卷6:利用构造性仿真促进强化学习¶
Harnessing Constructive Simulations for Reinforcement Learning¶
GARY J. BRIGGS

https://www.rand.org/pubs/research_reports/RRA1722-6.html
关键要点¶
- RAND 研究人员开发了一种灵活的软件 harness(软件挂接器),使得许多现有的构造性仿真能够使用最先进的 强化学习(Reinforcement Learning, RL) 方法,而无需大量额外编码。
- RL 是一种强大的 人工智能(Artificial Intelligence, AI) 技术,可用于在构造性仿真中训练软件智能体(agent)做出操作者期望的决策或表现得更加逼真。
- 大多数现代 RL 训练环境(gym,用于训练软件智能体)是用 Python 编写的,而一些应用最广泛的构造性仿真(如美国空军研究实验室的 先进仿真、集成与建模框架(Advanced Framework for Simulation, Integration, and Modeling, AFSIM))则是用其他编程语言编写的。
- RAND 的 RL 软件挂接器将智能体训练与智能体应用分离,使研究人员能够在现有的 C++ 构造性仿真中使用在现代 RL gym 中训练的智能体。
- RAND 研究人员已经在 AFSIM 中展示了该挂接器在一架飞机试图突破对手综合防空系统(Integrated Air Defense System, IADS)的场景下的应用。
- RAND 的 RL 软件挂接器已通过空军研究实验室的 AFSIM 门户向所有授权用户提供。
强化学习(Reinforcement Learning, RL)是一种强大的人工智能技术,用于开发能够做出智能决策并表现出复杂行为的软件智能体。RL 通过来自环境的奖励和惩罚反馈来驱动智能体学习如何在该环境中成功。它曾被广泛应用于训练智能体击败人类选手于围棋、国际象棋等经典策略游戏。\({ }^{1}\)
RL 训练通常发生在一个 RL gym(训练环境)中,这是专门为此优化的人工环境,智能体可以在其中快速多次运行相同场景。\({ }^{2}\) 使用这些方法训练、测试和改进软件智能体可能需要数百万次迭代,因此需要一个快速高效的 RL gym 以满足研发时间要求。如果与未经优化的仿真或现实世界交互,则会更慢、更昂贵,甚至可能不可行。
将现代 RL 训练智能体的智能与成熟构造性仿真的深度结合,可以显著提升仿真的分析能力,使研究人员能够刻画更复杂的交互和更精细的环境。然而,尽管大多数最先进的 RL gym 是用 Python 编写的,大多数构造性仿真并不是。特别是,许多军事研究人员希望能够在 AFSIM(由空军研究实验室开发的仿真环境,用 C++ 编写,已授权超过 275 家政府、工业和学术机构使用)中使用基于 Python 定义的 RL 智能体。\({ }^{3}\)
在 2019 到 2020 年间,RAND 研究人员开发了一个原型 RL gym,称为 AFGYM,它使用简化的特征集来表示飞机攻击或规避雷达的场景。\({ }^{4}\) 该原型证明了 RL 训练可以高效构建适用于更大型仿真(如 AFSIM)的有效智能体。
在软件中,harness(挂接器) 是围绕另一个程序的封装,可以控制该程序的执行或为其提供所需的其他内容(如数据输入)。本报告描述了 RAND 研究人员开发的一种软件挂接器,用于在 AFSIM 和其他构造性仿真中使用 RL 训练的智能体。\({ }^{5}\) 该挂接器提供了一个简单接口,使开发者能够继续使用当前模型的编程语言(不一定是 Python),并且由于其独特的模型执行方法,在速度和内存方面表现出色。本文还介绍了该挂接器在 AFSIM 中应用于一架飞机试图突破对手综合防空系统(IADS)的案例。
设计¶
RAND 的 RL 挂接器跨越了多种语言边界:它将 Python 定义的智能体在基于 Python 的 RAND RL gym 中训练,通过使用 Python 的 ctypes 模块 与 C 编写的“shim”(过渡接口)进行调用,并与主要的构造性仿真对接(以 AFSIM 为例,使用 C++ 编写)。\({ }^{6}\) 最终,像 AFSIM 这样的模型还具有内置的脚本语言:该架构最终调用分析人员定义的脚本,完成一条从 Python 开始、到模型脚本结束的调用链。图 1 展示了这一架构(以 AFSIM 为主要构造性仿真)。
该设计的关键目标是让各领域专家能够使用自己偏好的编程工具:AI 研究人员可以使用 Python,而建模与仿真分析人员则可使用仿真的内置脚本语言。
尽管语言切换复杂,RL 挂接器的运行对性能影响极小。其结构设计使得流程中最慢的步骤(如插件实例化、动态链接库 DLL 加载、大输入文件解析)只在执行阶段开始时运行一次。这使得所有后续迭代(在 RL 中通常称为 epoch)运行迅速。该架构允许即使在大数据集下也能快速重置 AFSIM 场景。
图 1 强化学习挂接器架构
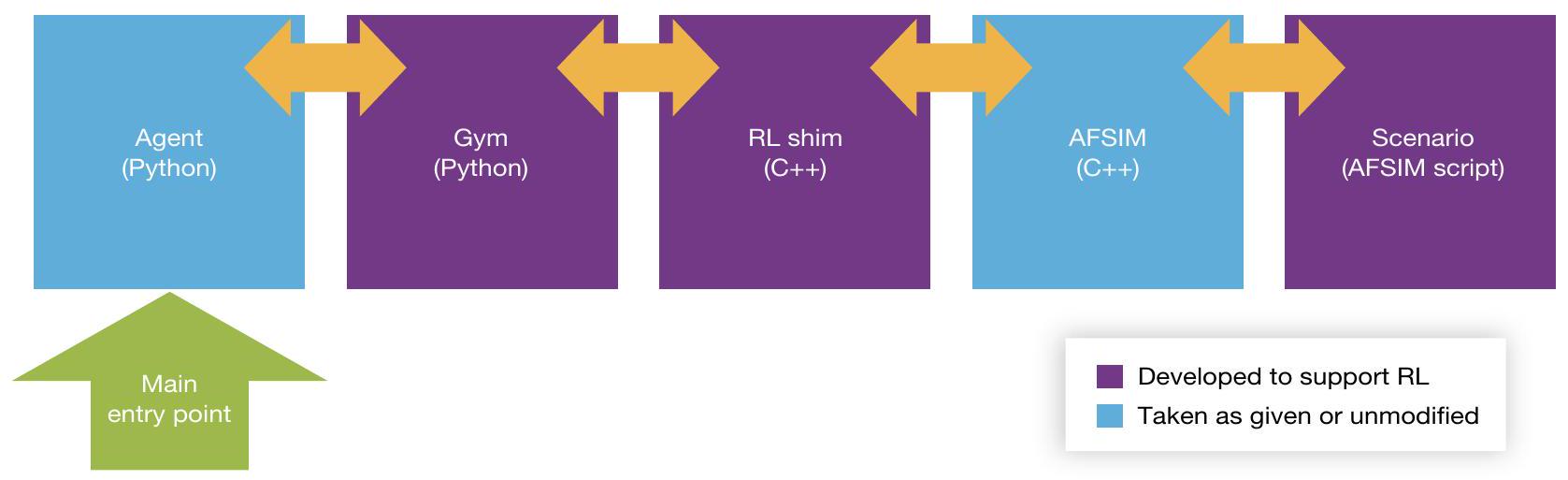
RL 挂接器的关键部分是在主要仿真外部添加一个循环,其中包括一组函数调用——统称为 应用程序接口(Application Programming Interface, API)——供 RL gym 使用。由于模型可能需要在网络受限、互联网访问受限的环境中运行,因此必须尽量减少对 Python 库的依赖;这通过使用 C 调用来封装 C++ 函数,从而利用 Python 内置的 ctypes 模块实现。此方法需要额外步骤来创建函数调用并通过 C API 传递,但也使 DLL 对编译器差异不那么敏感,并避免强制使用 Python-C++ 模块(例如 Boost.Python)。
随后,C++ 模型使用替代的外部 API 重新编译为 DLL(而不是典型的可执行文件)。这样,Python 的 ctypes 模块就可以直接从 Python 调用替代 DLL 的函数。这些函数调用大部分会明确传递给 C++,再进入主要构造性仿真的脚本语言。
RL gym 可以在 AFSIM 能建模的任意环境(包括空中、陆地、海洋、网络、太空)中训练智能体。训练完成后,这些智能体可直接部署到 AFSIM 中。
RAND 研究人员还为 AFSIM 创建了一个附加模块,配合该 RL 挂接器,使训练后的智能体无需挂接器即可部署。这是一个 AFSIM 专用组件,使用 TensorFlow Lite(也可从空军研究实验室的 AFSIM 门户下载)。重要的是,这一附加模块在训练后不需要任何 Python 挂接器,从而使训练好的智能体能够在 AFSIM 的任何常用工具中运行,例如 mission(用于无人值守构造性仿真)或 warlock(用于有人在环和虚拟环境)。\({ }^{7}\) 该部署流程将来自 Python 的训练智能体编译为 TensorFlow Lite 可理解的二进制格式(本质上是神经网络的权重和偏置)。在运行时,该二进制格式由 AFSIM 模块加载,使 AI 在仿真中做出决策。
演示¶
为了展示并与标准方法进行比较,RL 挂接器被用于训练两个构造性仿真的智能体:RAND 目标可达性模型(Target Accessibility Model)\({ }^{8}\) 和 AFSIM。前者用于直接比较 RL 训练智能体与非 RL 训练智能体的性能,后者用于展示该挂接器方法在美国空军建模中的广泛适用性。\({ }^{9}\)
在这两个模型中,都模拟了敌方飞机试图突破一个虚拟 IADS(防御美国领空以攻击目标或目标集)。敌方飞机在尽量降低被探测风险的同时,还需要应对仿真中动态加入的既有威胁和突发威胁。图 2 展示了该系统从大西洋固定起点出发,为抵达分布在美国大陆各地的目标所探索的路径示例。
奖励与惩罚¶
为任何 RL 模型(Reinforcement Learning model,强化学习模型) 选择和实施合适的奖励与惩罚机制至关重要。在该模型中,智能体可能因接近目标而获得奖励,因击中目标而获得奖励,因被探测到而受到惩罚,因燃料耗尽而受到惩罚。为了诱导出逼真的行为,需要在奖励和惩罚之间找到恰当的平衡,这往往需要大量反复试验。例如,如果被探测的惩罚过高,智能体可能会在学习到燃料耗尽的惩罚低于被探测惩罚后,干脆掉头,在 IADS(Integrated Air Defense System,综合防空系统)外盘旋直至燃料耗尽。另一方面,如果击中目标的奖励过于诱人,智能体可能会直接不顾危险冲刺。所需的精确平衡最终取决于 IADS 威胁的密度和风险、飞机的信号特征与机动能力,以及突发威胁出现的频率等因素。
图 2 示例路径集
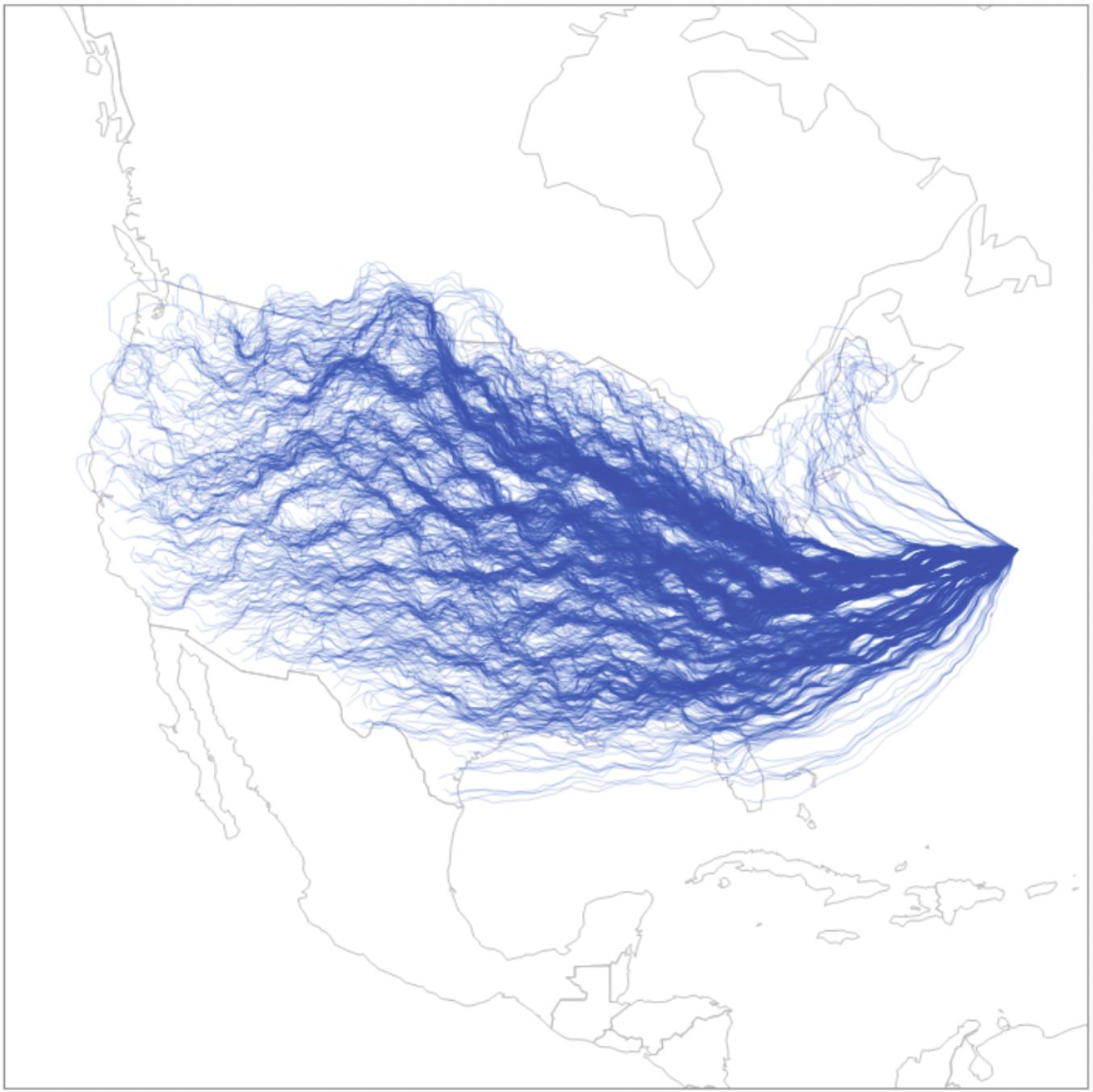
来源:RAND 目标可达性模型(Target Accessibility Model)截图,摘自 Scholl 等,2024,第 14 页。
此外,还可能需要大量次要惩罚和奖励来实现更逼真的行为。例如,最终模型包括了与转弯幅度成比例的小惩罚:如果没有该惩罚,智能体会几乎持续地调整航向。同样,在飞机可能采取直接压制威胁的行为时,通常需要为此类动作加入小惩罚,以防止其被不断执行。当然,必须确保这些惩罚被成功压制威胁所带来的奖励所抵消。
有时,RL 智能体还可能学会 “奖励漏洞利用(reward hack)”。例如,如果指向目标的梯度过陡,RL 智能体可能会学会在目标附近盘旋,反复收集奖励而不是实际击中目标。部分解决办法是减缓该梯度,但另一种有效方式是在每个时间步给予一个小幅度的生存惩罚,从而抵消奖励漏洞利用并鼓励智能体更快抵达目标。同样,有助于在每次训练运行中稍微随机化 IADS 的固定位置,以避免 RL 智能体发现一个偶然的、狭窄的局部最优而与现实不符。
如果分阶段进行训练,效果也会更好。通过在训练初期仅给予极小、几乎可以忽略的探测惩罚,智能体首先学会如何到达目标。随着训练推进,逐步增加被探测的惩罚,使 RL 智能体学会规避威胁。智能体也可能最初从更接近目标的位置开始,然后逐渐拉远。以这种方式递增训练,有助于智能体比原本更快找到解决方案,或避免其始终未能学会击中目标。这些变化可以通过在目标被击中后调整奖励来实现,或者通过在多个 epoch 中以编程方式调整奖励来实现。
最后,一些 RL 框架(包括本案例研究中主要使用的 Stablebaselines3)提供了一种方法,可以在训练 gym 的同时运行一个独立的评估 gym。在该设置下,智能体可以在学习过程中自动保存最佳模型。在该评估 gym 中,对击中目标给予极高奖励,对燃料耗尽给予极高惩罚,对被探测给予一个小但显著的惩罚。在此阶段,其他所有奖励都会被移除。因此,唯一会被视为优秀的模型是那些成功击中目标的模型(并且在这些模型中,优先考虑最能避免探测的模型)。这种机制有助于避免出现飞机未能完成任务的解决方案。
训练空间¶
与大多数构造性仿真(如 AFSIM 和 RAND 目标可达性模型)中智能体在现实世界仿真中交互不同,RL gym 中的智能体生活在一个 抽象训练空间(abstract training space) 中。这种抽象是理想的,因为它使分析人员能够使用同一个 RL gym 来训练几乎任何用途的智能体。同时,也需要考虑如何进行转化,以确保智能体在训练空间中学到的内容能有意义地迁移到主要构造性仿真中。
RL gym 中的智能体生活在一个抽象训练空间中,这是理想的,因为它使分析人员能够使用同一个 RL gym 来训练几乎任何用途的智能体。
在抽象 RL gym 空间中,智能体的主要动作是从区间 \([-1,1]\) 中选择一个数。这被解释为航向的变化——具体来说,是飞机在该时间步内可转向的最大角度的一个比例。例如,如果飞机在一个时间步内最多能转 10 度,那么 +1 表示向右转 10 度,-0.5 表示向左转 5 度,0 表示保持航向不变。
观测空间更复杂,原则上可以是任意大小,但在本例中,每个数值都被缩放到相同的 \([-1,1]\) 区间,并以单一数组形式呈现。此外,观测空间会持续更新,以飞机的坐标来表示仿真,因此不需要进一步转化。在此情境中,观测空间包括一组与仿真中各个感兴趣点相关的数值,描述了项目类别(威胁类型或目标)、机头偏角(相对于当前航向)、距离(相对于当前位置)、项目的威胁范围(若适用),以及可能与模型和智能体相关的其他因素(如频率)。
如果存在多个目标,且目标顺序无关紧要,或者智能体应当自主确定最佳攻击顺序,那么所有目标都可以包含在观测矩阵中,并在数组中加入一个额外项指示目标是否已被击中。如果目标顺序有要求,则可以在每个目标被击中后动态替换观测空间中的目标部分。如果飞机需要返回起点,可以在 IADS 外设定一个最终的人工目标,以诱导其撤离。
结论¶
RAND 研究人员已在 AFSIM 和 RAND 目标可达性模型中展示了 RL 挂接器的应用,并已通过空军研究实验室的 AFSIM 门户向所有授权用户提供该挂接器。RL 挂接器的架构使其适用于多种仿真,并且这一通用方法也可扩展至用其他语言构建的仿真。该方法为在现有和遗留构造性仿真中引入人工智能训练提供了一种高效有效的方式。
未来研究与发展¶
多样化场景的开发与分发。 美国空军部(Department of the Air Force, DAF)创建并共享的 AI 工具因包含广泛的情景片段(vignettes)而成倍增加其价值。开发并传播多样化且具有挑战性的场景不仅可以检验 AI 系统的鲁棒性,还能激发社区内部的创新。这一努力将增强研究成果的实际适用性,并确保开发的工具在各种真实场景中都具备多样性和有效性。
多智能体系统扩展。 在本报告探索的单一 IADS 突破者的基础上,自然的下一步是将工作扩展至完整打击群。这种向 多智能体系统(multiagent systems) 的扩展将允许对协同作战和争夺环境下的战略决策进行更复杂、更逼真的仿真。
推进空军部的社区中心化方法。 本研究推动了一种有前景的方式,使 DAF 能够与更广泛的社区共同构建并共享 AI 工具。通过促进一种社区中心化的模式,DAF 可以通过与学术界、工业界和盟军的合作,加速创新和技术采用。这一战略对于保持 DAF 的技术优势以及培育开放式创新生态系统至关重要。
¶
Notes¶
\({ }^{1}\) David Silver, Thomas Hubert, Julian Schrittwieser, Ioannis Antonoglou, Matthew Lai, Arthur Guez, Marc Lanctot, Laurent Sifre, Dharshan Kumaran, Thore Graepel, Timothy Lillicrap, Karen Simonyan, and Demis Hassabis, "A General Reinforcement Learning Algorithm That Masters Chess, Shogi, and Go Through Self-Play," Science, Vol. 362, No. 6419, December 7, 2018.
\({ }^{2}\) Christian D. Hubbs, Hector D. Perez, Owais Sarwar, Nikolaos V. Sahinidis, Ignacio E. Grossmann, and John M. Wassick, "OR-Gym: A Reinforcement Learning Library for Operations Research Problems," arXiv, arXiv:2008.06319, October 17, 2020.
\({ }^{3}\) AFSIM is based on Boeing's Analytic Framework for Network-Enabled Systems, which was built with internal funding from 2003 to 2014. The framework was delivered to the Air Force Research Laboratory in 2013 with "unlimited rights, including source code" and rebranded as AFSIM (J. Scott Thompson and Douglas D. Hodson, "AFSIM's Pseudo-Realtime Hybrid Simulation Software Design," Journal of Defense Modeling and Simulation, Vol. 19, No. 4, October 2022; Peter D. Clive, Jeffrey A. Johnson, Michael J. Moss, James M. Zeh, Brian M. Birkmire, and Douglas D. Hodson, "Advanced Framework for Simulation, Integration and Modeling [AFSIM]," International Conference of Scientific Computing, 2015, p. 73).
\({ }^{4}\) Li Ang Zhang, Jia Xu, Dara Gold, Jeff Hagen, Ajay K. Kochhar, Andrew J. Lohn, and Osonde A. Osoba, Air Dominance Through Machine Learning: A Preliminary Exploration of Artificial Intelligence-Assisted Mission Planning, RAND Corporation, RR-4311-RC, 2020. As of March 28, 2024: https://www.rand.org/pubs/research_reports/RR4311.html
\({ }^{5}\) Gary J. Briggs, AFSIM Reinforcement Learning Tool, RAND Corporation, 2022, Not available to the general public.
\({ }^{6}\) Python ctypes is function library built using datatypes that are compatible with C . Documentation for ctypes may be found within the Python Standard Library at Python Software Foundation, "ctypes-A Foreign Function Library for Python," webpage, undated. As of April 15, 2024: https://docs.python.org/3/library/ctypes.html
\({ }^{7}\) Timothy D. West and Brian Birkmire, "AFSIM: The Air Force Research Laboratory's Approach to Making M\&S Ubiquitous in the Weapon System Concept Development Process," Journal of the Cyber Security \& Information Systems Information Analysis Center, Vol. 7, No. 3, Winter 2020.
\({ }^{8}\) RAND researchers first developed the RL software harness for use in the RAND Target Accessibility Model. \({ }^{9}\) Keller Scholl, Gary J. Briggs, Li Ang Zhang, and John L. Salmon, Understanding the Limits of Artificial Intelligence for Warfighters: Volume 5, Mission Planning, RAND Corporation, RR-A1722-5, 2024. As of March 28, 2024: https://www.rand.org/pubs/research_reports/RRA1722-5.html
致谢¶
我们感谢项目联系人 Kathryn Sowers,以及行动主管 Julia Phillips 和 Gregory Cazzell,他们在选择应用案例、确定研究问题范围方面给予了指导,并与我们勤奋合作,帮助我们获得开展本系列报告中众多机器学习实验所需的数据。感谢 Li Ang Zhang 和 Lance Menthe 对于本研究最初开发工作的支持,以及在推动本报告完成过程中提供的鼓励和帮助。同时也要感谢以下人士:R. Scott Erwin 和 Jean-Charles Ledé,他们慷慨地帮助我们与空军研究实验室中众多人工智能(AI)研发工作建立联系;Lee Seversky 与我们分享了其在任务规划方面的专业知识;Kari K. Mott 中校与我们讨论了空中作战中心的自动化;Nicholas J. Harris 中校跨越十多个时区与我们沟通,向我们解释了主攻空袭计划(Master Air Attack Planning)流程。
我们也感谢许多 RAND 现任和前任同事,包括 Caolionn O'Connell、Sherrill Lingel、Osonde Osoba 和 Chris Pernin,帮助我们制定研究议程。感谢评审 James Williams 和 Jair Aguirre 的支持,没有他们,本报告将更薄弱且不够清晰。我们也感谢 RAND Project AIR FORCE 团队的全体成员的支持。没有他们的帮助,我们不可能完成这些报告;任何遗留的错误都完全由我们负责。
关于本报告¶
本报告是一个系列的一部分,该系列探讨如何将人工智能(Artificial Intelligence, AI)应用于辅助作战人员的四个不同领域:网络安全、预测性维护、兵棋推演以及任务规划。这些领域的选择旨在体现 AI 潜在用途的广泛性,并突出 AI 应用的不同限制。每个应用案例在单独的卷册中呈现,以便对应不同的受众群体。
本系列的第六份报告描述了 RAND 研究人员如何开发一种灵活的软件 harness(挂接器),使得许多现有的构造性仿真能够使用最先进的强化学习(Reinforcement Learning, RL)方法,而无需大量额外编码。RL 是一种强大的 AI 技术,可用于训练构造性仿真中的软件智能体,使其做出操作者期望的决策或表现得更逼真。本系列的第 1 卷总结了所有应用案例的研究发现与建议,其他卷册则提供了各个应用案例的详细分析:
- Lance Menthe, Li Ang Zhang, Edward Geist, Joshua Steier, Aaron B. Frank, Eric Van Hegewald, Gary J. Briggs, Keller Scholl, Yusuf Ashpari, 和 Anthony Jacques, Understanding the Limits of Artificial Intelligence for Warfighters: Vol. 1, Summary, RR-A1722-1, 2024
- Joshua Steier, Erik Van Hegewald, Anthony Jacques, Gavin S. Hartnett, 和 Lance Menthe, Understanding the Limits of Artificial Intelligence for Warfighters: Vol. 2, Distributional Shift in Cybersecurity Datasets, RR-A1722-2, 2024
- Li Ang Zhang, Yusuf Ashpari, 和 Anthony Jacques, Understanding the Limits of Artificial Intelligence for Warfighters: Vol. 3, Predictive Maintenance, RR-A1722-3, 2024
- Edward Geist, Aaron B. Frank, 和 Lance Menthe, Understanding the Limits of Artificial Intelligence for Warfighters: Vol. 4, Wargames, RR-A1722-4, 2024
- Keller Scholl, Gary J. Briggs, Li Ang Zhang, 和 John L. Salmon, Understanding the Limits of Artificial Intelligence for Warfighters: Vol. 5, Mission Planning, RR-A1722-5, 2024
本研究由 空军装备司令部(Air Force Materiel Command, AFMC)战略计划、方案、需求与评估局(A5/8/9) 委托,并作为 2022 财年的项目“Understanding the Bounds of Artificial Intelligence in Warface Applications”在 RAND Project AIR FORCE 的 部队现代化与作战运用计划(Force Modernization and Employment Program) 中开展。
RAND Project AIR FORCE¶
RAND Project AIR FORCE(PAF) 是 RAND 下属的一个部门,也是美国空军部(Department of the Air Force, DAF)的联邦资助研究与发展中心,负责研究与分析工作,为美国空军和美国太空军提供支持。PAF 为 DAF 提供关于政策选择的独立分析,这些选择涉及当前与未来空军、太空军和网络部队的发展、运用、战备和保障。研究分为四个项目:战略与学说;部队现代化与作战运用;资源管理;以及人力资源、发展与健康。本研究在合同 FA7014-22-D-0001 下完成。
© 2024 RAND Corporation
缩略语¶
| AFSIM | Advanced Framework for Simulation, Integration, and Modeling(先进仿真、集成与建模框架) |
|---|---|
| AI | artificial intelligence(人工智能) |
| API | application programming interface(应用程序接口) |
| DAF | Department of the Air Force(美国空军部) |
| DLL | dynamic link library(动态链接库) |
| IADS | integrated air defense system(综合防空系统) |
| RL | reinforcement learning(强化学习) |