卷5:任务规划¶
关于本报告¶
这是五卷系列报告中的第五份报告,第五卷描述了AI如何用于执行任务规划,以及这些方法与更传统的运筹学方法相比如何。本卷面向对任务规划、运筹学和AI应用(更广泛地说)感兴趣的读者。
系列中的第1卷提供了所有用例的调查结果和建议摘要,其他各卷提供了各个用例的详细分析:
- Lance Menthe、Li Ang Zhang、Edward Geist、Joshua Steier、Aaron B. Frank、Eric Van Hegewald、Gary J. Briggs、Keller Scholl、Yusuf Ashpari和Anthony Jacques,《理解人工智能对作战人员的局限性:第1卷,摘要》,RR-A1722-1,2024年
- Joshua Steier、Erik Van Hegewald、Anthony Jacques、Gavin S. Hartnett和Lance Menthe,《理解人工智能对作战人员的局限性:第2卷,网络安全数据集中的分布偏移》,RR-A1722-2,2024年
- Li Ang Zhang、Yusuf Ashpari和Anthony Jacques,《理解人工智能对作战人员的局限性:第3卷,预测性维护》,RR-A1722-3,2024年
- Edward Geist、Aaron B. Frank和Lance Menthe,《理解人工智能对作战人员的局限性:第4卷,兵棋推演》,RR-A1722-4,2024年。
此处报告的研究由空军装备司令部战略规划、项目、需求和评估部门(AFMC/A5/8/9)委托,并在兰德公司项目空军的部队现代化和运用项目中进行,作为2022财年项目"理解人工智能在战争应用中的界限"的一部分。

致谢¶
我们感谢我们的赞助方联系人Kathryn Sowers以及我们的行动官员Julia Phillips和Gregory Cazzell,感谢他们在选择用例方面的指导,感谢他们在确定研究问题范围方面的深思熟虑,以及感谢他们与我们勤奋合作以获得进行本系列报告中描述的众多机器学习实验所需的数据。同时感谢以下个人:R. Scott Erwin和Jean-Charles Ledé慷慨地将我们与空军研究实验室的许多AI开发工作联系起来,Lee Seversky分享了他在任务规划方面的专业知识,Lt Col Kari K. Mott讨论了空中作战中心的自动化,以及Lt Col Nicholas J. Harris跨越十几个时区与我们交谈以解释主空袭规划过程。
我们还要感谢许多现任和前任兰德同事,包括Caolionn O'Connell、Sherrill Lingel、Osonde Osoba和Chris Pernin,帮助我们塑造研究议程。我们感谢我们的审稿人Nick O'Donoughue和Jair Aguirre的支持,没有他们,这将是一份较弱且不够清晰的报告,以及我们从整个兰德公司项目空军团队获得的支持。没有他们的帮助,我们无法撰写这些报告;任何仍然存在的错误都是我们自己的。
摘要¶
问题¶
任务规划涉及将离散资产分配给优先目标,包括在复杂环境条件下将这些资产动态路由到目的地。由于快速周转的价值和模拟作战环境的相对简单性,人们对通过添加人工智能(AI)的强化学习技术来改进任务规划过程产生了相当大的兴趣,这可以产生更好、更快或仅仅是独特的人类考虑解决方案。
方法¶
在背景研究方面,我们采访了主题专家,查阅了学术文献以及政府和行业出版物,并研究了一个在类似领域训练的引人注目的最先进模型(AlphaStar)。\({ }^{1}\) 基于从AlphaStar获得的经验教训,我们开始了两条原创研究路线,专注于将AI应用于窄范围的路线规划任务。我们使用内部建模软件来量化和更好地了解AI模型的一般相对优势和劣势。我们还实施了一个针对重大障碍(缺乏系统集成)的解决方案,以更精确地了解该障碍以及可以采取什么措施来克服它。
主要发现¶
很难预测AI的发展速度有多快。尽管如此,有些领域AI将相对有能力,而建立能力、经验和用户信任是进一步采用的重要步骤。任务规划就是这样一个领域。
目前的任务规划过程是人力密集型的,但足以满足和平时期的节奏:没有主题专家或实践者认为需求超出了规划能力。虽然整个战区资产规模的任务规划相对罕见,但努力建立自动化整个过程的能力将超出当前AI能力,并且会受到严重数据限制的困扰。\({ }^{2}\) 基于我们的主题专家访谈和案例研究,AI在快速适应新的敌人战略和战术方面将相对薄弱。然而,有一些特定应用,如快速响应新信息(例如,未知威胁),AI可以提供实质性优势。
AI采用的关键问题可能是软件集成和数据可用性,因为这些问题已经对现有的人类流程施加了实质性约束。我们验证了这一评估是正确的:对我们解决软件集成问题以连接两个流行软件系统的解决方案需求很强烈。我们发现,AI即使不能提供最优解决方案,也比替代方案具有实质性速度优势,并且能够容忍变化的条件。
表S.1显示了通常纳入运筹学的数学方法与我们的AI方法之间的差异。
表S.1. 路线规划的运筹学与人工智能方法比较
| 运筹学 | AI | |
|---|---|---|
| 敌方探测 | 平均风险水平:1.12 | 平均风险水平:2.91 |
| 路径长度 | 平均:\(5,070 \mathrm{~km}\) | 平均:\(3,938 \mathrm{~km}\) |
| 开发成本 | 低 | 高 |
| 响应时间 | 秒到分钟 | 毫秒 |
| 可预测性 | 给定效用函数和情况时固定 | 每次运行都变化 |
传统(运筹学)方法的平均敌方探测风险要低得多;开发成本较低,但更可预测,在获得新信息后生成响应的时间更长,并且规划的路径更长。
建议¶
我们对空军部在任务规划AI工作方面有三个主要建议:
- 任务规划的AI实施应针对人类相对薄弱的领域,特别是快速应对新情况,并计划从那里扩展
- 空军部应优先创建不仅仅是有用的工具和软件,而是使这些资源能够被其他人(政府和第三方)扩展,并将其连接到现有系统
- 空军部应持续监控AI领域:AI领域以前发生过范式转变,未来可能还会再次发生。
第1章 引言¶
概述¶
美国空军部对人工智能(AI)在作战各个方面革命性潜力的兴趣日益增加。\({ }^{3}\) 对于这个项目,美国空军要求兰德公司研究人员广泛考虑AI能做什么和不能做什么,以了解AI在作战应用中的局限性。为应对这一要求,我们调查了AI在四个特定作战应用中的适用性:网络安全、预测性维护、兵棋推演和任务规划。
基于给定的联合综合优先目标清单,空中作战中心(AOC)的规划人员通过主空袭计划过程分配武器和平台以实现指挥官的目标。从这些配对中,更详细的任务路线规划由中队的任务规划人员进行。
任务规划过程中花费的大部分时间都用于从不同机构收集数据、翻译数据、将数据输入软件以及生成频繁的PowerPoint简报。信息管理不佳:选择给定的打击组合或资产不会自动填充相关表单,需要手动输入和仔细检查以确保没有错误,因为作战范围或有效雷达距离的错误值可能导致灾难。
在与同等对手的高度竞争环境中,当前72小时的空中任务周期对于空中作战来说是不够的。\({ }^{4}\) 空军生命周期管理中心正在联合任务规划系统中努力缩短这一时间,但此类努力以前已经进行过。\({ }^{5}\) 通过创建更快更有效的规划软件,我们可能能够加快规划过程或在现有时间限制内制定更好的计划。确定任务规划过程的哪些部分可以被AI增强(如果有的话)是本报告的重点。
为检查任务规划AI如何能够有效使用,我们研究了类似的系统。在过去十年中,有几个高调的AI系统演示,这些系统在曾经被认为需要人类智能的游戏中实现了高水平表现。这些演示中的许多涉及在固定棋盘上进行的轮流游戏,双方玩家都能获得完整信息。例如,DeepMind的AlphaZero在国际象棋、围棋和将棋中展示了超越大师的能力。\({ }^{6}\) 最近开发的AlphaStar是一个AI系统,能够在《星际争霸II》视频游戏中胜过专家级人类玩家。\({ }^{7}\) AlphaStar也是由DeepMind创建的,这是一家总部位于伦敦的AI初创公司,现在隶属于Alphabet(前身为Google)。在2016年AlphaGo成功击败前职业围棋选手李世石后,DeepMind在完成了回合制游戏的征服后开始致力于掌握《星际争霸II》。\({ }^{8}\)
《星际争霸II》可以说是AI领域中强化学习(RL)能力最复杂和最强大的例子之一,体现了作战和战术指挥控制的许多特征,包括在面对未知情况时的关键决策(战争迷雾)。我们评估了AlphaStar开发过程中获得的经验教训,以指导任务规划的哪个方面适合AI。简而言之,AlphaStar的优势表明小规模战术级问题可能最适合AI,这引导我们探索AI进行路线规划。
游戏人工智能:AlphaStar¶
AlphaStar玩《星际争霸II》的能力被用作我们评估AlphaStar AI优势的基础。《星际争霸II》是一款激烈的实时策略游戏,拥有高度竞争的国际场景。《星际争霸II》最受欢迎的双人模式遵循三个大致的游戏阶段。玩家开始时拥有一个基地和采集资源的工人单位。在第一阶段,玩家开始建造建筑和单位;玩家可以派遣单位骚扰或简单地侦察敌人以了解他们在做什么。玩家将选择升级和新选项来对抗他们对敌人选择的预期。在第二阶段(称为中期),力量将发生冲突,玩家将扩展到额外的基地。在最后阶段(后期),升级被淡化,转而大量生产单位以赢得决定性战斗。
《星际争霸II》提出了比以前游戏显著更难的AI问题。在给定时间步长中,平均有\(10^{26}\)个选项,相当于国际象棋中每名玩家大约十步。《星际争霸II》中的每个时间步长发生在不到一秒的时间内。微观层面的可能选项数量巨大,远超国际象棋或围棋等回合制游戏。详细讨论请参见附录。
AlphaStar在战术决策和快速反应方面远超人类,并利用其多任务处理、战术层面的优势来弥补战略理解的不足。AlphaStar不依赖优越的战略来击败人类,因为它可以利用其在战斗中的压倒性优势来赢得大多数游戏。后期迭代显示了改进,但AlphaStar在适应新策略方面仍然困难。
在《星际争霸II》中,玩家实际上将游戏分为微观和宏观要素。微观指对单个单位的指挥控制,是战斗期间的主要游戏内容。多任务处理在微观中发挥巨大作用。宏观指战略要素:确定军队组成、发展研究和增加经济产出。AlphaStar主要使用微观要素获胜,因为机器具有优越的多任务处理能力。
AlphaStar能够依靠单一远程单位赢得大多数战斗,尽管在《星际争霸II》中,这种策略通常会导致失败,因为游戏设计使单位相互克制(例如,类似于石头剪刀布游戏)。\({ }^{9}\) 优越的微观策略使AlphaStar能够在对抗具有最佳反制措施的军队时赢得战斗。具体而言,它利用了一个具有短程传送和可充电护盾的远程追踪者单位,在超人控制下,可以在死亡前的精确时刻传送离开,重新充电护盾,然后重新投入战斗。AlphaStar在多任务处理和战斗战术方面的压倒性优势足以击败专业人类玩家。
尽管有这种压倒性优势,AlphaStar在游戏中其他领域相对较弱。一些早期弱点包括缺乏侦察(确定军队组成以对抗敌人)、易受早期攻击(缺乏防御来对抗敌人的经济骚扰)以及无法在战场上制造瓶颈(在预期的 chokepoints 放置建筑以在战斗中获得优势)。AlphaStar在后期游戏中修正了这些弱点,但在面对新策略时仍然遇到更多困难,即使在持续改进之后也是如此。\({ }^{10}\) 这表明AlphaStar在战略层面决策方面存在困难。
强化学习旨在帮助算法确定行动以获得奖励。在《星际争霸II》的微观层面,战斗快速进行和获胜,很容易将奖励归因于给定行动。\({ }^{11}\) 然而,将因10,000个时间步长前像素级精确放置的 chokepoint 而赢得的战斗归因于奖励是一个更加困难的问题。稀疏奖励问题是在该领域的持续研究领域,也是AlphaStar在战略(宏观)层面竞争困难的最可能原因。
从AlphaStar的例子中,我们确定了两个关键教训:
-
我们应该预期快速反应相对更好,而不确定性下的战略决策相对比人类基准更差。战略和作战规划能力将落后于快速反应和作战能力。
-
没有操作理解反馈循环的替代品。AlphaStar的设计者包括了星际争霸大师级玩家和纯AI专家,他们积极干预训练过程以纠正错误。
方法¶
AlphaStar证明了AI(特别是强化学习)可以在狭窄问题上表现出色。路线规划是在民用领域已有AI成功经验的领域,自动驾驶汽车和自动驾驶仪是最突出的例子。\({ }^{12}\) 适当的路线规划可以最小化对飞行员和系统的风险,减少敌人关于美国资产的信息,并增加任务执行成功的可能性。
虽然只是所有路线规划的一个子集,但为单个编队穿透敌方空域进行规划包含了足够的复杂性元素(敌方位置和多条可行路线),而不会使读者或我们自己(例如,动态敌方位置)负担过重。这也是空军部(DAF)经常遇到的场景,因此可能值得实施,因为AI模型的前期成本相对高于训练人类执行任务,但AI模型更容易扩展到大量应用。使用先前的兰德内部模型,我们探索了将AI应用于此应用的可行性,将AI性能与优化方法进行比较,并评估了这种方法的局限性。在本报告中,我们将纯优化方法与任务规划的纯强化学习方法进行了比较。涉及两种方法或包括经验丰富的人员参与过程的混合解决方案可能会产生改进的结果。
本报告的组织结构¶
第2章介绍了兰德研究人员的工作,以识别ML模型相对于计算替代方案的相对和绝对弱点。第3章描述了我们在高级仿真、集成和建模框架(AFSIM)中创建强化学习环境的工作。这克服了一个关键障碍,即将现有系统与现有AI工具包集成。第4章包含我们的发现和建议。
第2章 兰德目标可达性模型研究¶
我们使用了一个名为兰德目标可达性模型(RTAM)的专有模型来检查一个训练用于穿透敌方防空系统并到达目标点的机器学习(ML)模型,与一个旨在实现相同目标的运筹学(OR)优化函数进行对比。我们对ML方法的绝对和相对弱点感兴趣。鉴于现代ML改进的速度、历史教训,甚至非常大且昂贵的最先进模型的规模正回报,我们不愿将任何当前限制描述为永远不可能。\({ }^{13}\)
然而,通过检查玩具系统中的相对优势和劣势,应该能够确定AI在执行哪些任务时相对更好或更差。只要ML中的当前范式(神经网络)继续领先,这将是一种相对安全的推断。当前范式的结束将是高度可见的,使得这是一个安全的假设,只要它似乎继续成立。
在我们的分析中,OR方法几乎每次都找到了比ML模型更好的路径。我们还发现ML模型需要更长时间进行训练。这不仅仅是计算机时间的问题:模型的更长训练时间意味着规格不当的效用函数需要更长时间来解决。然而,我们在ML的适应性方面看到了优势:它可以根据新信息更快地做出决策。在高度不确定性的条件下,这尤其有价值:遇到敌方资产的可能性更大,因为它们无法避免,但也更有信息价值,因为遇到敌方资产提供了关于其位置的大量信息。
建模方法¶
RTAM由兰德公司在过去20年中开发,以实现同类替代方案的对比分析,并广泛探索不同飞机选项穿透不同防空威胁区域的成功程度。它提供了一个模拟环境,适用于包括指导飞行代理通过威胁区域在内的多项任务。代理可以通过控制器手动控制或通过任何程序定义的输入控制。可以手动调整代理可以定位的区域大小,系统支持预填充的已知威胁和可以动态添加到模拟中的弹出威胁。我们使用了现有的RTAM模型,该模型模拟一个无人机试图穿越现已废弃的半自动地面环境(SAGE)早期预警雷达网络横跨美国本土(CONUS),尽可能避免被探测到,并导航到内部的特定任务目标。为简化、清晰和训练速度,我们检查了从单一起点到单个终点的穿越:我们不期望在添加额外目标并确定这些目标的顺序时,我们的定性结果会发生变化。
OR方法将连续宇宙(见图2.1)划分为具有节点间边缘的离散空间,以覆盖感兴趣的区域。给定指定的效用函数(主要是最小化敌方雷达探测),OR目标是在可能的边缘内找到数学上最优的路径。计算每条边缘的风险,并通过类似Dijkstra的算法确定最低风险路径。当地理精确模型使用更多离散空间时,存在权衡,因此需要更多时间来计算路径。
图2.1. 显示节点-边缘离散化的兰德目标可达性模型地图

注:描绘RTAM场景的屏幕截图。线条代表环境离散化后OR算法可以选择的可能穿越路径。散布在美国周围的小方块代表早期预警雷达。
ML方法使用强化学习(RL)。我们使用了Stable Baselines3 RL PyTorch神经网络库,并使用近端策略优化(PPO)算法训练模型。\({ }^{14}\) 成功训练RL算法相当具有挑战性,经过大量实验后,我们得出了以下训练启发式。利用课程学习的概念,我们首先训练简单的到达目标行为,忽略早期预警雷达探测。在算法生成可靠的寻的RL代理(从任何起始位置到达任何目标)后,我们使用连续训练会话训练早期预警雷达规避行为,从基础到达目标模型开始。\({ }^{15}\) 奖励函数(将讨论)被调整以激励所需行为。在每次后续训练探索序列后进行模型测试和评估。
虽然由于算法差异,损失函数(OR)和奖励函数(RL)不能直接比较,但两个函数都设计为在最小化雷达总探测时间的同时找到到达目标的最短路径。RL奖励函数需要更多项,如接近目标的奖励(随后到达目标以在早期训练迭代期间激励代理)、转向惩罚和燃料惩罚(以鼓励更短的路径)。
图2.2是从RTAM中截取的图像,显示了训练ML模型过程中的部分情况。
图2.2. 兰德目标可达性模型中部分训练的机器学习模型路径
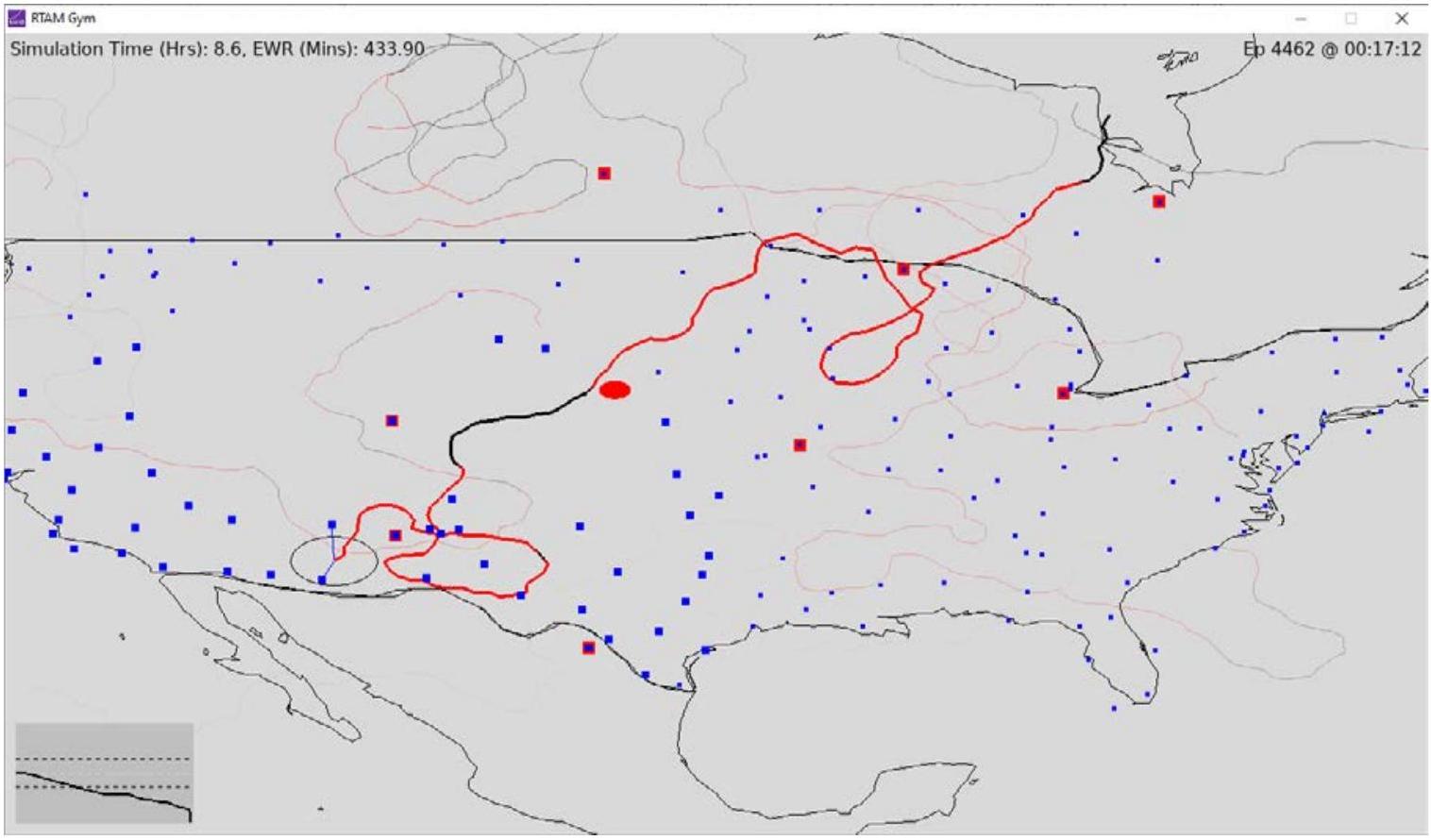
注:RTAM屏幕截图,描绘了ML生成的路径。蓝色点代表早期预警雷达站点的位置。路径段以红色(被雷达探测)或黑色(未被探测)着色。路径末端的圆圈是目标。
飞行路径的红色段表示资产正在被雷达站探测到并处于风险中。黑色段距离雷达站足够远且未受威胁。淡色痕迹的线条是代理最近训练的十个场景的路径,具有不同的起始位置和终点目标位置。
显示的路径与看起来一样低效:要使模型与OR方法竞争,需要大量工作来指定效用函数和环境,然后进行数千次训练周期。这个过程永远不会完美,因此需要多次迭代修改效用函数或训练风格。与OR公式所需的几秒钟相比,每次迭代将需要数小时,导致更慢的观察-定向-决策-行动循环。这降低了结果模型的质量并大幅增加了成本。这个劣势可以通过强大的服务器和经验丰富的工程师来缓解,但不能消除。训练只需在离线状态下进行一次,然后训练好的代理可以在操作中多次使用。但是,在RTAM中,训练对飞机特征、威胁部署、密度和类型敏感;这使得真正的通用路线规划RL具有挑战性,但更专注的路线规划更可行。
RTAM OR以检测时间和射击机会的期望值形式提供单一分析解决方案;期望值在运行之间没有方差。另一方面,ML方法会显著变化:训练的RL本质上可能是随机的,因此在我们的分析中,我们给它每个目标十次尝试并选择最佳的一个。当RL计算路径的时间是毫秒时,根据现实世界的时间线,存在大量寻找最优解的机会。
量化运筹学与机器学习性能:经历的风险¶
我们采用了几种方法来描述两种方法之间的差异。一种可视化方法,图2.3和图2.4,显示了OR方法(图2.3)和ML模型(图2.4)在飞机从大西洋中部起始位置(纬度和经度分别为34.86度和-61.85度)飞向目标时在敌方探测半径内经历的总时间。这些起始位置在图2.3和图2.4中用黑色菱形表示。其他点代表分布在美国本土(CONUS)各地的目标位置,通过不同风险水平的路径到达,代理穿越或绕过早期预警雷达威胁。在大多数情况下,OR方法产生了一个较低风险的选择(从这个特定起始位置到每个目标),范围在0到2.76之间(注意图2.3右侧的风险水平刻度)。相比之下,ML模型的风险水平在CONUS远西部目标处高达8.18。
图2.3. OR路径的目标进入期间风险水平
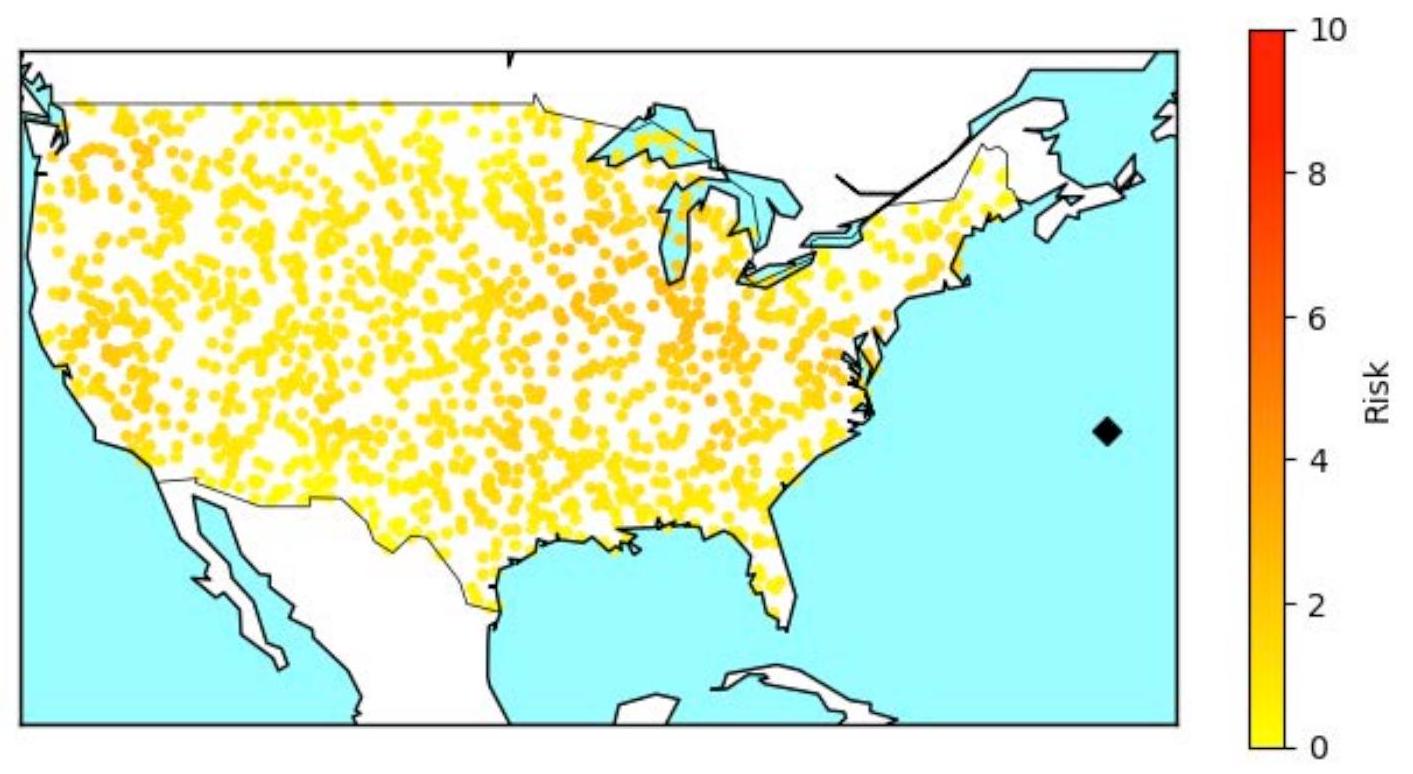
注:右侧的黑色菱形是起始位置。
图2.4. ML路径的目标进入期间风险水平
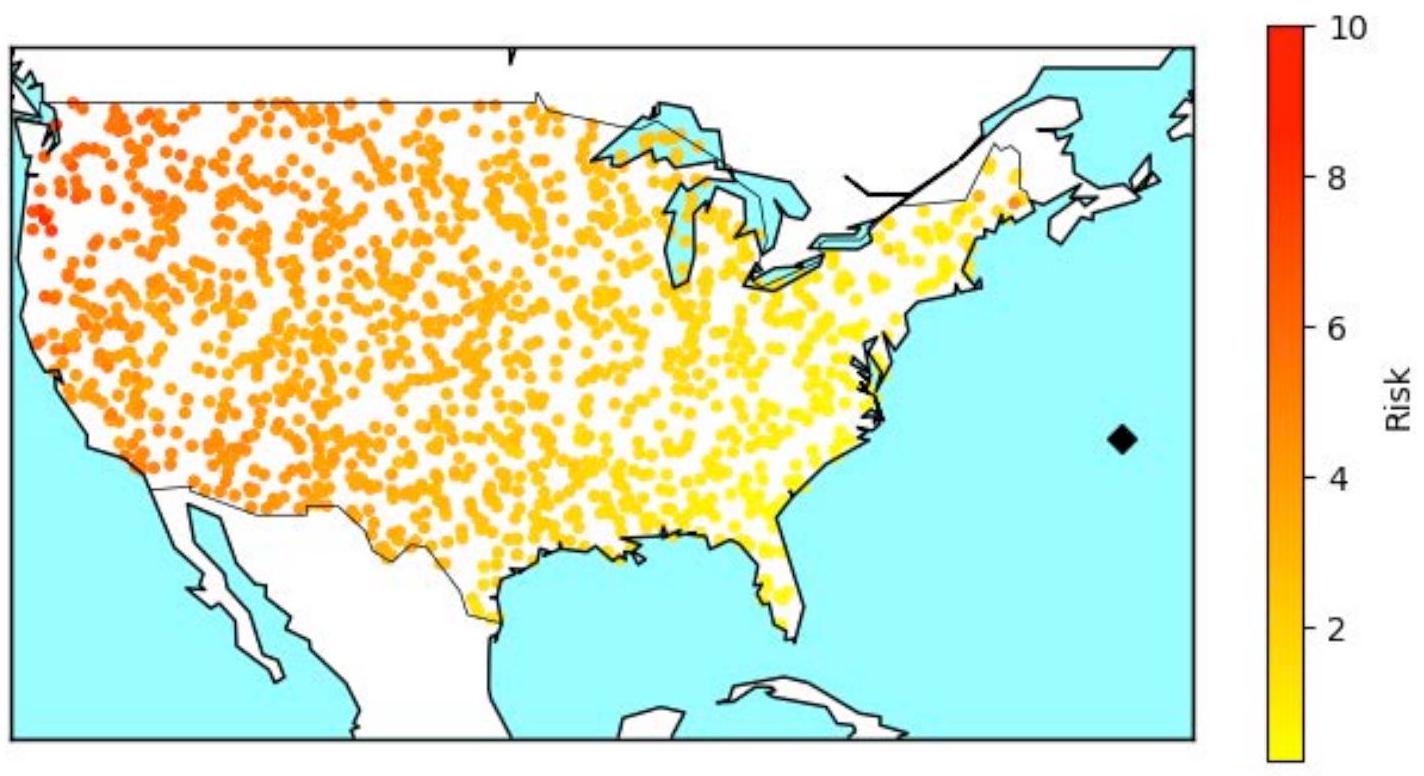
注:右侧的黑色菱形是起始位置。
图2.5有效地结合了图2.3和图2.4。
图2.5. 兰德目标可达性模型图像、运筹学和机器学习优势图
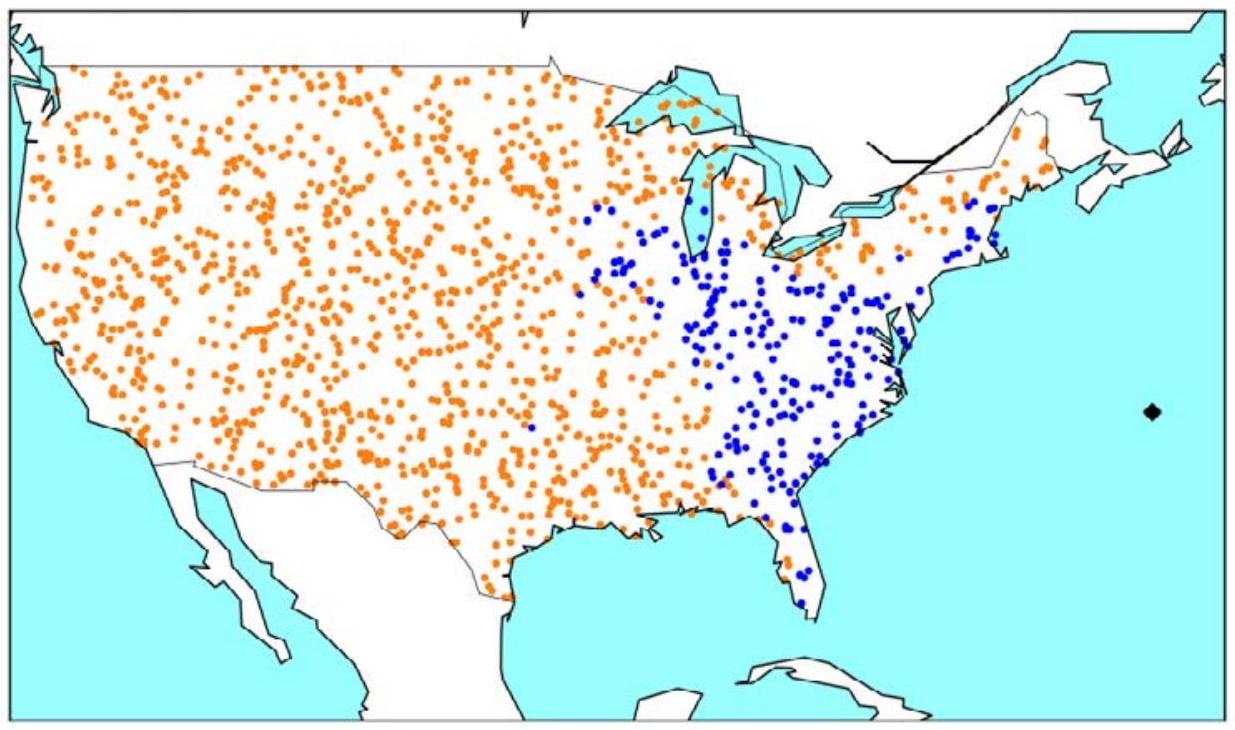
注:蓝色点表示ML表现优于OR,橙色点表示OR表现优于ML。右侧的黑色菱形是起始位置。
蓝色目标位置表示ML模型在风险水平方面优于橙色显示的OR模型的地方。ML在测试位置的16%中表现更好,平均风险水平比OR水平低0.5。ML模型在接近距离较近且更直接路径到起始点的目标时往往表现更优。
相同的数据以另外两种方式呈现,以进一步说明ML模型在此领域的局限性。图2.6展示了所有目标风险水平的直方图。ML模型的风险水平以蓝色显示,OR模型的风险水平以橙色显示。
图2.6. 所有目标风险水平的直方图
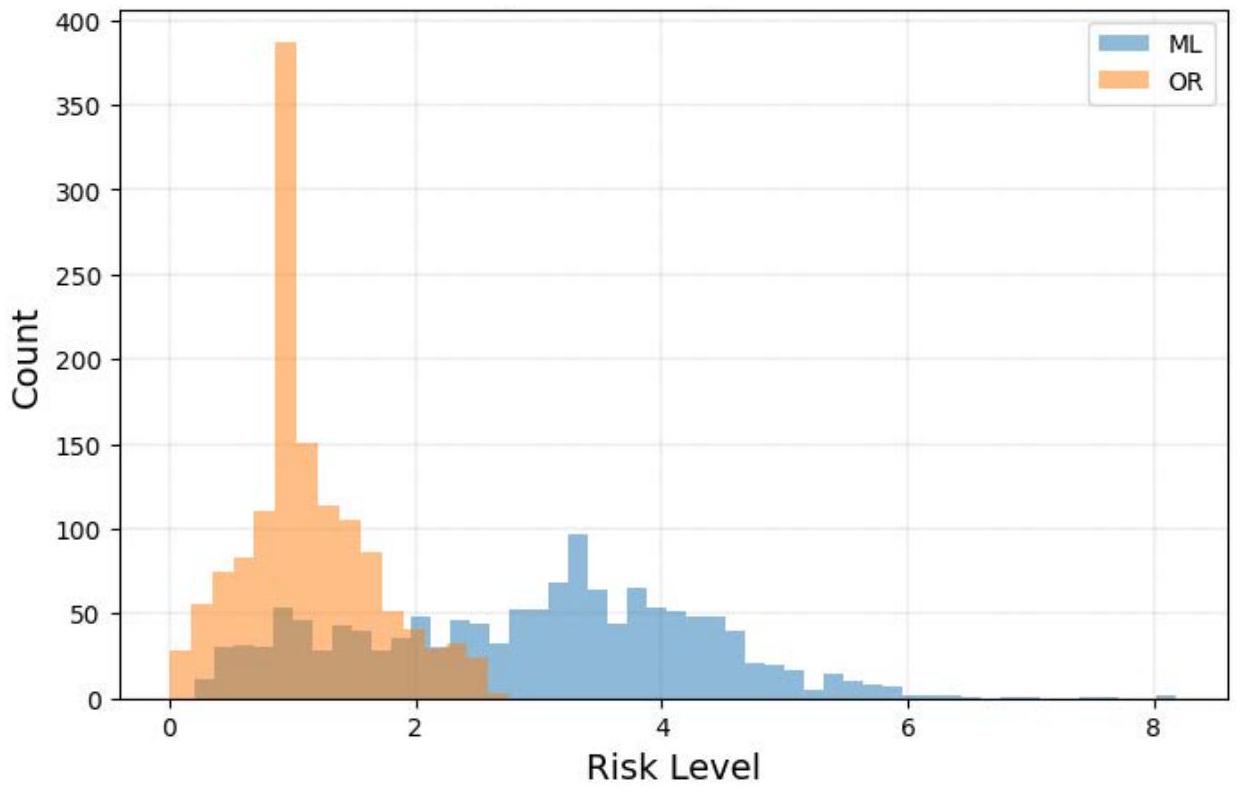
图2.6中两个模型的所有1,376个目标位置风险水平的重叠直方图显示了鲜明的差异。如预期的那样,大多数OR模型风险水平低于ML水平。ML表现更好的16%目标位于两个直方图的重叠部分。ML模型的分布也更平坦,相对而言有更多异常高风险和异常安全的路径。OR模型的非常高峰值代表了更稳定的方法。
最后,图2.7使用散点图格式显示了两个风险水平如何相互比较给定目标。
图2.7. 运筹学与机器学习结果图
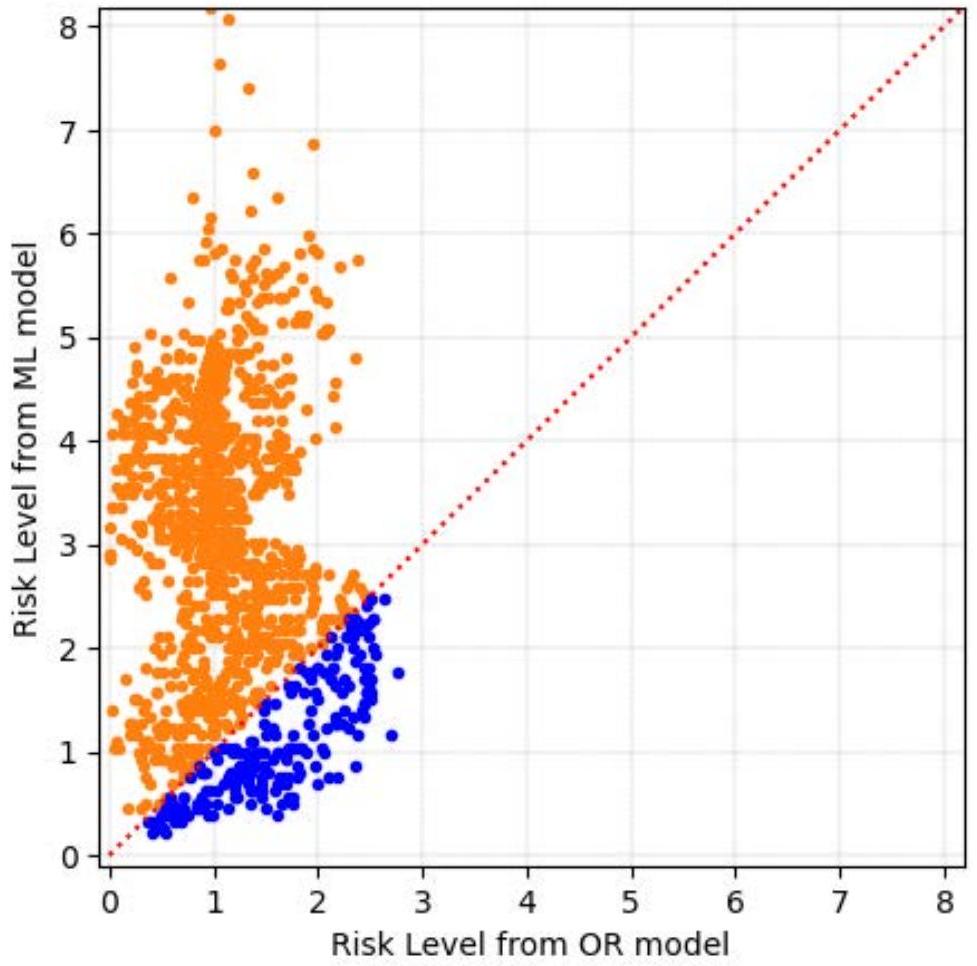
注:比较给定目标的风险水平的散点图(x轴上的点散表示OR生成路径的风险,y轴上的点散表示ML生成路径的风险)。红色虚线是对角线y=x图,表示模型之间的等同性。橙色散点表示OR在给定目标上表现更好,蓝色散点表示ML在给定目标上表现更好。
蓝色目标位置对应ML表现更好的点,适当地位于等同45度线之下。图2.7中分布的平坦性现在是沿轴的垂直扩展远大于水平扩展。有趣的是,两个模型的风险水平之间没有特别强的关系:OR方法能否找到好路径似乎与ML模型做同样事情的能力关系不大。
路径长度¶
效用函数的另一个关键变化组件是代理到达目标所用路径的长度。较短的路径花费更少时间,使用更少燃料,造成更少磨损。我们训练的ML模型倾向于采用更直的路径,直接朝目标前进,适度调整以避免敌方探测。在模拟环境中,使用我们使用的代理,速度是恒定的,所以路径长度和总飞行时间是等效的。
图2.8显示了三个ML案例(标记为AI-1到AI-3)和三个OR案例(标记为OR-1到OR-3)的样本路径。
图2.8. 类似目标位置的ML路径与相应OR路径比较
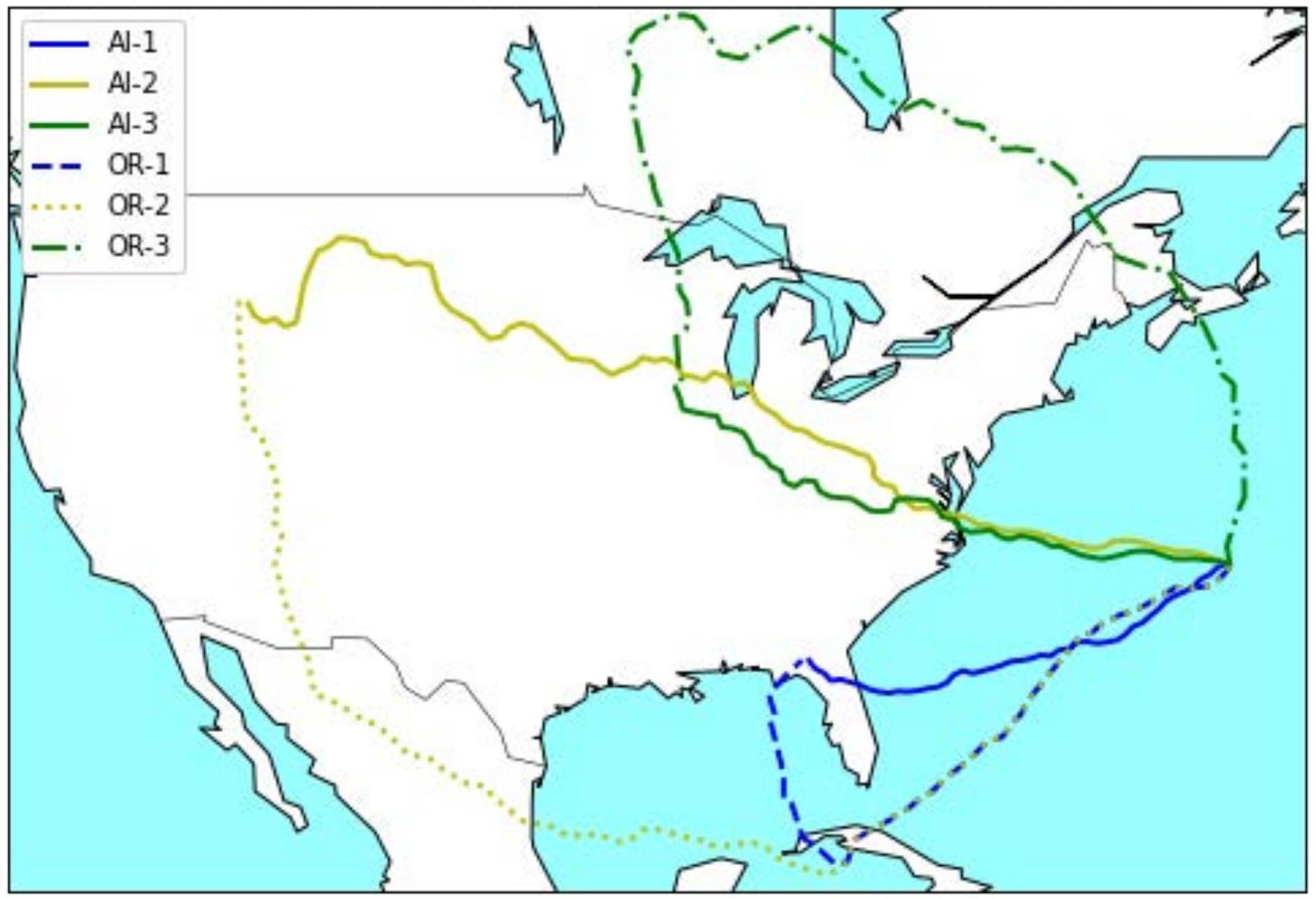
注:ML路径由图例中标记的实线AI-1、AI-2和AI-3表示。OR路径由图例中标记的虚线OR-1、OR-2和OR-3表示。
三个目标位置都显示了ML模型(实线)和OR模型(虚线),都从相同起始位置出发。OR路径最初会绕行CONUS,在没有威胁的地方,到达一个更接近预期目标的位置。ML模型(至少如目前训练的)会在一般直线上尽可能好地穿过威胁。ML模型在东部海岸沿线可能表现更好,因为其路径不像前面描述的那样受限于地图离散化的边缘。这表明ML模型在某些情况下比OR模型更好地编织和穿针引线。最终,对于东海岸上的精确位置,预计这些模型之间会达到等同,因为起始位置和东海岸之间没有威胁。
观察两个不同模型朝目标位置采取的所有路径,有助于了解模型在策略上的差异。图2.9显示了所有可能的路径。
图2.9. 运筹学模型和机器学习模型的1,376条目标路径
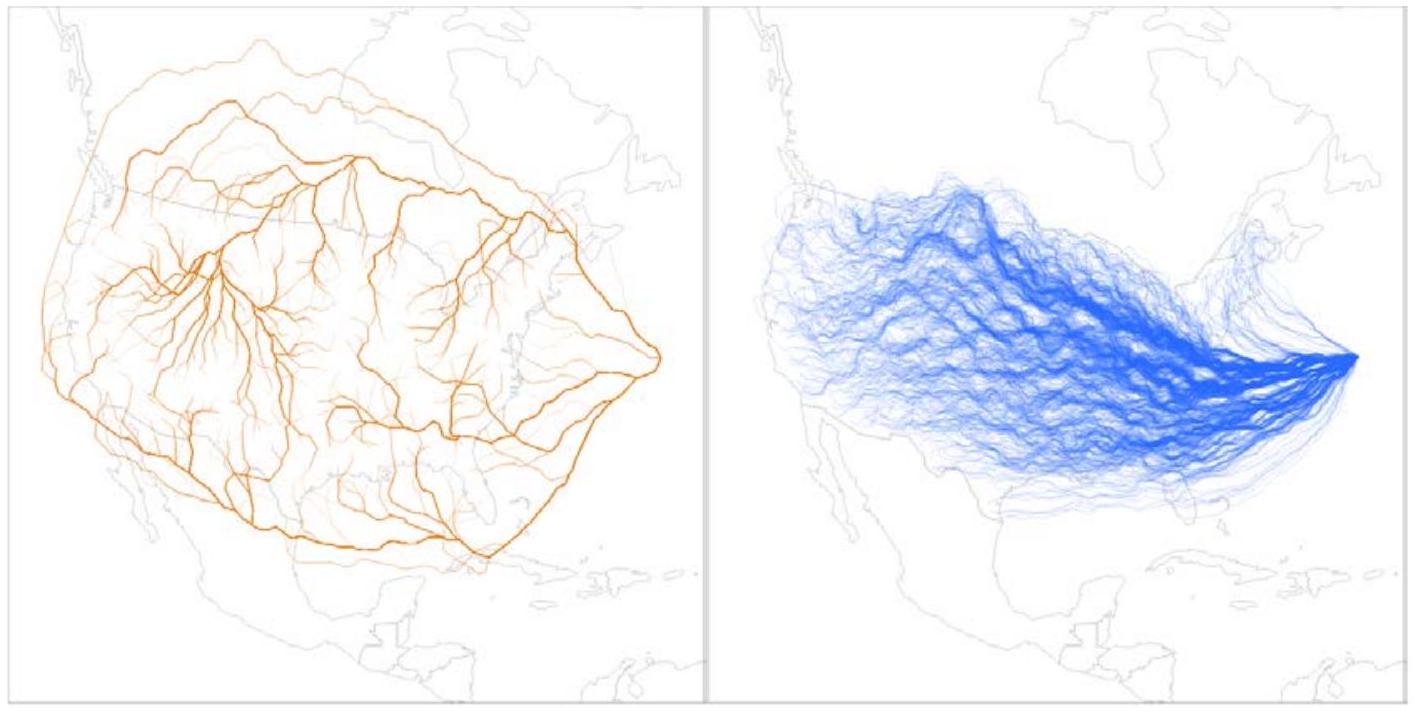
注:左侧图像描绘了OR方法找到的所有可能路径。右侧图像描绘了ML方法找到的所有可能路径。
图2.9中左侧的OR模型朝目标采取不同的轨迹。因此,两个在距离上接近的目标在进入时可能导致显著不同的路径长度。另一方面,图2.9右侧显示的ML模型有更直接的轨迹朝目标,导致总体上更短的路径,但风险更高,如前所述。这些结果让人想起AlphaStar:速度优势得以保持,而不是复杂策略和响应,采用了一种在局部交战中具有优越技能的暴力方法。
在我们的测试中,OR方法几乎总是找到了比ML方法更高效的解决方案,如我们定义的效用函数所示。然而,ML有两个优势。首先,ML更快地提出了解决方案。\({ }^{16}\) 为了在我们使用的硬件上对意外威胁生成新路径,OR方法需要许多秒到分钟,具体取决于地图离散化的粒度。\({ }^{17}\) ML方法在每一步都从可见世界生成新路径,只需毫秒。
其次,OR方法经常找到极其精确和谨慎的路径,而ML方法会摇摆。这导致ML方法生成更稳健的路线,对不确定性有更高的容忍度。例如,现实世界中的风可以使飞机产生侧滑(将飞机角度设置为与地面净运动方向不同),而ML方法可以容忍这种偏移。注意我们训练RL算法来响应突发威胁(当以前未知的早期预警雷达突然出现在飞机前方时)和不确定的雷达位置(在每次模拟中,雷达位置在略微不同的位置生成)。然而,为了公平的苹果对苹果路径比较,我们关闭了突发威胁以生成图2.9。
我们认为相对经验至关重要。虽然AI目前处于劣势,但了解其相对优势和劣势将使AI在向超人能力发展时得到更好的应用。例如,训练AI模型很困难(而且需要很长时间),但好处是快速(在我们的情况下是实时)的路线建议。了解AI的哪些方面可以做得更好,可以更好地规划。这假设技能改进率是恒定的,这似乎是合理的。在我们的实验中,我们发现
- 平均而言,ML模型在敌方资产半径内花费的时间比OR方法多2.5倍
- ML模型能够在OR算法时间的五分之四内到达目标
- 威胁密度和整体环境复杂性的增加使ML方法更具吸引力。
OR算法以检测时间和射击机会的期望值形式提供单一分析解决方案;运行之间期望值没有方差,结果相当正常。另一方面,ML模型会有显著变化:训练的RL本质上可能是随机的,因此在我们的分析中,我们生成了十条路径并选择了最佳路径。当RL计算路径所需的时间是毫秒时,根据现实世界的时间线,有很多机会找到最优解。表2.1比较了OR和ML方法的路径属性。
表2.1. 运筹学和机器学习结果
| OR | ML | |
|---|---|---|
| 敌方探测 | 平均风险水平:1.12 | 平均风险水平:2.91 |
| 路径长度 | 平均:\(5,070 \mathrm{~km}\) | 平均:\(3,938 \mathrm{~km}\) |
| 开发成本 | 低 | 高 |
| 响应时间 | 秒到分钟 | 毫秒 |
| 可预测性 | 给定效用函数和情况时固定 | 每次运行都变化 |
注:敌方探测是在敌方探测能力范围内花费的时间总和。结果显示在成功任务(到达目标)中。
训练AI模型变得更容易和更直接。例如,AutoML脚本可以自动化一些步骤,如算法选择和超参数优化。然而,开发过程中的许多步骤仍然需要人工干预(例如,数据清理、特征选择和设计网络架构的某些方面可能是手动的)。在实验期间,几次模型训练尝试被放弃,因为奖励函数略有校准错误。有一次,探测惩罚太高,模型宁愿避开目标并撞入海洋,也不愿穿越对手的防空系统。
在蛋白质折叠或文本生成等高度复杂领域中的ML模型通常随着模型规模和训练迭代的增加而改进。然而,任务规划在计算上相对简单。一旦模型提供了良好性能(非正式定义为人类看不到明显改进),更多训练不会产生记录到的敌方雷达威胁更低、飞行时间更短或任何其他指标改进的飞行路径。我们还经常遇到远离全局最大值的局部最大值,这需要人工干预。在超参数优化期间,我们发现表现最好的模型是一个相对简单的两层模型。虽然人类专业知识至关重要,但我们发现结果模型不需要特别复杂。
从我们与RTAM的工作中,我们得出以下要点:
- ML模型通常在与我们的OR方法比较时表现不佳。
- ML模型在六分之一的情况下表现优于OR,并且具有显著的速度优势。
- 在任务规划中结合多种方法和方法的灵活性是有用的,即使一种方法或方法通常比另一种更好。
- 在简单表示中,长时间训练的费用是不必要的。
- 没有计算能力、时间或金钱的量能够充分替代专业知识。
第3章 从高级仿真、集成和建模框架制作强化学习环境¶
第2章讨论的RTAM玩具问题展示了基于ML和OR的路线规划方法之间的关键差异。在本章中,我们讨论了为DAF使用的仿真工具开发基于ML方法的工具。DAF使用AFSIM,这是一个基于C++的多域建模和仿真框架,用于进行分析以支持兵棋推演、实验和任务规划。AFRL根据信息转让协议与合作伙伴共享AFSIM,已授权给超过275个政府、工业和学术组织。\({ }^{18}\) 图3.1提供了AFSIM的公开发布屏幕截图。
图3.1. 高级仿真、集成和建模框架屏幕截图
来源:赖特-帕特森空军基地,"高级仿真、集成和建模软件",网页,美国空军,未注明日期。
灰色文献来源和我们采访的专家都同意,AFSIM受欢迎的一个重要贡献因素是开放访问的程度。\({ }^{19}\) 它不仅在符合国际武器贸易条例的环境中免费提供给合作伙伴,还包括底层源代码。设计高度模块化,因此可以分发相对最少武器系统信息的受控非密版本,而包含更多详细信息的模块可以在其他密级分发。AFSIM还支持自定义领域特定语言AFSIMScript,被誉为更容易访问,我们在自己的工作中发现它很有帮助。
AFSIM的模块化使像我们这样的工作能够轻松应用于用户的现有系统而无需任何额外修改。然而,仅仅是模块化不足以解决所有问题。AFSIM的代码最初由波音公司于2003年开发,基于C++,因为当时广泛使用,并且在中央处理器比2023年慢几个数量级的时代,它提供了更关键的速度优势。然而,C++在接下来的二十年中流行度下降,该语言不是任何当前流行ML框架的原生宿主。今天工业界大多数建模者和研究人员选择的语言是Python,特别是在性能敏感性有用但不是高优先级的情况下。
在RL术语中,gym是开发代理的环境。它提供了一个动作和观察空间,使给定策略能够快速评估。速度对gym至关重要,因为RL依赖于多次迭代模型。gym对于有效的模型训练、测试和改进是必要的,因为与现实世界的交互要昂贵得多,速度要慢得多。
2019年至2020年,兰德研究人员开发了一个原型RL gym,与AFSIM相比,具有简化的雷达模型和显著简化的功能集,称为AFGYM。\({ }^{20}\) 通过限制其范围,兰德研究人员能够展示有效的学习并表明性能提升导致RL训练时间大幅减少。AFGYM引起了工业界和政府的极大兴趣,表明美国国防部在RL建模基础设施方面存在能力差距和需求。然而,AFGYM的功能缺乏意味着更广泛的社区使用最少。
我们制作了一个端到端集成,使用Python TensorFlow框架在AFSIM内启用RL训练。我们用两个概念验证场景演示了这个RL框架:使用虚拟飞机输入,我们展示了跟随领航飞机和在作战区域内的自动目标感知是可能的。与Python(AI的通用语言)的集成为可能不熟悉AFSIM代码的ML研究人员打开了AFSIM RL探索的大门。
这不仅是第一个在AFSIM内工作的免费gym,也是任何地方的第一个。解决端到端集成需要有人理解领域和作战人员及规划人员的需求,并且是有经验的ML从业者。兰德以前的研究人员在此领域的研究作为ML演示很好,但没有产生满足所有需求的有用环境。通过实现更接近的匹配,兰德研究人员的解决方案可以被广泛使用。
然而,即使Python很受欢迎,它也不是完美的。最关键的是,Python运行速度明显较慢,特别是在设置时间(部分原因是Python的类型系统迫使解释器在运行时完成大量工作,而C++是预先编译的)。我们的版本关键在于训练后不需要Python框架,否则会导致运行时大幅延迟,并且在与其他建模基础设施一起运行时很笨拙;我们基于这样的前提:Python对训练有价值,但在项目其余部分运行模型(AI已经训练完成)时移除该要求具有内在价值。训练的模型可以直接部署到AFSIM。可以不涉及任何Python来运行模型,这支持只懂C++的用户。AFSIM是用C++构建的,除了AFSIMScript外还支持C++命令,TensorFlow Lite导出到C++。
gym适用于AFSIM可以建模的任何环境,包括空中、陆地、海上、网络和太空。同样,虽然我们研究了一个具有非常高粒度的模型,TensorFlow设置在战役级别同样有效。使用这个gym,我们在AFSIM内原型化了几个RL解决方案:保持倒立摆直立、跟随领航者和自主感知。
我们的代码通过发布到AFSIM门户与AFRL共享。AFSIM门户已被众多用户使用,包括AFRL内部、更广泛的DAF社区和DAF外部用户。我们遇到的一些了解门户使用情况的人包括学生、工业合作伙伴和AI采用和实施小组。我们通过电子邮件、一对一会议、演示和其他方法与用户互动。不幸的是,由于门户没有跟踪用户的方法,完整用户范围未知。
我们从这项工作中得出了四个教训。首先,建模和仿真社区对采用ML工具感到兴奋和感兴趣。其次,将开源工具连接到国防部系统以产生有用产品的当前支持选项有限。虽然开放访问是关键步骤,没有它就无法完成这项工作,但它不是最后一步。第三,利用现有资源节省了大量时间和精力,使我们能够有效地接触到已经具有AFSIM经验的更广泛社区。最后,更新库、框架甚至语言以匹配现代从业者社区的需求有显著好处。
第4章 发现和建议¶
发现¶
AlphaStar说明了利用RL解决复杂规划问题的困难。教机器做战略级决策具有挑战性,因为很难将个人行为归因于具有长期奖励回报的战略目标。这一限制引导我们探索路线规划中的RL,这是一个范围更窄的问题。虽然我们取得了成功,但训练过程涉及试错、启发式开发和奖励函数的重大修订,以平衡两个目标(到达目标和最小化雷达探测风险)。对于相对简单的任务(路径查找),我们需要大量的代码开发(支持AI的工具)、研发和计算资源。在投资任务规划和RL的AI之前,应进行成本效益分析。
与OR方法相比,AI通常表现更差。鉴于OR涉及解决表述良好的优化问题,这一结果并不令人意外。然而,AI对变化的环境可能更具鲁棒性和响应性,因为OR解决方案仅用于解决静态问题。
尽管有这些警告,AI能够帮助某些规划角色,以这种方式使用AI将为未来AI使用建立能力、经验和用户信任。任务路线规划是窄范围AI应用的一个例子,特别适用于动态威胁环境,其中任务编队进入具有突发威胁的复杂防空环境。
任务规划的AI需要开发基础设施,有效连接仿真环境和AI框架,后者通常用不同的编码语言编写(例如TensorFlow或PyTorch)。幸运的是,这对每个仿真环境都是一次性投资。DAF应考虑此类投资并将基础设施发布给政府和合作伙伴组织。在共同基础设施上开发AI比让供应商在重复功能上竞争更便宜,并且能够更容易地在竞争性RL模型之间进行苹果对苹果的比较。
在任务规划中实施AI,以及更广泛地在战争中实施AI,不仅仅是创建独立程序的问题。支持与其他工具的连接并随着新工具的发明不断更新这些连接至关重要。没有这种持续的支持和努力,AI的实际使用不可避免地会落后于近等对手。DAF通过有意识地考虑未来应用和软件,将更好地满足作战人员的需求。
建议¶
作为任务路线规划AI应用的第一步,我们建议为AI划定一个狭窄的问题,然后原型化一系列奖励函数以鼓励一次学习一种行为。OR方法客观上更好,但在所有领域可能不够鲁棒或不可能。对于许多时间步长的非常复杂决策,将此类挑战表述为基于优化的问题(或数学上不可行)可能是不可能的,而ML方法是吸引人的选择。狭窄地划定问题并迭代开发奖励函数使研究人员能够随着时间推移开发复杂行为。
我们建议DAF将RL任务规划应用于由操作员审查和判断的无人系统的动态路线规划。目前,RL在任务规划中的最佳用途是作为快速反应管理系统,动态响应威胁。这既适用于机载无人机,也适用于能够在几秒而不是几分钟内提供更新飞行计划的总部。我们相信这种方法对扩展无人系统的能力具有吸引力,实施将建立用户信任和经验。即使RL提供次优计划,它也能建议立即行动;操作员可以利用快速反应节省的时间,使用他们当前标准和首选方法制定更好的计划。
由于现有的人类规划过程有效利用了可用信息,实施AI任务规划对结果效率的改进相对较小。然而,为高端冲突扩大数百架每日飞机出动的规划在AOC内创造了对人类规划人员无法承受的需求。目前,我们预计基于AI的任务规划成本将大幅超过收益,如果将其设想为人类规划的完全替代品。然而,DAF可以采取措施为AI使用奠定基础,正如兰德研究人员先前建议的那样。\({ }^{21}\)
DAF应培训既深入了解军事任务规划又具备AI专业知识的专家。RL是一个困难的研究领域,依赖于经验和启发式。应用特定知识的需要进一步复杂化了研究。那些在该领域缺乏熟悉度的人可能无法识别不良状态和行为,从而无法制定合适的奖励函数。
DAF必须优先考虑工具和软件,不仅要创建它们,还要使这些资源可扩展并连接到现有系统。现有仿真工具应扩展以与AI框架兼容。训练RL需要让算法经历各种情况。自动输入数据、目标和其他信息将大大加快训练和操作部署的工作流程。我们代码的强烈需求表明,存在对不仅与AI兼容而且主动集成AI的工具的需求。我们已在AFRL Gitlab门户上发布了我们的基础设施,这减轻了未来研究人员使用AFSIM进行RL的资源负担。
DAF应持续监控AI RL领域;RL中以前发生过范式转变,以后也可能再次发生。虽然AI在商业和研究社区中快速发展,但DAF需要保持警惕,寻找整合新进展的机会。
附录 详细的AlphaStar讨论¶
任务规划是同时分配各种有人和无人资产,在有限时间内完成目标。在我们的分析中,我们主要关注路线规划:一旦某个资产或编队被分配了特定目标,它如何到达那里并返回?
关于路线规划软件的商业使用信息很少。然而,AI在计算机游戏方面引起了相当多的公众关注,导致各种来源,这似乎是合理的近似。
以前的竞争性AI系统,包括视频游戏AI在内,严重依赖手工编码元素和基于决策树的启发式方法。\({ }^{22}\) 为了创建AlphaStar,DeepMind组建了一个ML模型联盟,它们相互竞争。联盟采用的战术随着时间变化,最终收敛到AlphaStar最终采用的相对稳定策略。这是一个非常昂贵的过程:仅计算资源就需要超过1200万美元才能复制。\({ }^{23}\)
一个重要的考虑点是《星际争霸II》是一个信息不完全的游戏。与围棋、国际象棋和将棋不同,存在战争迷雾,遮蔽了敌方活动。视野仅限于玩家单位和建筑周围的区域,这使得侦察以确定敌人位置、力量组成和未来意图变得至关重要。信息不完全迫使玩家预测敌人在建造什么,而不仅仅是最大化经济或军队生产效率。玩家必须在敌人最弱时攻击,在敌人最强时保护自己的单位。后期单位更强大,至少中期游戏的单位需要有效摧毁敌方基地,但早期有效攻击如果不受挑战仍然有价值。早期攻击脆弱的工人可以削弱敌方资源生产,创造后期游戏优势。基于有限信息判断敌人何时强弱的过程与战时任务规划过程有相当多的相似之处。然而,这不是AlphaStar表现良好的领域。
联盟比赛前的预期喜忧参半。Caster Falcon Paladin表示,虽然AI显然能够进行战术和决策,如过去AI在国际象棋和围棋方面的成功所证明的那样,但AI预计会在定位、微观操作和"更大的大局复杂决策"等方面遇到困难。\({ }^{24}\) 微观是电竞玩家使用的专业术语,指高速和精确的动作,特别是在单次战斗中,而宏观指整个游戏的更广泛战略。如前所述,AlphaStar利用了微观,并通过追踪者单位连续击败人类。
AlphaStar表现出一些人类决策的模仿,这很奇怪。例如,人类从游戏中移除岩石,因为它们的存在会导致误点击(例如,攻击岩石而不是敌方玩家)。然而,AlphaStar会移除岩石,即使误点击对它不是问题。这种错误不是DeepMind建模的必要特征(AlphaZero仅通过自我对弈学习了DeepMind的围棋模型),但可能是包括人类水平玩家的训练策略的可能产物。
一种被称为三先知的新战术在职业选手中迅速流行,给AlphaZero带来了麻烦,可能是因为它从未针对这种战术进行过训练。\({ }^{25}\) 虽然ML模型能够快速响应新信息,但它们难以应对需要范式转变的全新策略。对样本外数据的不良响应是ML中已知且持续的问题。战略失败也是持续的:"他们会建造建筑物将自己困在自己的基地里,将单位挤入危险的瓶颈以到达巧妙放置的敌方单位,当当前策略不起作用时无法改变战术。"\({ }^{26}\) 一些由优越微观操作实现的策略被严肃玩家认为是可行的,并被人类采用。\({ }^{27}\)
缩写¶
| AFRL | 空军研究实验室 |
|---|---|
| AFSIM | 高级仿真、集成和建模框架 |
| AI | 人工智能 |
| AOC | 空中作战中心 |
| CONUS | 美国本土 |
| DAF | 空军部 |
| ML | 机器学习 |
| OR | 运筹学 |
| RL | 强化学习 |
| RTAM | 兰德目标可达性模型 |
| ## References |
Falcon Paladin, "Alphastar (P) v MaNa (P) 5-Game Series!-StarCraft2-Legacy of the Void 2018," video, YouTube, January 27, 2019. As of September 24, 2022: https://youtu.be/sB7unYvSKk8?si=FfillIBU8QCejKMt
Fraade-Blanar, Laura, and Brian A. Jackson, "Developing a Winning Safety Strategy for Automated Vehicles," RAND Blog, February 18, 2022. As of September 24, 2022: https://www.rand.org/blog/2022/02/developing-a-winning-safety-strategy-for-automated.html
Geist, Edward, Aaron B. Frank, and Lance Menthe, Understanding the Limits of Artificial Intelligence for Warfighters: Vol. 4, Wargames, RR-A1722-4, 2024.
Kaplan, Jared, Sam McCandlish, Tom Henighan, Tom B. Brown, Benjamin Chess, Rewon Child, Scott Gray, Alec Radford, Jeffrey Wu, and Dario Amodei, "Scaling Laws for Neural Language Models," arXiv, January 23, 2020.
Knapp, Jaclyn, "Information Transfer Agreement Enables AFRL Software Sharing with Industry," WrightPatterson Air Force Base, March 10, 2017.
Korzekwa, Rick, "The Unexpected Difficulty of Comparing AlphaStar to Humans," AI Impacts blog, September 17, 2019.
Lingel, Sherrill, Edward Geist, Thomas Hamilton, Daniel M. Norton, and Colby P. Steiner, (U) Toward Continuous Planning for Modern Warfare: A Warfighting-Focused Framework for Operational Planning of Science and Technology Pursuits, RAND Corporation, RR-A953-1, 2023, Not available to the general public.
Lingel, Sherrill, Jeff Hagen, Eric Hastings, Mary Lee, Matthew Sargent, Matthew Walsh, Li Ang Zhang, and David Blancett, Joint All-Domain Command and Control for Modern Warfare: An Analytic Framework for Identifying and Developing Artificial Intelligence Applications, RAND Corporation, RR-4408/1-AF, 2020. As of October 11, 2023: https://www.rand.org/pubs/research_reports/RR4408z1.html
LowkoTV, "StarCraft 2: AlphaStar (Artificial Intelligence) vs Grand Master League!" video, YouTube, November 12, 2019. As of September 24, 2022: https://www.youtube.com/watch?v=VsJpWZj9j10
Menthe, Lance, Li Ang Zhang, Edward Geist, Joshua Steier, Aaron B. Frank, Eric Van Hegewald, Gary J. Briggs, Keller Scholl, Yusuf Ashpari, and Anthony Jacques, Understanding the Limits of Artificial Intelligence for Warfighters: Vol. 1, Summary, RR-A1722-1, 2024.
Schulman, John, Filip Wolski, Prafulla Dhariwal, Alec Radford, and Oleg Klimov, "Proximal Policy Optimization Algorithms," arXiv, August 28, 2017.
Silver, David, Thomas Hubert, Julian Schrittwieser, Ioannis Antonoglou, Matthew Lai, Arthur Guez, Marc Lanctot, Laurent Sifre, Dharshan Kumaran, Thore Graepel, Timothy Lillicrap, Karen Simonyan, and Demis Hassabis, "A General Reinforcement Learning Algorithm That Masters Chess, Shogi, and Go Through Self-Play," Science, Vol. 362, No. 6419, December 2018.
Steier, Joshua, Erik Van Hegewald, Anthony Jacques, Gavin S. Hartnett, and Lance Menthe, Understanding the Limits of Artificial Intelligence for Warfighters: Vol. 2, Distributional Shift in Cybersecurity Datasets, RAND Corporation, RR-A1722-2, 2024.
Thaler, David E., and David A. Shlapak, "Perspectives on Theater Air Campaign Planning," RAND Corporation, MR-515-AF, 1995. As of October 11, 2023: https://www.rand.org/pubs/monograph_reports/MR515.html
Vinyals, Oriol, Igor Babuschkin, Wojciech M. Czarnecki, Michaël Mathieu, Andrew Dudzik, Junyoung Chung, David H. Choi, Richard Powell, Timo Ewalds, Petko Georgiev, Junhyuk Oh, Dan Horgan, Manuel Kroiss, Ivo Danihelka, Aja Huang, Laurent Sifre, Trevor Cai, John P. Agapiou, Max Jaderberg, Alexander S. Vezhnevets, Rémi Leblond, Tobias Pohlen, Valentin Dalibard, David Budden, Yury Sulsky, James Molloy, Tom L. Paine, Caglar Gulcehre, Ziyu Wang, Tobias Pfaff, Yuhuai Wu, Roman Ring, Dani Yogatama, Dario Wünsch, Katrina McKinney, Oliver Smith, Tom Schaul, Timothy Lillicrap, Koray Kavukcuoglu, Demis Hassabis, Chris Apps, and David Silver, "Grandmaster Level in StarCraft II Using Multi-Agent Reinforcement Learning," Nature, Vol. 575, November 2019.
Wang, Ken, "DeepMind Achieved StarCraft II GrandMaster Level, but at What Cost?" Medium, January 4, 2020.
Waters, K. Houston, "Hanscom AFB Team Supports JADC2 Through Agile Software Development," U.S. Air Force, June 7, 2021.
West, Timothy D., and Brian Birkmire, "AFSIM: The Air Force Research Laboratory's Approach to Making M\&S Ubiquitous in the Weapon System Concept Development Process," Journal of the Cyber Security \& Information Systems Information Analysis Center, Vol. 7, No. 3, Winter 2020.
Wright-Patterson Air Force Base, "Advanced Framework for Simulation, Integration and Modeling Software," webpage, U.S. Air Force, undated. As of September 24, 2022: https://www.wpafb.af.mil/News/Art/igphoto/2001709929/
Zhang, Li Ang, Yusuf Ashpari, and Anthony Jacques, Understanding the Limits of Artificial Intelligence for Warfighters: Vol. 3, Predictive Maintenance, RAND Corporation, RR-A1722-3, 2024.
Zhang, Li Ang, Jia Xu, Dara Gold, Jeff Hagen, Ajay K. Kochhar, Andrew J. Lohn, and Osonde A. Osoba, Air Dominance Through Machine Learning: A Preliminary Exploration of Artificial Intelligence-Assisted Mission Planning, RAND Corporation, RR-4311-RC, 2020. As of October 11, 2023: https://www.rand.org/pubs/research_reports/RR4311.html
notes¶
\({ }^{1}\) The interviews were conducted from September 2021 to May 2022 and took place primarily by phone or video call. The interviews were not for attribution, so no names are provided.
\({ }^{2}\) The mission planning process includes the commander's intent; the selection of targets; the evaluation of threats and environmental considerations, such as inclement weather; the selection of air assets to observe points of interest and to neutralize targets; the mapping of how U.S. and allied air assets will accomplish their missions; the processing of all information generated by those mission flights; and all the information flows and iteration required to make the mission function (since the availability of assets can limit which targets can be addressed on a given day).
\({ }^{3}\) In this report, we use \(A I\) to refer to the most common methods of machine learning (ML) today: deep learning neural networks.
\({ }^{4}\) Sherrill Lingel, Edward Geist, Thomas Hamilton, Daniel M. Norton, and Colby P. Steiner, (U) Toward Continuous Planning for Modern Warfare: A Warfighting-Focused Framework for Operational Planning of Science and Technology Pursuits, RAND Corporation, RR-A953-1, 2023, Not available to the general public.
\({ }^{5}\) K. Houston Waters, "Hanscom AFB Team Supports JADC2 Through Agile Software Development," U.S. Air Force, June 7, 2021; David E. Thaler and David A. Shlapak, "Perspectives on Theater Air Campaign Planning," RAND Corporation, MR-515-AF, 1995.
\({ }^{6}\) David Silver, Thomas Hubert, Julian Schrittwieser, Ioannis Antonoglou, Matthew Lai, Arthur Guez, Marc Lanctot, Laurent Sifre, Dharshan Kumaran, Thore Graepel, Timothy Lillicrap, Karen Simonyan, and Demis Hassabis, "A General Reinforcement Learning Algorithm That Masters Chess, Shogi, and Go Through Self-Play," Science, Vol. 362, No. 6419, December 2018.
\({ }^{7}\) Vinyals, Oriol, Igor Babuschkin, Wojciech M. Czarnecki, Michaël Mathieu, Andrew Dudzik, Junyoung Chung, David H. Choi, Richard Powell, Timo Ewalds, Petko Georgiev, Junhyuk Oh, Dan Horgan, Manuel Kroiss, Ivo Danihelka, Aja Huang, Laurent Sifre, Trevor Cai, John P. Agapiou, Max Jaderberg, Alexander S. Vezhnevets, Rémi Leblond, Tobias Pohlen, Valentin Dalibard, David Budden, Yury Sulsky, James Molloy, Tom L. Paine, Caglar Gulcehre, Ziyu Wang, Tobias Pfaff, Yuhuai Wu, Roman Ring, Dani Yogatama, Dario Wünsch, Katrina McKinney, Oliver Smith, Tom Schaul, Timothy Lillicrap, Koray Kavukcuoglu, Demis Hassabis, Chris Apps, and David Silver, "Grandmaster Level in StarCraft II Using Multi-Agent Reinforcement Learning," Nature, Vol. 575, November 2019.
\({ }^{8}\) Silver et al., 2018.
\({ }^{9}\) In a more detailed example, imagine a scenario in which spearmen counter a cavalry, which counters archers, who counter spearmen, and AlphaStar wins with the equivalent of an all-archer army. A cavalry, which otherwise counters archers, is defeated because archers are world champion-level snipers who pick optimal targets at the individual level.
\({ }^{10}\) For example, see LowkoTV, "StarCraft 2: AlphaStar (Artificial Intelligence) vs Grand Master League!" video, YouTube, November 12, 2019, 18:50-19:23.
\({ }^{11}\) For example, AlphaStar learned that retreating while firing on the enemy is a good strategy because it keeps enemy units within firing range but its own units out of the enemy's range. The immediate reward is that the enemy units' health decreases while its own units' health stays high.
\({ }^{12}\) See Laura Fraade-Blanar and Brian A. Jackson, "Developing a Winning Safety Strategy for Automated Vehicles," RAND Blog, February 18, 2022.
\({ }^{13}\) Jared Kaplan, Sam McCandlish, Tom Henighan, Tom B. Brown, Benjamin Chess, Rewon Child, Scott Gray, Alec Radford, Jeffrey Wu, and Dario Amodei, "Scaling Laws for Neural Language Models," arXiv, January 23, 2020.
\({ }^{14}\) John Schulman, Filip Wolski, Prafulla Dhariwal, Alec Radford, and Oleg Klimov, "Proximal Policy Optimization Algorithms," arXiv, August 28, 2017.
\({ }^{15}\) We used one million training epochs per session. This value was arbitrary and not rigorously tested, but we found it sufficient to reliably learn desired behaviors.
\({ }^{16}\) The ML approach is faster than the OR approach, but there are caveats. The runtime for the OR approach is directly affected by the quantization of the simulation environment; it typically uses \(5-30 \mathrm{~km}\) granularity. The granularity, or number of discrete points that the OR algorithm can consider, could be decreased to the point where the OR algorithm can generate a path as fast as the ML model. However, the loss in precision would render very bad results (uniformly worse than those generated by the ML model). Increasing the discretization raises both path precision and OR runtime. Setting a fair level of granularity for speed comparisons is not possible because the ML approach operates on continuous space.
\({ }^{17}\) The hardware we used was a commercial laptop with an integrated Intel UHD Graphics 620 (GT2).
\({ }^{18}\) Jaclyn Knapp, "Information Transfer Agreement Enables AFRL Software Sharing with Industry," Wright-Patterson Air Force Base, March 10, 2017; Timothy D. West and Brian Birkmire, "AFSIM: The Air Force Research Laboratory's Approach to Making M\&S Ubiquitous in the Weapon System Concept Development Process," Journal of the Cyber Security \& Information Systems Information Analysis Center, Vol. 7, No. 3, Winter 2020.
\({ }^{19}\) West and Birkmire, 2020.
\({ }^{20}\) Li Ang Zhang, Jia Xu, Dara Gold, Jeff Hagan, Ajay K. Kochar, Andrew J. Lohn, and Osonde A. Osoba, Air Dominance Through Machine Learning: A Preliminary Exploration of Artificial Intelligence-Assisted Mission Planning, RAND Corporation, RR-4311-RC, 2020.
\({ }^{21}\) Sherrill Lingel, Jeff Hagen, Eric Hastings, Mary Lee, Matthew Sargent, Matthew Walsh, Li Ang Zhang, and David Blancett, Joint All-Domain Command and Control for Modern Warfare: An Analytic Framework for Identifying and Developing Artificial Intelligence Applications, RAND Corporation, RR-4408/1-AF, 2020.
\({ }^{22}\) One prominent StarCraft II example involves programming a swarm of flying units with superhuman multitasking precision. However, as typical of most game-playing AI, this was a hardcoded behavior.
\({ }^{23}\) Ken Wang, "DeepMind Achieved StarCraft II Grandmaster Level, but at What Cost?" Medium, January 4, 2020.
\({ }^{24} \mathrm{~A}\) caster is a commentator who provides a spoken overview to help viewers parse what is happening in a videogame. Falcon Paladin, "AlphaStar (P) v MaNa (P) 5-Game Series!-StarCraft2-Legacy of the Void 2018," video, YouTube, January 27, 2019.
\({ }^{25}\) Three oracles refers to three specific units created at a particular point in time. LowkoTV, 2019, 5:00.
\({ }^{26}\) Rick Korzekwa, "The Unexpected Difficulty of Comparing AlphaStar to Humans," AI Impacts blog, September 17, 2019.
\({ }^{27}\) LowkoTV, 2019, 10:30-11:03.