2 目标函数¶
电子战(Electronic Warfare, EW)决策管理(Decision Management, DM)的挑战在于构建一种认知控制器,使其能够在高度动态的环境中自动维持近似最优的配置。每个DM问题都包含以下组成部分:
- 一组系统需完成的目标(objectives),每个目标均具有既定的重要性;
- 一组系统可用于实现目标的动作(actions);
- 一组用于评估系统状态以确定后果的方法(例如,强化成功结果并处理不利后果)。
借助这三个组成部分,系统能够针对不断演化的任务条件选择最合适的动作。本章描述了EW决策者的核心:目标集合。这些目标必须具备作战相关性,并且在实践中可被优化[1–4]。因此,我们必须将任务目标与约束条件纳入一个数学上可优化的目标函数(objective function)中,该函数也被称为效用函数(utility function)。目标与约束来源于用户与任务需求、环境限制以及装备能力。效用函数衡量所有用于评估决策的因素,从而使系统能够选择“最优”解决方案。考虑一个包含 \(N\) 个节点的EW系统;每个节点 \(n \in N\) 具有:
- 一组可观测参数 \(\mathbf{o}_{\mathbf{n}}\),用于描述射频(RF)环境(见第2.1节);
- 一组可控参数 \(\mathbf{c}_{\mathbf{n}}\),供决策者用于改变系统行为(见第2.2节);
- 一个或多个度量指标(metrics)\(m_{n}\),用于反馈节点执行效果,并附带相应的权重(weights)\(w_{n}\)(见第2.3节);
- 一个效用函数 \(\tilde{\mathcal{U}}\),将度量指标与权重综合为单一标量结果(见第2.4节)。
策略(strategy)\(s_{n}\) 是一组控制参数 \(c_{n}\) 的组合。目标是使每个节点 \(n\) 选择其策略 \(s_{n}\),以最大化系统的效用 \(\tilde{U}_{n}\)。
表2.1汇总了上述符号。在本书正文部分,我们通常对这些概念采用非正式记号;第2.4节则给出了真实效用函数 \(\mathcal{U}\) 及其近似形式 \(\tilde{U}_{n}\) 的正式定义。
根据系统需求,某一策略可能服务于电子防护(Electronic Protection, EP)目标、电子攻击(Electronic Attack, EA)目标,或同时服务于两者。同样,策略也可能服务于通信目标、雷达目标,或两者兼有。人工智能(AI)对问题领域是无偏的(agnostic),不会区分目标类型或问题领域。具体问题的定义决定了该问题特有的可观测量(observables)、可控量(controllables)、目标(objectives)和启发式规则(heuristics)。
AI技术可同等应用于EP/EA以及通信/雷达领域。效用函数将AI技术与具体问题领域联系起来。
表2.1 支持构建效用函数的符号
| 符号 | 定义 |
|---|---|
| \(n \in N\) | 节点集合 \(N\) 中的节点 \(n\) |
| \(t\) | 时间戳 |
| \(o_{n}\) | 节点 \(n\) 的可观测量;\(o_{n}(t)\) 表示 \(o_{n}\) 在时刻 \(t\) 的取值。记 \(\overline{o_{n}} \triangleq \mid o_{n}\mid\) |
| \(z\) | 不可观测的上下文信息 |
| \(c_{n}\) | 节点 \(n\) 的可控量;\(c_{n}(t)\) 表示 $c_{n} $ 在时刻 \(t\) 的取值。记 \(\overline{c_{n}} \triangleq \mid c_{n}\mid\) |
| \(m_{n}\) | 节点 \(n\) 的度量指标;记 \(\overline{m_{n}} \triangleq\mid m_{n}\mid\) |
| \(w_{n}\) | 与 \(m_{n}\) 中各度量指标对应的权重;\(\mid w_{n}\mid =\overline{m_{n}}\) |
| \(s_{n}\) | 节点 \(n\) 的策略;即可控量 \(c_{n}\) 的组合 |
| \(\mathcal{U}\) | 真实效用函数,无对应的精确解析表达式 |
| \(\tilde{U}_{n}\) | 节点 \(n\) 对效用的局部估计 |
| \(\tilde{\mathcal{F}}_{n}\) | 节点 \(n\) 对性能曲面(performance surface)的局部模型 |
| \(U_{n}\) | 节点 \(n\) 处观测到的效用 |
| \(\hat{U}_{n}\) | 节点 \(n\) 处测得的最佳(或最优)效用 |
| \(g_{n}\) | 基于度量指标 \(m_{n}\) 和权重 \(w_{n}\) 评估效用 \(\tilde{U}_{n}\) 的函数 |
| \(f_{n k}\) | 基于可观测量 \(o_{n}\) 和可控量 \(c_{n}\) 评估节点 \(n\) 第 \(k^{\text{th}}\) 个度量指标的函数:\(m_{n k}=f_{n k}\left(o_{n}, c_{n}\right)=f_{n k}\left(o_{n}, s_{n}\right)\),或简写为 \(m_{k}=f_{k}(o, s)\) |
2.1 描述环境的可观测量(Observables)¶
在电子战(EW)中,可观测特征(observable features),或称可观测量(observables),是对信号环境及任何相关上下文信息的一般性描述。可观测量由电子支援(Electronic Support, ES)模块计算得出。每个节点 \(n \in N\) 都拥有其自身的可观测量集合 \(o_{n}\),且该集合可能与其他节点 \(n^{\prime} \in N\) 的可观测量不同。每个节点包含 \(\overline{o_{n}}\) 个可观测量。可观测量可包括原始数值、推导出的抽象信息或推断出的概念:
- 接收机原始的同相/正交(In-phase/Quadrature, I/Q)数值;
- 所有被探测到的辐射源(友方、中立方或敌方)的描述。这些特征可能包括噪声电平、误码率、高斯性(Gaussianness)、重复性、与己方通信信号的相似度、辐射源地理位置信息、辐射源能力以及当前工作模式;
- 所有被探测到的目标的描述,包括载波特性、脉冲统计参数和多普勒(Doppler)信息;
- 接收机状态的描述(例如饱和状态和天线特性);
- 内部软件状态的描述,在认知无线电(Cognitive Radio, CR)场景下,这包括来自IP协议栈或终端用户应用的统计信息,例如消息误码率、队列长度和邻域规模;
- 任务相关信息的描述,包括已知或预测的位置、任务内容、用户信息以及指挥官意图(commander's intent);
- 环境描述,例如温度、沙尘或地形特征。
图2.1展示了若干用于表征不同类型干扰机(jammer)的可观测量。每个被探测到的辐射源均关联一个独立的可观测量向量。
通常,当导出或推断出的特征能够相对于预期进行抽象化或归一化时,决策者便能更轻松地判断不同特征的相对重要性。例如,可观测量可相对于预期在 -1 到 1 的范围内取值(-1 表示“强烈不符合”,1 表示“强烈符合”)。部分不可观测的值可用 NaN(Not a Number)表示。
有多种可视化工具可用于理解不同环境之间的差异。图2.2展示了观察数据的四种不同方式,每种方式因目的不同而各有用处:柱状图使用每个可观测量的均值,以快速提供整体直观印象(gestalt sense);箱线图展示数值的分布情况;散点图则显示每次环境观测中各可观测量的详细分布。
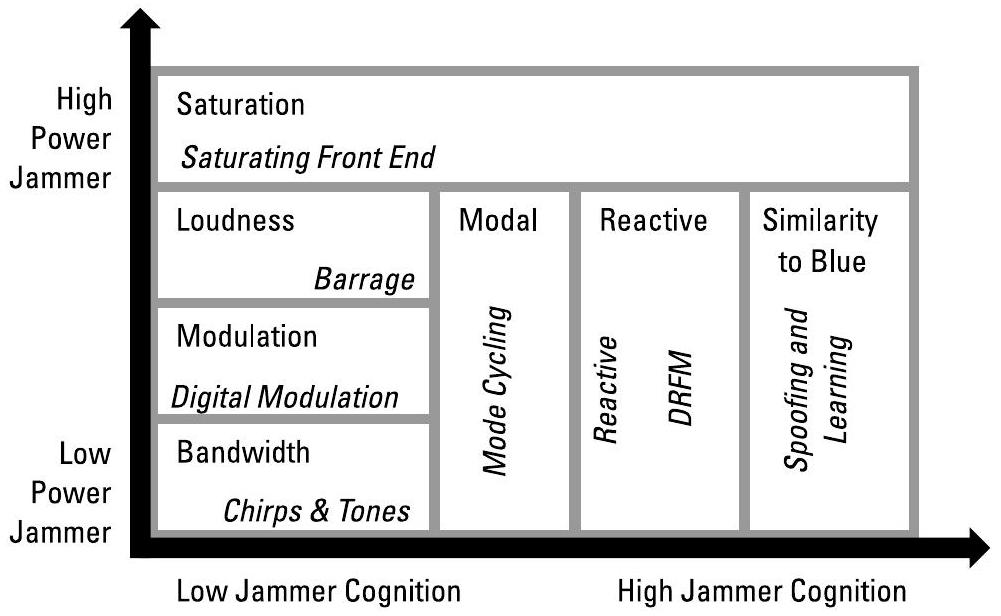
图2.1 可观测量是使系统能够做出决策的特征;这些可观测量有助于表征不同类型的干扰机(jammer)。
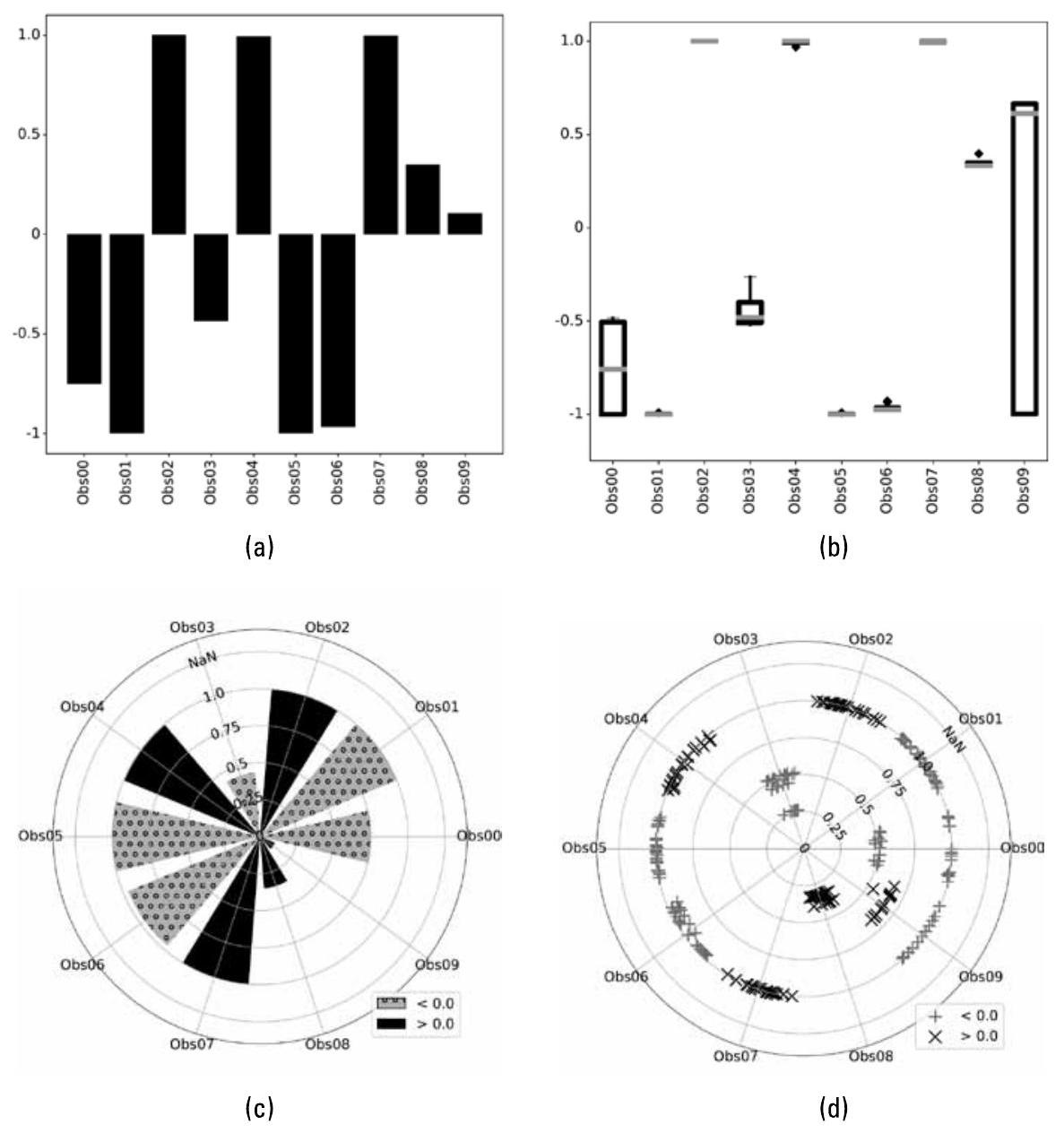
图2.2 可视化环境观测数据的四种不同方式:(a) 显示非NaN值均值的柱状图;(b) 展示数值分布的箱须图(box-and-whiskers plot);(c) 在极坐标轴上绘制的柱状图;(d) 在极坐标轴上的散点图。这些可视化方式均基于相同的底层可观测数据。(图7.3对箱线图进行解释。)
所有模型都是错误的,但有些是有用的。
——乔治·博克斯(George Box)[5]
需要注意的是,可能存在不可观测的上下文信息 \(z\)。这些隐变量可能包括广泛环境因素,如政治局势、风力发电场、天气,或更细致的概念,如未被探测到的辐射源或正在失效的硬件组件。理论上,每一只蝴蝶都可能影响系统性能;实践中,设计者应尽可能捕捉所有相关因素。不可观测因素是电子支援(ES)中建模误差的主要来源。物理系统的模型本质上是不完备的,而系统表现出的随机性往往取决于那些未被观测到或无法测量的变量。
2.1.1 环境聚类(Clustering Environments)¶
作为我们在电子战(EW)系统中首次尝试应用机器学习(ML)的方法,可以使用聚类(clustering)来判断环境之间的相似性。聚类是一种无监督机器学习方法,它根据样本的特征将相似的项目分组[6, 7]。我们将可观测特征向量聚类为若干射频(RF)环境,并绘制相应的树状图(dendrogram),以可视化各环境之间的相似或相异程度。图2.3展示了一个基于23种不同射频环境构建的树状图,以及其中三个环境对应的箱线图(boxplots)。连接两个环境的线段越短,说明它们越相似。环境06和05是最相似的两个环境,首先形成一个簇;随后,该簇与(环境16和环境13)组成的另一对簇进一步合并。环境16和环境06的箱线图也表明,它们实际上非常相似。而环境21则显著不同,在树状图中距离其他环境非常远。
标准机器学习库中提供了多种聚类方法(见第11.2.1节)。算法2.1展示了如何使用scikit-learn绘制一个简单的树状图。需要注意的是,scikit-learn的树状图函数要求数据中不能包含NaN值。因此,cleanNaNs() 函数会将NaN值替换为有效数值:对于每个环境中的每个可观测量,用该可观测量在该环境中所有非NaN值的均值来填充NaN。
标准机器学习库通常无法复用已用于其他目的的计算结果,且需要针对嵌入式环境进行重新实现。K均值聚类(K-means clustering)计算效率高,适用于嵌入式领域[8];此外,也可利用已知的标签作为初始聚类中心(cluster seeds)。如果系统已维护样本之间的距离(例如,用于支持支持向量机(SVM)训练或保持数据集多样性),那么层次聚类(hierarchical clustering)方法也同样适用。最终的聚类数量可由可用内存大小或簇间距离决定。
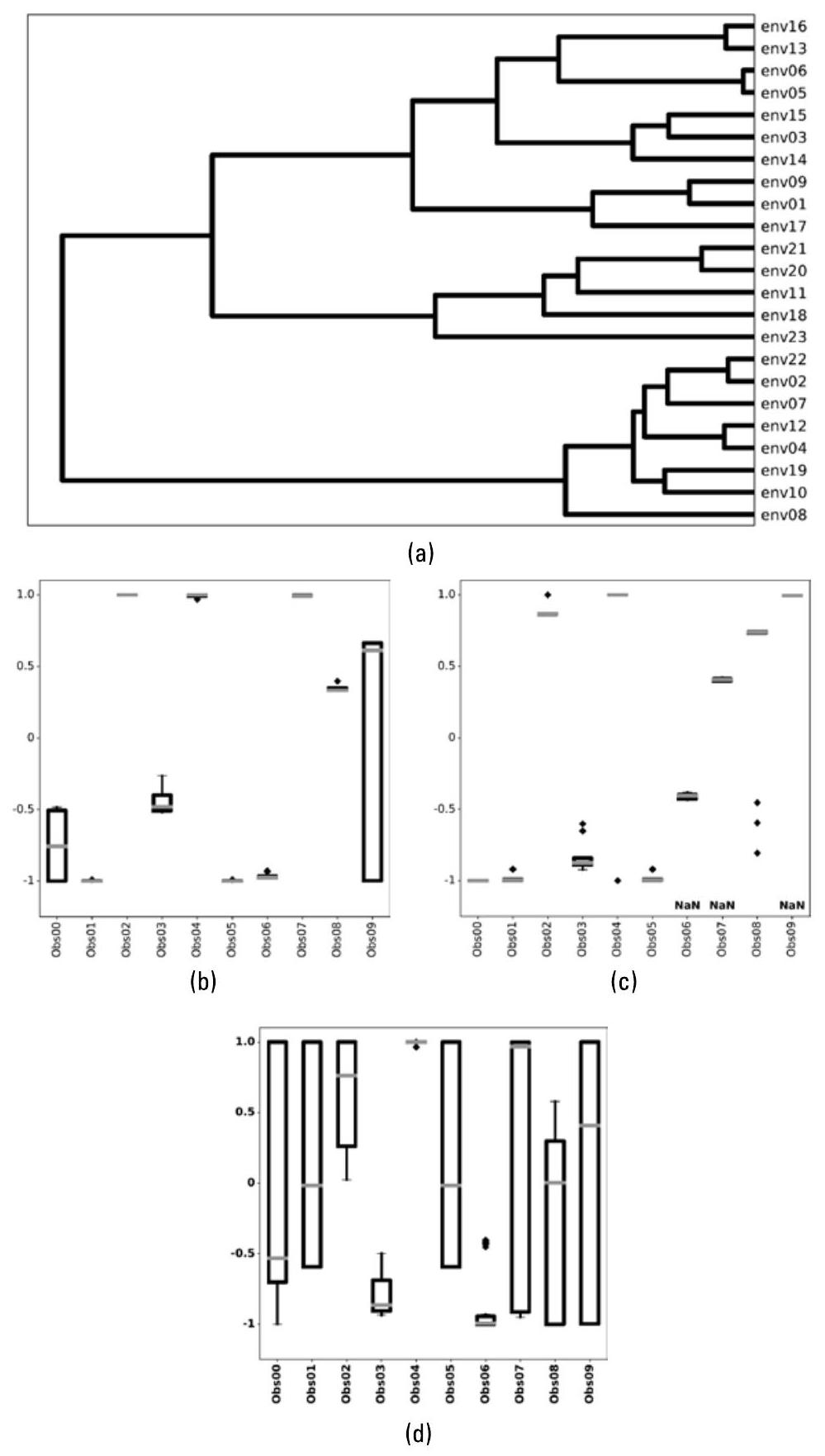
图2.3 树状图用于可视化各项目之间的相似程度。每个环境由箱线图中所示的多个特征进行描述。(a) 树状图,其中横轴表示环境之间的距离;(b) 环境16;(c) 环境06;(d) 环境21。(图7.3对箱线图进行解释。)
算法 2.1 scikit-learn 代码绘制类似于图 2.3 的树状图,以展示射频(RF)环境之间的相似性。
import csv
import numpy as np
import pandas as pd
import matplotlib.pyplot as plt
from scipy.cluster.hierarchy import dendrogram
from scipy.cluster.hierarchy import linkage
####################
#加载数据集:列包括(Environ)标签和多个可观测量(obs)
def getData():
environs = pd.read_csv('radardata.csv')
environs = environs.set_index('Environ')
return environs
####################
#高效方法:将 NaN 替换为该环境/可观测量对应的均值(mu)
def cleanNaNs(df):
newDF = pd.DataFrame()
environs = np.unique(df.index)
for environ in environs:
# 获取该环境下的所有样本实例
instances = df.loc[df.index == environ]
# 仅对包含 NaN 值的列进行替换
nanCols = instances.isnull().any(axis=0)
for i in instances.columns[nanCols]:
# 将该列中的 NaN 替换为其他有效值的均值
instances[i].fillna(instances[i].mean(), inplace=True)
newDF = newDF.append(instances)
return newDF
####################
if __name__ == '__main__':
df = getData()
df = cleanNaNs(df)
nEnvirons = len(np.unique(df.index))
fig, ax = plt.subplots(figsize=(12, 8))
Z = linkage(df, method='ward')
dendrogram(Z, truncate_mode='lastp',
p=nEnvirons, orientation='left')
fig.tight_layout()
plt.savefig('dendrogram.pdf')
plt.close()
2.2 用于改变行为的控制参数(Control Parameters)¶
控制参数(control parameters),或称可控变量(controllables),可包括节点可用的任何操作。每个节点 \(n\) 都有一组可控变量 \(c_{n}\),这些变量符合该平台所具备的能力;这些即为平台的“调节旋钮”(knobs)或自由度(degrees of freedom)。每个节点拥有 \(\overline{c_{n}}\) 个可控变量。策略(strategy)\(s_{n}\) 是控制参数的一种组合,其中每个可控变量都被赋予一个特定值。每个节点在每个时间步(timestep)所能采用的策略最大数量为 \(\Pi_{\forall c} v_{c}\),其中 \(v_{c}\) 表示控制参数 \(c\) 可能取值的数量;如果所有 \(c_{n}\) 个可控变量均为二元开关(binary on/off)类型,则策略总数为 \(2^{c_{n}}\),这一数量远超人类的管理能力。例如,若有五个可控变量:\(c_{1}\)、\(c_{2}\)、\(c_{3}\) 为二元开关,\(c_{4}\) 可取 3 个值,而 \(c_{5}\) 可取 10 个值,则策略总数为 \(2^{3} \times 3 \times 10 = 240\) 种。当可控变量可取连续值或大量离散值时,每个节点的策略数量可能趋于无限。
控制参数是由平台有意暴露出来用于调节的;通过从多个组件中选择控制参数,可隐式地捕获跨层(cross-layer)问题。对于认知无线电(Cognitive Radio, CR)系统,这些参数通常位于协议栈或无线电设备中,例如可通过管理信息库(Management Information Base, MIB)或任务数据文件(Mission Data File, MDF)进行设置的参数。
算法或模块的选择允许对软件和固件流程进行在线重构(online reconfiguration)。若将每个可用模块建模为二元开关(on/off),则每个模块对应一个控制参数 \(x\):当 \(x=1\) 时表示应调用该模块,\(x=0\) 时表示该模块不应运行[9]。
层级式控制参数(hierarchical control parameters)是指仅在关联的参数或算法被启用时才有效的参数。例如,主动式(proactive)路由协议需要设置“Hello”消息的发送周期,而反应式(reactive)协议则需要设定生存时间(time-to-live)阈值。
我们假设系统由一组异构节点(heterogeneous nodes)组成。每个节点都配备一个优化器(optimizer),可配置其自身能力,包括射频(RF)硬件、现场可编程门阵列(FPGA)、IP协议栈中的技术,甚至在适当情况下可调用RF系统之外的功能,例如指令平台移动或请求人工用户介入。具体示例包括:
- 天线技术,如波束成形(beamforming)、零点置零(nulling)和灵敏度时间控制(sensitivity time control);
- 射频前端技术,如模拟可调滤波器或频分复用(frequency-division multiplexing);
- 物理层参数,如发射功率、陷波滤波器(notch filters)或傅里叶变换频点数量;
- 媒体访问控制(Medium Access Control, MAC)层参数,如动态频谱接入(dynamic spectrum access)、帧大小、载波侦听阈值、可靠性模式、单播/广播选择、定时器、竞争窗口算法(如线性或指数退避)、邻居聚合算法、驻留时间(dwell time)、脉冲重复间隔(pulse repetition interval)和脉冲压缩长度;
- 网络层或多节点协同参数,如邻居发现算法及其阈值与定时器、多基地雷达(multistatic radar)中需组合的发射/接收对数量,以及需干扰的接收机数量;
- 加密设置,如加密算法(cipher)和哈希函数(hash function);
- 应用层参数,如压缩等级(例如 JPEG 质量 1 与 10)、数据类型(如音频 vs. 视频)、扫描模式,或对单个雷达回波的加权方式;
- 雷达/反雷达相关参数,如调制类型、天线扫描速率与波束指向序列、接收机带宽与驻留时长、空时自适应处理(Space-Time Adaptive Processing, STaP)参数,以及电子攻击(Electronic Attack, EA)技术;
- 超出射频框架的概念,例如与人类或平台交互时的操作(如投放箔条(chaff)以改变空气的电磁特性,或部署拖曳式阵列(towed array)以提升空间分集能力)。
可控量可能附带相关成本(costs),这些成本必须在度量指标(metrics)中予以考虑。成本可包括启动(ramp-up)、维持(maintenance)或关闭(ramp-down)阶段的开销。成本可反映任何相关度量,包括时间、功耗或内存占用。成本可能依赖于可控量的具体取值;例如,频繁的“Hello”消息定时器比低频设置消耗更多功率和带宽。一组可控量的成本可以不同方式组合:例如,实施延迟(latency-to-implement)属于并行成本,而发射功率则需累加。
可控量的取值可能互斥(mutually exclusive)。例如,合成孔径雷达(Synthetic Aperture Radar, SAR)可控制积分时间或方位分辨率,但无法同时控制两者。
可控量并非始终可用。例如,任务的不同阶段可能启用或禁用平台的某些能力(如任务的情报收集阶段可能禁用会暴露节点存在的动作,而在打击阶段则重新启用这些能力)。
人工智能中的“可调自主性”(adjustable autonomy)概念也可用于启用或禁用某些能力。在可调自主系统中,人类用户可赋予平台不同级别的自主权[10]。例如,用户可选择低自主级别,通过操纵杆(“joysticks”)直接控制飞行器;也可选择高自主级别,仅通过地理标记(geotag)指定感兴趣区域,由平台自主执行监视任务。
2.3 用于评估性能的度量指标(Metrics)¶
系统需求直接驱动在复杂系统中识别适当度量指标(metrics)的过程。选择一组良好的度量指标,可能是构建一个能有效自主选择动作的系统中最困难的部分。每个度量指标必须准确反映可用动作与系统高层需求之间的关联。该指标集合应尽可能完整,且不包含冗余的测量项。度量指标应具备相关性(relevant)、可测性(measurable)、可归责性(responsible)和资源可行性(resourced)[11]。
度量指标存在多个层次,但其中最重要的两类是直接影响任务成功(mission success)和电子战(EW)性能的指标。任务成功指标(如平台生存能力、任务毁伤概率(probability of mission kill))对军事决策者和用户最为关键。这些指标用于评估子组件在不同作战条件下的性能,并可在设计阶段或通过在线自评估与行为调整进行直接优化。
度量指标量化了EW系统在任务层面和态势层面满足需求的程度。每个节点包含 \(\overline{m_{n}}\) 个度量指标。决策者选择可控量 \(\mathbf{c}_{\mathbf{n}}(t)\),以影响未来时刻 \(t^{\prime} > t\) 的度量指标 \(m_{n k}(t^{\prime})\)。这些指标可基于模型计算,也可通过第4.2节及第7章所述的实证学习方法获得。度量指标包括:
- 效能类概念:包括吞吐量(throughput)、时延(latency)、灵敏度(sensitivity)、比特误码率(bit-error rate, BER)、消息误码率(message error rate)、检测概率(\(P_d\))、虚警概率(\(P_{fa}\))、杂波噪声比(clutter-to-noise ratio),以及干扰效能(jamming effectiveness)等广义概念(如干扰信号比 J/S 或电子战作战毁伤评估 EW BDA)。需要注意的是,EW BDA 是对敌方系统效能的推断性指标,无法直接测量,例如雷达航迹质量(包括角度、距离、速度及协方差矩阵估计等)。
- 成本因素:包括时间、功耗、控制开销、时间线占用、被探测概率(probability of detection),甚至平台的磨损与损耗(wear-and-tear)。
- 其他概念:包括决策管理(DM)不确定性、启发式偏好(heuristic preference)或应对突发情况的灵活性。例如,设计者可能更倾向于基于现场可编程门阵列(FPGA)的动作而非基于软件的动作,或希望系统在时间上保持相对稳定(即不在每个时间步都改变动作)。信息价值(Value of Information,见第6.1.4节)也可作为一个重要度量指标。当系统使用机器学习(ML)来学习模型 \(f_{k}(o, s)\) 时,决策置信度(decision confidence)或适用域(applicability domain)可能成为关键指标。(统计模型的适用域是指该模型预期能给出可靠预测的底层模式子集。)
Haigh 等人[1]探讨了四种潜在的度量指标:(1) 多种异构业务流的应用层服务质量(Quality-of-Service, QoS)需求;(2) 节点级电池寿命约束;(3) 节点级被探测概率约束;(4) 网络因应用层数据传输而浪费带宽所造成的成本。表4.1列出了面向5G定位的一些度量指标。 度量指标(metrics)与可观测量(observables)之间存在一种内在张力,因为许多项既可作为指标也可作为可观测量。例如,比特误码率(BER)可作为支持低截获概率/低探测概率(Low Probability of Intercept / Low Probability of Detection, LPI/LPD)指标的可观测量,也可作为电子防护(EP)系统试图最小化的度量指标。将某一特征归类为度量指标还是可观测量,取决于具体任务和问题定义。在系统构建初期,通常最合理的方式是从最简单的度量指标(即最容易测量的)入手,而将更复杂或需推断的特征作为可观测量。待系统稳定后,可将某些特征从可观测量转换为度量指标。例如,初始系统可能仅优化 BER,随后再扩展至吞吐量和时延等更广义的概念。
每个度量指标可关联一个权重(weight),用于指定该指标对整体性能的影响程度。可使用标量值对各指标进行加权求和;也可使用 lambda 函数定义更灵活的结构,以处理非均匀或非线性的指标。例如,若 BER 超过某一阈值,或时延超出可接受时限,则可将该指标置零。图 2.4 示意了几种可能的权重函数。
度量指标的值应进行归一化(normalized),以确保大数值与小数值在相同尺度上被评估。指标可采用线性尺度或对数尺度(如分贝 dB)进行测量,归一化方法应根据所选尺度相应调整。权重用于控制各指标的相对重要性。在最大化效用(utility)时,效能类指标应赋予正权重,而成本类指标则应赋予负权重。
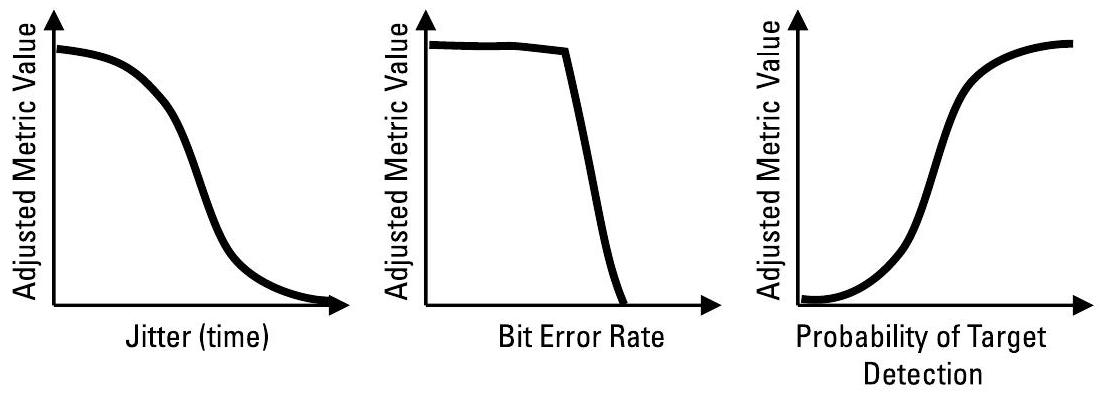
图 2.4 权重可以以不同方式调整度量指标的值,并且可能随任务阶段而变化(例如,辐射源处于搜索、捕获或跟踪模式时)。
最有效的度量指标是那些具备快速、可测量反馈的指标。反馈由电子支援/作战毁伤评估(ES/BDA)模块计算得出,用于将观测到的指标值与学习模型所估计的值进行比较。以下问题有助于评估指标的有效性:
- 该指标能否直接测量? BER 可直接测量,而 EW BDA 则需推断。系统可同时使用这两类指标,但直接可测的指标在开发和应用上要容易得多。
- 有多少节点参与该指标的测量? BER 可在单个节点上测量;往返时延(roundtrip time)需单一流中所有节点共同测量;EW BDA 可在本地节点或小规模节点团队内构建。通常,参与节点越少,计算越快、越准确。多节点测量会引入延迟,可借助共识传播(consensus propagation)等技术进行计算[12]。
- 反馈速度如何? BER 基本是瞬时的;吞吐量通常有秒级延迟;目标跟踪精度通常以分钟计;而任务中人员伤亡数量则需数小时甚至数天才能评估。随着反馈间隔增大,系统更难将特定动作与其效果关联起来。理论上系统可自动学习这些关系,但所需的时间和数据量往往难以承受。
- 该指标值是否会随时间或其他上下文变化? 例如,监视雷达中的目标跟踪精度以分钟为单位评估,而火控系统仅需数秒即可生成射击解算。此外,精度可能仅在武器制导的初始射击选择和中段/末段阶段才至关重要。若 EW 系统在敌方导弹制导雷达飞行时间的 90% 内成功实施欺骗,但未能阻止最后 10% 的飞行阶段,则任务仍属失败。因此,必须在指标最相关的时刻对其进行评估,以确保其在整体交战结果中的意义。上述部分问题可通过 lambda 函数处理,其他问题则可能需要调整效用函数的结构。
2.4 构建效用函数(Creating a Utility Function)¶
在能够自主选择行动的系统中,效用函数(utility function)用于刻画各利益相关方的目标。效用函数的结构取决于系统的具体任务与能力。该函数以一种在作战上具有意义且在实践中可优化的方式,对各项指标进行组合。Callout 2.1给出了效用函数的形式化定义,并说明了如何对其进行简化,以便在实际中实现优化。
通常,通信(comms)系统的效用函数比雷达系统的更为精细(nuanced),因为通信领域可获取的指标更多。联合优化(如电子防护/电子攻击(EP/EA)或通信/雷达联合优化)则进一步增加了复杂性。
在复杂系统中,需求驱动着指标选择、权重设定以及组合方式的确定过程。目标与约束来源于用户与任务需求、环境限制以及装备能力。Haigh 等人 [1] 提出了一种通过策略包(policy bundles)实现在任务中动态调整效用函数的方法。重要的是,必须全面纳入所有利益相关方的目标。
一个简单的效用函数可表示为各指标的加权和:
其中,每个权重 \(w_{n k}\) 为标量值,每个指标 \(m_{n k}\) 是节点可观测量(observables)与可控量(controllables)的函数,即 \(m_{n k}=f_{n k}\left(\mathrm{o}_{n}, \mathrm{c}_{n}\right)\)。当权重为 lambda 函数(即权重本身是指标的函数)时,效用函数可表示为:
当指标之间并非相互独立时,可能需要采用其他函数结构。例如,截止时间前的任何通信流量应使用抖动(jitter)进行评估,但一旦超过截止时间,数据的送达便不再产生任何收益。若时延 \( m_1 < 3 \) 是一个硬性约束,而抖动 \( m_2 = 0 \) 是一个软性约束,则该概念的一个良好数学表达为:
其中,\(w_{1}(\cdot)\) 为单位阶跃函数(unit step function),\( w_{2} > 0 \) 为一个参数,用于刻画抖动约束的“软度”(即对抖动的容忍程度)。图2.5展示了该函数对应的效用值。需要注意的是,对 \( m_1 \) 和 \( m_2 \) 的估计仍可能分别依赖于学习得到的模型 \(f_{1}(o, s)\) 和 \(f_{2}(o, s)\)。
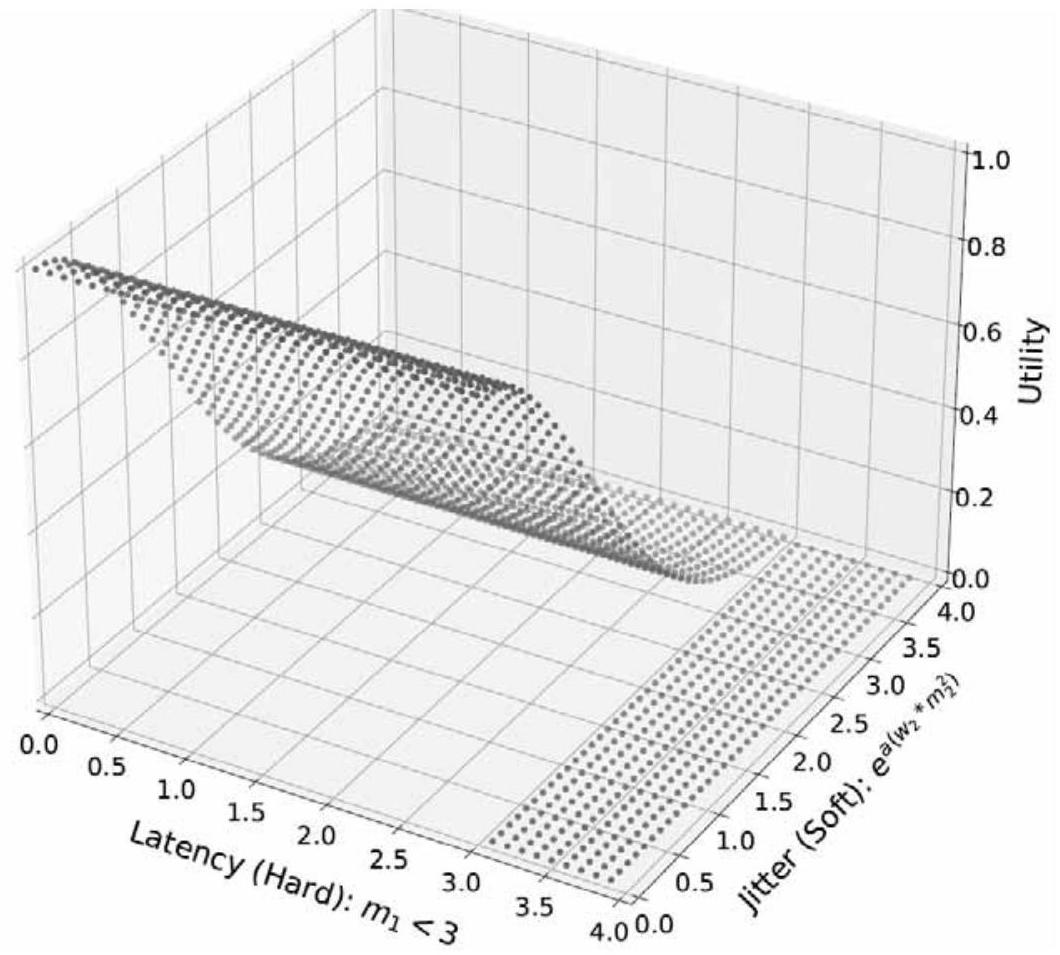
图2.5 该服务质量(QoS)指标结合了时延的硬性截止约束与抖动的软性约束 [1];此处我们取 \( w_{2} = 0.3 \)。
例如,电子支援(Electronic Support, ES)系统的截获概率(Probability-of-Intercept, POI)目标为 100%。实现 100% POI 的唯一方法是构建一种凝视型(staring)架构,对该频谱进行连续监视。无法提供连续监视的架构必须采用扫描模式,通过顺序调谐与驻留(dwelling),在辐射源发射信号且接收机恰好驻留在其频率上的时刻完成截获。在此情况下,一个简化的效用函数可表示为:
\(\mathrm{POI} = f(\mathrm{RF}\text{ 环境可观测量}, \text{扫描速率}, \text{重访模式}, \text{驻留时间}, \ldots, \text{频率})\) ,与大多数战场毁伤评估(Battle Damage Assessment, BDA)指标类似,POI 无法直接测量,必须通过 ES/BDA 功能进行推断。
第 5.1.1 节描述了使用和优化多目标效用函数(multiobjective utility function)的不同方法。博弈论(Game Theory)(见第 6.2 节)可在效用函数之上增加一层概率模型,用于处理存在自私但理性个体的环境。
Callout 2.1 形式化问题定义
真实的效用函数(utility function)\(\mathcal{U}\) 必须加以简化,以便在实践中可优化。
考虑一个包含 \(N\) 个异构节点的电子战(Electronic Warfare, EW)系统。每个节点 \(n \in N\) 具有以下内容:
- 一组 \(\overline{o_{n}}\) 个可观测特征(observable features),记为 \(\mathbf{o}_{n} \triangleq\left(o_{n 1}, o_{n 2}, \ldots, o_{n o_{n}}\right)\)。
- 一组 \(\overline{c_{n}}\) 个控制参数(control parameters),记为 \(\mathbf{c}_{n} \triangleq\left(c_{n 1}, c_{n 2}, \ldots, c_{n c_{n}}\right)\)。
将不可观测的上下文信息(unobservable contextual information)记为 \(z\)。
为刻画随时间的变化,记 \(\mathbf{c}_{\mathbf{n}}(t)\) 为控制参数 \(c_{n}\) 在时刻 \(t\) 的取值,对 \(\mathbf{o}_{\mathbf{n}}\) 和 \(\mathbf{z}\) 同理。
与该系统相关联的是一个实值标量效用度量(utility measure)\(\mathcal{U}(t)\),用于表征在时刻 \(t\) 的全局、全网性能指标。该度量是自任务开始以来所有节点的控制参数、可观测特征和不可观测因素的函数 \(\mathcal{F}\):
目标是求解如下分布式优化问题:
设计一种完全分布式的算法,使得每个节点 \(n\) 仅利用其自身先前的可观测特征 \(\mathbf{o}_{n}(0), \ldots, \mathbf{o}_{n}(t)\) 和控制参数值 \(\mathbf{c}_{n}(0), \ldots, \mathbf{c}_{n}(t)\) 来确定其在时刻 \(t\) 的控制参数 \(\mathbf{c}_{n}(t)\),从而在每个时刻 \(t\) 最大化(或最小化)\(\mathcal{U}(t+1)\)。*
\({ }^{*}\) 优化目标可扩展为计算整个任务周期的效用,而非仅针对每个连续的瞬时时刻 \(t\)。
挑战在于,由于存在不可观测因素 \(z\) 以及复杂的节点内(intra-node)与节点间(inter-node)交互,我们无法为 \(\mathcal{F}\) 给出精确的解析表达式。因此,本书及相关工作中描述的算法通常通过使用局部的、无记忆(memory-less)的 \(\mathcal{F}\) 近似来简化问题:每个节点使用 \(\tilde{U}_{n}\) 来近似真实的效用 \(\mathcal{U}\)。
本质上,节点 \(n\) 假设历史决策(\(\mathbf{c}_{n}(t^{\prime} < t)\))以及邻近节点(\(n^{\prime} \neq n\))所作的决策,会隐式地体现在其当前可观测特征 \(\mathbf{o}_{n}(t)\) 中。例如,若邻居节点 \(n^{\prime}\) 提高了数据速率,节点 \(n\) 将观测到拥塞程度的增加。当其他节点 \(n^{\prime} \neq n\) 显式地将其先前的可观测特征或控制参数设置共享给节点 \(n\)(即 \(\mathbf{o}_{n^{\prime} \neq n}(t^{\prime} < t)\) 或 \(\mathbf{c}_{n^{\prime} \neq n}(t^{\prime} < t)\)),这些值便成为 \(\mathbf{o}_{n}(t)\) 中的附加特征。
为配置各节点,在每个时间步 \(t\),每个节点选择一个策略(strategy)\(\mathbf{s}_{n}(t)\),该策略是控制参数 \(\mathbf{c}_{n}(t)\) 的一种特定设置,旨在优化该效用曲面上的性能:
(或者,等价地使用 \(\arg\min\)。)在每个时间步,节点 \(n\) 有 \(\Pi_{\forall c_{n}} v_{c_{n}}\) 个候选策略,其中 \(v_{c_{n}}\) 表示给定控制参数 \(c_{n}\) 可取的值的数量。当控制参数为连续取值时,该数量变为无穷大。
为支持在任务执行过程中动态调整系统行为,我们将 \(\tilde{U}_{n}\) 表示为一组 \(\overline{m_{n}}\) 个度量(metrics)\(m_{n}\),从而允许用户在任务过程中调整相应的权重(weights)\(w_{n}\)。\({ }^{\dagger}\) 因此,对于任意节点 \(n \in N\),\(\tilde{U}_{n}(t)\) 是其度量及其权重的函数,而每个度量本身又是该节点可观测特征与控制参数的函数:
\({ }^{\dagger}\) 权重不一定为标量值;对于某些度量,使用 lambda 函数可能更为合适。
函数 \(f_{n k}\) 是人工构建或通过经验学习得到的模型。在时刻 \(t\),模型 \(f_{n k}\) 利用可观测特征 \(\mathbf{o}_{n}(t)\) 和控制参数 \(\mathbf{c}_{n}(t)\) 预测下一时刻的度量值 \(m_{n k}(t+1)\),从而使节点 \(n\) 上的决策者能够选择最优的控制参数设置。
在本书其他部分,我们通常无需如此详细的符号表示。因此,我们采用如下简写形式:\(m_{k}=f_{k}(o, s)\),或更简洁地写作 \(m=f(o, s)\)。同理,\(\tilde{U}\left(s_{i}\right)\) 是候选策略 \(s_{i}\) 效用的简写。
与更常见的记法 \(y=f(x)\) 不同,我们明确区分可观测特征(observables)与控制参数(controllables),以凸显系统进行决策的能力。这种记法类似于马尔可夫决策过程(Markov Decision Processes, MDPs)中的表示方式,其中奖励(reward)被表达为状态(state)和动作(action)的函数:\(U=R(s, a)\)(见第 6.1.3 节)。
2.5 效用函数设计考量(Utility Function Design Considerations)¶
从架构设计与实现的角度出发,建议考虑以下几点:
- 选择单一、快速且易于测量的度量指标(如比特误码率 BER)用于测试决策流水线。
- 设计函数结构时,应便于新增度量指标和新需求,从而有效应对系统中计划内与计划外的变化。
-
在逻辑上尽可能保持各度量指标相互独立,直至最后必须组合的时刻,以支持任务过程中优先级的快速调整。特别值得注意的是,若采用机器学习(ML)技术学习可控量与度量指标之间的关系(即 \(m_{k}=f_{k}(o, s)\)),这种关注点分离(separation of concerns)至关重要。某些系统会构建单一模型 \(\tilde{U}_{n}=\tilde{\mathcal{F}}_{n}(o, s)\),将各组成指标隐式嵌入其中;这种做法意味着系统要么无法重新分配任务,要么必须彻底重构已有经验。
例如,通过将检测概率(\(P_d\))与虚警概率(\(P_{fa}\))保持分离,系统可在接收机工作特性(Receiver Operating Characteristic, ROC)曲线上动态选择其工作点。
第 4.2 节描述了从实测数据中学习度量指标的方法,第 7 章则阐述了任务执行过程中的在线学习流程。
-
由于不同节点可能具备不同能力与需求,不同节点(或节点类型)。效用函数无需在所有节点上完全一致:每个节点可拥有其独特的效用函数。在异构节点集合中,效用评估因网络连接间歇性和成员动态变化而更加复杂。真实效用函数 \(\mathcal{U}\) 考虑的是一个完全异构的团队,其中各节点具有不同的能力与任务;而近似效用函数 \(\tilde{U}_{n}\) 仅针对特定节点 \(n\),可使用与其他节点不同的度量指标、权重、可观测量和可控量。
- 为本质上属于多节点概念的度量指标,设计高效的信息共享机制。共识传播(consensus propagation)是一种有效方法,可最小化测量延迟,且无需系统预先知道网络中节点总数[1, 12]。每个节点 \(n\) 计算其对共享度量指标的局部贡献,并在可用时融合来自其他节点 \(n^{\prime}\) 的估计值。第 6.1.4 节讨论了知识共享问题。
- 避免创建用于为分布式节点确定策略或效用的中心化节点。中心化系统会引入通信延迟、信息不一致与过载,更重要的是,会形成单点故障。仅在无需快速响应的场景下,才可将中心节点用作建议源;也可将其作为不可靠的信息存档(前提是通信资源充足)。
电子战(EW)条令中定义的目标可能需要调整或扩展,以纳入传统上未被考虑的概念。例如,削弱敌方决策管理(DM)能力,或导致其相关流程失效(如破坏敌方飞机航迹自动化系统,或通过增加人工干预需求,降低敌方操作员可独立管理的目标数量)。
2.6 结论¶
一个具备完全能力且高效的电子战(EW)系统,其核心基础在于一个能够衡量系统性能的效用函数(utility function),从而为任务选择优良的策略。该效用函数以数学上可优化的方式,融合了用户目标、任务需求以及环境约束。
第 4 章介绍了电子支援(ES)及用于决策的可观测特征;目标函数的结构支持多种类型的可观测量,包括原始数值、基于物理模型导出的量,以及通过学习模型推断出的特征。第 5 章和第 6 章阐述了如何将目标函数应用于决策管理(DM):包括如何利用优化与调度技术为电子防护(EP)和电子攻击(EA)选择策略,以及如何通过规划方法实现面向更长期的基于证据的决策管理(Evidence-Based Management, EBM DM)。
References¶
[1] Haigh, K. Z., O. Olofinboba, and C. Y. Tang, "Designing an Implementable User-Oriented Objective Function for MANETs," in International Conference on Networking, Sensing and Control, IEEE, 2007.
[2] Jouini, W., C. Moy, and J. Palicot, "Decision Making For Cognitive Radio Equipment: Analysis of the First 10 years of Exploration," EURASIP Journal on Wireless Communications and Networking, No. 26, 2012.
[3] Arrow, K., "Decision Theory and Operations Research," Operations Research, Vol. 5, No. 6, 1957.
[4] Roth, E., et al., "Designing Collaborative Planning Systems: Putting Joint Cognitive Systems Principles to Practice," in Cognitive Systems Engineering: A Future for a Changing World, Ashgate Publishing, 2017, Ch. 14.
[5] Box, G., "Robustness in the Strategy of Scientific Model Building," in Robustness in Statistics, Academic Press, 1979.
[6] Rokach, L., and O. Maimon, "Clustering Methods," in Data Mining and Knowledge Discovery Handbook, Springer, 2005.
[7] Bair, E., "Semi-Supervised Clustering Methods," Wiley Interdisciplinary Reviews. Computational Statistics, Vol. 5, No. 5, 2013.
[8] MacQueen, J., "Methods for Classification and Analysis of Multivariate Observations," in Berkeley Symposium on Mathematical Statistics and Probability, 1967.
[9] Haigh, K. Z., S. Varadarajan, and C. Y. Tang, "Automatic Learning-Based MANET CrossLayer Parameter Configuration," in Workshop on Wireless Ad Hoc and Sensor Networks, IEEE, 2006.
[10] Mostafa, S., M. Ahmad, and A. Mustapha, "Adjustable Autonomy: A Systematic Literature Review," Artificial Intelligence Review, No. 51, 2019.
[11] US Army Headquarters, "Targeting," Department of the Army, Tech. Rep. ATP 3-60, 2015.
[12] Moallemi, C., and B. Van Roy, "Consensus Propagation," Transactions on Information Theory, Vol. 52, No. 11, 2006.