卷1:概要¶
VOLUME 1 SUMMARY
UNDERSTANDING THE LIMITS OF ARTIFICIAL INTELLIGENCE FOR WARFIGHTERS
https://www.rand.org/content/dam/rand/pubs/research_reports/RRA1700/RRA1722-1/RAND_RRA1722-1.pdf

© 2024 RAND Corporation
关于本报告¶
这是一个共五卷系列报告的第一卷,探讨人工智能(AI, Artificial Intelligence)如何在四个不同领域中辅助作战人员:网络安全、预测性维护、兵棋推演(wargames)以及任务规划(mission planning)。选择这些领域是为了体现AI潜在用途的多样性,并突出AI应用的不同局限性。每个应用场景在单独的卷册中呈现,以便面向不同的研究和应用群体。
本卷汇总了所有应用场景的主要发现与建议,面向政策制定者、采购专家以及对AI在作战应用方面具有一般兴趣的读者。以下卷册分别对各个应用场景进行了深入分析:
- Joshua Steier, Erik Van Hegewald, Anthony Jacques, Gavin S. Hartnett, 和 Lance Menthe,《Understanding the Limits of Artificial Intelligence for Warfighters: Vol. 2, Distributional Shift in Cybersecurity Datasets》,RR-A1722-2,2024
- Li Ang Zhang, Yusuf Ashpari, 和 Anthony Jacques,《Understanding the Limits of Artificial Intelligence for Warfighters: Vol. 3, Predictive Maintenance》,RR-A1722-3,2024
- Edward Geist, Aaron B. Frank, 和 Lance Menthe,《Understanding the Limits of Artificial Intelligence for Warfighters: Vol. 4, Wargames》,RR-A1722-4,2024
- Keller Scholl, Gary J. Briggs, Li Ang Zhang, 和 John L. Salmon,《Understanding the Limits of Artificial Intelligence for Warfighters: Vol. 5, Mission Planning》,RR-A1722-5,2024
本研究由空军装备司令部战略计划、项目、需求与评估处(AFMC/A5/8/9)委托实施,并在兰德公司(RAND Corporation)“空军项目研究部”(RAND Project AIR FORCE)下的“力量现代化与运用计划”(Force Modernization and Employment Program)中开展,属于2022财年的“Understanding the Bounds of Artificial Intelligence in Warfare Applications”项目。
兰德公司空军项目研究部(RAND Project AIR FORCE)¶
兰德公司空军项目研究部(RAND Project AIR FORCE, PAF)是美国空军部(DAF, Department of the Air Force)的联邦资助研究与开发中心,负责政策研究与分析,为美国空军与太空军提供决策支持。PAF为空军部提供有关政策方案的独立分析,研究范围包括现役与未来空、天、网部队的发展、运用、作战准备与支援。研究主要在四个项目下进行:战略与理论、力量现代化与运用、资源管理、以及人力发展与健康。本研究依据合同FA7014-22-D-0001完成。
更多关于PAF的信息可在以下网站获取:www.rand.org/paf/
本报告记录的工作最早于2022年9月23日与空军部共享。2022年9月版的报告草稿已由正式同行评审员及空军主题专家进行审查。
致谢¶
我们感谢项目联系人Kathryn Sowers,以及行动官Julia Phillips和Gregory Cazzell,在选择应用场景、界定研究问题和数据收集过程中给予的指导与支持。感谢以下人员:Jeremy Brogdon 协助我们理解预测性维护问题;Richard Moore 分享了其在相关领域的专业知识;R. Scott Erwin 和 JeanCharles Ledé 将我们与空军研究实验室的多项AI开发项目联系起来;Lee Seversky 分享了其在任务规划方面的经验;David A. Kapp 讨论了分布漂移(distributional shift);Kari K. Mott 中校分享了当前空中作战中心的自动化实践;Nicholas J. Harris 中校跨越多个时区向我们讲解了主空中打击计划(Master Air Attack Planning)过程。
我们还要感谢兰德公司的现任与前任同事,包括Caolionn O'Connell、Sherrill Lingel、Osonde Osoba 和 Chris Pernin,帮助我们制定研究议程。感谢John Salmon 的见解,以及Matthew Walsh、Marjory S. Blumenthal 和 Jair Aguirre 对本文的审阅。特别感谢John Drew 和 James Leftwich 在预测性维护问题上的专业意见;感谢Ellie Bartels 和 Paul K. Davis 就兵棋推演研究提供的经验;感谢Prince Rupert 港务局的Angela Gruber 介绍她将AI应用于识别合并移动目标的创新方法。没有他们的帮助,我们无法完成此系列报告;文中若有疏漏,均由作者负责。
问题¶
美国空军对人工智能(AI)在提升作战能力各方面的潜力日益关注。在本项目中,空军委托兰德公司反向思考:与其探讨AI能做什么,不如研究AI不能做什么,以便更好地理解AI在作战应用中的局限。
方法¶
我们并未试图界定AI的一般极限,而是选取并研究了四个具体的作战应用案例:网络安全(cybersecurity)、预测性维护(predictive maintenance)、兵棋推演(wargames)与任务规划(mission planning)。这些应用代表了AI可能用途的不同类别,并揭示了各自的约束条件。针对每个应用场景,我们采用了定制化的研究方法。在其中三个我们能够获得充分数据的案例中,进行了AI实验;而在兵棋推演案例中,我们从整体角度分析了AI可否被有效应用。各应用场景的详细内容见后续各卷。
主要发现¶
四个案例揭示了两个共同主题:(1)用于训练与测试AI系统的数据必须具备时效性、可访问性与高质量;(2)AI算法的局限性会显著影响其实用性。表S.1总结了各案例的主要发现。
表 S.1. 主要发现汇总
| 应用场景 | 数据局限性 | 算法局限性 |
|---|---|---|
| 网络安全 | - 要识别自适应威胁,数据必须是最新的。分布漂移(distributional shift)——即真实世界经验与初始训练数据之间的差距——会削弱模型性能,且在恶意软件或网络入侵中不可避免,尤其是对高维数据。 | - AI分类算法无法学习未被教授的知识。AI无法预测或识别新类型的恶意软件或入侵方式。 |
| 预测性维护 | - 数据必须可访问且经过良好处理。相关后勤数据分布于多个数据库,常存在条件不良问题。若无自动化数据管线(data pipeline),将无法收集足够数据以支持AI。 - 和平时期数据不能替代战时数据。AI无法弥补缺乏适用数据的问题。 |
- AI能很好地估计复杂函数,但代价是通用性降低。AI对单个部件的失效率预测远优于通用概率分布,但必须针对每个部件单独训练。 |
| 兵棋推演 | - 数字化是AI开发的前提。多数兵棋推演并未在数字环境中进行,无法生成电子数据。数字化是AI数据管线的必要前提。 - 需要新的数据类型。为支持AI,需要人机交互(HCI, Human-Computer Interaction)技术来捕获目前未被记录的推演特征。 |
- AI距离人类智能尚远,无法取代人类,也不能作出人类判断。因此,AI仅可能适用于特定阶段、特定目的的兵棋推演。 |
| 任务规划 | - 为应对自适应威胁,数据必须保持更新。模型需定期刷新以适应动态威胁环境。 | - AI在战术层面表现出色,但在战略层面仍显幼稚。它往往通过进入对手的“观察–判断–决策–行动(OODA)循环”来取胜,而非制定高明的总体战略。 - AI的精度低于传统优化方法,但其解更具鲁棒性(robustness),且计算速度更快。 |
建议¶
在所有应用案例的建议中,出现了两个共同主题:一是需要进行系统的测试与实验;二是需要建立更完善的基础设施以支持未来AI(Artificial Intelligence,人工智能)发展。表S.2汇总了各应用场景的具体建议。
表 S.2. 建议汇总
| 应用场景 | AI 测试与实验 | 支撑性基础设施 |
|---|---|---|
| 网络安全 | - 进行数据集分割测试,以评估分布漂移(distributional shift)对AI系统的重要性,并确定大致的性能衰减率与AI的“保质期”。 | - 不适用。 |
| 预测性维护 | - 通过AI实验改进备件需求预测(RSP, readiness spares packages),并将概念验证模型扩展到所有机型。这可能需要按部件、按平台分别实施。 - 考虑使用AI来解决更广泛的运筹学问题,例如确定应将哪些部件分配到何处。 |
- 建立数据运维管线(data operations pipeline),以高效地对多个部件和平台的飞机维护与RSP数据进行回溯分析。 |
| 兵棋推演 | - 将AI应用开发资源集中于最有潜力的方向:用于评估明确标准的条件变化推演;已具备数字基础设施(含人机交互HCI技术)的推演;以及定期重复的推演。 | - 扩大数字化推演基础设施与HCI(Human-Computer Interaction,人机交互)技术的应用,尤其是在系统探索与创新类推演中,以收集支持AI开发的数据。 - 普遍采用AI能力以支持未来兵棋推演活动。 |
| 任务规划 | - 考虑AI如何为无人机在突发情况下提供快速响应策略。 | - 投资开发将强化学习(reinforcement learning)应用于现有任务规划模型与仿真(如高级仿真、集成与建模框架AFSIM, Advanced Framework for Simulation, Integration, and Modeling)的工具。 |
第1章 概述¶
引言¶
空军部(DAF, Department of the Air Force)对人工智能(AI)提升作战能力各方面潜力的兴趣日益增强。国防部长劳埃德·奥斯汀(Lloyd Austin)在2021年曾指出:“AI 是我们创新议程的核心,它帮助我们更快地计算、更好地共享……并更迅速、更严谨地做出决策。”\({ }^{1}\)
在过去五年中,兰德公司(RAND Corporation)的研究人员探讨了AI如何用于改进指挥与控制(C2, Command and Control)、情报分析、作战评估、人力资源管理等多种应用。\({ }^{2}\)
而在本项目中,美国空军(USAF)委托兰德公司反向思考:不是探讨AI能做什么,而是研究AI不能做什么,从而理解AI在作战应用中的局限性。
\({ }^{1}\) Lloyd J. Austin III, “Secretary of Defense Austin Remarks at the Global Emerging Technology Summit of the National Security Commission on Artificial Intelligence (as Delivered),” transcript, U.S. Department of Defense, July 13, 2021.
\({ }^{2}\) Matthew Walsh 等人,《Exploring the Feasibility and Utility of Machine Learning-Assisted Command and Control: Vol. 1, Findings and Recommendations》,RAND Corporation, RR-A263-1, 2021a;Sherrill Lingel 等人,《Joint All-Domain Command and Control for Modern Warfare》,RAND Corporation, RR-4408/1-AF, 2020;Daniel Ish 等人,《Evaluating the Effectiveness of Artificial Intelligence Systems in Intelligence Analysis》,RAND Corporation, RR-A464-1, 2021;Lance Menthe 等人,《Technology Innovation and the Future of Air Force Intelligence Analysis》,RAND Corporation, RR-A341-1, 2021a;Daniel Egel 等人,《Leveraging Machine Learning for Operation Assessment》,RAND Corporation, RR-4196-A, 2022;David Schulker 等人,《Can Artificial Intelligence Help Improve Air Force Talent Management?》,RAND Corporation, RR-A812-1, 2021;Sean Robson 等人,《U.S. Air Force Enlisted Classification and Reclassification》,RAND Corporation, RR-A284-1, 2022。
显然,要确定AI在所有可能作战应用中的局限性,范围过于庞大,无法在单一报告中全面覆盖。因此,我们选取并研究了四个具体的作战应用场景:网络安全、预测性维护、兵棋推演和任务规划。这些场景是与委托方——空军装备司令部战略计划、项目、需求与分析处(AFMC/A5/8/9)——协商后确定的,旨在体现AI在空军部(DAF)中潜在用途的多样性,并揭示其应用约束。
本报告阐述了在使用AI解决不同问题时所面临的内在局限性,包括数据和算法方面的挑战。然而,我们并未探讨另一类重要局限——对抗性攻击(adversarial attack)对AI系统的破坏,如生成式对抗网络(GAN, generative adversarial networks)、数据投毒(data poisoning)、木马算法(Trojan algorithms)等。这类局限在兰德的其他报告中已有讨论。\({ }^{3}\)
\({ }^{3}\) 例如:Andrew J. Lohn 等人,《Attacking Machine Learning in War》,RAND Corporation, RR-4386-AF, 2020;Li Ang Zhang 等人,《Operational Feasibility of Adversarial Attacks Against Artificial Intelligence》,RAND Corporation, RR-A866-1, 2022。
我们所说的“人工智能”是什么意思?¶
更新自Marvin Minsky在1968年的原始定义,我们沿用兰德公司此前的研究,将人工智能(AI)广义定义为:“利用计算机执行过去需要人类智能才能完成的任务。”\({ }^{4}\)
在讨论作战应用时,我们遵循兰德的既有做法,将AI划分为以下六项具体能力:
- 计算机视觉(computer vision):在视觉媒体中检测和分类对象 \({ }^{5}\)
- 自然语言处理(natural language processing):识别与翻译语音和文本
- 规划(planning):利用模型寻找通向目标的行动路径
- 预测与分类(prediction and classification):基于历史数据对当前或未来数据进行分类
- 生成式学习(generative learning):合成语言、图像及其他媒体内容
- 专家系统(expert systems):基于规则的模型,用以表达专家知识与通用启发式方法 \({ }^{6}\)
在本系列报告中,我们主要关注利用当前机器学习(ML, Machine Learning)方法(尤其是神经网络)实现上述AI能力。尽管ML与AI常被混用,但两者并非同义。AI近年来的突破主要源于深度学习(deep learning)革命——ML的一个分支,它使传统的计算机视觉与自然语言处理方法几乎被淘汰。\({ }^{7}\)
深度学习通常指神经网络(neural network)中包含多个“隐藏层(hidden layers)”的结构,每层由相互连接的“神经元(neurons)”组成。\({ }^{8}\)
\({ }^{4}\) Minsky最初定义AI为“使机器能够做那些若由人完成则需要智能的事情的科学”(Marvin Minsky, Semantic Information Processing, MIT Press, 1968, p. v)。
\({ }^{5}\) 尽管计算机视觉在技术上属于预测与分类的子集,但其方法具有独特性与特定脆弱性,因此在此作为独立类别讨论。
\({ }^{6}\) 这些能力来自标准AI参考书:Stuart Russell 和 Peter Norvig,《Artificial Intelligence: A Modern Approach》第4版,Pearson, 2021。另见 Li Ang Zhang 等人,《Incorporating Artificial Intelligence into Army Intelligence Processes》,RAND Corporation, RR-A729-1, 2021。
\({ }^{7}\) 早期计算机视觉主要依赖特征提取方法(如边缘检测、角点检测)。参见 Niall O'Mahony 等人,《Deep Learning vs. Traditional Computer Vision》,载于 Advances in Computer Vision,Springer, 2019。
\({ }^{8}\) M. L. Jordan 和 T. M. Mitchell, “Machine Learning: Trends, Perspectives, and Prospects,” Science, Vol. 349, No. 6245, July 2015。
现代机器学习通常分为三类:监督学习(supervised learning),即使用带标签数据训练AI系统;无监督学习(unsupervised learning),即AI系统在无标签数据中发现潜在结构;以及强化学习(reinforcement learning),即AI系统通过与环境交互最大化预期效用函数。\({ }^{9}\)
本报告涵盖三者,但重点关注监督学习与强化学习——虽然它们对数据量的需求不一定高于无监督学习,但通常需要对数据进行预处理或标注。
\({ }^{9}\) Christopher M. Bishop, Pattern Recognition and Machine Learning, Springer, 2006, p. 3.
我们未探讨通用人工智能(AGI, Artificial General Intelligence)或其他尚属突破性的新型机器学习方法。尽管AGI尚无统一定义,但一般指具备类似人类的“通用”认知能力的系统,而非仅限于特定任务。目前学界尚未就实现该能力的技术达成共识,且多数专家认为仍需重大基础性突破。\({ }^{10}\)
正如一位学者所言:
“也许机器终将像人一样聪明,甚至更聪明,但这场竞赛远未结束。要让机器真正理解并推理其周围世界,还有大量工作要做……这就是为何基础研究仍然至关重要。”\({ }^{11}\)
然而,我们也意识到,突破性研究往往无法预测。因此,当我们谈论AI在作战应用中的局限时,特指我们对当前技术水平的理解。描述当今AI的极限,也许就像1950年讨论电力的极限一样,当时核动力汽车似乎与飞行汽车同样合理。尽管如此,这些预测仍可为未来20年的规划提供参考。
\({ }^{10}\) Menthe 等人, 2021b。
\({ }^{11}\) Gary Marcus, “Artificial General Intelligence Is Not as Imminent as You Might Think,” Scientific American, July 1, 2022。
选择应用场景¶
本项目的首要任务是选择空军部(DAF, Department of the Air Force)感兴趣的潜在AI(Artificial Intelligence,人工智能)应用场景,并且这些场景能够揭示AI应用的不同局限类型。我们首先提出了五项筛选标准,如表1.1所示。
表 1.1. 筛选标准
| 标准 | 描述 |
|---|---|
| DAF 重要性 | 该AI应用所针对的能力缺口或流程对空军部的重要性如何? |
| DAF 影响力 | 理论上,该AI应用能在效率、效能、人力资源利用率和/或灵活性方面提升多少? |
| AI 成功经验 | 在相关领域中,AI在实现此类改进方面的成功程度如何? |
| AI 局限相关性 | 该应用场景揭示AI在作战人员使用中重要局限或边界的可能性有多大? |
| 研究可行性 | 兰德公司(RAND)在该领域开展机器学习(ML, Machine Learning)实验的可行性如何? |
随后,我们提出了14个潜在研究方向,涵盖从情报、监视与侦察(ISR, Intelligence, Surveillance, and Reconnaissance)应用,到指挥控制(C2, Command and Control)与作战,再到企业级用途,如后勤与人事管理。\({ }^{12}\)
这些方向结合了AI已在空军部或兰德内部活跃开展的研究领域,以及专家(SMEs, Subject-Matter Experts)认为仍具潜力的方向。表1.2按类别列出了潜在研究领域,并依据五项标准给出了大致排名。
\({ }^{12}\) 我们最初仅提出了13个研究方向;“兵棋推演(wargames)”是在委托方建议下增补的方向。
表 1.2. 人工智能应用选择
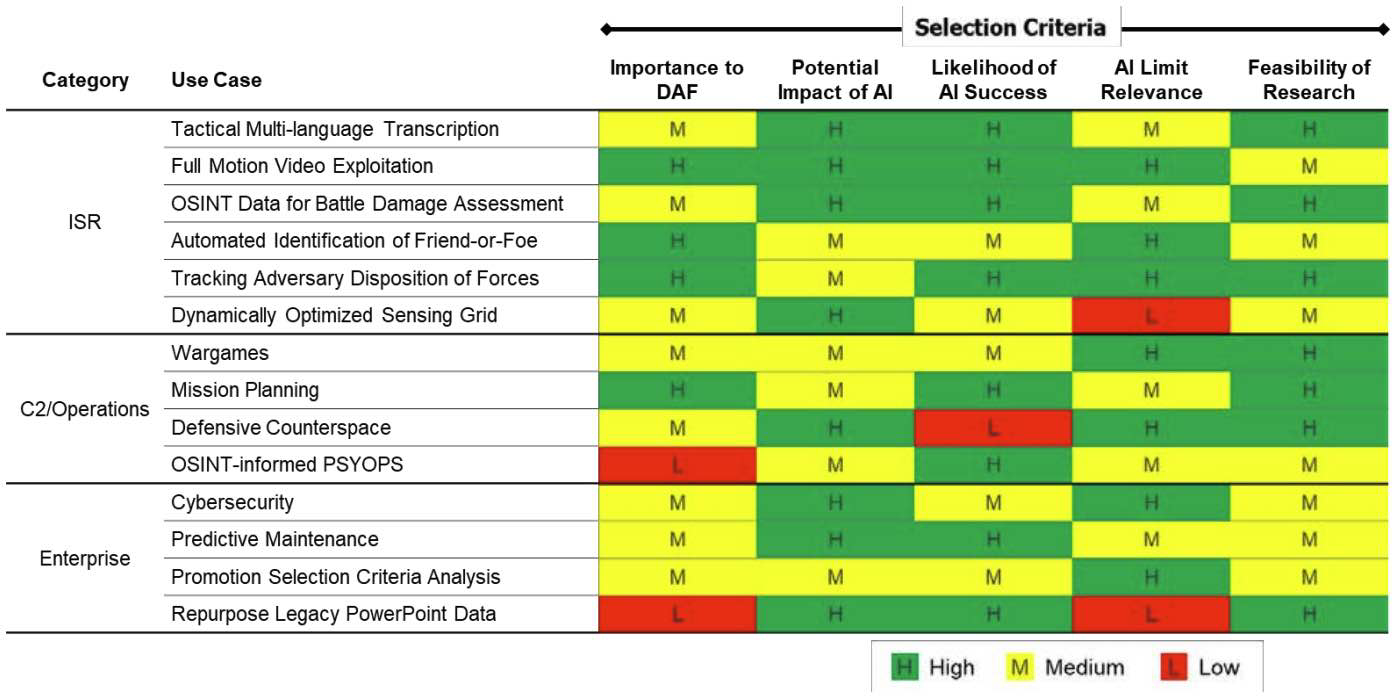
注:OSINT = 开源情报(open source intelligence);PSYOPS = 心理作战(psychological operations)。
虽然我们期望筛选标准能明确指出优先方向,但从表1.2可见,结果较为复杂,并无显著“优胜者”。AI具有广泛适用性,许多研究方向都颇具吸引力,但每个方向也都有自身问题。最终,我们与委托方协商后,决定排除整个ISR类别,因为兰德研究人员已在该领域完成大量研究,且相关的力量部署与传感网络研究正在进行中。\({ }^{13}\)
尽管如此,该领域仍是后续研究的重要方向。我们还排除了任何在某一评估维度中被评为“低”的方向。最后被剔除的研究方向是“晋升标准分析”,因为其高评分最少,且兰德研究团队近期已有相关研究成果。\({ }^{14}\)
\({ }^{13}\) 参见 Menthe 等人, 2021a;Menthe 等人, 2021b。
\({ }^{14}\) 参见 Schulker 等人, 2021。
由此,我们最终确定了四个应用场景:网络安全(cybersecurity)、预测性维护(predictive maintenance)、兵棋推演(wargames) 和 任务规划(mission planning)。这些场景涵盖多种类型,且提出了不同的研究挑战。
如何阅读本系列报告¶
第2章总结了每个应用场景的研究方法、发现与建议。本系列其余四卷则分别深入探讨各自的应用场景。\({ }^{15}\)
之所以将其分卷呈现,是因为不同作战领域的群体可能对不同的案例感兴趣。
\({ }^{15}\) 参见:Joshua Steier 等人,《Vol. 2, Distributional Shift in Cybersecurity Datasets》,RR-A1722-2, 2024;Li Ang Zhang 等人,《Vol. 3, Predictive Maintenance》,RR-A1722-3, 2024;Edward Geist 等人,《Vol. 4, Wargames》,RR-A1722-4, 2024;Keller Scholl 等人,《Vol. 5, Mission Planning》,RR-A1722-5, 2024。
第2章 研究方法、发现与建议¶
我们针对每个应用场景定制了研究方法。在三个具备公开大型数据集的案例中,我们聚焦特定任务,从而能对数据进行技术性实验。而在剩下的“兵棋推演”案例中,我们构建了一个分析框架,宏观探讨AI未来可否被有效应用。本章将分别介绍每个应用场景,最后总结其共性主题。
网络安全¶
该应用场景的研究目标是分析分布漂移(distributional shift)对AI在网络安全应用中有效性的限制作用。
分布漂移指AI系统在实际运行中遇到的数据与其训练或测试阶段使用的数据随时间产生偏差。根据漂移的具体形式,这种变化可能显著降低AI系统的性能。我们聚焦分布漂移,是因为近期研究显示,它可能是影响AI在网络安全领域应用效果的关键因素。正如一项研究指出:“在真实的网络安全环境中,黑客往往会改变攻击方式,这会导致多种变量在一段时间内发生变化。”\({ }^{16}\)
\({ }^{16}\) Shu-Yi Xie 等人,“Models and Features with Covariate Shift Adaptation for Suspicious Network Event Recognition,” 2019 IEEE International Conference on Big Data, Los Angeles, December 9–12, 2019, p. 5946.
在此类问题中,分布漂移尤其棘手,因为漂移通常不可预测,且可发生在极高维度的特征空间中。在网络安全中,黑客可能以出乎意料的方式适应系统,而每个软件或事件的分类通常需要成千上万的特征。
这与更传统的AI任务(如人脸识别)不同,后者虽然也包含大量特征,但这些特征所携带的信息不会随时间变化。因此,最直接的缓解策略——通过扩充初始数据集以覆盖潜在未来变化——在此场景下几乎不可行。
例如,某数据集使用约2,000个维度来分类潜在恶意软件。如果在每个维度上仅扩大10%的取值范围,总体搜索空间的体积将呈指数级增长,增加多个数量级,几乎无法实现。
研究方法(Approach)¶
基于对现有文献的回顾,我们选择了两个常见的网络安全任务——网络入侵检测(network intrusion detection)与恶意软件识别(malware identification)——这两个任务均拥有大型且公开可用的基准数据集。
在网络入侵检测任务中,我们基于开源框架 TensorFlow 构建了两个AI模型,用于分析加拿大网络安全研究所(CIC, Canadian Institute for Cybersecurity)提供的两组数据集:CIC-IDS2017 和 CSE-CIC-IDS2018。\({ }^{17}\)
在恶意软件识别任务中,我们使用了为三个超大型互相关联数据集专门创建的AI系统:EMBER(Endgame Malware BEnchmark for Research)、SOREL-20M(Sophos-Reversing Labs-20 Million) 和 BODMAS(Blue Hexagon Open Dataset for Malware Analysis)。\({ }^{18}\)
\({ }^{17}\) Martín Abadi 等人,“TensorFlow: Large-Scale Machine Learning on Heterogeneous Distributed Systems,” Google Research, 2015;Iman Sharafaldin 等人,“Toward Generating a New Intrusion Detection Dataset and Intrusion Traffic Characterization,” Proceedings of the 4th International Conference on Information Systems Security and Privacy, 2018。
\({ }^{18}\) Hyrum S. Anderson 和 Phil Roth,“EMBER: An Open Dataset for Training Static PE Malware Machine Learning Models,” arXiv, 2018;Richard Harang 和 Ethan M. Rudd,“SOREL-20M: A Large Scale Benchmark Dataset for Malicious PE Detection,” arXiv, 2020;Limin Yang 等人,“BODMAS: An Open Dataset for Learning Based Temporal Analysis of PE Malware,” IEEE Symposium on Security and Privacy Workshops, 2021。
我们利用这些AI模型探讨了这些数据集中分布漂移(distributional shift)的存在程度,以及这种漂移是否足以降低AI性能。
为此,我们采用了一种新颖的数据分段(data segmentation)方法:将数据集按时间窗口进行切片,并反复用相同的AI模型在不同子集上进行训练与测试。
通过固定AI架构(即不针对每个数据子集重新优化超参数和配置——这通常是标准做法),我们得以隔离“数据变化”对AI性能的影响。这种方法使我们能够识别分布漂移的存在,并评估其随时间对AI性能的影响程度。
研究结果(Results)¶
我们的研究确认,所分析的网络安全数据集确实存在分布漂移现象,并且只要这些数据能反映现实情况,AI在此类任务中的性能就会随时间退化。这意味着网络安全领域的AI系统具有“保质期”,必须定期进行再训练(retraining)。主要发现如下:
-
分布漂移对某些网络安全应用的影响显著,但时间尺度不同。
在网络入侵检测中,两个AI模型的准确率以每天约4.5%的速度下降;
而在恶意软件识别中,变化速率较慢,约为每年1.5%。\({ }^{19}\)
需要强调的是,这些估计仅基于少量时间段的测量结果,其他数据集可能表现出显著不同的行为。\({ }^{20}\) -
AI系统无法可靠地从旧数据中识别新型网络攻击。
在所研究的案例中,AI系统几乎无法识别新攻击;尽管更先进的AI模型(通过调整超参数)可能表现更好,但当AI依赖最新数据,而数据生成速度有限时,其优化空间极为有限。
这一局限不仅存在于网络安全领域,也适用于任何在高维空间中面临不可预测变化的AI算法。
\({ }^{19}\) 我们针对不同数据集采用了略有差异的性能度量方法:网络入侵检测以精确率(precision,真阳性/全部阳性)衡量;恶意软件识别使用 \(\mathrm{F}_{1}\) 分数,即精确率与召回率(recall)的调和平均值。
\({ }^{20}\) 尤其需要注意的是,网络入侵数据集虽然反映了真实网络流量,但其构建基于少数用户一周内的活动,因此威胁的时间尺度可能被压缩,且样本来源有限。
基于以上发现,我们提出了一项普适性建议:
应开展类似的数据集分段测试,以评估分布漂移对任何网络安全AI系统的影响程度。
这种测试能提供性能衰减率(decay rate),用于估计AI系统的再训练间隔或“保质期”。
此外,它还能帮助判断AI系统是否足够稳健,或是否需要人工监督来应对突发的新威胁。
此类分析同时要求开发者明确标注所使用的训练与测试数据集——这本身也被视为AI开发的最佳实践之一。\({ }^{21}\)
有关该应用场景的更多信息,详见《卷二:网络安全数据集中的分布漂移(Distributional Shift in Cybersecurity Datasets)》。\({ }^{22}\)
\({ }^{21}\) Department of the Air Force and Massachusetts Institute of Technology,《Artificial Intelligence Acquisition Guidebook》,MIT AI Accelerator, 2022。
\({ }^{22}\) Joshua Steier 等人,《Understanding the Limits of Artificial Intelligence for Warfighters: Vol. 2, Distributional Shift in Cybersecurity Datasets》,RAND Corporation, RR-A1722-2, 2024。
预测性维护(Predictive Maintenance)¶
本研究案例的目标是探讨AI(Artificial Intelligence,人工智能)如何改进飞机部件的故障分析,从而帮助确定战备备件包(RSP, Readiness Spares Packages)的内容。
美国空军(USAF)中队通常会携带RSP以支持为期30天的部署任务。目前,空军使用飞机可持续性模型(ASM, Aircraft Sustainability Model)来根据多种因素(如现有库存、积压订单历史以及部件失效率估计)生成每个RSP的“购物清单”。\({ }^{23}\)
ASM使用泊松分布(Poisson distribution)来预测部件失效率。\({ }^{24}\)
本研究评估了ASM基于泊松分布的故障需求预测的准确性,并探讨了利用AI作为替代手段预测失效率的可行性。需要指出的是,ASM的功能远不止于此,本研究仅关注其众多功能中的一个方面。
\({ }^{23}\) F. Michael Slay 等人,《Optimizing Spares Support: The Aircraft Sustainability Model》,Logistics Management Institute, AF501MR1, 1996。
\({ }^{24}\) 其他概率分布(如负二项分布)在模型中技术上可用,但美国空军并未采用。
研究方法(Approach)¶
经过大量工作,我们获得了一份有限的ASM历史输出样本,并将其与后勤、设施与任务支援企业视图系统(LIMS-EV, Logistics, Installations, and Mission Support–Enterprise View)中的实证数据进行了交叉对照,从而比较ASM泊松模型预测的失效率与实际失效率的差异。随后,我们构建了一个AI概念验证模型(proof-of-concept AI model),以验证AI是否能改进这些预测。
由于时间与数据限制,我们仅研究了单一机型——A-10C攻击机——的部件失效,使用的历史数据时间范围为2007年9月至2022年6月。这段时间共包含约105,000次部件失效,涉及113个唯一部件编号。\({ }^{25}\) 我们采用长短期记忆神经网络(LSTM, Long Short-Term Memory)来捕获时间序列关系。模型使用前10年的数据进行训练,并用后续年份的数据进行测试。考虑到潜在的分布漂移(distributional shift),我们还在模型运行中按月进行再训练(retraining),但由于时间不足,未能像网络安全案例那样执行完整的数据分段测试。
\({ }^{25}\) 最终约有16%的数据因条件不良(如缺少日期)而被弃用。
研究结果(Results)¶
通过Kolmogorov–Smirnov检验发现,超过80%的部件失效分布不符合泊松分布,这表明AI模型(或至少非泊松分布模型)可能具有更好的预测潜力。图2.1展示了ASM模型与AI模型在预测A-10C部件失效率方面的散点图对比。
图2.1. 2007–2022年A-10C部件实际失效率与ASM模型和AI模型预测结果对比
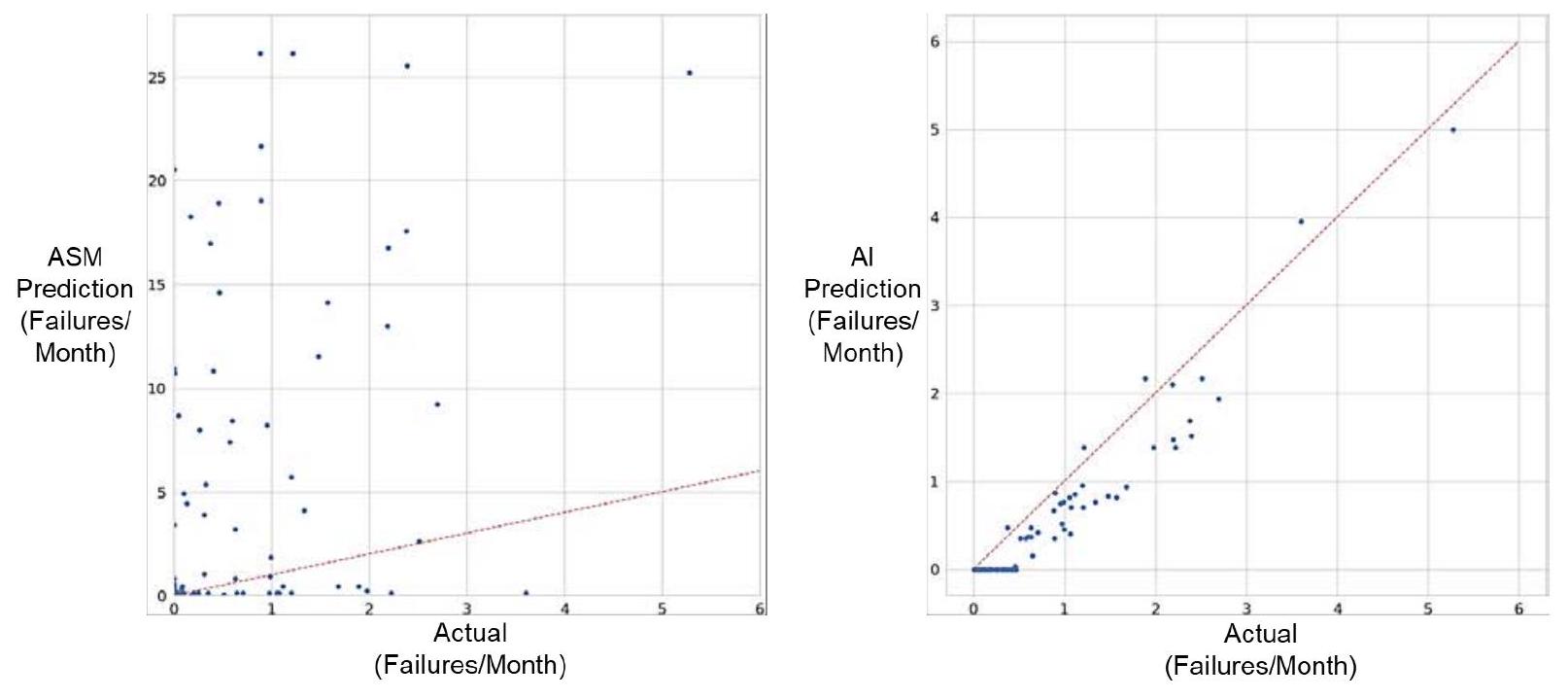
注:虚线红线表示预测与实际完全一致的位置。两图虚线角度不同是因为纵轴尺度不同:ASM失效率轴的比例约为AI预测轴的四倍。
从图中可以直观看出,AI模型的预测显著优于ASM使用的泊松分布。ASM预测结果离散度大且严重高估需求,而AI预测几乎始终在实际值的±1至2件范围内。AI模型的平均误差为1.6%,导致平均每月超储成本约为 $1.2百万;ASM模型的平均误差为119%,导致平均每月超储成本高达 $31百万。\({ }^{26}\) 当然,从政策角度看,适度的超储是合理的,但这种程度显然过高。
\({ }^{26}\) 虽然AI模型略有低估(underpredict)失效,但在该指标中低估并不会抵消超储(overstock)部分的成本。两者属于不同的政策问题,且低储通常并非有益。
尽管研究结果颇具潜力,但仍需注意若干重要的限定条件。
首先,我们的AI模型仅针对单一平台的部件进行分析,而ASM(Aircraft Sustainability Model,飞机可持续性模型)则需同时考虑所有机型。虽然本研究采用的机器学习(ML, Machine Learning)方法可复用于其他平台模型,但仍需大量额外的调参工作,且无法预先确定这些新模型是否能像A-10C那样取得相同程度的改进。
其次,如前所述,ASM的功能远不止于预测部件失效。它还需决定从哪个维修库(depot)提取部件、并将其分配至哪些基地(base)。这在预测问题之外增加了一个复杂的运筹学(OR, Operations Research)优化问题。若要解决这一“维修库与基地选择”的高维组合问题,还需进行大量额外工作。此外,我们在“任务规划(Mission Planning)”章节中的研究发现,AI在运筹问题中的应用并不总能提高最优性(optimality),尽管改进的失效率预测模型本身依然有价值。
最后,RSP(Readiness Spares Package,战备备件包)过程本质上是对稀有事件(rare events)的预测,而这类问题天生具有高度难度。 进一步观察图2.1可见,AI模型的一部分优异表现仅源于其预测某些部件“永不失效”(即零失效率),这在政策层面显然不可接受。我们专门构建了一个概念验证AI模型(proof-of-concept model)来研究这些情况,达到了±6个月范围内77%的准确率。 然而,样本量较小,该结果仅具参考意义。任何现实中的AI系统都可能需要混合模型(hybrid model)设计。尤其是在战时,由于缺乏可用数据,即便算法再智能,也无法弥补数据稀缺的根本问题。
因此,这一概念验证不应被视为对ASM的否定,而应视为一种探索契机,激励空军部(DAF, Department of the Air Force)进一步研究如何将现代AI技术应用于这一经典模型。
基于以上研究结果,我们得出以下总结性结论(summary findings):
-
AI可提升RSP(Readiness Spares Package,战备备件包)需求预测能力。 静态的泊松分布(Poisson process)对于许多部件而言预测效果较差,且任何单一概率分布模型都难以充分反映失效特征。本研究仅在单一平台与单一概率分布条件下进行了验证,尚未涉及更复杂的维修库(depot)到基地(base)的分配问题。
-
在DAF(美国空军部)维护数据库上应用AI前,必须建立复杂且高劳动量的数据操作管线(data operations pipeline)。 当前从LIMS-EV(Logistics, Installations and Mission Support–Enterprise View)系统提取数据的过程依赖人工脚本、下拉列表及嵌套菜单操作,仅适用于概念验证(proof-of-concept)阶段。此外,还需进行大量数据清洗(data cleaning),以解锁更多历史数据(如平台升级前的部件变体关联)及潜在预测因子。
-
AI无法缓解战时数据稀缺问题。 为弥补这一限制,需引入额外假设与政策考量。然而,通过AI模型的定期再训练与更新机制(retraining and updating policy),可在战时环境中保持系统的适应性(adaptability)。
基于上述发现,我们提出以下建议:
- 空军装备司令部(AFMC, Air Force Materiel Command)应建立数据操作管线,以开展飞机维护与RSP效率的回溯分析(retrospective analysis)。 当前的飞机维护程序与数据库虽能有效支持其原始设计目标,但并非为历史分析或AI训练所建。若数据未经过恰当的处理(conditioning)与提取(pulling),后续任何AI相关建议均无法落地。正如《人工智能采购指南(Artificial Intelligence Acquisition Guidebook)》中所指出的,这是一项普遍性挑战:
“仅仅收集所有‘数据’并不能解决数据资产危机。数据形式多样,可能并不适用于特定任务。项目经理(PM)应尽可能要求以通用格式和尺寸提供数据,以促进高效的数据供给管线。通常,AI项目适用的数据格式包括图像、视频、表格、CSV与TSV文件。具体格式依赖于算法类型与模型训练方式。 > 即使格式正确,数据仍需在AI训练前进行整理(curation)与条件化(conditioning)。”\({ }^{27}\)
-
利用AI改进RSP(Readiness Spares Package,战备备件包)的需求预测模型。将当前的概念验证模型(proof-of-concept model)扩展至所有机型。尽管建模工作可能需要以“部件为单位、平台为单位”分别进行,但一旦建立完善的数据操作管线(data operations pipeline),这一过程将大幅简化。
-
考虑利用AI解决更大规模的运筹学(OR, Operations Research)问题——确定从哪个维修库(depot)向哪个基地(base)发送哪类部件。这是一个独立且高度复杂的问题,但其潜在价值巨大,可进一步推动空军保障体系的智能化与优化。
有关本案例的更多信息,详见《卷三:预测性维护(Predictive Maintenance)》。\({ }^{28}\)
\({ }^{27}\) Department of the Air Force and Massachusetts Institute of Technology, Artificial Intelligence Acquisition Guidebook, 2022, p. 25。
\({ }^{28}\) Li Ang Zhang, Yusuf Ashpari, and Anthony Jacques,《Understanding the Limits of Artificial Intelligence for Warfighters: Vol. 3, Predictive Maintenance》,RAND Corporation, RR-A1722-3, 2024。
兵棋推演(Wargames)¶
本研究案例的目标是了解兵棋推演(wargames)中哪些环节最适合(或最不适合)通过AI系统实现自动化。
在2010年代,AI在游戏领域的突破——如国际象棋(Chess)、围棋(Go)和《星际争霸II(StarCraft II)》——引发了人们对AI在兵棋推演中潜在作用的极大兴趣。\({ }^{29}\)
AI支持者认为,AI可以使兵棋推演更高效,甚至能够用于解决全新的战略问题。然而,近期兰德公司(RAND)的研究表明,AI在常规博弈(如围棋、象棋)中的成功,并不能直接转化为真实军事指挥控制(C2, Command and Control)问题中的有效性,因此仍需保持谨慎。\({ }^{30}\)
此外,兵棋推演种类繁多,AI可介入的环节也各不相同,不同类型的推演对AI的适用性差异明显。
\({ }^{29}\) 例如,David Silver 等人,“Mastering the Game of Go with Deep Neural Networks and Tree Search,” Nature, 2016;Oriol Vinyals 等人,“Grandmaster Level in StarCraft II Using Multi-Agent Reinforcement Learning,” Nature, 2019。
\({ }^{30}\) Walsh 等人, 2021a。
研究方法(Approach)¶
第一步是建立一个用于分析兵棋推演设计与执行过程的通用框架。
我们回顾了历史与当代的AI兵棋推演文献,并访谈了领域专家(SMEs),包括兵棋设计专家与AI从业者。
这一框架主要借鉴了Elizabeth Bartels在兰德博士论文中的成果,她将兵棋推演按“目的”划分为四类。\({ }^{31}\)
表2.1总结了这四种类型的兵棋推演、所用战术技术程序(TTPs, Tactics, Techniques, and Procedures)的成熟度及其分析重点。
\({ }^{31}\) Elizabeth M. Bartels,《Building Better Games for National Security Policy Analysis: Towards a Social Scientific Approach》,RAND Corporation, RGSD-437, 2020。
表 2.1. 按目的划分的兵棋推演类型
| 类型 | 目的 | TTPs成熟度 | 分析重点 | 示例 |
|---|---|---|---|---|
| 系统探索(Systems exploration) | 通过专家玩家的思维模型提升对战术或技术问题的理解 | 不断演化 | 问题 | RAND的灰色地带战术游戏(Gray Zone Games)\({ }^{\text a}\) |
| 创新(Innovation) | 提出突破现状的新决策方案,鼓励“跳出框架”思考 | 不断演化 | 解决方案 | DARPA的马赛克作战游戏(Mosaic Warfare Games)\({ }^{\text b}\) |
| 替代条件(Alternative conditions) | 探讨决策在不同起始条件下是否会变化,以测试战略稳健性 | 成熟 | 问题 | USAF战略与力量评估游戏(SAFE Games)\({ }^{\text c}\) |
| 评估(Evaluation) | 依据规范标准评判玩家决策的结果 | 成熟 | 解决方案 | DARPA/CNA “Scud Hunt”\({ }^{\text d}\) |
来源:改编自 Bartels, 2020。
注:CNA = 海军分析中心(Center for Naval Analyses);DARPA = 国防高级研究计划局(Defense Advanced Research Projects Agency)。
\({ }^{\text a}\) Becca Wasser 等人,《Gaming Gray Zone Tactics》,RAND Corporation, RR-2915-A, 2019。
\({ }^{\text b}\) Timothy R. Gulden 等人,《Modeling Rapidly Composable, Heterogeneous, and Fractionated Forces》,RAND Corporation, RR-4396-OSD, 2021。
\({ }^{\text c}\) Thomas A. Brown 和 Edwin W. Paxson,《A Retrospective Look at Some Strategy and Force Evaluation Games》,RAND Corporation, R-1619-PR, 1975。
\({ }^{\text d}\) Peter P. Perla 等人,《Gaming and Shared Situation Awareness》,CNA, 2000。
虽然这些类型并非互斥,但它们在规划与执行方法上存在显著张力。
例如,“替代条件”与“评估”类游戏的形式化结构虽有助于精确分析,但若应用于“系统探索”或“创新”类游戏则可能适得其反。
我们在此框架基础上,将兵棋推演划分为四个阶段性任务:准备(preparing)、执行(playing)、裁决(adjudicating) 与 解读(interpreting)。
通过按目的分组、按任务划分,我们评估了AI在各阶段的技术可行性与成本效益。
这一评估基于专家访谈,并结合理论推演,因为此前尚无AI系统在此领域的系统性应用案例。
研究结果(Results)¶
图2.2展示了我们对AI在不同类型兵棋推演及各任务阶段中的技术可行性与成本效益的综合评估。
图 2.2. 兵棋推演中AI开发的技术可行性与成本效益评估
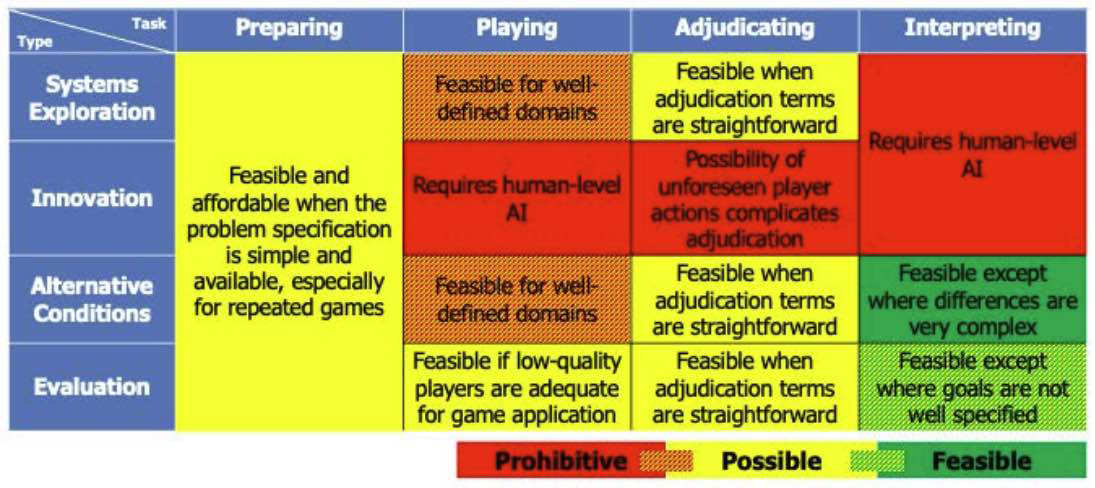
| 任务 类型 |
准备阶段 | 执行阶段 | 裁决阶段 | 解读阶段 |
|---|---|---|---|---|
| 系统探索 | 当问题定义明确且可获取时可行,尤其适用于重复游戏 | 适用于定义良好的领域 | 裁决条件清晰时可行 | 需具备人类水平AI |
| 创新 | 需具备人类水平AI | 不可预见的玩家行为增加裁决复杂性 | ||
| 替代条件 | 对定义良好的领域有可行性 | 裁决条件清晰时可行 | 除非差异极其复杂,否则可行 | |
| 评估 | 若低质量玩家可接受,则可行 | 裁决条件清晰时可行 | 目标定义模糊时除外,均可行 |
该图采用“信号灯”式表示:红色表示成本高或难度大,绿色表示容易或成本低,黄色为中间状态。
总体可见,AI在多数兵棋推演环节的应用仍较困难,但某些领域已具备可行性,并有望通过技术投资由“黄”转“绿”。
我们发现,AI最有潜力应用于以下类型的兵棋推演:
- 用于研究替代条件或评估性目的的游戏,尤其是具有明确标准和指标的;
- 在裁决过程中使用计算模型或生成大量需判定的数字数据的游戏;
- 使用先进人机交互(HCI, Human-Computer Interaction)技术(如摄像头、麦克风)进行数据采集和交互的;
- 重复执行次数多、尤其是模拟“零和对抗(zero-sum, force-on-force)”场景的游戏。
相对而言,AI最不适用于:
- 以系统探索或创新为目标的游戏;
- 数字化基础设施或计算模型交互较少的游戏;
- 在安全环境中限制使用HCI技术的场景;
- 一次性或仅为特定目的执行少数几次的游戏。
基于以上分析结果,我们提出三项关于AI(Artificial Intelligence,人工智能)在兵棋推演(wargames)中投资方向的建议:
-
集中资源于最具潜力的应用领域。
重点投资于那些旨在研究替代条件(alternative conditions)或用于评估(evaluation)的兵棋推演,尤其是具有明确问题定义与评价标准的类型;
同时优先考虑已具备数字化基础设施(包括人机交互技术,HCI, Human-Computer Interaction)并能重复开展的推演任务。 -
加强数字化推演基础设施与HCI技术的应用。
兵棋推演任务的数字化是未来AI应用的前提。应在系统探索(systems exploration)与创新(innovation)类游戏中加大数字化投入,采用HCI技术采集对话与决策数据,以支撑AI的训练与发展。
这对于AI从评估型推演中学习尤为有价值,可形成数据闭环并提升模型泛化能力。 -
在战略研究中引入AI以支持未来兵棋推演。
利用AI增强战略层面的支撑研究,使潜在设想从“可行”转向“可实施”。
相关研究可包括场景生成(scenario generation)、案例筛选(case identification)以识别值得重点关注的复杂条件,以及舆情分析或立场分析(sentiment or stance analysis),用于辅助兵棋推演的定性研究。
有关本案例的更多信息,详见《卷四:兵棋推演(Wargames)》。\({ }^{32}\)
\({ }^{32}\) Edward Geist, Aaron B. Frank, 和 Lance Menthe,《Understanding the Limits of Artificial Intelligence for Warfighters: Vol. 4, Wargames》,RAND Corporation, RR-A1722-4, 2024。
任务规划(Mission Planning)¶
本研究案例的目标是确定AI(Artificial Intelligence,人工智能)在任务规划(mission planning,尤其是路径规划)中,相较于传统运筹学(OR, Operations Research)方法的改进极限与适用条件。
任务规划的一般问题是:在复杂环境条件下,同时为多个作战资源分配优先目标,并动态规划其到达路径。
兰德公司(RAND)此前关于“主空中打击计划(Master Air Attack Plan)”过程的研究指出,数据可用性不足与操作风险是AI在该领域应用面临的主要约束。\({ }^{33}\)
该研究中的实验显示,混合整数规划(MIP, Mixed Integer Programming)等传统OR方法可在数小时内接近最优解;而简单的机器学习(ML, Machine Learning)方法则能在两秒内达到“距最优解仅17%”的效果。\({ }^{34}\)
不过,该实验案例较为简化,若考虑上千个作战单元,其组合爆炸将使传统方法不再可行。
同时,AI在高级仿真、集成与建模框架(AFSIM, Advanced Framework for Simulation, Integration, and Modeling)中的任务规划研究也展现出一定潜力,但在众多算法中,仅有一种能稳定生成合理的路径。\({ }^{35}\)
本研究在此前AFSIM建模与仿真工作的基础上,旨在探索AI何时以及在何种条件下能与传统OR方法性能持平或超越。
\({ }^{33}\) Walsh 等人, 2021a。
\({ }^{34}\) Matthew Walsh 等人,《Exploring the Feasibility and Utility of Machine Learning-Assisted Command and Control: Vol. 2》,RAND Corporation, RR-A263-2, 2021b, p. 56。
\({ }^{35}\) Li Ang Zhang 等人,《Air Dominance Through Machine Learning》,RAND Corporation, RR-4311-RC, 2020。
研究方法(Approach)¶
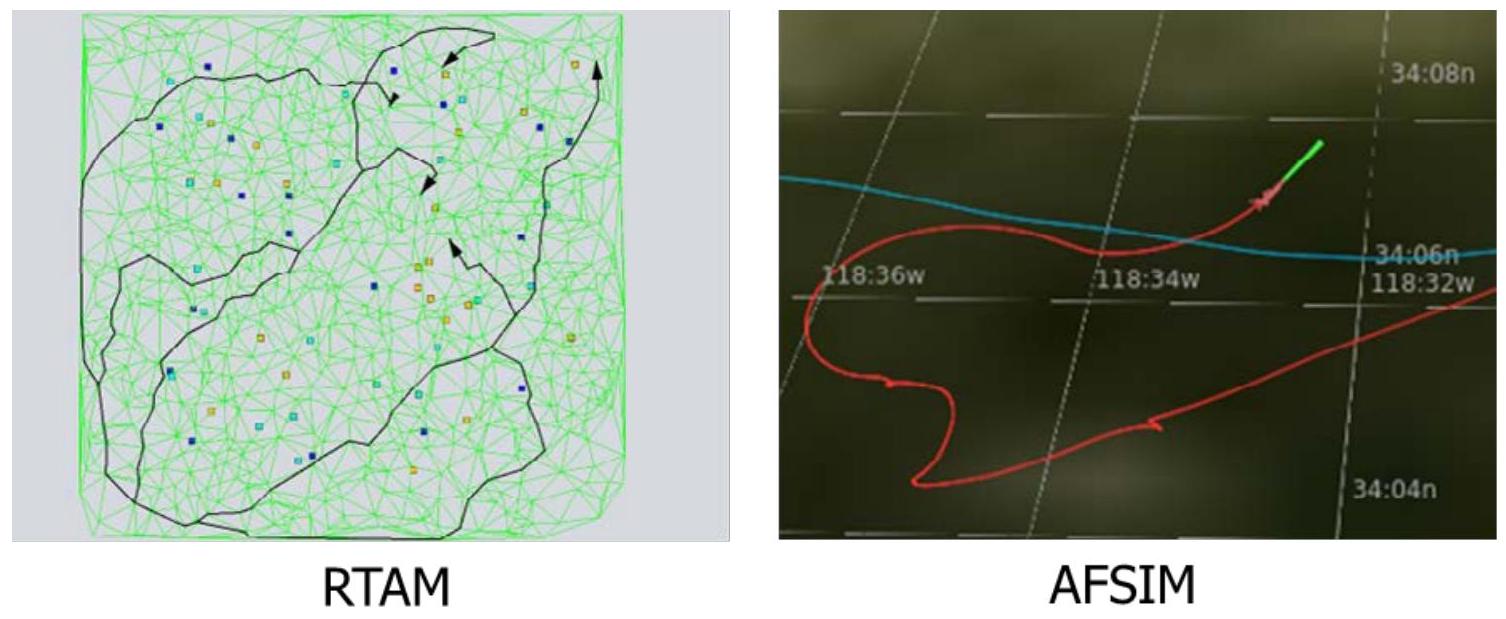
我们使用兰德目标获取模型(RTAM, RAND Target Acquisition Model),模拟单架无人机在飞行至目标点的过程中如何规避探测。
研究比较了两种路径规划方法:
-
传统运筹学方法:
将空域划分为离散网格,并基于成本函数(cost function)在网格间搜索最优路径。
由于离散单元数量有限,该方法可在多项式时间复杂度内找到数学意义上的最优解。 -
AI方法:
使用AFSIM中的强化学习(reinforcement learning)算法,以开放式搜索方式发现最佳路径。
下图展示了两种模型的截图。
图2.3. 兰德目标获取模型与AFSIM系统界面示意
在本研究中,我们还构建了AFSIM与主流机器学习框架间的数据管线(pipeline),并已分享给空军装备司令部(AFMC)。\({ }^{36}\)
这一端到端集成方案支持AI模型在AFSIM中直接训练与运行,且无需Python封装(Python harness),避免了运行时延迟问题。\({ }^{37}\)
由于AFSIM支持C++命令且TensorFlow Lite可导出C++模型,因此AI模型可直接在AFSIM中部署运行。\({ }^{38}\)
我们利用此方案测试AI方法相较于传统方法的效率表现。
\({ }^{36}\) Gary J. Briggs,《AFSIM Reinforcement Learning Tool》,RAND Corporation, TL-A1722-1, 2022。
\({ }^{37}\) 多数AI模型使用Python开发,需特定接口方可跨语言运行。
\({ }^{38}\) AFSIM支持C++命令,且TensorFlow Lite支持C++导出,因此可直接运行AI模型而无需Python。
研究结果(Results)¶
结果显示,传统OR方法始终比AI方法更优。
这并不意外,因为OR方法能求得数学上的全局最优解,而AI本质上是函数逼近器(function approximator)。
然而,AI方法具有三项显著优势:
- 鲁棒性更强。
AI生成的路径虽非最优,但在威胁位置变化时仍保持可行; - 具备动态适应性。
能在不重新训练的情况下考虑突发目标(pop-up targets); - 计算效率高。
生成可行解的速度远超传统算法。
基于上述实验,我们总结如下主要发现:
- AI任务规划结果在明确的路径优化问题上低于传统OR方法的最优性;
- AI能生成近似最优路径,且更具鲁棒性与实时响应能力;
- AI可用于辅助任务规划,通过生成多种可行路径供人工决策;
- 受限于当前技术,AI尚难应用于长期战略级规划(strategic-level planning)。
\({ }^{39}\) Keller Scholl, Gary J. Briggs, Li Ang Zhang, 和 John L. Salmon,《Understanding the Limits of Artificial Intelligence for Warfighters: Vol. 5, Mission Planning》,RAND Corporation, RR-A1722-5, 2024。
基于以上研究结果,我们提出以下建议:
-
空军部(DAF, Department of the Air Force)应投资开发适配工具,以支持强化学习(Reinforcement Learning, RL)模型与现有任务规划模型的融合。
在AFSIM(Advanced Framework for Simulation, Integration, and Modeling)中应用此类方法,将有助于提升战术级任务规划(tactical mission planning)的智能化与自适应能力。 -
空军部应考虑利用AI(Artificial Intelligence)为无人机制定快速反应策略(fast-reaction policy),以应对突发环境变化。
我们的实验表明,小型、高效的AI模型可直接运行于无人机机载系统中,实现实时决策与路径调整。
更多相关内容详见《卷五:任务规划(Mission Planning)》。\({ }^{39}\)
\({ }^{39}\) Keller Scholl, Gary J. Briggs, Li Ang Zhang, and John L. Salmon, Understanding the Limits of Artificial Intelligence for Warfighters: Vol. 5, Mission Planning, RR-A1722-5, 2024.
结论(Conclusion)¶
在所有研究案例中,我们发现了两个共同主题:
-
用于训练与测试AI系统的数据必须具备时效性、可获取性与高质量。
数据的稀缺性显著限制了AI在作战(warfighting)领域的有效性,尤其是在无法通过外部手段弥补这一不足的情况下。 -
AI算法在学习方式与学习内容上的局限性,严重约束了其通用性与应用范围。
尤其在涉及人类洞察力(human insight)的情境中,AI往往只能作为辅助工具而非替代方案。
AI显然有潜力提升所有四个研究案例的表现,但由于上述两类限制,其应用仍受到显著约束。
表2.2总结了各案例的主要发现,并按上述两大主题进行分类。
表2.2 各应用案例主要发现汇总(Summary of Findings)¶
| 应用案例 | 数据局限性 | 算法局限性 |
|---|---|---|
| 网络安全(Cybersecurity) | - 为识别自适应威胁(adaptive threats),数据必须保持最新。分布漂移(distributional shift)会导致模型性能退化,且在高维数据下无法避免。 | - AI分类算法不能学习未被教授的知识。AI无法预见或识别新型网络攻击。 |
| 预测性维护(Predictive maintenance) | - 数据必须可访问且条件良好。相关后勤数据分散于多个数据库中,且往往存在条件不良问题。若无自动化数据管线(data pipeline),则无法捕获足够数据以支持AI训练。 - 和平时期数据不能替代战时数据;AI无法弥补适用数据的缺乏。 |
- AI能很好地估计复杂函数,但会失去泛化性。它能比通用概率分布更准确地预测部件失效率,但必须针对每个部件单独训练。 |
| 兵棋推演(Wargames) | - 数字化必须先于AI开发。多数兵棋推演仍非数字化过程,未生成电子数据。数字化是AI数据管线的前提。 - 需要新的数据类型。要让AI参与兵棋推演,需借助人机交互(HCI, Human-Computer Interaction)技术捕捉当前未被记录的要素。 |
- AI距离实现人类级智能(human-level intelligence)仍有很大差距,因而无法取代人类判断。AI仅可能适用于特定目的的特定阶段。 |
| 任务规划(Mission planning) | - 为应对自适应威胁,数据必须及时更新。模型必须定期刷新以反映环境变化。 | - AI在战术层面(tactical)表现出色,但在战略层面(strategic)相对“幼稚”。其倾向于通过快速进入对手的“观察-定向-决策-行动(OODA)环”而取胜,而非制定宏观战略。 - AI精度低于传统优化算法,但其解更鲁棒(robust),且收敛速度更快。 |
在所有研究案例的建议中,同样出现了两个共通主题:
(1)需要开展更多测试与实验,以验证AI的适用边界;
(2)需要建立更完善的基础设施(包括数字化技术与数据管线)以支撑未来AI发展。
表2.3总结了各案例的具体建议。
表2.3 各应用案例主要建议汇总(Summary of Recommendations)¶
| 应用案例 | AI测试与实验 | 支撑基础设施 |
|---|---|---|
| 网络安全 | - 开展数据集分段测试,以评估分布漂移对AI系统的影响程度,并估算其性能衰减速率与“保质期(shelf life)”。 | - 不适用。 |
| 预测性维护 | - 通过AI改进备件保障包(RSP, Readiness Spares Package)的需求预测,并将验证模型扩展至所有机型。此过程可能需按“部件-平台”逐项实施。 - 考虑利用AI解决更复杂的运筹优化问题,如“从何处向何处发送哪类部件”。 |
- 建立后勤维护数据操作管线,用于多机型、多部件的回溯分析与RSP效率评估。 |
| 兵棋推演 | - 将AI开发资源集中于最具潜力的领域:研究替代条件或用于评估、具备明确定义标准、已有数字化基础设施(含HCI技术)、并能重复进行的推演类型。 | - 增加数字化游戏基础设施与HCI技术的使用,尤其在系统探索与创新类推演中,以采集数据支持AI发展。 - 更广泛地利用AI能力支撑未来兵棋推演研究。 |
| 任务规划 | - 探讨AI如何用于制定无人机应对突发状况的快速反应策略(fast-reaction policy)。 | - 投资开发工具,将强化学习(Reinforcement Learning)应用于现有任务规划模型与仿真平台(如AFSIM)。 |
总体而言,关于“AI在作战应用中的边界”这一问题,仍有大量研究空间。
我们已识别出多项局限性——部分是普遍性的,部分是特定情境的——但显然还有更多未知因素。
AI并非“万能解”(panacea):它能做很多事,但同样有许多无法完成的任务。
这是一个极具潜力的实验与验证方向,但前提是必须建立可靠的数据管线与技术基础。
空军部(DAF)应在这两方面提供支持。
缩略词(Abbreviations)¶
| 缩写 | 全称 |
|---|---|
| AFMC | Air Force Materiel Command(空军装备司令部) |
| AFSIM | Advanced Framework for Simulation, Integration, and Modeling(高级仿真、集成与建模框架) |
| AI | Artificial Intelligence(人工智能) |
| ASM | Aircraft Sustainability Model(飞机可持续性模型) |
| C2 | Command and Control(指挥与控制) |
| CIC | Canadian Institute for Cybersecurity(加拿大网络安全研究所) |
| DAF | Department of the Air Force(美国空军部) |
| HCI | Human-Computer Interaction(人机交互) |
| ISR | Intelligence, Surveillance, and Reconnaissance(情报、监视与侦察) |
| LIMS-EV | Logistics, Installations and Mission Support–Enterprise View(后勤、设施与任务支援企业视图系统) |
| ML | Machine Learning(机器学习) |
| OR | Operations Research(运筹学) |
| RSP | Readiness Spares Package(战备备件包) |
| RTAM | RAND Target Acquisition Model(兰德目标获取模型) |
| SME | Subject-Matter Expert(领域专家) |
| TTPs | Tactics, Techniques, and Procedures(战术、技术与程序) |
| USAF | United States Air Force(美国空军) |
References¶
Abadi, Martín, Ashish Agarwal, Paul Barham, Eugene Brevdo, Zhifeng Chen, Craig Citro, Greg S. Corrado, Andy Davis, Jeffrey Dean, Matthieu Devin, Sanjay Ghemawat, Ian Goodfellow, Andrew Harp, Geoffrey Irving, Michael Isard, Rafal Jozefowicz, Yangqing Jia, Lukasz Kaiser, Manjunath Kudlur, Josh Levenberg, Dan Mané, Mike Schuster, Rajat Monga, Sherry Moore, Derek Murray, Chris Olah, Jonathon Shlens, Benoit Steiner, Ilya Sutskever, Kunal Talwar, Paul Tucker, Vincent Vanhoucke, Vijay Vasudevan, Fernanda Viégas, Oriol Vinyals, Pete Warden, Martin Wattenberg, Martin Wicke, Yuan Yu, and Xiaoqiang Zheng, TensorFlow: Large-Scale Machine Learning on Heterogeneous Distributed Systems, preliminary white paper, Google Research, November 9, 2015.
Anderson, Hyrum S., and Phil Roth, "EMBER: An Open Dataset for Training Static PE Malware Machine Learning Models," arXiv, April 16, 2018.
Arai, Kohei, and Supriya Kapoor, eds, Advances in Computer Vision: Proceedings of the 2019 Computer Vision Conference CVC, Vol. 1, Springer, 2019.
Austin, Lloyd J., III, "Secretary of Defense Austin Remarks at the Global Emerging Technology Summit of the National Security Commission on Artificial Intelligence (as Delivered)," transcript, U.S. Department of Defense, July 13, 2021.
Bartels, Elizabeth M., Building Better Games for National Security Policy Analysis: Towards a Social Scientific Approach, dissertation, Pardee RAND Graduate School, RAND Corporation, RGSD-437, 2020. As of August 27, 2022: https://www.rand.org/pubs/rgs_dissertations/RGSD437.html
Bishop, Christopher M., Pattern Recognition and Machine Learning, Springer, 2006. Briggs, Gary J., AFSIM Reinforcement Learning Tool, RAND Corporation, TL-A1722-1, 2022, Not available to the general public.
Brown, Thomas A., and Edwin W. Paxson, A Retrospective Look at Some Strategy and Force Evaluation Games, RAND Corporation, R-1619-PR, 1975. As of September 13, 2023: https://www.rand.org/pubs/reports/R1619.html
Department of the Air Force and Massachusetts Institute of Technology, Artificial Intelligence Acquisition Guidebook, Artificial Intelligence Accelerator, February 14, 2022.
Egel, Daniel, Ryan Andrew Brown, Linda Robinson, Mary Kate Adgie, Jasmin Léveillé, and Luke J. Matthews, Leveraging Machine Learning for Operation Assessment, RAND Corporation, RR-4196-A, 2022. As of August 25, 2022: https://www.rand.org/pubs/research_reports/RR4196.html
Geist, Edward, Aaron B. Frank, and Lance Menthe, Understanding the Limits of Artificial Intelligence for Warfighters: Vol. 4, Wargames, RAND Corporation, RR-A1722-4, 2024.
Gulden, Timothy R., Jonathan Lamb, Jeff Hagen, and Nicholas A. O'Donoughue, Modeling Rapidly Composable, Heterogeneous, and Fractionated Forces: Findings on Mosaic Warfare from an Agent-Based Model, RAND Corporation, RR-4396-OSD, 2021. As of September 13, 2023: https://www.rand.org/pubs/research_reports/RR4396.html
Harang, Richard, and Ethan M. Rudd, "SOREL-20M: A Large Scale Benchmark Dataset for Malicious PE Detection," arXiv, December 14, 2020.
Ish, Daniel, Jared Ettinger, and Christopher Ferris, Evaluating the Effectiveness of Artificial Intelligence Systems in Intelligence Analysis, RAND Corporation, RR-A464-1, 2021. As of August 25, 2022: https://www.rand.org/pubs/research_reports/RRA464-1.html
Jordan, M. I., and T. M. Mitchell, "Machine Learning: Trends, Perspectives, and Prospects," Science, Vol. 349, No. 6245, July 2015.
Lingel, Sherrill, Jeff Hagen, Eric Hastings, Mary Lee, Matthew Sargent, Matthew Walsh, Li Ang Zhang, and David Blancett, Joint All-Domain Command and Control for Modern Warfare: An Analytic Framework for Identifying and Developing Artificial Intelligence Applications, RAND Corporation, RR-4408/1-AF, 2020. As of August 25, 2022: https://www.rand.org/pubs/research_reports/RR4408z1.html
Lohn, Andrew J., Jair Aguirre, Mark Ashby, Benjamin Boudreaux, Johnathan Fujiwara, Gavin S. Hartnett, Daniel Ish, John Speed Meyers, Caolionn O'Connell, and Li Ang Zhang, Attacking Machine Learning in War, RAND Corporation, RR-4386-AF, 2020, Not available to the general public.
Marcus, Gary, "Artificial General Intelligence Is Not as Imminent as You Might Think," Scientific American, July 1, 2022.
Menthe, Lance, Dahlia Anne Goldfeld, Abbie Tingstad, Sherrill Lingel, Edward Geist, Donald Brunk, Amanda Wicker, Sarah Lovell, Balys Gintautas, Anne Stickells, and Amado Cordova, Technology Innovation and the Future of Air Force Intelligence Analysis: Vol. 1, Findings and Recommendations, RAND Corporation, RR-A341-1, 2021a. As of August 25, 2022: https://www.rand.org/pubs/research_reports/RRA341-1.html
Menthe, Lance, Dahlia Anne Goldfeld, Abbie Tingstad, Sherrill Lingel, Edward Geist, Donald Brunk, Amanda Wicker, Sarah Lovell, Balys Gintautas, Anne Stickells, and Amado Cordova, Technology Innovation and the Future of Air Force Intelligence Analysis: Vol. 2, Technical Analysis and Supporting Material, RAND Corporation, RR-A341-2, 2021b. As of April 13, 2022: https://www.rand.org/pubs/research_reports/RRA341-2.html
Minsky, Marvin, ed., Semantic Information Processing, MIT Press, 1968. O’Mahony, Niall, Sean Campbell, Anderson Carvalho, Suman Harapanahalli, Gustavo Velasco Hernández, Lenka Krpalkova, Daniel Riordan, and Joseph Walsh, "Deep Learning vs. Traditional Computer Vision," in Kohei Arai and Supriya Kapoor, eds, Advances in Computer Vision: Proceedings of the 2019 Computer Vision Conference CVC, Vol. 1, Springer, 2019.
Perla, Peter P., Michael Markowitz, Albert Nofi, Christopher Weuve, Julia Loughran, and Marcy Stahl, Gaming and Shared Situation Awareness, Center for Naval Analyses, November 2000.
Robson, Sean, Maria C. Lytell, Matthew Walsh, Kimberly Curry Hall, Kirsten M. Keller, Vikram Kilambi, Joshua Snoke, Jonathan W. Welburn, Patrick S. Roberts, Owen Hall, and Louis T. Mariano, U.S. Air Force Enlisted Classification and Reclassification: Potential Improvements Using Machine Learning and Optimization Models, RAND Corporation, RR-A284-1, 2022. As of August 25, 2022: https://www.rand.org/pubs/research_reports/RRA284-1.html
Russell, Stuart, and Peter Norvig, Artificial Intelligence: A Modern Approach, 4th ed., Pearson, 2021. Scholl, Keller, Gary J. Briggs, Li Ang Zhang, and John L. Salmon, Understanding the Limits of Artificial Intelligence for Warfighters: Vol. 5, Mission Planning, RAND Corporation, RR-A1722-5, 2024.
Schulker, David, Nelson Lim, Luke J. Matthews, Geoffrey E. Grimm, Anthony Lawrence, and Perry Shameem Firoz, Can Artificial Intelligence Help Improve Air Force Talent Management? An Exploratory Application, RAND Corporation, RR-A812-1, 2021. As of August 25, 2022: https://www.rand.org/pubs/research_reports/RRA812-1.html
Sharafaldin, Iman, Arash Habibi Lashkari, and Ali A. Ghorbani, "Toward Generating a New Intrusion Detection Dataset and Intrusion Traffic Characterization," Proceedings of the 4th International Conference on Information Systems Security and Privacy, Funchal-Madeira, Portugal, January 22-24, 2018.
Silver, David, Aja Huang, Chris J. Maddison, Arthur Guez, Laurent Sifre, George van den Driessche, Julian Schrittwieser, Ioannis Antonoglou, Veda Panneershelvam, Marc Lanctot, Sander Dieleman, Dominik Grewe, John Nham, Nal Kalchbrenner, Ilya Sutskever, Timothy Lillicrap, Madeleine Leach, Koray Kavukcuoglu, Thore Graepel, and Demis Hassabis, "Mastering the Game of Go with Deep Neural Networks and Tree Search," Nature, Vol. 529, January 27, 2016.
Slay, F. Michael, Tovey C. Bachman, Robert C. Kline, T. J. O'Malley, Frank L. Eichorn, and Randall M. King, Optimizing Spares Support: The Aircraft Sustainability Model, Logistics Management Institute, AF501MR1, October 1996.
Steier, Joshua, Erik Van Hegewald, Anthony Jacques, Gavin S. Hartnett, and Lance Menthe, Understanding the Limits of Artificial Intelligence for Warfighters: Vol. 2, Distributional Shift in Cybersecurity Datasets, RAND Corporation, RR-A1722-2, 2024.
Vinyals, Oriol, Igor Babuschkin, Wojciech M. Czarnecki, Michaël Mathieu, Andrew Dudzik, Junyoung Chung, David H. Choi, Richard Powell, Timo Ewalds, Petko Georgiev, Junhyuk Oh, Dan Horgan, Manuel Kroiss, Ivo Danihelka, Aja Huang, Laurent Sifre, Trevor Cai, John P. Agapiou, Max Jaderberg, Alexander S. Vezhnevets, Rémi Leblond, Tobias Pohlen, Valentin Dalibard, David Budden, Yury Sulsky, James Molloy, Tom L. Paine, Caglar Gulcehre, Ziyu Wang, Tobias Pfaff, Yuhuai Wu, Roman Ring, Dani Yogatama, Dario Wünsch, Katrina McKinney, Oliver Smith, Tom Schaul, Timothy Lillicrap, Koray Kavukcuoglu, Demis Hassabis, Chris Apps, and David Silver, "Grandmaster Level in StarCraft II Using Multi-Agent Reinforcement Learning," Nature, Vol. 575, October 30, 2019.
Walsh, Matthew, Lance Menthe, Edward Geist, Eric Hastings, Joshua Kerrigan, Jasmin Léveillé, Joshua Margolis, Nicholas Martin, and Brian P. Donnelly, Exploring the Feasibility and Utility of Machine LearningAssisted Command and Control: Vol. 1, Findings and Recommendations, RAND Corporation, RR-A263-1, 2021a. As of August 25, 2022: https://www.rand.org/pubs/research_reports/RRA263-1.html
Walsh, Matthew, Lance Menthe, Edward Geist, Eric Hastings, Joshua Kerrigan, Jasmin Léveillé, Joshua Margolis, Nicholas Martin, and Brian P. Donnelly, Exploring the Feasibility and Utility of Machine LearningAssisted Command and Control: Vol. 2, Supporting Technical Analysis, RAND Corporation, RR-A263-2, 2021b. As of September 5, 2022: https://www.rand.org/pubs/research_reports/RRA263-2.html
Wasser, Becca, Jenny Oberholtzer, Stacie L. Pettyjohn, and William Mackenzie, Gaming Gray Zone Tactics: Design Considerations for a Structured Strategic Game, RAND Corporation, RR-2915-A, 2019. As of September 14, 2023: https://www.rand.org/pubs/research_reports/RR2915.html
Xie, Shu-Yi, Jian Ma, Yu-Bin Luo, Lian-Xin Jiang, Shirly Jin, Yang Mo, and Jian-Ping Shen, "Models and Features with Covariate Shift Adaptation for Suspicious Network Event Recognition," 2019 IEEE International Conference on Big Data, Los Angeles, December 9-12, 2019.
Yang, Limin, Arridhana Ciptadi, Ihar Laziuk, Ali Ahmadzadeh, and Gang Wang, "BODMAS: An Open Dataset for Learning Based Temporal Analysis of PE Malware," 2021 IEEE Symposium on Security and Privacy Workshops, San Francisco, May 27, 2021.
Zhang, Li Ang, Yusuf Ashpari, and Anthony Jacques, Understanding the Limits of Artificial Intelligence for Warfighters: Vol. 3, Predictive Maintenance, RAND Corporation, RR-A1722-3, 2024.
Zhang, Li Ang, Gavin S. Hartnett, Jair Aguirre, Andrew J. Lohn, Inez Khan, Marissa Herron, and Caolionn O'Connell, Operational Feasibility of Adversarial Attacks Against Artificial Intelligence, RAND Corporation, RR-A866-1, 2022. As of September 14, 2023: https://www.rand.org/pubs/research_reports/RRA866-1.html
Zhang, Li Ang, Lance Menthe, Ian Fleischmann, Sale Lilly, Joshua Kerrigan, Michael J. Gaines, and Gregory A. Schumacher, Incorporating Artificial Intelligence into Army Intelligence Processes, RAND Corporation, RR-A729-1, 2021, Not available to the general public.
Zhang, Li Ang, Jia Xu, Dara Gold, Jeff Hagen, Ajay K. Kochhar, Andrew J. Lohn, and Osonde A. Osoba, Air Dominance Through Machine Learning: A Preliminary Exploration of Artificial Intelligence-Assisted Mission Planning, RAND Corporation, RR-4311-RC, 2020. As of August 25, 2022: https://www.rand.org/pubs/research_reports/RR4311.html