9 架构¶
基于第1至8章中对态势感知(SA, Situational Awareness)和决策制定(DM, Decision Making)的深入理解,我们可以将图1.4中认知系统的组成部分重新绘制为如图9.1所示。模块化架构(modular architecture)为这些能力提供了基础支撑,使得不同技术能够提供不同的服务,并确保信息与控制流的一致性。本章简要探讨了软件与硬件架构方面的考虑,并提供了一份简短的开发者路线图。
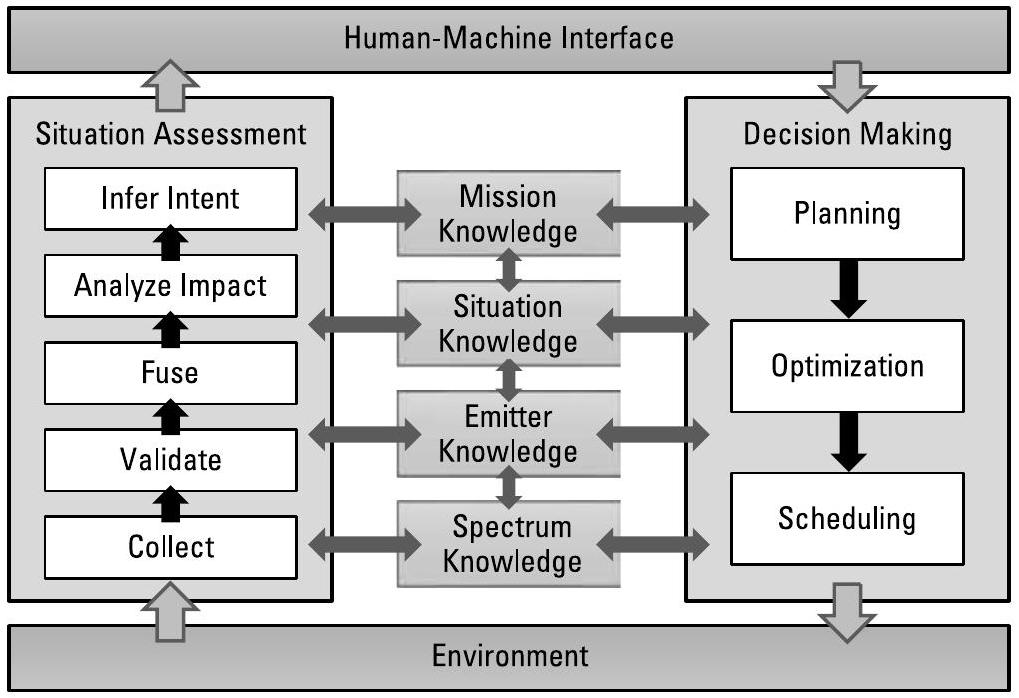
图9.1 决策制定(DM)高度依赖于态势感知(SA)。
9.1 软件架构:进程间通信(Interprocess)¶
尽管高度自适应,先进的雷达和软件定义无线电(SDR, Software-Defined Radio)架构通常仍依赖于定制化的应用程序接口(API),这些API将每个参数单独暴露出来。这种方法不适用于电子战(EW, Electronic Warfare)系统中的实时认知控制,因为紧密耦合(tight coupling)意味着人工智能(AI)无法做出全局性决策。
为消除这一障碍,各组成模块必须具备高度的模块化(modularity)和可组合性(composability)。一个通用接口(general interface)允许模块暴露其参数和依赖关系,从而实现跨多个处理器的全局优化和计算负载均衡 [1–5]。模块化系统还支持系统的实时可组合性(real-time composability),即根据任务需求动态地插入或移除模块 [1]。为此,我们需要一个中间代理(broker),提供以下功能:
-
统一接口:为任意及所有模块提供一致的接口,使得当某个模块发生变更或新增模块时,其控制模块或从属模块均无需修改。图9.2示意了紧密耦合接口与基于代理(brokered)接口之间的区别。这种模块化方法解决了模块升级或替换时的 \(m \times n\) 问题(即任意模块与任意其他模块之间需单独适配的问题)。
-
控制协调:确保多个控制器不会相互覆盖彼此的控制指令。模块不得通过除代理以外的任何接口将其参数暴露给外部进行控制。
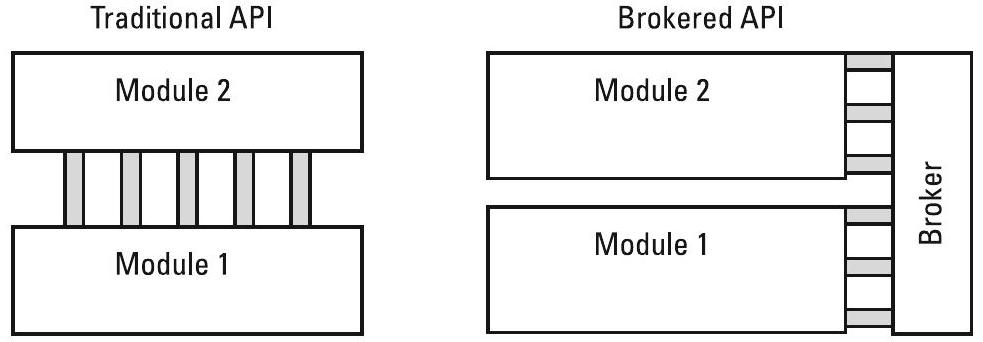
图9.2 在紧密耦合的传统API中添加或修改模块需要更新所有连接的模块,而基于代理(brokered)的API则不会影响其他模块。
首个在射频(RF, Radio Frequency)领域提供此类能力的软件架构是ADROIT代理(ADROIT broker)[1],其采用的抽象结构如图9.3所示。每个模块暴露其参数及其属性(尤其是读/写权限)。当模块发生变更(例如新增一个参数)时,只需调用 exposeParameter(name, properties) 来暴露该新参数,而无需为该参数新增一个API函数。ADROIT通过图9.4所示的具体模块实例化了该代理。ADROIT的开发人员还进行了若干详细案例演示,清晰展示了网络模块与认知层(cognitive layer)之间的关注点分离(separation of concerns)[1]。
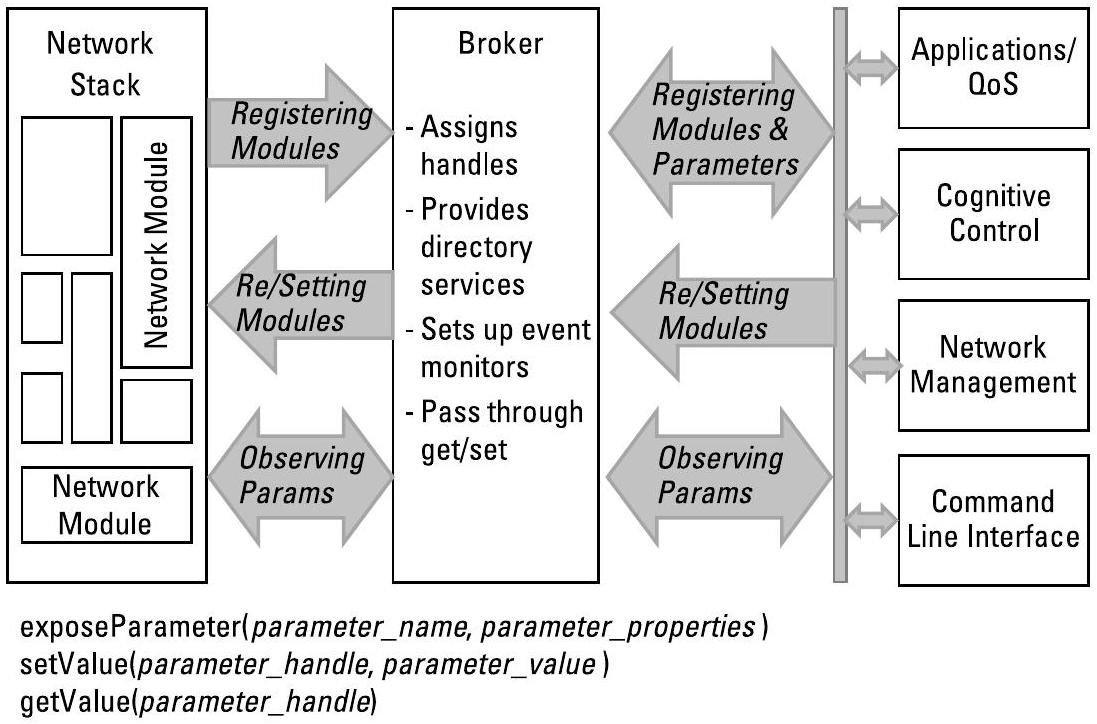
图9.3 ADROIT是首个通过代理支持认知控制(cognitive control)的网络架构。(引自[1]。)
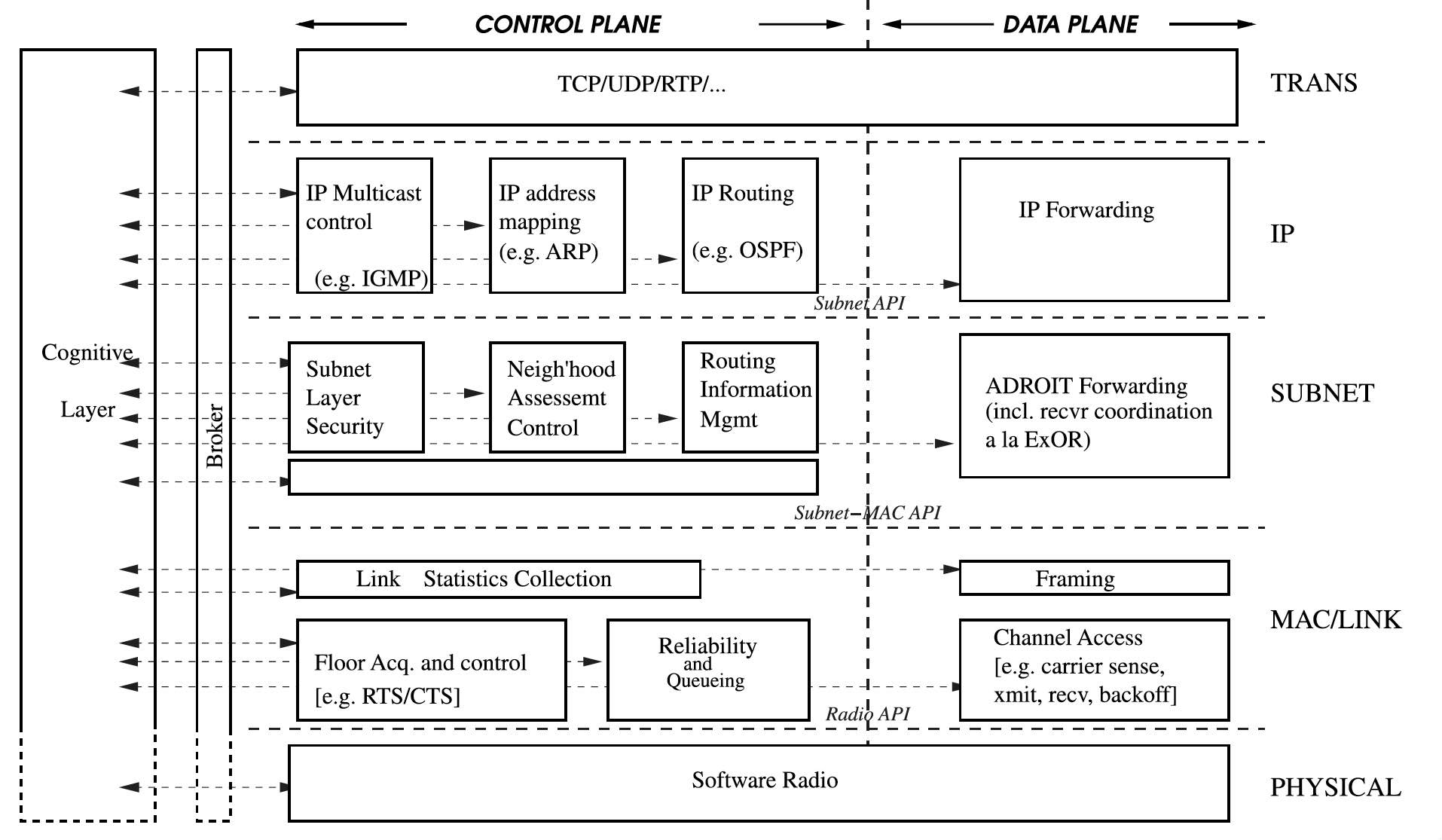
图9.4 ADROIT利用代理为模块化网络协议栈(modular networking stack)提供认知控制。(引自[1]。)
这种通用化、模块化方法的优势在于,它不限制认知(cognition)的具体形式,使设计人员能够根据问题选择合适的技术:
- 该架构支持几乎任何认知技术(cognitive technique);
- 该架构可容纳多种认知技术;
- 该架构不强制要求使用特定的认知技术。
模块化允许对能力进行细粒度分解(fine-grained decomposition);例如,某个模块可能仅计算并发布一个(且仅一个)统计量(如误码率 BER, Bit Error Rate),该统计量随后成为多个模块的输入。
基于代理(broker-based)方法的一个有趣副作用是,“应用程序”(application)与“模块”(module)之间的界限变得模糊。某个模块不仅可以向下层(“down” the stack)请求变更,还可以向上层(“up”)提出请求,例如要求视频模块降低其分辨率以满足带宽限制。理论上,任何模块都可以向任何其他模块发出指令。
现代射频(RF, Radio Frequency)系统采用各种“发布/订阅”(pub/sub, publish/subscribe)系统,例如数据分发服务(DDS, Data Distribution Service)[6, 7] 或 Kafka [8]。发布/订阅是一种异步消息传递服务,它将生成事件的服务(发布者,publishers)与处理事件的服务(订阅者,subscribers)解耦。尽管发布/订阅系统最常用于在广域网(WAN)中分发服务,但在单个CPU内部同样有效。此外,这些服务可自然地扩展至单个平台上的总线或多核处理器,或跨多个平台部署,但延迟会随之增加。
实现认知控制(cognitive control)的挑战之一是如何与遗留系统(legacy systems)协调共存。理想情况下,系统中的每个模块都应订阅同一个代理(broker),以便每个模块都能获得做出准确推理所需的上下文感知(context awareness)。然而在实践中,遗留系统通常不连接到代理,更重要的是,往往不允许认知系统追踪所有输入数据。一个常见问题是:遗留系统仅对其“已知”的射频信号作出响应,并只将未知信号传递出去。这种做法会导致排除偏差(exclusion bias,见第8.2节),并因缺乏对长期模式的感知而得出错误结论。
9.2 软件架构:进程内通信(Intraprocess)¶
当进程间的交互需要更紧密的耦合时(例如共享内存访问和相似的计算操作),线程(threading)与共享内存(shared memory)方法是合适的。任何基于实例的学习方法(instance-based learning method)——即直接将新实例与训练实例进行比较的方法——通常属于此类。
BBN SO(见例7.1)中使用的支持向量机(SVMs, Support Vector Machines)要求射频推理引擎(RRE, Radio Frequency Reasoning Engine)和长期推理引擎(LTRE, Long-Term Reasoning Engine)运行在同一进程的不同线程中。RRE 和 LTRE 均需高频、低延迟地访问同一个内部数据存储(datastore);训练数据中被选中的实例将成为支持向量(support vectors)。图9.5展示了各功能在线程间的分布情况,支撑了图5.2所示的功能结构。这项工作凸显了构建认知电子战(cognitive EW)解决方案所必需的一项关键活动:
将通用机器学习(ML, Machine Learning)库转换为嵌入式硬实时(hard real-time)软件需要大量工程投入。
该作战系统(SO, System Operator)的SVM模型源自WEKA [10],该库在当时是可用的最快机器学习库之一,并同时提供Java和C/C++版本。为嵌入式系统移植该代码的工作包括:移除不必要的代码、扁平化或替换对象结构,以及评估数值表示方式 [11]。其中工作量最大的部分(远超其他任务)是将代码改写为多线程结构:使射频推理引擎(RRE, Radio Frequency Reasoning Engine)在硬实时(hard real-time)调度下运行,确保策略选择具有确定性的时序;而长期推理引擎(LTRE, Long-Term Reasoning Engine)则在计算资源可用时于后台线程中运行。图9.6展示了这种线程划分。经过优化后的嵌入式代码运行时间仅为原始C/C++基准代码的5%,其中基准代码已禁用了“易于剥离”(easy-to-ablate)的功能模块。原始的现成(off-the-shelf)Java代码则包含一些无法剥离的额外开销,例如线程间共享计算,其运行速度比嵌入式代码慢了1,000,000倍。若将RRE和LTRE置于不同进程中,运行时间可能还会再增加超过1,000倍,因为两个进程将重复计算共享值,且系统还需承担跨进程共享数据集所带来的额外开销。
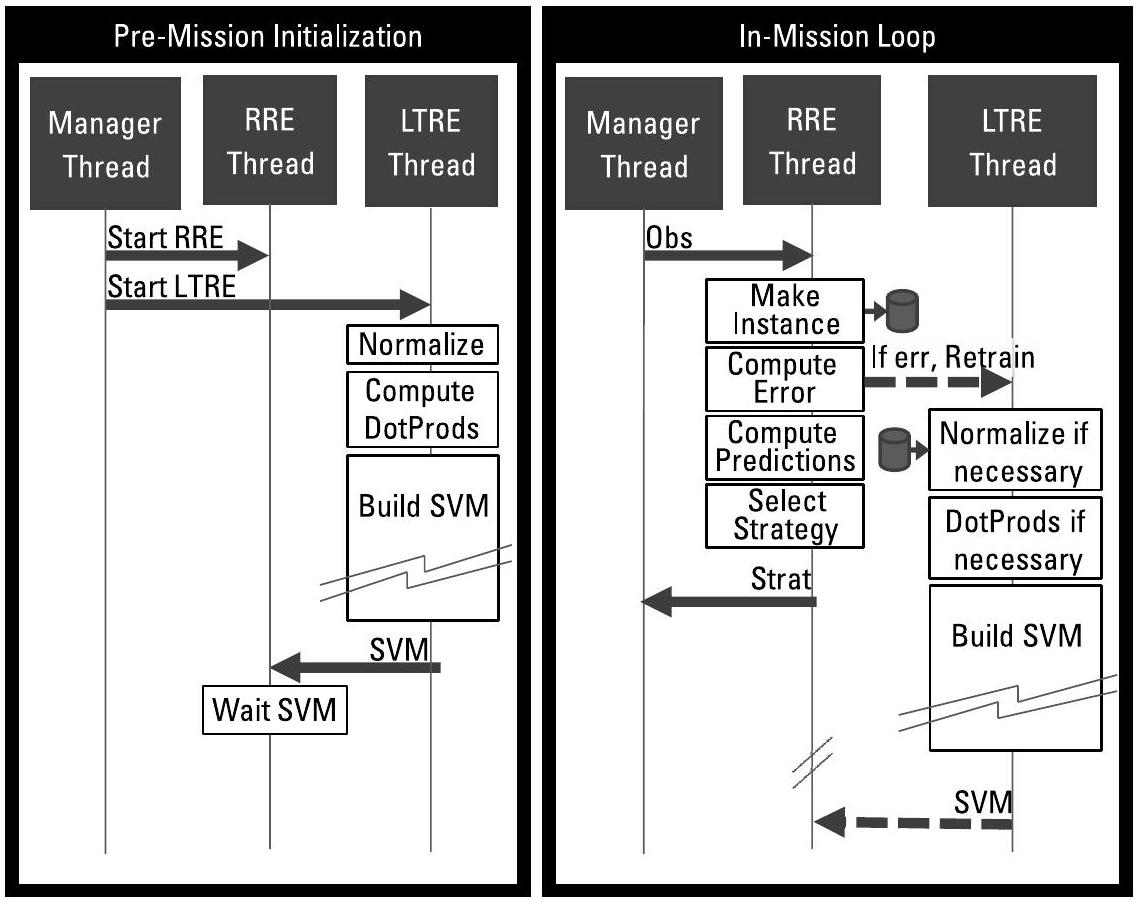
图9.5 BBN SO利用线程在线程间共享数据以实现不同能力的协同。(例7.1,[9]。)
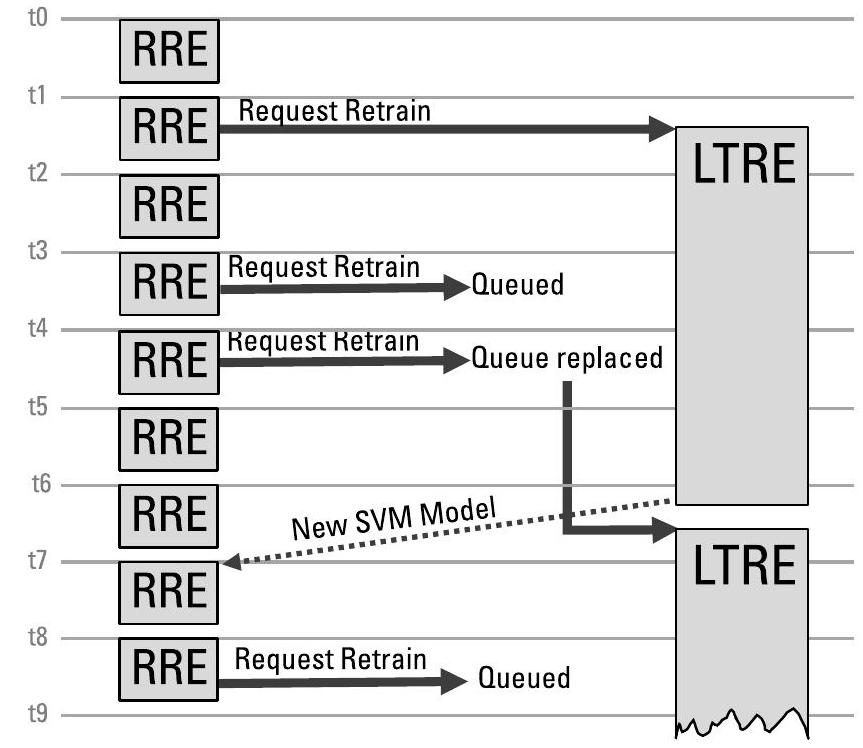
图9.6 RRE在硬实时调度下计算策略选择,而LTRE在计算资源可用时于后台线程中运行。(例7.1,[9]。)
9.3 硬件选型(Hardware Choices)¶
许多认知电子战(cognitive EW)解决方案将以软件(或固件)叠加层(overlay)的形式部署在现有遗留系统之上,在这种情况下,本节内容并不适用。但对于具备硬件选择自由度的系统而言,需权衡若干关键因素。
客户正逐渐意识到,不存在一种“最佳”的硬件能够运行种类繁多的人工智能(AI)应用,因为AI本身并无单一类型。从数据中心到边缘再到终端设备,具体应用的约束条件决定了所需硬件的能力,这也再次凸显了构建更加多样化硬件组合(hardware portfolio)的必要性。
——Naveen Rao(英特尔),2018年 [12]
对于电子战(EW)系统而言,通常最合适的硬件组合是中央处理器(CPU, Central Processing Unit)与现场可编程门阵列(FPGA, Field-Programmable Gate Array)的结合。Callout9.1强调了EW系统在硬件设计中的一些关键考量。
图形处理器(GPU, Graphics Processing Unit)在电子战作战中很可能并不适用。
Callout9.1 嵌入式电子战(EW)系统,尤其是部署在战术边缘的系统,带来了独特的硬件考量。较宽的瞬时带宽加剧了电子战对处理资源和功耗的需求问题。
| 无法接入云计算,需依赖本地处理 | 发电机与电池供电有限,要求高能效系统 |
| 空间与重量限制要求紧凑型解决方案 | 任务关键型安全与保密要求可靠且可信的解决方案 |
| 10 年以上的升级周期要求具备可扩展性与模块化的解决方案 | 面临温度、压力、冲击和湿度变化的严苛环境,要求加固型系统 |
表9.1总结了中央处理器(CPU, Central Processing Unit)、现场可编程门阵列(FPGA, Field-Programmable Gate Array)、图形处理器(GPU, Graphics Processing Unit)和定制专用集成电路(ASIC, Application-Specific Integrated Circuit)的关键特性。主要经验教训是:GPU很少能满足电子战(EW)对时序的要求——GPU虽在深度神经网络(DeepNets)训练中表现优异,但其功耗过高,且在硬实时(hard real-time)任务中可靠性不足 [13, 14]。因此,CPU和FPGA通常是EW应用的首选。其中一些显著问题包括:
- GPU功耗高(power-hungry);
- 同步(synchronization)尤为困难,有时甚至会导致CPU在无关任务上阻塞;
- 并行计算的卓越性能是以高昂的内存传输开销为代价的,这意味着实时系统会遭受不可接受的延迟;
- 文档描述与实际观测到的性能常常不一致,有时甚至相互矛盾;
- GPU的“黑盒”(black-box)特性使开发者无法建立可靠的GPU行为模型,因此系统设计者针对当前GPU所获得的经验可能在未来不再适用;
- GPU的生命周期显著短于CPU或FPGA。在国防部(DoD)项目背景下,这一问题使得系统持续保障(sustainment)更加困难,并更容易出现停产元器件与材料短缺(DMSMS, Diminishing Manufacturing Sources and Material Shortages)问题;
- GPU的安全功能集远不如CPU和FPGA先进,使其更难融入项目防护(program protection)方案。
表9.1 CPU、FPGA、GPU和定制ASIC的关键特性
| 处理器 | 特性 | 优缺点 |
|---|---|---|
| CPU(中央处理器) | - 通用应用的传统处理器 - 单核与多核架构,并包含专用功能模块(如浮点运算单元) - 缓存丰富;从内存到核心的延迟性能最佳 - 可独立运行并承载操作系统 - 针对顺序处理优化,仅支持有限并行性 |
- 支持多种任务模式;具备面向未来的能力(future-proofing) - 数据局部性(data locality)好 - 供应商可靠性高 - 提供工业级版本 - 软件生态成熟,程序员资源丰富 - 在非深度神经网络(non-DeepNet)机器学习任务中性能优异 - 在需要大量内存的推理任务中表现优异 |
| FPGA(现场可编程门阵列) | - 由可在现场重新配置的逻辑单元组成 - 可根据具体应用定制架构 - 性能更高、成本更低、功耗更低 |
- 可重构(reconfigurable) - 具备确定性的时序性能(guaranteed timing performance) - 适用于处理大规模数据集 - 适用于计算密集型应用 - 浮点运算能力较弱 - 编程难度高于其他平台,因此相对缺乏灵活性 |
| GPU(图形处理器) | - 专为执行大量相同并行操作(如矩阵运算)而设计 - 包含数千个相同的处理器核心 |
- 供应商可靠 - 对深度神经网络(DeepNets)的软件支持最完善 - 功耗高 - 计算性能提升以高昂的内存传输开销为代价 - 不适用于硬实时任务 - 规格不透明(“黑盒”特性) - 生命周期短于CPU或FPGA - 安全功能集不够先进 |
| ASIC(专用集成电路) | - 面向特定应用的集成电路(Application-Specific Integrated Circuit) - 能效比(性能/功耗)最优的解决方案 |
- 仅支持单一模式(专用AI处理) - 因技术快速过时,寿命极短(<1年) - 软件支持有限 |
GPU不适用于电子战(EW)这一事实实际上并非是一种损失:
电子战并非“大数据”(big-data)环境。
专用集成电路(ASIC, Application-Specific Integrated Circuit)在EW中或许仍有一席之地,前提是该硬件技术较短的生命周期(以及由此决定的单一应用特性)能够被相关领域所接受。
中央处理器(CPU)在硬实时系统中拥有长期优异的性能表现,并且在其长达十年的生命周期内能够灵活适应软件应用的变更。现场可编程门阵列(FPGA)则因其在流式数据上执行固定算法时性能优于CPU而成为理想选择,但其成本(以美元计)可能过高。FPGA具备可重构性,并提供强大的高能效处理能力,从而降低热管理需求和空间占用。这一特性使得加速硬件能够集成到小型封装和极端环境中。
9.4 结论(Conclusion)¶
从软件架构的角度来看,实现全系统范围的认知控制(cognitive control)最好通过模块化基础设施(modular infrastructure)来完成,其中每个模块均连接至一个骨干(backbone)并暴露其参数。
从硬件角度来看,图形处理器(GPU)在嵌入式电子战(EW)环境中通常并不适用。由于中央处理器(CPU)和现场可编程门阵列(FPGA)能够支持硬实时操作(hard real-time operations)和流式计算(streaming computation),二者结合通常是EW系统最合适的硬件选择。
在EW系统中引入认知技术(cognitive techniques)并不像许多人想象的那样复杂;关键在于选择一个规模适当的问题加以解决。
References¶
[1] Haigh, K. Z., et al., "Rethinking Networking Architectures for Cognitive Control," in Microsoft Research Cognitive Wireless Networking Summit, 2008.
[2] Troxel, G., et al., "Enabling Open-Source Cognitively-Controlled Collaboration Among Software-Defined Radio Nodes," Computer Networks, Vol. 52, No. 4, 2008.
[3] Blossom, E., "GNU Radio: Tools for Exploring the Radio Frequency Spectrum," Linux Journal, Vol. 2004, No. 122, 2004.
[4] Casimiro, A., J. Kaiser, and P. Verissimo, "An Architectural Framework and a Middleware For Cooperating Smart Components," in Conference on Computing Frontiers, 2004.
[5] Hiltunen, M., and R. Schlichting, "The Cactus Approach to Building Configurable Middleware Services," in Workshop on Dependable System Middleware and Group Communication, 2000.
[6] Object Management Group, Data Distribution Service (DDS), version 1.0, 2004. Online: https://www.omg.org/spec/DDS/1.0.
[7] Object Management Group, Data Distribution Service, DDS Portal. Accessed 2020-10-21, 2020. Online: https://www.omg.org/omg-dds-portal/.
[8] Apache. (2020). "Kafka," Online: https://kafka.apache.org/.
[9] Haigh, K. Z., et al., "Parallel Learning and Decision Making for a Smart Embedded Communications Platform," BBN Technologies, Tech. Rep. BBN-REPORT-8579, 2015.
[10] University of Waikato, NZ, WEKA: The Workbench for Machine Learning. Accessed: 2020-04-12. Online: https://www.cs.waikato.ac.nz/ml/weka/.
[11] Haigh, K. Z., et al., "Machine Learning for Embedded Systems: A Case Study," BBN Technologies, Tech. Rep. BBN-REPORT-8571, 2015.
[12] Rao, N., Intel AI—The Tools for the Job, 2018. Online: https:// tinyurl.com/intel-hw-trades.
[13] Yang, M., et al., "Avoiding Pitfalls When Using NVIDIA GPUs for Real-Time Tasks in Autonomous Systems," in Euromicro Conference on Real-Time Systems, 2018.
[14] Maceina, T., and G. Manduchi, "Assessment of General Purpose GPU Systems in Real-Time Control," Vol. 64, No. 6, 2017.