训练出能有效表现出智能任务规划行为的当代ML智能体?
- 机器智能体能否通过重复博弈学会:干扰机需要接近地对空导弹(SAM)到足以影响其作用,但又不能近到被击落?它们能否学会需要在打击机到达之前先行到位?它们能否学会需要多少诱饵——以及以何种进近路径——来使地对空导弹偏离真实打击机目标?
- 能否构建足够通用的状态与动作空间表示,以捕捉规划问题的丰富性?这些经验能否在威胁位置、类型与数量变化时稳健地泛化?
背景¶
当今的任务规划¶
军用飞机历来并非单独行动,而是以“编队包”(packages)形式互相支援。最小的包可能由两架飞机组成——领队与僚机。在另一端,更大的编队可能包含打击机、压制敌方防空(SEAD)、空对空、侦察与干扰飞机,总数可达数十架。\({ }^{7}\) 这些不同类型的能力需要在时空上进行精细协调,例如确保打击机不会同时攻击同一目标或在没有防空压制力量在近旁保护时接近目标。它们还需要针对预期威胁进行精心规划,以避免使部分飞机处于无防护或无传感器支援的状态、在危险区域过近运行,或浪费通常稀缺的支援资源。考虑到不同类型飞机可能从不同地点起飞、飞行速度与高度各异,并且飞行员经验水平差别很大且可能未曾共同飞行,这一难度可想而知。
为管理上述复杂性,任务包规划是飞行员训练中最为高级的课题之一。只有具有多年飞行经验的飞行员才承担这些任务,规划与整合此类编队也是如Red Flag和空军武器学校(Air Force Weapons School)等高级训练项目的重要内容。\({ }^{8}\) 该方法通常先确定为发现并摧毁计划目标所需的侦察与打击资源数量与类型,然后基于威胁相对于目标与打击航线的位置、威胁射程、速度与可能的警戒等级来识别对该编队的关键威胁。一旦关键威胁明确,就可规划针对这些威胁的防护措施,包括通过干扰降低其探测范围,以及为拦截地对空导弹或空中拦截器而配备专门的对地/对空作战飞机。上述每一项防护任务本身又可能形成需要更详细规划的编队。最终,航线与时序被微调以确保安全与适当的相互支援程度。在有充足时间的情况下,最复杂的编队可在实机或联网模拟器中进行排练。
然而,随着飞机与防御系统在能力、集成度、自动化和速度上的提升,这类劳动密集型的人工规划可能变得不可行。一些最复杂的任务(例如涉及B-2等隐身飞机的任务)可能需要数天时间与数百人参与规划。\({ }^{9}\) 在与先进对手的战争中,这样的时间与人员资源可能无法得到保障,尤其当每日需要执行大量任务时。另一个值得关注的问题是即将出现的技术,例如具有高度灵活载荷、能够承担更多风险且可能具备自主行为的无人平台。\({ }^{10}\) 在仅有数小时(甚至更短时间)可用的情形下,人类规划者能否有效利用数量呈指数级增长的载有人与无人平台能力与战术组合,更不用说在航线与时机选择上进行优化?
有必要区分任务规划(mission planning)与航线规划(route planning)。在此,我们将“任务规划”一词理解为不仅包含飞机将飞行何处,还包括使用何种、多少数量的飞机及其相对时序等参数。而在静态、非交互的环境中、约束较为简单的航线规划——即我们主要考虑“去哪里飞”——是一个较为成熟且有高效解法的问题,例如Dijkstra算法或A*搜索等。\({ }^{11}\) 这些算法类似于商业导航与路径规划系统,通常旨在最小化路线长度与时间等关键变量。在国家安全应用中,它们可用于控制风险,并可包括诸多约束,如平台性能、禁飞/限制区、传感器或武器射程。国防部已经在联合任务规划系统(Joint Mission Planning System)等工具中采用这些方法来帮助为单架或小规模飞机群规划任务。\({ }^{12}\) 当前许多相关工作集中在提高速度,以便处理大规模问题并在任务期间(例如出现威胁时)支持动态再规划,同时纳入更多变量与约束(如风、平台横滚角约束、或对目标函数如风险进行更高保真度的计算)。
任务分析与规划常通过直觉与启发式方法来控制搜索问题规模。尽管启发式方法能帮助识别点解,但这些解很少具有可扩展性或足够可靠,无法一致性地评估由大量策略可选项所带来的海量可能性。在具有大量参与者以及复杂传感器与武器交互的高维问题中,直觉也可能失效,而这类特征恰恰可能定义未来的空中战争。
在国防或商业领域中,针对我们所称的“任务规划”(即应当同时确定哪些类型与数量的资产应协同使用以达成目标)的自动化工具的研究似乎很少。\({ }^{13}\) 如本报告后文所述,随着ML智能体之间以及智能体与环境之间的交互性增加,任务规划与航线规划之间的界限愈发模糊;具体而言,如何最好地协调协同平台在很大程度上取决于它们相对于彼此及相对于威胁的位置以及它们效果的相对时序。我们的算法旨在将航线规划与任务规划功能进行整合。
作战级仿真环境:AFSIM¶
AFSIM(Advanced Framework for Simulation, Integration, and Modeling,高级仿真、集成与建模框架)是我们用于评估机器学习(ML,machine learning)工作效果的作战任务级仿真工具。\({ }^{14}\) 它最初被设计为替代空军现有的综合防空系统(Integrated Air Defense Systems)模型,如今被国防部(DoD)社区普遍视为标准的任务级仿真工具。
AFSIM采用面向对象(object-oriented)和基于智能体(agent-based)的设计:单个平台可以配置传感器、武器、目标跟踪管理器、通信网络与处理器(可自定义或从AFSIM库中选择)。其体系结构包含了构建和脚本化复杂平台及其交互所需的全部工具:仿真对象、武器交战与通信建模、自定义脚本语言、以及地形选项(包括地下与太空场景)。用户可通过脚本定义平台行为,包括航线、射击触发条件、成像与通信规则、及其他交战规则。尽管平台在场景运行过程中相互交互,用户仍可选择输出任意时间步的事件记录,如目标探测、开火与干扰等。该工具内置的“可脚本化性”和仪器化特征为批量处理与马尔可夫决策过程(MDP,Markov decision process)形式化提供了途径。
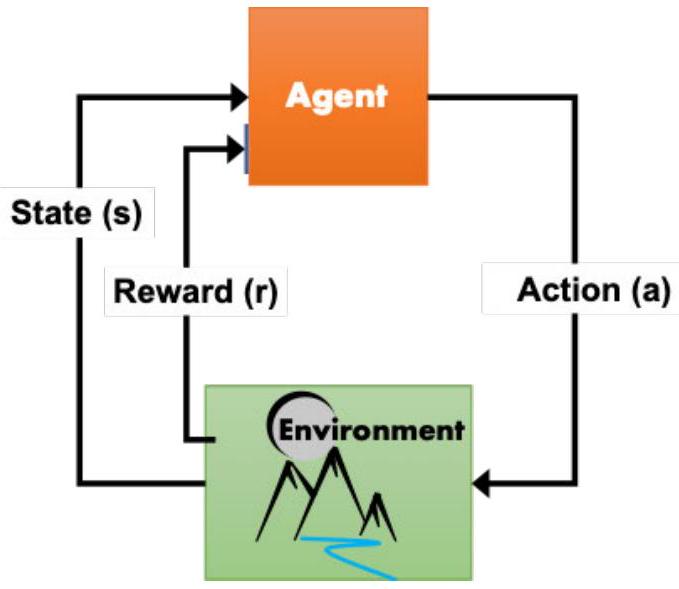
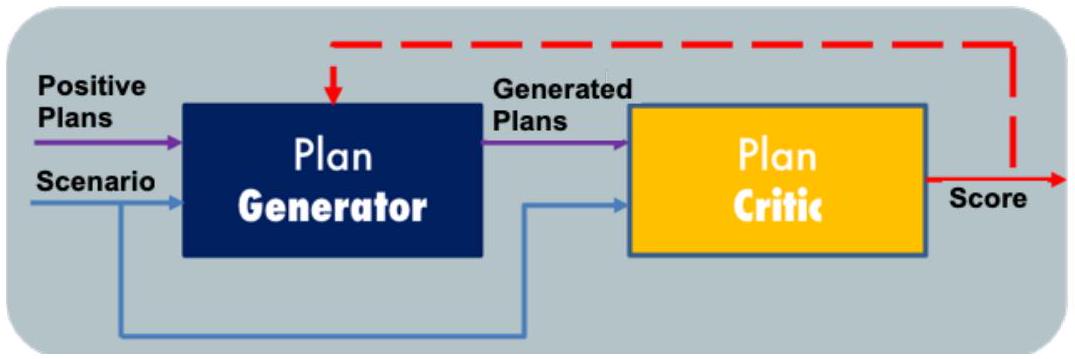
MDP是一种对序列决策进行数学形式化的模型,其中动作会产生随机的回报(可能是即时或延迟的)。MDP为大多数强化学习(reinforcement learning)算法提供了理论基础,其目标是最大化长期期望回报。图1.1展示了典型强化学习问题的示意图。智能体与环境进行交互,对于其所处的每一个状态,智能体都必须做出决策(采取行动)以获取回报。关于MDP等概念的数学形式化定义,可参见附录D。
图1.1 强化学习MDP的可视化表示
游戏中的机器学习现状¶
数十年来,游戏一直是人工智能(AI,artificial intelligence)研究的巅峰领域,激发了许多具有里程碑意义的成果。游戏成为AI研究的天然实验室有多重原因。关键之一在于,游戏运行在受约束且可度量的环境中,规则与动作明确可定义。计算机在被精确指令时表现出色,但当任务的某些方面难以由程序员具体描述时,计算机会遇到困难。在许多游戏中,规则、动作以及——更重要的——胜负条件都可以被精确地定义,只留下策略部分或完全未指定。而对于大多数现实问题,这些要素很少或几乎无法如此精确定义。因此,现实世界问题很少成为开发AI技术的良好试验平台。然而,游戏作为AI发展试验场的优点,同样限制了其成果的实用性,因为研究目标很少仅限于“让AI玩游戏”。对游戏的投入之所以合理,是因为人们希望将该技术转化用于现实世界问题——但这一转化并非必然。
这一转化过程有时会遇到困难,部分原因在于从高度约束、简化的游戏环境直接跳跃到开放的现实世界环境跨度过大。游戏(及仿真)与现实之间的鸿沟问题因当代ML技术对训练与评估数据微小差异的敏感性而更加复杂。因此,有必要回顾AI在游戏领域的一些标志性成果(包括历史与近期成就),以及这些成果从“实验室”环境向更实用应用过渡过程中取得的成功与遭遇的困难。
或许最著名的游戏AI是IBM的超级计算机“深蓝”(Deep Blue),它在1996年击败了国际象棋冠军加里·卡斯帕罗夫(Garry Kasparov)。\({ }^{15}\) 这一事件对许多人来说是个转折点——计算机在一项象征智慧与策略的重大测试中超越了人类。许多领先的AI思想家曾认为,会下棋的计算机将成为解决更广泛复杂现实问题(如“语言翻译”或“简化军事背景下的战略决策”)的垫脚石。\({ }^{16}\) 然而,很快事实表明,国际象棋只是游戏,为单一目的设计的计算机在通用性上收效甚微。几十年后,尽管机器翻译取得了巨大进展,但这与深蓝所采用的技术关系不大。\({ }^{17}\) 军事战略与规划仍牢牢掌握在人类手中。
近年,IBM在另一场智慧竞赛——电视问答节目《Jeopardy!》(《危险边缘》)中再次战胜人类。获胜系统“沃森”(Watson)能够理解复杂多变的问题,被誉为AI里程碑。获胜后,74次连胜的选手Ken Jennings幽默地评论道:“我欢迎我们的计算机霸主。”\({ }^{18}\) 许多人认为,能理解该节目问题的计算机将能在多种实际任务中表现出色,因此沃森被宣传为无所不能——从创作音乐到治愈癌症。\({ }^{19}\) 公平地说,沃森确实在多个领域取得了一定成功,但远未达到投资与雄心的规模预期。\({ }^{20}\) 事实再次表明,沃森本质上仍是为特定游戏定制的程序,要转向现实问题需要大规模的重新设计。而且,在现实环境中,沃森面临数据可得性与质量不足、个体差异与应用差异过大的问题。\({ }^{21}\)
一种更具普适性的博弈AI开发路径是强化学习(RL,reinforcement learning)。RL的原理是:程序将游戏状态作为输入,根据大量过往动作及其结果来建议下一步动作。此类程序仅能玩它所被训练的游戏,但该方法不需对游戏规则进行特定编程,因而比象棋或问答更具一般性。作为这一通用性的证明,相同设计被用于49种经典Atari游戏,系统迅速展现出与专业游戏测试员相当的表现。\({ }^{22}\)
类似的方法被用于击败围棋世界冠军的AI“AlphaGo”,该比赛让人联想到20世纪90年代的“深蓝大战卡斯帕罗夫”。\({ }^{23}\) AlphaGo与Atari智能体采用相同的基本思想,但其神经网络结构更贴合围棋特点。尽管如此,相同的算法与架构也能迁移至其他游戏,只是性能有所降低。这种可迁移性使得许多行业相信,游戏AI向现实应用的转化可期。事实上,图像处理与机器翻译等领域已借助类似技术取得商业化突破。\({ }^{24}\) 然而,关于军事战略决策的应用仍远未实现,尽管进展仍在继续。
诸如数学优化(例如凸优化)与元启发式搜索(例如遗传算法)等搜索算法可帮助解决高维问题。例如,有研究尝试使用遗传算法训练模糊推理系统,以控制AFSIM中的多智能体。\({ }^{25}\) 强化学习采取了不同的方法,其重点不在于在静态世界中寻找“最优”解,而在于训练智能体在动态环境中做出合理反应。这使得RL更适合“编程”那些能够与环境互动、影响并被环境影响的智能体——如自动驾驶汽车。RL方法的优势在于无需显式抽象、表示或编码游戏规则。智能体可以从几乎一无所知的状态出发,通过试错学习游戏策略。近期的创新,如深度Q学习(deep Q-learning)——谷歌DeepMind的AlphaGo平台的关键组成部分——利用深度神经网络逐步逼近智能体的回报函数,并在推理过程中引入层次化的机器抽象与压缩。\({ }^{26,27}\)
近年来最引人注目的成果集中于更接近军事交战的游戏。这些系统能够处理连续、信息不完全的博弈,并考虑后勤与短期牺牲以实现长期目标。例如,在电子游戏《刀塔2》(Defense of the Ancients 2,DOTA 2)中,这些深度强化学习方法已经超越业余选手,正在逼近职业乃至超人水平。\({ }^{28}\) 在更复杂的策略游戏如《星际争霸》(StarCraft)中,人类仍具显著优势,但鉴于计算机游戏AI的历史成功,许多人认为这种优势不会持续太久。\({ }^{29}\)
虽然游戏环境中的这些展示令人印象深刻,但正如前文所述,人们真正的希望在于这些技术能在现实中应用。然而至今,这一目标依然困难重重且未完全实现。从高度约束的虚拟环境跨越到复杂多变的现实世界,对于大多数情形而言跨度过大。本项目试图在游戏环境与现实实用性之间迈出中间一步。仿真环境广泛用于探索新的计划、设计与战术,以及培训与兵棋推演(wargames)的组成部分。仿真与游戏一样具有约束性,但努力融入足够的现实复杂性,以便为决策者提供有价值的结果参考。
通过将最近在Atari、围棋与DOTA 2等游戏中发展与验证的深度强化学习算法与架构应用于空军标准仿真环境AFSIM,我们希望能将这些方法从游戏向现实应用推进一步。尽管我们认识到简单的空战规划可通过IF-THEN决策树实现,但我们希望探索RL工具展现独特行为、跨任务类型泛化与体现多智能体协作性的潜力。
报告结构¶
第2章讨论解决简单一维(1-D)任务规划问题所需的工具与算法;第3章延续相似结构,但将复杂性扩展到二维(2-D)空间,更贴近现实问题;第4章重点介绍类似项目中面临的计算基础设施挑战;第5章总结研究发现并探讨未来可能的研究方向。附录详细说明了本研究中所使用工具处理各种内部变量的方式。
本研究的主要工作具有探索性,我们同时推进了多条研究路线。图1.2展示了这些研究路线的总体路线图。
图1.2 报告路线图
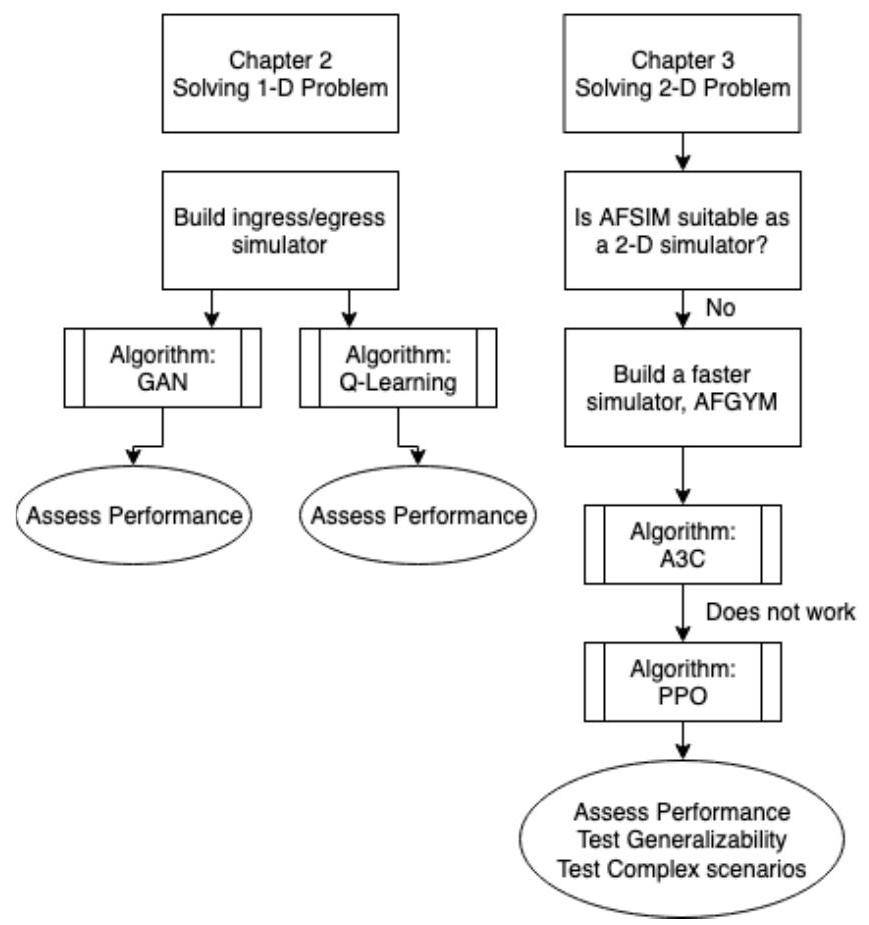
注:A3C = 异步优势行为者-评论家(Asynchronous Advantage Actor Critic);PPO = 近端策略优化(proximal policy optimization)。AFGYM为作者命名的AFSIM低保真快速版本。
2. 一维问题¶
机器学习(ML,machine learning)项目的复杂性可能迅速增长。人们很容易在程序并未真正有效时误以为其正常工作,或编写出复杂却以非直观或难以解释方式失败的程序。为降低这些风险,我们采用渐进式方法,从高度简化的任务规划问题入手,逐步构建至更高复杂度的层级。该简化方法从一个一维(1-D)导航问题及一组具有理论完备性和长期实证验证的算法开始。由于该1-D问题的最优解可以人工推导,因此也便于验证算法性能的正确性。
问题建模¶
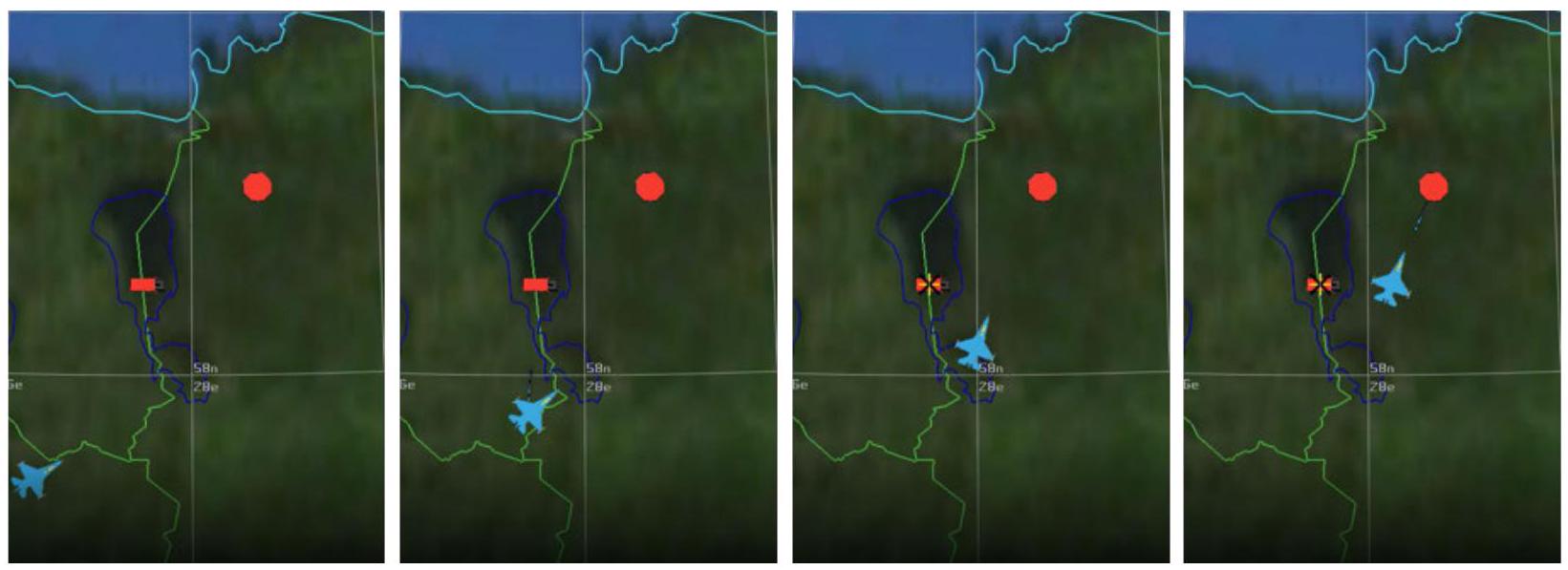
简化的一维场景包含三个组成部分:战斗机、干扰机以及地对空导弹系统(SAM,surface-to-air missile)(见图2.1)。\({ }^{30}\) 战斗机的目标是摧毁SAM;而SAM的目标是摧毁战斗机。在此设定中,SAM具有射程优势(100 km),因而可在战斗机进入其射程(80 km)之前将其击毁。图中仅存在两种可能结果:战斗机可在进入SAM射程前转向返回——双方均存活;或继续前进进入SAM射程——被击落。
图2.1 无干扰机时的一维问题

然而,时机与位置至关重要。引入干扰机后,结果空间被扩展,优势可重新回到战斗机一方(见图2.2)。干扰机可以靠近SAM并降低其有效射程。如果战斗机在此期间进入,则可摧毁SAM并安全返航。但若干扰机飞得过近,可能在战斗机完成任务前被击落,或者干扰机、战斗机、乃至双方均被摧毁。AI系统被告知SAM的位置以及三方平台(战斗机、干扰机、SAM)的射程信息,并被期望学习在何时、何地派出战斗机与干扰机,以在摧毁SAM的同时不损失己方平台。\({ }^{31}\)
图2.2. 含干扰机的一维问题

在AFSIM环境中,通用的任务规划通常涉及多自由度的计划参数。然而在此1-D场景中,任务仅限定为沿单一方向的运动与行动规划。场景布置仍嵌入标准三维(3-D)环境中,但控制变量仅定义一维动作。表2.1给出了1-D AFSIM场景中的智能体设置。
表2.1 一维任务场景中的智能体
| 阵营 | 智能体描述 | |
|---|---|---|
| 蓝方 | - 具备导弹攻击能力的机动战斗机,在指定射程内可执行攻击 | |
| - 具备电子干扰能力的机动干扰机,可削弱或抵消红方SAM的攻击区域 | ||
| 红方 | - 固定式SAM阵地,其攻击范围为预设并向蓝方公开 |
该场景被称为“一维”,因为所有平台均被限制沿连接蓝方与红方起始位置的直线飞行。蓝方飞机的高度保持固定。为保证AI系统能从足够多样的经验中学习到可泛化的策略,红方位置与蓝方初始点之间的距离被随机设定。AI系统需要学习以下要点:
- 在派出战斗机前先派出干扰机以压制红方SAM;
- 控制干扰机距离,使其既足够靠近以有效干扰,又不至于被击落;
- 派出战斗机攻击被压制的SAM,同时避免飞得过近;
- 最后将两机均安全返回基地。
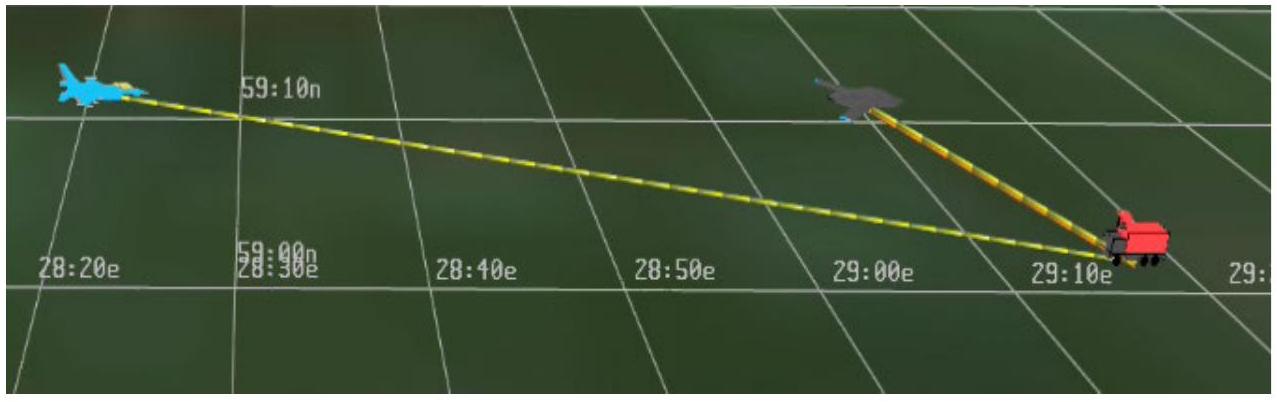
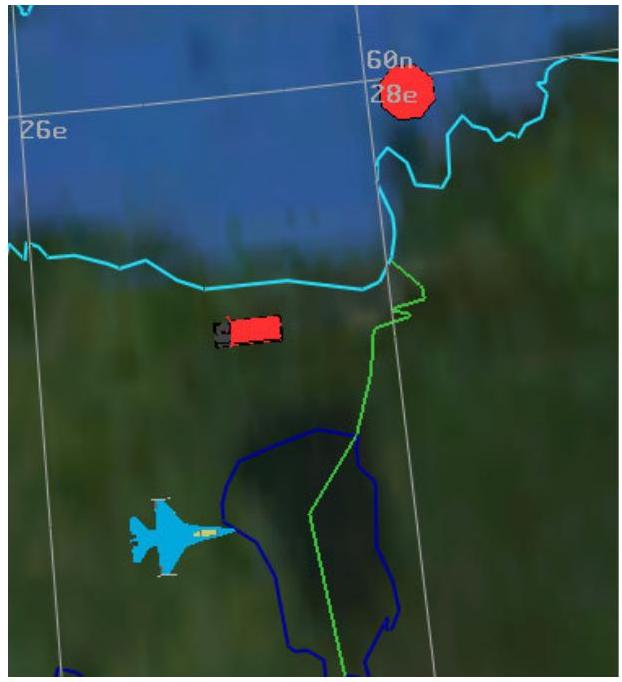
图2.3展示了AFSIM环境中该1-D场景的渲染视图(俯视与侧视结合)。蓝方飞机从左向右飞行,战斗机跟随在干扰机之后,后者成功压制了红方SAM(可见橙色干扰线及黄色探测线仅从蓝方平台指向SAM)。此例中,战斗机成功接近目标、发射导弹、摧毁SAM并返航。
图2.3 一维场景示例的VESPA回放截图
每个场景由两类变量定义:环境变量与学习变量。前者是预先设定的场景特征,确定变量值即定义了特定的“初始世界状态”(laydown)。例如,平台的射程为环境变量——设定其值定义了AI智能体所处的环境。学习变量则是AI智能体需要学习的特征,确定这些值即描述了平台与环境交互的具体方案。例如,平台的飞行距离可视为学习变量,其值可能依赖于环境特征,如附近平台的射程等。在此1-D任务规划问题中,AI智能体旨在为给定布置找到最优方案。平台行为与场景变量如表2.2与表2.3所示。\({ }^{32}\)
通过改变射程与距离,系统的目标是训练战斗机学习可泛化策略(例如,当战斗机射程大于SAM时选择进攻,否则撤退),而非仅学习特定场景的硬编码规则。
表2.2 一维问题建模——环境变量
| 环境变量 | 变量范围 |
|---|---|
| 战斗机射程 | \(0-40 \mathrm{~km}\) |
| 战斗机速度(固定) | \(740 \mathrm{~km} / \mathrm{h}\) |
| 干扰机干扰范围(固定) | 30 km |
| 干扰机速度(固定) | \(740 \mathrm{~km} / \mathrm{h}\) |
| SAM射程 | \(0-40 \mathrm{~km}\) |
| SAM与战斗机的初始距离 | \(0-100 \mathrm{~km}\) |
| 战斗机起始位置(固定) | 纬度:\(59.04^{\circ}\) |
| 经度:\(27.75^{\circ}\) | |
| 高度:6 km | |
| 干扰机起始位置(固定) | 纬度:\(59.04^{\circ}\) |
| 经度:\(27.75^{\circ}\) | |
| 高度:6 km |
表2.3 一维问题建模——场景设置与学习变量
| 平台 | 阵营 | 学习变量 | AFSIM脚本行为 | 需学习的行为 |
|---|---|---|---|---|
| 战斗机 | 蓝方 | - 进入距离(Ingress Distance) - 干扰机领先距离(Lead Distance) |
- 战斗机等待干扰机飞完领先距离后再开始突入 - 若SAM在战斗机突入时进入射程,则开火并转向返航 - 若不在射程内,则转向返回起点(若未被击中) |
- 学习在任意情形下不飞越自身射程 - 学习识别干扰机何时能有效确保安全突入,即使SAM初始射程大于战斗机 |
| 干扰机 | 蓝方 | - 进入距离(Ingress Distance) | - 干扰机从任务开始即向SAM方向突入 - 当进入30 km范围内时开启S波段干扰 - 达到突入距离后停止并悬停 |
- 学习飞至有效干扰范围但不更近 |
| SAM | 红方 | - 无 | - 若蓝方平台进入射程,则开火 | - 无 |
AI系统的对抗训练数据约包含20,000组随机生成的布置与计划(laydown-plan)对。计划在布置下随机分配,使智能体能初步判断哪些方案在特定环境中有效。因此,在训练数据中,环境变量与学习变量均已给定。环境变量的取值在表2.2范围内随机生成;而计划变量(即后续由ML智能体学习到的部分)则在表2.4范围内随机生成。
表2.4 一维问题建模——测试数据中的学习变量范围
| 学习变量 | 变量范围 |
|---|---|
| 战斗机突入距离 | 最小:0 km 最大:SAM位置(上限设定为战斗机不得飞越SAM位置) |
| 干扰机突入距离 | 最小:0 km 最大:SAM位置(上限设定为干扰机不得飞越SAM位置) |
| 干扰机领先距离 | 最小:0 km 最大:干扰机突入距离(领先距离即战斗机等待干扰机飞行的距离,不可超过干扰机总突入距离) |
解决一维问题的机器学习方法¶
该学习问题可表述如下:给定一个任务场景,学习生成一个在AFSIM任务仿真中被评估为成功的任务计划。针对这一问题,可采用多种可行的机器学习(ML,machine learning)建模方法。更一般而言,许多搜索算法也可用于通过迭代或批量评估求解决策变量,这一事实凸显了在简单规划问题中搜索与机器学习之间的重叠性。
我们选择将该问题表述为模仿学习(imitative learning)问题,并使用AFSIM仿真器作为模拟任务数据的来源。基本的模仿学习模型输入正样本数据(即成功任务),然后学习其潜在空间表示与生成器,以生成类似的正样本。我们对该模型进行了改进,引入状态输入向量,从而实现状态条件的任务计划生成器(state-conditional plan generator)。这一特征十分重要,因为我们希望计划生成器具有足够的灵活性与泛化能力,以应对从未出现过的输入场景(在此简化情形下,主要指不同的起始位置与交战距离)。
在该阶段我们采用了两种算法,因为事先无法确定哪种最合适。二者都具有坚实的理论基础与丰富的实践历史。第一种是Q学习(Q-learning),该方法曾用于击败Atari游戏。\({ }^{33}\) 在此实验中,神经网络为简单的全连接前馈网络(fully connected feed-forward network),包含若干层与数百个节点。
在该一维问题中,决策仅依赖于战斗机、干扰机与SAM的射程以及SAM的位置,因此状态(state)为战斗机、干扰机与SAM的位置;动作(action)为战斗机与干扰机的时间与转向点设置;价值(value)为任务结束后获得的得分。为将此问题转化为机器代码,我们将其重构为飞行过程中的逐步决策模型:战斗机与干扰机在每一步判断是前进、保持还是返航。此时,状态即为三者的位置,动作为三种选择之一(前进、保持、返航),而价值为一个表示当前状态达成有利结果可能性的数值。通过将决策过程转化为逐步模型,可应用Q-learning算法。
在Q-learning中,神经网络用于逼近所谓的“动作-价值函数”(action-value function)。该方法与其他估计状态价值或采用“策略内”(on-policy)方法(如state-action-reward-state-action)的方法不同。\({ }^{34}\) 简而言之,Q-learning训练一个神经网络来计算每个动作可能带来的价值,并通过比较所有可选动作的分值来选择最优行动方案。\({ }^{35}\) Q-learning的目标是学习并逼近所有可能状态与动作的Q函数。
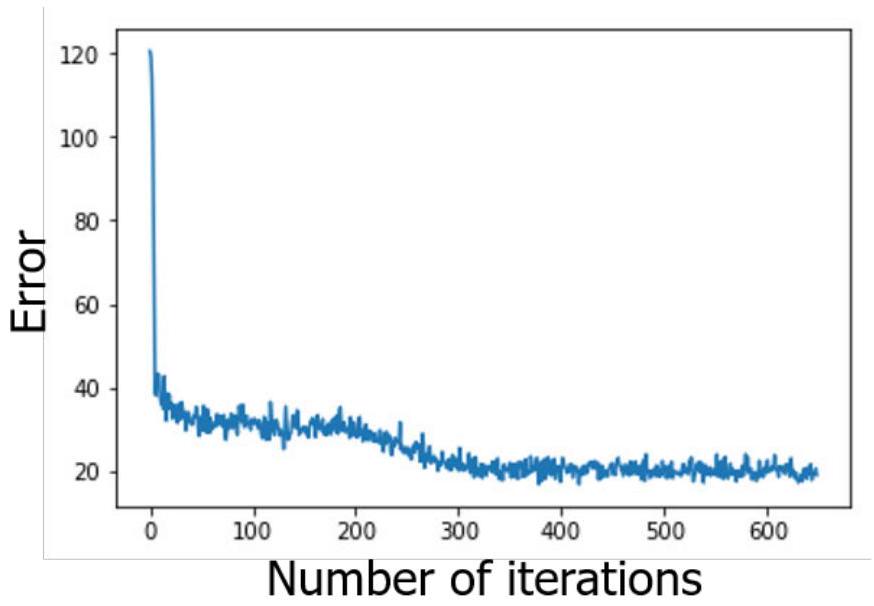
Q-learning具有较强的鲁棒性,对于本1-D简单问题而言,给定的网络具有较高的学习能力。当学习率、批大小与探索参数等超参数设定完成后,网络迅速提升性能。如图2.4所示,误差值几乎立即下降,并在几百批次内快速收敛。误差定义为神经网络预测的Q函数与真实Q函数之间的接近程度,可作为强化学习性能的代理指标(越低越好)。
图2.4 Q-learning在一维问题上的快速收敛
Q-learning的表现如预期般良好,但由于问题本身的简化性,其实用价值有限。每个回合仅包含一个决策步骤(即任务参数选择),因此我们认为无需进一步优化Q-learning性能,而应继续探索其他更具潜力的方法。其中之一即生成对抗网络(GAN,generative adversarial network)。\({ }^{36}\)
第二种机器学习方法是GAN模型,它通过生成器(generator)与判别器(discriminator,也称critic)网络共同训练以解决模仿学习问题。生成器子网络输入噪声信号并输出模拟样本(此处为任务计划),而判别器子网络则将这些模拟样本作为输入,输出一个介于\([0,1]\)的连续评分,用于表示模拟质量。两者通过对判别器误差信号的反向传播迭代更新,并基于正样本数据学习。状态条件计划生成器是条件GAN(CGAN,conditional GAN)的改进实现。\({ }^{37}\) 图2.5展示了我们改进的状态条件GAN模型架构,该模型实现了针对一步马尔可夫决策过程(one-step MDP)的解法。这一思路与近期研究中指出的GAN模型与演员-评论家(actor-critic)强化学习模型在多步MDP求解中的联系相一致(例如本报告中开发的二维规划器)。\({ }^{38}\)
CGAN可理解为两个网络之间的竞争过程:一个网络(记作G)在给定场景条件下生成“伪造”计划(即非人类生成的计划);另一个网络(记作D)则根据场景条件判别计划的真伪。\({ }^{39}\)
为适应CGAN,智能体-环境交互行为被重新表述。与Q-learning的逐步决策不同,此处的动作为单一输入——突入距离(ingress distance)。生成器\(G\)根据场景条件\(y\),从概率分布中抽取突入距离值\(z\)。一维环境将此值解释为执行相应突入距离、尝试开火并返航的完整动作。
图2.5 一维问题的模仿规划模型架构
GAN规划器训练的评估反馈¶
仿真训练数据由带有随机分配布置(laydown)或场景的计划向量(plan vectors)组成。布置与计划组合后共同定义一个任务向量(mission vector)。要训练规划器,就必须从AFSIM仿真器中获取任务结果(任务成功或失败)的评估反馈。由于AI系统与AFSIM之间的接口较为复杂,而在本简化示例中任务成功与否可直接计算得出,因此我们开发了一个更简单、更快速的测试环境——名为AFGYM的简化一维任务仿真器。\({ }^{40}\)
我们使用AFGYM估算AFSIM中任务向量的结果并对任务结果进行评分,从而在算法开发阶段无需每次调用AFSIM(仅用于生成起始位置)。评分函数的定义如下:蓝方平台的存活获得奖励(战斗机+2分,干扰机+1分),红方平台存活受到惩罚(基准项-4分)。该评估器用于筛选随机生成的任务中表现成功的任务向量。请注意,GAN的训练仅需要正样本数据。用于GAN任务规划器训练的正样本AFSIM数据约包含26,000对成功的随机布置与计划。
这一针对接口问题的临时解决方案带来了复杂性代价。由于初始数据经过筛选,意味着GAN规划器实际上是在为该简化评估器学习任务规划问题的解法。GAN规划器在AFSIM环境中仍能表现出成功的结果,实质上表明其在执行了成功的迁移学习(transfer learning)。
GAN规划器的评估¶
评估GAN规划器的质量需要为规划模型制定相关的性能指标(figure of merit)。我们采用“提升率”(lift)的概念来量化GAN相较于随机行为智能体的改进效果。表2.5列出了部分评估指标(并非详尽列表)。
表2.5 机器学习规划模型的评估指标说明
| 指标 | 描述 | 基线(百分比) |
|---|---|---|
| 对失败样本的提升(Lift over failed samples) | 在原本被判定为失败的随机任务向量中,经过训练的规划器能使多少比例变为成功 | 0 |
| 对正样本的提升(Lift over positive samples) | 在原本被判定为成功的随机任务向量中,经过训练的规划器能保持多少比例继续成功 | 100 |
| 总体提升(Overall lift) | 在全部随机任务场景中,训练后的规划器能使多少比例成功(基线定义为完全随机智能体的成功率) | 36 |
| 训练集规模(Training set size) | 为达到报告的性能指标,规划器训练了多少样本 | n/a |
为测试GAN架构并加速开发,我们首先在AFGYM环境中对其进行基准测试。完成开发后,再切换回AFSIM环境对任务规划性能进行评分。表2.6第一列报告了简化AFGYM模型的性能指标,第二列为AFSIM中1-D GAN规划器的指标。
表2.6结果显示,GAN规划器的规划行为优于随机未训练规划器,能生成得分更高的任务计划。然而,得分更高并不总意味着可观察行为更优,尽管奖励函数被设计为鼓励蓝方生存并强烈惩罚红方生存。进一步分析生存统计数据表明,GAN规划器更可能学会了识别哪些场景难以或无法解决,并在此类情形下制定保守策略——即蓝方不尝试攻击SAM。
表2.6 GAN规划模型在两种任务环境中的性能对比
| 指标 | 简化模型 | AFSIM |
|---|---|---|
| 对失败样本的提升 | \(+30 \%\) | \(+17.9 \%\) |
| 对正样本的提升 | \(-2.1 \%\) | \(-6.8 \%\) |
| 总体提升 | \(+26 \%\) | \(+11 \%\) |
| 训练集规模 | 50,000 | \(\sim 20,000\) |
3. 二维问题¶
上一节中的一维问题验证了GAN在简单规划任务中的可行性。下一步是将问题扩展至二维空间,从而引入航迹规划(route planning)需求——即从起点飞向目标点的同时规避沿途威胁。实质上,原本的一维“进或退”问题,变为时间序列上的“应该转多少角度”的问题。
针对搜索与学习,有多种方式可表示航迹规划问题,从离散网格上的图搜索到连续参数化表示(如贝塞尔曲线 Bezier splines)。本研究采用常见的基于智能体的马尔可夫决策过程(MDP,Markov decision process)形式,将航迹规划问题表述为智能体在每个时间步感知世界状态并决定下一动作的过程。更严格地说,这是一种部分可观测马尔可夫决策过程(POMDP,partially observable Markov decision process),即智能体无法获得完整的世界状态信息。\({ }^{41}\)
在本初始设定中,智能体控制所有无人机(UAVs)并具有完全信息。该渐进与迭代式方法与1-D场景中的一次性规划策略形成鲜明对比。采用MDP建模的动因在于需在控制状态空间规模的同时保持航迹表示的细粒度。此外,MDP建模还能更高效地支持动态事件下的实时规划。
问题建模¶
相较于1-D问题,通用的二维SEAD(Suppression of Enemy Air Defenses,压制敌方防空)问题更为复杂,因为其决策空间巨大,且随智能体数量变化,其复杂度可能高到无法通过推理甚至高算力求解。我们进一步增加问题复杂度,引入一个红方目标(在1-D问题中SAM即为目标),使得蓝方可通过绕过SAM攻击目标。\({ }^{42}\)
问题建模与决策空间如图3.1所示:蓝方无人机从二维空间的随机起点出发,需学习如何在存在随机放置的SAM威胁下攻击红方目标。蓝方智能体拥有关于红方导弹与目标位置的完全信息,但并无预设规则或启发式策略以指导其在避开SAM的同时攻击目标。目标是通过反复对局(repeated play)学习出这些启发式规则。
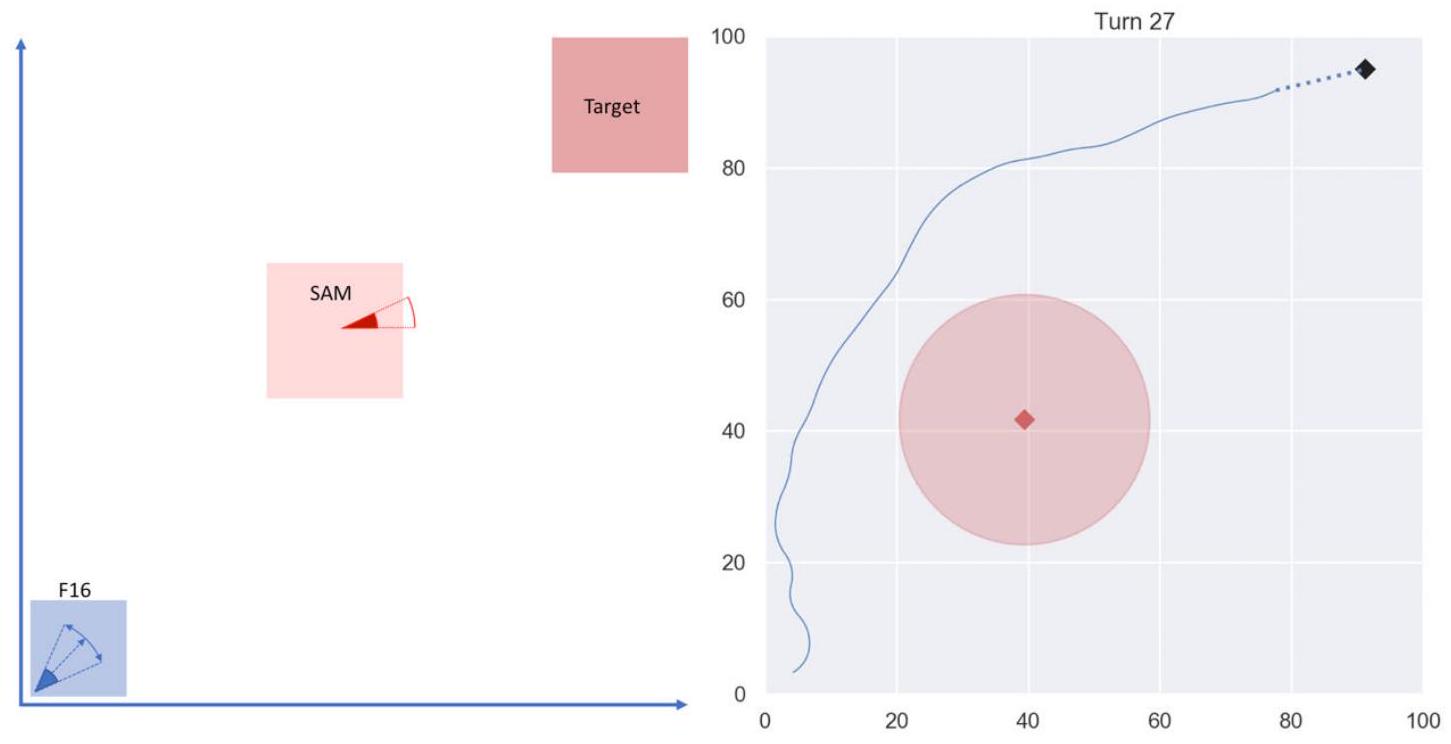
在AFSIM环境中,基本二维问题包括三个平台:蓝方战斗机、红方SAM与红方目标。任务目标是战斗机在不被SAM击落的情况下飞抵并摧毁目标。图3.1展示了一个二维布置示例:战斗机位于左下角,SAM位于中央,目标位于右上角。任务目标是战斗机绕过SAM射程后打击目标。在此简化形式下,仅包含两平台与一个目标,算法性能可直接验证。
图3.1 二维布置示例截图
与在1-D问题中使用RL与GAN选择完整任务计划不同,二维问题使用强化学习(RL)在任务执行过程中持续决策平台动作。该过程涉及AFSIM与ML智能体在任务执行期间的实时交互:AFSIM在运行期间定期报告场景状态,智能体返回下一时段应执行的动作,如此循环直至仿真结束。此协调机制将在后文详细描述。
二维场景中定义初始“世界状态”的环境变量列于表3.1。
表3.1 二维问题建模——环境变量
| 环境变量 | 变量范围 |
|---|---|
| 战斗机位置 | 纬度:\(58.5^{\circ}\) 至 \(59.0363^{\circ}\)(随机) 经度:\(26.3^{\circ}\) 至 \(26.8^{\circ}\)(随机) |
| SAM位置 | 纬度:\(59.1^{\circ}\) 至 \(59.5^{\circ}\)(随机) 经度:\(27.2^{\circ}\) 至 \(27.5^{\circ}\)(随机) |
| 目标位置 | 纬度:\(59.6^{\circ}\) 至 \(60^{\circ}\)(随机) 经度:\(27.7^{\circ}\) 至 \(28.5^{\circ}\)(随机) |
| 战斗机射程 | \(3.5-10.5\)(单位为\(100 \mathrm{~km} \times 100 \mathrm{~km}\)区域) |
| SAM射程 | \(5.0-10.5\)(单位为\(100 \mathrm{~km} \times 100 \mathrm{~km}\)区域) |
智能体输出的动作包含学习变量的取值。在本问题中,唯一的学习变量——即智能体在每个时间步提供的唯一值——是战斗机的下一个航向(heading)。战斗机将沿该航向直线飞行,直到下一个状态读出传回智能体。值得强调的是,与1-D情形下每个布置仅存在一个理想学习变量值不同,二维问题中智能体需在每个时间步仅依据当前状态(而非历史信息)学习出最优航向。
降阶仿真环境:AFGYM¶
二维运动的参数化需要使用连续变量(例如飞行器航向,以角度为单位)。为简化问题并限制决策空间的规模,速度保持恒定。引入连续航向变量意味着机器学习(ML)过程需要比一维情况进行更多的探索,才能学会如何在给定布局中导航。为支持如此大量的仿真运行,我们构建了一个更快速的“轻量版AFSIM”程序。这种方法在该领域十分常见。例如,OpenAI的DOTA 2智能体训练时使用加速仿真技术,实现了每日相当于180年游戏时长的训练量。\({ }^{43}\)
二维模型通过将一维降阶训练仿真器AFGYM扩展至二维,解决了模型与仿真器之间的接口问题。由此引出的关键研究问题是:在这种代理环境(AFGYM)中训练得到的智能体,能否有效迁移到代表性环境(AFSIM)中工作。
AFGYM是一个用于二维深度强化学习(deep RL)问题的Python模块。其设计目标是在最简程度上模拟SEAD(压制敌防空)任务的关键行为(即飞行器绕过敌方SAM的运动),不考虑AFSIM中大量与SEAD任务无关的计算。AFGYM进行了重大简化——它不执行任何雷达计算。蓝方与红方的智能体只要检测到有效目标在预设射程内,就会自动开火。电子战(EW)同样未建模,干扰(jamming)仅通过按比例降低武器射程的方式实现。
AFGYM的应用程序接口遵循OpenAI Gym环境标准。OpenAI Gym是一个为强化学习研究设计的Python工具包与目标环境,提供一套标准化协议,支持研究者快速原型验证AI系统,可用于倒立摆平衡、Atari游戏或机械臂控制等任务。\({ }^{44}\)
AFGYM基于相同协议,用于模拟简化版的AFSIM行为,支持多种强化学习方法(如并行化学习),并可实现快速算法测试。
更具体地说,AFGYM当前支持创建蓝方飞行器,用户可定义其导弹射程、导弹数量、冷却时间、干扰范围与干扰效果。红方对手为静态平台,用户可定义其导弹射程、数量及冷却时间。敌方包括固定式SAM与目标平台。AFGYM相较AFSIM的一个显著简化在于:它不执行浮点雷达探测计算,而是采用查表方式确定传感器探测范围;导弹与干扰射程被设定为常数;与AFSIM一样,为避免不确定性,假设武器不会失效。AFSIM提供了丰富的编程规则以控制智能体行为,而AFGYM为提高速度未尝试复制这些规则。\({ }^{45}\)
此外,AFGYM假设雷达探测范围为全向(omnidirectional),而AFSIM则考虑雷达方位、扫描速率与天线方向图。AFGYM中所有数值均为无量纲值,使用笛卡尔坐标系(例如导弹射程为10表示坐标系中10个单位长度),并假定为平面环境(而非AFSIM采用的球面地球模型)。各单元可在\([0,100]\)范围的方形区域内活动。每个时间步,AFGYM都会报告各单元状态(如位置、航向、武器射程),并将这些信息输入神经网络。为防止训练中常见的梯度爆炸问题,所有AFGYM输入值在训练前均被归一化到\([0,1]\)范围。未经归一化的多尺度输入容易导致梯度过大,从而在反向传播阶段饱和网络层。
解决二维问题的机器学习方法¶
在二维问题上,我们转向基于策略梯度(policy gradient)的算法。对于状态与动作空间都较大的复杂模型,策略梯度算法较基于样本回放的离策略(off-policy)算法(如Q-learning)表现更优。策略梯度方法在收敛性方面有理论保证,且更适用于高维空间的学习。\({ }^{46}\)
Q-learning通常不适用于连续动作空间,这在实践中也得到了验证:我们曾尝试在连续二维问题上使用REINFORCE Q-learning算法,结果表现为随机游走行为。此外,GAN不适合二维任务,因为其决策需在每一步实时作出,而非像一维问题那样事先规划完整任务。
异步优势行动者–评论者算法(A3C)¶
第一个表现出潜力的强化学习算法是A3C(Asynchronous Advantage Actor-Critic)。\({ }^{47}\)
A3C基于经典的Actor-Critic(行动者–评论者)强化学习模型,并在训练并行化和经验利用效率方面引入创新。当该方法首次被提出时,研究者证明其在性能(如游戏得分)和学习效率方面优于许多现有算法。A3C相较于直接使用奖励信号的传统方法有多方面优势。
简言之,A3C基于REINFORCE算法(一个典型的on-policy算法)。与Q-learning(通过神经网络近似状态–动作表)不同,on-policy算法直接使用神经网络同时学习Q函数与策略函数。\({ }^{48}\)
A3C引入一个称为“优势值”(advantage)的计算量,它定义为智能体执行某一动作的期望奖励与实际奖励之间的差值。算法据此利用相对奖励进行更新。例如,一个从零开始(tabula rasa)的智能体在学习Pong游戏时,会随机左右移动球拍。最初,它的价值网络对任何动作的估计值均为0;若随机一次动作意外挡回球获得正奖励,则该奖励高于预期奖励(0),从而算法更新策略以倾向执行类似行为。使用相对奖励(相对于过往表现)而非绝对奖励,有助于算法更高效地学习更优策略。负责计算优势值的网络称为评论者(critic)。
其次,A3C维持一个独立的神经网络——行动者(actor)网络——用于计算每一步应采取的最优动作。当行动者执行动作后,评论者网络计算优势值。该优势值与鼓励探索的熵项共同用于反向传播更新策略网络,从而增加产生正优势动作的概率,减少负优势动作的概率。
A3C的关键创新在于异步并行学习。传统RL在单个CPU上串行执行仿真、计算优势并更新网络,而A3C允许多个CPU并行执行。每个工作线程下载最新的全局网络副本,运行仿真,并异步地向全局网络提交学习更新,从而加速训练。
如后续结果部分所述,A3C在AFGYM环境中针对多种任务规划布置表现出良好前景。例如,A3C能够成功控制多架蓝方飞机(多战斗机、战斗机与诱饵机、战斗机+干扰机组合)对抗多个红方目标。\({ }^{49}\)
训练后的算法展现出协同效应,例如:(1)干扰机缩小SAM射程,使原本处于劣势射程的战斗机得以靠近并摧毁SAM;(2)多架具有不同导弹射程的战斗机能各自选择合适的红方目标交战。
然而,算法在一致性(同一布置下并非所有仿真都成功)与收敛性方面存在问题。策略坍塌(policy collapse)是一种现象,即行动者–评论者策略网络偏离最优策略后无法继续从经验中学习。神经网络作为策略函数\(\pi\)的近似器,当在反向传播过程中出现数值问题时,可能远离真实策略函数,导致策略坍塌。\({ }^{50}\)
我们观察到多数A3C运行出现了飞机原地绕圈的行为模式。
对于从零开始的A3C算法,蓝方飞行器的控制初期类似随机游走。要获得正奖励,算法必须连续执行一系列正确动作以避开SAM并击毁目标。然而,随机游走过程中,一旦蓝机靠近红方SAM,往往被击落,从而算法在奖励反馈中惩罚此类探索,使后续仿真中飞行器趋向远离该区域。尝试通过修改奖励函数抑制这种行为反而导致蓝机持续原地打转(试图同时避开SAM又避免“飞离”惩罚)。由于探索SAM附近的情况极为罕见,这些探索带来的策略更新会被其他并行线程发现的局部最优(原地转圈)所淹没。
为解决这一问题,我们采用课程学习(curriculum learning)策略,使训练任务的难度逐步提高。该方法通过初始化飞行器靠近红方目标与SAM,使算法学习如何获取奖励(即射程占优时接近SAM,否则避开SAM仅攻击目标)。随着训练迭代的推进,布置逐步将蓝机起始位置设得更远,算法也逐步学会相应地调整策略。
信赖域策略优化(TRPO)与PPO¶
信赖域策略优化(Trust Region Policy Optimization, TRPO)和近端策略优化(Proximal Policy Optimization, PPO)是对基于梯度的强化学习(RL)方法的改进。传统梯度法通过梯度下降优化代价函数(例如最大化奖励或优势值),但其学习过程容易因学习率设置不当而出现学习缓慢或策略坍塌等问题。TRPO针对这一问题进行了改进,其目标函数与A3C相同,记为\(J\),但在优化时约束策略\(\pi_{\theta}\)在更新后不得变化过大。这通过限制更新前后的策略分布\(\pi_{\theta}\)与\(\pi_{\theta^{\prime}}\)之间的Kullback–Leibler(KL)散度实现。\({ }^{51}\)
由于这一约束优化问题在实际计算中不可解,TRPO采用代理目标函数(surrogate objective function)进行近似估计。关于TRPO的数学细节可参考原始论文。\({ }^{52}\)
这一约束机制有助于防止学习坍塌,因为它限制了错误更新(如强化“原地打转”行为)的影响范围。此外,代理目标函数作为代价函数的二次近似,能够保证学习过程的单调改进。PPO由OpenAI提出,旨在简化TRPO的实现,因为计算KL散度较为复杂。\({ }^{53}\)
PPO的创新之处在于完全消除了KL项的计算,而是在目标函数中对优势项进行截断(clipping)。这种“截断”机制可平衡更新步长,无论优势项过高或过低,都能防止梯度爆炸或消失。在A3C中,极端优势值常导致梯度爆炸或梯度消失,从而引发学习坍塌。
我们针对PPO开发了非并行化版本的行动者–评论者(actor-critic)网络。PPO用于更新行动者网络,而评论者网络则采用常规梯度下降进行优化。
智能体与AFSIM的协同¶
在通过AFGYM以MDP形式训练智能体后,AFSIM以逐步执行的方式运行以更新“世界状态”。\({ }^{54}\)
机器学习智能体读取状态向量(state vector),并输出下一步的动作。该循环持续执行,直到任务结束或战斗机被击落。表3.2总结了每个时间步报告给ML智能体的状态变量。
表3.2 二维问题建模——每个时间步报告给ML智能体的状态变量
| 状态变量 | 说明 |
|---|---|
| 战斗机航向 | 战斗机朝向方向(0°表示笛卡尔坐标系的正\(x\)方向);范围-180°至180°,归一化为[0,1] |
| 战斗机纬度 | 战斗机的纬度(笛卡尔坐标中的\(y\)值),归一化为[0,1] |
| 战斗机经度 | 战斗机的经度(笛卡尔坐标中的\(x\)值),归一化为[0,1] |
| 战斗机状态 | 若被击落则为1,存活为0 |
| 战斗机射程 | 对目标的最大打击距离(欧几里得距离),归一化为[0,1] |
| 战斗机弹药量 | 弹药数量,归一化为[0,1] |
| SAM朝向 | 当前未使用(为未来雷达朝向特性预留),固定为0上报\({ }^{\text {a }}\) |
| SAM纬度 | SAM位置的纬度(\(y\)值),归一化为[0,1] |
| SAM经度 | SAM位置的经度(\(x\)值),归一化为[0,1] |
| SAM状态 | 若被击毁则为1,存活为0 |
| SAM射程 | 对目标的最大打击距离(欧几里得距离),归一化为[0,1] |
| SAM弹药量 | 弹药数量,归一化为[0,1] |
| 目标朝向 | 当前未使用(为未来雷达方向特性预留),固定为0上报 |
| 目标纬度 | 目标位置的纬度(\(y\)值),归一化为[0,1] |
| 目标经度 | 目标位置的经度(\(x\)值),归一化为[0,1] |
| 目标状态 | 若被摧毁则为1,存活为0 |
\({ }^{\text {a }}\) 由于AFGYM简化了SAM的行为,未考虑其朝向。假设SAM具备全向探测能力,因此神经网络未被训练去解释定向雷达行为。
注:当前状态向量中所有数值均归一化到[0,1]范围,以约束神经网络反向传播时的梯度。归一化细节见附录A。
智能体与仿真器的成功交互很大程度上依赖于AFSIM环境的灵活性与状态透明性。MDP形式的实现为如何在现有仿真环境中集成机器学习智能体提供了一个可推广的有趣案例。协调与消息传递机制的更多细节见附录C。
二维问题结果¶
在训练完成后,通过在每个时间步匹配AFSIM与AFGYM的输出格式,我们成功实现了预训练智能体与AFSIM环境的协同(即完全去除AFGYM参与)。
使用A3C算法并在简单布置(如单战斗机对单SAM)上训练的模型出现了过拟合。当布置作出微小调整(如起始航向略变)时,算法性能大幅下降。A3C在多智能体布置(如多战斗机或战斗机+干扰机/诱饵机)中偶尔能表现出成功行为,但动作极不稳定,成功率低于10%。此外,所有算法最终都出现学习坍塌或陷入局部最优。虽然降低学习率能略微改善,但无法根除退化。
A3C最大的问题是缺乏泛化能力。训练后的算法即使在已训练的布置中也难以保持稳定成功,更无法适应新场景。如图3.3所示,算法对轻微扰动(如目标位置或初始航向变化)反应异常,常表现为无规律飞行或任务失败(飞离目标或被SAM击落)。
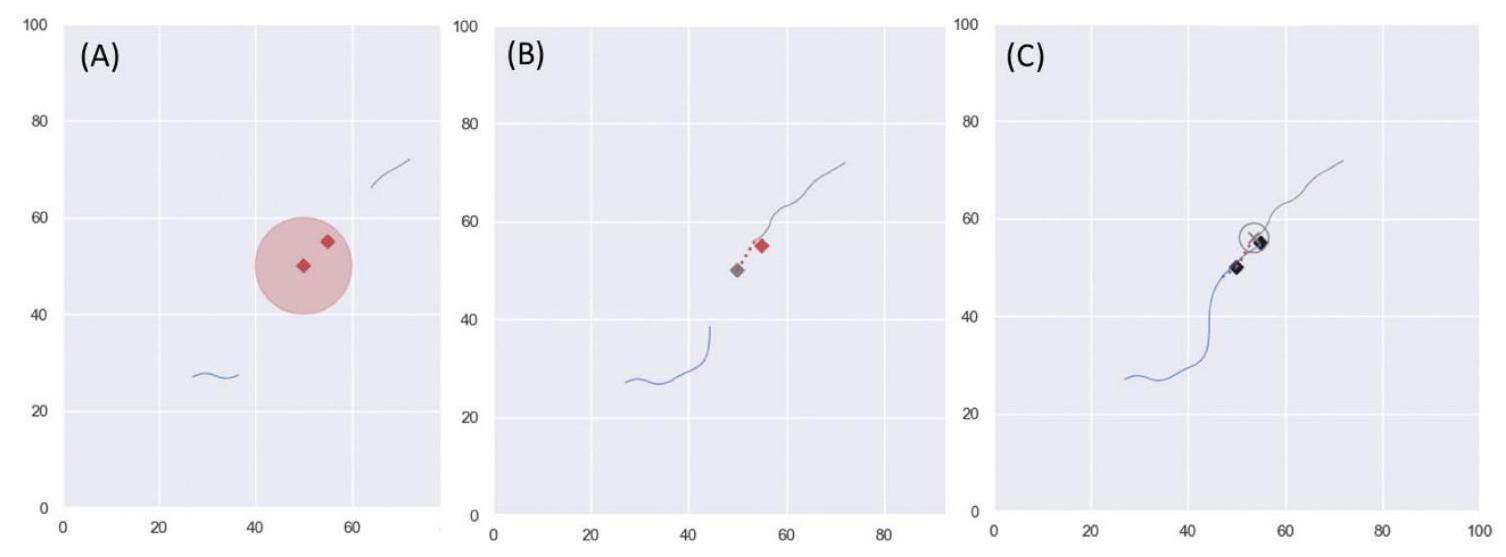
图3.2展示了四个AFGYM仿真示例,说明上述情形。仿真在\(100 \mathrm{~km} \times 100 \mathrm{~km}\)网格上进行,蓝线为战斗机航迹,红菱形及红圆圈代表SAM及其有效射程。
- 面板(A):存在多架战斗机,只有其中一架的导弹射程足以安全摧毁SAM。尽管航迹曲折,算法仍选择正确的战斗机进攻。
- 面板(B):展示了战斗机与干扰机布置的少见成功案例。在此情形中,所有战斗机均射程不足,必须依赖干扰机。图中干扰机(绿色航迹)在SAM附近安全区内盘旋并减小其射程,战斗机成功进攻。
- 面板(C):展示典型的战斗机与干扰机布置。A3C算法未能准确学习时序,导致干扰机飞得过远或被击落,从而战斗机撤退。
- 面板(D):为学习坍塌现象。神经网络某些连接饱和,输出固定指令使飞机持续逆时针转圈。
我们决定放弃A3C方法的原因主要有三点。首先,所有A3C训练仿真(100%)最终都出现了学习坍塌(learning collapse)。每一次训练在大约3,000次迭代后,智能体都会陷入“原地打转”的状态。该行为的高收敛率表明,AFGYM提出的任务规划问题并不适合A3C算法。其次,能够使用的结果都必须从坍塌前的检查点(pre-collapse checkpoint)中“精挑细选”出来。我们分析了所有训练检查点,发现绝大多数模型都无法成功完成任务。最后,大部分A3C的成功案例都是依赖“奖励塑形”(reward shaping)获得的。由于大多数仿真无法收敛,我们不得不通过额外奖励机制辅助算法,例如对靠近目标或朝向目标的动作给予正向奖励。这使得奖励函数高度特化,甚至逐渐接近基于规则(rule-based)的系统。
图3.2 A3C算法结果

随后,我们基于PPO(Proximal Policy Optimization)开发了单智能体算法,该算法对任务布局(laydown)的变化具有较强的鲁棒性与泛化能力。经过训练后,算法在不同任务布置中表现出稳定且可推广的行为。在AFGYM的10,000次仿真中,该算法的成功率达到了96%。图3.3展示了任务布局的情况。
- 面板(A)显示了每次仿真中被随机化的变量:战斗机的初始位置在浅蓝色方框内随机分布,其导弹射程和初始航向也会变化;SAM与目标的位置同样在各自区域内随机分布,且SAM的射程范围也被随机初始化。
- 面板(B)展示了由PPO训练算法控制的成功任务实例。在该快照中,战斗机成功摧毁目标并安全避开了SAM。其飞行轨迹较图3.2中的任何示例都更加平滑与直接。由于射程被随机化,战斗机在约35%的情形下射程优于SAM,因此算法在多数情况下选择避开SAM(在10,000次仿真中,仅3%的任务同时摧毁了SAM与目标)。
图3.3 PPO算法结果
我们还训练了一个涉及战斗机与诱饵的多智能体(multiagent)场景。图3.4展示了该场景。面板(A)显示了一个目标及其防护的地空导弹系统(SAM)。战斗机与诱饵从不同位置起飞。面板(B)显示诱饵被SAM击毁的情形。SAM在再次开火前会有一个短暂的延迟。面板(C)展示了战斗机利用这一延迟机会,摧毁了SAM和目标。对布局(laydown)的修改(例如战斗机和诱饵的起始位置及初始航向)表明,该算法尚未完全学会如何在时间上协调蓝方(Blue)智能体,以充分利用SAM的延迟。例如,在许多失败的任务中,战斗机在诱饵之前过早突入。值得注意的是,在某些任务中,诱饵会有意避开SAM。在修改起始位置的1万次AFGYM仿真中,成功率为18%;相比之下,当起始位置固定、仅变化初始航向时,成功率为80%。该算法的鲁棒性低于单智能体算法。
图3.4. 带诱饵的PPO算法结果
最后,我们还在AFSIM环境中验证了单智能体PPO算法的成功应用。图3.5显示该算法在类似图3.3的AFSIM布局(laydown)中成功执行导航。战斗机以近似正交的路径接近SAM,摧毁其后再突入攻击目标。该实验作为Python版PPO算法与AFSIM环境之间通信层的概念验证(proof of concept)。这种跨环境的领域迁移表明,我们训练的智能体能够在与训练环境不同的仿真系统中运行。由于AFSIM仿真耗时较长,本研究未对其鲁棒性与迁移程度进行系统测试。然而,我们认为PPO算法在1万次仿真中的成功率应与AFGYM相当,因为通信层确保PPO算法在AFSIM中“体验”的环境输入与在AFGYM中一致。
图3.5. PPO算法在AFGYM与AFSIM间可迁移性的验证
与A3C相比,PPO在性能上具有明显优势。学习崩溃(learning collapse)极为罕见,仅在5%至10%的情况下发生。经过数千次迭代后,学习过程仍保持稳定。此外,PPO学会了A3C无法实现的可泛化行为。PPO智能体在不同布局下表现出良好的泛化能力(96%),甚至在AFSIM中也能成功运行。相比之下,A3C未表现出任何泛化性,其在类似测试中的成功率不足5%,因为智能体要么飞入SAM的攻击范围,要么飞出战场。此外,PPO还学会了鲁棒的SAM规避行为,在攻击目标的途中能通过从SAM的上方或下方绕行来规避威胁。
2D问题的未来可能研究方向¶
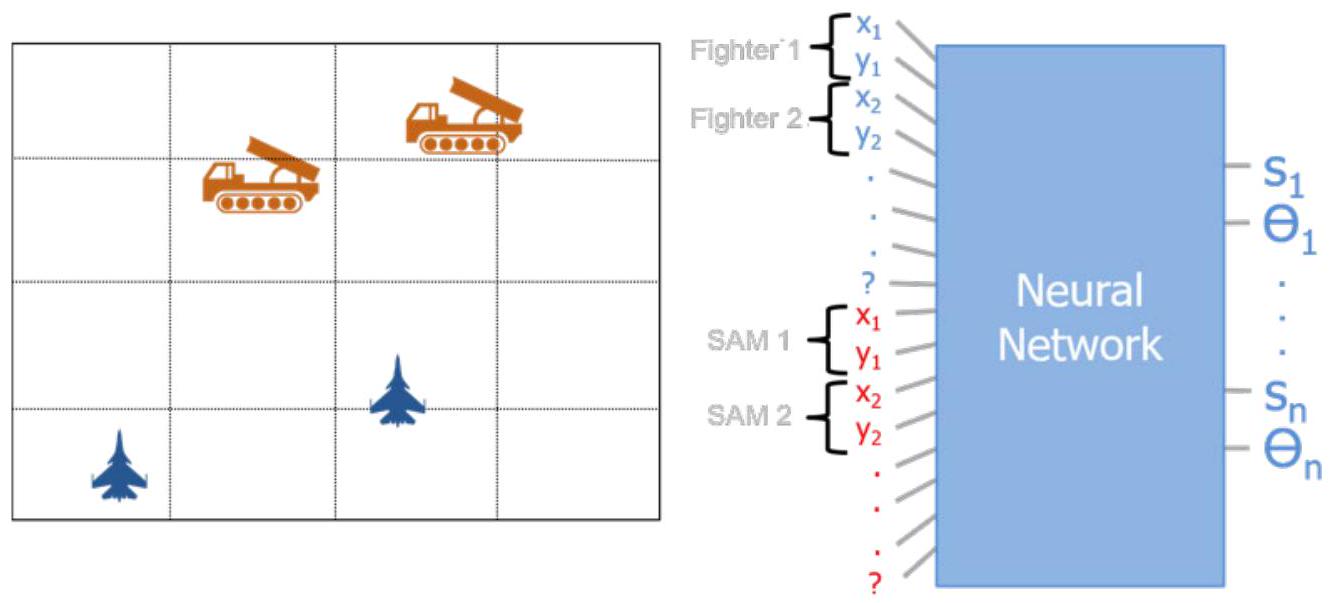
在任务规划中引入不同数量的智能体是一项挑战。在我们的案例中,智能体包括两种飞机和若干地空导弹系统(SAM)。在当前方法中,我们通过设置算法的输入与输出,使其在五架飞机和五个SAM的数量范围内运行。减少智能体数量是可行的,只需将多余智能体放置于无关位置或将其赋值为零即可。然而,增加智能体数量则需要扩展输入与输出空间并重新训练模型。这种智能体布置及其对应神经网络架构的方式如图3.6所示。
图3.6. 当前神经网络状态与输出的表示方式
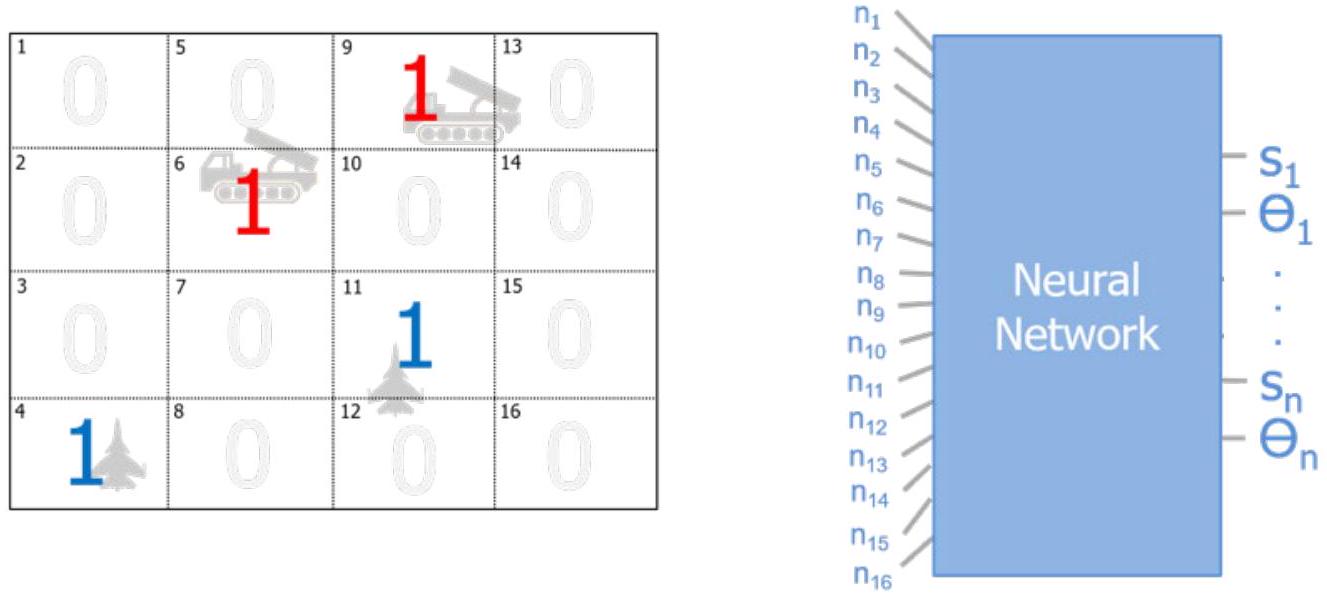
未来可探索的另一种方案是以“区域”为单位定义输入,并使输出对应于单一决策。该种状态与神经网络结构的替代形式如图3.7所示。在图中,\(x\) 和 \(y\) 表示各智能体的位置,下标表示具体的智能体编号;\(s\) 和 \(\theta\) 分别表示智能体的速度与方向。
图3.7. 基于地理区域的状态与输出表示方式
以这种方式构建状态,可自然地融入可变数量的智能体,因为地图中的每个地理区域都可以包含不同数量的各类智能体。图3.8展示了相同地图与架构在包含17个SAM和16架战斗机时的情形。
图3.8. 基于地理区域的表示方式可支持任意数量的智能体
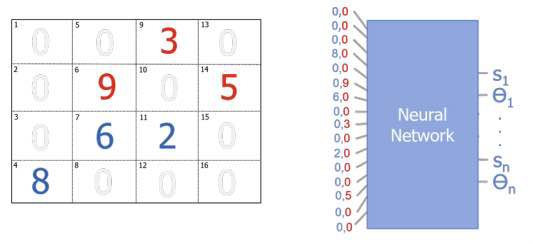
这种状态描述方式的优点在于,它能够自然地容纳大量智能体,因此是未来考虑大规模蜂群系统(swarm)时的潜在发展方向。该方法在获得更高泛化能力的同时,也带来了设计上的权衡与局限:网络的输入向量显著增大,并且随空间网格分辨率的提高而扩展;同时,系统布局(laydown)表示的精度也受限于网格分辨率。
4. 计算基础设施¶
要在任务规划问题空间中实现一个稳健的机器学习(ML)推理系统,可能需要大量计算资源与训练时间,从而限制系统的实用性。本节讨论基于AFSIM的强化学习(RL)所需的计算基础设施。当前的深度强化学习方法计算密集,需要大量评估过程以完成训练。\({ }^{55}\)
例如,非分布式版本的AlphaGo使用了48个CPU和8个图形处理单元(GPU);而分布式版本则利用了1,202个CPU和176个GPU。策略网络与价值网络的训练需要数千万至数亿次迭代。同样,生成足够规模的训练数据也需要大量时间与计算资源。此外,AlphaGo的仿真环境仅为棋盘游戏,对计算资源的需求极低;而当前研究中使用的复杂仿真模型显著增加了计算负担。
在早期方案讨论中,研究团队意识到可以通过系统性设计,将一组灵活的基础设施组件集成到AI系统中。通过合理的系统架构设计,可以为更复杂、更耗时或数据密集型的实现提供一种自然且具成本效益的扩展途径。表4.1列出了在计算基础设施设计中需考虑的主要因素。
表4.1. 影响计算基础设施的示例因素
| 因素 | 潜在考量 |
|---|---|
| 算法的并行性 | 算法的可并行程度如何?如果算法本身支持并行,最少需要多少计算工作单元?这些工作单元之间如何协调? |
| 对大数据集的依赖程度 | 每次迭代中算法使用的数据量是多少?这些数据是本地的还是外部获取的?需要与其他组件或系统交换的数据量及频率如何? |
| 算法在实现层面的模块化与可移植性 | 系统的单个组件能否独立更新与部署而无需重新部署整个系统?研究流程需要怎样的开发管线支持?新版本的部署难易程度如何? |
| 算法复杂度 | 计算复杂度随问题规模的变化如何?计算平台的扩展性是否足以支持目标问题? |
| 组件间交互机制 | 系统内组件间如何通信?需要支持何种通信机制?是否依赖网络或基于Web的服务?是否已有标准化的接口定义? |
| AFSIM与学习模块之间的耦合程度 | AFSIM与RL引擎的执行在多大程度上依赖彼此的技术实现细节?两者是否能独立演化并各自完成任务?是否采用共享内存或共享数据存储? |
| 信息安全与防护 | 系统需要哪些安全工具与辅助功能?现有安全机制是否对研究开发造成约束? |
在扩展AI系统计算能力的过程中,研究首先关注如何为AFSIM计算组件构建合适的运行环境,特别是采用计算节点集群架构的可能性。\({ }^{56}\)
研究团队重点评估了公有云与私有云方案,优先选择进入门槛低且能在研究场景中立即部署的选项。除本项目外,将AFSIM分布式运行于云架构的能力也对其他分析类工作具有潜在价值。
接下来,我们定义了AFSIM运行的操作环境。AFSIM的资源需求会随着问题空间规模与仿真次数的增加而增长。对于计算密集型仿真任务,需要开发方法以在单节点或多节点上并行启动多个AFSIM实例,因为AFSIM目前原生并不支持并行或分布式执行。\({ }^{57}\)
AFSIM的执行本身较为直接,可通过命令行启动。然而仍需脚本支持以自动化以下过程:启动AFSIM、收集与分析结果、并依据时间计划或外部触发重新运行带新参数的仿真。在研究初期阶段,强化学习模块与AFSIM之间的应用层接口保持开放状态,以便在ML模型定义更精确后实现对接。
研究还考虑了跨平台的解决方案与AFSIM实例的统一管理,“容器化”(container-based)方法被认为能有效满足这两方面需求。容器化管理具有以下优势:(1)消除在不同平台上维护一致运行环境的顾虑;(2)能够动态“启动/关闭”AFSIM计算实例;(3)潜在支持基于集群的负载均衡等技术。AFSIM本身提供Windows与Linux版本,通过标准云管理与编排工具(如Chef、Puppet、Ansible、CloudFormation)实现模板化部署将更为简化。\({ }^{58}\)
附录B进一步介绍了AFSIM与规划智能体容器化部署的具体过程及相关挑战。
总而言之,我们构建了一个基于高度可移植容器的虚拟化机器学习(ML)与AFSIM联合运行的概念验证环境。AFSIM 2.2仿真器、基于TensorFlow实现的ML引擎以及部分批处理执行框架均已在内部平台与外部Amazon Web Services(AWS)GovCloud平台的Docker容器中实现,初步测试至少在外部架构上取得了部分成功。容器化的使用支持通过复用AFSIM容器及多种ML技术,实现更高效的研究实验与算法选择。本方法应被进一步探索,用于需要大规模计算资源的分析研究工作。
计算基础设施挑战¶
标准的安全防护性环境控制与私有云平台的默认配置,构成了容器化解决方案开发的主要障碍。以安全为导向的控制措施阻碍了容器软件的安装及基础镜像的创建。例如,Docker工具依赖公共注册表提供标准基础镜像,同时在本地生成新镜像或更新Docker本身时需要频繁与外部服务通信。
尽管私有云分配的磁盘空间足以运行单个AFSIM实验,但却限制了多实例并行开发与改进所需的“工作空间”,从而削弱了高效测试与分布式训练数据生成的能力。虽然可用的虚拟机(VM)数量充足,但我们发现磁盘空间在账户所有者范围内共享,这在代码更新或数据生成时可能引发冲突。为缓解此问题,需要编写大量与平台相关的脚本。此外,容器工具被安装在系统级分区,无法灵活配置其可用磁盘空间,重新配置尝试也未成功。将开发环境迁移至AWS GovCloud公共云平台解决了所有这些问题,且标准化的工具链显著增强了AI系统的管理能力。
在互操作性、ML架构各组件之间的数据通信,以及第三方依赖项集成方面也存在技术挑战。尽管接口定义与互操作性问题在标准系统中较常见,但ML架构的长期设计尚未确定,导致“稳定”的ML容器定义(即AI系统的基础镜像)难以固定。例如,最佳实践通常是为应用的每个组件构建独立的容器,保持轻量化与独立维护。组件间交互可通过宿主系统资源(如共享磁盘卷)或服务化设计模式协调。随着系统演进,实际部署中使用的基础镜像可能需要底层计算基础设施提供不同的支持。然而,预期这些问题可以在当前选定的云平台及已定义的容器构建流程中得到解决。
鉴于此,研究重点转向外部GovCloud云平台。定义了运行Ubuntu 16.04的Amazon弹性计算云(EC2)实例,并构建了包含AFSIM 2.2与二维强化学习系统实现的新Docker镜像。该基础镜像扩展包含Python 3、TensorFlow、NumPy和Pandas。如前几章所述,该AI系统在每次运行间通过文件传递方式(容器内部)交换数据,并通过标准挂载卷机制让宿主系统访问结果。虽然系统仍在开发中,但AFSIM与AI的基本联合运行框架已建立。下一步计划包括完整运行AI系统以进行分析,并使用更大规模的EC2模板在多个AI系统实例上开展分布式ML实验。将当前的多应用镜像拆分为若干小型镜像将提供所需的灵活性与自由度,从而使系统逐步成熟,迈向实际应用。
5. 结论¶
在本报告中,我们探讨了将机器学习(ML)应用于防空压制(SEAD)问题的途径。我们创建了AFGYM,用于模拟SEAD任务。AFGYM是AFSIM的低保真版本,旨在为强化学习(RL)研究提供快速运行的环境。我们训练了RL智能体以执行日益复杂的SEAD任务。首先,我们从一维的战斗机与战斗机-干扰机场景入手,测试了Q-learning与GAN算法,发现两者均表现良好。随后,我们将任务扩展到二维的战斗机、战斗机-诱饵机与战斗机-干扰机场景,并测试了A3C与PPO算法,结果显示只有PPO表现稳定有效。
本项目原型化设计了一种AI系统概念验证(proof-of-concept),用于在简化的打击任务规划问题中帮助开发与评估新的作战概念(CONOPs)。给定一组具备不同传感器、武器、诱饵及电子战(EW)载荷的无人机(UAV),我们尝试构建能在孤立防空系统下制定任务策略的智能体。研究探索了多种现代统计学习技术,用于在两个具备作战相关性的仿真环境中训练空战规划智能体。这包括开发一个简化环境以支持快速算法迭代,以及将ML智能体集成入AFSIM战斗仿真框架。虽然本项目的测试问题属于空中领域,但我们预期类似技术经适当调整后也适用于其他作战问题与领域。
项目最初被设想为任务包规划器,但在发现其实现依赖于空战规划能力后,研究方向转向空战规划。在项目过程中,我们意识到神经网络的基本局限在于其作为通用函数逼近器,仅能实现固定输入与固定输出的映射。因此,我们的算法只能控制固定数量的蓝方智能体(Blue agents)。尚未开展多智能体(multi-agent)AI的研究,而后者是任务包编排系统所必需的。这一限制来自问题建模方式而非RL本身。因此,我们将多智能体训练排除在项目范围之外,聚焦于算法的测试与开发。
本探索性研究既展示了强化学习在应对复杂规划问题上的潜力,也揭示了该方法当前存在的持续性局限与挑战。具体而言,纯RL算法效率低下且易发生学习崩溃。RL的“悖论”在于:需要大量训练迭代才能培养出优秀智能体,但迭代次数越多,学习崩溃的可能性也越高。所有用于二维问题的算法均出现过学习崩溃现象。PPO代表了积极的方向性改进,其内置约束防止网络参数在每次迭代中变化过大,从而减少对学习率的手动调参。未来研究可尝试以更系统化的方式解决学习崩溃问题。研究的具体下一步可能包括:
- 提升问题复杂度与规模: 增加更多平台将迫使ML学习无人机间的协同策略。通过引入多个SAM、目标与地形障碍可提高环境的现实性,并可扩展至包含地形效应的三维空间。
- 聚焦多智能体问题: 未来的自动化任务规划应致力于开发稳健的多智能体算法。可借鉴近期StarCraft 2与DOTA 2 AI的成果,这些AI网络可同时控制多个角色。StarCraft AI在双向循环神经网络(bidirectional recurrent neural network)方面取得进展,使多智能体能够互相通信;而DOTA 2 AI则发展了无需通信、基于“信任”机制的独立智能体,可为长期胜利牺牲短期奖励。OpenAI的DOTA 2智能体采用了源自图像分析的算子(maxpool),以整合任意数量智能体的信息。\({ }^{59}\)
尽管上述两种方法的实现仍在进行中,但由于缺乏开源实现,进展较为困难。 - 验证AFGYM到AFSIM的迁移学习(transfer learning): 在二维问题中,智能体在AFGYM环境中训练完成后,通过在每个时间步匹配AFSIM与AFGYM的输出格式,实现了预训练智能体与AFSIM的协同运行(从而移除了AFGYM)。未来可直接在AFSIM环境中训练智能体,这将需要并行运行多个AFSIM实例,从而带来显著计算负担。对于以大规模仿真替代大数据集的分析任务,这种计算负载仍是主要挑战。同时,这也提出了一个更普遍的问题:建模与仿真系统及其他潜在可提供学习反馈的“目标环境”需随着ML的进步不断演化。
- 探索通过自博弈(self-play)提升性能: 现代AI(如AlphaZero与DOTA 2智能体)能够通过大规模自博弈持续改进。然而,由于当前问题为异构非对称任务(蓝方与红方智能体不相同),需引入红方SAM智能体以支持自适应自博弈。
- 实现超参数自动化调优: 超参数调优至关重要但缺乏系统理论支撑。自动化的超参数探索是防止学习过早崩溃的关键。
- 改进状态表示与问题建模: 当前环境表示缺乏灵活性。ML智能体只能针对固定数量的目标与平台进行训练。一旦引入更多目标或智能体,输入向量规模将增长,需重新训练智能体。在第4章中,我们已提出构建更通用问题表示的一种潜在途径。
政策启示¶
最后,我们回到第1章中讨论的国防部(DoD)任务规划问题。该章节中强调的主要挑战在于:当平台、传感器及其他能力的组合数量极为庞大时,其复杂性将超出人类在有限时间内进行有效规划与协调的能力。显然,我们在第2章与第3章中的演示并未完全体现这种复杂程度。然而,我们通过AI系统在不同初始条件下生成时间与空间协调的飞行路线所取得的成功表明,这种方法在规模化与更优参数调校的条件下应具有实用潜力。鉴于当前的先进规划器尚不能实现多平台的交互式协调,一种集成式规划能力将构成显著改进。然而,这一前景同时伴随以下重要警示:
-
训练具备现实能力集(数十个平台)对抗现实威胁(数十个SAM)的计算能力与时间需求的可扩展性仍不明确。在和平时期,可能可以动用数月时间与数百台计算机,但显然无法承担数十年或上万台计算机的需求。然而,一旦训练完成,其实际规划过程应远快于当前自动化规划器(后者可能需耗时数小时评估复杂任务,再经人工精调数小时)。将现有的机器学习(ML)方法应用于任务规划将迫使建模与仿真环境需具备更快、更可扩展且更灵活的特性。
-
蓝方或红方若引入新的类别能力(例如不仅仅是射程变化),则需重新训练算法以利用或规避这些新能力。如果现实算法训练需在超级计算机集群上耗时数周,这在冲突期间将难以使用。然而,我们的结果表明,训练后的算法应能较容易地适应资产数量与位置的变化。从长期来看,实现泛化能力的根本解决之道在于模块化与可组合网络(modular and composable networks)、迁移学习(transfer learning)以及结合概率学习与知识表示的混合方法(hybrid methods),从而能够利用已有知识,而非每次都从零开始(tabula rasa)。
-
本研究中的算法极易产生出乎意料、甚至可能令人类难以接受的结果。例如,算法可能会“牺牲少量飞机以挽救更多飞机”。即便在战斗情况下,这种结果通常也是不可接受的。现实冲突中,该效应通常被转化为“可接受风险水平”——即某些任务的重要性更高,因此允许承担更大风险;然而,我们开发的框架中并无风险调节“旋钮”。若要迫使算法遵循此约束,则必须在训练过程中将风险增大表现为任务得分的惩罚项。
-
现实世界中几乎不存在关于任务成功与失败的真实数据。与当代AI系统所需的大规模训练数据相比,针对防空系统的真实任务极为稀少,且几乎全都成功。回顾我们的实验,即便是简单任务,也需要上万条训练样本。因此,必须依赖仿真来训练此类算法,而仿真并不能完美代表现实世界。这带来了风险:算法在仿真世界中达到“完美表现”,却在现实中表现糟糕。正如自动驾驶汽车的发展所示,建立信任将需要更全面的测试,以及在算法可验证性、安全性与边界保证方面的根本性进步。
这些技术与过渡挑战具有深远的政策意义。目前,美国政府的多个部门正在投入大量资金与人力,以探索AI(尤其是机器学习,ML)的应用。在某些领域——例如存在丰富标注数据,且问题类型与算法设计初衷一致(如情报图像特征识别)——相对快速的成功是可以预期的。
然而,对于不具备这两项条件的应用领域,进展可能会较为缓慢。例如,如前所述,使用仿真生成训练数据将带来一整套计算与算法层面的挑战。本研究所探讨的特定问题在一定程度上展示了进展,但仅限于可人工规划的简单情境。显然,要处理更复杂的情况,需要在数据生成与训练时间上投入显著更多的资源。对于涉及战略决策的应用而言,若仿真甚至无法依赖物理规律,现实与仿真之间的对应关系可能极低,训练出的算法将几乎毫无用处。此外,高层战略推理的最终目标往往不是在既定约束下求最优解,而是颠覆或改变“游戏规则”本身。因此,国家安全决策者必须谨慎地将投资集中于最有可能取得成果的领域,而将其他方向作为基础性研究课题。并非所有安全问题都能通过AI解决。
附录A.二维问题状态向量归一化¶
二维状态向量的所有元素在AFSIM中每个时间步更新后,均被归一化到0至1之间的数值范围内。对输入空间进行这种归一化有助于提升收敛性与稳定性。归一化的过程如表A.1所示。场景布局(laydown)在设置时通过将目标与战斗机的初始位置视为矩形的两个对角点,从而确定归一化区域。场景中的所有事件均发生在该矩形范围内,矩形的长与宽被用于对多个场景参数进行归一化处理,如下一节所述。在表A.1中,变量FighterStart表示战斗机的随机生成起始点,它是下述多个归一化计算的基准点。此外,我们使用TotalLatLength与TotalLongLength作为归一化因子,其定义如下:\({ }^{60}\)
表A.1.二维问题建模——每个时间步汇报给机器学习智能体的状态变量
| 状态变量 | 归一化方式 |
|---|---|
| 战斗机航向 | AFSIM中的角度方位首先映射为标准单位圆角度(例如0度=正东,90度=正北)。我们将此转换后的角度称为FighterHeading。归一化公式为 FighterHeading/360(即Fighter*( \(\pi / 180\) )/\(2\pi\) ),其范围为[0,1]。 |
| 战斗机纬度 | (FighterCurrent_lat - FighterStart_lat)/TotalLatLength |
| 战斗机经度 | (FighterCurrent_long - FighterStart_long)/TotalLongLength |
| 战斗机是否被击毁 | 若被击毁则为1,否则为0 |
| 战斗机射程 | 射程在归一化前的单位为米。归一化时以布局矩形的长与高之和为基准(单位同为米): FighterFiringRange(normalized) = FighterFiringRange / [(TotalLatLength)40008000/360 + TotalLongLength(40075160*Cos(FighterStart_lat)/360)] \({ }^{a}\) |
| 战斗机弹药数量 | FighterWeapCount(normalized) = FighterWeapCount / max(SAMWeapCount, FighterWeapCount) |
| SAM航向 | 0 —— 向智能体固定汇报 |
| SAM纬度 | (SAMCurrent_lat - FighterStart_lat)/TotalLatLength |
| SAM经度 | (SAMCurrent_long - FighterStart_lat)/TotalLongLength |
| SAM是否被击毁 | 若被击毁则为1,否则为0 |
| SAM射程 | SAMFiringRange(normalized) = SAMFiringRange / [(TotalLatLength)40008000/360 + TotalLongLength(40075160*Cos(FighterStart_lat)/360)] \({ }^{b}\) |
| SAM弹药数量 | SAMWeapCount(normalized) = SAMWeapCount / max(SAMWeapCount, FighterWeapCount) |
| 目标航向 | 0 —— 向智能体固定汇报 |
| 目标纬度 | (TargetCurrent_lat - FighterStart_lat)/TotalLatLength |
| 目标经度 | (TargetCurrent_long - FighterStart_long)/TotalLongLength |
| 目标是否被击毁 | 若被击毁则为1,否则为0 |
附录B.容器化与机器学习基础设施¶
容器技术将虚拟化从机器层扩展到应用层,使应用能够在任意平台上运行。容器是应用程序的运行实例,它通过“镜像化”方式被封装,使其可在任何计算机上直接执行。虚拟机(VM)是对应用运行所依赖的物理计算环境及其操作系统的虚拟化。而容器进一步实现了跨系统运行——一个在某主机环境下准备好的应用可以在不同操作系统与主机上原样执行。图B.1展示了容器与虚拟机在应用层面的差异。特别地,容器并不直接与操作系统交互。实质上,容器通过以下两种方式实现对操作系统的虚拟化:(a)将应用运行所需的全部组件封装成镜像;(b)通过主机操作系统桥接该应用镜像的执行。\({ }^{61}\)
容器与虚拟机类似,同时也具备多项优势。两者均可作为云环境兼容的应用交付与实验环境,提供可复现的运行环境,并以自包含(self-sufficient)的打包形式部署研究产物。容器以应用为中心的设计理念带来了更多优势,与虚拟机结合使用可提升物理基础设施的整体效能。由于容器代表的是单个正在运行的应用实例,而非整个虚拟机系统,其在应用准备、测试与部署方面的时间与复杂度显著降低。容器化同时维护并连接应用与其外部依赖(包括其他容器),以保证系统中各组件的协同运行。图B.1与表B.1展示了虚拟机与容器化应用的总体对比。
图B.1.容器与虚拟机

来源:改编自Docker,“Orientation and Setup”,网页,未注明日期。
在应用层面,这种“平台独立性”促进了可复现计算研究架构与研究产物的可移植性。通过降低开发与运维成本,并允许在现实应用与决策支持中使用多样化的异构平台与工具,该方法可提升总体投资回报率。利用标准且公开的工具来协调或编排(orchestrate)容器化应用的群组执行,可进一步增强所选基础设施的效用,并在AI系统需要时动态应对可扩展性问题。基于开放、模块化或面向服务(service-oriented)架构的方法(如微服务microservices)也因此成为可行设计模式。
表B.1.虚拟机与容器化应用的简要比较
| 虚拟机(计算机虚拟化) | 容器(应用虚拟化) | |
|---|---|---|
| 统一、可复现、自包含的运行环境 | X | X |
| 支持云环境 | X | X |
| 适用于可复现研究 | X | X |
| 安装与执行开销最小 | X | |
| 启动速度快 | X | |
| 更新与维护简单快速 | X |
从应用及其运行所需资源的角度出发,我们利用容器化技术以自包含方式封装AFSIM的批处理执行过程,从而扩展其部署与可扩展性选项,而无需大量额外开发。
鉴于Docker在跨平台支持、易用性与普及度方面的优势,我们选择其作为本研究的容器化工具。\({ }^{62}\) Docker还提供私有本地注册服务,便于在开发团队内部分发容器。值得注意的是,高性能计算(HPC)环境可能提供或要求使用专用容器化工具,以支持在HPC系统上的研究。\({ }^{63}\) 事实上,容器化已被应用于美国橡树岭国家实验室(Oak Ridge National Labs)的深度学习研究,用于癌症行为与治疗研究——其核心目的在于以标准化方式向科研社区提供最新的机器学习工具,并支持算法多样性。\({ }^{64}\)
在最初阶段,我们在笔记本电脑上使用Docker创建了AFSIM 2.0.1的镜像,并通过AFSIM脚本生成大量仿真结果。容器化过程本身在一个运行开源Linux系统(Ubuntu 16.04)的虚拟机中执行,镜像以精简版Python 2.7为基础构建。当该系统验证可行后,我们在RAND内部云上运行Red Hat Enterprise Linux的多台服务器上安装了Docker。随后,我们在该私有云环境中准备了AFSIM 2.2镜像,并生成仿真数据以训练当前在一维场景中的机器学习实现。容器生成的AFSIM仿真结果随后传递至另一独立系统上正在开发的强化学习(RL)应用,由人工管理进行处理。
然而,私有云操作环境的设计限制了我们高效构建镜像以及在不同虚拟主机上协调多个容器工作的能力。所探索的Actor-Critic模型要求多个与AFSIM耦合的机器学习工作节点,并可能需要更多的训练迭代。此外,为并行生成更大规模的训练数据,我们还需编写自定义代码以管理私有云系统特定的磁盘配置,这与我们构建灵活计算基础设施的目标相悖。进一步而言,私有云的磁盘配置使得在不同虚拟主机之间协调容器变得复杂,增加了系统集成难度。
附录C.在二维问题中管理智能体与仿真交互¶
AFSIM仿真环境与基于Python的强化学习(RL)智能体之间的信息流如图C.1所示。这种方法在不同的RL智能体中是通用的。
图C.1.AFSIM/ML智能体协调
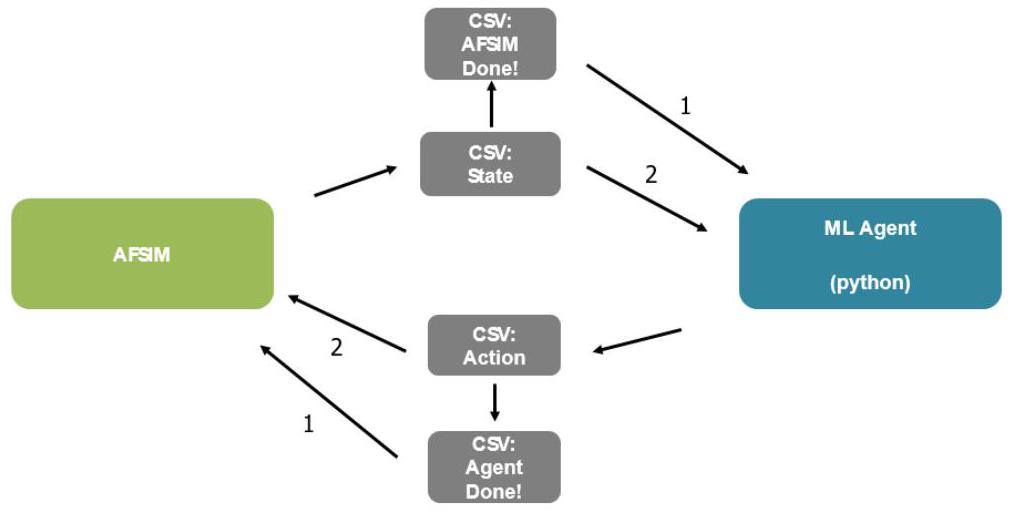
注:CSV指逗号分隔值(comma-separated value)文本文件。
以下列表总结了关键步骤:
- 运行开始时,ML智能体“监听”AFSIM的首次状态报告。\({ }^{65}\)
- AFSIM场景开始,战斗机直接朝目标飞行。
- 当战斗机在归一化空间中飞行总距离达到0.5单位(有关归一化细节见附录A)后,AFSIM将其首次状态更新报告写入一个文本文件,我们称之为“State”文件。
- 这将触发创建另一个文本文件,作为智能体的标志文件。该文件——“AFSIM-Done.csv”文件——表示当前状态的新数据已被追加到State文件中。\({ }^{66}\)
- AFSIM进入“监听”模式,等待来自智能体的下一步动作信号。
- 智能体从目录中移除新创建的“AFSIM-Done.csv”文件。
- 基于输入给智能体的最新状态向量,智能体将计算出的动作返回到一个“Action”文件中。在本问题中,该动作仅包括战斗机新的航向变化。
- 智能体在工作目录中创建一个“Agent-Done.csv”文件,用以作为AFSIM的信号,表明新的动作(战斗机航向)已准备就绪。
- AFSIM从目录中移除新创建的“Agent-Done”文件。
- 战斗机被指令转向最新航向并继续前进0.5个归一化单位。
智能体与AFSIM配对的过程将持续循环,直到仿真完成或战斗机被击落。
附录D.学习算法概述¶
MDP形式化¶
图1.1中的MDP(马尔可夫决策过程,Markov Decision Process)可由元组 \((S, A, P_{a}(s, s^{\prime}), R_{a}(s, s^{\prime}))\) 表示。
其中,\(S\) 是智能体在环境中可能经历的所有状态集合;\(A\) 是智能体可采取的所有动作集合;\(P_{a}(s, s^{\prime})\) 是一个马尔可夫转移矩阵,描述智能体通过动作\(a\)从状态\(s\)转移到另一状态\(s^{\prime}\)的概率;\(R_{a}(s, s^{\prime})\) 是奖励矩阵,描述通过动作\(a\)从状态\(s\)转移到\(s^{\prime}\)的期望奖励。
RL算法的目标是找到一个最优策略 \(\pi^{*}\),使得随时间的期望累计奖励最大化。一个小于1的折扣因子 \(\gamma\) 用于在无限时间跨度上稳定该级数。
Q-Learning¶
以下方程描述了Q-learning(Q学习)的基本原理。Q函数计算在状态\(s\)下采取动作\(a\)的期望奖励,其值由执行动作获得的即时奖励的期望值与未来所有奖励的期望值之和组成(假设遵循当前策略\(\pi\))。Q-learning的目标是学习并逼近所有状态-动作对的Q函数。
首先,问题可被形式化为一个MDP:
其中,\(S\) 表示环境中所有可能状态的集合,\(A\) 表示所有可能动作的集合,\(R\) 表示奖励矩阵,编码智能体在每个状态-动作对下获得的奖励;\(P\) 表示从任一状态转移到另一状态的概率;\(\gamma\) 表示折扣因子。
在此,我们使用Q-learning来学习给定一维部署(状态)下每个平台的进入距离(动作)。
Q函数的定义为:
该函数可以解释为与环境交互所获得的总累积奖励。折扣因子\(\gamma\)用于对未来奖励赋予较小权重,从而使无限级数收敛。交互定义为从初始状态\(s_{0}\)开始采取动作\(a_{0}\),然后按照策略\(\pi\)进行。由于MDP是概率性的,动作从概率分布\(\pi(s)\)中抽取,因此整个表达式取期望值。
Q-learning是一种off-policy算法,它试图在整个环境中逼近并映射\(Q\)函数,而不是直接学习\(\pi\)。
Q-learning的损失函数\(J\)定义为最小化以下目标:
其中,\(Q\) 表示神经网络的Q函数逼近器,\(y\) 表示经验计算得到的\(Q\)值(在多个智能体-环境仿真批次上平均)。损失函数为Q函数逼近值与真实Q值的平方误差之和。
\(y\)项用于迭代计算下一状态\(s^{\prime}\)下的最大奖励动作。Q-learning的更新步骤为:
其中,\(\alpha\) 为算法的学习率超参数。
生成对抗网络(Generative Adversarial Networks,GAN)¶
条件生成对抗网络(CGAN)可被解释为两个相互竞争的网络。一个网络(记作\(G\))用于在给定场景的条件下生成“伪造”计划(即非人工生成的计划);另一个网络(记作\(D\))用于在同一场景条件下区分真实计划与伪造计划。其目标函数\(V\)定义为如下的极小极大问题:
其中,\(x\)表示计划,\(y\)表示条件化的场景,\(z\)表示从概率分布\(p_{z}\)中采样的伪造计划。
在实际操作中,该极小极大问题的优化非常困难。GAN的训练过程为交替冻结并更新子网络:首先冻结判别器子网络,训练生成器以欺骗判别器(执行\(\min_G V(D, G)\));然后冻结生成器,更新判别器以区分生成计划与真实计划(执行\(\max_D V(D, G)\))。该过程重复,直到生成器或判别器达到预期性能。
A3C¶
A3C(异步优势行为者-评论家算法,Asynchronous Advantage Actor-Critic)基于REINFORCE算法,该算法是一种on-policy算法。与Q-learning不同,后者实质上相当于神经网络存储一个大的状态-动作对表格;on-policy算法直接通过神经网络同时学习Q函数\(Q(s,a)\)和策略函数\(\pi(s)\)。给定前述Q函数:
A3C的损失函数为:
其目标是最大化每个状态-动作对下的Q值与该动作被策略选中的概率之乘积。若\(Q\)值高,则增加该动作的概率;若\(Q\)值低,则减少其概率。
A3C引入了“优势值”(advantage)概念,定义为智能体执行某动作的期望奖励与实际奖励之差。算法维护一个神经网络以学习在给定状态下采取不同动作的价值。更新规则为:
PPO¶
TRPO(信任域策略优化,Trust Region Policy Optimization)通过限制更新前后策略\(\pi_{\theta}\)与\(\pi_{\theta^{\prime}}\)之间的Kullback-Leibler散度(KL)来防止策略更新过大。该约束优化在实践中难以精确计算,TRPO方法提供了一种基于代理目标函数的近似形式。此处仅总结其核心概念,详细推导见原论文。\({ }^{67}\)
关于作者¶
Li Ang Zhang(张立昂) 是兰德公司(RAND Corporation)的副工程师。他的研究兴趣包括将机器学习、优化与数学建模方法应用于国防与技术政策领域。张博士在匹兹堡大学(University of Pittsburgh)获得化学工程博士学位。
Jia Xu(徐佳) 曾任兰德公司高级工程师,现任空中客车公司(Airbus)城市空中交通系统首席架构师。他的研究兴趣包括飞机设计、无人机以及自主/人工智能(AI)系统。他在斯坦福大学(Stanford University)获得航空与航天学博士学位。
Dara Gold 是兰德公司的副数学家,她的研究兴趣涵盖多个应用领域的数学建模与仿真。她在波士顿大学(Boston University)获得数学博士学位,研究方向为微分几何。
Jeff Hagen 是兰德公司的高级工程师,研究方向包括技术系统分析、战略政策与决策制定。他在华盛顿大学(University of Washington)获得航空与航天学硕士学位。
Ajay K. Kochhar 是兰德公司的技术分析师。他在加州大学圣塔芭芭拉分校(University of California, Santa Barbara)获得计算机科学硕士学位,并在匹兹堡大学获得物理学硕士学位。
Andrew J. Lohn 是兰德公司的工程师兼帕迪·兰德研究生院(Pardee RAND Graduate School)公共政策教授。他主要从事科技政策领域的研究,尤其是在国家安全与全球安全背景下的技术政策问题。他在加州大学圣克鲁兹分校(University of California, Santa Cruz)获得电气工程博士学位。
Osonde A. Osoba 是兰德公司的信息科学家及帕迪·兰德研究生院教授。他的研究背景涵盖机器学习算法的设计与优化。Osoba博士在南加州大学(University of Southern California)获得电气工程博士学位。
美国的制空优势——其威慑战略的基石——正受到竞争对手(尤其是中国)的挑战。机器学习(ML)的广泛传播只会进一步加剧这一威胁。应对这一挑战的潜在途径之一,是通过更有效地利用自动化技术来实现新的任务规划方法。
本报告的作者展示了一种概念验证(proof-of-concept)人工智能(AI)系统原型,用于辅助开发和评估空域作战的新作战概念(CONOPs)。该原型平台集成了开源深度学习框架、当代算法,以及美国国防部标准的战斗仿真工具——高级仿真集成与建模框架(Advanced Framework for Simulation, Integration, and Modeling,AFSIM)。其目标是利用AI系统的可扩展重放学习能力、从经验中泛化的能力以及通过迭代提升性能的能力,加速并丰富作战概念的开发。
在本报告中,作者讨论了人工智能智能体(AI agents)在高度简化的压制敌防空(SEAD)任务中的协同行为。初步研究结果显示,强化学习(RL)在处理复杂的协同空中任务规划问题上具有显著潜力,同时也揭示了这种方法所面临的一些关键挑战。
References¶
Arulkumaran, Kai, Marc Peter Deisenroth, Miles Brundage, and Anil Anthony Bharath, "A Brief Survey of Deep Reinforcement Learning," IEEE Signal Processing Magazine, Vol. 34, No. 6, November 2017, pp. 26-38.
Åström, K. J., "Optimal Control of Markov Processes with Incomplete State Information," Journal of Mathematical Analysis and Applications, Vol. 10, No. 1, February 1965, pp. 174205.
Bahdanau, Dzmitry, Kyunghyun Cho, and Yoshua Bengio, "Neural Machine Translation by Jointly Learning to Align and Translate," arXiv:1409.0473, last revised May 19, 2016.
Bai, Haoyu, David Hsu, Mykel J. Kochenderfer, and Wee Sun Lee, "Unmanned Aircraft Collision Avoidance Using Continuous-State POMDPs," in Hugh Durrant-Whyte, Nicholas Roy, and Pieter Abbeel, eds., Robotics: Science and Systems VII, Cambridge, Mass.: MIT Press, 2012.
Brown, Jennings, "Why Everyone Is Hating on IBM Watson-Including the People Who Helped Make It," Gizmodo, August 10, 2017.
Canon, Scott, "Inside a B-2 Mission: How to Bomb Just About Anywhere from Missouri," Kansas City Star, April 6, 2017.
Chan, Dawn, "The AI That Has Nothing to Learn from Humans," The Atlantic, October 20, 2017.
Clive, Peter D., Jeffrey A. Johnson, Michael J. Moss, James M. Zeh, Brian M. Birkmire, and Douglas D. Hodson, "Advanced Framework for Simulation, Integration and Modeling (AFSIM)," Proceedings of the International Conference on Scientific Computing, 2015.
Defense Advanced Research Projects Agency, "DARPA Announces \(\$ 2\) Billion Campaign to Develop Next Wave of AI Technologies," webpage, September 7, 2018. As of December 17, 2019: https://www.darpa.mil/news-events/2018-09-07 Defense Science Board, Report of the Defense Science Board Summer Study on Autonomy, Washington, D.C.: Office of the Under Secretary of Defense for Acquisition, Technology, and Logistics, June 2016.
Docker, "Orientation and Setup," webpage, undated. As of December 20, 2019: https://docs.docker.com/get-started/#containers-and-virtual-machines
Ernest, Nicholas, David Carroll, Corey Schumacher, Matthew Clark, Kelly Cohen, and Gene Lee, "Genetic Fuzzy Based Artificial Intelligence for Unmanned Combat Aerial Vehicle Control in Simulated Air Combat Missions," Journal of Defense Management, Vol. 6, No. 1, March 2016.
Freedman, David H., "A Reality Check for IBM's AI Ambitions," blog post, MIT Technology Review, June 27, 2017. As of December 17, 2019: https://www.technologyreview.com/s/607965/a-reality-check-for-ibms-ai-ambitions/
Frisk, Adam, "What is Project Maven? The Pentagon AI Project Google Employees Want Out Of," Global News, April 5, 2018. As of December 17, 2019: https://globalnews.ca/news/4125382/google-pentagon-ai-project-maven/
Gillott, Mark A., Breaking the Mission Planning Bottleneck: A New Paradigm, Maxwell Air Force Base, Ala.: Air Command and Staff College, AU/ACSC/099/1998-04, April 1, 1998. As of December 17, 2019: http://www.dtic.mil/dtic/tr/fulltext/u2/a398531.pdf
Gilmer, Marcus, "IBM's Watson Is Making Music, One Step Closer to Taking Over the World," Mashable, October 24, 2016.
Goerzen, C., Z. Kong, and Berenice F. Mettler May, "A Survey of Motion Planning Algorithms from the Perspective of Autonomous UAV Guidance," Journal of Intelligent and Robotic Systems, Vol. 57, No. 1-4, January 2010, pp. 65-100.
Goodfellow, Ian, Jean Pouget-Abadie, Mehdi Mirza, Bing Xu, David Warde-Farley, Sherjil Ozair, Aaron Courville, and Yoshua Bengio, "Generative Adversarial Nets," in Z. Ghahramai, M. Welling, C. Cortes, N. D. Lawrence, and K. Q. Weinberger, eds., Advances in Neural Information Processing Systems (NIPS 2014), Vol. 27, 2014, pp. 2672-2680.
Gruntwork, "Why We Use Terraform and Not Chef, Puppet, Ansible, SaltStack, or CloudFormation," blog post, September 26, 2019. As of December 17, 2019: https://blog.gruntwork.io/why-we-use-terraform-and-not-chef-puppet-ansible-saltstack-or-cloudformation-7989dad2865c
Harken, Rachel, "Containers Provide Access to Deep Learning Frameworks," blog post, Oak Ridge National Laboratory, undated. As of December 17, 2019: https://www.olcf.ornl.gov/2017/05/09/containers-provide-access-to-deep-learningframeworks/
He, Kaiming, Xiangyu Zhang, Shaoqing Ren, and Jian Sun, "Deep Residual Learning for Image Recognition," Proceedings of the 29th IEEE Conference on Computer Vision and Pattern Recognition: CVPR 2016, 2016, pp. 770-778.
Heckman, Jory, "Artificial Intelligence Vs. 'Snake Oil:' Defense Agencies Taking Cautious Approach Toward Tech," blog post, Federal News Network, December 12, 2018. As of December 17, 2019: https://federalnewsnetwork.com/defense-main/2018/12/ai-breakthroughs-versus-snake-oil-defense-agencies-taking-cautious-approach-toward-tech/
Jackson, Joab, "Containers for High Performance Computing," blog post, New Stack, June 26, 2018. As of December 17, 2019: https://thenewstack.io/roadmap-containers-for-high-performance-computing/
Jones, Jimmy, "System of Systems Integration Technology and Experimentation (SoSITE)," blog post, Defense Advanced Research Projects Agency, undated. As of December 17, 2019: https://www.darpa.mil/program/system-of-systems-integration-technology-andexperimentation
Kania, Elsa, "AlphaGo and Beyond: The Chinese Military Looks to Future "Intelligentized" Warfare," blog post, Lawfare, June 5, 2017. As of December 17, 2019: https://www.lawfareblog.com/alphago-and-beyond-chinese-military-looks-future-intelligentized-warfare
Kim, Yoochul, and Minhyung Lee, "Humans Are Still Better Than AI at Starcraft-For Now," blog post, MIT Technology Review, November 1, 2017. As of December 17, 2019: https://www.technologyreview.com/s/609242/humans-are-still-better-than-ai-at-starcraftfornow/
Kincade, Kathy, "A Scalable Tool for Deploying Linux Containers in High-Performance Computing," blog post, Lawrence Berkeley National Laboratory, September 1, 2015. As of December 17, 2019: https://phys.org/news/2015-09-scalable-tool-deploying-linux-high-performance.html
Markoff, John, "Computer Wins on 'Jeopardy!': Trivial, It's Not," New York Times, February 16, 2011.
Martin, Jerome V., Victory From Above: Air Power Theory and the Conduct of Operations Desert Shield and Desert Storm, Miami, Fla.: University Press of the Pacific, 2002.
Matthias, Karl, and Sean Kane, Docker Up and Running, Sebastopol, Calif.: O'Reilly Media, 2015.
Mehta, Aaron, "DoD Stands Up Its Artificial Intelligence Hub," blog post, C4ISRNET, June 29, 2018. As of December 17, 2019: https://www.c4isrnet.com/it-networks/2018/06/29/dod-stands-up-its-artificial-intelligencehub/
Mirza, Mehdi, and Simon Osindero, "Conditional Generative Adversarial Nets," arXiv: 1411.1784, 2014.
Mnih, Volodymyr, Adrià Puigdomènech Badia, Mehdi Mirza, Alex Graves, Timothy P. Lillicrap, Tim Harley, David Silver, and Koray Kavukcuoglu, "Asynchronous Methods for Deep Reinforcement Learning," in Maria Florina Balcan and Kilian Q. Weinberger, eds., Proceedings of the 33rd International Conference on Machine Learning, Vol. 48, 2016, pp. 1928-1937.
Mnih, Volodymyr, Koray Kavukcuoglu, David Silver, Alex Graves, Ioannis Antonoglou, Daan Wierstra, and Martin Riedmiller, "Playing Atari with Deep Reinforcement Learning," arXiv: 1312.5602, 2013.
Mnih, Volodymyr, Koray Kavukcuoglu, David Silver, Andrei A. Rusu, Joel Veness, Marc G. Bellemare, Alex Graves, Martin Riedmiller, Andreas K. Fidjeland, Georg Ostrovski, Stig Petersen, Charles Beattie, Amir Sadik, Ioannis Antonoglou, Helen King, Dharshan Kumaran, Daan Wierstra, Shane Legg, and Demis Hassabis, "Human-Level Control Through Deep Reinforcement Learning," Nature, Vol. 518, February 25, 2015, pp. 529-533.
Nair, Arun, Praveen Srinivasan, Sam Blackwell, Cagdas Alcicek, Rory Fearon, Alessandro De Maria, Vedavyas Panneershelvam, Mustafa Suleyman, Charles Beattie, Stig Petersen, Shane Legg, Volodymyr Mnih, Koray Kavukcuoglu, and David Silver, "Massively Parallel Methods for Deep Reinforcement Learning," arXiv: 1507:04296, last updated July 16, 2015.
OpenAI, "OpenAI Five," blog post, OpenAI Blog, June 25, 2018. As of December 17, 2019: https://blog.openai.com/openai-five/ "OpenAI Five Model Architecture," webpage, June 6, 2018. As of December 20, 2019: https://d4mucfpksywv.cloudfront.net/research-covers/openai-five/network-architecture.pdf
Pfau, David, and Oriol Vinyals, "Connecting Generative Adversarial Networks and Actor-Critic Methods," arXiv: 1610.01945, last updated January 18, 2017.
Qiu, Ling, Wen-Jing Hsu, Shell-Ying Huang, and Han Wang, "Scheduling and Routing Algorithms for AGVs: A Survey," International Journal of Production Research, Vol. 40, No. 3, 2002, pp. 745-760.
Schulman, John, Sergey Levine, Philipp Moritz, Michael Jordan, and Pieter Abbeel, "Trust Region Policy Optimization," in Francis Bach and David Biel, eds., Proceedings of Machine Learning Research, Vol. 37: International Conference on Machine Learning, 2015, pp. 1889-1897.
Schulman, John, Filip Wolski, Prafulla Dhariwal, Alec Radford, and Oleg Klimov, "Proximal Policy Optimization Algorithms," arXiv: 1707.06347, last updated August 28, 2017.
Shannon, Claude E., "Programming a Computer for Playing Chess," Philosophical Magazine, Vol. 41, No. 314, 1950, pp. 256-275. "'Shifter' Makes Container-Based HPC a Breeze," blog post, National Energy Research Scientific Computing Center, August 11, 2015.As of December 17, 2019: http://www.nersc.gov/news-publications/nersc-news/nersc-center-news/2015/shifter-makes-container-based-hpc-a-breeze/
Silver, David, Aja Huang, Chris J. Maddison, Arthur Guez, Laurent Sifre, George van den Driessche, Julian Schrittwieser, Ioannis Antonoglou, Veda Panneershelvam, Marc Lanctot, Sander Dieleman, Dominik Grewe, John Nham, Nal Kalchbrenner, Ilya Sutskever, Timothy Lillicrap, Madeleine Leach, Koray Kavukcuoglu, Thore Graepel, and Demis Hassabis, "Mastering the Game of Go with Deep Neural Networks and Tree Search," Nature, Vol. 529, January 27, 2016, pp. 484-489.
Sutton, Richard S., and Andrew G. Barto, "Chapter 6: Temporal-Difference Learning," Reinforcement Learning: An Introduction, 2nd ed., Cambridge, Mass.: MIT Press, 2018.
Sylabs.io, "Documentation and Examples," webpage, undated. As of December 17, 2019: https://www.sylabs.io/
Tarateta, Maja, "After Winning Jeopardy, IBM's Watson Takes on Cancer, Diabetes," Fox Business, October 7, 2016. As of February 17, 2020: https://www.foxbusiness.com/features/after-winning-jeopardy-ibms-watson-takes-on-cancer-diabetes U.S. Air Force, Exercise Plan 80: RED FLAG-NELLIS (RF-N), COMACC EXPLAN 8030, ACC/A3O, July 2016a. U.S. Air Force, F-16 Pilot Training Task List, ACC/A3TO, June 2016b, Not available to the general public. U.S. Air Force, Office of the Chief Scientist, Autonomous Horizons: System Autonomy in the Air Force-A Path to the Future, Vol. 1: Human-Autonomy Teaming, Washington, D.C., 2015.
Vincent, James, "AI Bots Trained for 180 Years a Day to Beat Humans at Dota 2," The Verge, June 25, 2018. As of December 17, 2019: https://www.theverge.com/2018/6/25/17492918/openai-dota-2-bot-ai-five-5v5-matches
Weber, Bruce, "Swift and Slashing, Computer Topples Kasparov," New York Times, May 12, 1997.
White, Samuel G., III, Requirements for Common Bomber Mission Planning Environment, Wright-Patterson Air Force Base, Ohio: Department of the Air Force, Air University, Air Force Institute of Technology, AFIT/IC4/ENG/06-08, June 2006.
Wu, Yonghui, Mike Schuster, Zhifeng Chen, Quoc V. Le, Mohammad Norouzi, Wolfgang Macherey, Maxim Krikun, Yuan Cao, Qin Gao, Klaus Macherey, Jeff Klingner, Apurva Shah, Melvin Johnson, Xiaobing Liu, Łukasz Kaiser, Stephan Gouws, Yoshikiyo Kato, Taku Kudo, Hideto Kazawa, Keith Stevens, George Kurian, Nishant Patil, Wei Wang, Cliff Young, Jason Smith, Jason Riesa, Alex Rudnick, Oriol Vinyals, Greg Corrado, Macduff Hughes, and Jeffrey Dean, "Google's Neural Machine Translation System: Bridging the Gap Between Human and Machine Translation," arXiv: 1609.08144, last updated October 8, 2016.
About the Authors¶
Li Ang Zhang is an associate engineer at the RAND Corporation. His research interests include applying machine learning, optimization, and mathematical modeling toward the policy areas of defense and technology. Zhang received his Ph.D. in chemical engineering from the University of Pittsburgh.
Jia Xu, formerly a senior engineer at the RAND Corporation, is chief architect for urban air mobility systems at Airbus. His research interests include aircraft design, unmanned aerial vehicles, and autonomy/artificial intelligence. He holds a Ph.D. in aeronautics and astronautics from Stanford University.
Dara Gold is an associate mathematician at the RAND Corporation, where she is interested in mathematical modeling and simulation across a variety of applications. She holds a Ph.D. in math from Boston University, where she specialized in differential geometry.
Jeff Hagen is a senior engineer at the RAND Corporation. His research areas include technological systems analysis and strategic policy and decisionmaking. He received his M.S. in aeronautics and astronautics from the University of Washington.
Ajay K. Kochhar is a technical analyst at the RAND Corporation. He earned an M.S. degree in computer science from the University of California, Santa Barbara, and an M.S. in physics from the University of Pittsburgh.
Andrew J. Lohn is an engineer at the RAND Corporation and a professor of public policy at the Pardee RAND Graduate School. He works primarily in areas of technology policy, often within a national or global security context. He holds a Ph.D. in electrical engineering from the University of California, Santa Cruz.
Osonde A. Osoba is an information scientist at the RAND Corporation and a professor at the Pardee RAND Graduate School. He has a background in the design and optimization of machine learning algorithms. Osoba received his Ph.D. in electrical engineering from the University of Southern California. U.S. air superiority, a cornerstone of U.S. deterrence efforts, is being challenged by competitors-most notably, China. The spread of machine learning (ML) is only enhancing that threat. One potential approach to combat this challenge is to more effectively use automation to enable new approaches to mission planning.
The authors of this report demonstrate a prototype of a proof-of-concept artificial intelligence (AI) system to help develop and evaluate new concepts of operations for the air domain. The prototype platform integrates open-source deep learning frameworks, contemporary algorithms, and the Advanced Framework for Simulation, Integration, and Modeling-a U.S. Department of Defense-standard combat simulation tool. The goal is to exploit AI systems' ability to learn through replay at scale, generalize from experience, and improve over repetitions to accelerate and enrich operational concept development.
In this report, the authors discuss collaborative behavior orchestrated by Al agents in highly simplified versions of suppression of enemy air defenses missions. The initial findings highlight both the potential of reinforcement learning (RL) to tackle complex, collaborative air mission planning problems, and some significant challenges facing this approach.
footnote:¶
\({ }^{1}\) Elsa Kania, "AlphaGo and Beyond: The Chinese Military Looks to Future 'Intelligentized' Warfare," blog post, Lawfare, June 5, 2017.
\({ }^{2}\) 有关这些工作的示例,见 Adam Frisk, "What is Project Maven? The Pentagon AI Project Google Employees Want Out Of," Global News, April 5, 2018; 以及 Aaron Mehta, "DoD Stands Up Its Artificial Intelligence Hub," blog post, C4ISRNET, June 29, 2018.
\({ }^{3}\) 有关合理设定期望的几个示例,见 Jory Heckman, "Artificial Intelligence vs. 'Snake Oil:' Defense Agencies Taking Cautious Approach Toward Tech," blog post, Federal News Network, December 12, 2018.
\({ }^{4}\) Defense Science Board, Report of the Defense Science Board Summer Study on Autonomy, Washington, D.C.: Office of the Under Secretary of Defense for Acquisition, Technology, and Logistics, June 2016.
\({ }^{5}\) U.S. Air Force, Office of the Chief Scientist, Autonomous Horizons: System Autonomy in the Air Force-A Path to the Future, Vol. 1: Human Autonomy Teaming, Washington, D.C., 2015.
\({ }^{6}\) 有关人工智能“浪潮”的定义,见 Defense Advanced Research Projects Agency, "DARPA Announces $2 Billion Campaign to Develop Next Wave of AI Technologies," webpage, September 7, 2018.
\({ }^{7}\) Jerome V. Martin, Victory From Above: Air Power Theory and the Conduct of Operations Desert Shield and Desert Storm, Miami, Fla.: University Press of the Pacific, 2002.
\({ }^{8}\) 例如,见 U.S. Air Force, Exercise Plan 80: RED FLAG-NELLIS (RF-N), COMACC EXPLAN 8030, ACC/A3O, July 2016a; 以及 U.S. Air Force, F-16 Pilot Training Task List, ACC/A3TO, June 2016b, Not available to the general public.
\({ }^{9}\) Scott Canon, "Inside a B-2 Mission: How to Bomb Just About Anywhere from Missouri," Kansas City Star, April 6, 2017.
\({ }^{10}\) 例如,参见 Defense Advanced Research Projects Agency 的 System of Systems Integration Technology and Experimentation 项目 (Jimmy Jones, "System of Systems Integration Technology and Experimentation (SoSITE)," blog post, Defense Advanced Research Projects Agency, undated).
\({ }^{11}\) 有关路径规划算法的部分综述,见 C. Goerzen, Z. Kong, and Berenice F. Mettler May, "A Survey of Motion Planning Algorithms from the Perspective of Autonomous UAV Guidance," Journal of Intelligent and Robotic Systems, Vol. 57, No. 1-4, January 2010; 以及 Ling Qiu, Wen-Jing Hsu, Shell-Ying Huang, and Han Wang, "Scheduling and Routing Algorithms for AGVs: A Survey," International Journal of Production Research, Vol. 40, No. 3, 2002.
\({ }^{12}\) 有关该项目的历史背景,见 Mark A. Gillott, Breaking the Mission Planning Bottleneck: A New Paradigm, Maxwell Air Force Base, Ala.: Air Command and Staff College, AU/ACSC/099/1998-04, April 1, 1998; 以及 Samuel G. White III, Requirements for Common Bomber Mission Planning Environment, Wright-Patterson Air Force Base, Ohio: Department of the Air Force, Air University, Air Force Institute of Technology, AFIT/IC4/ENG/06-08, June 2006.
\({ }^{13}\) 政府机构(如国防高级研究计划局 DARPA)已认识到这些挑战,并资助了如“分布式作战管理(Distributed Battle Management)”等项目以应对。
\({ }^{14}\) Peter D. Clive, Jeffrey A. Johnson, Michael J. Moss, James M. Zeh, Brian M. Birkmire, and Douglas D. Hodson, "Advanced Framework for Simulation, Integration and Modeling (AFSIM)," Proceedings of the International Conference on Scientific Computing, 2015.
\({ }^{15}\) Bruce Weber, "Swift and Slashing, Computer Topples Kasparov," New York Times, May 12, 1997.
\({ }^{16}\) Claude E. Shannon, "Programming a Computer for Playing Chess," Philosophical Magazine, Vol. 41, No. 314, 1950.
\({ }^{17}\) Yonghui Wu, Mike Schuster, Zhifeng Chen, Quoc V. Le, Mohammad Norouzi, Wolfgang Macherey, Maxim Krikun, Yuan Cao, Qin Gao, Klaus Macherey, Jeff Klingner, Apurva Shah, Melvin Johnson, Xiaobing Liu, Łukasz Kaiser, Stephan Gouws, Yoshikiyo Kato, Taku Kudo, Hideto Kazawa, Keith Stevens, George Kurian, Nishant Patil, Wei Wang, Cliff Young, Jason Smith, Jason Riesa, Alex Rudnick, Oriol Vinyals, Greg Corrado, Macduff Hughes, and Jeffrey Dean, "Google's Neural Machine Translation System: Bridging the Gap Between Human and Machine Translation," arXiv:1609.08144, last updated October 8, 2016.
\({ }^{18}\) John Markoff, "Computer Wins on 'Jeopardy!': Trivial, It's Not," New York Times, February 16, 2011.
\({ }^{19}\) Marcus Gilmer, "IBM's Watson Is Making Music, One Step Closer to Taking Over the World," Mashable, October 24, 2016; Maja Tarateta, "After Winning Jeopardy, IBM's Watson Takes on Cancer, Diabetes," Fox Business, October 7, 2016.
\({ }^{20}\) Jennings Brown, "Why Everyone Is Hating on IBM Watson—Including the People Who Helped Make It," Gizmodo, August 10, 2017.
\({ }^{21}\) David H. Freedman, "A Reality Check for IBM's AI Ambitions," blog post, MIT Technology Review, June 27, 2017.
\({ }^{22}\) Volodymyr Mnih, Koray Kavukcuoglu, David Silver, Andrei A. Rusu, Joel Veness, Marc G. Bellemare, Alex Graves, Martin Riedmiller, Andreas K. Fidjeland, Georg Ostrovski, Stig Petersen, Charles Beattie, Amir Sadik, Ioannis Antonoglou, Helen King, Dharshan Kumaran, Daan Wierstra, Shane Legg, and Demis Hassabis, "HumanLevel Control Through Deep Reinforcement Learning," Nature, Vol. 518, February 25, 2015.
\({ }^{23}\) Dawn Chan, "The AI That Has Nothing to Learn from Humans," The Atlantic, October 20, 2017.
\({ }^{24}\) Kaiming He, Xiangyu Zhang, Shaoqing Ren, and Jian Sun, "Deep Residual Learning for Image Recognition," Proceedings of the 29th IEEE Conference on Computer Vision and Pattern Recognition: CVPR 2016, 2016; Dzmitry Bahdanau, Kyunghyun Cho, and Yoshua Bengio, "Neural Machine Translation by Jointly Learning to Align and Translate," arXiv: 1409.0473, last revised May 19, 2016.
\({ }^{25}\) Nicholas Ernest, David Carroll, Corey Schumacher, Matthew Clark, Kelly Cohen, and Gene Lee, "Genetic Fuzzy Based Artificial Intelligence for Unmanned Combat Aerial Vehicle Control in Simulated Air Combat Missions," Journal of Defense Management, Vol. 6, No. 1, March 2016.
\({ }^{26}\) Volodymyr Mnih, Koray Kavukcuoglu, David Silver, Alex Graves, Ioannis Antonoglou, Daan Wierstra, and Martin Riedmiller, "Playing Atari with Deep Reinforcement Learning," arXiv: 1312.5602, 2013.
\({ }^{27}\) Arun Nair, Praveen Srinivasan, Sam Blackwell, Cagdas Alcicek, Rory Fearon, Alessandro De Maria, Vedavyas Panneershelvam, Mustafa Suleyman, Charles Beattie, Stig Petersen, Shane Legg, Volodymyr Mnih, Koray Kavukcuoglu, and David Silver, "Massively Parallel Methods for Deep Reinforcement Learning," arXiv: 1507:04296, last updated July 16, 2015.
\({ }^{28}\) OpenAI, "OpenAI Five," blog post, OpenAI Blog, June 25, 2018.
\({ }^{29}\) Yoochul Kim and Minhyung Lee, "Humans Are Still Better Than AI at Starcraft—For Now," blog post, MIT Technology Review, November 1, 2017.
\({ }^{30}\) 我们将飞机建模为类似F-16战斗机的机型,后者经常为美国空军执行反制地空导弹(SAM)的任务。
\({ }^{31}\) 在我们的初始研究中,AI规划器被提供了SAM与蓝方飞机的精确位置,尽管这些信息并非必需。
\({ }^{32}\) 请注意,尽管战斗机与干扰机起始于完全相同的位置,我们并未对任何碰撞进行建模。
\({ }^{33}\) Mnih et al., 2013.
\({ }^{34}\) Richard S. Sutton and Andrew G. Barto, "Chapter 6: Temporal-Difference Learning," Reinforcement Learning: An Introduction, 2nd ed., Cambridge, Mass.: MIT Press, 2017.
\({ }^{35}\) 有关更深入的解释与数学公式,请参见附录D。
\({ }^{36}\) Ian Goodfellow, Jean Pouget-Abadie, Mehdi Mirza, Bing Xu, David Warde-Farley, Sherjil Ozair, Aaron Courville, and Yoshua Bengio, "Generative Adversarial Nets," in Z. Ghahramai, M. Welling, C. Cortes, N. D. Lawrence, and K. Q. Weinberger, eds., Advances in Neural Information Processing Systems (NIPS 2014), Vol. 27, 2014.
\({ }^{37}\) Mehdi Mirza and Simon Osindero, "Conditional Generative Adversarial Nets," arXiv:1411.1784, 2014.
\({ }^{38}\) David Pfau and Oriol Vinyals, "Connecting Generative Adversarial Networks and Actor-Critic Methods," arXiv:1610.01945, last updated January 18, 2017.
\({ }^{39}\) 有关更深入的解释与数学公式,请参见附录D。
\({ }^{40}\) 这是一种双关用法,结合了“AFSIM”和常用于开发ML算法的“Gym”工具集。AFGYM将在下一章中更详细地介绍。
\({ }^{41}\) 更多细节,见 K. J. Åström, "Optimal Control of Markov Processes with Incomplete State Information," Journal of Mathematical Analysis and Applications, Vol. 10, No. 1, February 1965。最近的一个应用,见 Haoyu Bai, David Hsu, Mykel J. Kochenderfer, and Wee Sun Lee, "Unmanned Aircraft Collision Avoidance Using Continuous-State POMDPs," in Hugh Durrant-Whyte, Nicholas Roy, and Pieter Abbeel, eds., Robotics: Science and Systems VII, Cambridge, Mass.: MIT Press, 2012
\({ }^{42}\) 出于显而易见的原因,在一维情形下并不存在“绕飞”的选项。
\({ }^{43}\) James Vincent, "AI Bots Trained for 180 Years a Day to Beat Humans at Dota 2," The Verge, June 25, 2018.
\({ }^{44}\) 截至2018年9月,许多此类gym已被托管。
\({ }^{45}\) 对于蓝方的行为,所开发的智能体被用作该行为逻辑的替代。
\({ }^{46}\) Kai Arulkumaran, Marc Peter Deisenroth, Miles Brundage, and Anil Anthony Bharath, "A Brief Survey of Deep Reinforcement Learning," IEEE Signal Processing Magazine, Vol. 34, No. 6, November 2017.
\({ }^{47}\) Volodymyr Mnih, Adrià Puigdomènech Badia, Mehdi Mirza, Alex Graves, Timothy P. Lillicrap, Tim Harley, David Silver, and Koray Kavukcuoglu, "Asynchronous Methods for Deep Reinforcement Learning," in Maria Florina Balcan and Kilian Q. Weinberger, eds., Proceedings of the 33rd International Conference on Machine Learning, Vol. 48, 2016.
\({ }^{48}\) 有关更深入的解释与数学公式,请参见附录D。
\({ }^{49}\) 诱饵被建模为与战斗机相同,但其损失不计为任务失败。其目的是分散红方SAM,从而在时机与几何条件合适时,为蓝方飞机提供一个短暂的脆弱窗口以加以利用。
\({ }^{50}\) 爆炸或消失梯度通常会导致此问题。反向传播步骤依赖于估计的梯度;若梯度过大或过小,神经网络参数便会受到影响并偏离期望的策略函数。
\({ }^{51}\) John Schulman, Sergey Levine, Philipp Moritz, Michael Jordan, and Pieter Abbeel, "Trust Region Policy Optimization," in Francis Bach and David Biel, eds., Proceedings of Machine Learning Research, Vol. 37: International Conference on Machine Learning, 2015; and John Schulman, Filip Wolski, Prafulla Dhariwal, Alec Radford, and Oleg Klimov, "Proximal Policy Optimization Algorithms," arXiv: 1707.06347, last updated August 28, 2017.
\({ }^{52}\) Schulman et al., 2015.
\({ }^{53}\) Schulman et al., 2017.
\({ }^{54}\) 这并不意味着AFSIM场景在“停止”和“启动”。由于AFSIM按线性顺序执行事件,向智能体报告当前状态所需的仅是一个预定义的事件触发(在我们的案例中为战斗机在归一化空间中飞行一定距离)。AFSIM的下一个事件——读取新的战斗机航向并转向该方向——在智能体的动作被送达之前不会发生,因为该动作被设置为AFSIM运行中的下一“事件”。
\({ }^{55}\) David Silver, Aja Huang, Chris J. Maddison, Arthur Guez, Laurent Sifre, George van den Driessche, Julian Schrittwieser, Ioannis Antonoglou, Veda Panneershelvam, Marc Lanctot, Sander Dieleman, Dominik Grewe, John Nham, Nal Kalchbrenner, Ilya Sutskever, Timothy Lillicrap, Madeleine Leach, Koray Kavukcuoglu, Thore Graepel, and Demis Hassabis, "Mastering the Game of Go with Deep Neural Networks and Tree Search," Nature, Vol. 529, January 27, 2016.
\({ }^{56}\) 我们在此聚焦AFSIM,因为AFGYM工具被专门设计为足够快速执行,无需分布式计算环境。
\({ }^{57}\) AFSIM支持集成到分布式交互式仿真与高层体系结构(HLA)的分布式仿真环境中,但这并非出于纯“计算”原因。此外,尽管可以对AFSIM进行核心开发以原生利用云端服务(而非云托管服务),但该开发工作劳动强度大,且超出本项目范围。
\({ }^{58}\) 关于云管理与编排工具的简要讨论见 Gruntwork 博客(Gruntwork, "Why We Use Terraform and Not Chef, Puppet, Ansible, SaltStack, or CloudFormation," blog post, September 26, 2019)。
\({ }^{59}\) "OpenAI Five Model Architecture," webpage, June 6, 2018.
\({ }^{60}\) 额外的0.1可确保在用 TotalLatLength 或 TotalLongLength 进行归一化时,所得数值略小于1,从而使战斗机有机会在不触及场景边界的情况下到达目标;一旦触边,ML将自动停止。
\({ }^{61}\) 从历史上看,容器化可追溯至20世纪70年代末,其核心是通过一种简单机制改变应用访问资源时所使用的基准参考点(即文件系统的“根”)。关于其与虚拟化的关系及动机,已有大量文献论述。进入21世纪初,容器化迅速成熟,并在2013年前后得到广泛常态化应用。
\({ }^{62}\) Karl Matthias and Sean Kane, Docker Up and Running, Sebastopol, Calif.: O'Reilly Media, 2015.
\({ }^{63}\) 例如,见 Sylabs.io, "Documentation and Examples," webpage, undated; "Shifter' Makes ContainerBased HPC a Breeze," blog post, National Energy Research Scientific Computing Center, August 11, 2015; 以及 Joab Jackson, "Containers for High Performance Computing," blog post, New Stack, June 26, 2018.
\({ }^{64}\) Rachel Harken, "Containers Provide Access to Deep Learning Frameworks," blog post, Oak Ridge National Laboratory, undated; Kathy Kincade, "A Scalable Tool for Deploying Linux Containers in High-Performance Computing," blog post, Lawrence Berkeley National Laboratory, September 1, 2015.
\({ }^{65}\) 此处的“监听”指智能体每秒检查其当前文件目录中是否已生成“AFSIM done”文件,该文件表明AFSIM的最新状态已就绪。后续步骤中会对此进行说明。
\({ }^{66}\) 向 State 文件追加数据本身不能作为“新状态已就绪”的标志。我们在尝试这种方法时发现其行为不稳定,常因智能体(或反向工作时的AFSIM)在仅写入部分数据片段时就检测到 State(或 Action)文件被追加所致。
\({ }^{67}\) Schulman et al., 2015; Schulman et al., 2017.