6 电子战管理¶
电子战管理(Electronic Battle Management, EBM)系统负责规划部署多少个平台、每个平台分配哪些资源,以及它们将部署在何处。该系统协调电磁频谱作战(Electromagnetic Spectrum Operations, EMSO)各领域内的活动,并统筹考虑后勤等更广泛的议题。电子战(Electronic Warfare, EW)计划应明确期望的电磁特征(electromagnetic profile);确定任务、具体行动和所需资源;评估威胁;并满足相关政策的约束条件与目标[1]。影响计划制定的因素包括可用资产、期望达成的效果、部署限制(如高度、距离、时间或载荷)、频率去冲突(frequency deconfliction)、其他军种预期开展的电子战任务,以及身份认证要求[2]。图6.1展示了EBM系统的一些输入与输出,包括期望效果、平台限制、交战规则(rules of engagement)以及其他军种预期的电子战任务。
美国国防部(DoD)条令阐述了电子战规划的传统方法,指出“联合电子战由中央统一规划和指挥,分散执行……”[1],并强调“……此类规划需要多学科方法,融合来自作战(地面、空中、太空)、情报、后勤、气象和信息等领域的专业知识。”[2]
转向自动化EBM规划系统,可构建一个更具交互性的系统,能够对任务执行过程中发生的事件实时响应。如第5章所述,自动化规划活动与优化和调度相互重叠,未来将发展为完全交互式的集成系统。第6.1节介绍了人工智能(AI)规划方法,讨论了不确定性、资源分配和多时间尺度等问题。第6.2节涉及博弈论(game theory)方法,用于团队协同以及对敌方对抗性行动的推理。第6.3节探讨了人机接口(Human-Machine Interface, HMI),包括如何在系统中利用人类专家知识、提取人类层级的目标以用于优化,以及向人类用户解释系统决策。(第7.2节描述了如何在任务执行过程中动态更新计划。)
| 输入 | ||||
|---|---|---|---|---|
| 交战规则(Rules of Engagement) | 环境(Environment) | 运行约束(Operating Constraints) | 可用资产(Available Assets) | 与其他组织的协同(Cooperation with other organizations) |
| 指挥官意图(Commander Intent) | 任务模型(Mission Model) | 预期威胁(Expected Threats) | 攻击库(Attack Library) | 期望效果(Desired Effects) |
| 输出 | ||||
| 资产分配(Asset Allocations) | 频谱感知计划(Spectrum Sensing Plan) | 电子防护与电子攻击规划(EP and EA Planning) | 人机交互(Human interactions) | 互操作性(Interoperability) |
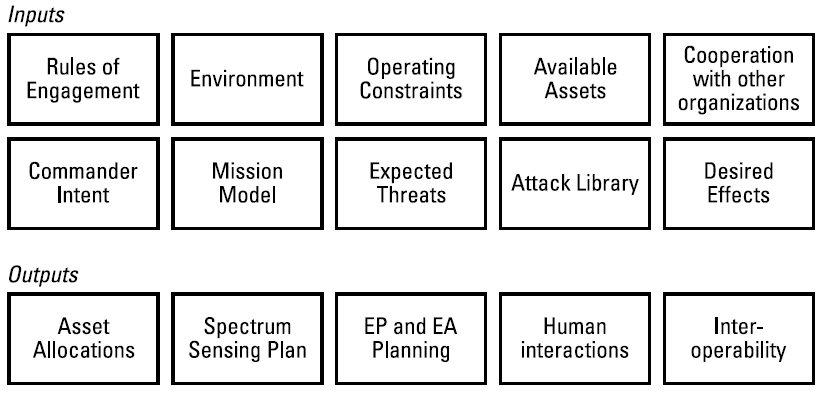
图6.1 为支持深思熟虑的基于效果的管理(EBM)规划,输入包括对任务的相对静态描述,输出则包括高层级任务指派。(随着规划过程日益自动化,动态输入也将变得相关。)
在一个完整的电子战(EW)系统中,将存在多个决策者。规划器可能是面向特定任务的、由算法明确界定的,并在地理上或时间上相互分离。这种关注点分离显著简化了系统设计。面向特定任务的规划器示例包括ROGUE系统,该系统包含一个任务规划器和一个航路规划器[3];以及战术专家任务规划器(TEMPLAR),该系统包含四个规划器(见例6.1)。
例6.1 TEMPLAR生成空中任务指令(Air Tasking Orders)。
战术专家任务规划器(Tactical Expert Mission Planner, TEMPLAR)
TEMPLAR包含四个独立的规划模块:
- 编组规划器(package planner):在目标规划工作表(Target Planning Worksheets)上生成任务行。
- 流程规划器(flow planner):为[近距空中支援(Close Air Support, CAS)]和[防御性制空(Defensive Counter Air, DCA)]任务在单位日程表上生成任务行。
- 空对空加油规划器(air-air refueling planner):在加油规划工作表(Refueling Planning Worksheets)上生成任务行。
- 任务行规划器(mission line planner):在已有任务行中填写任务编号、呼号、SIF代码及其他信息。
—— Siska、Press和Lipinski [4]
6.1 规划(Planning)¶
规划(Planning)的作用范围比优化(optimization)或调度(scheduling)更广,且时间尺度更长。规划在更长的时间范围内评估行动,并处理更广泛的资产与资源类型。哈勃空间望远镜(Hubble Space Telescope)采用了一套于20世纪90年代初构建的规划与调度系统进行自动控制,凸显了规划器与调度器之间的紧密耦合(见例6.2)。
例6.2 一个AI规划器与调度器控制哈勃空间望远镜上的天文观测任务。
哈勃空间望远镜是首批部署的大型自动化规划与调度系统之一[5, 6]。启发式调度试验平台系统(Heuristic Scheduling Testbed System, HSTS)基于目标展开(goal expansion,即规划)和资源分配(resource allocation,即调度)来构建观测调度方案。天文学家制定包含时间约束的观测计划,指定使用六台科学仪器之一对某一天体进行光线采集。最终生成的计划必须同时满足多位天文学家的任务需求。多层抽象机制使规划器能够有效管理问题的组合复杂性:抽象层负责管理望远镜可用性、重构时间(reconfiguration time)和目标可见性(target visibility),而细节层则负责管理具体的曝光(exposures)操作。
规划(Planning)侧重于因果推理,以找出实现目标所需的一系列行动。规划结果通常是一个部分有序的动作集合,不指定具体资源或时间安排;而调度(scheduling)则为规划分配时间和资源。图6.2展示了不同挑战如何驱动规划方法的选择。
经典规划(Classical planning)以当前情境的描述(初始状态)、一组动作以及目标描述作为输入,输出一个从当前情境导向目标的动作序列。概率规划(Probabilistic planning)用于处理非确定性(nondeterministic)和部分可观测(partially observable)的环境。时序规划(Temporal planning)处理具有持续时间的动作,或允许多个动作并发执行;时序规划技术通常也处理资源问题,因为资源的使用本质上往往是时序性的(例如,某一资源在同一时刻最多只能被一个动作使用)。条件规划(Conditional planning),又称应急规划(contingent planning),生成包含条件分支的规划:它输出的不是一个简单的动作序列,而是一个应急计划(contingency plan),该计划根据对环境的感知动态选择动作,如图6.3所示。任务失败的后果越严重,提前准备应急方案就越重要[7]。

图6.2 不同的问题领域挑战在规划方法选择中需考虑不同因素(这些因素并非互斥)。
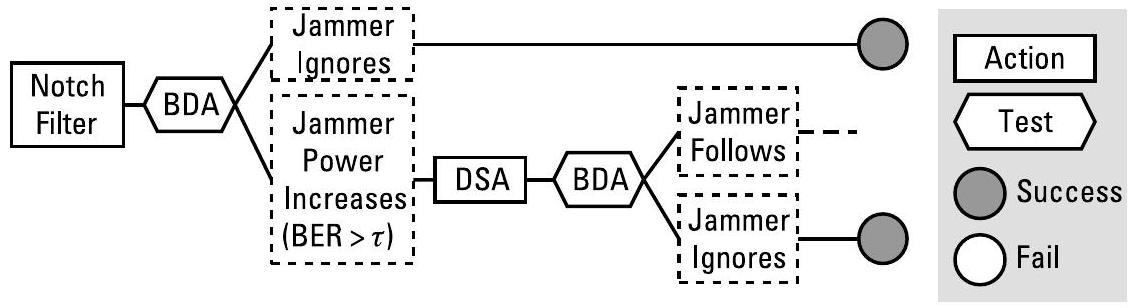
图6.3 应急规划(contingent plan)根据预期结果生成带条件分支的动作。在诸如表5.1所示的音调干扰机(tone jammer)这类简单场景中,此类规划看起来类似于决策树或规则系统。
目前已有多部优秀的规划领域专著[8–10]。Benaskeur 等人[7]描述了适用于海军交战场景的不同规划方法。自1998年以来,国际规划竞赛(International Planning Competition, IPC)[11]大约每两年举办一次,针对不同类型规划器设置多个赛道,处理诸如基于卫星的地球观测、野生动物盗猎防控和数据网络任务调度等现实(有时甚至是真实)世界问题。值得注意的是,这些规划器的源代码是公开的。Yuen [12] 提供了一幅图表,展示了IPC竞赛赛道的演进历程,并阐明了针对不同类型问题所需权衡的关键因素;随后,Yuen 还详细阐述了一个网络红队(cyber red-teaming)应用案例。
搜索与规划算法通常根据完备性(completeness)、最优性(optimality)、时间复杂度(time complexity)和空间复杂度(space complexity)进行评估[8]。本章介绍的搜索算法以深思熟虑(deliberative)的方式在解空间中进行搜索。第5.1.2节介绍了随机化搜索引擎,并采用相同的评估标准来判断其在电子战(EW)中的适用性。
6.1.1 规划基础:问题定义与搜索¶
一个问题可通过以下形式化组件进行定义:
- 一个初始状态(initial state)\(s_{0} \in S\);
- 一组可能的动作(actions)\(A\);
- 对每个动作效果的描述,表示为一个函数 \(\rho:(s, a) \rightarrow s^{\prime}\),该函数返回在状态 \(s\) 下执行动作 \(a\) 后得到的新状态 \(s^{\prime} \in S\);
- 一个目标状态(goal state)\(s_{g} \in S\);
- 一个代价函数(cost function),为状态之间的每一步转移分配代价,记为 \(c\left(s, a, s^{\prime}\right)\)。
规划问题 \(P\) 的解是找到一个从 \(s_{0}\) 出发的动作序列 \(\pi = \left(a_{1}, a_{2}, \ldots, a_{n}\right)\),该序列产生一连串状态 \(\left(s_{1}, s_{2}, \ldots, s_{g}\right)\)。最优解(optimal solution)是指从 \(s_{0}\) 到 \(s_{g}\) 代价最低的路径。
经典规划领域(classical planning domains)通常采用规划域定义语言(Planning Domain Definition Language, PDDL)[13] 进行表示。PDDL 语法用于对规划域进行编码,包括状态、动作以及复合动作。状态表示为若干正文字(positive literals)的合取式,形式为 predicate(arg1,...,argN),例如:\(s =\) in(pilot, airplane) AND has_fuel(airplane)。 动作具有前提条件(preconditions)和效果(effects);仅当动作 \(a\) 的所有前提文字 \(p_{i}\) 在状态 \(s\) 中为真时,该动作才可在 \(s\) 中应用。PDDL 存在多种变体,可表达不同性质与复杂度的规划问题,包括约束(constraints)、条件效果(conditional effects)、数值特征(numeric features)、时序特征(temporal features)以及动作代价(action costs)等。
搜索算法通过构建一棵以初始状态为根节点的搜索树(search tree)来寻找动作序列。在每个分支步骤中,算法通过对当前状态应用所有合法动作来扩展该状态,从而生成新的状态。例如,一个在网格世界(grid-world)中移动的简单机器人可以移动到任意相邻的网格单元,从而产生四个可能的后续状态。(在平面上移动的机器人具有二维无限的未来状态空间;而空中无人机则具有三维无限的状态空间。)连续值可通过离散化处理,或以统计量(如均值和方差)形式表示。剪枝(pruning)步骤用于剔除非法状态或重复状态,以减少搜索开销。
无信息搜索算法(Uninformed algorithms)在不利用领域知识引导的情况下构建搜索树,持续扩展节点直至抵达目标。常见策略包括广度优先搜索(breadth-first search)、深度优先搜索(depth-first search)、迭代加深搜索(iterative deepening)和双向搜索(bidirectional search)。鉴于电子战(EW)问题的复杂性,本文不再详细展开这些方法,因为领域知识对于找到可行解至关重要。
有信息搜索策略(Informed search strategies)利用启发式(heuristics)引导搜索过程,从而提升搜索效率或效果[14]。启发式规则可由领域专家人工制定,也可通过机器学习(ML)从经验数据中生成。最著名的启发式算法之一是 \(\mathrm{A}^{*}\) 算法——一种最佳优先搜索(best-first search),它优先扩展估计路径代价最低的节点 \(n\)(即 \(g(n)+h(n)\) 最小的节点,其中 \(g(n)\) 是从初始状态 \(s_{0}\) 到节点 \(n\) 的实际代价,\(h(n)\) 是从 \(n\) 到目标状态 \(s_{g}\) 的估计代价)。
几乎所有面向现实世界领域的成功规划系统都使用了领域特定的启发式方法。
第5.1.2节所述的随机元启发式搜索算法(randomized metaheuristic search algorithms)是求解复杂空间问题的一种途径,第5.2节中的许多调度器(schedulers)也采用了启发式方法。通常,每个可能的规划被编码为一个可由随机搜索引擎操作的动作序列。例如,在遗传算法(Genetic Algorithms, GAs)中,规划被表示为染色体(chromosomes)[15, 16];而在蚁群优化(Ant Colony Optimization, ACO)中,规划被建模为图结构,用于捕捉火灾逃生路径中的危险因素[17]。
6.1.2 分层任务网络(Hierarchical Task Networks, HTN)¶
分层任务网络(HTN)规划体现了一种不同于传统规划的视角[10, 18–20]:它并非通过改变世界模型的状态来搜索目标,而是将规划问题视为一组待完成的抽象任务,以及针对每个任务的一组方法(methods),这些方法代表了执行该任务的不同方式。动作之间的依赖关系通过层次化结构的网络进行表示。
HTN规划器在不断细化的抽象层级上生成规划。HTN是实际应用中最广泛采用的规划形式,原因有二:第一,它能有效管理计算复杂性;第二,它天然契合人类思考问题的方式。这一特性使得人类能够更轻松地描述任务之间的关系,同时用户界面本身也能直观地解释任务进展。
HTN规划器在一个表示待解决问题的任务网络(task network)上进行推理。该网络包含一系列待执行的任务及其相关约束(如任务顺序、必须满足的前提条件等),如图6.4所示。任务分为三类:
- 目标任务(Goal tasks):描述期望的最终状态;
- 基本任务(Primitive tasks):可直接在状态中执行的动作,具有关联的前提条件和预期效果;
- 复合任务(Compound tasks):说明如何通过基本任务实现目标。方法(Method)则描述如何将一个复合任务分解为部分有序的子任务(可以是基本任务或复合任务)。

图6.4 HTN包含任务、其前提条件以及诸如顺序等关联约束。任务目标包含三个可能相互独立的任务:电子对抗措施(ECM)、压制敌方防空(Suppression of Enemy Air Defense, SEAD)或巡逻空域。SEAD方法被分解为三个有序任务:突入(ingress)、打击(strike)和撤离(egress)。(源自[21]。)
因此,HTN问题的解是从初始任务网络出发,通过将复合任务递归分解为其更简单的子任务集,并插入必要的顺序约束后,所得到的一个可执行的基本任务序列。
HTN规划器已被广泛应用于多个问题领域[20],包括医学、生产计划、物流、危机管理、空中战役规划、海军指挥与控制(naval command and control)[22]、航空母舰调度[23]以及无人作战机器人编队[21]。例6.3展示了其在联合作战规划中的一个更详细实例。由于HTN规划器将领域知识编码在任务网络中,因此相比领域无关(domain-independent)的规划器,它能够求解规模更大、速度更快的规划问题。
HTN可被转换为其他规划表示形式以提升性能,例如PDDL[27]、马尔可夫决策过程(MDPs)[28]以及时序规划器(temporal planners)[29]。通过这种方式,领域无关规划器能够利用HTN中编码的领域知识。在复杂领域中求解大规模问题时,利用领域知识的能力至关重要。
例6.3 行动方案显示与评估工具(Course-of-Action Display and Evaluation Tool, CADET)将分层任务网络(HTN)规划与调度相结合,用于生成联合作战行动计划。
CADET 用于协助军事规划人员在联合作战环境中制定计划[24–26]。它是一种基于知识的工具,能够自动生成(或在人工指导下生成)具备现实细节程度与复杂度的作战计划。CADET 已与多个作战管理系统集成,应用于美国国防高级研究计划局(DARPA)和美国陆军的项目中[25]。
人类规划员首先定义战术行动方案(Course of Action, COA)的关键目标,CADET 随即将其扩展为一份详细的操作计划与调度方案。CADET 集成了交织式(interleaved)规划、调度、路径规划、损耗(attrition)建模和资源消耗等技术。它对作战资产与任务进行建模,处理对抗性环境,协调团队行动,并通过“指挥官意图”(commander's intent)支持自主行动。
作者指出:“规划与调度的集成通过一种紧密交织的增量式规划与调度算法实现。类HTN的规划步骤通过应用领域特定的‘扩展’(expansion)规则,对当前计划状态中需要层次化分解的活动进行处理,从而生成一组增量任务。调度步骤则执行时间约束传播(包括层次结构内的横向与纵向传播),并将新添加的活动分配到可用资源和时间段上。”[25]
6.1.3 动作不确定性(Action Uncertainty)¶
在动作结果具有非确定性(nondeterministic outcomes)的领域中,存在多种规划方法,包括条件规划(conditional planning)[30, 31]、图规划(graph planning)[32]、随机可满足性(stochastic satisfiability)[33, 34]、一阶决策图(first-order decision diagrams)[35]以及马尔可夫决策过程(Markov Decision Processes, MDPs)。由于MDP是其中应用最广泛的方法,本节将重点介绍MDP。(第6.1.4节将讨论与之正交的信息不确定性问题。)
MDP是一种用于在不确定性条件下对序贯决策(sequential decision making, DM)进行建模与引导的框架[8, 36, 37]。马尔可夫模型描述的是在有限状态集合之间以概率方式转移的系统。当领域仅部分可观测时,规划问题则对应于部分可观测马尔可夫决策过程(Partially Observable Markov Decision Process, POMDP)。
MDP在第6.1.1节的问题定义基础上增加了转移概率 \(P\left(s^{\prime} \mid s, a\right)\),表示在状态 \(s \in S\) 下执行动作 \(a \in A\) 后到达状态 \(s^{\prime} \in S\) 的概率。奖励函数 \(R\) 则刻画了在状态 \(s\) 下执行动作 \(a\) 所获得的期望奖励。如果电子支援(Electronic Support, ES)系统提供了敌方行为模型,则可将其整合进转移函数中,以反映威胁状态(作为每个状态 \(s_i \in S\) 的一部分)同时受到己方与敌方行动影响的事实。
策略(policy)\(\pi\) 规定了智能体在每个状态应采取的动作;\(\pi(s)\) 表示策略 \(\pi\) 在状态 \(s\) 下推荐的动作。在平稳策略(stationary policy)中,一旦策略确定,每个状态对应的动作即固定不变;而在非平稳策略(nonstationary policy)中,策略会随时间变化(即动作依赖于历史)。
由于环境具有随机性,策略的质量通过多次执行该策略所获得的期望效用(expected utility)来衡量。最优策略 \(\pi^{*}\) 是指能产生最高期望效用的策略。规划问题的目标即是寻找一个良好(或最优)的策略。两种标准算法——值迭代(value iteration)和策略迭代(policy iteration)[38]——可在有限次迭代后返回一个平稳的最优策略。
MDP中最常用的效用函数是折扣奖励(discounted rewards)形式,其中状态序列的效用随时间按折扣因子 \(\gamma \in [0,1]\) 进行衰减。从初始状态 \(s_0\) 出发、遵循策略 \(\pi\) 的期望效用为:
其中 \(a_{i} = \pi(s_{i})\),而最优策略 \(\pi^{*}(s_{i})\) 是使后续状态 \(s_{i+1}\) 的期望效用最大化的动作。
针对任务需求,可采用多种动作选择函数,包括:
- 最大最大准则(Maximax):选择期望奖励最大的动作,即使其实现概率很低(乐观型;高风险)。
- 最大似然准则(Maximum likelihood):结合结果发生的概率与期望奖励,选择期望值最大的动作。
- 最大最小准则(Maximin):选择各动作中“最坏情况”下收益最大的那个(悲观型;风险规避)。
- 最小最大遗憾准则(Minimax regret):选择使最坏情况下的“遗憾”(即因决策错误而损失的机会收益)最小的动作(风险规避)。
短视最优响应(Myopic best response)则仅选择当前状态下奖励最大的动作,忽略任何未来可能的收益(即设 \(\gamma = 0\))。
MDP规划在计算上效率极低[38–40],但MDP仍是构建概率性规划(probabilistic plans)最广泛使用的框架。正因如此,大量研究聚焦于如何提升MDP规划的性能[28, 41–47]。
对于协同节点团队,去中心化POMDP(Decentralized POMDPs, Dec-POMDPs)是一种常见解决方案[48],但其计算复杂度为NEXP完全(NEXP-complete)[49],在最坏情况下可能需要双重指数时间求解。此外,节点 \(n\) 的状态和动作需包含其他节点 \(n^{\prime}\) 的知识与动作。在实践中,节点通常通过启发式方法或利用问题结构来降低问题规模。例如,“交互局部性”(locality of interaction)假设节点仅需与有限子集的其他节点协调(即无需知晓所有其他节点的全部细节)[48, 50, 51]。第5.4节将进一步介绍其他分布式优化方法。
POMDP也是强化学习(Reinforcement Learning, RL)场景中最常用的表示形式(见第7章),其中RL技术用于学习模型中的转移概率和/或奖励函数。然而,RL并不等同于MDP,原因有三:(1) MDP是用于指定策略的模型,而RL通过与环境交互采取动作以更新策略;(2) 在MDP规划中,规划器需自行决定何时终止规划过程,而RL仅在任务结束时终止[42];(3) RL也可基于其他机器学习模型实现,不限于MDP。
6.1.4 信息不确定性(Information Uncertainty)¶
在复杂环境中,信息很少能被完全准确获知。决策(Decision-Making, DM)引擎必须纳入并对导致决策的信息不确定性进行推理。借助此类信息,规划器可利用主动感知(active sensing)和通信(communication)来提升信息质量或确定性。管理信息不确定性的方法包括:
- Dempster-Shafer证据理论(Dempster-Shafer theory):用于度量对某一事实的“信任度”(belief),并计算证据支持该命题的概率[52, 53];
- 模糊逻辑(Fuzzy logic):用于表示事实的真值程度(truth value)[54];
- 论证推理(Argumentation):显式构建证据与结论之间的关联关系,使系统能够直接对这些关系进行推理[55],例如用于解决信息冲突,或使规划器能够推理因果关系[56]。
这些方法支持对信息效用(utility of information)进行评估。
信息效用使得系统能够深思熟虑地决定是否、何时、与谁以及以何种方式通信或感知。
表6.1总结了这些主动感知/通信动作。信息来源(provenance)与可信度(credibility)的概念与此密切相关(见第8.1.3节),数据融合(data fusion)亦然(见第4.3节)。表6.2列举了一些系统可能采取的主动感知动作,具体取决于所需信息的性质。在执行主动感知动作后,执行监控器(execution monitor)必须判断所观察到的效果究竟是环境固有的行为,还是由感知动作本身所引发的。
表6.1 主动感知/通信动作
| 因素(Factor) | 主动感知(Active Sensing) | 有意通信(Deliberate Communication) |
|---|---|---|
| Why | 提升信息质量 | 提升信息质量 |
| Who | 协同感知(Collaborative sensing) | 与谁通信 |
| What | 需采集的信息内容 | 需传输的信息内容;抽象层级 |
| Where | 空间与频谱(Spatial and spectral) | 编队地理分布(Team geography) |
| When | 感知调度(Sensing schedule) | 信息的关键性(Criticality of information) |
| How | 使用何种传感器 | 隐式或显式交互(Implicit or explicit interactions) |
表6.2 感知动作可获取环境中未知辐射源的相关信息
| 领域(Domain) | 期望信息(Desired Info) | 主动感知动作(Active Sensing Action) |
|---|---|---|
| 雷达(Radar) | 雷达数量、雷达位置 | 生成“幽灵”(ghosts)、对盲区进行定向探测(directional probes) |
| 雷达(Radar) | 最大探测距离、灵敏度、过载(G-force)限制 | 向目标靠近、信号放大、改变脉冲重复间隔(PRI)与多普勒参数、提高重放速率 |
| 通信(Communications) | 节点响应时间;网络恢复时间;网络恢复方法 | 精准分组干扰(surgical packet jamming)、自触发崩溃攻击(self-collapse trigger attacks)、在网络恢复期间实施分段式攻击(piecewise attack during recovery) |
| 通信(Communications) | 网络关键节点 | 隔离节点(isolate nodes) |
| 通信与雷达(Communications and radar) | 电子支援(ES)识别能力、电子防护(EP)方法、电子攻击(EA)的敏捷性与精度 | 诱饵序列(honeypot sequences)、伪装信号特征(camouflage signatures) |
还需注意,通信既可发生在平台之间(平台间通信,interplatform),也可发生在同一平台内部(平台内通信,intraplatform),即同一平台上多个决策者之间的通信。本节聚焦于平台间通信,但类似的推理也适用于更简单的平台内通信问题。
当时间和带宽允许时,各节点可交换观测结果与决策,以改进或重新校准其对态势的理解。数据融合(data fusion)有助于消除歧义、降低模型中的不确定性,并加快对先前未知威胁的识别速度。例如,一组节点可融合各自对仅能短暂观测到的威胁的估计结果。图6.5展示了通信能力对综合防空系统(Integrated Air Defense System, IADS)任务规划的潜在影响:随着可用通信能力的增强,更多低优先级威胁得以被有效压制。
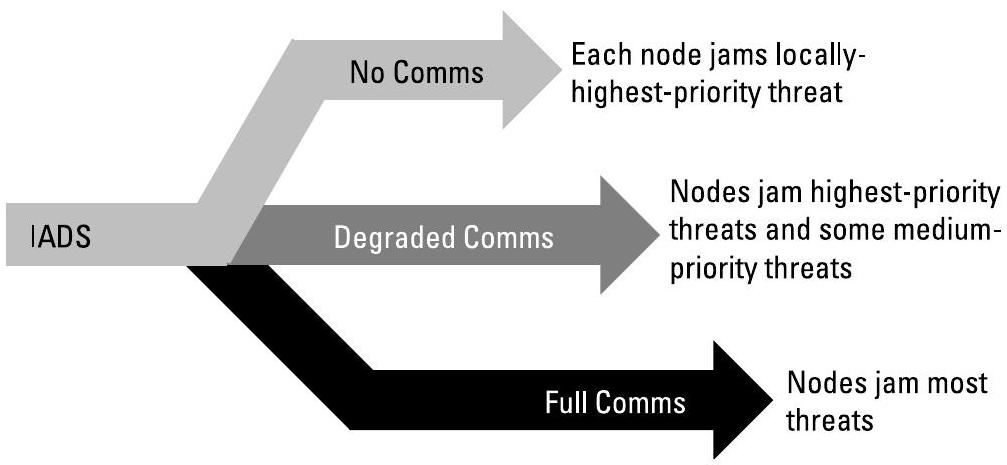
图6.5 任务完成程度依赖于可用于协同的通信资源。
在有限通信条件下执行分布式优化的广泛背景下,传统方法通常假设通信是安全且充足的。然而在电子战(EW)环境中,这一假设并不成立:通信可能因干扰(jamming)、机动导致的链路中断,或为降低射频(RF)辐射而做出的有意限制而变得受限甚至被拒止。对“何时通信”进行推理,可在通信受限条件下实现接近最优的结果[57–61]。系统可根据对通信或感知所带来收益的定量评估,最小化通信的操作与计算开销。决策(DM)过程中涉及的选择与权衡包括:
- 信息类型:意外结果;高惩罚后果;关键协同需求;模糊或冲突的观测;不确定的变量、预测或推断;陌生概念;假设(用于检验假说)。
- 通信对象:参与协同行动的节点;存在时间依赖关系的节点;邻近节点。
- 抽象层级:根据任务不同,采用不同的状态与动作抽象层次。
- 成本考量:能量消耗;暴露风险;信道拥塞;协同开销;决策错误的代价。
节点通信所采用的细节层级,决定了它们在需要时能够实现的协同程度,以及所能执行的协同动作类型。同时,这也直接影响求解问题所需的计算与通信成本。(即使在通信瞬时且无成本的理想场景中,将所有信息广播给所有节点也无法扩展[48]。)更丰富的通信语言更具信息量(例如包含详细的当前状态[62]),有助于做出更协调的决策,但会导致问题规模显著增大。在较简化的语言中,节点可交换关于具有非局部效应(nonlocal effects)动作的承诺(commitments)[63]。而在最简语言中,节点仅能发出“某项具有非局部效应的动作已完成”的信号;但要使该信息具有意义,接收方必须事先了解该动作完成对其发送方未来意图的隐含意义。
节点还可利用隐式通信(implicit communication)传递信息。该方法假设其他节点能够通过观察动作或状态变化来推断发生了什么,而无需显式交互。这种方式与第5.4节所述的去中心化协同方法相辅相成。
本体(Ontologies)是表示信息的一种手段(见第8.1.2节),可与规划器的通信语言联合使用。
6.1.5 时序规划与资源管理(Temporal Planning and Resource Management)¶
持久性交战(protracted engagements)要求对共享资源(包括通信)具备态势感知并进行协调。节点具有异构性,资源受限(且可能不可再生),分布式任务必须协同执行。在规划中引入资源管理,可确保资源优化与电子战(EW)策略选择采用统一的方法。(忽略资源约束将导致生成不可行的计划,和/或需要根据第7.1节所述的执行监控进行频繁更新。)规划器必须根据任务模型,在资源所需的时间尺度上,以最优方式利用资源来应对当前及预期威胁。时序规划与时序资源规划紧密耦合,因为资源使用本质上通常具有时序性。若多个动作以冲突方式使用同一资源,则它们的时序重叠将受到限制。
认知雷达的关键特征在于必须满足来自硬件、平台或环境的各种约束。在现实中,这些约束性需求往往相互矛盾。雷达系统工程的艺术就在于通过协调系统中不同的硬件与软件组件,在各项需求之间达成良好折衷,以满足这些约束。
——R. Klemm 等人 [64]
考虑一个由异构节点组成的编队:机载资产必须与地面电子战系统共存并协同执行任务。任务向资产的合理分配取决于可用资源(如发射功率、频段、作用距离、观测角度、到达目标时间等)以及友军因素(如最小化误伤(fratricide minimization))。例如,地面系统虽具备更长的在位时间(time-on-station),但其作用距离更有限且更易受攻击。规划器在分配任务时必须有效管理这些权衡。
资源管理确保资源在单个节点本地以及在节点协同组之间按需可用并被合理使用。规划器通过以下方式实现这一目标:(1) 跟踪当前及预期的资源使用情况;(2) 确定应向其他节点共享哪些资源使用信息;(3) 以高效且及时的方式共享该信息。
资源具有相应的容量(capacity),可以是类别型值(如“可用/不可用”),也可以是数值型值以追踪消耗情况。可消耗资源(consumable resources)可能是可再生的或一次性使用的,并且可能被多个任务共享,也可能专属于单一任务。
通过将资源消耗因素纳入规划器,我们可确保所做决策既能有效应对威胁态势,又能遵守长期的分布式资源约束。资源约束已成功整合进面向单个[65]和多个[66]决策者的决策理论模型中。
博弈论方法也与此相关(见第6.2节)(例如,用于寻找公平的资源分配方案)。各类优化与调度方法同样可完成此类任务;相关综述参见[7, 67–69]或第5章。多臂老虎机(Multi-armed bandits,见第7.3.4节)方法亦具实用性。
不同的资源建模方法对资源推理能力产生不同影响。在第6.1.3节定义的基础上进行扩展,我们可通过增强奖励函数 \(R\) 或状态描述 \(s\) 来建模资源。表6.3概述了以下选项:
- 通过代价管理本地资源消耗:最简单的方法是将本地资源消耗直接纳入奖励函数,从而同时优化领域奖励与资源使用。
- 将本地资源水平纳入状态:更丰富的表达方式是将资源概要(resource profiles)嵌入状态中,使规划器能够推理动作对资源的长期累积影响。对于燃料或可用诱饵数量等可消耗资源(consumable resources),必须在其对任务最有效时加以使用。节点 \(n\) 的增强状态 \(\overline{s_{n}}\) 定义为 \(\overline{s_{n}} = \left\langle s_{n}, q_{1}, \ldots, q_{K} \right\rangle\),其中每个 \(q_{k}\) 表示资源 \(k\) 的剩余可用量,\(s_{n}\) 为原始状态。转移函数 \(P\) 作用于该增强状态,所得函数 \(\overline{P_{n}}\left(\bar{s}_{n}^{\prime} \mid \bar{s}_{n}, a_{n}\right)\) 确保仅允许与动作资源消耗一致的状态转移:
- 将共享资源水平纳入状态:共享资源不完全受单个节点控制,因此需要协同。当节点协同工作时,可交换包含共享资源使用概率的抽象信息。因此,\(\bar{P}_{n}\) 需考虑其他节点采取的动作对共享资源的影响。例如,两个节点在传输时调整其发射功率,以使它们在目标处的合成信噪比(SNR)达到期望水平。随着节点(无论是友方还是敌方)移动,各节点需动态更新其功率等级。
这种将决策(DM)与资源管理统一的方法,使规划器能够同时权衡资源影响与攻击效能。规划器综合考虑动作对即时、近期及长期任务目标的影响。
表6.3 资源建模的不同方法
| 网络范围(Network Scope) | 时间范围(Temporal Scope) | 方法(Approach) |
|---|---|---|
| 本地(Local) | 即时(Immediate) | 考虑动作的资源消耗: \(R_{n}\left(s_{n}, a_{n}\right) = R_{n}\left(s_{n}, a_{n}\right) - \sum_{k=1}^{K} c_{k} \times \operatorname{needs}\left(a_{n}, k\right)\) |
| 本地(Local) | 长期(Long-term) | 在状态中捕获本地资源: \(\overline{s_{n}} = \left\langle s_{n}, q_{1}, \ldots, q_{r} \right\rangle\), 并使用增强转移函数 \(\bar{P}_{n}\left(\bar{s}_{n}^{\prime} \mid \overline{s_{n}}, a_{n}\right)\) |
| 全局(Global) | 长期(Long-term) | 在状态中捕获共享资源: \(\bar{P}_{n}\left(\overline{S_{n}}^{\prime} \mid \bar{S}_{n}, \vec{a}_{n}\right)\) |
其中:\(s_{n}\) = 节点 \(n\) 的状态;\(\overline{s_{n}}\) = 节点 \(n\) 的增强状态; \(a_{n}\) = 节点 \(n\) 的动作; \(c_{k}\) = 资源 \(k\) 的单位代价;\(\operatorname{needs}\left(a_{n}, k\right)\) = 动作 \(a_{n}\) 对资源 \(k\) 的需求量; \(K\) = 资源总数。
6.1.6 多时间尺度(Multiple Timescales)¶
系统设计需回答的一个关键问题是:如何处理不同时间尺度下的决策(DM)。各类决策可能具有不同的前置时间(lead times);动作可能具有不同的持续时间;而性能指标也可能在不同延迟后才能被测量。图6.6展示了这些时间分组。高优先级任务常常在平台内部及平台之间产生冲突,且底层架构的选择会制约上层能力的实现。
最有效的方法是将各规划器完全解耦(decouple)。例如,设置一个以“天”为单位运行的规划器、一个以“分钟”为单位运行的规划器,以及一个以“毫秒”为单位运行的规划器。每一层时间抽象都会对其下层(或多层)施加约束。该方法设计、实现和测试均较为简单,并支持在不同尺度上进行专门化的推理。
在单一规划器内部,也可能有益于采用多层抽象进行推理,并在每次迭代中逐步提高时间分辨率。尽管这种方法比解耦式规划器更难设计,但由于所有依赖关系都是显式建模的,因此可能产生显著更优的解决方案。
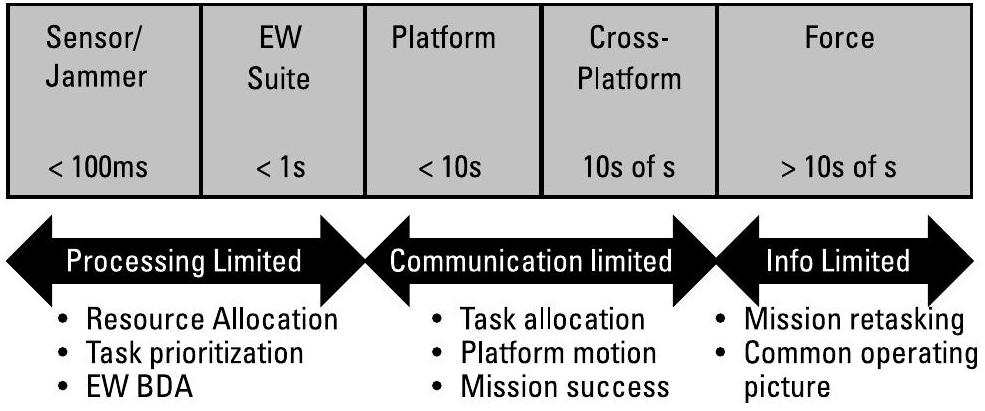
图6.6 不同的时间需求驱动不同的架构选择。
6.2 博弈论(Game Theory)¶
博弈论(Game Theory)是一套用于建模多个实体之间战略性、复杂交互关系的分析工具。当某一动作结果的不确定性取决于其他参与方如何反应时,博弈论可支持在不确定环境中的决策(DM)[70, 71]。
博弈论既能刻画合作行为,也能刻画竞争行为。它适用于协同团队、资源分配以及对抗性场景。在合作博弈(cooperative games)中,个体可在选择动作前达成协议;而在非合作博弈(noncooperative games)中,则对自私但理性的个体行为进行建模。
在团队协作场景中,博弈论可用于处理自组织、去中心化的网络,其中个体虽具有自利性,但必须通过合作以最大化整体性能[72–74]。这种“合作性自利”(cooperative self-interest)也延伸至分布式资源使用问题。博弈论已应用于射频(RF)领域,包括功率控制、接入控制和网络管理等[68, 73–76]。
博弈论也是处理对抗性(竞争性)情境的有效方法。它在安全领域广受欢迎,常用于建模攻击者与防御者之间的互动,例如网络安全[77–79],以及电子战(EW)中对抗干扰机的场景[80–87]。Sundaram 等人[88]研究了防御性电子防护(EP)动作具有成本的情形,而 Blum[89]则探讨了包括虚张声势(bluffing)在内的电子对抗措施,以制造不确定性。
混合策略的博弈论决策可被视作“掷有偏骰子”:传统上,决策者选择单一最优动作;而在对抗性博弈中,决策者则根据一个概率分布选择半随机动作,该概率是直接效用与对手可能反应的函数。这种随机性使对手更难以预测己方行动。
要在电子战(EW)决策器中引入博弈论,必须应对两大关键挑战:(1) 对敌方目标的置信度(confidence about adversary goals);(2) 计算成本(computational cost)。
在对抗性场景中,该方法依赖于对敌方效用函数(adversary's utility)的估计。零和博弈(zero-sum games)假设每个参与者的损失与收益恰好被其他参与者的收益或损失所抵消(即所有参与者的总收益与总损失之和为零)。零和博弈可通过线性规划求解。电子战通常假设“当己方部队失败时,敌方即获胜”,但这一简化并不总是成立。此外,某些博弈可能在一个维度上是零和的,但在另一维度上却非零和,这进一步增加了决策(DM)问题的复杂性。
算法博弈论(Algorithmic game theory)研究博弈论的计算层面,重点在于在计算复杂度合理受限的前提下寻找解。总体而言,博弈论解法在计算上通常十分困难,但可通过构造近似解或针对特定问题的专用解来应对。
6.3 人机界面(Human-Machine Interface)¶
成功的人机界面(HMI)设计必须具备直观性、灵活性、可扩展性以及高度响应性。HMI系统的主要目标应为:(1) 提升作战性能,(2) 增强效能,以及 (3) 减轻飞行员/驾驶员、电子战军官(Electronic Warfare Officers, EWOs)和任务规划人员的任务负荷。该系统应为操作员提供一套广泛且直观的显示与控制手段,以实现其对电子战(EW)系统功能与数据的及时交互。经过周密考虑的HMI设计对于维持态势感知(situational awareness)至关重要。
通常,HMI将人类操作员的动作转换为机器的指令动作,再将机器的传感数据转换回人类操作员,如图6.7所示 [90]。在传统HMI中,这些转换过程是静态的,不会根据人类操作员、机器或环境的状态而变化。
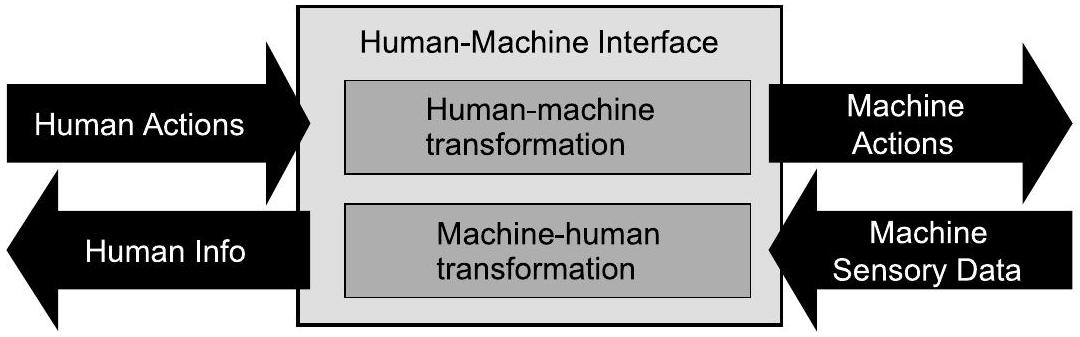
图6.7 HMI在人与机器之间进行转换(改编自 [90])。
人机协同(Human-Machine Teaming, HMT)正是为弥补这一缺陷而提出的:转换过程不再是静态的,可引入智能体(intelligent agents)和机器学习(Machine Learning, ML)。HMT是指人类操作员与机器之间的一种关系,其内涵超越了人类对机器的单纯操作或监督 [90,91]。这一不断发展的学科旨在构建高效协作的团队,其中人类操作员与自动化系统互为互补的团队成员 [92, 93]。为设计符合伦理且值得信赖的人工智能系统,HMT框架应围绕以下四大主题展开 [94]:
- 对人类负责(Accountability to humans);
- 对潜在风险与收益的认知(Cognizance of speculative risks and benefits);
- 尊重与安全性(Respectfulness and security);
- 诚实性与可用性(Honesty and usability)。
此外,人与机器之间的相互关系还将面临以下五个主要方面或技术挑战 [95]:
- 人类状态感知与评估(Human state sensing and assessment):包括性能、行为和生理因素;
- 人机交互(Human-machine interaction):人与机器之间的通信与信息共享;
- 任务与认知建模(Task and cognitive modeling):通过任务与功能分配建立工作负荷与决策(Decision-Making, DM)的平衡;
- 人类与机器学习(Human and ML):人与机器之间的自适应学习与持续相互训练;
- 数据融合与理解(Data fusion and understanding):融合人类与机器的数据,生成共享的世界模型(shared world model)。
电子战兵力管理(Electronic Battle Management, EBM)系统负责规划部署多少平台、每个平台分配哪些资源,以及它们将部署至何处。为实现所有这些目标,EBM系统可受益于多个支持人机协同(Human-Machine Teaming, HMT)的人机界面(HMI),并可能需要与图1.4所示EBM系统中每个概念模块建立交互节点。此外,设置一个覆盖全局的顶层HMI,为整个EBM系统提供端到端(end-to-end)能力,也可能大有裨益。在每一个基于HMT的HMI处,都必须建立信任关系。图6.8展示了认知电子战(cognitive EW)系统中EBM各组件潜在的HMI交互节点。
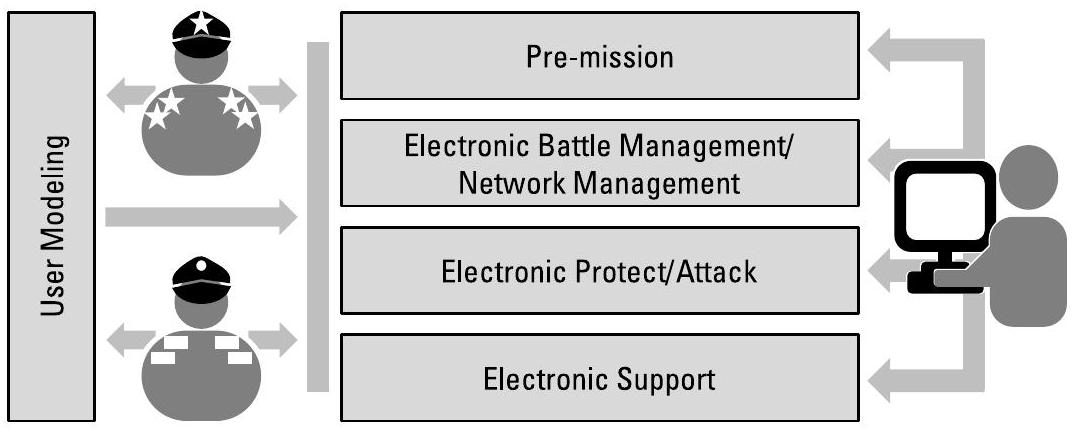
图6.8 任务前规划人员、电子战军官(EWOs)和系统设计人员在所有节点与系统交互;系统必须接受他们的指令与输入,跟踪其任务,学习其偏好,并解释自身的决策。
这些交互节点因认知电子战系统参与者(即系统设计人员、指挥官、任务规划人员、EWOs以及认知系统本身)的不同而有所差异。下文重点介绍各类利益相关者可能关注的部分概念或交互节点。
系统设计人员对系统运行方式具有最大影响力,却常常被忽视,未能被视为人机团队中的关键成员。利用人类专业知识可提升人工智能(AI)组件的性能,从而支持EWOs和电子战任务。自规划系统最初诞生以来,便已开始利用人类专业知识,例如在分层任务网络(Hierarchical Task Network, HTN)规划器中体现领域引导(domain-guidance)的强大作用(见第6.1.2节)。Haigh等人[96]讨论了射频(RF)领域中的混合机器学习(ML)模型,作为神经符号人工智能(neurosymbolic AI)方法的一个实例,该方法旨在融合数值方法(如神经网络)与符号方法(即人类可理解的概念)[97, 98]。设计人员可提供以下内容:
- 关于任务类型、用户和平台的假设;
- 用于表示的概念(例如通过本体论(ontologies)表示,见第6.1.4节);
- 系统可观测量(observables)、可控量(controllables)和度量指标的选择;
- 用于电子支援(Electronic Support, ES)的抽象特征构建(例如跨层交互,或地形对信号传播的影响)。例如,Haigh等人[96]利用“到邻节点的距离”来初步估算移动自组织网络(MANET)的吞吐量;
- 状态空间(statespace)的约简及优化引导(例如相关或关键参数、当前运行空间及约束条件);
- 所学模型的类型选择(例如根据结果所需可解释性程度,在决策树与深度神经网络(DeepNets)之间权衡[99]);
- 在所学模型内部,根据数据类型、推理需求、速度或精度要求调整模型形式(例如改变模型结构);
- 用于减少搜索开销的启发式搜索策略。专家和离线仿真可生成适用于决策者的语言所表达的指南与规则。例如,Mitola[100]提出了无线电知识表示语言(Radio Knowledge Representation Language, RKRL),而策略描述语言(policy description language)则用于管理无线电网络中的频谱共享[101]。
指挥官(Commanders)负责控制并指导任务中的所有参与者。系统必须准确捕获其作战目标与总体构想。指挥官意图(Commander's Intent, CI) 是整个电子战(EW)任务团队的关键概念,用于描述可接受的风险水平、可行的方法以及成功条件等要素。人类参与者与机器生成的决策支持系统都必须具备沟通和解读共享CI的能力 [102, 103]。例如,Gustavsson 等人 [102] 提出了一种将CI与作战效果(effects)关联的模型,同时支持传统军事规划和基于效果的作战(effects-based operations)。
效用(Utility) 用于量化目标。Roth 等人 [104] 将高层级效用分解为系统运行所需的低层级规范。Haigh 等人 [105] 描述了基于策略(policy-based)的方法,由人类专家制定策略,并将其转化为可实施、具有作战意义的目标函数(objective function)。一个令人满意的目标函数必须满足以下四个条件:(1) 具备作战意义;(2) 足够灵活;(3) 易于修改;(4) 在实践中可实施且可优化。
任务规划人员与电子战军官(EWOs)在任务前规划阶段和实时作战阶段均与电子战系统交互。他们必须能够引导和控制自动化系统,并理解所有反馈信息。任务规划人员可用的电子战资源包括:情报与作战数据数据库、(自动)规划器、空间与传播建模工具,以及在所需信息无法立即获取时的回传支援(reach-back support)[1](见图6.9)。

图6.9 多种决策辅助工具可协助人类电子战规划人员。
混合主动规划(Mixed-initiative planning) 是一种交互式制定计划的方法;例如,自动规划器呈现多种权衡选项,由人类规划员从中选择 [4, 22, 106, 107]。论证(Argumentation) 是向人类呈现冲突概念的自然方式,既能说明某项观测可能成立或某项决策可能合理的原因,也能指出反面理由(包括欺骗性因素)[56, 108, 109]。战术手册界面(Playbook interfaces) 允许用户调用一个“战术”(play),并根据当前态势进行定制 [110, 111]。受体育战术手册启发,此类界面假设每位参与者都了解战术的大致框架,且每个战术都已由团队充分演练过。共享任务模型(shared-task model) 为人类与自动化系统之间就计划、目标、方法和资源使用进行沟通提供了一种机制。雷神公司(Raytheon)的电子战规划与管理工具(EW Planning and Management Tool, EWPMT)就采用了战术手册界面(见例6.4)。战术手册界面还有一个额外优势:它天然契合分层任务网络(HTN)规划(见第6.1.2节)。例如,Goldman 等人 [21] 提出了一种带战术手册图形用户界面(GUI)的混合主动规划系统,用于为异构无人机(UAV)编队生成、校验和修改作战计划。最后,可调自主性(adjustable autonomy) 的概念允许人类用户为平台授予不同级别的自主权 [115]。
例 6.4 雷神公司(Raytheon)的 EWPMT 利用“战术”(plays)与电子战人员交互。
雷神公司的电子战规划与管理工具(EW Planning and Management Tool, EWPMT)软件旨在提升机动指挥官规划、协调和同步电子战(EW)、频谱管理及网络作战(Cyber operations)的能力 [112–114]。自2014年起,EWPMT 已成为美国陆军的正式列装项目(program of record)。
EWPMT 提供电子战任务规划、电子战目标定位和仿真能力,以支持作战行动方案(Course of Action, COA)的制定。该工具可构建电磁战场态势图(electromagnetic order of battle),协调电子战与通信资产以避免冲突,并可视化展示电磁作战环境 [113]。EWPMT 能实时接收传感器数据,并提供自动化处理与分析功能,使用户能够快速识别新威胁、对该威胁进行地理定位,并共享相关信息 [112]。
自动化的“战术”(Automated "plays")有助于减轻野战环境中电子战人员的认知负荷。当满足特定条件时(例如,若传感系统检测到某频率上的传感器信号,则自动关闭该频率上的传感器),系统可触发自动化操作 [112]。
除了上述规划与控制方法外,人类还可通过其他方式支持电子支援(Electronic Support, ES),例如对未知信号进行标注,或提供辅助性的人力情报(Human Intelligence, HumanINT)证据,如环境条件(例如地形、天气或威胁信息)。
人机协同(Human-Machine Teaming, HMT)中另一个未被充分重视的概念是:机器对人类用户的理解。偏好学习(Preference learning) 可在用户难以明确表达其偏好的情况下,捕捉其偏好信息 [116]。偏好学习方法可学习效用函数(即学习一个函数以解释为何选项 \(a\) 优于选项 \(b\)),或学习偏好关系(即选项之间的偏序图)。偏好学习可基于显式或隐式反馈进行 [117]。Bantouna 等人 [118] 利用贝叶斯统计方法学习用户对服务质量(QoS)的偏好。意图识别(Intent Recognition)(见第4.6节)则试图理解用户试图达成的目标;该信息可用于预判用户需求并定制化显示内容。
认知电子战(cognitive EW)系统的设计者/开发者可能希望采用敏捷软件开发方法(agile software development approach),其原则同样适用于硬件开发。在敏捷方法中,通过编写用户故事(user stories) 以最高层级捕捉每位用户的需求与期望功能。用户故事的目的是阐明某项功能如何为各类利益相关者创造价值 [119]。在人机界面(HMI)的语境下,这些用户故事应涵盖每位终端用户所需的所有必要接口/交互节点。用户故事是从终端用户视角撰写的、对某项功能的非正式且概括性的描述,其形式可简单如下 [120]:
作为一名[用户类型],我希望[目标],以便[原因]。
用户故事并非系统需求本身,而是一种确保各类需求在后续开发过程中“不失真”的手段。
敏捷软件开发的一个关键要素是以人为本,而用户故事将终端用户置于讨论的核心。这些故事使用非技术性语言,为开发团队及其工作提供上下文。团队在阅读用户故事后,便清楚自己为何而建、建造什么,以及所创造的价值是什么。[119]
在最高层级上,认知电子战系统的用户即为其利益相关者:系统设计人员、指挥官、任务规划人员、电子战军官(EWOs)以及机器或智能体(intelligent agents)。敏捷方法支持良好的人因工程(human factors)设计,要求从项目初期就定期征询利益相关者的意见。MITRE 的 HMT 工程指南为此过程提出了具体方法建议 [91]。
6.4 结论¶
自动化电子战兵力管理(Electronic Battle Management, EBM)规划系统必须在电子战(EW)规划的各个阶段——远程规划、中期规划和实时任务管理——全面支持人类规划人员。多个紧密耦合的决策者可分别处理各自关注的问题。
分层任务网络(Hierarchical Task Network, HTN)规划器适用于复杂领域,天然支持人机协同(Human-Machine Teaming, HMT)所要求的透明性、可解释性与可控性。任务中重规划(in-mission replanning)(见第7.2节)可确保即便在遭遇意外情况或任务目标发生变化时,作战计划仍保持可行性。
规划器必须同时应对行动不确定性与信息不确定性,管理时间与资源约束,并决定与团队成员通信的内容及时机。领域特定的启发式方法与元学习(metalearning)(见第5.1.3节)有助于优化搜索过程。博弈论方法(game-theoretic approaches)则有助于协调合作型团队管理并应对竞争性对手。
References¶
[1] Chairman of the Joint Chiefs of Staff, Joint publication 3-13.1: Electronic warfare, 2012. Online: https://fas.org/irp/doddir/dod/jp3-13-1.pdf.
[2] US Air Force, Air Force Operational Doctrine: Electronic Warfare, Document 2-5.1, 2002. Online: https://tinyurl.com/af-ew-2002-pdf.
[3] Haigh, K. Z., and M. Veloso, "Planning, Execution and Learning in a Robotic Agent," in AIPS, Summary of Haigh's Ph.D. thesis, 1998.
[4] Siska, C., B. Press, and P. Lipinski, "Tactical Expert Mission Planner (TEMPLAR)," TRW Defense Systems, Tech. Rep. RADC-TR-89-328.
[5] Miller, G., "Planning and Scheduling for the Hubble Space Telescope," in Robotic Telescopes, Vol. 79, 1995.
[6] Adler, D., D. Taylor, and A. Patterson, "Twelve Years of Planning and Scheduling the Hubble Space Telescope: Process Improvements and the Related Observing Efficiency Gains," in Observatory Operations to Optimize Scientific Return III, International Society for Optics and Photonics, Vol. 4844, SPIE, 2002.
[7] Benaskeur, A., E. Bossé, and D. Blodgett, "Combat Resource Allocation Planning in Naval Engagements," Defence R\&D Canada, Tech. Rep. DRDC Valcartier TR 2005-486, 2007.
[8] Russell, S., and P. Norvig, Artificial Intelligence: A Modern Approach, Pearson Education, 2015.
[9] Helmert, M., Understanding Planning Tasks: Domain Complexity and Heuristic Decomposition, Springer, 2008. (Revised version of Ph.D. thesis.)
[10] Wilkins, D., Practical Planning, Morgan Kaufmann, 1998.
[11] International Conference on Automated Planning and Scheduling Competitions. Accessed 2020-09-12. Online: https://www.icapsconference.org/competitions/.
[12] Yuen, J., "Automated Cyber Red Teaming," Defence Science and Technology Organisation, Australia, Tech. Rep. DSTO-TN-1420, 2015.
[13] Haslum, P., et al., An Introduction to the Planning Domain Definition Language, Morgan \& Claypool, 2019.
[14] Korf, R., "Heuristic Evaluation Functions in Artificial Intelligence Search Algorithms," Minds and Machines, Vol. 5, 1995.
[15] Liang, Y.-q., X.-s. Zhu, and M. Xie, "Improved Chromosome Encoding for Genetic-Algorithm-Based Assembly Sequence Planning," in International Conf. on Intelligent Computing and Integrated Systems, 2010.
[16] Brie, A., and P. Morignot, "Genetic Planning Using Variable Length Chromosomes," In ICAPS, 2005.
[17] Goodwin, M., O. Granmo, and J. Radianti, "Escape Planning in Realistic Fire Scenarios with Ant Colony Optimisation," Applied Intelligence, Vol. 42, 2015.
[18] Erol, K., J. Hendler, and D. Nau, "HTN Planning: Complexity and Expressivity," in \(A A A I\), 1994.
[19] Erol, K., J. Hendler, and D. Nau, "Complexity Results for HTN Planning," Institute for Systems Research, Tech. Rep., 2003.
[20] Georgievski, I., and M. Aiello, "HTN Planning: Overview, Comparison, and Beyond," Artificial Intelligence, Vol. 222, 2015.
[21] Goldman, R. P., et al., "MACBeth: A Multiagent Constraint-Based Planner," in Digital Avionics Systems Conference, 2000.
[22] Mitchell, S., "A Hybrid Architecture for Real-Time Mixed-Initiative Planning and Control," in AAAI, 1997.
[23] Qi, C., and D. Wang, "Dynamic Aircraft Carrier Flight Deck Task Planning Based on HTN," IFAC-PapersOnLine, Vol. 49, No. 12, 2016, Manufacturing Modelling, Management and Control.
[24] Kott, A., et al., Toward Practical Knowledge-Based Tools for Battle Planning and Scheduling, AAAI, 2002.
[25] Ground, L., A. Kott, and R. Budd, "Coalition-Based Planning of Military Operations: Adversarial Reasoning Algorithms in an Integrated Decision Aid," CoRR, 2016.
[26] Kott, A., et al., Decision Aids for Adversarial Planning in Military Operations: Algorithms, Tools, and Turing-Test-Like Experimental Validation, 2016. Online: https://arxiv.org/ abs/1601.06108.
[27] Alford, R., U. Kuter, and D. Nau, "Translating HTNs to PDDL: A Small Amount Of Domain Knowledge Can Go a Long Way," in IJCAI, 2009.
[28] Kuter, U., and D. Nau, "Using Domain-Configurable Search Control for Probabilistic Planning," AAAI, 2005.
[29] Victoria, J., "Automated Hierarchical, Forward-Chaining Temporal Planner for Planetary Robots Exploring Unknown Environments," Ph.D. dissertation, Technical University of Darmstadt, Germany, 2016.
[30] Andersen, M., T. Bolander, and M. Jensen, "Conditional Epistemic Planning," in Logics in Artificial Intelligence, 2012.
[31] To, S., T. Son, and E. Pontelli, "Contingent Planning as AND/OR Forward Search with Disjunctive Representation," in ICAPS, 2011.
[32] Blum, A., and J. Langford, "Probabilistic Planning in the Graph Plan Framework," in European Conference on Planning, 1999.
[33] Majercik, S., and M. Littman, "Contingent Planning Under Uncertainty via Stochastic Satisfiability," in AAAI, 1999.
[34] Ferraris, P., and E. Giunchiglia, "Planning as Satisfiability in Nondeterministic Domains," in AAAI, 2000.
[35] Joshi, S., and R. Khardon, "Probabilistic Relational Planning with First Order Decision Diagrams," Artificial Intelligence Research, Vol. 41, 2011.
[36] Mausam, W., and A. Kolobov, Planning with Markov Decision Processes: An AI Perspective, Morgan \& Claypool, 2012.
[37] Sutton, R., and A. Barto, Reinforcement Learning: An Introduction, Bradford, 2018.
[38] Littman, M., T. L. Dean, and L. P. Kaelbling, "On the Complexity of Solving Markov Decision Problems," in Uncertainty in AI, 1995.
[39] Gupta, A., and S. Kalyanakrishnan, "Improved Strong Worst-Case Upper Bounds for MDP Planning," in IJCAI, 2017.
[40] Jinnai, Y., et al., "Finding Options That Minimize Planning Time," in ICML, 2019.
[41] McMahan, B., and G. Gordon, "Fast Exact Planning in Markov Decision Processes," in ICAPS, 2005.
[42] Taleghan, M., et al., "PAC Optimal MDP Planning with Application to Invasive Species Management," Vol. 16, 2015.
[43] Busoniu, L., et al., "Optimistic Planning for Sparsely Stochastic Systems," in Adaptive Dynamic Programming, 2011.
[44] van Seijen, H., and R. Sutton, "Efficient Planning in MDPs by Small Backups," in ICML, 2013.
[45] Zhang, J., M. Dridi, and A. Moudni, "A Stochastic Shortest-Path MDP Model with Dead Ends for Operating Rooms Planning," in International Conference on Automation and Computing, 2017.
[46] Yoon, S., A. Fern, and R. Givan, "FF-Replan: A Baseline for Probabilistic Planning," in ICAPS, 2007.
[47] Teichteil-Koenigsbuch, F., G. Infantes, and U. Kuter, "RFF: A Robust, FF-Based MDP Planning Algorithm for Generating Policies with Low Probability of Failure," in ICAPS, 2008.
[48] Oliehoek, F., and C. Amato, A Concise Introduction to Decentralized POMDPs, Springer, 2016.
[49] Bernstein, D., et al., "The Complexity of Decentralized Control of Markov Decision Processes," Mathematics of Operations Research, Vol. 27, No. 4, 2002.
[50] Varakantham, P., et al., "Exploiting Coordination Locales in Distributed POMDPs via Social Model Shaping," in ICAPS, 2009.
[51] Nair, R., et al., "Networked Distributed POMDPs: A Synthesis of Distributed Constraint Optimization and POMDPs," in AAAI, 2005.
[52] Denoeux, T., "40 Years of Dempster-Shafer Theory," Approximate Reasoning, 2016.
[53] Liu, L., and R. Yager, "Classic Works of the Dempster-Shafer Theory of Belief Functions: An Introduction," Studies in Fuzziness and Soft Computing, Vol. 219, 2008.
[54] Nickravesh, M, "Evolution of Fuzzy Logic: From Intelligent Systems and Computation to Human Mind," in Forging New Frontiers: Fuzzy Pioneers I. Studies in Fuzziness and Soft Computing, Vol. 217, Springer, 2007.
[55] Mogdil, S., and H. Prakken, "The ASPIC* Framework for Structured Argumentation: A Tutorial," Argument and Computation, Vol. 5, No. 1, 2014.
[56] Collins, A., D. Magazzeni, and S. Parsons, "Towards an Argumentation-Based Approach to Explainable Planning," in Explainable Planning, 2019.
[57] Mostafa, H., and V. Lesser, "Offline Planning For Communication by Exploiting Structured Interactions in Decentralized MDPs," in International Conference on Web Intelligence and Intelligent Agent Technology, 2009.
[58] Mogali, J., S. Smith, and Z. Rubinstein, "Distributed Decoupling of Multiagent Simple Temporal Problems," in IJCAI, 2016.
[59] Melo, F., and M. Veloso, "Decentralized MDPs with Sparse Interactions," Artificial Intelligence, Vol. 175, 2011.
[60] Yordanova, V., "Intelligent Adaptive Underwater Sensor Networks," Ph.D. dissertation, University College London, London, UK, 2018.
[61] Ren, P., et al., A Survey of Deep Active Learning, 2020. Online: https://arxiv.org/ abs/2009.00236.
[62] Becker, R., V. Lesser, and S. Zilberstein, "Decentralized Markov Decision Processes with Event-Driven Interactions," in AAMAS, 2004.
[63] Xuan, P., and V. Lesser, "Incorporating Uncertainty in Agent Commitments," in Agent Theories, Architectures, and Languages, 1999.
[64] Klemm, R., et al. (Eds.), Novel Radar Techniques and Applications, Scitech Publishing, 2017.
[65] Altman, E., Constrained Markov Decision Processes, Chapman Hall, 1999.
[66] Dolgov, D., and E. Durfee, "Stationary Deterministic Policies for Constrained MDPs with Multiple Rewards, Costs, and Discount Factors," in IJCAI, 2005.
[67] Muhammad, N., et al., "Resource Allocation Techniques in Cooperative Cognitive Radio Networks," Communications Surveys \& Tutorials, Vol. 16, No. 2, 2013.
[68] Ramzan, M., et al., "Multiobjective Optimization for Spectrum Sharing in Cognitive Radio Networks: A Review," Pervasive and Mobile Computing, Vol. 41, 2017.
[69] Jorswieck, E., and M. Butt, "Resource Allocation for Shared Spectrum Networks,"in Spectrum Sharing: The Next Frontier in Wireless Networks, Wiley, 2020.
[70] Shoham, Y., and K. Leyton-Brown, Multiagent Systems: Algorithmic, Game-Theoretic, and Logical Foundations, Cambridge University Press, 2009.
[71] Nisan, N., et al. (Eds.), Algorithmic Game Theory, New York: Cambridge University Press, 2007.
[72] Saad, W., et al., "Coalitional Game Theory for Communication Networks: A Tutorial," IEEE Signal Processing Magazine, 2009.
[73] MacKenzie, A., and L. DaSilva, Game Theory for Wireless Engineers, Morgan \& Claypool, 2006.
[74] Han, Z., et al., Game Theory in Wireless and Communication Networks: Theory, Models, and Applications, Cambridge University Press, 2012, The course http://www2.egr.uh.edu/-zhan2/ game_theory_course/ contains slides based on the book.
[75] Zayen, B., A. Hayar, and G. Noubir, "Game Theory-Based Resource Management Strategy for Cognitive Radio Networks," Multimedia Tools and Applications, Vol. 70, No. 3, 2013.
[76] Mkiramweni, M., et al., "Game-Theoretic Approaches for Wireless Communications with Unmanned Aerial Vehicles," IEEE Wireless Communications, 2018.
[77] Snyder, M., R. Sundaram, and M. Thakur, "A Game-Theoretic Framework for Bandwidth Attacks and Statistical Defenses," in Local Computer Networks, 2007.
[78] Schramm, H., et al., "A Game Theoretic Model of Strategic Conflict in Cyberspace," Military Operations Research, Vol. 19, No. 1, 2014.
[79] Kasmarik, K., et al., "A Survey of Game Theoretic Approaches to Modelling DecisionMaking in Information Warfare Scenarios," Future Internet, Vol. 8, 2016.
[80] Liu, X., et al., "SPREAD: Foiling Smart Jammers Using Multilayer Agility," in INFOCOM, 2007.
[81] Yang, D., et al., "Coping with a Smart Jammer in Wireless Networks: A Stackelberg Game Approach," IEEE Transactions on Wireless Communications, Vol. 12, No. 8, 2013.
[82] Firouzbakht, K., G. Noubir, and M. Salehi, "Multicarrier Jamming Mitigation: A Proactive Game Theoretic Approach," in Proactive and Dynamic Network Defense, 2019.
[83] Wang, H., et al., "Radar Waveform Strategy Based on Game Theory," Radio Engineering, Vol. 28, No. 4, 2019.
[84] Li, K., B. Jiu, and H. Liu, "Game Theoretic Strategies Design for Monostatic Radar And Jammer Based on Mutual Information," IEEE Access, Vol. 7, 2019.
[85] Zhang, X., et al., "Game Theory Design for Deceptive Jamming Suppression in Polarization MIMO Radar," IEEE Access, Vol. 7, 2019.
[86] Wonderley, D., T. Selee, and V. Chakravarthy, "Game Theoretic Decision Support Framework for Electronic Warfare Applications," in Radar Conference, IEEE, 2016.
[87] Mneimneh, S., et al., "A Game-Theoretic and Stochastic Survivability Mechanism Against Induced Attacks in Cognitive Radio Networks," Pervasive and Mobile Computing, Vol. 40, 2017.
[88] Sundaram, R., et al., "Countering Smart Jammers: Nash Equilibria for Asymmetric Agility And Switching Costs," in Classified US Military Communications, 2013.
[89] Blum, D., "Game-Theoretic Analysis of Electronic Warfare Tactics with Applications to the World War II Era," M.S. thesis, 2001.
[90] Thanoon, M., "A System Development For Enhancement of Human-Machine Teaming," Ph.D. dissertation, Tennessee State University, 2019.
[91] McDermott, P., et al., "Human-Machine Teaming Systems Engineering Guide," MITRE, Tech. Rep. AD1108020, 2018.
[92] Urlings, P., and L. Jain, "Teaming Human and Machine," in Advances In Intelligent Systems For Defence, World Scientific, 2002.
[93] Taylor, R., "Towards Intelligent Adaptive Human Autonomy Teaming," Defence Science and Technology Laboratory, UK, Tech. Rep. STOMP-HFM-300, 2018.
[94] Smith, C., Ethical Artificial Intelligence (AI), 2020. doi: 10.1184/ R1/c.4953576.v1.
[95] Overholt, J., and K. Kearns, Air Force Research Laboratory Autonomy Science \& Technology Strategy, 2014. Online: https://tinyurl.com/afrl-autonomy.
[96] Haigh, K. Z., S. Varadarajan, and C. Y. Tang, "Automatic Learning-Based MANET CrossLayer Parameter Configuration," in Workshop on Wireless Ad hoc and Sensor Networks, IEEE, 2006.
[97] Hilario, M., "An Overview of Strategies for Neurosymbolic Integration," in ConnectionistSymbolic Integration, Lawrence Erlbaum, 1997.
[98] D'Avila Garcez, A., L. Lamb, and D. Gabbay, Neural-Symbolic Cognitive Reasoning, Springer, 2009.
[99] Confalonieri, R., et al., "A Historical Perspective of Explainable Artificial Intelligence," WIREs Data Mining and Knowledge Discovery, Vol. 11, No. 1, 2021.
[100] Mitola III, J., "Cognitive Radio: An Integrated Agent Architecture for Software Defined Radio," Ph.D. dissertation, Royal Institute of Technology (KTH), Kista, Sweden, 2000.
[101] Berlemann, L., S. Mangold, and B. H. Walke, "Policy-Based Reasoning for Spectrum Sharing In Radio Networks," in Symposium on New Frontiers in Dynamic Spectrum Access Networks, 2005.
[102] Gustavsson, P., et al., "Machine Interpretable Representation of Commander's Intent," in International Command and Control Research and Technology Symposium: C2 for Complex Endeavors, 2008.
[103] Gustavsson, P., et al., "Formalizing Operations Intent and Effects for Network-Centric Applications," in International Conference on System Sciences, 2009.
[104] Roth, E., et al., "Designing Collaborative Planning Systems: Putting Joint Cognitive Systems Principles to Practice," in Cognitive Systems Engineering: A Future for a Changing World, Ashgate Publishing, 2017, Ch. 14.
[105] Haigh, K. Z., O. Olofinboba, and C. Y. Tang, "Designing an Implementable User-Oriented Objective Function for MANETs," in International Conference On Networking, Sensing and Control, IEEE, 2007.
[106] Heilemann, F., and A. Schulte, "Interaction Concept for Mixed-Initiative Mission Planning on Multiple Delegation Levels in multi-UCAV Fighter Missions," in International Conference on Intelligent Human Systems Integration, Springer, 2019.
[107] Irandoust, H., et al., "A Mixed-Initiative Advisory System for Threat Evaluation," in International Command and Control Research and Technology Symposium, 2010.
[108] Parsons, S., et al., "Argument Schemes For Reasoning About Trust," Argument \& Computation, Vol. 5, No. 2-3, 2014.
[109] Sarkadi, S., et al., "Modelling Deception Using Theory of Mind in Multiagent Systems," \(A I\) Communications, Vol. 32, No. 4, 2019.
[110] Miller, C., and R. Goldman, "Tasking Interfaces; Associates That Know Who's the Boss," in Human/Electronic Crew Conference, 1997.
[111] Miller, C., et al., "The Playbook," in Human Factors and Ergonomics Society, 2005.
[112] Pomerleau, M., "Here's What the Army is Saying about Its New Electronic Warfare Solution," C4ISRNet, 2018.
[113] US Army, Electronic Warfare Planning and Management Tool (EWPMT), Accessed 2020-0919. Online: https://tinyurl.com/ewpmt-army.
[114] Raytheon, Electronic Warfare Planning Management Tool (EWPMT), Accessed 2020-09-19. Online: https://tinyurl.com/ewpmt-rtn.
[115] Mostafa, S., M. Ahmad, and A. Mustapha, "Adjustable Autonomy: A Systematic Literature Review," Artificial Intelligence Review, No. 51, 2019.
[116] Fürnkranz, J., and E. Hüllermeier, Preference Learning, Springer Verlag, 2011.
[117] Kostkova, P., G. Jawaheer, and P. Weller, "Modeling User Preferences In Recommender Systems," ACM Transactions on Interactive Intelligent Systems, Vol. 4, 2014.
[118] Bantouna, A., et al., "An Overview of Learning Mechanisms for Cognitive Systems," Wireless Communications and Networking, No. 22, 2012.
[119] Rehkopf, M., User Stories with Examples and Template. Accessed 2020-9-28. Online: https:// www.atlassian.com/agile/project-management/user-stories.
[120] Mountain Goat Software, User stories. Accessed 2020-09-28. Online: https://www. mountaingoatsoftware.com/agile/user-stories.