7 任务中实时规划与学习¶
态势感知(Situational Awareness, SA)和决策制定(Decision Making, DM)是所有电子战(Electronic Warfare, EW)系统的关键组成部分。第1至6章介绍了针对这些活动的方法,但并未将其置于任务执行过程中的实际性能背景下进行讨论。
传统的电子战重规划方法假设制定电子防护/电子攻击(Electronic Protection/Electronic Attack, EP/EA)计划与更新电子支援(Electronic Support, ES)模型之间存在较长的时间间隔。而在完全集成的现代电子战系统中,系统能够且必须对任务过程中发生的意外事件做出响应,并从自身经验中学习。
作为控制理论的自然演进,执行监控(Execution Monitoring)跟踪行动结果,使规划器具备适应变化的能力,同时使学习器能够整合经验。
7.1 执行监控¶
电子战系统必须在所有层级上进行执行监控:电子支援(ES)、电子防护/电子攻击(EP/EA)以及电子战行为模型(Electronic Battle Management, EBM)。监控必须在每个平台以及由多个节点组成的团队间同时进行。执行监控依赖于电子支援(ES)能力,并成为电子支援(ES)的一个内省性组成部分。
电子支援(ES)用于描述当前态势/环境。执行监控则将观测到的环境与预期环境进行比较。
图7.1所示的监控行动包括以下内容:
- 传感器监控(Sensor monitoring):原始数据是否正确?传感器是否正常工作?推断出的当前态势是否罕见或异常?传感器信息是否可信?是否存在针对传感器的对抗性攻击(adversarial attack)?
- 模型监控(Model monitoring):电子支援(ES)模型是否正确?态势感知(SA)是否准确?模型是否覆盖当前态势;当前态势是否处于模型的专业领域(domain of expertise)之内?是否存在针对态势推断的对抗性攻击?在使用学习型模型的系统中,输入数据是否符合模型训练时所依据的数据分布(即其专业领域或操作空间)?当系统在任务中持续学习时,概念漂移(concept drift)是否在可接受范围内?
- 行动监控(Action monitoring):某项行动的前提假设或先决条件是否仍然成立?执行行动后,是否出现了预期结果之一?该行动的执行效果如何?预期结果是否出现了虽微小但可能关键的偏差?
- 计划监控(Plan monitoring):计划的剩余部分是否仍然可行?系统是否仍能达成其目标?是否有任务需要重新分配?完成任务所需的成本或时间是否会改变?
- 目标监控(Goal monitoring):在执行行动前,长期目标是否仍然合理?任务是否发生了具有实质意义的变化?是否存在实现额外目标的新机会?
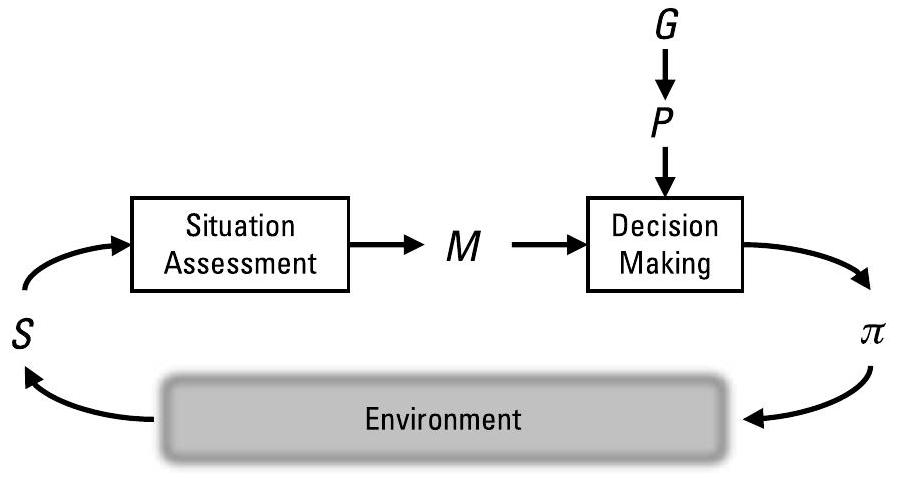
图7.1 在不确定或动态环境中,执行监控必须分析传感器(\(S\))、模型(\(M\))、行动(\(\pi\))、计划(\(P\))和目标(\(G\))。
上述任一问题的失败都可能触发重规划(replanning)或触发学习(learning)。重规划涉及更新计划以应对新态势;学习则用于更新和修正底层模型。
电子支援(ES)能力将预期条件与当前条件进行比对评估。当反馈结果与学习模型的预测一致时,该反馈可支持任务中学习(in-mission learning)的更新。例如,执行监控可通过计算模型的预测误差来触发模型重训练,如例7.1所示。
通过将行动与观测结果关联起来,执行监控能够计算事件之间的因果关系。这种分析使系统能够判断事件是所观测环境的固有特性,还是由特定行动真正引发的前兆(precursors)。随后,系统可将此类前兆事件作为“危险预警信号”(red flags),预示迫在眉睫的威胁。第4.5节描述了如何检测这些模式。
例 7.1:BBN 智能优化器(BBN SO)在任务中对通信电子防护(Communications Electronic Protection, EP)执行实时学习与优化。
BBN SO 能够在面对先前未知的干扰和干扰条件时,学习如何优化网络性能 [35, 51, 52]。该智能优化器(SO)可自动识别影响通信质量的环境条件,并学习选择能提升性能的配置,即使在高度动态的任务环境中亦能如此。SO 是首个已知在任务相关时间尺度上于任务中使用机器学习(Machine Learning, ML)的通信电子防护(EP)系统。
SO 由一个快速响应引擎(Rapid Response Engine, RRE)和一个长期响应引擎(Long-Term Response Engine, LTRE)组成:RRE 负责制定策略决策,LTRE 则学习各策略性能的模型。
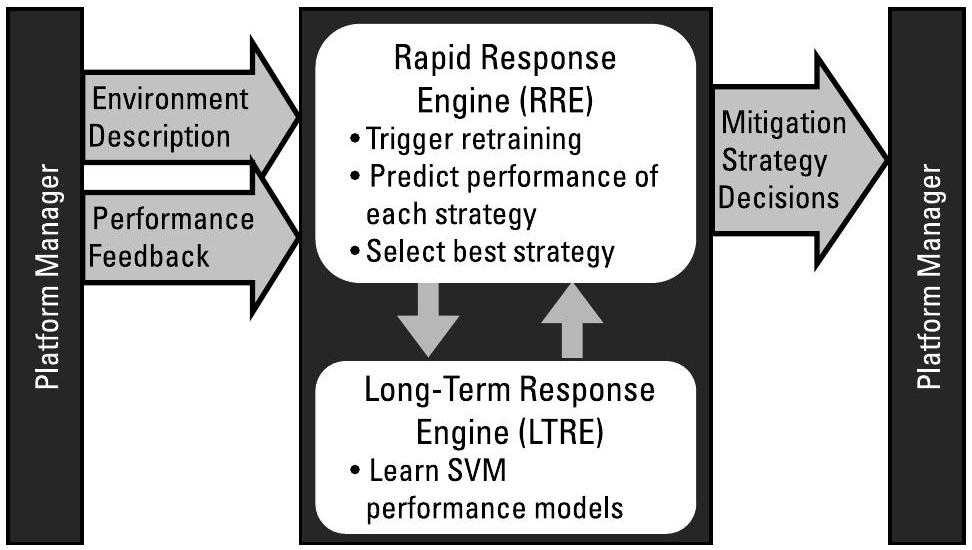
给定一组训练数据(可能为空),LTRE 为每个性能指标构建性能曲面模型:\(m_{k}=f_{k}(o, s)\)。SO 使用支持向量机(Support Vector Machines, SVMs)(见第3.1.1节)作为回归工具来估计性能(见第4.2节)。SO 选用 SVM 是因为其能够从少量训练样本中学习,并且可在资源受限的硬件上实现。由于该设备内存有限,LTRE 会管理数据多样性(见第8.3.2节)并遗忘旧样本(见第8.3.4节)。
随后,RRE 利用这些 SVM 模型 \(f_{k}\),在任务执行过程中依据算法 5.1 快速做出实时策略决策。
SO 能够在资源受限的硬件上,仅凭少量样本(甚至在没有先验训练数据的情况下),实时学习如何缓解通信干扰。
SO 已在多种干扰条件下进行了测试,包括分布式干扰和复杂干扰机(complex jammers),测试环境涵盖仿真、实验室模拟和外场试验。相关结果基于搭载硬实时操作系统(hard real-time operating system)的 PPC440 平台展示 [35]。
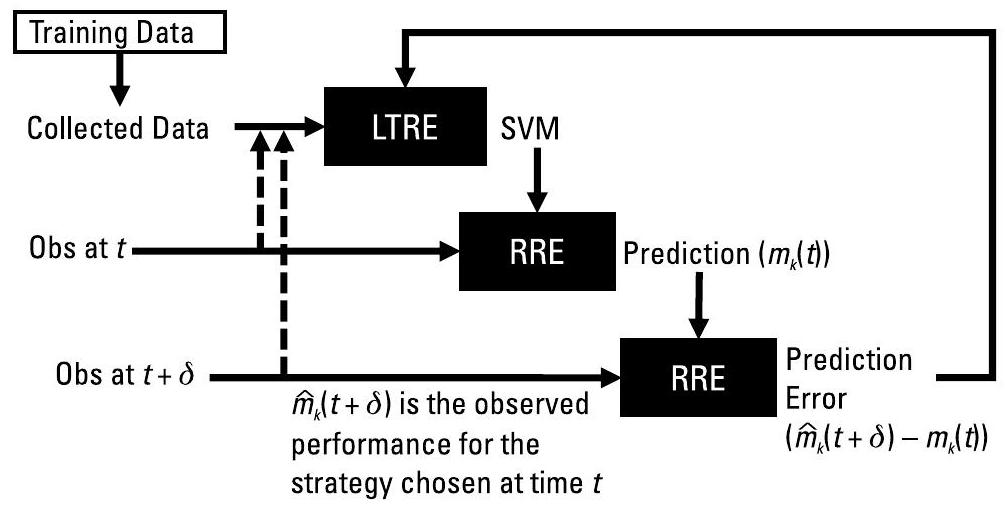
在每个时间步,平台提供可观测量(observables)以及各性能指标 \(m\) 的反馈。若 \(m_{k}(t)\) 的估计性能与观测到的性能 \(\hat{m}_{k}(t+\delta)\) 之间存在显著差异 *, 则 RRE 会触发一次重训练事件,LTRE 将利用新增的训练数据重建 \(m_{k}\) 对应的 SVM 模型。因此,SO 采用强化学习(Reinforcement Learning, RL)在任务相关的时间尺度上实现任务中学习(in-mission learning)。
\({ }^{*}\) BBN SO 使用 \(\delta=1\) 以获取即时反馈。
SO 对平台和问题领域保持中立(agnostic)。所有可观测量(observables)、可控量(controllables)和性能指标(metrics)均在配置 XML 文件中列出。可控量列出了其有效设置值,性能指标则列出了对应的权重和代价。因此,该学习与优化方法可迁移至其他平台、问题集和效用指标(utility metrics)。
BBN SO 属于自 2006 年起开展的面向射频(RF)系统的机器学习(ML)研究系列成果之一 [35, 43, 51–58]。ADROIT [43] 首次将 ML 应用于控制真实世界(非仿真)的移动自组织网络(mobile ad hoc network),展示了对网络层、MAC 层和物理层(PHY)参数的调控能力,以优化应用层的地图质量(map-quality)指标。BBN SO [35] 则是首个在任务执行过程中实时运用 ML 进行学习的通信电子防护(EP)系统,展示了对天线、物理层(PHY)和 MAC 层参数的控制能力以实现 EP。早期工作采用人工神经网络(Artificial Neural Networks, ANNs),虽能达到精度要求,却以较长的训练时间和庞大的训练集为代价。而支持向量机(SVMs)成功解决了这两个挑战。
7.1.1 电子战毁伤评估(Electronic Warfare Battle Damage Assessment, EW BDA)¶
在电子防护(EP)任务中,性能指标通常可直接测量(例如误码率(BER)或吞吐量)。而对于电子攻击(EA)系统,电子支援(ES)则必须推断攻击的有效性。可推断的指标示例包括干扰效能(jamming effectiveness)[1]、雷达工作模式、虚警概率/检测概率(Pfa/Pd)或兴趣点(Point of Interest, POI)。利用测试阶段收集的“真实标签”(ground truth)数据,可训练一个机器学习(ML)模型用于推断这些值,并在运行时加以应用。
例如,一个电子战毁伤评估(EW BDA)系统可估计威胁目标的工作模式或其他行为是否发生了变化。不同雷达模式通过调整不同参数以完成不同任务 [2–5],例如通过改变脉冲宽度(pulse width)以提升搜索能力,或调整脉冲重复间隔(PRI)以改变探测距离 [3]。这些特征的变化可能表明电子攻击(EA)的有效性 [5–10]。
除因果事件分析外,历史模式也可作为有效性的佐证。例如,当某雷达参数连续多次发生变化时,系统可提高对该电子攻击(EA)技术有效性的置信度。基于人工规则构建的毁伤评估(BDA)系统可能会为告警设定阈值或构造规则。每条规则可能贡献一个得分;这些得分可通过算术方式组合,或作为对行动整体有效性的“投票”。然而,随着辐射源(emitters)日益复杂,人工生成的规则很快变得脆弱(brittle)。
为降低人工规则的脆弱性,可将这些特征整合进一个机器学习(ML)模型中。任何 ML 模型(包括规则学习模型)均可作为 BDA 评分引擎。标准的分类方法能够融合多个特征,以估计 BDA 的有效性。
图 7.2 展示了一种可能的 ML 架构。每个特征(例如模式或行为)可由人工编写的算法导出,也可通过 ML 方法(传统方法、深度网络(DeepNet)或混合方法)推断得出。多个分类器利用这些特征计算其局部的威胁模式估计值,再通过集成方法(ensemble method)(见第 3.2 节)选择最优的威胁模式。最后,变化检测(change detection)将当前模式与先前模式进行比较。算法 7.1 给出了对应的代码示例,其中使用 scikit-learn 构建了一个由不同分类器组成的集成模型:决策树(decision tree)、极端随机树(extra tree)、高斯朴素贝叶斯(Gaussian Naïve Bayes),以及两个使用不同 \(k\) 值的 \(k\) 近邻(\(k\)NN)模型。图 7.3 展示了实验结果。evalModel() 中的十折交叉验证(tenfold cross-validation)为每个模型生成 10 个得分,并以箱线图(box-and-whisker plot)形式呈现。
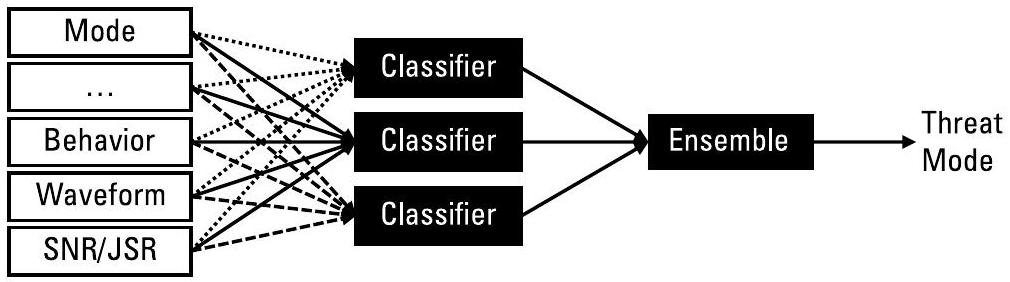
图 7.2 集成方法(Ensemble methods)可通过选择或组合多个假设来提高准确性。特征可以是人工生成的,也可以是通过学习获得的,任何机器学习(ML)方法均可作为中间分类器。
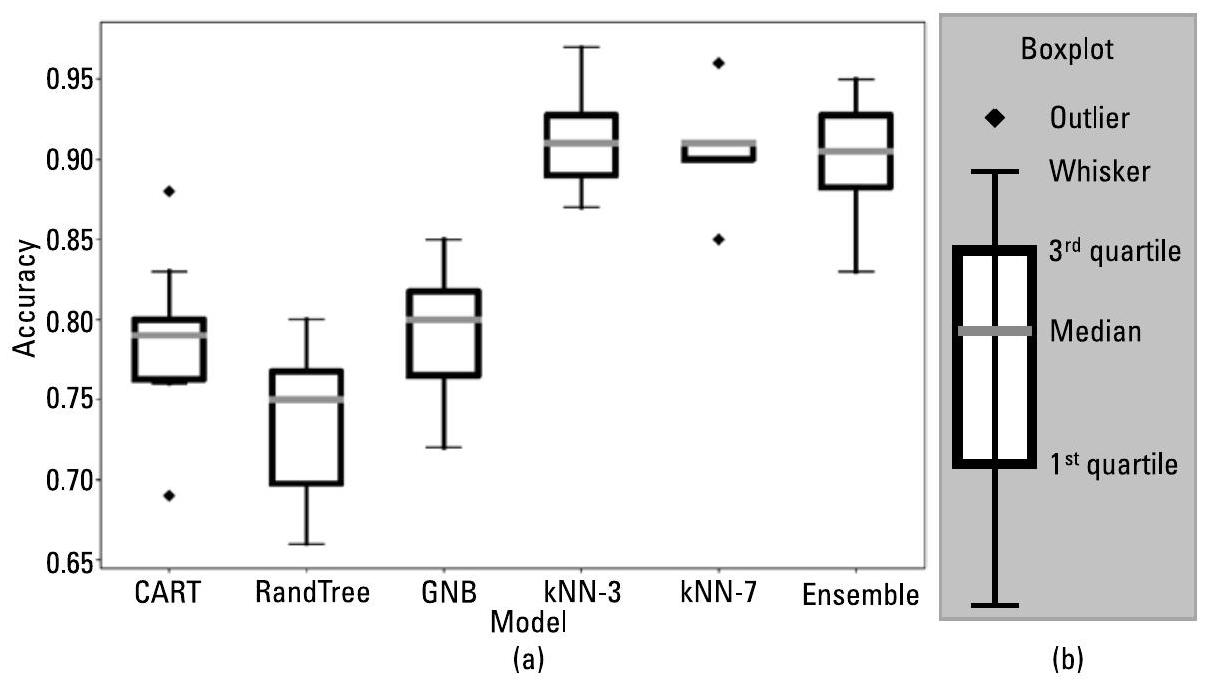
图 7.3 集成方法的准确率可高于独立模型。每个箱线图(boxplot)展示了对应模型的十折交叉验证得分。(a)\(k\) 折交叉验证(\(k\)-fold cross-validation)训练 \(k\) 个模型;每个模型使用数据集中不同的 \(1/k\) 部分作为测试样本。(b)箱线图(box-and-whisker plot)展示数值的分布情况:中央箱体表示数据中间一半的范围(第一四分位数到第三四分位数),须线(whiskers)对应 1.5 倍四分位距(若数据服从正态分布,则覆盖约 99.3% 的数据)。离群值(outliers)以单独点的形式标出。
算法 7.1 集成方法(Ensemble methods)可获得比独立模型更高的准确率。scikit-learn 包含多种分类器和集成方法。
from sklearn.tree import DecisionTreeClassifier
from sklearn.tree import ExtraTreeClassifier
from sklearn.naive_bayes import GaussianNB
from sklearn.neighbors import KNeighborsClassifier as KNN
from sklearn.ensemble import VotingClassifier
import numpy as np
from sklearn.datasets import make_classification
from sklearn.model_selection import cross_val_score
from sklearn.model_selection import KFold
from matplotlib import pyplot
#定义一个模拟数据集
def getData():
X, Y = make_classification(n_samples=1000,
n_features=25, n_informative=15,
n_redundant=5)
return (X, Y)
def getModels():
models = []
models.append(('CART', DecisionTreeClassifier()))
models.append(('RandTree', ExtraTreeClassifier()))
models.append(('GNB', GaussianNB()))
models.append(('kNN-3', KNN(n_neighbors=3)))
models.append(('kNN-7', KNN(n_neighbors=7)))
return models
#10层交叉验证
def evalModel(name, model, X, y):
cv = KFold(n_splits=10)
scores = cross_val_score(model, X, y,
scoring='accuracy',
cv=cv, error_score='raise')
s = '{:10s} mu={:.3f} '.format(
name, np.mean(scores))
s = s + 'std={:.3f} scores={}'.format(
np.std(scores), scores)
print(s)
return scores
if __name__ == '__main__':
names, results = [], []
X, y = getData()
models = getModels()
for name, model in models:
scores = evalModel(name, model, X, y)
results.append(scores)
names.append(name)
ensemble = VotingClassifier(estimators=models)
scores = evalModel('Ensemble', ensemble, X, y)
results.append(scores)
names.append('Ensemble')
# 绘制模型性能图
fig = pyplot.figure()
pyplot.boxplot(results, labels=names)
fig.savefig('ensemble.png')
7.2 任务中重规划(In-Mission Replanning)¶
任何作战计划在与敌方主力首次遭遇之后,都无法有任何确定的可行性。
——赫尔穆特·冯·毛奇(Helmuth von Moltke)
《军事历史单行本》(Kriegsgechichtliche Einzelschriften,1880年)
(常被误引为:“没有任何计划能在与敌人接触后依然有效。”)
任务中重规划(In-mission replanning)确保即使在遭遇意外情况或任务目标发生变化时,计划仍保持可行性。新的优先级可能出现,资源也可能被意外耗尽。某些规划方法,例如条件规划(conditional planning)和马尔可夫决策过程(MDPs, Markov Decision Processes),会为预期结果预先纳入多种应对选项。
规划器还必须始终更新计划,以应对未预料到的结果(包括正面和负面的)。图7.4展示了一种重规划根据实际情况进行调整的可能场景。
规划器可将应对意外情况的灵活性作为决策准则的一部分。此外,规划器还可预先规划通信机制,以应对任务目标的预期变化 [11]。
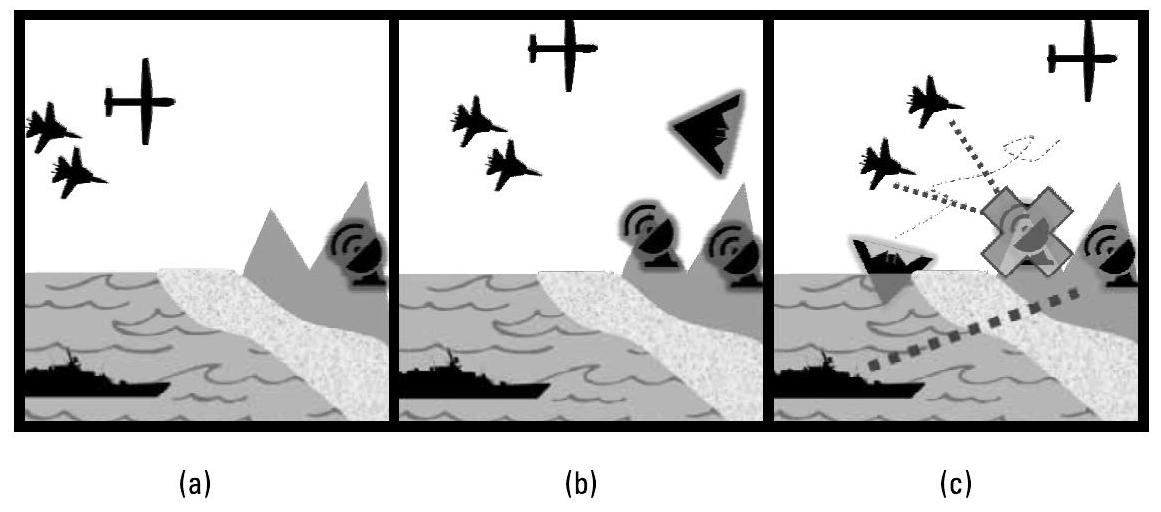
图7.4 任务中重规划必须适应意外情况:(a) 先验电子情报(ELINT, Electronic Intelligence)预计存在一部敌方雷达;(b) 任务中协同电子支援(ES, Electronic Support)探测到两部敌方雷达和一架空中无人机;(c) 任务中重规划随之调整,各节点成功压制敌方目标。
在条件规划(conditional planning)中,规划器会为多种可能结果(通常是任务最关键的几种)预先制定行动方案,而将其他行动留待动态重规划处理,因为这些行动重要性较低、发生概率较小,或在运行时易于应对 [12]。
在所有情况下,执行监控(execution monitoring)都会触发重规划过程。某项行动可能未能达到预期效果,因此必须重复执行或替换(例如,战斗毁伤评估(BDA, Battle Damage Assessment)表明所选的电子攻击(EA, Electronic Attack)方法效果不足,必须采用其他技术)。现有计划可能已无法实现,例如当某个平台失效,需要重新分配任务;或者现有计划可能已不再适用,因为任务目标发生了变化,必须生成一个全新的计划。
工程师通常能够预估故障的类型,即使具体故障难以预见。例如,可以预见到平台损耗(platform attrition),但无法预知哪些平台(以及相应哪些任务)会受到影响。
规划器可选择从当前状态开始进行完整重规划(complete replan),或对现有计划进行修复(repair the existing plan)[13,14]。这一决策可能取决于算法方法、计算时间或对计划稳定性(plan stability)的需求。在时间受限的情况下,任意时间算法(anytime approaches)可用于管理决策制定(DM, Decision Making)(见第5.3节)。计划修复技术通常依赖于所采用的规划方法,例如:
- 规划与执行交织(Interleaving planning and execution)[15, 16];
- 带感知的应急规划器(Contingent planner with sensing)[17, 18];
- 分层任务网络规划(HTN planning, Hierarchical Task Network planning)[19–21];
- 概率规划(Probabilistic planning)[22];
- 任务分配(Task allocation)[23, 24];
- 图规划(Graph planning)[25, 26];
- 类比规划(Analogical planning)[27];
- 计划编辑(Plan editing)[28, 29]。
这些方法的一个共同主题是计划稳定性,即新计划应尽可能与原始计划相似 [26–29]。这种方法可减少计算开销、降低参与者之间的协调复杂度,并更有效地支持人类操作员——人类通常不喜欢在缺乏明确理由的情况下对计划进行大幅更改。
美国空军研究实验室(AFRL)的“分布式作战”(Distribute Operations, DistrO)项目直接针对这一概念,研究计划生成与计划修复 [30]。其组件会评估任务目标的进展,识别与预期结果的偏差,并在反介入/区域拒止(A2/AD, Anti-Access/Area-Denial)环境中为前沿节点推荐计划调整方案。其中一个关键理念是尽量减少对计划的调整,因为各节点可能已做出承诺,且可能无法及时通信以同步变更。此外,在规划过程中纳入计划变更成本(cost of changing the plan)也可能具有实际价值。
7.3 任务中学习(In-Mission Learning)¶
强化学习(RL, Reinforcement Learning),在其最广义的定义下,是一种目标导向的学习方法,个体通过与环境交互,随时间推移不断提升其性能 [31]。(相比之下,监督学习器是被动的,仅接收给定的示例;参见第3章。)在电子战(EW, Electronic Warfare)中,RL 意味着系统可以在环境中执行电子防护(EP, Electronic Protection)或电子攻击(EA, Electronic Attack)动作,收集反馈,并评估自身性能。
现实世界环境通常过于复杂,难以收集覆盖所有预期情况的数据。此外,在电子战中,系统将遭遇任何实验室环境都无法复现的新颖条件。RL 与非线性系统的直接自适应控制(direct adaptive control)[32] 和模型预测控制(MPC, Model-Predictive Control)[33, 34] 相关。关键区别在于:MPC 是基于模型的(model-based),而 RL 则不是。RL 系统没有可微的目标函数,必须在环境中采取实际行动才能学习该函数。RL 使系统能够在最有益、最需要学习的现场(in situ)进行学习。
RL 可以更新动作描述,以准确反映环境中实际发生的情况——例如更新状态转移概率 \(P\left(s^{\prime} \mid s, a\right)\),或将动作前提条件从 \(\left(p_{1}, p_{2}, p_{3}\right)\) 更新为 \(\left(p_{1}, p_{2}, p_{4}\right)\),其中 \(p_{i}\) 属于状态 \(s\)。RL 是唯一能够准确学习第4.2节所引入的性能模型 \(m = f\left(\mathbf{o}_{n}, \mathbf{c}_{n}\right)\) 的方法。
图7.5 展示了一个任务中增量学习(in-mission incremental learning)的简化示例。在时刻 \(t - \delta\),优化器利用先前学习到的模型 \(f\),根据已知可观测量 \(\mathbf{o}\) 估算每个候选策略 \(s\) 的性能 \(m\):\(m = f\left(\mathbf{o}_{n}, \mathbf{c}_{n}\right) = f(\mathbf{o}, s)\)。在选择并执行最优策略 \(s = \operatorname{argmax}_{s_{i}} \tilde{U}_{n}\left(s_{j}\right)\) 后,系统观测该策略 \(s_i\) 的实际性能。学习器将该结果加入数据集,更新模型 \(f\),随后优化器开始使用更新后的函数 \(f\)。在图示中,若 \(\mathbf{o}_{n}(t) \approx \mathbf{o}_{n}(t - \delta)\),则优化器会选择图中所示的最优策略。
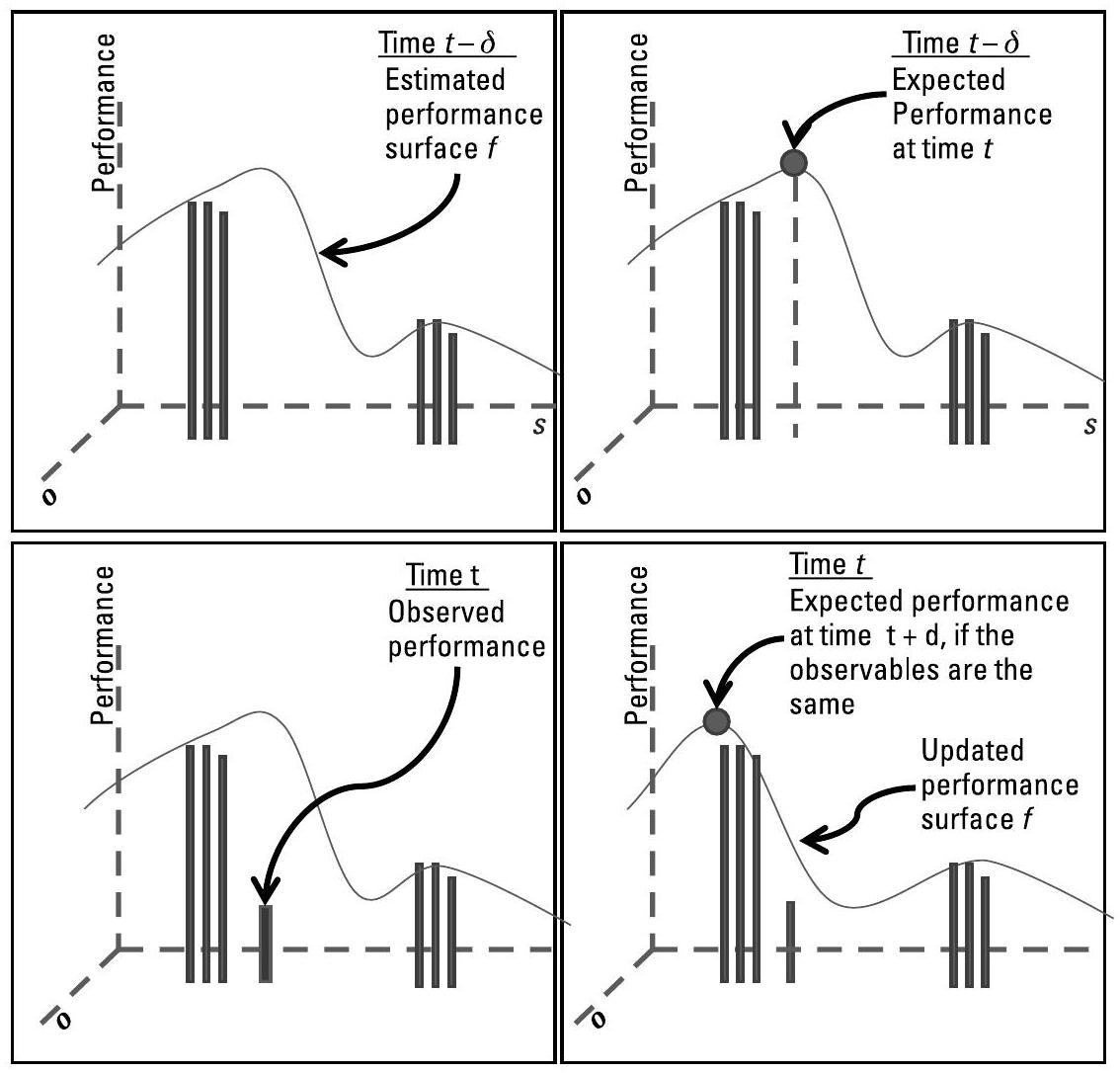
图7.5 在时刻 \(t - \delta\),贝叶斯信念网络(BBN, Bayesian Belief Network)智能体(SO, Smart Operator)(见例7.1,[35])使用模型 \(m_{k} = f_{k}(\mathbf{o}, s)\),基于(已知的)可观测量 \(\mathbf{o}\) 和所有(候选)策略 \(s\) 估算性能指标 \(m_{k}\),并选择最优策略。学习器随后为下一次迭代更新 \(f_{k}\)。为简化图示,x 轴和 y 轴均为多维:x 轴涵盖所有可控变量(controllables)的所有取值,y 轴涵盖所有可观测量(observables)的所有取值。此外需注意,图中仅展示了给定 \(\mathbf{o}_{t-\delta}\) 和 \(\mathbf{o}_{t}\) 下的 \(f_{k}\),但实际 \(f_{k}\) 模型覆盖所有可能的可观测量取值及所有策略对应的性能指标 \(m_{k}\)。
每个强化学习(RL, Reinforcement Learning)系统中的两个关键动作是:(1) 采取何种动作;(2) 何时更新模型。图5.2 展示了一个包含任务中性能指标学习的控制流示例。
大多数 RL 系统在每个时间步都更新模型,但这一选择也可以是有意为之。例如,若计算资源受限或出现新信息,系统可触发批量重训练。本质上,每一次预期或预测的失败都是学习的机会。新信息包括:在已知环境中执行新动作所获得的性能指标反馈、在新环境中执行已知动作的反馈,或在已知环境中对已知动作获得意外反馈。边缘案例(edge cases)、异常传感器读数以及对抗性攻击(adversarial attacks)也属于潜在的学习机会。
在动作选择方面,决策者需明确权衡探索(exploration)与利用(exploitation)。利用指决策者选择期望效用最高的策略;探索则指选择能获取新知识的动作。(效用函数也可直接纳入信息价值(value of information),见第6.1.4节。)该决策需在基于已有知识最大化回报与尝试新动作以扩展知识之间取得平衡。即使在人类决策(DM, Decision Making)中,对失败的容忍度越高,学习速率也越快 [36]。
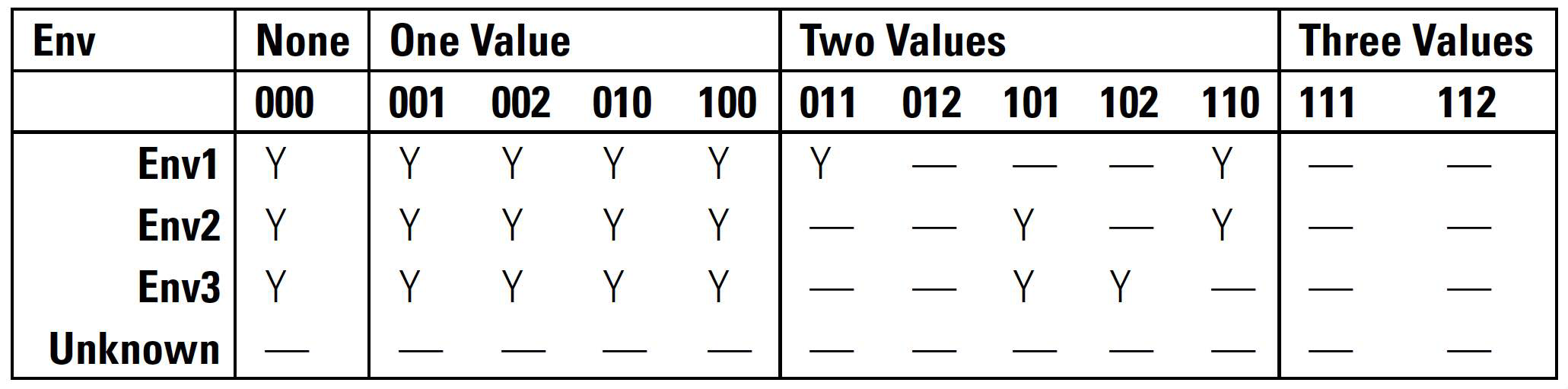
主动学习(Active Learning) 是 RL 中一种有意识选择动作的概念,即优先选择对学习最有价值的动作。例如,为管理偏差(bias)(见第8.2节)并维持数据多样性(data diversity)(见第8.3.2节),决策者可记录其在不同环境中使用过的策略,采用如表7.1所示的稀疏矩阵进行跟踪。决策者利用可观测量向量对环境进行聚类(见第2.1.1节),并在必要时新增环境类别。在表7.1中,可控变量 \(c_{1}\) 和 \(c_{2}\) 为二元开关(on/off),\(c_{3}\) 可取值 0、1、2,共构成12种策略。“Y”表示系统在该环境中对该策略已有性能结果,“—”表示尚无。
表7.1 决策者用于跟踪在射频(RF, Radio Frequency)环境中所用策略的稀疏矩阵示例
当前 RL 领域的大量研究均基于马尔可夫决策过程(MDP, Markov Decision Process),以至于 RL 几乎被视为 MDP 的同义词。但事实并非如此:MDP 可能是、也可能不是 RL 所采用的底层模型。
RL 并非由其学习方法定义,而是由其所解决的学习问题以及与环境的直接交互所定义 [31]。
事实上,由于计算复杂度高且所需训练样本数量庞大,基于 MDP 的 RL 通常不适用于任务中的电子战(EW)场景。第3.6节讨论了在选择模型及确定任务中应学习内容时需考虑的一些算法权衡。
7.3.1 认知架构(Cognitive Architectures)¶
许多认知架构(cognitive architectures)通过学习某种形式的规则来辅助决策。其中不少已在物理领域得到应用,例如机器人足球和战斗机飞行员模拟 [37–41]。第5.1.3节介绍了其他用于提升规划性能的学习方法。强化学习(RL)形式化了探索-利用(explore-exploit)权衡;而认知架构文献中则使用类似的概念,如感知注意(perceptual attention)和动作选择(action selection)。
7.3.2 神经网络(Neural Networks)¶
在时间充裕的情况下,人工神经网络(ANNs, Artificial Neural Networks)(见第3.1.2节)能够在强化学习环境中有效学习射频(RF, Radio Frequency)领域的多种任务 [42]。第4章中的许多示例均基于人工神经网络;强化学习框架利用真实环境反馈对这些模型进行训练。具体应用包括:学习性能建模 [43, 44]、在频谱共享雷达中避免冲突 [45]、在认知无线电网络(CRNs, Cognitive Radio Networks)中进行干扰控制 [46]、信号识别 [47, 48]、任务选择 [49],以及攻击类型检测与分类 [50]。文献[50]提出了一些应对相关挑战的技术,包括计算效率和非对称数据(类别不平衡,class imbalance)等问题。然而,由于人工神经网络需要大量数据和计算资源,且无法从单一样本中学习,因此尚未被纳入快速实时电子战(EW)相关文献中。小样本学习(Low-shot learning)(见第3.4节)是解决这一挑战的一个有前景的研究方向。
7.3.3 支持向量机(Support Vector Machines, SVMs)¶
支持向量机(SVMs, Support Vector Machines)(见第3.1.1节)是电子战(EW)中强化学习(RL)的一种特别有效的方法。SVM 能够从少量训练样本(甚至仅一个样本)中学习,且无需强大的计算能力。贝叶斯信念网络智能体(BBN SO, Bayesian Belief Network Smart Operator)利用 SVM 实现通信电子防护(EP, Electronic Protection)中的实时任务中学习 [35],并基于预测误差触发模型重训练(见例7.1)。
将深度神经网络(DeepNets)与 SVM 相结合是一个富有前景的研究方向 [59–61]。DeepNet 模型可在任务前利用大规模数据集进行预训练,以提取射频(RF, Radio Frequency)信号的潜在特征(latent features)。随后,可将 DeepNet 的输出层替换为一个 SVM,该 SVM 可在任务执行期间、在射频任务相关的时间尺度上进行更新,从而学习对新型辐射源(novel emitters)进行分类。图7.6 展示了这一概念。SVM 能从极少量数据中快速学习,且模型更新可在现场可编程门阵列(FPGAs)或通用处理器(CPUs)上以亚毫秒级(sub-millisecond)时间完成。
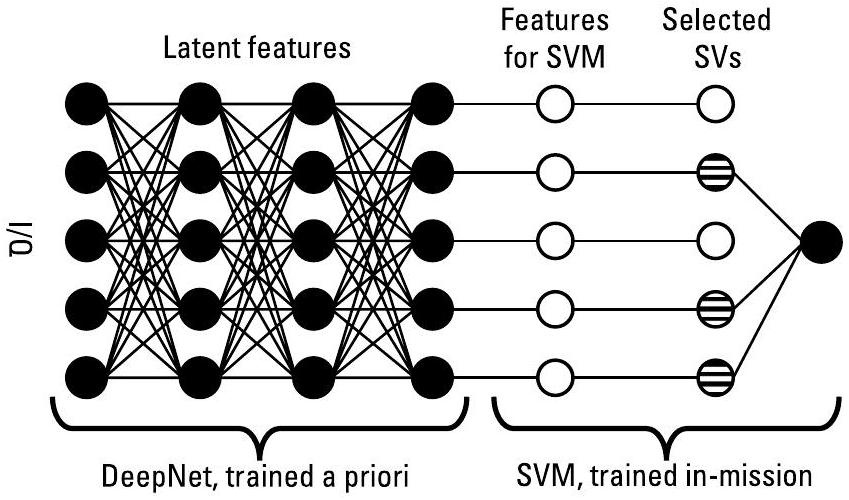
图7.6 任务前,DeepNet 从大量典型环境数据中学习以提取潜在特征;任务中,系统使用已训练的 DeepNet 进行推理,并利用这些特征训练(并更新)一个 SVM 模型。
7.3.4 多臂老虎机(Multiarmed Bandit, MAB)¶
多臂老虎机(MAB, Multiarmed Bandit)是一种经典的强化学习(RL)方法,其中奖励服从概率分布而非固定值 [31, 62, 63]。每个动作(策略 \(s\))对应一个“臂”(arm),具有奖励分布 \(R_s\) 及其对应的均值 \(\mu_s\)。MAB 建模的是一种环境静态、且需重复做出相同决策的情境。多臂老虎机可视为仅包含一个状态、但具有多个可用动作的马尔可夫决策过程(MDP);反之,MDP 也可看作是一组 MAB 问题的集合,因为其状态会随时间变化。MAB 的收敛速度通常快于 MDP。
MAB 的一种有用变体是上下文多臂老虎机(Contextual MAB),它为每个动作引入上下文信息,从而学习与上下文相关的奖励分布[即对于性能模型 \(m = f(\mathbf{o}, s)\),在可观测量 \(\mathbf{o}\) 下采用策略 \(s\) 所得 \(m\) 值的概率分布]。MAB 已被应用于信道选择 [64–66]、抗干扰(anti-jamming)[67] 和干扰(jamming)[68, 69] 等场景。
Takeuchi 等人 [70] 提出了一种简化的 MAB 信道选择算法,该算法能快速遗忘历史参数,从而降低计算开销。目前已存在多种任意时间(anytime)MAB 算法 [71–73],其设计思想与“多少信息才足够”这一问题密切相关 [74]。元学习(Metalearning)也可用于选择最优的 MAB 启发式策略 [75],而 MAB 本身亦可作为元学习器,用于选择高效算法 [76, 77]。
7.3.5 马尔可夫决策过程(Markov Decision Processes, MDPs)¶
MDP 是表示不确定性最常用的方法(见第6.1.3节)。Q学习(Q-learning)是一种无模型(model-free)的 RL 方法,用于学习动作的“质量”(即 Q 值);在无限探索时间的前提下,它能为任意有限 MDP 找到最优策略 [78]。在 RL 框架内,MDP 已被用于雷达中的频谱共享管理 [45]、干扰预测 [79]、抗干扰 [80] 以及用户行为建模 [81]。相关补充研究包括:构建效用函数以理解奖励函数需维持的精细程度 [82],以及在满足约束条件下优化效用函数 [83, 84]。
然而,总体而言,Q学习及其他基于 MDP 的方法并不适用于电子战(EW),因为它们样本效率极低,且计算复杂度很高 [45, 85]。
贝叶斯强化学习(Bayesian RL) [86, 87] 通过对关键概念(如模型参数、策略或奖励函数)维护一个概率分布,来刻画不确定性。贝叶斯后验分布自然地完整表达了当前知识状态(受限于所选的参数化表示),从而使智能体能够选择在该信息状态下期望收益最大的动作。
7.3.6 深度Q学习¶
深度Q网络(DQN)利用深度神经网络(DeepNet)来估计马尔可夫决策过程(MDP)每个状态下所有可能动作的Q值[88],从而减轻了传统Q学习的计算负担(以及所需样本数量)。《动手学深度强化学习》(Deep RL Hands-on)一书[89]提供了Python示例。DQN已被应用于多种射频(RF)任务,包括信号分类[47]、共存[90, 91]、干扰[92]以及抗干扰[93–99]。深度主动学习方法利用信息不确定性、多样性以及预期模型变化来选择实验[100]。然而,DQN在电子战(EW)领域尚未针对样本效率进行评估,而在该领域中,(1)可能需要仅凭单一样本进行学习,且(2)必须满足严格的实时电子战要求。
7.4 结论¶
没有任何计划能在与敌方接触后依然有效,也没有任何模型能够精确捕捉环境的每一个细节。电子战(EW)系统必须能够应对任务中出现的意外事件,并从自身经验中学习。本章讨论了实现实时任务内规划与学习的方法,特别聚焦于执行监控、任务内重规划以及任务内(机器)学习等概念。意外的观测结果、推理结论和环境变化必须通过人机界面(HMI,见第6.3节)及时传达给操作人员。
与真实环境的交互要求对规划过程进行持续监督,而正是重规划使任务得以保持正轨。此外,与真实环境的交互使机器学习(ML)能够改进经验模型;任务内学习基于真实经验提升系统性能。最后,执行监控形成了闭环,因为它将(1)行动与观测结果关联起来,(2)决策模块(DM)与态势感知(SA)关联起来,以及(3)电子攻击规划/电子攻击/电子战行为模型(EP/EA/EBM)与电子支援(ES)关联起来。
References¶
[1] Lee, G.-H., J. Jo, and C. H. Park, "Jamming Prediction For Radar Signals Using Machine Learning Methods," Security and Communication Networks, 2020.
[2] Melvin, W., and J. Scheer, Principles of Modern Radar: Radar Applications, Scitech, 2013.
[3] Aslan, M., "Emitter Identification Techniques in Electronic Warfare," M.S. thesis, Middle East Technical University, 2006.
[4] Morgan, T., How Do the Different Radar Modes of a Modern Fighter Aircraft Work? Accessed 2021-02-02, 2016. Online: https://tinyurl.com/radarmodes.
[5] Avionics Department, "Electronic Warfare and Radar Systems Engineering Handbook," Naval Air Warfare Center Weapons Division, Tech. Rep. NAWCWD TP 8347, 2013.
[6] Chairman of the Joint Chiefs of Staff, Joint publication 3-09: Joint fire support, 2019. Online: https://fas.org/irp/doddir/dod/jp313-1.pdf.
[7] Zhou, D., et al., "Battle Damage Assessment with Change Detection of SAR Images," in Chinese Control Conference, 2015.
[8] Basseville, M., and I. Nikiforov, Detection of Abrupt Changes: Theory and Application, Prentice-Hall, 1993.
[9] Choi, S., et al., "A Case Study: BDA Model For Standalone Radar System (Work-In-Progress)," International Conference on Software Security and Assurance, 2018.
[10] DoD Army, Electronic Warfare Battle Damage Assessment. Accessed 2021-02-02, 2014. Online: https://www.sbir.gov/sbirsearch/detail/872931.
[11] Yordanova, V., "Intelligent Adaptive Underwater Sensor Networks," Ph.D. dissertation, University College London, London, UK, 2018.
[12] Benaskeur, A., E. Bossé, and D. Blodgett, "Combat Resource Allocation Planning In Naval Engagements," Defence R&D Canada, Tech. Rep. DRDC Valcartier TR 2005-486, 2007.
[13] Garrido, A., C. Guzman, and E. Onaindia, "Anytime Plan-Adaptation for Continuous Planning," in UK Planning and Scheduling Special Interest Group, 2010.
[14] Cushing, W., and S. Kambhampati, "Replanning: A New Perspective," in ICAPS, 2005.
[15] Haigh, K. Z., and M. Veloso, "Planning, Execution and Learning in a Robotic Agent," in AIPS, Summary of Haigh's Ph.D. thesis, 1998.
[16] Nourbakhsh, I., "Interleaving Planning and Execution," in Interleaving Planning and Execution for Autonomous Robots, Vol. 385, 1997.
[17] Komarnitsky, R., and G. Shani, "Computing Contingent Plans Using Online Replanning," in AAAI, 2016.
[18] Brafman, R., and G. Shani, "Replanning in Domains with Partial Information and Sensing Actions," in Journal of Artificial Intelligence Research, Vol. 45, 2012.
[19] Ayan, F., et al., "HOTRiDE: Hierarchical Ordered Task Replanning in Dynamic Environments," in Planning and Plan Execution for Real-World Systems, 2007.
[20] Lesire, C., et al., "A Distributed Architecture for Supervision of Autonomous Multirobot Missions," Autonomous Robots, Vol. 40, 2016.
[21] Höller, D., et al., "HTN Plan Repair Via Model Transformation," in Künstliche Intelligenz, 2020.
[22] Chen, C., et al., "RPRS: a Reactive Plan Repair Strategy for Rapid Response to Plan Failures of Deep Space Missions," Acta Astronautica, Vol. 175, 2020.
[23] Beal, J., et al., "Adaptive Task Reallocation for Airborne Sensor Sharing," in Foundations and Applications of Self* Systems, 2016.
[24] Buckman, N., H.-L. Choi, and J. How, "Partial Replanning for Decentralized Dynamic Task Allocation," in Guidance, Navigation, and Control, 2019.
[25] Gerevini, A., A. Saetti, and I. Serina, "Planning Through Stochastic Local Search And Temporal Action Graphs," AI Research, Vol. 20, 2003.
[26] Fox, M., et al., "Plan Stability: Replanning Versus Plan Repair," in ICAPS, 2006.
[27] Veloso, M., Planning and Learning by Analogical Reasoning, Springer Verlag, 1994.
[28] van der Krogt, R., and M. de Weerdt, "Plan Repair as an Extension of Planning," in ICAPS, 2005.
[29] Bidot, J., B. Schattenberg, and S. Biundo, "Plan Repair in hybrid planning," in Künstliche Intelligenz, 2008.
[30] Marsh, G., "Distributed Operations," Air Force Research Labs, Tech. Rep. BAA-AFRL-RIK-2016-0003, 2015.
[31] Sutton, R., and A. Barto, Reinforcement Learning: An Introduction, Bradford, 2018.
[32] R. Sutton, A. Barto, and R. Williams, "Reinforcement Learning Is Direct Adaptive Optimal Control," IEEE Control Systems Magazine, Vol. 12, No. 2, 1992.
[33] Ernst, D., et al., "Reinforcement Learning Versus Model Predictive Control: A Comparison on a Power System Problem," IEEE Transactions on Systems, Man, and Cybernetics, Vol. 39, No. 2, 2009.
[34] Görges, D., "Relations Between Model Predictive Control and Reinforcement Learning," IFAC-PapersOnLine, Vol. 50, No. 1, 2017, IFAC World Congress.
[35] Haigh, K. Z., et al., "Parallel Learning and Decision Making for a Smart Embedded Communications Platform," BBN Technologies, Tech. Rep. BBN-REPORT-8579, 2015.
[36] Rzhetsky, A., et al., "Choosing Experiments to Accelerate Collective Discovery," National Academy of Sciences, 2015.
[37] Jiménez, S., et al., "A Review of Machine Learning For Automated Planning," The Knowledge Engineering Review, Vol. 27, 2012.
[38] Kotseruba, I., and J. Tsotsos, "A Review of 40 years of Cognitive Architecture Research: Focus on Perception, Attention, Learning and Applications," CoRR, 2016.
[39] Nason, S., and J. Laird, "Soar-RL: Integrating Reinforcement Learning with SOAR," Cognitive Systems Research, Vol. 6, 2005.
[40] T. de la Rosa and S. McIlraith, "Learning Domain Control Knowledge for TLPlan and Beyond," in ICAPS Workshop on Planning and Learning, 2011.
[41] Minton, S., et al., "Acquiring Effective Search Control Rules: Explanation-Based Learning in the Prodigy System," in International Workshop on Machine Learning, 1987.
[42] Yau, K.-L., et al., "Application of Reinforcement Learning in Cognitive Radio Networks: Models and Algorithms," The Scientific World Journal, 2014.
[43] Troxel, G., et al., "Cognitive Adaptation for Teams in ADROIT," in GLOBECOM, Invited, IEEE, 2007.
[44] Tsagkaris, K., A. Katidiotis, and P. Demestichas, "Neural Network-Based Learning Schemes for Cognitive Radio Systems," Computer Communications, No. 14, 2008.
[45] Thornton, C., et al., Experimental Analysis of Reinforcement Learning Techniques for Spectrum Sharing Radar, 2020. Online: https://arxiv.org/abs/2001.01799.
[46] Galindo-Serrano, A., and L. Giupponi, "Distributed Q-Learning for Aggregated Interference Control in Cognitive Radio Networks," Transactions on Vehicular Technology, Vol. 59, No. 4, 2010.
[47] Kulin, M., et al., "End-to-End Learning from Spectrum Data," IEEE Access, Vol. 6, 2018.
[48] Qu, Z., et al., "Radar Signal Intrapulse Modulation Recognition Based on Convolutional Neural Network and Deep Q-Learning Network," IEEE Access, Vol. 8, 2020.
[49] Li, M., Y. Xu, and J. Hu, "A Q-Learning Based Sensing Task Selection Scheme for Cognitive Radio Networks," in International Conference on Wireless Communications & Signal Processing, 2009.
[50] Qu, X., et al., "A Survey on the Development of Self-Organizing Maps for Unsupervised Intrusion Detection," Mobile Networks and Applications, 2019.
[51] Haigh, K. Z., et al., "Machine Learning for Embedded Systems: A Case Study," BBN Technologies, Tech. Rep. BBN-REPORT-8571, 2015.
[52] Haigh, K. Z., et al., "Optimizing Mitigation Strategies: Learning to Choose Communication Strategies to Mitigate Interference," in Classified US Military Communications, 2013.
[53] Haigh, K. Z., S. Varadarajan, and C. Y. Tang, "Automatic Learning-Based MANET Cross-Layer Parameter Configuration," in Workshop on Wireless Ad hoc and Sensor Networks, IEEE, 2006.
[54] Haigh, K. Z., O. Olofinboba, and C. Y. Tang, "Designing an Implementable User-Oriented Objective Function for MANETs," in International Conference On Networking, Sensing and Control, IEEE, 2007.
[55] Haigh, K. Z., et al., "Rethinking Networking Architectures for Cognitive Control," in Microsoft Research Cognitive Wireless Networking Summit, 2008.
[56] Haigh, K. Z., "AI Technologies for Tactical Edge Networks," in MobiHoc Workshop on Tactical Mobile Ad Hoc Networking, Keynote, 2011.
[57] Haigh, K. Z., et al., "Modeling RF Interference Performance," in Collaborative Electronic Warfare Symposium, 2014.
[58] Haigh, K. Z., "Learning to Optimize a Network Overlay Router," in Learning Methods for Control of Communications Networks, 2017.
[59] Ma, M., et al., "Ship Classification and Detection Based on CNN Using GF-3 SAR Images," Remote Sensing, Vol. 10, 2018.
[60] Wagner, S., "SAR ATR by a Combination of Convolutional Neural Network and Support Vector Machines," IEEE Transactions on Aerospace and Electronic Systems, Vol. 52, No. 6, 2016.
[61] Gao, F., et al., "Combining Deep Convolutional Neural Network and SVM to SAR Image Target Recognition," in International Conference on Internet of Things, IEEE, 2017.
[62] Lattimore, T., and C. Szepesvari, Bandit Algorithms, Cambridge University Press, 2019.
[63] Slívkins, A., Introduction to Multi-Armed Bandits, 1-2. 2019, Vol. 12.
[64] Jouini, W., C. Moy, and J. Palicot, "On Decision Making for Dynamic Configuration Adaptation Problem in Cognitive Radio Equipments: A Multiarmed Bandit Based Approach," Karlsruhe Workshop on Software Radios, 2010.
[65] Liu. K., and Q. Zhao, "Channel Probing for Opportunistic Access with Multichannel Sensing," Conference on Signals, Systems and Computers, 2008.
[66] Lu, J., et al., "Dynamic Multi-arm Bandit Game Based Multiagents Spectrum Sharing Strategy Design," in Digital Avionics Systems Conference, 2017.
[67] Li, H., J. Luo, and C. Liu, "Selfish Bandit-Based Cognitive Antijamming Strategy for Aeronautic Swarm Network in Presence of Multiple Jammer," IEEE Access, 2019.
[68] Amuru, S., et al., "Jamming Bandits: A Novel Learning Method for Optimal Jamming," IEEE Transactions on Wireless Communications, Vol. 15, No. 4, 2016.
[69] ZhuanSun, S., J. Yang, and H. Liu, "An Algorithm for Jamming Strategy Using OMP and MAB," EURASIP Journal on Wireless Communications and Networking, 2019.
[70] Takeuchi, S., et al., "Dynamic Channel Selection in Wireless Communications via a Multiarmed Bandit Algorithm Using Laser Chaos Time Series," Scientific Reports, Vol. 10,
[71] Jun, K.-S., and R. Nowak, "Anytime Exploration For Multiarmed Bandits Using Confidence Information," in ICML, 2016.
[72] Kleinberg, R. D., "Anytime Algorithms for Multiarmed Bandit Problems," in Symposium on Discrete Algorithms, 2006.
[73] Besson, L., and E. Kaufmann, What Doubling Tricks Can and Can't Do for Multiarmed Bandits, 2018. Online: https://tinyurl.com/doubling-mab.
[74] Even-Dar, E., S. Mannor, and Y. Mansour, "Action Elimination and Stopping Conditions for the Multiarmed Bandit and Reinforcement Learning Problems," Machine Learning Research, 2006.
[75] Besson, L., E. Kaufmann, and C. Moy, "Aggregation of Multiarmed Bandits Learning Algorithms for Opportunistic Spectrum Access," in Wireless Communications and Networking Conference, 2018.
[76] Gagliolo, M., and J. Schmidhuber, "Learning Dynamic Algorithm Portfolios," Annals of Mathematics and Artificial Intelligence, Vol. 47, 2006.
[77] Svegliato, J., K. H. Wray, and S. Zilberstein, "Meta-level Control of Anytime Algorithms with Online Performance Prediction," in IJCAI, 2018.
[78] Melo, F., Convergence of Q-Learning: A Simple Proof, 2007. Online: https://tinyurl.com/qlearn-proof.
[79] Selvi, E., et al., "On the Use of Markov Decision Processes in Cognitive Radar: An Application to Target Tracking," in Radar Conference, IEEE, 2018.
[80] Wu, Q., et al., "Reinforcement Learning-Based Antijamming in Networked UAV Radar Systems," Applied Science, Vol. 9, No. 23,
[81] Alizadeh, P., "Elicitation and Planning in Markov Decision Processes with Unknown Rewards," Ph.D. dissertation, Sorbonne, Paris, 2016.
[82] Regan, K., and C. Boutilier, "Regret-Based Reward Elicitation for Markov Decision Processes," in Uncertainty in AI, 2009.
[83] Efroni, Y., S. Mannor, and M. Pirotta, Exploration-Exploitation in Constrained MDPs, 2020. Online: https://arxiv.org/abs/2003.02189.
[84] Taleghan, M., and T. Dietterich, "Efficient Exploration for Constrained MDPs," in \(A A A I\) Spring Symposium, 2018.
[85] Tarbouriech, J., and A. Lazaric, "Active Exploration in Markov Decision Processes," in Artificial Intelligence and Statistics, 2019.
[86] Vlassis, N., et al., "Bayesian Reinforcement Learning," in Reinforcement Learning. Adaptation, Learning, and Optimization, Vol. 12, Springer, 2012.
[87] Ghavamzadeh, M., et al., "Bayesian Reinforcement Learning: A Survey," Foundations and Trendsfin Machine Learning, Vol. 8, No. 5-6, 2015.
[88] Mnih, V., et al., "Human-Level Control Through Deep Reinforcement Learning," Nature, Vol. 518, 2015.
[89] Lapan, M., Deep Reinforcement Learning Hands-On, Packt, 2018.
[90] Maglogiannis, V., et al., "A Q-Learning Scheme for Fair Coexistence Between LTE and Wi-Fi in Unlicensed Spectrum," IEEE Access, Vol. 6, 2018.
[91] Kozy, M., "Creation of a Cognitive Radar with Machine Learning: Simulation and Implementation," M.S. thesis, Virginia Polytechnic Institute, 2019.
[92] Zhang, B., And W. Zhu, "DQN Based Decision-Making Method of Cognitive Jamming Against Multifunctional Radar," Systems Engineering and Electronics, Vol. 42, No. 4, 2020.
[93] Kang, L., et al., "Reinforcement Learning Based Antijamming Frequency Hopping Strategies Design for Cognitive Radar," in Signal Processing, Communications and Computing, 2018.
[94] Bi, Y., Y. Wu, and C. Hua, "Deep Reinforcement Learning Based Multiuser Antijamming Strategy," in ICC, 2019.
[95] Ak, S., and S. Brüggenwirth, Avoiding Jammers: A Reinforcement Learning Approach, 2019. Online: https://arxiv.org/abs/1911.08874.
[96] Huynh, N., et al., "'Jam Me If You Can': Defeating Jammer with Deep Dueling Neural Network Architecture and Ambient Backscattering Augmented Communications," IEEE Journal on Selected Areas in Communications, 2019.
[97] Abuzainab, N., et al., "QoS and Jamming-Aware Wireless Networking Using Deep Reinforcement Learning," in MILCOM, 2019.
[98] Erpek, T., Y. Sagduyu, and Y. Shi, "Deep Learning for Launching and Mitigating Wireless Jamming Attacks," IEEE Transactions on Cognitive Communications and Networking, Vol. 45, No. 1, 2018.
[99] Li, Y., et al., "On the Performance of Deep Reinforcement Learning-Based Anti-Jamming Method Confronting Intelligent Jammer," Applied Sciences, Vol. 9, 2019.
[100] Ren, P., et al., A Survey Of Deep Active Learning, 2020. Online: https://arxiv.org/abs/2009.00236.