3 机器学习入门¶
人工智能(Artificial Intelligence, AI)是计算机科学中的一个领域,融合了数学、工程学和神经科学。图3.1展示了AI众多子领域中的一部分。机器学习(Machine Learning, ML)只是AI的众多子领域之一,而人工神经网络(Artificial Neural Networks, ANNs)则是机器学习中众多技术家族之一。
“AI” 并不等同于 “深度学习(Deep Learning, DL)。”
\(AI \supset ML \supset DL\)。
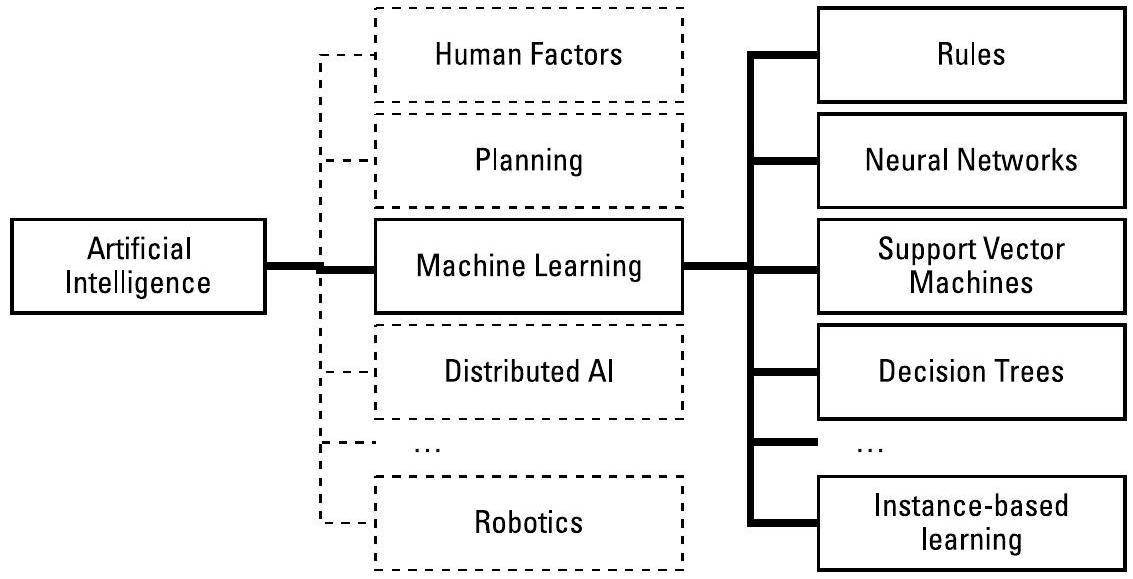
图3.1 如同数学包含微积分、几何和代数一样,人工智能(AI)也包含多个子领域,如规划、机器学习(ML)和机器人学;而机器学习领域本身又包含多种技术。
本书绝非一部关于人工智能的专著,而是选取了当前最直接适用于认知电子战(Cognitive Electronic Warfare, Cognitive EW)的AI技术进行介绍。《人工智能:一种现代方法》(AI: A Modern Approach)[1] 一书从构建完整智能体(intelligent agent)的视角出发,对人工智能概念进行了深入探讨。
第5章和第6章讨论了规划(planning)、优化(optimization)、分布式人工智能(distributed AI)以及人因工程(human factors)等AI技术,因为这些内容在决策管理(Decision Management, DM)中构成一个逻辑单元。
然而,机器学习在整个电子战(Electronic Warfare, EW)系统中具有更广泛的相关性。认知电子战技术依赖机器学习对电磁频谱进行建模、理解参与方(如辐射源和对手),并学习如何高效地进行规划与优化。任务中学习(in-mission learning)是完整认知电子战系统的关键组成部分;若缺乏这一能力,系统将无法应对新型辐射源(novel emitters)。
学习算法(learning algorithm)利用经验数据(empirical data)来学习对问题空间的模型。图3.2展示了构建机器学习模型的步骤。所有机器学习模型均遵循相同的基本流程进行训练与测试。算法4.1给出了实现该循环的一个代码示例。
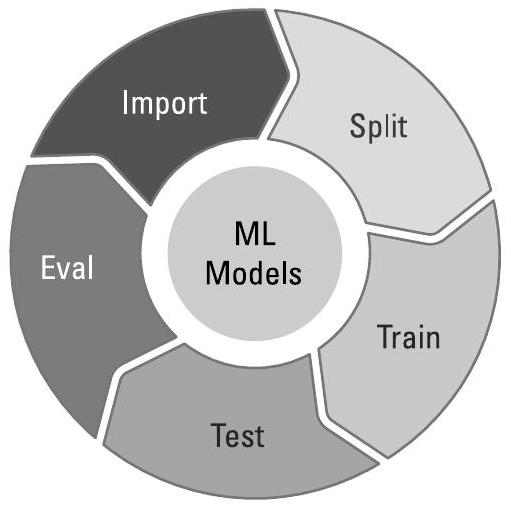
图3.2 所有机器学习模型均采用相同的基本流程进行训练和测试。
学习算法通常分为监督学习(supervised learning)和无监督学习(unsupervised learning)两类:在监督学习中,算法在训练时被提供真实标签(ground truth labels)\(Y\);而在无监督学习中则不提供这些标签。监督学习器利用有限数量的样本 \((X, f(X))\),从输入空间 \(X\) 到输出空间 \(Y\) 构建一个函数 \(f: X \rightarrow Y\)。该模型 \(f\) 用于逼近真实的输出空间 \(\mathcal{F}\)。无监督学习器仅使用输入数据 \(X\) 来构建模型,以发现未标注数据中的隐藏模式。例如,一个监督式的调制分类器(modulation classifier)会尝试为射频(RF)环境中的每一次观测分配其真实的调制类型标签;而一个无监督的调制聚类(modulation-clustering)算法则在不知道真实标签的情况下将相似的观测分组,其输出 \(Y\) 为每个观测对应的聚类编号。
半监督学习(semi-supervised learning)方法仅包含少量带标签样本和大量无标签样本。在强化学习(Reinforcement Learning, RL)方法中,学习器通过在环境中执行动作自行获取标签。强化学习构成了任务中学习(in-mission learning)的基础(见第7章)。
表3.1列出了机器学习的一些常见用途;本书还提供了许多适用于电子战(EW)的其他实例。第3.6节介绍了电子战工程师在选择机器学习算法时应考虑的一些权衡因素。第11.2节列出了可用于快速原型开发和支持数据集的机器学习工具包。
表3.1 机器学习算法的常见应用
| 应用 | 描述 | 电子战示例 |
|---|---|---|
| 分类(Classification) | 为样本分配一组离散类别中的标签(监督学习) | 第4.1.3节 |
| 回归(Regression) | 估计一个数值(监督学习) | 第4.2节 |
| 聚类(Clustering) | 将相似的样本归为一组(无监督学习) | 第2.1.1节 |
| 异常检测(Outlier detection) | 识别与典型样本显著不同的实例(无监督学习) | 第4.4节 |
3.1 常见的机器学习算法(Common ML Algorithms)¶
机器学习算法种类繁多;图3.1仅列举了其中在电子战(EW)中较为常用的一些。如需更深入的分析,可参考《百页机器学习书》(The Hundred-page Machine Learning Book)[2],或更为深入的《统计学习基础》(The Elements of Statistical Learning)[3]。此外,Vink 与 de Haan [4] 在目标识别的背景下对各类机器学习算法提供了简要描述,而 Kulin 等人 [5] 则探讨了用于频谱学习(spectrum learning)的机器学习相关数学原理。
基于实例的方法(instance-based methods)将所有训练样本存储在内存中,推理阶段通过将新样本与全部训练样本进行比较来做出预测。这类方法没有训练时间,但推理时间随训练数据规模而增长。查表法(table-lookup)、哈希(hashing)和最近邻(nearest neighbor)方法是常见的基于实例的学习方法 [1]。如果一个电子战系统能够自动将新威胁添加到威胁库中,那么传统电子战中“在库中查找威胁”的操作实际上就是一种基于实例的学习方法。
基于模型的方法(model-based methods)利用训练数据构建一个具有参数的模型;模型的大小(即参数数量)不随数据量变化。其训练时间与训练数据规模相关,而推理时间则为常数。支持向量机(Support Vector Machines, SVMs)(第3.1.1节)和人工神经网络(Artificial Neural Networks, ANNs)(第3.1.2节)是两种在电子战中尤为相关的基于模型的方法。
3.1.1 支持向量机(Support Vector Machines, SVMs)¶
支持向量机(SVMs)是一类用于聚类(clustering)、分类(classification)、回归(regression)和异常检测(outlier detection)的机器学习方法 [6–8]。SVMs 具有优异的泛化性能(generalization performance),尤其适用于处理复杂的非线性关系,以及在可用训练数据有限的情况下。
SVMs 在其决策函数中仅使用训练数据点的一个子集,这些点被称为支持向量(support vectors)。每个 SVM 构建一个决策函数,用于估计决策边界——即最大间隔超平面(maximum-margin hyperplane)——以及围绕该超平面的一个可接受的硬间隔(hard margin)或软间隔(soft margin)。支持向量即为位于间隔边界上的样本点,如图3.3所示。
SVMs 通过使用核函数(kernel functions)或“核技巧”(kernel tricks)[9],能够高效地实现非线性分类。借助核技巧,非线性分类器可将输入映射到高维特征空间中。
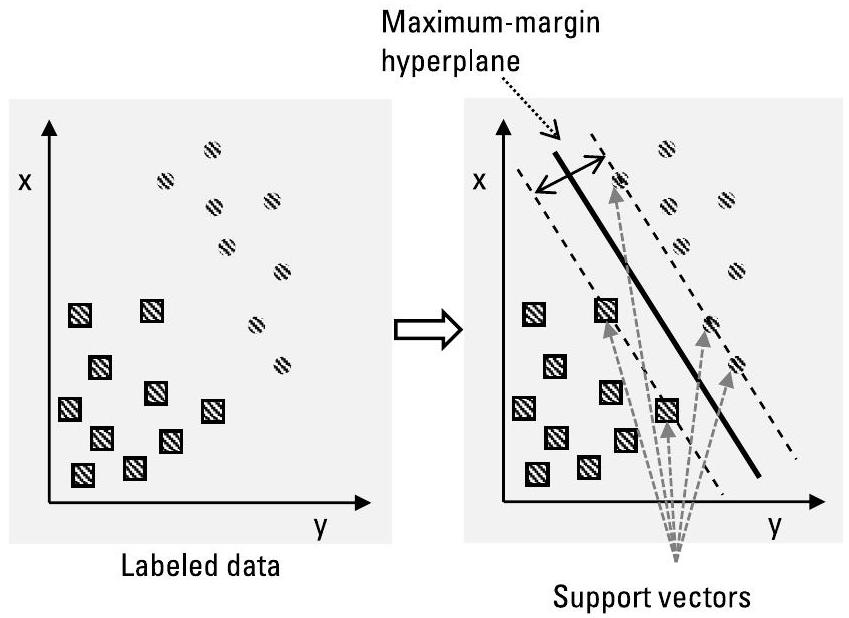
图3.3 支持向量机(SVMs)能够在数据有限的情况下高效学习复杂函数。
3.1.2 人工神经网络(Artificial Neural Networks, ANNs)¶
人工神经网络(ANNs)是一类受生物神经系统(如大脑)信息处理方式启发的算法。这些算法通过模拟神经元及其相互连接,来复现大脑的学习机制。ANNs 的概念起源可追溯至20世纪40年代 [10];1958年,Rosenblatt 设计了感知机(perceptron),这是一种用于模式识别的算法 [11]。1975年,Werbos 提出的反向传播(back-propagation)算法 [12] 使得多层网络的实用化训练成为可能:该算法通过逐层向上传播误差项,并在每个节点处调整权重,从而实现网络参数的优化。
ANNs 由输入层、隐藏层和输出层组成,如图3.4所示。网络的层数即指其深度(depth)。现代 ANNs 通常包含多个隐藏层,因此被称为深度学习(deep learning)、深度神经网络(deep neural networks)或简称为 DeepNets。DeepNets 能够发现人类难以手动提取或设计的复杂模式或潜在特征(latent features)。
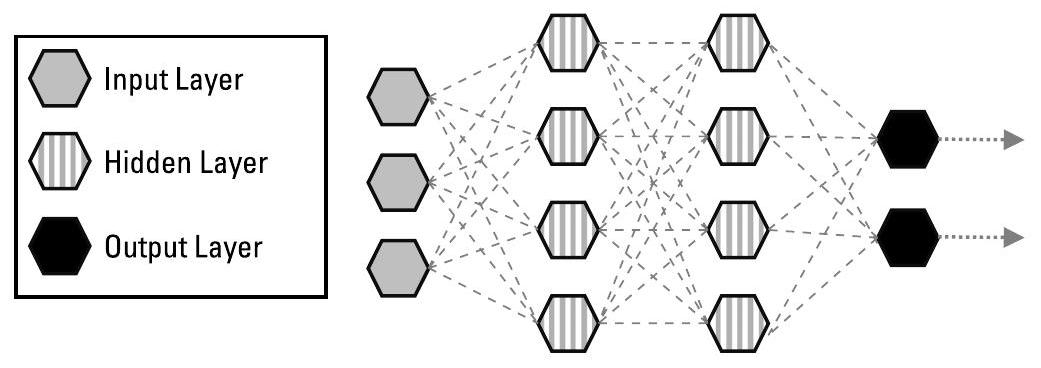
图3.4 人工神经网络(ANNs)由输入层、隐藏层和输出层组成。网络的层数即为其深度。
目前存在多种深度神经网络(DeepNet)架构,且新架构不断涌现。该领域最权威的综述来自 Bengio、Hinton 和 LeCun,他们因在深度学习领域的开创性工作荣获2018年图灵奖 [13, 14]。常见的架构包括:
-
卷积神经网络(Convolutional Neural Networks, CNNs) [15,16] 是一类用于处理具有已知网格状拓扑结构数据的神经网络。典型的 CNN 包含三种类型的层:卷积层(convolutional)、池化层(pooling)和全连接层(fully connected),如图3.5所示。卷积层使网络能够学习对输入局部区域响应的滤波器;池化层用于简化数据处理,将某一层中神经元簇的输出压缩为下一层中的单个神经元;全连接层则将一层中的每个神经元与下一层的所有神经元相连。
-
循环神经网络(Recurrent Neural Networks, RNNs) [17] 属于处理序列数据的神经网络家族 [14]。RNNs 具有反馈连接(即具备记忆能力),通过维持具有记忆功能的内部状态来处理输入数据的时间特性 [18]。
-
时序卷积网络(Temporal CNNs) 可处理与序列、时间及记忆相关的深度学习任务 [19],有望取代 RNNs。
-
自编码器(Autoencoders) 用于学习高效的数据编码。其模型包含一个瓶颈层(bottleneck layer):瓶颈层即为高效编码,输出层则是对输入的重构。自编码器试图从压缩后的编码中重建出尽可能接近原始输入的表示。它们能有效学习去除噪声(即学习常见模式),常被用作异常检测器(anomaly detectors)[14, 20]。
-
孪生神经网络(Siamese neural nets) 在多个子网络上共享相同的权重,同时使用不同的输入数据进行训练。相比其他方法,它们所需的训练数据更少 [21]。
-
Kohonen 网络,又称自组织映射(Self-Organizing Maps, SOMs),可生成输入空间的低维表示,常用于降维和可视化。
-
生成对抗网络(Generative Adversarial Networks, GANs) 由两个相互竞争的神经网络组成,各自试图提升其预测准确性。GAN 将一个生成网络(generative network)与一个判别网络(discriminative network)置于对抗关系中:生成网络的目标是“欺骗”判别网络。GANs 常用于生成合成数据。
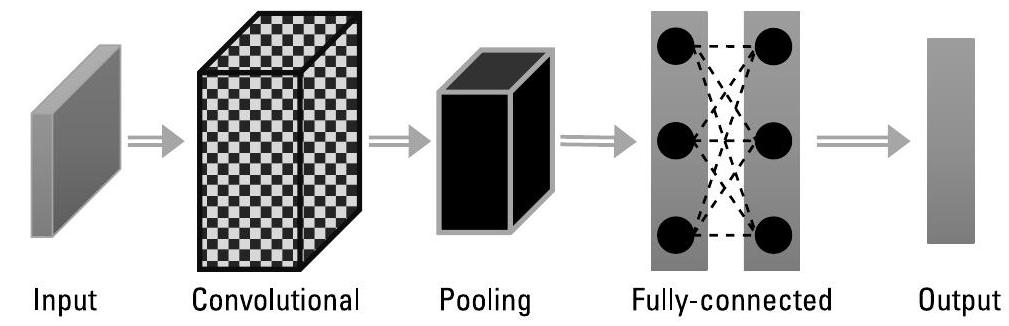
图3.5 卷积神经网络(CNNs)用于处理具有已知网格状拓扑结构的数据。
模型能够自行评估其预测置信度(即判断自身何时可信)是一项重要的新兴能力 [22]。
主流的人工神经网络(ANN)架构可在线获取 [23–25],且已有研究将其应用于射频(RF)领域 [26]。
3.2 集成方法(Ensemble Methods)¶
在集成(ensemble)中使用多个分类器 [1, 27–32] 可提升预测准确性,并增强对对抗性攻击(adversarial attacks)的鲁棒性,因为集成方法融合了多个具有差异性的模型的预测结果。例如,选举预测通常综合多个不同民调的结果,期望某一民调中的缺陷能被其他模型的缺陷所抵消。第7.1.1节展示了电子战毁伤评估(EW Battle Damage Assessment, BDA)环境中一个简单的集成应用示例。
常见的集成方法包括装袋法(bagging)、提升法(boosting)和贝叶斯模型平均(Bayesian model averaging);大多数机器学习工具包还提供了其他技术。简单多数投票(simple majority voting)选择出现频率最高的预测结果。装袋法为集成中的每个模型赋予相等的权重。提升法则通过增量方式构建集成:每训练一个新的模型时,会重点强化先前模型误分类的训练样本。贝叶斯模型平均则根据每个模型的后验概率(posterior probabilities)来分配权重。
3.3 混合机器学习(Hybrid ML)¶
符号主义人工智能(Symbolic AI)方法操作符号(通常为人类可读的形式),而非符号主义(nonsymbolic)方法则直接处理原始数据。决策树(decision trees)通常具有符号特性,而深度神经网络(DeepNets)则通常属于非符号方法。近年来,混合方法(hybrid approaches)将两者结合:利用符号知识来构建特征、缩小搜索空间、提升搜索效率,并增强模型的可解释性。混合方法常借助领域特定知识(domain-specific knowledge)和启发式规则(heuristics),以更快地找到解决方案 [33–41]。这类方法也被称为基于知识的机器学习(knowledge-based ML)或神经-符号人工智能(neural-symbolic AI)。
混合方法本质上对学习过程起到“引导启动”(bootstrap)的作用。图3.6展示了这一思想:解析模型(analytical model)提供一个初始框架或对结果的合理猜测,而经验数据(empirical data)则进一步优化预测,使其与实际观测经验相匹配。混合方法使学习器即使在无训练数据的情况下也能基本工作,并在经过真实世界训练后表现优异。图3.7示意了深度神经网络、经典机器学习和混合方法在不同数据量下的性能表现。
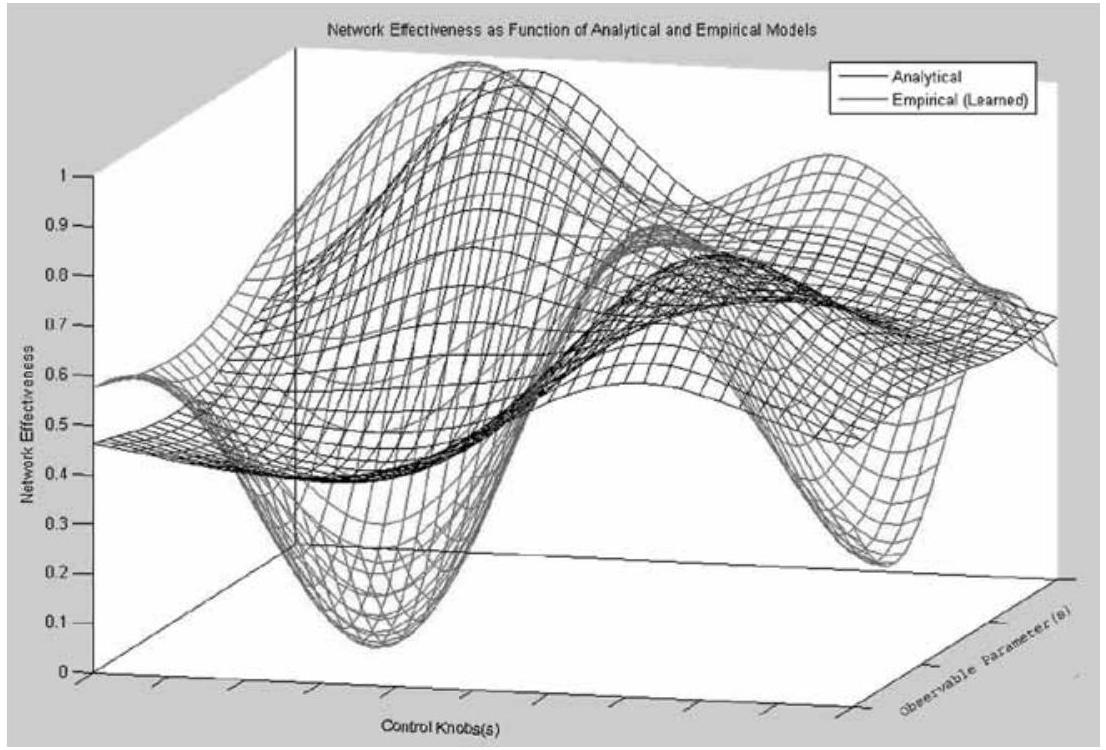
图3.6 解析模型根据可观测量(observables)的 \(\overline{\mathrm{o}_{n}}\) 维和可控变量(controllables)的 \(\overline{\mathrm{C}_{n}}\) 维来估计性能曲面;经验模型则对预测进行细化。(引自 [35]。)
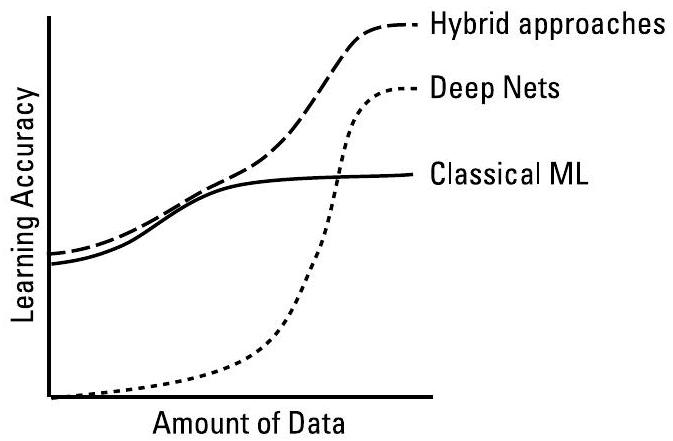
图3.7 深度神经网络(DeepNets)能够从数据中识别潜在特征,而经典机器学习方法则依赖于传统的特征工程(feature engineering)。
第4.1.1节给出了一个将传统特征与深度神经网络模型相结合的示例。第7.3.3节描述了如何将用于提取潜在特征(latent features)的深度神经网络与支持向量机(SVM)结合,以实现快速的任务中学习(in-mission learning)。第6.3节则介绍了多种在模型设计中利用人类专家知识的方法。
3.4 开集分类(Open-Set Classification)¶
开集分类(open-set classification)技术能够在初始模型训练完成后,在任务执行过程中动态创建新类别。这类方法用于处理在任务期间遇到的、在训练阶段未预料到的未知数据。
一种可行方案是选择能够从单个样本中高效学习的机器学习模型;k近邻(k-nearest neighbor, kNN)和支持向量机(Support Vector Machines, SVMs)是较好的选择 [42]。kNN 无需重新训练,但每次推理的时间复杂度与训练样本数量呈线性关系。SVMs 在新增样本时需重新计算模型(对于 \(n\) 个训练样本,复杂度约为 \(O(n^2)\)),但推理阶段通常非常高效。
其他方法还包括自编码器(autoencoders)、零样本学习(zero-shot learning)或小样本学习(low-shot learning)[43–48],以及异常检测(anomaly detection)(见第4.4节)。例如,小样本学习利用训练数据构建重要特征的潜在嵌入(latent embedding),并基于该嵌入在运行时动态创建新类别。数据增强(data augmentation)(见第8.3.3节)也有助于确保原始训练数据覆盖更多潜在的未知类别。
3.5 泛化与元学习(Generalization and Meta-learning)¶
泛化(generalization)指模型对来自与训练数据相同分布的新、未见过数据的适应能力。例如,查表法(table-lookup)完全不具备泛化能力。过拟合(overfitting)意味着模型对训练数据拟合得过于紧密,因此在新数据上表现不佳;而欠拟合(underfitting)则连训练数据本身都无法有效拟合(见图3.8)。良好的泛化能力意味着在欠拟合与过拟合之间取得恰当的平衡。
过拟合与欠拟合通过调整控制算法行为的超参数(hyperparameters)来控制,这一过程称为元学习(meta-learning)[49–52]。每种算法都有其特定的超参数:例如,决策树(decision trees)可调整 MaxDepth(最大深度)和 MinSamples(最小样本数);支持向量机(SVMs)可调整 \(C\)(误分类点的惩罚成本)和 \(\gamma\)(单个样本的影响范围);深度神经网络(DeepNets)则可能采用早停(early stopping)和激活丢弃(activation dropout)等策略。若使用标准机器学习工具包(见第11.2.1节),超参数通常作为函数的输入参数提供。第5.1.3节将进一步讨论元学习,并强调其在优化中的作用。元学习通常也是强化学习(RL)解决方案的一部分。
其他提升泛化能力的方法包括集成方法(见第3.2节)、混合模型(见第3.3节),以及诸如批归一化(batchnorm)[53, 54]、朗之万方法(Langevin methods)[55] 或熵滤波(entropy filtering)[56] 等训练策略。
当问题维度很高(即特征数量远大于训练样本数,亦即 \(\left(\overline{o_{n}}+\overline{c_{n}}\right) \gg n\))时,往往需要采用不同的方法 [3]。通过多样性管理、数据增强(augmentation)和遗忘机制(forgetting)来管理数据,是另一个关键步骤(见第8.3节)。
模型的专长领域(domain of expertise)指明了模型应能良好捕捉的数据范围:当新观测值落在该领域内时,模型表现应优于其落在领域外的情况。例如,在图3.8中,训练数据分布在区间 \([-1.0, 1.0]\) 内,而取值 2.0 则超出了模型的专长领域。二次多项式模型在此范围外仍能良好泛化,而其他两个模型则随着偏离预期范围越远,误差迅速增大。理想情况下,模型应能自行计算其预测置信度(confidence)。
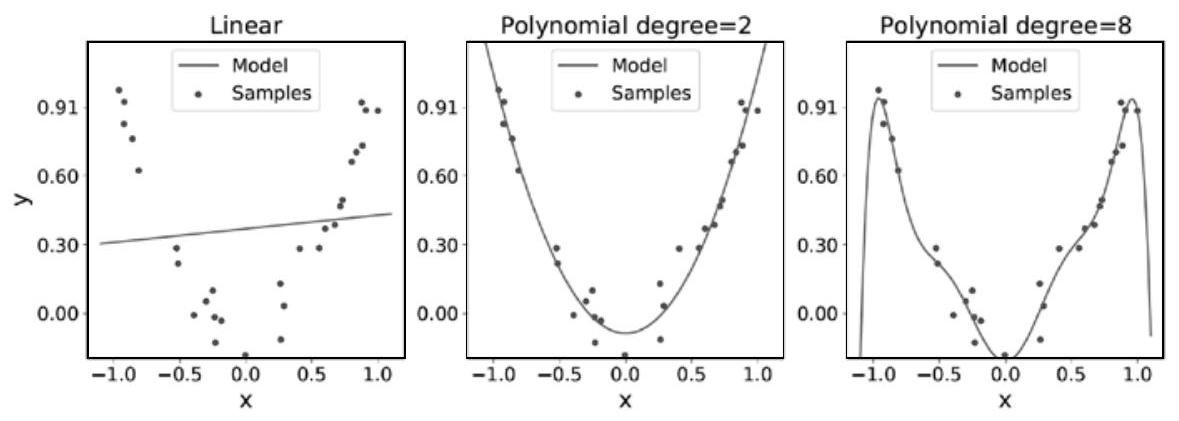
图3.8 线性模型通常欠拟合;当特征数量远多于训练样本时,模型容易过拟合。(底层数据为 \(y = x^{2} + \varepsilon\)。)
3.6 算法权衡(Algorithmic Trade-Offs)¶
选择何种机器学习技术应用于频谱理解(spectrum understanding)问题,取决于多种因素。并不存在一种在所有情况下都优于其他所有模型的“万能模型”[2, 57, 58]。这些因素包括任务类型、可用数据的性质、解决方案的目标以及运行约束条件。表3.2列出了在选择算法时必须考虑的一些关键问题。
例如,深度神经网络(DeepNets)能有效识别数据中的潜在特征(latent features)。然而,DeepNets 依赖于大量多样化且标注良好的训练数据。尽管蜂窝网络或 Wi-Fi 网络可能拥有海量数据,但电子战(EW)领域通常不具备这一优势。
表3.2 为机器学习任务选择算法解决方案时需回答的问题
| 因素 | 需考虑的问题 |
|---|---|
| 任务(Task) | 你试图理解环境?预测未来事件?控制行动?持续自适应? Scott Page 在《模型思维》(The Model Thinker)[57] 中提出了模型的用途(REDCAPE): - 推理(Reason):识别条件并推导逻辑结论。 - 解释(Explain):为经验现象提供(可检验的)解释。 - 设计(Design):选择制度、政策和规则的特征。 - 沟通(Communicate):传递知识与理解。 - 行动(Act):指导政策选择与战略行动。 - 预测(Predict):对未来的或未知的现象进行数值或类别预测。 - 探索(Explore):探究可能性与假设情景。 |
| 数据(Data) | 有多少训练数据可用(任务前和任务中)?数据标注质量如何?数据是否部分可观测(即特征可能缺失)?数据是数值型还是类别型?哪些特征可通过先验模型计算得出?自训练以来数据是否发生变化(例如概念漂移、组件更新)? |
| 目标(Goals) | 解决方案需要多高的准确率?系统需多快得出结论?假阳性与假阴性对性能的影响是否不同?决策是否需要附带置信度作为注释?解决方案是否需对电子战操作员具备可解释性或可说明性?解决方案是否需扩展至更多辐射源、更多环境或更多任务?有哪些安全/隐私方面的考量? |
| 约束(Constraints) | 必须满足哪些硬实时(hard real-time)要求?可用哪些计算资源(CPU、GPU、FPGA、定制ASIC)?模型和数据可用的存储空间有多大?哪些数据需在极长时间跨度内(例如跨任务)持久保存? |
图3.7展示了性能权衡关系:当数据量充足时,深度神经网络表现更优;而在数据有限的情况下,经典机器学习方法往往表现更好,这在很大程度上是因为其特征是针对具体问题人工设计的。第4.1.1节描述了如何在部署系统中有效结合深度神经网络与支持向量机(SVMs):由深度神经网络计算射频(RF)域的通用特征,而SVMs则负责执行任务中的模型更新。
在某些情况下,数据增强(data augmentation)和对抗训练(adversarial training)方法(见第8.3.3节)可弥补数据不足的问题 [59–63]。数据增强能在不实际采集新数据的前提下,提升数据的多样性。在图像识别中,常见的数据增强技术包括裁剪、翻转、旋转和调整光照方案。在射频(RF)领域,将信号通过信道模型和/或噪声模型,即可实现类似效果。
在预期任务中会遭遇新型辐射源(novel emitters)的电子战(EW)任务中,系统设计必须纳入能在任务相关时间尺度上、仅凭一两个样本就学习新模型的技术。开集分类(open-set classification)(见第3.4节)讨论了部分相关方法。
表3.3总结了几种常见机器学习算法的设计权衡。该列表并非详尽无遗,仅用于说明:在确定采用某一种具体方法前,必须对电子战系统的任务、数据、目标和约束条件进行综合分析。以下是一些通用的经验法则 [2]:
- 预测未来时,更大、更复杂的模型通常能更准确地拟合性能曲面;而解释现象时,更小、更简洁的模型更合适。
- 当训练样本数量有限时,特征工程(feature engineering)非常有帮助,经典机器学习方法更可能有效。
- 当训练样本数量庞大且训练时间充裕时,深度神经网络(DeepNets)可能表现优异。
- 当推理时间受限时,基于模型的方法(model-based techniques)优于基于实例的方法(instance-based techniques)。前者虽可能训练耗时较长,但推理速度快;后者无训练阶段,但推理时需进行大量计算。
表3.3 常见机器学习算法的设计权衡
| 机器学习算法 | 常见用途 | 优势 | 劣势 |
|---|---|---|---|
| 支持向量机(SVMs) | 股市预测;射频质量评估;雷达辐射源信号识别;调制识别;异常检测 | 小样本下精度高;计算效率极高;适用于高维特征 | 主要适用于数值型数据 |
| 深度神经网络(DeepNets) | 图像理解;自然语言处理;信号特性分析;调制识别;目标跟踪;异常检测;特定辐射源识别(SEI) | 能自动提取数据中的潜在特征;推理速度可极快 | 需大量训练数据;计算资源消耗大;可解释性差;训练时间可能很长 |
| 逻辑回归(Logistic regression) | 风险评估;过程失效预测 | 高效;可解释性强;可计算特征重要性 | 需要干净数据;仅支持一维输出 |
| 朴素贝叶斯分类器(Naïve Bayes classifier) | 情感分析;文档分类;垃圾邮件过滤 | 支持类别型输入;所需训练数据较少;可输出结果概率 | 要求特征条件独立 |
| k近邻(k-nearest neighbor, kNN) | 文档相似性;辐射源相似性 | 高效;可解释;无需训练阶段;可即时纳入新数据 | 在高维空间中性能下降;类别不平衡会导致问题;对异常值敏感;推理可能计算密集 |
| 决策树(Decision trees) | 设计决策;情感分析 | 易于解释;对离散数据表现极佳 | 特征过多时不稳定;对数值型数据表现较弱 |
| 因果模型(Causal models) | 因果关系建模 | 在无法实验时仍可发现模式 | 难以控制不可观测特征的影响 |
Lim 等人 [64] 使用训练时间和准确率等指标对33种算法进行了评估。更全面的评估指标列表见Callout 10.2。
3.7 结论(Conclusion)¶
人工智能(AI)是一个与数学或工程学同样宽广的学科领域。
人工智能就像数学一样,终将无处不在。
AI 包含众多子领域,涵盖态势评估(situation assessment)和决策管理(Decision Management, DM)等更广泛的概念。规划(planning)、优化(optimization)、数据融合(data fusion)和学习(learning)等技术支撑着机器视觉、自然语言处理(NLP)、机器人学和后勤物流等应用领域。
关于人工智能,最关键的一点是:机器学习(ML)是 AI 内部的一个概念,而深度神经网络(DeepNets)则是 ML 中的一类技术。因此,AI 不等同于 ML,AI 也不等同于 DeepNets。机器学习远不止深度学习。深度神经网络在电子战(EW)问题中确有其适用场景,但不应仅仅因为 DeepNets 当前最受关注,就忽视或忽略经典机器学习方法以及其他 AI 方法。
References¶
[1] Russell, S., and P. Norvig, Artificial Intelligence: A Modern Approach, Pearson Education, 2015.
[2] Burkov, A., The Hundred-Page Machine Learning Book, Andriy Burkov, 2019.
[3] Hastie, T., R. Tibshirani, and J. Friedman, The Elements of Statistical Learning, Springer, 2009.
[4] Vink, J., and G. de Haan, "Comparison of Machine Learning Techniques for Target Detection," Artificial Intelligence Review, Vol. 43, No. 1, 2015.
[5] Kulin, M., et al., "End-to-End Learning from Spectrum Data," IEEE Access, Vol. 6, 2018.
[6] Cristianini, N., and J. Shawe-Taylor, An Introduction to Support Vector Machines and other Kernel-based Learning Methods, Cambridge University Press, 2000.
[7] Schölkopf, B., and A. Smola, Learning with Kernels: Support Vector Machines, Regularization, Optimization, and Beyond, MIT Press, 2002.
[8] Support vector machines, Accessed: 2020-03-21. Online: https:// scikit-learn.org/stable/modules/svm.html.
[9] Üstün, B., W. Melssen, and L. Buydens, "Facilitating the Application of Support Vector Regression by Using a Universal Pearson VII Function-Based Kernel," Chemometrics and Intelligent Laboratory Systems, Vol. 81, No. 1, 2006.
[10] McCulloch, W., and W. Pitts, "A Logical Calculus of Ideas Immanent in Nervous Activity," Bulletin of Mathematical Biophysics, Vol. 5, No. 4, 1943.
[11] Rosenblatt, F., "The Perceptron: A Probabilistic Model for Information Storage and Organization in the Brain," Psychological Review, Vol. 65, 1958.
[12] Werbos, P., Beyond Regression: New Tools for Prediction and Analysis in the Behavioral Sciences, Harvard University, 1975.
[13] LeCun, Y., Y. Bengio, and G. Hinton, "Deep Learning," Nature, Vol. 521, 2015.
[14] Goodfellow, I., Y. Bengio, and A. Courville, Deep Learning, MIT Press, 2016.
[15] LeCun, Y., et al., "Gradient-Based Learning Applied to Document Recognition," Proceedings of the IEEE, Vol. 86, No. 11, 1998.
[16] Khan, A., et al., "A Survey of the Recent Architectures of Deep Convolutional Neural Networks," Artificial Intelligence Review, Vol. 53, 2020.
[17] Rumelhart, D., et al., "Schemata and Sequential Thought Processes in PDP Models," Parallel Distributed Processing: Explorations in the Microstructures of Cognition, Vol. 2, 1986.
[18] Miljanovic, M., "Comparative Analysis of Recurrent and Finite Impulse Response Neural Networks in Time Series Prediction," Indian Journal of Computer Science and Engineering, Vol. 3, No. 1, 2012.
[19] Baevski, A., et al., wav2vec 2.0: A Framework for Self-Supervised Learning of Speech Representations, 2020. Online: https://arxiv.org/abs/2006.11477.
[20] Kingma, D., and M. Welling, "An Introduction to Variational Autoencoders," Foundations and Trends in Machine Learning, Vol. 12, No. 4, 2019.
[21] Chicco, D., "Siamese Neural Networks: An Overview," in Artificial Neural Networks, Springer, 2020.
[22] Amini, A., et al., "Deep Evidential Regression," in NeurIPS, 2020.
[23] Culurciello, E., Analysis of Deep Neural Networks, Accessed 2020-10-06, 2018. Online: https://tinyurl.com/medium-anns.
[24] Culurciello, E., Neural Network Architectures, Accessed 2020-10-06, 2017. Online: https:// tinyurl.com/tds-anns-2018.
[25] Canziani, A., A. Paszke, and E. Culurciello, "An Analysis of Deep Neural Network Models for Practical Applications," in CVPR, IEEE, 2016.
[26] Majumder, U., E. Blasch, and D. Garren, Deep Learning for Radar and Communications Automatic Target Recognition, Norwood, MA: Artech House, 2020.
[27] Bauer, E., and R. Kohavi, "An Empirical Comparison of Voting Classification Algorithms: Bagging, Boosting, and Variants," Machine Learning, Vol. 36, 1999.
[28] Sagi, O., and L. Rokach, "Ensemble Learning: A Survey," Data Mining and Knowledge Discovery, Vol. 8, No. 4, 2018.
[29] Ardabili, S., A. Mosavi, and A. Várkonyi-Kóczy, "Advances in Machine Learning Modeling Reviewing Hybrid and Ensemble Methods," in Engineering for Sustainable Future, InterAcademia, 2020.
[30] Dogan, A., and D. Birant, "A Weighted Majority Voting Ensemble Approach for Classification," in Computer Science and Engineering, 2019.
[31] Abbasi, M., et al., "Toward Adversarial Robustness by Diversity in an Ensemble of Specialized Deep Neural Networks," in Canadian Conference on AI, 2020.
[32] Tramèr, F., et al., "Ensemble Adversarial Training: Attacks and Defenses," in ICLR, 2018.
[33] Aha, D., "Integrating Machine Learning with Knowledge-Based Systems," in New Zealand International Two-Stream Conference on Artificial Neural Networks and Expert Systems, 1993.
[34] Mao, J., et al., "The Neuro-Symbolic Concept Learner: Interpreting Scenes, Words, and Sentences from Natural Supervision," in ICLR, 2019.
[35] Haigh, K. Z. ,S. Varadarajan, and C. Y. Tang, "Automatic Learning-Based MANET CrossLayer Parameter Configuration," in Workshop on Wireless Ad hoc and Sensor Networks, IEEE, 2006.
[36] Towell, G., and J. Shavlik, "Knowledge-Based Artificial Neural Networks," Artificial Intelligence, Vol. 70, No. 1, 1994.
[37] T. Yu, S. Simoff, and D. Stokes, "Incorporating Prior Domain Knowledge into a Kernel Based Feature Selection Algorithm," in Pacific-Asia Conference on Knowledge Discovery and Data Mining, 2007.
[38] Muralidhar, N., et al., "Incorporating Prior Domain Knowledge into Deep Neural Networks," in International Conference on Big Data, 2018.
[39] Agrell, C., et al., "Pitfalls of Machine Learning for Tail Events in High Risk Environments," in Safety and Reliability—Safe Societies in a Changing World, 2018.
[40] d'Avila Garcez, A., et al., "Neural-Symbolic Computing: An Effective Methodology for Principled Integration of Machine Learning and Reasoning," Journal of Applied Logics, Vol. 6, No. 4, 2019.
[41] Workshop Series on Neural-Symbolic Integration, Accessed 2020-07-23. Online: http://www. neural-symbolic.org/.
[42] Haigh, K. Z., et al., "Parallel Learning and Decision Making for a Smart Embedded Communications Platform," BBN Technologies, Tech. Rep. BBN-REPORT-8579, 2015.
[43] Mattei, E., et al., "Feature Learning for Enhanced Security in the Internet of Things," in Global Conference on Signal and Information Processing, IEEE, 2019.
[44] Robyns, P., et al., "Physical-Layer Fingerprinting of LoRa Devices Using Supervised and Zero-Shot Learning," in Conference on Security and Privacy in Wireless and Mobile Networks, 2017.
[45] Tokmakov, P., Y.-X. Wang, and M. Hébert, "Learning Compositional Representations For Few-Shot Recognition," in CVPR, IEEE, 2019.
[46] Wang, W., et al., "A Survey of Zero-Shot Learning: Settings, Methods, and Applications," ACM Transactions on Intelligent Systems and Technology, Vol. 10, No. 12, 2019.
[47] Geng, C., S.-J. Huang, and S. Chen, "Recent Advances in Open Set Recognition: A Survey," IEEE Transactions on Pattern Analysis and Machine Intelligence, 2020.
[48] Cao, A., Y. Luo, and D. Klabjan, Open-Set Recognition with Gaussian Mixture Variational Autoencoders, 2020. Online: https://arxiv.org/abs/2006.02003.
[49] Brazdil, P., and C. Giraud-Carrier, "Meta Learning and Algorithm Selection: Progress, State of the Art and Introduction to the 2018 Special Issue," Machine Learning, Vol. 107, 2018.
[50] Schaul, T., and J. Schmidhuber, Metalearning, Scholarpedia, 2010. doi:10.4249/ scholarpedia. 4650.
[51] Finn, C., P. Abbeel, and S. Levine, Model-agnostic Meta-Learning for Fast Adaptation of Deep Networks, 2017. Online: https://arxiv.org/ abs/1703.03400.
[52] Hospedales, T., et al., Meta-Learning in Neural Networks: A Survey, 2020. Online: https:// arxiv.org/abs/2004.05439.
[53] Principe, J., et al., "Learning from Examples with Information Theoretic Criteria," VLSI Signal Processing-Systems for Signal, Image, and Video Technology, Vol. 26, 2000.
[54] Santurkar, S., et al., How Does Batch Normalization Help Optimization? 2019. Online: https://arxiv.org/abs/1805.11604.
[55] Barbu, A., and S.-C. Zhu, Monte Carlo Methods, Springer, 2020.
[56] Chaudhari, P., et al., "Entropy-SGD: Biasing Gradient Descent into Wide Valleys," in ICLR, 2017.
[57] Page, S., The Many Model Thinker, Hachette, 2018.
[58] Wolpert, D., "The Lack of A Priori Distinctions Between Learning Algorithms," Neural Computation, 1996.
[59] Rizk, H., A. Shokry, and M. Youssef, Effectiveness of Data Augmentation in Cellular-Based Localization Using Deep Learning, 2019. Online: https://arxiv.org/abs/1906.08171.
[60] Shi, Y., et al., "Deep Learning for RF Signal Classification in Unknown and Dynamic Spectrum Environments," in International Symposium on Dynamic Spectrum Access Networks, IEEE, 2019.
[61] Shorten, C., and T. Khoshgoftaar, "A Survey on Image Data Augmentation for Deep Learning," Big Data, Vol. 6, No. 60, 2019.
[62] Sinha, R., et al., "Data Augmentation Schemes for Deep Learning in an Indoor Positioning Application," Electronics, Vol. 8, No. 554, 2019.
[63] Xie, F., et al., "Data Augmentation for Radio Frequency Fingerprinting via Pseudo-Random Integration," IEEE Transactions on Emerging Topics in Computational Intelligence, Vol. 4, No. 3, 2020.
[64] Lim, T.-S., W.-Y. Loh, and Y.-S. Shih, "A Comparison of Prediction Accuracy, Complexity, and Training Time of Thirty-Three Old and New Classification Algorithms," Machine Learning, Vol. 40, 2000.