10 测试与评估¶
人工智能(AI)具有独特的评估需求,尤其是在任务执行过程中需要持续学习的情况下。本章描述了如何对系统性能进行测试与评估,以确保客户和最终用户即使在遭遇意外情况时也能信任该系统。本章回答了“如何测试一个会变化的系统”这一问题。测试与评估的关键步骤包括:
- 明确与任务和最终用户相关的性能度量指标(Metrics of Performance, MOPs)和成功度量指标(Metrics of Success, MOS)(参见第2.3节和Callout 10.2)。
- 采用闭环交互式测试框架(第10.1节)。
- 通过消融试验(ablation trials)证明系统在先前未知环境中仍能正常工作(第10.2节)。
- 计算分类、回归和策略选择的准确性(第10.3节)。
- 运用学习保障(learning assurance)流程对结果进行形式化和实证验证(第10.4节)。
评估的目标在于确定应给予AI多大程度的信任。简而言之,在任务背景下,该模型是否有用?是否能做出有效决策?你是否足够信任该AI,从而依靠它来报告观测结果?操控平台飞行?锁定敌方目标?抑或学习交战规则(rules of engagement)?
信任是风险的函数:信任方所承担的风险越大,赋予AI的权限越高,则所需的验证与保障(validation and assurance)要求就越高。
信任必须以安全性(safety)和安保性(security)[1]为基础,且信任程度取决于信任方所能容忍的风险水平,如图10.1所示。信任程度决定了他们将授予AI的权限大小。
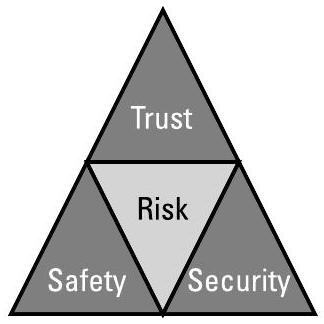
图10.1 信任取决于安全性与安保性,并取决于可接受的风险水平。
10.1 场景驱动器(Scenario Driver)¶
机器学习(ML)系统通常使用静态数据集来学习如何对目标进行分类。然而,在电子战(Electronic Warfare, EW)领域,这种方法是不够的,因为它无法体现系统如何处理新样本、如何应对动态环境,以及如何在对抗敌方时运行。在电子战中,环境会对系统的每一个动作做出响应。
要验证认知决策引擎(cognitive-decision engine),闭环测试框架(closed-loop testing framework)至关重要。
图10.2展示了场景驱动器(Scenario Driver, SD)的结构,该驱动器与认知引擎交互,并对刺激做出适当响应。
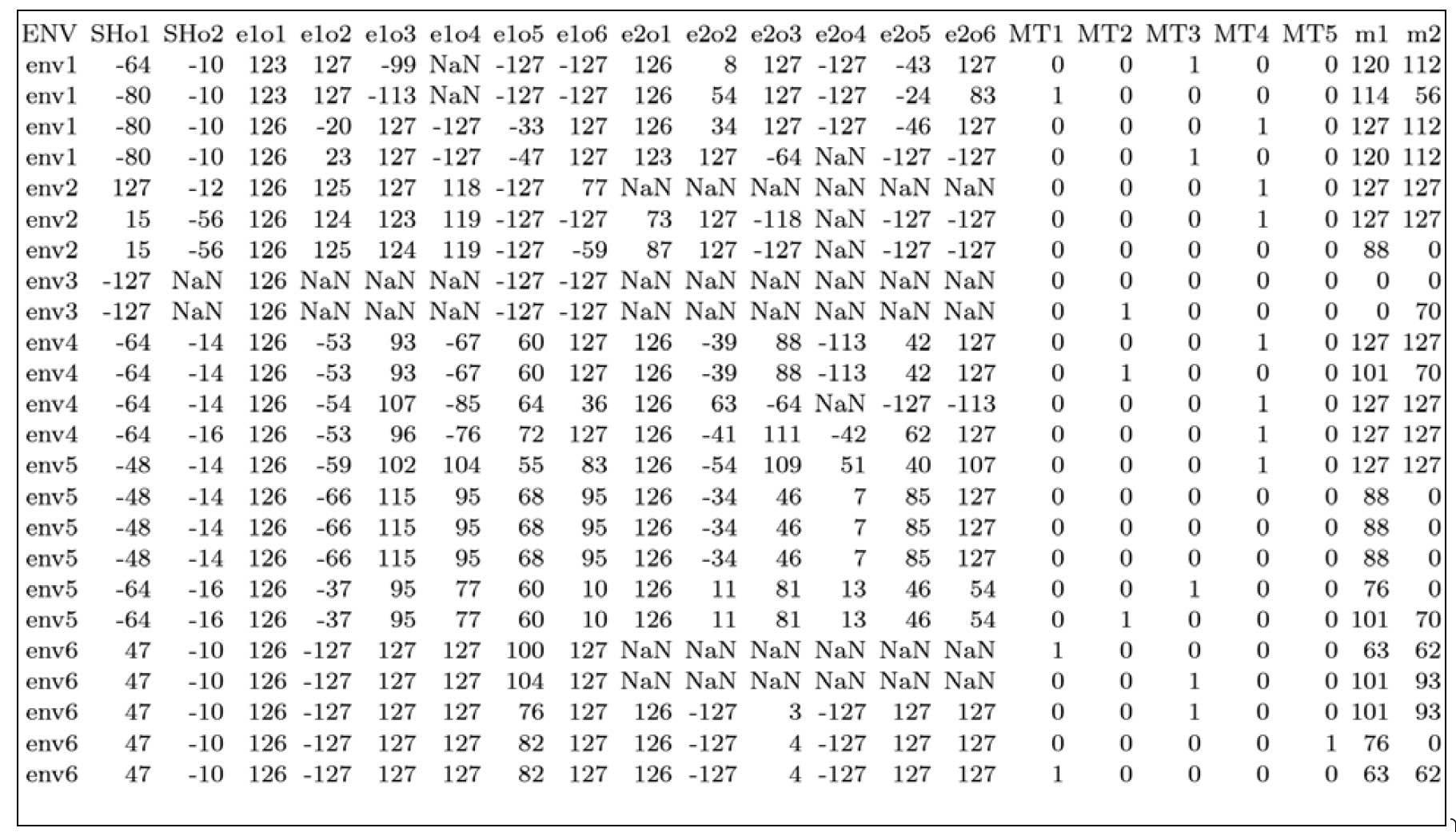
真实数据文件(Ground-Truth Data File, GTDF)包含所有已知数据,无论其生成方式如何;表10.1展示了一个来自真实通信电子防护(Electronic Protection, EP)系统的示例。根据AI模块的需求,GTDF可能包含原始I/Q采样数据、脉冲描述字(Pulse Descriptor Words, PDWs)或推断出的特征。GTDF涵盖所有已知真实条件的任务场景,包括任务、节点(友方、中立方和敌方)以及配置的所有组合。
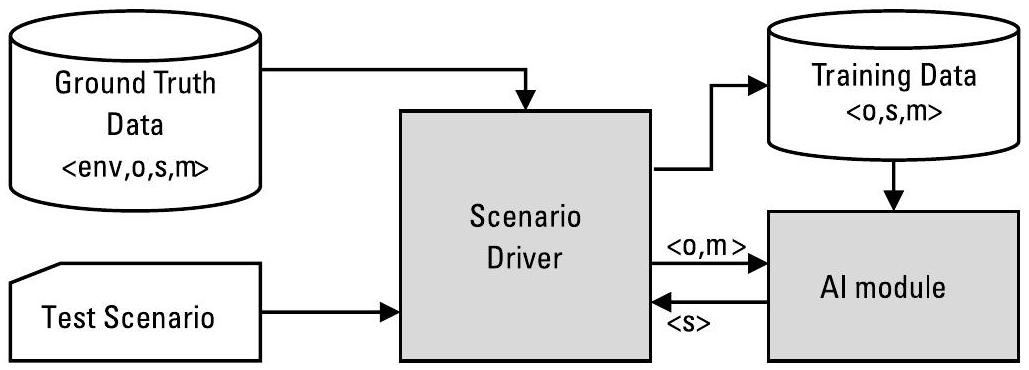
图10.2 闭环场景驱动器确保认知决策引擎能对刺激做出正确响应:将可观测量(observables)\(o\) 和度量指标(metrics)\(m\) 发送给AI模块,后者据此计算出策略(strategy)\(s\)。
表10.1 包含所有已知数据(仿真、模拟或真实世界)的真实数据文件(Ground-Truth Data File, GTDF)
| ENV | SHo1 | SHo2 | elol | e1o2 | elo3 | elo4 | elo5 | elo6 | e201 | e2o2 | e2o3 | e204 | e205 | e206 | MT1 | MT2 | MT3 | MT4 | MT5 | m1 | m2 |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| env1 | -64 | -10 | 123 | 127 | -99 | NaN | -127 | -127 | 126 | 8 | 127 | -127 | -43 | 127 | 0 | 0 | 1 | 0 | 0 | 120 | 112 |
| env1 | -80 | -10 | 123 | 127 | -113 | NaN | -127 | -127 | 126 | 54 | 127 | -127 | -24 | 83 | 1 | 0 | 0 | 0 | 0 | 114 | 56 |
| env1 | -80 | -10 | 126 | -20 | 127 | -127 | -33 | 127 | 126 | 34 | 127 | -127 | -46 | 127 | 0 | 0 | 0 | 1 | 0 | 127 | 112 |
| env1 | -80 | -10 | 126 | 23 | 127 | -127 | -47 | 127 | 123 | 127 | -64 | NaN | -127 | -127 | 0 | 0 | 1 | 0 | 0 | 120 | 112 |
| env2 | 127 | -12 | 126 | 125 | 127 | 118 | -127 | 77 | NaN | NaN | NaN | NaN | NaN | NaN | 0 | 0 | 0 | 1 | 0 | 127 | 127 |
| env2 | 15 | -56 | 126 | 124 | 123 | 119 | -127 | -127 | 73 | 127 | -118 | NaN | -127 | -127 | 0 | 0 | 0 | 1 | 0 | 127 | 127 |
| env2 | 15 | -56 | 126 | 125 | 124 | 119 | -127 | -59 | 87 | 127 | -127 | NaN | -127 | -127 | 0 | 0 | 0 | 0 | 0 | 88 | 0 |
| env3 | -127 | NaN | 126 | NaN | NaN | NaN | -127 | -127 | NaN | NaN | NaN | NaN | NaN | NaN | 0 | 0 | 0 | 0 | 0 | 0 | 0 |
| env3 | -127 | NaN | 126 | NaN | NaN | NaN | -127 | -127 | NaN | NaN | NaN | NaN | NaN | NaN | 0 | 1 | 0 | 0 | 0 | 0 | 70 |
| env4 | -64 | -14 | 126 | -53 | 93 | -67 | 60 | 127 | 126 | -39 | 88 | -113 | 42 | 127 | 0 | 0 | 0 | 1 | 0 | 127 | 127 |
| env4 | -64 | -14 | 126 | -53 | 93 | -67 | 60 | 127 | 126 | -39 | 88 | -113 | 42 | 127 | 0 | 1 | 0 | 0 | 0 | 101 | 70 |
| env4 | -64 | -14 | 126 | -54 | 107 | -85 | 64 | 36 | 126 | 63 | -64 | NaN | -127 | -113 | 0 | 0 | 0 | 1 | 0 | 127 | 127 |
| env4 | -64 | -16 | 126 | -53 | 96 | -76 | 72 | 127 | 126 | -41 | 111 | -42 | 62 | 127 | 0 | 0 | 0 | 1 | 0 | 127 | 127 |
| env5 | -48 | -14 | 126 | -59 | 102 | 104 | 55 | 83 | 126 | -54 | 109 | 51 | 40 | 107 | 0 | 0 | 0 | 1 | 0 | 127 | 127 |
| env5 | -48 | -14 | 126 | -66 | 115 | 95 | 68 | 95 | 126 | -34 | 46 | 7 | 85 | 127 | 0 | 0 | 0 | 0 | 0 | 88 | 0 |
| env5 | -48 | -14 | 126 | -66 | 115 | 95 | 68 | 95 | 126 | -34 | 46 | 7 | 85 | 127 | 0 | 0 | 0 | 0 | 0 | 88 | 0 |
| env5 | -48 | -14 | 126 | -66 | 115 | 95 | 68 | 95 | 126 | -34 | 46 | 7 | 85 | 127 | 0 | 0 | 0 | 0 | 0 | 88 | 0 |
| env5 | -64 | -16 | 126 | -37 | 95 | 77 | 60 | 10 | 126 | 11 | 81 | 13 | 46 | 54 | 0 | 0 | 1 | 0 | 0 | 76 | 0 |
| env5 | -64 | -16 | 126 | -37 | 95 | 77 | 60 | 10 | 126 | 11 | 81 | 13 | 46 | 54 | 0 | 1 | 0 | 0 | 0 | 101 | 70 |
| env6 | 47 | -10 | 126 | -127 | 127 | 127 | 100 | 127 | NaN | NaN | NaN | NaN | NaN | NaN | 1 | 0 | 0 | 0 | 0 | 63 | 62 |
| env6 | 47 | -10 | 126 | -127 | 127 | 127 | 104 | 127 | NaN | NaN | NaN | NaN | NaN | NaN | 0 | 0 | 1 | 0 | 0 | 101 | 93 |
| env6 | 47 | -10 | 126 | -127 | 127 | 127 | 76 | 127 | 126 | -127 | 3 | -127 | 127 | 127 | 0 | 0 | 1 | 0 | 0 | 101 | 93 |
| env6 | 47 | -10 | 126 | -127 | 127 | 127 | 82 | 127 | 126 | -127 | 4 | -127 | 127 | 127 | 0 | 0 | 0 | 0 | 1 | 76 | 0 |
| env6 | 47 | -10 | 126 | -127 | 127 | 127 | 82 | 127 | 126 | -127 | 4 | -127 | 127 | 127 | 1 | 0 | 0 | 0 | 0 | 63 | 62 |
该数据集已归一化为int8格式,表示以下推断特征:(a) 两个描述整个射频(RF)频谱的共享可观测量(shared observables);(b) 两个辐射源(emitter)各自对应的六个可观测量;(c) 五种可组合的电子战技术(techniques);(d) 两个度量指标(metrics)。
射频(Radio Frequency, RF)环境是多种测试场景条件之一。在最简单的情况下,它可能是在晴好天气和低通信流量条件下的无干扰通信环境。其他环境则可能引入移动性、干扰机(jammers)、气象条件和地形等因素。在受控实验中,每种环境都会被标记其已知的环境类型,并记录在真实数据文件(Ground-Truth Data File, GTDF)中。
如果数据以逗号分隔值(Comma-Separated Value, CSV)文件形式记录,则每一行对应一个可观测量(observables)、可控量(controllables)和度量指标(metrics)的样本 \(\langle o, s, m\rangle\),用于描述所选策略 \(s\) 在针对节点 \(n\) 的特定环境中的表现。其中,可观测量对应于对该环境的一次单一观测。
理论上,GTDF 可能对每个测试的射频环境包含大量行数据,并且列数可能呈指数级增长(甚至无限),以对应所有可能的策略。但在实践中,一个规模较小但多样性高且稀疏的数据集更具价值(参见第8.3.2节)。随着任务的推进,系统会持续收集数据、积累经验并更新该表格。一种典型做法是:针对每个独立的可控量分别采集数据(即在其他可控量设为默认值的情况下,仅改变一个可控量),并额外采集若干对可控量组合的数据(例如表7.1所示)。
测试场景(test scenario)定义了哪些环境用作训练数据,哪些用作测试数据。场景驱动器(Scenario Driver, SD)会从GTDF中选取与训练环境匹配的样本,并生成一个训练数据文件,供AI模块在任务前(premission)使用(图9.5展示了BBN SO的任务前步骤)。闭环测试包含以下步骤:
- SD 生成测试数据的一个观测样本(包括可观测量 \(o\) 和度量指标 \(m\));
- AI 选择一个策略(或对信号进行特征识别等操作),并将结果返回给SD;
- SD 评估该策略,并在下一次迭代中计算度量指标 \(m\) 以及根据第10.3.3节所述方法计算最优性能。
场景驱动器(Scenario Driver, SD)会播放与AI所做决策适当交互的序列。例如,利用图10.3所示的简单状态机:如果AI观测到请求发送(Request-to-Send, RTS)信号,并成功选择了一种干扰技术以阻断清除发送(Clear-to-Send, CTS)信号,那么SD将重放另一个RTS;如果AI未选择对CTS进行干扰,则SD将开始发送数据。在雷达领域,这些标签可能对应不同的雷达工作模式(radar modes)。图中每条弧线表示触发状态转换的条件。
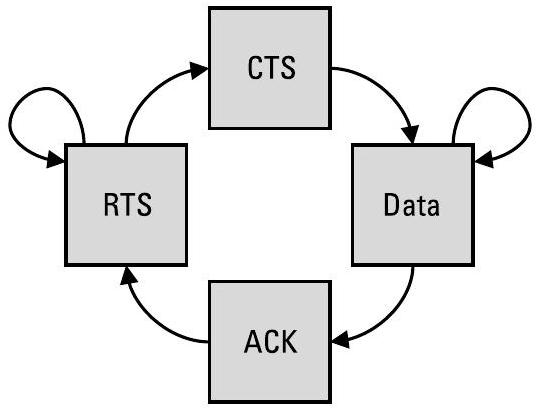
图10.3 SD可使用此类简单通信序列的状态机,从GTDF中重放数据。GTDF中的“环境(environments)”对应于RTS、CTS、Data和ACK等标签。
对于开集分类(open-set classification)(参见第3.4节),这种交互过程可用于评估系统在正确识别一个新类别之前需要多少个新样本;对于消融试验(ablation trials)(参见第10.2节),则用于评估系统学习应对新射频(RF)环境的速度。
应将SD设计为能够使用任意底层状态机重放任意类型的数据。这种方法支持对多个AI模块进行测试,例如:一个生成I/Q采样数据以测试信号解交织器(deinterleaver)的模块,一个生成脉冲描述字(Pulse Descriptor Words, PDWs)以测试分类器(classifier)的模块,以及一个结合状态机生成PDWs以测试电子对抗措施(Electronic Countermeasures, ECM)选择的模块。
由于系统需求文档通常对学习能力的描述不够明确,因此尽早确定需要测试的场景至关重要。
不可能通过无限(\(\infty\))种场景来测试无限(\(\infty\))种配置。应识别图1.3所示三个维度中哪些与系统性能和客户需求相关,并在每个维度上选取多个测试点进行验证。此外,尽管存在组合爆炸问题,但电子战(Electronic Warfare, EW)交战过程受到物理规律以及信息获取/拒止所驱动的交战状态演进的约束,这有助于聚焦和精简测试需求。
图10.4展示了一个用于开发和测试多个AI模块的概念性架构。场景驱动器(Scenario Driver, SD)生成的数据格式与实际部署系统中接收到的数据格式一致。在对整个处理序列进行测试之前,每个模块都应独立完成单元测试(unit test)。当将模块集成到序列中时,应将其余模块替换为“全知”(omniscient)组件——即始终正确的组件。(例如,为测试态势感知(Situation Awareness, SA)模块,决策管理(Decision Management, DM)模块可简化为一组人工编写的规则,而毁伤效果评估(Battle Damage Assessment, BDA)模块则精确知晓所选电子对抗措施(Electronic Countermeasures, ECM)的实际效果。)对BDA和SA模块的评估应采用加权准确率(weighted accuracy)(参见第10.3.1节或第10.3.2.3节),而对DM模块的评估则采用充分性(adequacy)指标(参见第10.3.3.1节)。
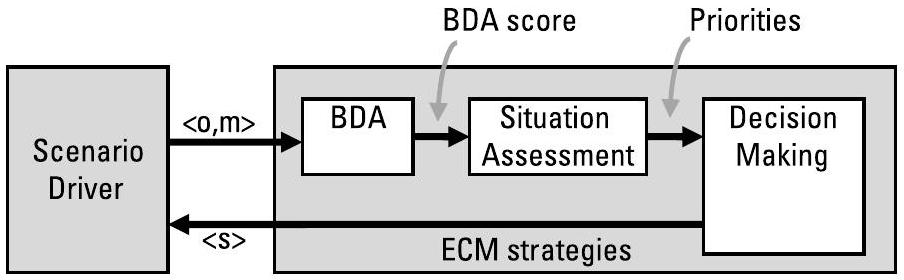
图10.4 场景驱动器(SD)可用于驱动多个AI模块的测试。
10.2 消融测试(Ablation Testing)¶
“n选k”(\(n\)-choose-\(k\))消融测试用于证明认知系统具备学习应对新环境的能力。消融试验(ablation trial)用于检验给定的训练样本对模型泛化能力的贡献程度。\({}^1\) 真实数据(ground truth data)包含 \(n\) 个已知场景;我们在其中 \(k \subseteq n\) 个场景上训练系统,并在全部 \(n\) 个场景上进行测试,遍历所有可能的 \(k\) 值及所有 \(\binom{n}{k}\) 个子集。因此,在测试阶段,有 \(n - k\) 个环境是系统未曾见过的新环境。对于场景驱动器(Scenario Driver, SD)已知的 \(n = 3\) 个环境,共需进行八次消融测试:
- \(k=0\):SD 创建一个测试场景 \(\binom{3}{0}\)。AI 未获得任何先验训练数据;测试时,全部 \(n=3\) 个环境均为新环境。
- \(k=1\):SD 创建三个测试场景 \(\binom{3}{1}\)。每个场景中,AI 在一个环境上训练;测试时,1个环境已知,2个为新环境。
- \(k=2\):SD 创建三个测试场景 \(\binom{3}{2}\)。每个场景中,AI 在两个环境上训练;测试时,2个环境已知,1个为新环境。
- \(k=3\):SD 创建一个测试场景 \(\binom{3}{3}\)。AI 在全部三个环境上训练;测试时,仅环境出现的顺序未知。
\({}^1\) 传统意义上的消融研究(ablation studies)通过移除系统组件来理解该组件对整体性能的贡献;此类研究要求系统在组件被移除时表现出“优雅降级”(graceful degradation)特性 [2]。
消融测试类似于“留一法”(leave-one-out)测试——后者在 \(n-1\) 个样本上训练,并在剩余的1个样本上测试。同样地,\(k\) 折交叉验证(\(k\)-fold cross-validation)会训练 \(k\) 个模型,每个模型在数据的 \(1/k\) 部分上进行测试。其核心思想是证明:无论初始训练数据如何,系统都能学会处理新环境。
图10.5展示了在开发BBN认知引擎(BBN SO)(参见例7.1 [3])过程中收集的 \(n\)-choose-\(k\) 测试结果。针对 \(n=9\) 个环境中的每一个,SD 在所有可能的子集 \(k \subseteq n\) 上训练SO,并在全部九个环境上进行测试。该图表共包含512次独立测试,涵盖从 \(k=0\)(无任何先验训练数据)到 \(k=9\)(在全部 \(n=9\) 个环境上训练,但测试时SO不知道环境出现顺序)的各种情况。

图10.5 BBN认知引擎(BBN SO)的 \(n\)-choose-\(k\) 消融试验表明:随着SO先验训练数据中包含的环境条件减少,其性能呈现优雅降级(graceful degradation)。图中每个数据点对应一次实验的充分性(adequacy)结果(例如图10.8所示);横轴 \(x\) 表示 \(k\),即训练数据集中包含的环境条件数量;纵轴 \(y\) 表示根据第10.3.3.1节计算的充分性值。括号中的“(x)”数值表示针对9选k(9-choose-k)所执行的实验次数。(参见例7.1,[3])
即使在极端情况下——SO未获得任何先验训练数据——它仍可通过任务中学习(in-mission learning)达到最优性能的 \(70\%\)。
图10.8和图10.9分别展示了单个测试场景,各自对应图10.5中的一个数据点,并突出说明:任务中学习仅需一到两个样本即可学会如何应对一个全新环境。当训练数据约为完整数据集的 \(30\%\) 时,SO在最佳情况下可达到 \(98\%\) 的充分性;而在最差情况下,仍能达到 \(78\%\) 的充分性。
这一差异源于训练数据的多样性:即在大小为 \(k\) 的训练集中使用了哪些环境。最差情况使用了三个高度相似的环境,而最佳情况则使用了三个差异显著的环境。第2.1.1节描述了如何计算环境相似性:通过对射频(RF)环境进行无监督聚类(unsupervised clustering),并用树状图(dendrogram)进行可视化。该树状图基于 \(n\) 个已知环境的可观测量(observables)构建,而具体测试场景则决定从中选择哪些环境用于训练和测试。
由于该聚类方法是无监督的(unsupervised),电子战(EW)决策者可利用此聚类结果及其对应的树状图(dendrogram)来驱动主动学习(active learning)(参见第7.3节)。
场景驱动器(Scenario Driver, SD)也可利用该聚类结果来评估系统相对于最优性能的表现(参见第10.3.3.1节);各聚类根据真实标签(ground-truth labels)命名。以图2.3为例,一个有效的测试方法是:在顶部聚类中的15个环境(垂直方向编号16至23)上训练模型,然后在底部聚类的8个环境(编号22至08)上进行测试,以此检验系统在面对差异极大的数据时的表现。
再次参考图10.5,最佳情况可能对应三个差异显著的环境——16、23和22——因为模型能有效泛化到其余20个环境中;而最差情况可能对应三个高度相似的环境——22、02和07——导致系统需要更长时间才能学会应对新情境,从而获得较低的充分性(adequacy)评分。
在算法4.1的第4步(“对新雷达进行分类”)中,被测AI系统并不知晓真实环境标签,但SD仍能正确评估一个开集分类器(open-set classifier)的性能。该分类器的评分取决于所涉及的具体环境。例如,将环境05和06视为同一类可能是可接受的,特别是当这些环境代表干扰机(jammers),且所选的对抗措施(mitigation techniques)在两者上表现相同时。同样,当一个新发射机与已知样本差异显著时,开集分类器应能比仅存在细微差异时更快地识别出该新类别。
消融测试(Ablation tests)通过实证表明:认知系统能够从其经验中学习,并泛化以应对全新环境。
10.3 准确性计算(Computing Accuracy)¶
电子战(Electronic Warfare, EW)系统同时采用回归(regression)和分类(classification)两种学习方法。
回归模型用于预测数值型输出[即 \(y = f(x)\),其中 \(y \in \mathbb{R}\)]。回归模型的准确性通过归一化均方根误差(Normalized Root-Mean-Squared Error, RMSE)进行评估(参见第10.3.1节)。
分类模型用于为输入分配离散类别标签[即 \(y = f(x)\),其中 \(y \in S\),\(S\) 为一个离散类别集合]。分类模型的性能通过混淆矩阵(confusion matrices)及相关统计指标进行评估(参见第10.3.2节)。
在电子战中,我们还需考虑这样的情形:多种电子防护(Electronic Protection, EP)/电子攻击(Electronic Attack, EA)策略在不同射频(RF)环境下产生不同的性能表现。例如,多种EP策略可能对同一类干扰机(jammer)提供防护,但其有效性各不相同。此类模型采用一种改进的混淆矩阵进行评估(参见第10.3.3节)。
10.3.1 回归与归一化均方根误差(Regression and Normalized Root-Mean-Square Error)¶
回归算法通常使用均方根误差(Root-Mean-Square Error, RMSE)进行评估,RMSE 是观测值 \(\hat{y}\) 与估计值 \(y\) 之间平方差的平均值的平方根。归一化均方根误差(Normalized RMSE, nRMSE)使得来自不同数据分布的结果能够被公平比较。nRMSE 定义为 RMSE 除以观测值的标准差 \(\sigma\)。对于 \(v\) 个样本,其均值为 \(\mu = \frac{1}{v} \left( \sum_{i=1}^{v} \hat{y}_{i} \right)\),则:
标准差 \(\sigma\) 代表一种“基准学习器”的性能——该学习器对所有样本均以均值 \(\mu\) 作为预测值。我们的目标是尽可能降低 nRMSE:
- nRMSE = 0.0 表示所有样本的预测均无误差;
- nRMSE > 1.0 则表明无需使用复杂的模型,因为直接使用均值作为预测反而效果更好。
图10.6展示了一个简单示例,用于比较两个度量指标下不同模型的性能。
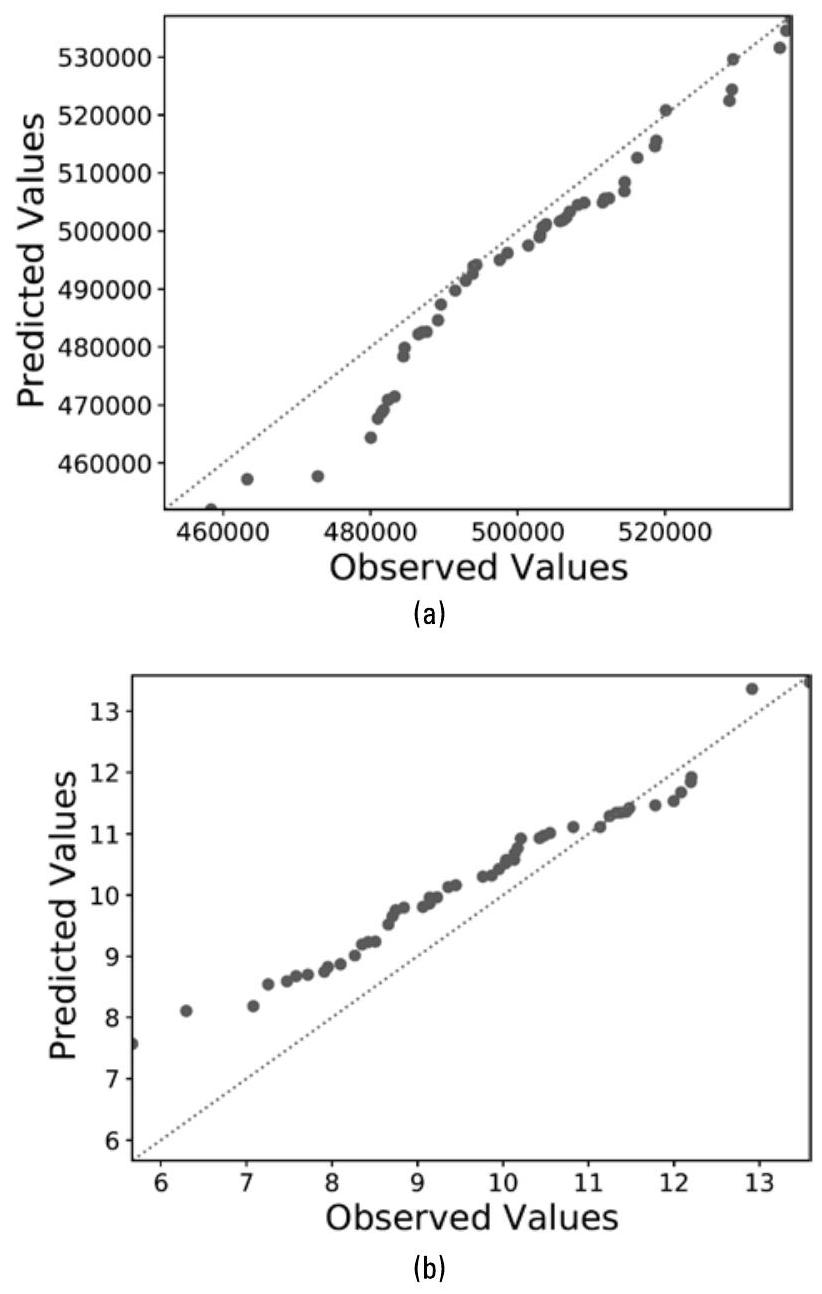
图10.6 为比较预测值范围不同的模型,必须将 RMSE 除以标准差进行归一化。(a)度量指标 \(m_{1}\) 的取值范围为 458,365 至 537,068,均值 \(\mu = 501,041\),标准差 \(\sigma = 18,061\);RMSE 为 6,328,对应 nRMSE 为 0.350。(b)度量指标 \(m_{2}\) 的取值范围为 5.7 至 13.6,均值 \(\mu = 9.7\),标准差 \(\sigma = 1.7\);RMSE 为 0.76,对应 nRMSE 为 0.442。(当所有预测值与真实值完全一致并落在灰色对角线上时,nRMSE = 0.0。)
较高的 nRMSE 表明模型难以准确拟合性能曲面(performance surface)。这一结果可帮助系统工程师识别和诊断系统性问题,例如缺失的可观测量(missing observables)、传感器故障(faulty sensors)、度量指标不可靠(unreliable metrics)或时间延迟(temporal latencies)等。
10.3.2 分类与混淆矩阵(Classification and Confusion Matrices)¶
分类算法通常通过混淆矩阵(confusion matrices)计算准确率(accuracy)进行评估,其结构如表10.2所示。矩阵的行对应已知的真实类别(observed classes),列对应模型预测的类别(predicted classes)。
- 真正例(True Positive, TP) 和 真负例(True Negative, TN) 表示模型预测正确;
- 假正例(False Positive, FP) 和 假负例(False Negative, FN) 表示模型预测错误。
表10.3展示了针对声学信号类别“生物源”(biological)与“人工源”(man-made)的一组假设性结果;该假设分类器的准确率为 \(94.5\%\),但倾向于将目标判为“人工源”。该混淆矩阵中的每个单元格统计了两类中每种类型样本的数量。
根据具体任务,假负例和假正例可能带来不同严重程度的后果。例如,若机场行李安检中的爆炸物探测器将非爆炸物误判为爆炸物(假正例),只会导致额外的筛查时间;但若探测器漏检了真实爆炸物(假负例),则可能导致人员伤亡。
表10.2 混淆矩阵:展示分类算法如何识别目标
| 预测为 正类(Predicted Positive) |
预测为 负类(Predicted Negative) |
|
|---|---|---|
| 观测为 正类(Observed Positive) |
真正例(True positive) | 假负例(False negative) |
| 观测为 负类(Observed Negative) |
假正例(False positive) | 真负例(True negative) |
表10.3 声学信号类别“生物源”与“人工源”的假设性分类结果
| 生物源(Bio) | 人工源(Man-made) | |
|---|---|---|
| 生物源 | 90 | 10 |
| 人工源 | 1 | 99 |
10.3.2.1 准确率、精确率、召回率与类别不平衡(Accuracy, Precision, Recall, and Class Imbalance)¶
混淆矩阵的准确率(Accuracy) 定义为对角线元素之和除以测试样本总数。对于一个记录 \(x\) 个类别标签的混淆矩阵 \(\mathcal{M}\)(\(\mathcal{M} \in \mathbb{N}^{x \times x}\)),其准确率计算公式为:
然而,当数据集存在类别不平衡(class imbalance) 时(例如,人工源目标远少于生物源目标),准确率可能产生误导。此时可采用平衡准确率(Balanced Accuracy),该指标通过对每个类别的预测结果按该类样本数量进行归一化来消除不平衡影响:
召回率(Recall) 衡量某一类别中被正确识别的样本比例,通过将对角线元素 \(\mathcal{M}_{i,i}\) 除以第 \(i\) 行总和计算得出:
精确率(Precision) 衡量模型对某一类别的预测有多“精准”,即预测为该类的样本中有多少确实是该类,通过将对角线元素 \(\mathcal{M}_{j,j}\) 除以第 \(j\) 列总和计算得出:
10.3.2.2 多类别情况(Multiple Classes)¶
当类别数量超过两类时,我们期望混淆矩阵的对角线上出现较高的匹配计数;非对角线元素则表示分类错误。通常,矩阵的行和列会按照某种相似性度量进行排序,以便更清晰地识别(甚至在某些情况下可忽略)相似类别之间的误分类。例如,在调制方式分类评估中,我们预期16-QAM(QAM16)和64-QAM(QAM64)会相邻排列,因为它们之间的误分类并不意外。
在图10.7所示的特定辐射源识别(Specific Emitter Identification, SEI)示例中,每一对行/列对应安装在同一无线电平台上的两个发射机,它们共用一个电源。因此,对角线周围每个由四个单元格组成的“块”内部发生的误分类,相较于其他位置的误分类,“错误程度”更低——因为这些发射机在物理特性上高度相似。
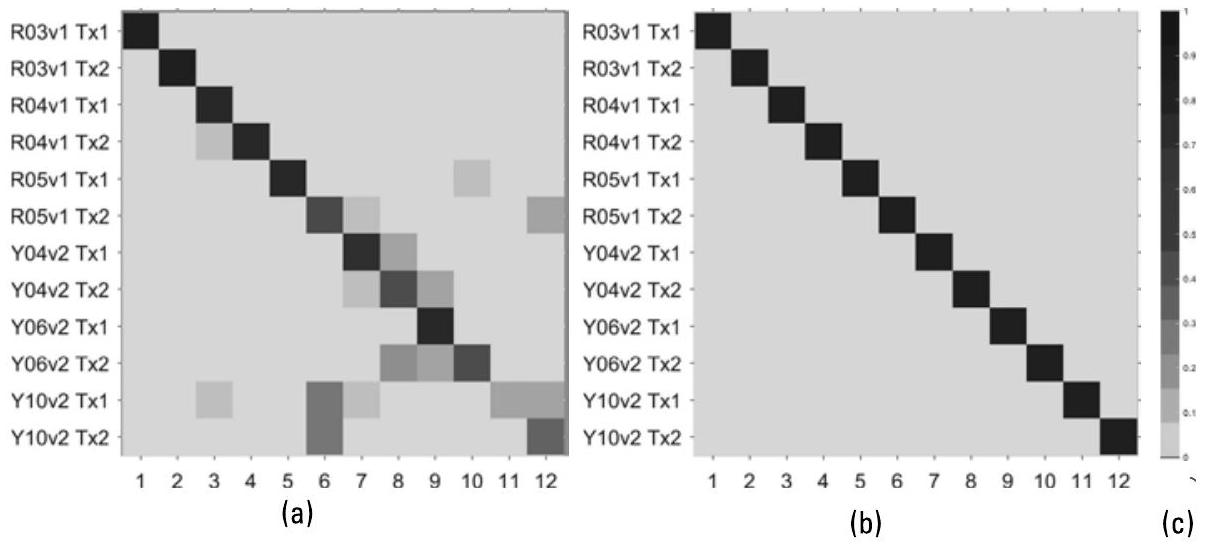
图10.7 这些混淆矩阵展示了使用两种不同分类算法对特定辐射源识别(SEI)任务的标签结果 [4]。(a)DeepNets 算法达到了 \(71.9\%\) 的准确率;(b)一种多阶段训练算法(multistage training algorithm)达到了 \(98.7\%\) 的准确率。
10.3.2.3 加权准确率与模型质量(Weighted Accuracy and Model Quality)¶
当不同类别的分类结果所对应的奖励(reward)不同时,我们可通过引入一个奖励矩阵(reward matrix)\(\mathcal{R} \in \mathbb{R}^{x \times x}\)(其中 \(0 \leq \mathcal{R}_{i, j} \leq 1\))对准确率评估进行加权。此时,将混淆矩阵 \(\mathcal{M}\) 与奖励矩阵 \(\mathcal{R}\) 逐元素相乘,得到加权准确率矩阵(weighted accuracy matrix)\(\mathcal{Q} \in \mathbb{R}^{x \times x}\):即 \(\mathcal{M}\) 中每个单元格 \((i, j)\) 的值乘以其在 \(\mathcal{R}\) 中对应位置的奖励权重:
模型的总体质量(Quality)计算为加权后总得分占标签总数的百分比(即加权标签质量除以标签总数):
举例说明:表10.4展示了一个针对六类雷达(两个雷达平台,每个平台具有三种工作模式)的假设性奖励矩阵。对角线单元格表示模型同时正确识别了雷达平台及其工作模式的情形。若仅正确识别了雷达平台(但模式错误)或仅正确识别了工作模式(但雷达平台错误),则视为部分正确,并赋予相应的中间奖励值。
利用该奖励权重矩阵 \(\mathcal{R}\) 对表10.5中的分类结果 \(\mathcal{M}\) 进行加权,即可得到表10.6所示的质量矩阵 \(\mathcal{Q}\)。最终计算得出的总体模型质量为 \(90\%\)。
表10.4 假设性雷达奖励矩阵 \(\mathcal{R}\)
| R1M1 | R1M2 | R1M3 | R2M1 | R2M2 | R2M3 | |
|---|---|---|---|---|---|---|
| Radar 1, Mode 1 | 1.0 | 0.5 | 0.5 | 0.3 | – | – |
| Radar 1, Mode 2 | 0.5 | 1.0 | 0.5 | – | 0.3 | – |
| Radar 1, Mode 3 | 0.5 | 0.5 | 1.0 | – | – | 0.3 |
| Radar 2, Mode 1 | 0.3 | – | – | 1.0 | 0.5 | 0.5 |
| Radar 2, Mode 2 | – | 0.3 | – | 0.5 | 1.0 | 0.5 |
| Radar 2, Mode 3 | – | – | 0.3 | 0.5 | 0.5 | 1.0 |
注:表中“–”表示该组合在任务设定中不适用或奖励为0。
表10.5 假设模型对雷达及其工作模式的分类结果,对应混淆矩阵 \(\mathcal{M}\),准确率为 \(85\%\)
| R1M1 | R1M2 | R1M3 | R2M1 | R2M2 | R2M3 | Recall | |
|---|---|---|---|---|---|---|---|
| Radar 1, Mode 1 | 10 | – | – | 2 | – | – | 83% |
| Radar 1, Mode 2 | 1 | 11 | – | – | – | – | 92% |
| Radar 1, Mode 3 | – | 1 | 5 | – | 1 | 5 | 42% |
| Radar 2, Mode 1 | – | – | – | 11 | – | – | 100% |
| Radar 2, Mode 2 | – | – | – | 1 | 12 | – | 92% |
| Radar 2, Mode 3 | – | – | – | – | – | 12 | 100% |
| Precision | 91% | 92% | 100% | 79% | 92% | 71% |
表10.6 将表10.5中的混淆矩阵 \(\mathcal{M}\) 与表10.4中的奖励权重 \(\mathcal{R}\) 相乘,得到质量矩阵 \(\mathcal{Q}\),总体质量得分为 \(90\%\)
| R1M1 | R1M2 | R1M3 | R2M1 | R2M2 | R2M3 | |
|---|---|---|---|---|---|---|
| Radar 1, Mode 1 | 10 | – | – | 0.6 | – | – |
| Radar 1, Mode 2 | 0.5 | 11 | – | – | – | 1.5 |
| Radar 1, Mode 3 | – | 0.5 | 5 | – | 0 | – |
| Radar 2, Mode 1 | – | – | – | 11 | – | – |
| Radar 2, Mode 2 | – | – | – | 0.5 | 12 | – |
| Radar 2, Mode 3 | – | – | – | – | – | 12 |
注:表中数值为 \(\mathcal{Q}_{i,j} = \mathcal{M}_{i,j} \times \mathcal{R}_{i,j}\)。例如,Radar 1 Mode 1 被误判为 R2M1 的样本数为2,对应奖励为0.3,故贡献为 \(2 \times 0.3 = 0.6\);Radar 1 Mode 2 被误判为 R1M1 的样本数为1,奖励为0.5,故贡献为 \(1 \times 0.5 = 0.5\),依此类推。
10.3.3 策略性能评估(Evaluating Strategy Performance)¶
要评估策略对系统性能的影响,无论是归一化均方根误差(nRMSE)还是混淆矩阵,都无法捕捉一个核心概念:
对于给定的射频(RF)环境,可能存在多个策略均能产生非零效用(nonzero utility),从而对系统性能做出贡献。
为此,我们采用一种改进的混淆矩阵来衡量策略在不同环境下的性能表现。不同于传统以“环境 vs. 环境”构建的混淆矩阵,此处使用“环境 vs. 策略”(environments by strategies)的结构。
态势判别器(Situation Discriminator, SD)为每个度量指标 \(m_k\) 维护一个性能表 \(\mathcal{P}^{m_k} \in \mathbb{J}^{a \times b}\),其中 \(\mathbb{J}\) 为正整数集合,\(a \ll \overline{o_n}\) 表示环境(environment)的数量,\(b\) 表示策略 \(\Pi_{\forall c} v_c\) 的数量。每个单元格 \(\mathcal{P}_{i, j}^{m_k}\) 对应于在与可观测值 \(\mathrm{o}_n\) 相关联的环境 \(i\) 中,采用策略 \(j=\mathrm{s}_n\) 时所观测到的度量指标 \(m_k\) 的性能。 \({}^2\) 第2.1.1节描述了如何根据所收集的可观测值(observables)计算一个环境。
\({}^2\) 在某些情况下,更合适的做法是保留所有观测到的性能值列表,并通过概率分布或其他统计量来衡量其相对于最优性能的优劣程度。
本质上,\(\mathcal{P}^{m_k}\) 汇总了真实数据文件(GTDF)中的数据以及任务中(in-mission)积累的经验。GTDF 是一系列三元组样本 \(\langle o, s, m \rangle\) 的集合,而 \(\mathcal{P}^{m_k}\) 则是针对特定度量 \(m_k\) 构建的 \(a \times b\) 性能表格。理论上,\(\mathcal{P}^{m_k}\) 可能包含大量行,但SD可通过设定环境聚类的最大数量(参见第2.1.1节)来控制环境数量 \(a\)。
10.3.3.1 充分性:场景下的性能(Adequacy: Performance over a Scenario)¶
充分性(Adequacy) 衡量系统在整个测试场景中的综合性能。一种简化的充分性计算方法是:对每个环境统计系统所选策略,并将其性能与该环境下最优策略的性能进行比较——类似于计算质量矩阵 \(\mathcal{Q}\) 的方式。
然而,这种方法未考虑策略切换本身可能构成效用函数一部分的情形(即:时刻 \(t\) 的最优策略依赖于时刻 \(t-\delta\) 所采用的策略)。
为在任务执行过程中计算充分性,场景驱动器(SD)采用以下公式:将系统在时刻 \(t\) 的观测性能 \(U_n(t)\) 除以该时刻理论上可达到的最佳性能 \(\hat{U}_n(t)\):
其中,\(\hat{U}_{n}(t)\) 对应于在时刻 \(t\) 能够实现最佳性能的策略。SD 根据性能表 \(\mathcal{P}^{m_k}\) 和时刻 \(t\) 在节点 \(n\) 处生效的效用函数(utility function)计算 \(\hat{U}_{n}(t)\);而 \(U_{n}(t)\) 则由系统在时刻 \(t+\delta\) 返回的性能反馈得出。(注意:此处的“最优”并非全局理论最优,而是基于已收集的真实数据(ground truth)中的最优。)
整个场景的充分性为所有时间戳上的充分性均值:
图10.8展示了一个包含六个环境的场景测试结果,每个环境每五个时间单位切换一次。总体而言,BBN认知引擎(BBN SO)通常能为当前环境选择最优策略,最终获得整体充分性 \(\mathcal{A}_{n} = 0.86\)。大多数误差出现在环境切换时刻,此时在环境 \(env_i\) 中生效的策略对下一环境 \(env_{i+1}\) 的效用较低。若在环境切换时充分性仍保持为1.0,则表明所选策略在两个环境中同样有效。充分性也可能为负值(例如在 \(t=1\) 时),因为此时策略带来的成本超过了收益。此外,充分性可在多个时间步内逐步提升(例如 \(t=[11, \ldots, 13]\)),这可能是由于策略存在启动延迟(ramp-up time),或决策器通过增量学习(incremental learning)尝试不同策略所致。
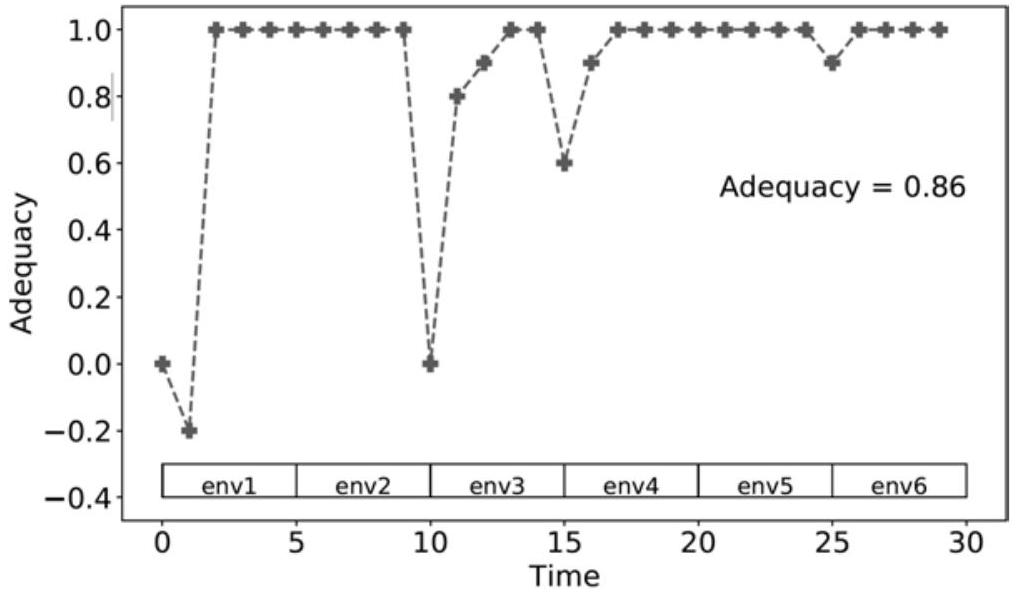
图10.8 场景驱动器(SD)在每个时间步评估充分性,方法是将决策器所选策略与该环境下已知最优策略进行比较。(参见例7.1,[3]。)
图10.9展示了增量式任务中学习(incremental in-mission learning)带来的影响。自适应系统与认知系统初始时使用相同训练数据构建的模型。SD 向两个系统施加相同的全新环境序列。自适应系统在整个场景中不允许重新训练,仅使用固定不变的已学模型,最终充分性得分为0.28;而认知系统在任务过程中进行了三次重训练,从而能够选择更优策略,最终达到0.88的充分性得分。任务中学习仅需一个样本即可学会应对新环境。
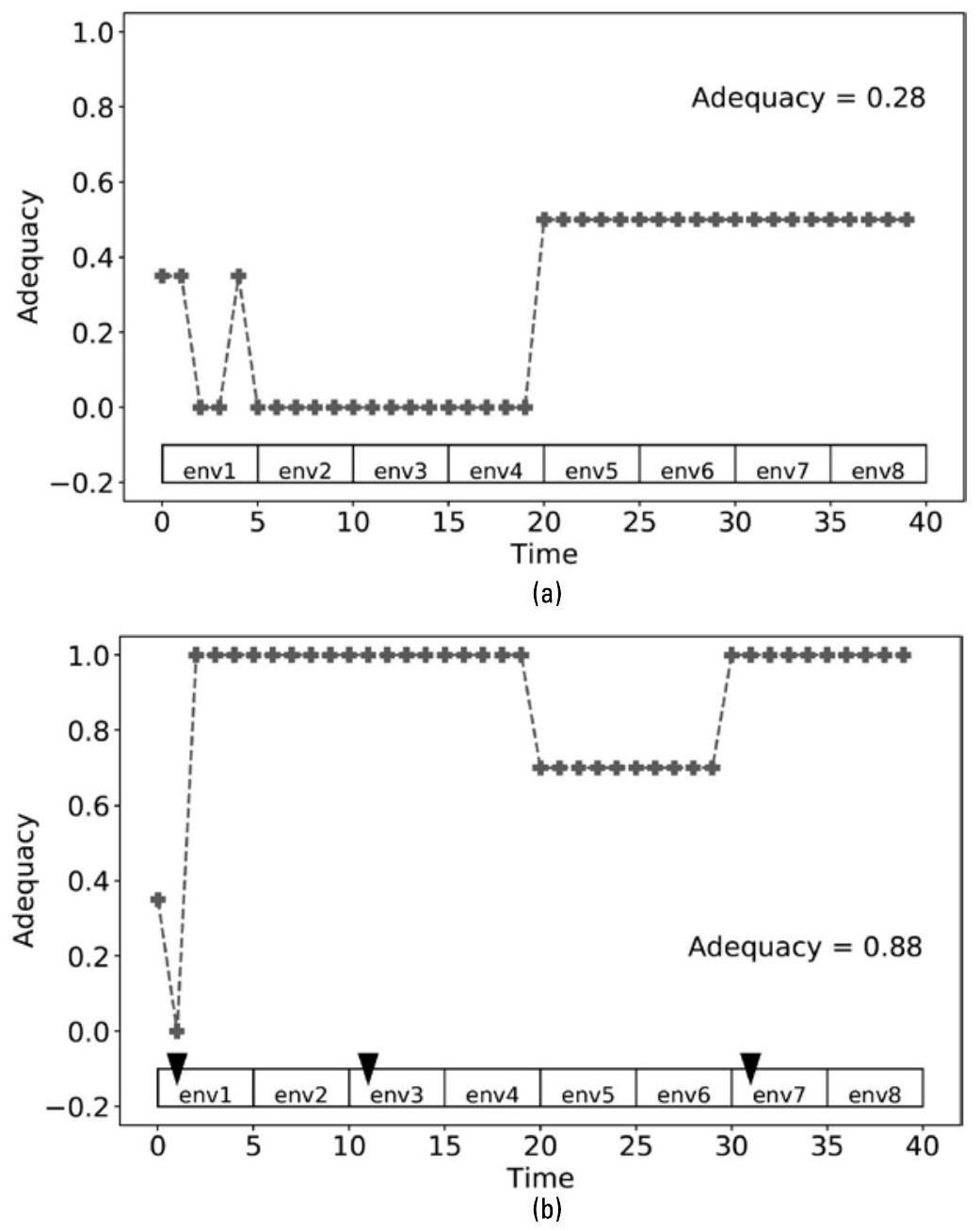
图10.9 在相同测试场景下,(b)中的认知系统表现优于(a)中的自适应系统。三角形标记表示决策器触发学习事件的时刻。(参见例7.1,根据[3]重绘。)
图10.5中的每个数据点均代表一个训练/测试场景的充分性得分,展示了所有训练与测试环境组合下的充分性表现。
增量学习仅以微小的最优性损失即可有效应对新环境。
环境由无监督聚类(unsupervised clustering)确定,而效用则由真实世界观测到的性能决定。对于给定环境,其“最优”性能值可能在任务过程中发生变化,尤其是在探索过程中发现了更优的候选策略时。在缺乏真实标签(ground truth)的运行环境中,“最优”指的是截至目前已知的最佳性能。
10.4 学习保障:认知系统的评估(Learning Assurance: Evaluating a Cognitive System)¶
评估认知系统与传统的验证与确认(Validation and Verification, V&V)方法有许多相似之处。测试内容包括正常情况、边界情况、压力条件以及对抗性场景。然而,学习系统要求对V&V流程进行适应性调整。尤其重要的是,该流程需确保并评估模型的鲁棒性(robustness),特别是在面对数据变化时的表现。数据管理、模型开发和元学习(metalearning)等所有环节都会影响最终系统的质量。
[复杂模型的] 验证是一个结合测量、计算建模和领域专业知识的过程,用于评估模型在特定关注量和适用领域内对现实的表征能力。
——美国国家研究委员会(National Research Council),2012年 [5]
10.4.1 学习保障流程(Learning Assurance Process)¶
学习保障(Learning Assurance) 是针对任何具备机器学习能力(ML-enabled)系统的质量保证(QA)或质量控制(QC)流程。学习保障流程旨在为电子战(EW)领域的利益相关者(包括认知系统用户)提供与现有EW系统同等的信任水平——后者正是通过传统的“V”型开发保障流程实现的。
Callout 10.1列出了开发高效AI系统所必需的任务清单。图10.10所示的设计闭环确保了数据质量、模型准确性和模型泛化能力。该设计阶段是迭代进行的,以确保所有变更均经过验证:包括数据格式的变更、模型结构的选择以及超参数的调整。
为将这些设计理念纳入正式的认证方法论,欧洲航空安全局(European Aviation Safety Agency)与Daedalean AG公司对传统的“V”型流程进行了扩展,以适用于认知系统。图10.11所示的学习保障“W”型流程(learning assurance “W”)纳入了针对学习系统的专门步骤:数据全生命周期管理(data life-cycle management)以及模型训练与验证(model training and verification)[6],具体描述如下:
Callout 10.1 一个AI项目的五个步骤,用于指导并约束开发工作,确保仅执行必要且充分的行动。
1988年,Cohen和Howe [2] 提出了一个AI研究的五阶段模型,为每个阶段提供了评估指南。这些指南以详细的评估标准与技术形式呈现,说明了如何开展评估,至今仍然适用:
- 明确任务(Refine the topic to a task):该任务是否具有重要意义?是否能代表一类任务?
- 设计方法(Design the method):该方法是否优于现有方法?其适用范围是什么?存在哪些替代方案?
- 构建程序(Build a program):该程序的示范性如何?是否仅为特定示例进行了调优?结果是否可预测?
- 设计实验(Design experiments):可展示多少个示例?应使用哪些基准(benchmarks)来比较结果?各组件对最终结果有何影响?
- 分析结果(Analyze the results):性能如何?算法效率如何?其局限性是什么?
该论文对每项任务及各步骤的评估方法进行了更为详尽的阐述。
- 数据管理(Data management):根据产品/系统需求和作战概念(Concept of Operations, ConOps),识别候选数据集、数据预处理方法、数据质量要求以及验证目标。
- 学习过程管理(Learning process management):驱动训练算法、初始化策略和超参数等要素的选择与验证;同时考虑软硬件框架,并选定评估指标。核心度量指标是准确性(accuracy)。然而,准确性依赖于多种上下文因素,这些权衡关系应被量化评估(参见Callout 10.2)。
- 模型训练(Model training):利用验证数据集对模型进行训练,并评估模型参数。
- 学习过程验证(Learning process verification):使用预先确定的评估度量指标,在测试数据集上对训练后的模型进行验证。
- 模型实现(Model implementation):将模型转换为可在目标硬件上运行的可执行形式。所有针对嵌入式硬实时环境所做的优化与修改都必须经过验证。
- 推理模型验证(Inference model verification):确保嵌入式部署后的模型持续满足预期性能要求。
- 数据验证(Data verification):确保数据的基本假设未发生改变。
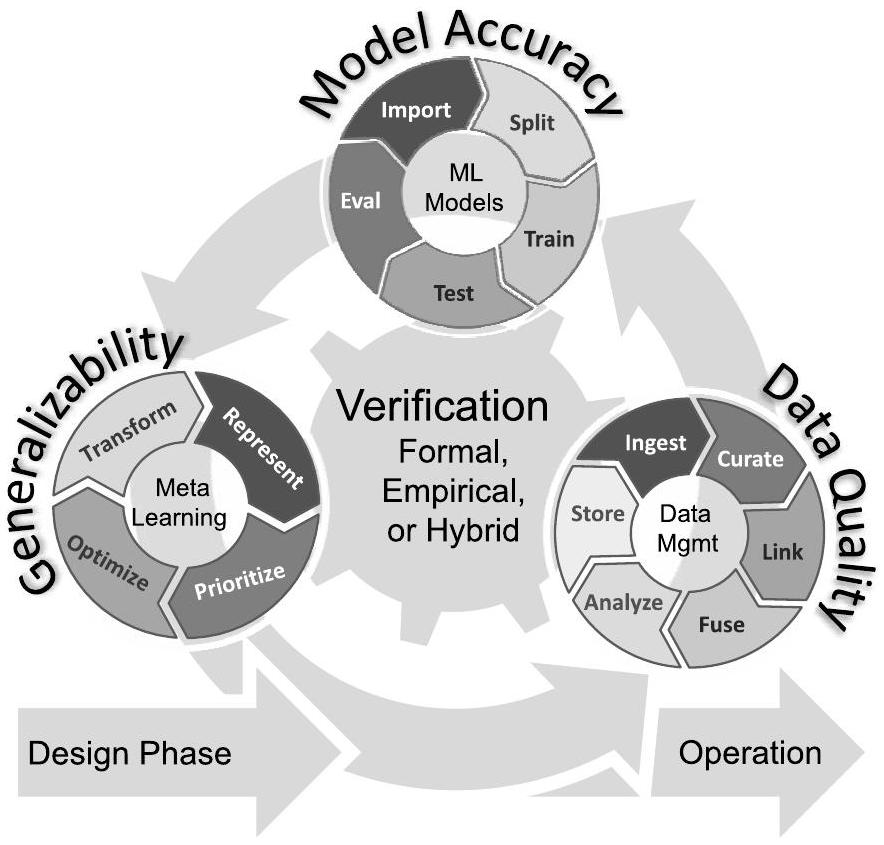
图10.10 在设计阶段,验证原则适用于数据管理、模型开发和元学习(metalearning)的迭代过程。良好的设计验证可为运行阶段提供性能保障。
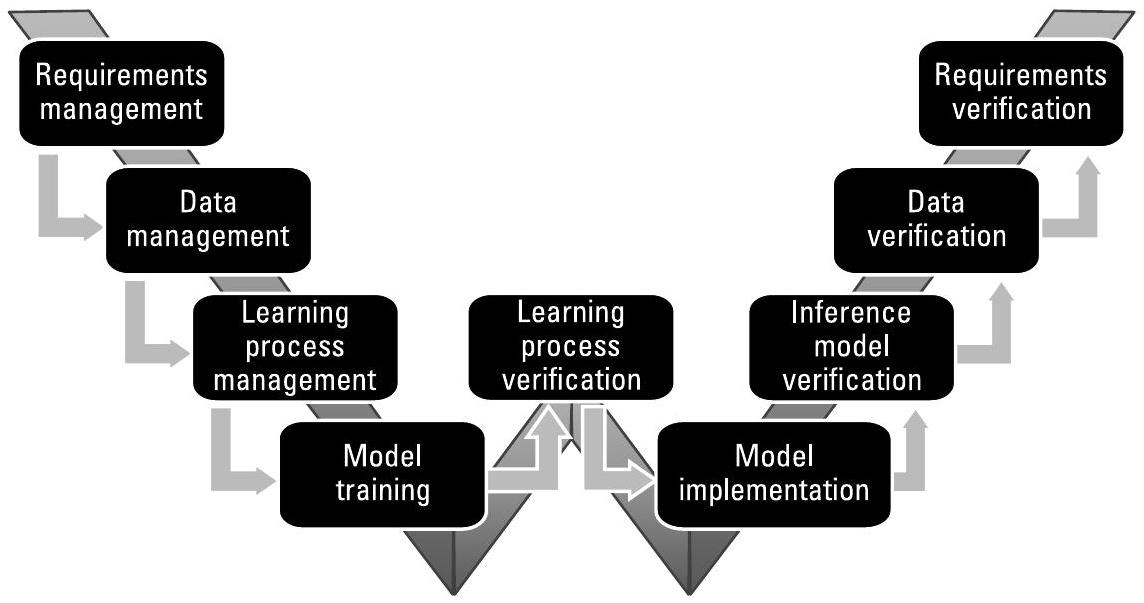
图10.11 面向学习系统的验证与确认(V&V)流程。(来源:[6],经许可转载。)
Callout 10.2 准确性(Accuracy)是系统评估的主要指标,但其表现依赖于多种上下文因素和系统需求。
- 准确性(Accuracy):对环境、行为及因果事件模式的成功表征,以及电子防护/电子攻击(EP/EA)策略的高充分性(adequacy)。
- 可扩展性(Scalability):可处理的辐射源(emitter)数量、策略数量、训练数据规模。
- 可移植性(Portability):对硬件平台和操作系统的依赖程度。
- 复杂性(Complexity):任务与威胁场景的复杂程度。
- 数据需求(Data requirements):所需数据的数量、类型、完整性与正确性(另见表8.1)。
- 计算开销(Computation effort):模型训练耗时、推理耗时、样本效率(sample efficiency)。
- 适应性(Adaptability):模型更新以适应新条件所需的时间和样本数量。
- 泛化能力(Generalizability):在适用域(domain of applicability)之外的准确性表现。
- 鲁棒性/稳定性(Robustness/stability):对输入值变化的敏感程度及系统脆弱性(brittleness)。
- 不确定性/置信度(Uncertainty/confidence):系统对自身估计结果的置信度自评估能力。
- 可用性与可解释性(Usability and explainability):人类用户在任务中或事后取证时理解系统结果的难易程度。
- 安全性(Safety):提供性能保证的难易程度。
- 迁移性(Transferability):模型在略有差异的上下文中的有效性(例如,在合成数据上训练、在真实数据上测试)。
- 累积增益(Cumulative gains):随时间或经验积累的性能提升,或与其他AI/ML组件协同带来的综合效益。
- 时序性能(Performance over time):系统长期运行中的性能表现,包括概念漂移(concept drift);以及利益相关者是否真正建立起对系统决策的信任并愿意依赖其输出。
多版本异构软件(Multiple-version dissimilar software)是一种系统设计技术,通过开发两个或多个实现相同功能但实现方式不同的软件组件,以规避组件间共因故障(common-mode errors)的来源 [7]。该方法与集成学习(ensemble learning)(参见第3.2节)相关,冗余解决方案可提升系统韧性(resilience),并增强对学习方法结果的信心。
学习系统应通过实证方法(empirical methods)、形式化方法(formal methods)或二者结合的方式进行验证 [6, 8]。图10.12简要定义了各类验证方法。第10.4.2节和第10.4.3节分别介绍了形式化与实证验证方法的具体实例。
| 实证验证(Empirical Verification) | 半形式化验证(Semiformal Verification) | 形式化验证(Formal Verification) |
|---|---|---|
| 将模型视为白盒(white box) | 结合数学与实证概念 | 使用形式化方法获取最坏情况下的鲁棒性边界 |
| - 对训练后的模型进行系统性测试 - 检查模型的内在与外在特征/行为 |
- 识别训练模型的边界案例 - 评估预测的置信度 - 对抗性测试(Adversarial testing) |
- 理论上判定在训练数据扰动下模型何时发生剧烈变化(例如,机器学习算法稳定性被破坏时) |
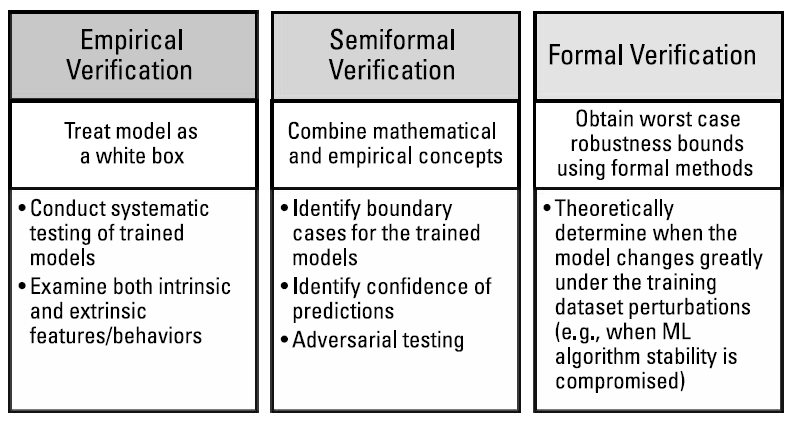
图10.12 学习系统的验证方法包括实证、形式化及混合方法。
美国国家研究委员会(National Research Council)阐述了如何评估复杂模型的可靠性 [5]。Luckcuck 等人 [9] 对自主机器人系统的形式化规约与验证(formal specification and verification)进行了详细综述。Jacklin 等人 [10] 探讨了自适应飞行关键控制软件所面临的独特验证与确认(V&V)挑战。Lahiri 与 Wang [11] 提出了多种用于安全关键系统中人工神经网络(ANN)验证的形式化方法。例10.1展示了一个面向飞机滑行应用的保障架构实例。
从实践角度看,验证方法应产出以下有用结果 [6, 13]:
- 违反约束条件的输入(即样本外误差,out-of-sample error);
- 输入在导致输出违反需求前可允许的最大变化量;
- 对于给定输入集,预期的输出结果;
- 描述模型可能失效时机的置信度估计(confidence estimates)。
例10.1 多种保障方法共同验证了飞机滑行应用中基于机器学习(ML)组件的安全性。
Cofer 等人 [12] 为飞机滑行应用演示了一种运行时保障(run-time assurance)架构。该演示包含:基于 ASTM F3269-17 标准(用于复杂系统有界行为)的安全架构、多样化的系统安全运行时监视器,以及关键高保障组件的形式化综合(formal synthesis)。所开发的架构证明了即使底层基于人工神经网络(ANN)的组件存在缺陷,系统仍能维持安全性。
Cofer 等人采用以下技术对系统进行保障:(1) 使用架构分析与设计语言(Architecture Analysis and Design Language, AADL)对系统架构进行建模;(2) 利用假设-保证推理环境(Assume Guarantee Reasoning Environment, AGREE)对系统行为进行形式化验证;(3) 采用基于架构的保障论证(assurance case),并通过 Resolute 语言证明其实现的正确性;(4) 部署多种运行时监视器,以保障系统的安全性、完整性与可用性;(5) 从形式化规约出发,对关键高保障组件进行综合,并提供正确性证明。注:AGREE 使用 \(k\)-归纳法(\(k\)-induction)作为其模型检测(model checking)的底层算法。
10.4.2 形式化验证方法(Formal Verification Methods)¶
计算学习理论(Computational Learning Theory, CLT)与统计学习理论(Statistical Learning Theory, SLT)是人工智能的子领域,致力于机器学习(ML)算法的设计与分析 [14–16]。尽管CLT与SLT共享相同的理论框架,但CLT旨在判定哪些问题是“可学习的”(learnable),而SLT则聚焦于提升现有ML算法的准确性。
Vapnik-Chervonenkis(VC)维数(VC dimension)用于衡量给定分类器的复杂度 [17]。较大的VC维数表明分类器更复杂,反之亦然。例如,VC维数可用于预测分类器测试误差的概率上界 [18]。
概率近似正确(Probably Approximately Correct, PAC)学习是由Leslie Valiant于1984年提出的理论框架 [19]。PAC学习用于分析ML模型的泛化误差与其在训练集上的误差之间的关系,同时提供对其复杂度的度量。其典型目标是证明:算法以高概率(“probably”部分)实现较低的泛化误差(“approximately correct”部分)。PAC学习已被扩展至PAC-贝叶斯不等式(PAC-Bayesian inequalities)[20–22]。例如,McAllester的PAC-贝叶斯分析为贝叶斯分类器推导出了经验上界 [23]。从某种意义上说,此类分析可视为半形式化方法。
Katz 等人 [24, 25] 提出了一种用于验证深度神经网络(Deep Neural Networks, DNNs)的理论框架。Marabou 工具基于模理论可满足性(Satisfiability Modulo Theories, SMT)求解器,能通过将关于DNN性质的查询转化为约束满足问题来回答这些查询。Marabou已形式化证明了DNN可避免空中碰撞。SMT方法还可用于检测对抗性扰动(adversarial perturbations),即导致网络误分类的最小输入变化。该方法可保证:若在给定区域和特定操作族下存在对抗样本,则必能被发现 [26]。
SMT求解器属于一类自动定理证明器,能够判定一阶逻辑公式(尤其是特定逻辑理论)的可满足性与有效性。Balunovic 等人 [27] 指出,SMT求解器比可满足性(SAT)求解器更具通用性,已被应用于神经网络验证、程序综合、静态分析和调度等领域。SAT求解器本质上提供了一个通用的组合推理与搜索平台,广泛用于软件验证、规划与调度等任务 [28]。
Wang 等人 [29] 利用区间算术(interval arithmetic)计算深度神经网络(DNN)输出的严格边界,并采用符号区间分析(symbolic interval analysis)以最小化对输出边界的高估。Amini 等人 [30] 则计算精确且经过校准的不确定性估计(uncertainty estimates),用于识别分布外(out-of-distribution)样本,并判断模型可能失效的时机。不确定性来源可分为两类:数据不确定性(aleatoric uncertainty,源于观测噪声等随机因素)和模型不确定性(epistemic uncertainty,源于模型自身对未知区域的认知不足)。
Maher 与 Orlando [31] 利用基于本体的知识图谱(ontology-based knowledge graphs)来增强机器学习能力的作战训练。通过构建知识图谱,本体模型(ontology model)可作为一种应对低质量数据的解决方案。该方法通过引入语义信息,形式化且显式地表达领域概念,并描述领域数据之间的相互关系。
形式化验证方法因其能够从理论上判定算法稳定性而备受关注。然而,深度神经网络(DeepNets)及其他机器学习算法的高度复杂性,使得传统形式化软件验证流程难以直接应用。主要挑战包括:计算复杂度高、可扩展性受限、适用范围有限、缺乏标准化基准(benchmarking),以及运行时开销与结果完备性之间的权衡。
10.4.3 实证与半形式化验证方法(Empirical and Semiformal Verification Methods)¶
实证验证方法必须以闭环方式(closed-loop manner)进行,因为环境会对系统动作做出响应(参见第10.1节)。
在设计阶段,验证测试可使用合成数据(synthetic data)、模拟数据(emulated data)、真实训练数据、增强数据(augmented data)或其任意组合。性能度量应在实际部署环境中进行,尤其是在学习保障(learning assurance)的运行阶段。例如,若无法获取真实的原始I/Q数据,射频(RF)信号分类器可先在合成I/Q数据上进行训练与验证(如通过MATLAB生成)。尽管合成数据可能引入非预期的人工伪影(artifacts)并缺乏真实感(例如特定OFDM系统中的I/Q不平衡或相位噪声),但它也能提供数据多样性并覆盖边界情况(参见第8.3.2节)。
实证验证方法的一些普遍缺陷包括训练数据完整性(data integrity)和数据偏差(data bias)。应对策略包括:
- 消融测试(Ablation testing):\(n\)-choose-\(k\) 消融测试(参见第10.2节)通过在 \(k\) 个案例上训练、并在全部 \(n\) 个已知真实环境上测试,证明系统能够应对新环境,从而评估其在 \(n-k\) 个新环境中的性能。
- 对抗性测试(Adversarial testing):该方法评估机器学习算法在面对“最坏情况”对手时的鲁棒性,即对手会采取最不利的行动(例如 [32] 所述)。
- 白盒测试(White-box testing):白盒验证方法通过测试评估模型行为。“白盒”概念不仅关注最终输出行为,还分析其内部参数,如神经元覆盖率(neural coverage)和激活模式(activation patterns)[33, 34]。
- 局限性研究(Limitation studies):为了解系统在意外条件下的表现,需使用已知的边界案例进行测试,例如增加噪声、数据缺失或存在错误等情况。例如,证伪(falsification)方法可自动生成边界案例。尽管该方法无法保证完备性或正确性,但通常能以高效且合理的方式扩展测试覆盖范围 [35, 36]。
- 错误界模型(Mistake-bound model):该模型回答在线学习算法在学会目标函数 \(f\) 前最多会犯多少错误 [37, 38]。学习过程以轮次进行:每轮中,场景驱动器(SD)提供一个未标记样本 \(x\),学习器需预测未知目标函数 \(f\) 的值 \(f(x)\);随后SD提供性能反馈,使学习器可重新训练并更新其假设。学习器的错误界即为其在所有轮次中最坏情况下的错误总数。
- 简化(Simplification):Elboher 等人 [39] 提出一种通过过近似(overapproximation)简化神经网络的验证框架。知识蒸馏(Knowledge distillation)先训练一个复杂的“教师”模型,再训练一个简单的“学生”模型来模仿教师行为 [40–42]。抽象解释(Abstract interpretation)则通过显式管理近似与精度之间的权衡,来近似网络行为 [43]。
- 奥卡姆学习(Occam learning):奥卡姆学习与PAC学习密切相关,但能对训练数据集复杂度给出更紧致的(实证)界。其目标是输出对训练数据的简洁表示。该方法得名于“奥卡姆剃刀”原则——在对观测数据的两种解释中,若其他条件相同,则更简单的解释更优 [44]。
- 敏感性分析/调优研究(Sensitivity analysis/tuning studies):元学习(参见第5.1.3节)可估计模型对超参数变化的敏感度,从而评估其稳定性与鲁棒性。输出可达性分析(Output reachability analysis)计算神经网络的最大敏感度,并模拟其输出可达集 [45]。
- 直接评估(Direct assessment):在某些情况下,最终用户可直接评估系统性能的“合理性”(plausibility)。尽管该方法无法产生可发表的量化结果,但有助于建立利益相关者对系统的信任。
10.5 结论(Conclusion)¶
评估一个学习系统需要突破传统验证与确认(V&V)方法的思维框架。传统方法通常仅在一种(或若干种)固定的、已知场景下验证系统性能,无法反映系统在全新情境中的表现。学习保障(learning assurance)流程必须对数据质量、模型准确性和模型泛化能力进行全面验证。当前的系统需求规范通常适用于纯决策管理(Decision Management, DM)类(即优化型)方法,但尚未跟上基于学习的人工智能(AI)系统的新需求。在数据质量、数据存储、模型安全性以及验证目标等方面,现有规范仍存在明显缺失。
鉴于电子战(EW)固有的交互性与对抗性,认知系统必须在闭环环境中进行测试。系统需求应明确指出认知能力三维模型(图1.3)中哪些维度对任务至关重要,从而确保测试场景和所测特性能够切实满足任务目标。
References¶
[1] McLeod, S., "Maslow's Hierarchy of Needs," Simply Psychology, 2018.
[2] Cohen, P., and A. Howe, "How Evaluation Guides AI Research: The Message Still Counts More Than the Medium," AI Magazine, Vol. 9, No. 4, 1988.
[3] Haigh, K. Z., et al., "Parallel Learning and Decision Making for a Smart Embedded Communications Platform," BBN Technologies, Tech. Rep. BBN-REPORT-8579, 2015.
[4] Youssef, K., et al., "Machine Learning Approach to RF Transmitter Identification," IEEE Journal of Radio Frequency Identification, Vol. 2, No. 4, 2018.
[5] National Research Council, Assessing the Reliability of Complex Models, National Academies Press, 2012.
[6] Cluzeau, J., et al., Concepts of Design Assurance For Neural Networks (CoDANN), European Union Aviation Safety Agency. Online: https://tinyurl.com/CoDANN-2020.
[7] Software Considerations in Airborne Systems and Equipment Certification, RTCA DO-178C/ EUROCAE ED-12C Standard, Radio Technical Commission for Aeronautics (RTCA), 2011.
[8] Sun, X., H. Khedr, and Y. Shoukry, "Formal Verification of Neural Network Controlled Autonomous Systems," in Hybrid Systems: Computation and Control, 2019.
[9] Luckcuck, M., et al., "Formal Specification and Verification of Autonomous Robotic Systems: A Survey," ACM Comput. Surv., Vol. 52, No. 5, 2019.
[10] Jacklin, S., et al., "Verification, Validation, and Certification Challenges for Adaptive FlightCritical Control System Software," in AIAA Guidance, Navigation, and Control Conference and Exhibit, 2004.
[11] Lahiri, S. K., and C. Wang, Computer Aided Verification, Springer Nature, 2020, Vol. 12224.
[12] Cofer, D., et al., "Run-Time Assurance for Learning-Enabled Systems," in NASA Formal Methods Symposium, Springer, 2020.
[13] Liu, C., et al., Algorithms for Verifying Deep Neural Networks, 2019. Online: https://arxiv.org/ abs/1903.06758.
[14] Bousquet, O., S. Boucheron, and G. Lugosi, "Introduction to Statistical Learning Theory," in Summer School on Machine Learning, Springer, 2003.
[15] Kearns, M., U. Vazirani, and U. Vazirani, An Introduction to Computational Learning Theory, MIT Press, 1994.
[16] Russell, S., and P. Norvig, Artificial Intelligence: A Modern Approach, Pearson Education, 2015.
[17] Vapnik, V., and A. Chervonenkis, "On the Uniform Convergence of Relative Frequencies of Events to Their Probabilities," Theory Of Probability & Its Applications, Vol. 16, No. 2, 1971.
[18] Vapnik, V., The Nature of Statistical Learning Theory (Second ed.), New York: SpringerVerlag, 2000.
[19] Valiant, L., "A Theory of the Learnable," Communications of the ACM, Vol. 27, No. 11, 1984.
[20] Shawe-Taylor, J., and R. Williamson, "A PAC Analysis of a Bayesian Estimator," in Computational Learning Theory, 1997.
[21] McAllester, D., "Some PAC-Bayesian Theorems," Machine Learning, Vol. 37, No. 3, 1999.
[22] McAllester, D., "PAC-Bayesian Model Averaging," in Computational Learning Theory, 1999.
[23] Guedj, B., A Primer on PAC-Bayesian Learning, 2019. Online: https://arxiv.org/ abs/1901.05353.
[24] Katz, G., et al., "The Marabou Framework for Verification and Analysis of Deep Neural Networks," in Computer Aided Verification, Springer, 2019.
[25] Katz, G., et al., "Reluplex: An Efficient SMT Solver for Verifying Deep Neural Networks," in International Conference on Computer Aided Verification, Springer, 2017.
[26] Huang, X., et al., "Safety Verification of Deep Neural Networks," Lecture Notes in Computer Science, 2017.
[27] Balunovic, M., P. Bielik, and M. Vechev, "Learning to Solve SMT Formulas," in NeurIPS, 2018.
[28] Gomes, C., et al., "Satisfiability Solvers," Foundations of Artificial Intelligence, Vol. 3, 2008.
[29] Wang, S., et al., "Formal Security Analysis of Neural Networks Using Symbolic Intervals," in Conference on Security Symposium, USENIX Association, 2018.
[30] Amini, A., et al., "Deep Evidential Regression," in NeurIPS, 2020.
[31] Maher, M., and R. Orlando, "Solving the 'Garbage In-Garbage Out' Data Issue Through Ontological Knowledge Graphs," Processus Group and Kord Technologies, Tech. Rep., 2019.
[32] Katz, G., et al., "Towards Proving the Adversarial Robustness of Deep Neural Networks," in Formal Verification of Autonomous Vehicles, 2017.
[33] Pei, K., et al., "Deepxplore: Automated Whitebox Testing of Deep Learning Systems," in Symposium on Operating Systems Principles, 2017.
[34] Tian, Y., et al., "Deeptest: Automated Testing of Deep-Neural-Network-Driven Autonomous Cars," in International Conference on Software Engineering, 2018.
[35] Dreossi, T., A. Donzé, and S. A. Seshia, "Compositional Falsification of Cyberphysical Systems with Machine Learning Components," in NASA Formal Methods Symposium, Springer, 2017.
[36] Zhang, Z., et al., "Two-Layered Falsification of Hybrid Systems Guided by Monte Carlo Tree Search," IEEE Transactions on Computer-Aided Design of Integrated Circuits and Systems, Vol. 37, No. 11, 2018.
[37] Buhrman, H., D. García-Soriano, and A. Matsliah, "Learning Parities in the Mistake-Bound Model," Information Processing Letters, Vol. 111, No. 1, 2010.
[38] Littlestone, N., "Learning Quickly When Irrelevant Attributes Abound: A New LinearThreshold Algorithm," Machine Learning, Vol. 2, No. 4, 1988.
[39] Elboher, Y., J. Gottschlich, and G. Katz, "An Abstraction-Based Framework for Neural Network Verification," in International Conference on Computer Aided Verification, Springer, 2020.
[40] Hinton, G., O. Vinyals, and J. Dean, Distilling the Knowledge in a Neural Network, 2015. Online: https://arxiv.org/abs/1503.02531.
[41] Papernot, N., et al., "Semisupervised Knowledge Transfer for Deep Learning From Private Training Data," in ICLR, 2017.
[42] Mishra, A., and D. Marr, Apprentice: Using Knowledge Distillation Techniques to Improve LowPrecision Network Accuracy, 2017. Online: https://arxiv.org/abs/1711.05852.
[43] Singh, G., et al., "Fast and Effective Robustness Certification," in NeurIPS, 2018.
[44] Blumer, A., et al., "Occam's Razor," Information Processing Letters, Vol. 24, No. 6, 1987.
[45] Xiang, W., H.-D. Tran, and T. Johnson, "Output Reachable Set Estimation and Verification for Multilayer Neural Networks," IEEE Transactions on Neural Networks and Learning Systems, Vol. 29, No. 11, 2018.