8 数据管理¶
数据收集与管理或许是构建基于人工智能(Artificial Intelligence, AI)和机器学习(Machine Learning, ML)系统中最困难的部分。对于所有采用机器学习的系统而言,有一条经验法则:尽管数据收集与数据整理(curating the data)仅是数据生命周期(data lifecycle)中的两个步骤(见图8.1),但却占据了约80%的工作量。第4章讨论了从数据中生成推断(deductions)和推理(inferences)的相关步骤;本章则阐述如何从源头创建高质量数据,以及如何随时间推移持续维护数据质量。
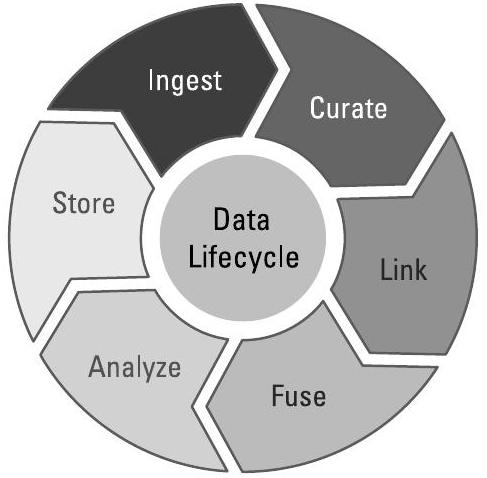
图8.1 数据生命周期包括数据的收集与处理;通过迭代可提升数据在多种用途中的效用。
电子战(Electronic Warfare, EW)中最大的挑战之一便是数据质量:数据可能因整理不当而存在问题,也可能因旧有系统(legacy system)未予记录而“丢失”,甚至被蓄意销毁。数据常常要么不可获取,要么缺少正确的元数据(metadata)标注,要么缺乏可信度。在创建(或使用)一个数据集之前,请考虑以下问题:
- 问题是什么? 需要为哪项决策提供依据?任务目标是什么:理解、预测、控制,还是持续自适应?若明确了问题,便可更有针对性地选择所需数据。现有哪些数据?是否充足?是否具有多样性?若不足,能否进一步收集?数据采用何种格式?构建模型的过程本身可能有助于识别数据缺失之处。
- 数据是如何整理的? 数据本身是否存在固有偏差(inherently biased)?是否曾被对手(adversary)篡改?若清楚数据来源,便能明确其适用的场景与方式。
系统需求文档很少涵盖数据需求,例如应记录哪些数据、如何对其进行标记,或数据必须具备哪些属性(例如多样性)。
本章既介绍了数据管理流程(如何收集与整理电子战数据),也阐述了相关实践(如何在系统内部使用这些数据以达成预期效果)。欧洲安全局(European Safety Agency)从安全关键系统(safety-critical systems)的角度提出了许多类似的观点[1]。
8.1 数据管理流程(Data Management Process)¶
数据“供应链”(data supply chain)是决定人工智能/机器学习(AI/ML)系统质量的关键驱动因素。该供应链涵盖数据的来源(provenance)与可信度(credibility)、完整性(completeness)以及可访问性(accessibility)。如果数据(或其元数据)质量低下,机器学习模型将得出错误的推理结果,更重要的是,它无法意识到自身的缺陷。Callout 8.1概述了在开展实验和收集数据时应采取的关键行动。
元数据(metadata)用于记录数据的上下文;语义(semantics)用于确立数据中概念的含义;可追溯性(traceability)则为数据完整性(data integrity)提供结构支撑。这些概念共同确保了推理与数据管理(Data Management, DM)的准确性、实验的可复现性(experiment reproducibility),以及跨平台和跨时间的数据共享能力。此外,当数据需在不同安全等级或安全保证等级(security- or safety-assurance levels)之间流转时,这些概念也是关键要求:它们有助于判断是否适合对数据进行处理、是否应向用户授予访问权限,或系统是否满足认证(accreditation)要求。表8.1总结了美国国防部(DoD)将数据视为资产进行管理的观点。其目标支撑了数据访问、可用性与治理(stewardship)的宗旨,而元数据、语义和可追溯性构成了贯穿其中的共同主题。
Callout 8.1 在开展实验时,应建立清晰的语义(semantics)并对所有内容进行充分标注。
- 对所有数据添加元数据(metadata)标注,详细说明其采集方式,包括采集地点、实验类型和参与人员。
- 确保合成数据(synthetic data)与真实数据(real data)具有相同的结构。
- 对所有内容实施版本控制(version-control):包括软件、硬件、任务数据(mission data)和场景配置(scenario configurations)。
建立清晰的语义,以支持跨任务(across missions)、跨平台(across platforms)及跨时间(over time)的互操作性(interoperability)。
- 明确所有假设,包括显式假设和(若可能)隐式假设。若数据为合成数据,需注明所有简化假设(simplifying assumptions)。
- 识别异常情况,例如罕见的“边缘”案例(rare "edge" cases)或专门构造用于利用系统弱点的对抗样本(adversarial examples)。
表 8.1 美国国防部(DoD)将数据作为战略资产进行管理的数据战略关键目标
| 目标(Goal) | 实现可衡量进展所需的能力(Required Capabilities for Measurable Progress) |
|---|---|
| 可见(Visible) | 数据应被公开宣传;可获取;采用元数据标准;已编目;提供通用服务以发布、搜索和发现数据;政府基于实时可视化(live visualizations)做出决策 |
| 可访问(Accessible) | 提供标准API;通用平台用于创建和使用数据;数据访问受到保护 |
| 可理解(Understandable) | 保留语义(semantics);采用通用语法(common syntax);各要素对齐;已编目 |
| 可关联(Linked) | 可发现且可关联;采用元数据标准 |
| 可信(Trustworthy) | 具备保护机制;具备数据血缘(lineage);具备来源谱系元数据(pedigree metadata);保障数据质量 |
| 互操作(Interoperable) | 具备交换规范(exchange specifications);包含元数据与语义;机器可读(machine-readable);跨格式转换不损失保真度(fidelity);具备数据标记(data tagging) |
| 安全(Secure) | 具备细粒度权限(granular privileges);采用经批准的标准;有清晰标识;仅授权用户可访问 |
上表摘编自:[2]。
从工程角度看,各模块必须提供可被其他模块直接使用的信息,包括数据融合(data fusion)、数据管理(DM)和用户界面(user interface)。图8.2突出了支撑互操作性与协同流程的关键概念。

图 8.2 为支持互操作性,态势评估(situation assessment)与数据管理(DM)模块应产出具有可操作性(actionable)、可叠加性(additive)、可审计性(auditable)和格式无关性(agnostic)的实用结果。(该概念最初为概率管理(probability management)提出[3]。)
8.1.1 元数据(Metadata)¶
元数据(Metadata)记录了关于实验(及数据集)的所有信息,而这些信息本身并不属于数据集的固有内容。它构成了数据创建时“谁、什么、何处、为何、何时”(who, what, where, why, and when)的地面实况(ground truth)上下文。高质量的元数据是认知电子战(cognitive EW)系统的关键基础,可支持多种任务,例如:
- 准确的根因分析或地面实况分析(Accurate root-cause or ground-truth analysis):评估认知电子战系统需要确切了解实际发生了什么(例如,判断一次数据包碰撞是有意为之还是偶然发生)。同样,在特定辐射源识别(Specific Emitter Identification, SEI)任务中,记录发射机到接收机的距离,可帮助实验人员判断模型是否利用了发射机的潜在特征(latent features),而非仅依赖接收功率(作为距离的代理变量)。
- 实验可复现性(Experiment reproducibility):评估系统准确性要求能够重新运行实验、微调实验条件,或对不同机器学习模型进行相互比较。例如,系统可评估按频率分离信号与按循环平稳性(cyclostationary)处理信号的相对效益。
- 元分析(Meta-analysis):评估数据质量涉及对数据集中的模式(如分布、完整性、系统性偏差)进行分析。构建融合多个(先前独立)数据集特征的复杂场景,需要理解这些数据集在何处以及如何相互作用。元分析也有助于评估数据完整性(data integrity):确保传入或存储的数据真实且完整。
- 面向未来的能力(Future-proofing):减少“比特腐烂”(bitrot)需要完整记录实验细节,以确保即使设备或软件发生变化,数据仍具可用性。
- 互操作性(Interoperability):跨平台或工具复用信息,要求对所有采集、导出或推断出的知识进行适当标记。
- 任务复用(Task reuse):了解数据采集的目的,可帮助开发者判断该数据集是否可用于其他用途。例如,为波形分类(waveform classification)目的采集的数据集,不太可能适用于SEI任务或判断节点是否遭受干扰(jamming);但反之未必成立:特定辐射源数据很可能对波形分类有用。同样,明确SEI任务中哪台接收机记录了哪些数据,有助于开发与接收机无关(receiver-independent)的模型。
- 数据共享(Data sharing):出于研究与作战目的与其他组织共享数据,可支持协同任务并促进合作研究。元数据有助于决定是否以及如何授予对敏感数据的访问权限。
- 供应链评估(Supply-chain evaluation):了解数据的来源(provenance)与可信度(credibility),可使电子支援(Electronic Support, ES)做出正确推理,使电子防护/电子攻击/电子战作战管理(EP/EA/EBM)做出正确决策,也使系统设计者判断是否应使用该数据。在供应链的任何环节——包括硬件、软件、传输过程或存储阶段——都可能发生数据篡改(manipulation)。
开发认知电子战(cognitive EW)系统的一大障碍在于数据采集质量差、标注不足和/或具有专有性(proprietary)。良好的元数据(metadata)有助于消除这一障碍。除数据本身的完整性、偏差性以及对新任务的适用性外,元数据还支持对认知电子战系统的评估。
元数据应对数据集的宏观特征(macro features)进行标注,例如版本、作者、采集日期,以及场景的目的与目标。合成数据(synthetic data)与真实数据(real data)应采用相同的结构。这些全局特征(global features)的示例包括:
- 任务类型与序列(Mission type and sequencing);
- 通信流量类型与模式(Traffic type and patterns);
- 位置信息(Location),例如室内、室外、实验室、微波暗室(anechoic chamber)、GPS坐标及地形(topography);
- 环境条件(Conditions),例如天气、移动性(mobility)、农村/城市环境;
- 实验设计(Experiment design),例如受控实验(controlled)或“野外”实验("in-the-wild");
- 实验场景(Experiment scenario),例如辐射源数量及其类型/角色;
- 硬件与软件组件(Hardware and software components),例如版本、能力及测量误差;
- 数据生成/采集方式(Generation/collection style),例如有线采集(over-the-wire)、无线采集(over-the-air)或合成数据(并注明所用软件);
- 数据集内部及数据集之间的相互依赖关系(Interdependencies);
- 采集协议(Collection protocols),例如连续/间歇性实验、重置/持久化配置;
- 假设条件(Assumptions),包括显式假设和(若可能)隐式假设,尤其是针对合成数据的简化假设(simplifying assumptions)。
标注越详细,数据在多种场景下的可用性就越高。例如,“此电缆将无线电C内部的部件A连接至部件B”这样的细节,在初始采集阶段可能看似多余或过度工程化(overengineered),但保留这一记录可为未来的分析与复用提供可能。再如,注明数据是以二进制、整数、定点数还是n位浮点数(n-bit floating point)格式采集的,能让其他使用者立即判断该数据是否适用于其特定场景。(许多公开数据集以浮点格式记录,而这与现场可编程门阵列(FPGAs)不兼容。)
图8.3展示了一个基于空中交通管制雷达的概念性(notional)复杂示例。最终的空中交通管制显示界面整合了来自多个不同来源的信息,包括场面监视雷达(Surface-Movement Radar, SMR)、机场监视雷达(Airport Surveillance Radar, ASR)、机场周边的多点定位(multilateration)传感器、广播式自动相关监视(Automatic Dependent Surveillance-Broadcast, ADS-B)传感器,以及飞行计划数据。

图 8.3 多个组件构成的复杂网络,共同生成高质量航迹并保障整体空中交通安全。
每条推断出的飞行航迹都依赖于一个由相互连接组件构成的复杂网络。多个平台采集不同类型的原始数据,生成中间推理结果,并将这些结果传递给其他平台。不同的数据格式、通信媒介和通信协议协同传输这些推理信息,最终形成支持告警系统和空中交通管制的综合航迹推断。该复杂系统中的每个组成部分——包括硬件、固件(firmware)、软件、通信链路和显示设备——都必须通过认证,以满足航空安全标准,因为每个部分都会影响最终推理的准确性,以及利益相关方对系统的信任程度。而这些信息被记录的详尽程度,则直接影响数据分析和故障定位的难易程度。
对所有内容进行标注(Annotate everything):包括人类观察者和软件组件所做出的所有观测与结论,例如发送数据的目的以及所进行的推理。例如,一天开始时采集的实验数据可能与设备持续运行发热后的数据存在不同的伪影(artifacts)。特别重要的是识别异常情况,例如罕见的“边缘”案例(rare "edge" cases)或专门构造用于利用系统弱点的对抗性案例(adversarial cases)。
对所有内容实施版本控制(Version-control everything):包括软件与硬件配置、定制化设置以及任务场景(mission scenarios)。这一要求的重要性无论如何强调都不为过。
认知雷达需要一种机制来评估并确保其知识来源的可靠性:既包括通过访问数据库提供的历史知识来源,也包括通过作战经验习得的知识。这不仅需考虑欺骗(deception)的可能性,还需评估数据的有效性是否会随时间推移而退化。
——Gürbüz 等,2019年[4]
东北大学(Northeastern University, NEU)的射频指纹(RF fingerprinting)项目为综合性实验中的元数据提供了具体范例[5]。该元数据记录了原始数据集的描述、预处理步骤、模型架构,以及数据训练与测试的方法,如表8.2所总结。为评估射频指纹识别性能并确保实验可复现,NEU对每次实验的详细特征进行了记录[5]。每个组件均关联相应参数(例如,“切片”操作会从可配置比例的数据中随机选取样本)。基于此结构,特定实验可评估信道效应、每个突发(burst)中I/Q样本数量,以及信号起始时刻(signal onset)是否对结果产生影响。若通过标签注明训练集包含发射机1至k,而测试集包含发射机k+1至n,则可进一步评估数据多样性对学习新型辐射源(novel emitters)能力的影响[6]。
表 8.2 东北大学(NEU)为确保实验可复现而记录的每次实验详细特征
| 预处理(Preprocessing) | 模型(Model) | 学习任务(Learning Task) |
|---|---|---|
| 带通滤波(Band-filtering) | 完整人工神经网络架构(Full ANN architecture)(例如层数、激活函数、批归一化(batch normalization)和丢弃率(dropout)) | 评估场景(Evaluation scenario) 训练过程(批次、轮次、归一化、早停等) |
| 部分均衡(Partial equalization) | 优化器(类型、评估指标、损失函数) 训练平台(CPU、GPU等) |
训练集群体(Training population)(设备、样本数量等) |
| 切片(Slicing) | 训练后的权重(Trained weights) | 验证集群体(Validation population) |
| 测试集群体(Test population) | ||
| 结果(准确率、耗时等) |
上表源自:[5]
原始数据本身理想情况下应记录每个发射机与每个接收机的详细信息,包括时间同步传输(time-synchronous transmissions)等信息。这些细节使得分析移动性(mobility)、发射机与接收机链路(transmitter versus receiver chains)以及同时存在的信号(simultaneous signals)所产生的影响成为可能。
时间是必须忠实记录的最重要特征之一。
若时间未被准确记录,人工智能系统将极难恢复相关信息。例如,一个脉冲串(pulse burst)的汇总信息可能与其组成脉冲的时间到达(Time of Arrival, TOA)不一致。
硬件布局(Hardware layouts)和软件版本同样应详细记录。当前开发能够认知自身局限性的AI系统所面临的一个主要缺口,是关键信息在处理链(processing chain)中丢失。例如,尽管系统集成商了解雷达系统的角度与距离测量误差,但这些信息必须对AI可用。如果元数据(metadata)记录了原始测量中的不确定性(uncertainty),软件模块(尤其是数据融合模块)便可据此估算最终推理结果的误差与置信度(confidence)。
图8.4展示了一个基础的、单一的通用软件无线电外设(Universal Software Radio Peripheral, USRP)无线电设置,用以说明USRP硬件驱动(UHD)和基于FPGA的应用程序所处的位置。在服务器端,有多种方式可与UHD通信:使用原始C/C++编码性能最佳,但要求用户从头编写所有信号处理模块;而GNU Radio软件包(C/C++或Python)则更易于快速采用,但效率可能略低。在USRP端,可利用射频片上网络(RF Network on Chip, RFNoC)工具创建FPGA应用程序,以抽象部分基于FPGA的处理流程。UHD软件应用程序编程接口(Application Programming Interface, API)支持在所有USRP软件定义无线电(Software-Defined Radio, SDR)产品上进行应用开发[7]。采用通用软件API可提升代码可移植性(portability),使应用程序在必要时能无缝迁移到其他USRP SDR平台,同时通过保留和复用既有代码降低开发工作量,使开发者能专注于新算法的开发。
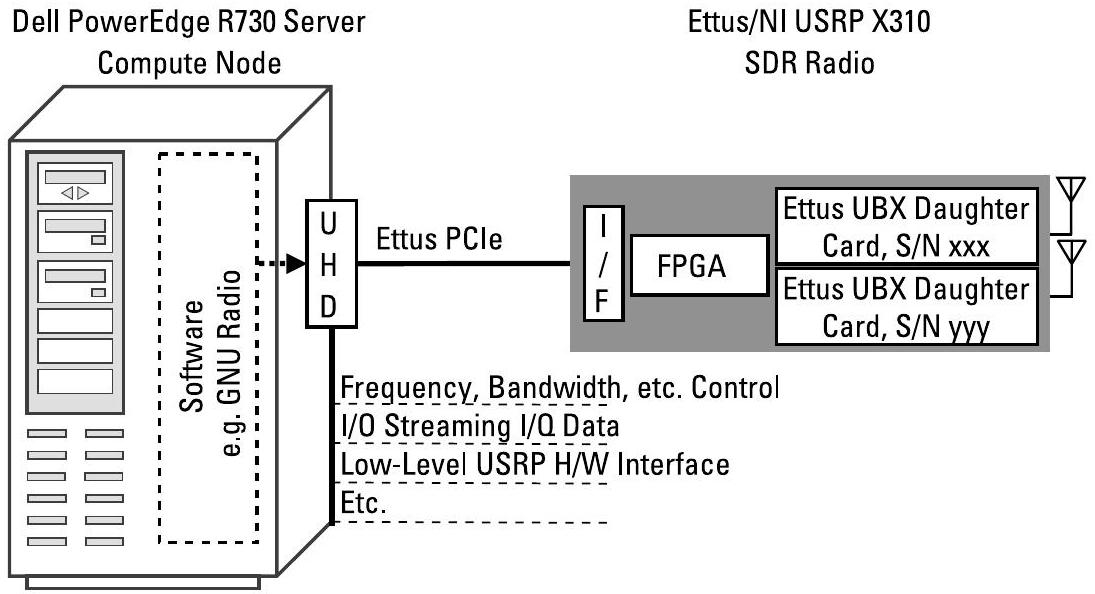
图 8.4 元数据应包含此USRP结构中硬件、固件(firmware)和软件的详细信息,包括版本号与序列号。
8.1.2 语义(Semantics)¶
成熟的数据语义(data semantics)是支撑互操作性(interoperability)、任务复用(task reuse)和数据共享(data sharing)等任务的关键要素。良好的语义使数据能够在不同系统之间以及跨越时间被有效复用。即使组件(包括软件、硬件、平台和任务)不断演进,数据集仍可持续扩展。
有两种正交(orthogonal)工具用于捕获数据语义:本体(ontologies)和模式(schemas)。本体是用于捕获概念含义的词典;模式则是用于捕获数据的格式。
本体(Ontology)是一种表示语义信息的形式化结构,它对特定问题领域中的术语、类别、概念、数据和实体及其相互关系进行正式命名与定义。领域本体(domain ontology)聚焦于特定问题领域,而过程本体(process ontology)则描述处理链(processing chain)中所涉及的步骤与约束条件。目前已存在针对认知无线电(Cognitive Radio, CR)[8–10]和雷达[11]的本体。这些本体各有侧重:例如,软件定义无线电(SDR)论坛的本体[8]聚焦于自适应调制(adaptive modulation),而Cooklev与Stanchev提出的本体[10]则支持无线电拓扑结构(radio topology)的描述。网络本体语言(Web Ontology Language, OWL)常用于构建本体[12],而Protégé编辑器则用于创建和操作本体[13]。开发本体时的主要挑战在于:仅针对必要任务进行构建,避免过度工程化(overengineer)而引入永远不会被使用的概念。
对于某些任务而言,形式化的本体可能过于繁复。关键在于建立清晰、无歧义的语义(clear semantics that cannot be misinterpreted)。
信号元数据格式(Signal Metadata Format, SigMF)[14, 15]是由GNU Radio社区采纳的一种开放标准模式(schema)。它记录了样本采集的通用信息(例如目的、作者、日期)、生成样本的系统特性(例如硬件、软件、场景),以及每个信号的特征(例如中心频率和时间戳)。该基础格式存在多种扩展:例如,天线格式(antenna format)可记录天线型号、频率范围和增益方向图等信息,而WiFi扩展则增加了帧(frames)和数据包(packets)的相关信息。配套的Python库sigmf使该格式易于使用。此外,SigMF支持标注(annotations),可用于添加注释,例如该信号是否为人为注入,或由机器学习模型如何分类。算法8.1给出了一个简短示例。东北大学(NEU)的GENESYS实验室提供了两个与SigMF兼容的数据集,用于USRP X310无线电的射频指纹(RF fingerprinting)研究[16]。
VITA-49是一种互补标准,用于通过数据传输链路发送射频样本[17, 18];其设计面向动态传输中的数据(data in motion),而非长期存储。其数据包类型包括上下文包(context)、信号数据包(signal data)和控制包(control)。
谷歌(Google)的开源协议缓冲区(Protocol Buffers, protobuf)用于序列化和共享结构化数据[19]。Protobuf以紧凑性著称,强调简洁性与性能(尤其适用于网络通信),并保持向后兼容性。然而,它并非自描述(self-describing)格式:数据的结构信息独立于数据本身。相比之下,简单对象访问协议(Simple Object Access Protocol, SOAP)[20, 21]是一种自描述(因此紧凑性较低)的数据格式。
算法 8.1 SigMF记录了关于数据采集、系统特性以及每个信号特征的信息。(示例由文献[15]中README文件的代码生成。)
{
"global": {
"core:author": "jane.doe@domain.org",
"core:datatype": "cf32_le",
"core:description": "All zero example file.",
"core:sample_rate": 48000,
"core:sha512": "18790c279e0ca614c2b57a215fec...",
"core:version": "0.0.2"
},
"captures": [
{
"core:datetime": "2020-08-19T23:58:58.610246Z",
"core:frequency": 915000000,
"core:sample_start": 0
}
],
"annotations": [
{
"core:comment": "example annotation",
"core:freq_lower_edge": 914995000.0,
"core:freq_upper_edge": 915005000.0,
"core:sample_count": 200,
"core:sample_start": 100
}
]
}
8.1.3 可追溯性(Traceability)¶
可追溯性是从安全视角和学习/推理视角判定数据完整性(data integrity)的必要组成部分。其两个关键要点是:
- 系统必须确保数据在摄入(ingest)、分析、传输或存储过程中未被篡改或损坏;
- 系统必须追踪数据在其流经硬件、固件(firmware)、软件、通信链路及人工环节过程中的来源(provenance)与可信度(credibility)。
数据的来源记录了数据的出处,而其可信度则衡量数据源的可靠性(即数据是否真实反映了其所应代表的内容)。尽管来源与可信度常被视为网络安全问题,但这些问题同样适用于采集质量低劣的数据。事实上,若系统能够判定数据系被蓄意操纵(deliberately manipulated),反而可能通过补偿机制得出比数据采集草率或不完整时更准确的推理结果。
凡可归因于无能者,勿归咎于恶意。
——罗伯特·汉隆(Robert Hanlon),汉隆剃刀(Hanlon's Razor)
良好的数据采集与整理(curation)是创建可信数据的第一步;数据的每一次转换(transformation)也会相应改变其可信度。例如,数据融合(data fusion)可将多个低可信度来源的信息融合,生成相对高可信度的结论。另一个例子是:通过融合多个分类器的预测结果与无人机(drone)的监视数据,可提升雷达辐射源信号识别与分类的准确性;其中,监视数据可提供目标的视觉确认及其位置信息,从而进一步增强预测数据的可信度。
可追溯性确保电子支援(Electronic Support, ES)数据融合能得出正确结论(见第4.3节),并确保数据管理(Data Management, DM)算法能正确处理信息不确定性(见第6.1.4节)。此外,可追溯性还使得异常与错误能够被回溯至其源头,便于更换故障组件并获得更优结果。
8.2 数据整理与偏差(Curation and Bias)¶
数据整理(Data curation)是指对数据进行验证、组织与整合的活动。整理的目的是确保数据的高质量,从而使系统能够从中得出高质量的结论。其核心目标是消除偏差(bias)并提升数据质量。几乎所有的数据集都存在某种程度的偏差,即它们无法准确反映模型的实际应用场景,从而导致结果偏斜、准确率低下和分析错误。例如,偏差可能导致雷达跟踪误差,甚至对同一目标生成多条航迹(tracks)。常见的数据偏差形式包括:
-
样本偏差或选择偏差(Sample or selection bias):当样本无法代表数据的底层分布时即发生此类偏差。该问题源于实验设计缺陷(如缺失关键样本)或环境因素导致部分样本遗漏。例如,由于大气波导(ducting)和地表波(surface-wave)效应,信号在陆地与海面上传播特性截然不同;实验与数据采集必须对此类因素进行补偿。
反馈回路(例如由强化学习(Reinforcement Learning, RL)所引发的)可能加剧选择偏差。例如,每次成功使用某电子对抗(Electronic Countermeasures, ECM)技术都会强化系统重复使用相同(或类似)技术的倾向,从而沿梯度方向陷入局部最优(local optimum)。若不主动采用主动学习(active learning)策略并维持数据多样性,系统可能被困于局部最优,永远无法发现全局最优解(global optimum)。
-
类别偏差(Class bias):当数据过度偏向某些特定类别时即产生此类偏差。若数据能覆盖射频(RF)信号的各类形式(如频率、调制方式和协议),所训练出的模型就越有可能捕捉到射频信号的全部潜在特征(latent features),而非仅限于过于狭窄数据集中的特征。(针对特定类型射频信号的专用模型是合理的,但应明确标注其适用范围。)
-
排除偏差(Exclusion bias):指在数据采集完成后、通常在预处理阶段人为剔除部分样本所导致的偏差。例如,若系统仅记录“值得关注”的辐射源数据,或仅保留信噪比(SNR)高于/低于某一阈值的数据,则关键样本将被丢失。电子战(EW)系统中一种常见结构是:传统(legacy)框架会直接处理其已知的信号,仅将无法识别的数据转发给后续模块;这种模式构成重大挑战,因为认知模块仅能接收到“残余数据”(scraps),缺乏足够的历史信息与上下文,难以做出准确推断。
-
测量偏差(Measurement bias):由校准错误、传感器偏差或空间配准错误(misregistration)、测量故障、样本误标(mislabeled examples)、变量缺失,或训练与推理阶段所采集数据不一致等因素引起。
例如,空间配准错误(spatial misregistration)会导致虚假的雷达航迹(false radar tracks)。 数字信号处理(Digital Signal Processing, DSP)中的重采样(resampling)也可能引发显著的测量偏差。若为满足DSP的计算或内存需求而对原始数据进行降采样(down-sampled),则可能丢失关键特征。同样,若数据抽取(decimating)过程违反奈奎斯特准则(Nyquist criteria),将产生混叠(aliasing),造成无法在后续处理中纠正的失真。
-
回忆偏差(Recall bias):一种误标类型,指相似样本被赋予不同标签;在随时间演化的动态系统中,这是常见问题。领域可能发生变化,概念也可能发生漂移(concept drift)。
若系统组件被更换,标签的含义可能随之改变。例如,通过循环平稳性(cyclostationary)处理分离的信号,其特性与通过频率分离的信号截然不同。维护完整的元数据(metadata)可确保这些含义被正确解读。
-
观察者偏差或确认偏差(Observer or confirmation bias):标签基于预期结果而非实际结果。此类问题的常见原因是系统无法识别新颖样本(例如一种新型调制方式),而将其归类为最相似的已知样本。单一数据源同样会带来风险,即数据可能编码了该特定来源的伪影(artifacts),例如当数据仅由单台接收机采集时。
系统性偏差(Systemic bias)不同于噪声(noise)——噪声是指领域中随机的可变性。相比偏差,噪声更容易被度量和校正。尽管从存储数据中去除噪声可能颇具诱惑力,但所采用的特定去噪技术本身可能引入新的偏差。通常而言,数据集中应保留噪声,以降低过拟合(overfitting)风险;事实上,数据增强(data augmentation)技术会刻意引入噪声(见第8.3.3节)。一般预期是:训练数据属性中的噪声分布应与推理阶段的噪声分布相匹配[22, 23],这一点应予以验证[1]。
然而,噪声也是导致分类错误的主要原因之一,因为模型可能学习拟合噪声而非底层概念(underlying concept)。正则化(regularization)、多样性(diversity)和交叉验证(cross-validation)是确保噪声有助于提升模型质量的有效技术。
8.3 数据管理实践(Data Management Practice)¶
任务中(in-mission)和任务后(postmission)的数据管理是实现预期实践效果的基础。算法开发阶段与任务中运行阶段对数据管理的要求有所不同。在开发阶段,数据库的空间和时序约束相对较少,因此应做到内容全面且标注详尽。
然而,在嵌入式系统(embedded system)中,必须考虑空间和时序约束。数据多样性(data diversity)可在保证所需模型质量的同时,实现高效的内存利用和快速计算。数据增强(augmenting data)是确保数据多样性的有效方法,尤其在应对对抗性环境(adversarial settings)时效果显著。遗忘无关数据(forgetting irrelevant data)有助于确保模型与当前态势的相关性。最后,数据安全(data security)可保障数据的私密性。
8.3.1 嵌入式系统中的数据¶
嵌入式系统中的数据管理需求与服务器集群(server farm)中的大规模数据计算系统截然不同。此外,许多电子战(EW, Electronic Warfare)系统运行在战术边缘(tactical edge),通信能力受限甚至完全缺失,因此存储与计算必须严格本地化。
控制数据集规模可同时解决内存占用和计算时间两个问题。BBN SO [24](见例7.1)采用固定长度的循环缓冲区(circular buffer),在内存中维持样本实例的多样性,并遗忘旧实例。所有样本均记录在持久化存储(persistent storage)中,供后续任务使用,但这些数据不会在实时(real time)中被访问。BBN SO 存储 \(k\) 个实例,每个实例包含 \(\overline{o_{n}}+\overline{c_{n}}+\overline{m_{n}}\) 个特征(每个特征为一个8位整数)。系统计算实例两两之间的点积距离,并存储一个三角形相似度矩阵(triangular similarity matrix),其大小为 \(\frac{1}{2} k^{2}\)。为提升内存和计算效率,该三角矩阵采用固定大小的一维数组实现,并通过索引算术(index arithmetic)[25]进行访问:一维数组中元素 \(x[i ; j]\) 的索引为 \(\frac{1}{2} i(i+1)+j\)。该相似度矩阵随后成为数据多样性、模型计算以及主动学习(active learning)实验管理的基础。矩阵规模可控且可预先确定,并可根据平台可用内存进行调整。
控制数据集规模不仅可满足内存约束,还能提升计算效率:较小的数据集更不易触发缓存未命中(cache miss)惩罚,且使用较小数据集训练模型的速度更快。
8.3.2 数据多样性(Data Diversity)¶
在内存受限的嵌入式系统中,尽可能高效地利用可用内存至关重要。确保数据多样性(data diversity)是构建具有良好泛化能力(generalizability)模型的关键之一。训练数据的多样性可确保数据包含足够的判别性信息,以识别关键特征(即最大化数据所包含的信息量)。数据应涵盖边缘案例(edge cases)和对抗性样本(adversarial examples)。其目标是使模型能够构建高质量的抽象表征(abstract representations)。模型泛化能力越强,就越有可能在面对全新环境时仍保持良好性能。此外,如数据增强(data augmentation)文献(见第8.3.3节)所示,多样性还有助于抵御对抗性攻击(adversarial attacks)。
数据集无需庞大,但必须多样。
在三种不同射频(RF, Radio Frequency)环境中各采用三种不同策略所获得的27个样本,远比在单一射频环境中重复采集一百万个样本更有价值——即便每次对该环境的观测都略有差异。图8.5展示了这27个数据点;尽管样本数量极少,但显然这些样本对性能曲面(performance surface)的覆盖远优于针对单一策略或单一环境的大量样本。通过维持一个多样化的数据集,即使样本数量有限,所学习的模型仍可实现良好性能。
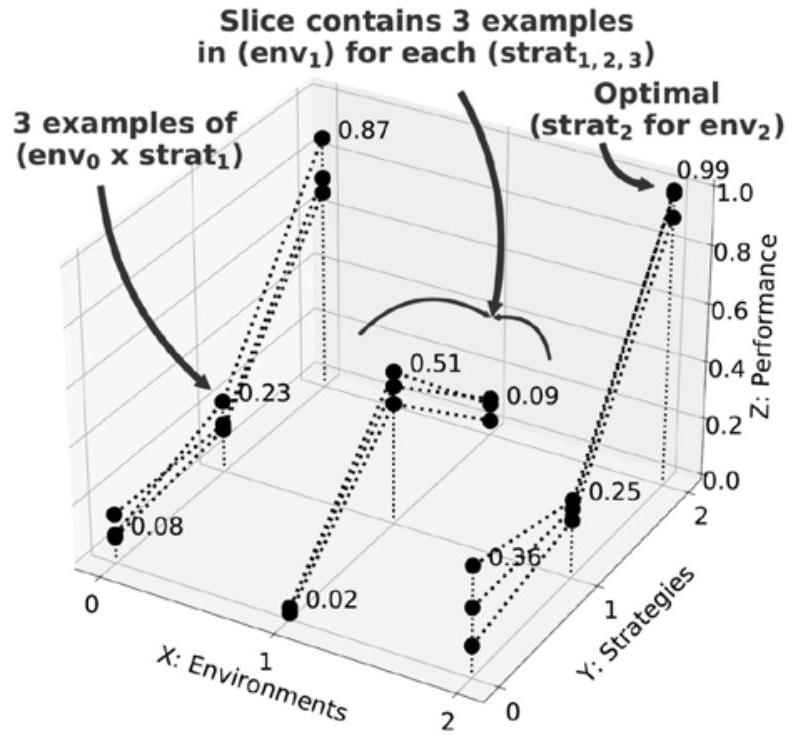
图8.5 三种环境与三种策略各自组合产生27个多样化的训练点(人工数据)。其中,一个“环境”对应一组可观测向量 \(o\) 的聚类,而一个“策略”对应一组可控变量 \(c\) 的设定。图4.5展示了来自真实环境的若干二维环境“切片”,其中某些区域并无观测数据,但模型仍能基于相似特征进行泛化。
计算多样性的简单有效方法之一,就是计算样本之间的两两点积(pairwise dot products)。当一个新观测到达时,可计算其与内存中已有样本之间的距离。若该距离为零,则说明该新观测与现有知识完全冗余。需要注意的是,点积计算可根据用途不同,仅包含可观测变量(observables),或同时包含可观测变量与策略(strategy),甚至进一步包含度量指标(metrics)。例如,计算射频环境(RF environments,见第2.1.1节)时仅使用可观测变量,而管理多样化的训练数据集则还需纳入策略和度量指标。
Mirzasoleiman 等人 [26] 提出了一种严谨的方法,用于从完整训练数据集 \(V\) 中选取一个小型子集 \(S\)。该数据核心集(coreset)是一个加权子集 \(S\),能够最佳逼近 \(V\) 的完整梯度(full gradient),并可通过一种快速贪心算法(fast greedy algorithm)高效求得。在每一步中,该贪心算法选择能使估计误差上界的缩减幅度最大的元素。能够以至多 \(\varepsilon\) 的误差估计完整梯度的最小子集 \(S\) 的规模,取决于数据的结构性质(structural properties)。该算法在保持泛化精度的同时,显著加快了训练速度。
事实上,多样性的重要性如此之高,以至于模拟生成的多样性数据甚至能取得优于非多样化真实世界数据集的效果。本质上,尽管模拟值无法完全捕捉真实环境的复杂性或自然噪声,但它们确实拓宽了可用于推理的知识广度。真实世界数据集天然存在不平衡性,而隐蔽的战备保留模式(hidden war reserve modes)会进一步加剧这种不平衡。模拟数据有助于“引导启动”(bootstrap)学习过程。第11.2.3节介绍了若干射频(RF)数据生成工具。展示多样性影响的相关研究包括:
- 消融实验(ablation trials)表明,使用多样性最高的数据集训练模型,可在新环境中获得最佳泛化性能(见第10.2节)。
- “伪类”(pseudo classes)促使不同类别相互排斥,从而使所学模型倾向于选择更具判别性的特征 [27]。
- 多样化小批量随机梯度下降(Diversified Minibatch Stochastic Gradient Descent, DM-SGD)通过构建相似度矩阵,抑制相似数据点在同一训练小批量(minibatch)中同时出现 [28]。该方法在无监督问题中可生成更具可解释性和多样性的特征,在有监督问题中则能获得更高的分类准确率。
- 凸传导实验设计(Convex Transductive Experimental Design, CTED)[29, 30] 引入了多样性正则项(diversity regularizer),以确保所选样本具有多样性。该方法排除了信息冗余的高度相似样本,在性能上持续优于其他主动学习(active learning)方法。
- 信息量分析(informativeness analysis)采用两两点积梯度长度(pairwise gradient length)[29] 作为信息量度量,而多样性分析则对所提出的多样性梯度角度施加约束。实证评估验证了该方法的有效性与高效性。
- 熵度量与管理(entropy measurement and management)[31] 可控制样本外误差(out-of-sample error);高熵解具有更低的误差,并能更好地应对新出现的情境。
多样性(diversity)与不确定性(uncertainty)是主动学习中选择实验(即选择待标注样本)的有效方法 [32, 33]。
8.3.3 数据增强(Data Augmentation)¶
创建数据多样性(data diversity)最有效的方法之一是数据增强(data augmentation)。数据增强是一组技术,使机器学习(ML)从业者能够在无需实际收集新数据的情况下,提升训练数据的多样性。增强技术包括:在现有数据集中添加对已有数据进行轻微修改的副本,或基于现有数据合成全新的数据。
数据增强与数据分析中的过采样(oversampling)概念密切相关,可在学习模型的训练阶段有效减轻过拟合(overfitting)[34]。例如,在图像处理领域,常用的数据增强技术包括填充(padding)、裁剪(cropping)、翻转(flipping)以及调整光照方案(changing lighting schemes)。
数据增强对于捕捉数据不变性(data invariance)至关重要。数据不变性指在测量条件发生变化时,某些属性仍保持不变的特性。例如,当一架飞机改变其俯仰(pitch)、偏航(yaw)和/或滚转(roll)姿态时,其表面积保持不变;因此,飞机的表面积具有旋转不变性(rotational invariance)。数据增强可确保模型在训练过程中充分学习此类不变性特征。
Chung 等人 [35] 提出了一种方法,通过相关性分析(correlation analysis)、动态分桶(dynamic bucketization)、未知计数估计(unknown count estimation)和未知值估计(unknown value estimation)来检测样本偏差、类别偏差和召回偏差(sample, class, and recall bias)。随后,他们利用检测结果对数据进行增强。
许多数据增强(data augmentation)方法的一个共同主题是在数据集中添加噪声(noise)。噪声可存在于可观测变量(observables)和度量指标(metrics)中。通过向特征中注入结构化噪声(structured noise),可提升模型精度 [36–41]。高斯噪声(Gaussian noise)是最常用的噪声类型。噪声具有正则化效应(regularization effect),可增强模型的鲁棒性(robustness)。添加噪声意味着网络更难以记忆训练样本,从而导致网络权重更小,构建出泛化误差更低、更鲁棒的网络。可参考以下准则:
- 在添加噪声前对数据进行归一化(normalize)。
- 仅在训练阶段添加噪声。
- 可向输入数据的特征中添加噪声。
- 可在训练前向输出中添加噪声,尤其适用于目标值为连续变量的回归任务。然而,在能够从输出中去除噪声的情况下,往往可获得更优的结果 [42]。
- 可向激活值(activations)、权重(weights)和/或梯度(gradients)中添加噪声 [37]。
Soltani 等人 [43] 提出了一种用于训练阶段的数据增强技术,该方法使射频指纹识别(RF fingerprinting)深度神经网络(DeepNet)暴露于原始数据集中所未包含的多种模拟信道和噪声变化中。作者提出了两种数据增强方法:一种针对发射机数据(使用无数据失真的纯净信号),另一种针对接收机数据(使用被动获取的空中传输信号)。实验表明,采用发射机数据增强后性能提升了 75%,而接收机数据增强则带来了 32%–51% 的性能提升。
Sheeny 等人 [44] 提出了一种基于雷达信号实测特性的雷达数据增强技术。其模型在未增强数据上的准确率仅为 39%;在引入平移(translations)和图像镜像(image mirroring)增强后,准确率提升至 82%;而当进一步采用包含信号衰减、距离相关的分辨率变化、散斑噪声(speckle noise)和背景偏移(background shift)等雷达特性的数据增强后,准确率高达 99.8%。
数据增强并不依赖对射频频谱(RF spectrum)的先验知识。Huang 等人 [45] 利用旋转(rotation)、翻转(flip)和高斯噪声(Gaussian noise)来提升无线调制识别(radio-modulation recognition)的分类准确率。借助数据增强,即使使用更短的无线信号样本也能成功完成调制分类,从而简化深度学习模型并缩短推理时间。他们还证明,数据增强在低信噪比(SNR)条件下同样能显著提升分类准确率。
数据增强(data augmentation)还有助于防御对抗性攻击(adversarial attacks)。精心构造的样本可训练模型抵御白盒攻击(white-box attacks,攻击者完全了解模型)、黑盒攻击(black-box attacks,攻击者对模型一无所知)以及介于两者之间的灰盒攻击(gray-box attacks)[46, 47]。
生成对抗网络(GANs, Generative Adversarial Networks)[48] 正逐渐成为生成对抗样本和训练模型的事实标准方法。GAN 的一个关键优势在于其无需任何关于射频(RF)特性的先验信息。对抗训练(adversarial training)技术将一个生成网络(generative network)与一个判别网络(discriminative network)置于对抗竞争之中:生成网络的目标是欺骗判别网络,其生成的人工数据专门用于暴露判别模型的弱点。最著名的 GAN 应用之一是生成不存在的名人照片 [49],其逼真程度足以使人类无法将其与真实照片区分开来。GAN 已被证明可提升调制识别(modulation recognition)[50, 51] 和雷达目标识别(radar target recognition)[52] 等分类任务的准确率。此外,其生成组件还被用于信号欺骗(signal spoofing)和合成新型调制方式(synthesizing new modulations)[53, 54]。
8.3.4 遗忘(Forgetting)¶
与数据增强(data augmentation)相对的是遗忘(forgetting)。有多种原因需要主动从训练数据集中剔除数据,包括内存受限、信息不准确以及类别不平衡(class imbalance)。关键在于避免在某一类别(如射频环境或策略)内发生信息的完全丢失,即维持数据集的多样性(diversity)。
在任务执行过程中,当内存和计算时间受限时,可采用以下简单策略来决定从内存中的训练数据集中剔除哪些样本:
- 距离(Distance):剔除与其他样本(在可观测变量、策略和度量指标方面)高度相似的实例;
- 类别不平衡(Class imbalance):剔除那些已被充分代表的类别实例(即其样本数量远多于其他类别的实例);
- 保真度(Fidelity):剔除用于引导学习器(bootstrap the learner)的实例(例如由模拟数据生成,或在相似但非完全相同的平台上采集的数据);
- 时效性(Age):采用“剔除最旧实例”(drop-the-oldest)策略,该方法能对不断变化的任务条件做出响应。
需要注意的是,所有在任务中(in-mission)采集的样本都应(且必须)存储在持久化存储(persistent storage)中,以供任务后(postmission)分析使用。任务后分析可用于识别缺失数据(例如,无法解释的性能表现通常意味着缺少某些可观测变量)、跨系统与跨任务的模式(例如,某些现象在单个节点上仅短暂出现,但在整个编队中却规律性地重复发生),以及最佳实践(例如,不同的数据筛选与管理方法)。
永久性地遗忘数据很难被合理化。尽管数据可能随时间推移而退化,但旧有知识在面对全新条件、系统一无所知时,仍可作为引导启动(bootstrap)学习过程的重要资源。此类知识迁移(knowledge transfer)能够显著加速模型在新环境中的学习速度。良好的元数据(metadata)可记录数据的历史与上下文信息,供任务前(premission)分析用于决策:在未来的任务中应选用哪些数据进行训练。我们必须克服为安全起见而刻意销毁数据的惯性思维,转而探索适当的数据保护方法。
8.3.5 数据安全(Data Security)¶
数据存储中的一个常见问题是数据敏感性(data sensitivity),尤其是涉密数据集(classified datasets)。系统必须同时保护数据(防止对手重建原始数据)和模型(防止对手推断系统漏洞)。
差分隐私(Differential Privacy, DP)是一种用于量化隐私保护强度的数学定义,可为抵御隐私攻击提供可证明的保障 [55]。DP 具有若干可用于分析保护效果的宝贵性质 [56],包括:(1) 隐私损失的可量化性;(2) 群体隐私(group privacy);(3) 对后处理(postprocessing)的免疫性;以及 (4) 多次计算下的可组合性与隐私损耗可控性。
实现差分隐私的方法多种多样,大多数涉及对原始数据集进行修改。对数据集进行匿名化(anonymizing)可提供隐私保护,并便于在其他场合共享数据。具体方法包括:
- 标签匿名化(Label anonymization):为特征(可观测变量、可控变量和度量指标)赋予匿名名称(例如,“音调干扰机”变为“environment#1”,“陷波滤波器”变为“technique#1”)。标签匿名化的优势在于,决策者无法利用标签本身的语义含义(换言之,人工智能系统对特定数据集保持语义无关性),从而使同一套代码可迁移至不同的能力、平台和任务。
- 归一化(Normalization):将数据归一化至固定范围,例如使用 int8 表示的 -128 到 127。此外,大多数学习模型都要求数据归一化,以避免大数值特征压制小数值特征;在归一化数据上训练的模型通常具有更好的泛化性能。
- 泛化(Generalization):对数据进行舍入并降低其精度。
- 离散化(Discretization):将数值区间替换为离散标签。
- 扰动(Perturbation):使用均匀函数对数值进行修改;在适当情况下可添加噪声。
此外,还存在一些可在保护隐私的前提下进行模型学习的方法。其目标是构建一个不会泄露原始训练数据特征的模型,同时确保基于特定样本的任何推理结果保持不变。可考虑以下方法:
- 系统在完全加密的数据上训练模型 [57–62],并输出加密结果;
- 系统将敏感数据划分后,训练一组“教师”(teacher)模型;随后,利用未标记的非敏感数据,训练一个“学生”(student)模型来模仿该教师模型集成的行为 [63];
- 联邦学习(federated learning)系统将训练数据分布于多个节点,各节点本地训练模型参数,随后在中心节点聚合这些参数,生成融合模型后再分发回各节点 [64]。每个节点仅基于自身观测数据进行学习,而中心模型从未接触原始数据。
良好的安全策略需采用多层防护机制,包括标准的网络安全(cybersecurity)措施。在整体解决方案中,其中一层关键防护是即使模型本身遭到泄露,也能通过保护模型与数据来维持信息隐私(information privacy)。
8.4 结论(Conclusion)¶
尽管存在相反的误解,系统并不需要庞大的数据集即可实现有效学习。通过数据管理(data management)维持数据多样性(diversity),是构建高质量、具备良好泛化能力模型的最有效途径——此类模型不仅能应对新出现的情境(样本外,out-of-sample),还具备对抗对抗性攻击(adversarial attacks)的鲁棒性。较小的数据集还能显著提升计算效率,缩短训练与推理时间。
一名优秀的数据工程师(data engineer)应确保数据具备高质量,并能在不同平台、不同任务以及跨时间维度上重复使用。通过深入的交互设计与用例开发,可确保电子战(EW)领域与人工智能(AI)领域使用相同的术语并拥有共同的目标 [65];同时,我们也必须弥合这两个社群之间的社会认知鸿沟。详尽的元数据(metadata)是实现高质量数据管理(DM, Data Management)和根本原因分析(root-cause analysis)的基础,使系统能够将误差从原始测量逐级追溯至最终推理结果。
垃圾进,垃圾出。
——托马斯·麦克雷(Thomas McRae),1964年,《计算机对会计的影响》人生就像下水道:你从中得到什么,取决于你往里投入什么。
——汤姆·莱勒(Tom Lehrer),1959年,《当我们一同离去时》(We will all go together when we go)
References¶
[1] Cluzeau, J., et al., Concepts of Design Assurance For Neural Networks (CoDANN), European Union Aviation Safety Agency. Online: https://tinyurl.com/CoDANN-2020.
[2] US DoD. (2020). "DoD data strategy." Accessed 2020-10-08, Online: https://tinyurl.com/ dod-data-strategy-2020.
[3] Savage, S., and J. Thibault, "Towards a Simulation Network," in Winter Simulation Conference, 2015.
[4] Gürbüz, S., et al., "An Overview of Cognitive Radar: Past, Present, and Future," IEEE Aerospace and Electronic Systems Magazine, Vol. 34, 2019.
[5] Tong, J., et al., "Deep Learning for RF Fingerprinting: A Massive Experimental Study," Internet of Things (IoT) Magazine, 2020.
[6] Youssef, K., et al., Machine Learning Approach to RF Transmitter Identification, 2017. Online: https://arxiv.org/abs/1711.01559.
[7] Ettus Research. (2020). "UHD (USRP Hardware Driver)," Online: https://www.ettus.com/ sdr-software/uhd-usrp-hardwaredriver/.
[8] Li, S., et al., Now Radios Can Understand Each Other: Modeling Language for Mobility, Wireless Innovation Forum. Ontology from May 08, 2014 on https://www.wirelessinnovation. org/reference-implementations/.
[9] Li, S., et al., "An Implementation of Collaborative Adaptation of Cognitive Radio Parameters Using an Ontology and Policy Based Approach," Analog Integrated Circuits and Signal Processing, Vol. 69, No. 2-3, 2011.
[10] Cooklev, T., and L. Stanchev, "A Comprehensive and Hierarchical Ontology for Wireless Systems," Wireless World Research Forum Meeting, Vol. 32, 2014.
[11] Horne, C., M. Ritchie, and H. Griffiths, "Proposed Ontology for Cognitive Radar Systems," IET Radar, Sonar and Navigation, Vol. 12, 122018.
[12] World Wide Web Consortium (W3C). (2020). "Web Ontology Language (OWL)." Accessed 2020-11-07, Online: https://www.w3.org/OWL/.
[13] Musen, M., "The Protégé Project: A Look Back and a Look Forward," ACM SIG in AI, Vol. 1, No. 4, 2015.
[14] Hilburn, B., et al., "SigMF: The Signal Metadata Format," in GNU Radio Conference, 2018.
[15] GNU Radio Foundation. (2020). "Signal Metadata Format (SigMF)." Accessed 2020-1031, Online: https://github.com/gnuradio/SigMF.
[16] Sankhe, K., et al., "ORACLE: Optimized Radio Classification Through Convolutional Neural Networks," in INFOCOM, Dataset available at https://genesys-lab.org/oracle, 2019.
[17] Cooklev, T., R. Normoyle, and D. Clendenen, "The VITA 49 Analog RF-Digital Interface," IEEE Circuits and Systems Magazine, 2012.
[18] VMEbus International Trade Association (VITA). (2020). "Vita: Open Standards." Accessed 2020-10-31, Online: https://www.vita.com/.
[19] Google. (2020). "Protocol Buffers." Accessed 2020-11-07, Online: https://developers. google.com/protocol-buffers.
[20] World Wide Web Consortium (W3C), SOAP, Accessed 2020-12-08, 2020. Online: https:// www.w3.org/TR/soap/.
[21] Potti, P., "On the Design of Web Services: SOAP vs. REST," M.S. thesis, University of Northern Florida, 2011.
[22] Quinlan, J., "The Effect of Noise on Concept Learning," in Machine Learning, An Artificial Intelligence Approach, Morgan Kaufmann, 1986.
[23] Zhu, X., and X. Wu, "Class Noise vs. Attribute Noise: A Quantitative Study of Their Impacts," Artificial Intelligence Review, Vol. 22, 2004.
[24] Haigh, K. Z., et al., "Parallel Learning and DM for a Smart Embedded Communications Platform," BBN Technologies, Tech. Rep. BBN-REPORT-8579, 2015.
[25] Haigh, K. Z., et al., "Machine Learning for Embedded Systems: A Case Study," BBN Technologies, Tech. Rep. BBN-REPORT-8571, 2015.
[26] Mirzasoleiman, B., J. Bilmes, and J. Leskovec, "Coresets for Data-Efficient Training of Machine Learning Models," in ICML, 2020.
[27] Gong, Z., et al., "An End-to-End Joint Unsupervised Learning of Deep Model and PseudoClasses for Remote Sensing Scene Representation," in IJCNN, 2019.
[28] Zhang, C., H. Kjellstrom, and S. Mandt, "Determinantal Point Processes for Mini-Batch Diversification," in Uncertainty in AI, 2017.
[29] You, X., R. Wang, and D. Tao, "Diverse Expected Gradient Active Learning for Relative Attributes," IEEE Transactions on Image Processing, Vol. 23, No. 7, 2014.
[30] Shi, L., and Y.-D. Shen, "Diversifying Convex Transductive Experimental Design for Active Learning," in IJCAI, 2016.
[31] Zhang, Y., et al., "Energy-Entropy Competition and the Effectiveness of Stochastic Gradient Descent In Machine Learning," Molecular Physics, No. 16, 2018.
[32] Gong, Z., P. Zhong, and W. Hu, "Diversity in Machine Learning," IEEE Access, Vol. 7, 2019.
[33] Ren, P., et al., A Survey of Deep Active Learning, 2020. Online: https://arxiv.org/ abs/2009.00236.
[34] Shorten, C., and T. Khoshgoftaar, "A Survey on Image Data Augmentation for Deep Learning," Journal Of Big Data, Vol. 6, No. 1, 2019.
[35] Chung, Y., et al., Learning Unknown Examples for ML Model Generalization, 2019. Online: https://arxiv.org/abs/ 1808.08294.
[36] Brownlee, J. (2018). "Train Neural Networks with Noise to Reduce Overfitting." Accessed 2020-11-22, Online: https://tinyurl.com/noise-and-overfitting.
[37] Goodfellow, I., Y. Bengio, and A. Courville, Deep Learning, MIT Press, 2016.
[38] Chen, T., et al., "Big Self-Supervised Models Are Strong Semisupervised Learners," in NeurIPS, 2020.
[39] Sohn, K., et al., "FixMatch: Simplifying Semisupervised Learning with Consistency and Confidence," in NeurIPS, 2020.
[40] Reed, R., and R. Marks II, Neural Smithing: Supervised Learning in Feedforward Artificial Neural Networks, Bradford Books, 1999.
[41] Bishop, C., "Training with Noise Is Equivalent to Tikhonov Regularization," Neural Computation, Vol. 7, No. 1, 2008.
[42] Mirzasoleiman, B., K. Cao, and J. Leskovec, "Coresets for Robust Training of Neural Networks Against Noisy Labels," in NeurIPS, 2020.
[43] Soltani, N., et al., "More Is Better: Data Augmentation for Channel-Resilient RF Fingerprinting," IEEE Communications Magazine, Vol. 58, No. 10, 2020.
[44] Sheeny, M., A. Wallace, and S. Wang, "RADIO: Parameterized Generative Radar Data Augmentation for Small Datasets," Applied Sciences, Vol. 10, No. 11, 2020.
[45] Huang, L., et al., "Data Augmentation for Deep Learning-Based Radio Modulation Classification," IEEE Access, Vol. 8, 2020.
[46] Yuan, X., et al., "Adversarial Examples: Attacks and Defenses for Deep Learning," IEEE Transactions on Neural Networks and Learning Systems, Vol. 30, No. 9, 2019.
[47] Ren, K., et al., "Adversarial Attacks and Defenses in Deep Learning," Engineering, Vol. 6, No. 3, 2020.
[48] Goodfellow, I., et al., "Generative Adversarial Nets," in NeurIPS, 2014.
[49] Karras, T., et al., "Progressive Growing of GANs for Improved Quality, Stability, and Variation," in ICLR, 2018.
[50] Li, M., et al., "Generative Adversarial Networks-Based Semisupervised Automatic Modulation Recognition for Cognitive Radio Networks," Sensors, 2018.
[51] Davaslioglu, K., and Y. E. Sagduyu, "Generative Adversarial Learning for Spectrum Sensing," in ICC, 2018.
[52] Majumder, U., E. Blasch, and D. Garren, Deep Learning for Radar and Communications Automatic Target Recognition, Norwood, MA: Artech House, 2020.
[53] Shi, Y., K. Davaslioglu, and Y. Sagduyu, Generative Adversarial Network for Wireless Signal Spoofing, 2019. Online: https://arxiv.org/abs/1905.01008.
[54] O'Shea, T., et al., "Physical Layer Communications System Design Over-the-Air Using Adversarial Networks," in European Signal Processing Conference, 2018.
[55] Wood, A., et al., "Differential Privacy: A Primer for a Nontechnical Audience," Vanderbilt Journal of Entertainment & Technology Law, Vol. 21, No. 1, 2018.
[56] Dwork, C., and A. Roth, The Algorithmic Foundations of Differential Privacy, Now Publishers, 2014.
[57] Bost, R., et al., Machine Learning Classification Over Encrypted Data, International Association for Cryptologic Research, 2014. Online: https://eprint.iacr.org/2014/331.pdf.
[58] Dowlin, N., et al., "CryptoNets: Applying Neural Networks to Encrypted Data with High Throughput and Accuracy," in ICML, 2016.
[59] Tang, X., et al., When Homomorphic Cryptosystem Meets Differential Privacy: Training Machine Learning Classifier with Privacy Protection, 2018. Online: https://arxiv.org/abs/1812.02292.
[60] Lou, Q., and L. Jiang, "SHE: A Fast and Accurate Deep Neural Network for Encrypted Data," In NeurIPS, 2019.
[61] Catak, F., et al., "Practical Implementation of Privacy Preserving Clustering Methods Using a Partially Homomorphic Encryption Algorithm," Electronics, Vol. 9, 2020.
[62] Kumbhar, H., and R. Srinivasa, "Machine Learning Techniques for Homomorphically Encrypted Data," In Applied Computer Vision And Image Processing, 2020.
[63] Papernot, N., et al., "Semisupervised Knowledge Transfer for Deep Learning From Private Training Data," in ICLR, 2017.
[64] Geyer, R., T. Klein, and M. Nabi, "Differentially Private Federated Learning: A Client Level Perspective," in NIPS Workshop Machine Learning on the Phone and Other Consumer Devices, 2017.
[65] Haigh, K. Z., et al., "Rethinking Networking Architectures for Cognitive Control," in Microsoft Research Cognitive Wireless Networking Summit, 2008.