多无人机任务分配算法的比较分析¶
Comparative Analysis of Centralized and Distributed Multi-UAV Task Allocation Algorithms: A Unified Evaluation Framework¶
Yunze Song , Zhexuan , Nuo Chen , Shenghao Zhou and Sutthiphong Srigrarom (D)
Mechanical Engineering, National University of Singapore, 5A Engineering Drive 1, Singapore 117411, Singapore
Published: 28 July 2025
Citation: Song, Y.; Ma, Z.; Chen, N.; Zhou, S.; Srigrarom, S. Comparative Analysis of Centralized and Distributed Multi-UAV Task Allocation Algorithms: A Unified Evaluation Framework. Drones 2025, 9,530. https://doi.org/10.3390/drones9080530
摘要¶
无人机(UAVs),通常称为无人机(drones),在执行区域监视、搜索与救援以及协同检查等复杂任务时,提供了前所未有的灵活性。本文提出了一个统一的评估框架,用于比较专门针对多无人机操作的集中式和分布式任务分配算法。我们首先在无人机任务约束下对经典的任务分配问题(AP)进行背景化分析,这些约束包括飞行时间、推进能量容量和通信范围,并评估了最优的一对一求解器,包括Hungarian算法、Bertsekas \(\epsilon\)-auction算法,以及最小成本最大流模型。为了反映无人机集群在动态、不确定环境中所遇到的挑战,我们将分析扩展到分布式多无人机任务分配(MUTA)方法。特别地,我们考察了基于共识的捆绑算法(CBBA)和一种分布式拍卖2-opt改进策略,这两种方法通过跨无人机迭代地协商任务捆绑,以适应实时任务到达和间歇性连接。最后,我们概述了如何引入强化学习(RL),以学习能够在不同风场条件和障碍环境下平衡能量效率与任务成功率的自适应策略。通过包含无人机特定成本模型和通信拓扑的仿真,我们评估了每种算法在任务完成时间、总能量消耗、通信开销以及对无人机故障的鲁棒性方面的表现。我们的结果突出了严格最优解(适用于静态场景中的小规模机群)与可扩展、鲁棒协调(适用于大规模、动态多无人机部署)之间的权衡。
关键词:任务分配问题(AP);多无人机任务分配(MUTA);多智能体任务分配(MATA);基于共识的捆绑算法(CBBA);Bertsekas \(\epsilon\)-auction算法;Hungarian算法;一对一任务分配;集中式与分布式算法;评估框架
Keywords: assignment problem (AP); multi-UAV task allocation (MUTA); multi-agent task allocation (MATA); consensus-based bundle algorithm (CBBA); Bertsekas \(\epsilon\)-auction algorithm; Hungarian algorithm; one-to-one assignments; centralized and distributed algorithms; evaluation frameworks
1. 引言¶
由于具备机动性、灵活性以及作为协同团队执行任务的能力,无人机(UAVs,通常称为drones)在民用和军用领域迅速普及 [1]。现代多无人机系统执行的任务涵盖从城市监视、环境监测到搜索与救援以及物流投递 [2]。通过协同部署多架无人机,这些系统能够覆盖大范围区域并并行执行任务,从而实现远高于单机的效率。例如,一个完全自主的掌上大小无人机蜂群已被证明可以在密林中自主导航,这需要实时的协调来避免障碍物和无人机间碰撞 [3]。这展示了多无人机团队在复杂且先前难以进入的环境中执行任务的潜力,同时也凸显了需要稳健的任务分配与协调策略来管理此类任务。
从广义上看,多智能体任务分配(MATA)问题旨在解决如何在多个自主智能体(机器人或无人机)之间分配一组任务,以优化整体性能 [4]。在多机器人系统的具体语境下,多无人机任务分配(MUTA)指的是将任务分配给无人机团队的协同过程。当单一无人机无法独立完成所有任务时,有效的任务分配变得至关重要——这在广域监视或灾害应对等复杂任务中极为常见。在这些场景下,任务必须根据无人机的能力(如传感器载荷、续航能力)以及任务需求被智能地划分。近期研究强调,多无人机任务相较于其他多机器人环境引入了独特挑战。例如,持续监视任务中的无人机必须应对时变环境状态、有限的飞行续航(推进能量容量)以及受限的空中通信范围 [2]。若忽视这些因素,任务性能可能显著下降。这在分布式持续监视方法中尤为明显,其中任务需要动态地重新分配,以应对不断变化的信息并保持数据的实时性 [2]。总体而言,随着无人机数量和任务数量的增加,任务分配问题迅速变得组合复杂,难以在实时中得到最优解(许多任务分配问题的形式为NP-hard)。这推动了从经典优化方法到基于市场的拍卖方法以及机器学习方法的多样化研究,以在多无人机应用中在可接受的时间范围内得到足够好的解。
MUTA 的一个基本设计决策是协调架构,它大致可以分为集中式和分布式方案。在集中式架构中,单一控制节点(可以是机载的指定无人机或地面控制站)负责聚合全局状态信息,计算整个机群的最优或近似最优任务分配,并据此下达指令 [5]。这种方法的优点在于,它在一定假设下可以保证全局最优性,简化系统级监控,并且有助于集成复杂的优化算法 [6,7]。然而,集中式方案也存在一些关键缺陷,包括单点故障、大量的通信开销(随着团队规模增加而急剧上升)、在动态或竞争环境中的鲁棒性降低,以及由于非实时数据聚合和决策计算所带来的延迟问题 [8,9]。
相反,分布式架构将决策过程分散到单个无人机或局部集群。每个智能体基于局部可用信息以及点对点通信独立计算任务分配,通常采用共识算法或基于市场的协商机制 [10,11]。分布式方案天然提高了可扩展性,减少了对高带宽通信链路的依赖,并通过消除中央控制节点提升了容错能力 [2,12]。然而,去中心化方法可能由于缺乏完整的全局信息而导致次优分配,需要复杂的协调协议来达成共识,并且容易受到通信延迟和智能体间状态知识不一致的影响 [6,7]。
集中式算法如Hungarian任务分配方法在全信息条件下可以产生全局最优的分配 [13]。但这种最优性是以大量通信和单点故障风险为代价的。每架无人机必须持续向中央控制器共享其状态(位置、燃料等),这可能导致网络过载和瓶颈 [13]。更重要的是,如果中央节点发生故障或失去连接,整个任务都可能受到威胁 [13]。相比之下,分布式(或去中心化)方法避免了单一领导者的存在;无人机通过点对点通信或共识进行本地决策。这带来了更高的鲁棒性,应对故障与通信中断的能力更强,并且在团队规模扩展时表现更佳 [13]。但其代价是可能牺牲部分最优性和协调精度。缺乏全局视角时,无人机可能做出局部理性但全局次优的决策——这会导致冲突(例如多架无人机选择同一任务)或资源闲置 [13]。例如,基于市场的拍卖算法允许无人机通过投标来竞争任务并迭代达成分配;这类方法高度可扩展且灵活,但通常只能得到近似最优而非真正最优的分配。最新研究探索了混合架构(有时称为分层或混合协调),即结合集中式规划与分布式执行,从而在两者之间取得平衡 [2]。总体而言,集中式与分布式策略的选择对MUTA性能有着深远影响,特别是在受限或对抗性通信环境中。
另一个重要考量是无人机间的合作模式。在某些任务中,任务相互独立,可以简单地分配给单个无人机。在其他任务中,如重载运输或大范围搜索,将无人机组建为联盟或子团队来共同执行任务可能更具优势。近期研究已开始将MUTA视为一个联盟形成问题,并引入博弈论框架 [1]。在这种建模下,无人机不仅要决定承担哪些任务,还要决定是否与其他无人机组队共同执行任务。与单机独立执行相比,合理地将无人机组合成联盟可以显著提高复杂目标的任务效率 [1]。这些基于联盟的方法引入了额外的决策层次(例如如何在无人机间分配奖励,如何确保联盟内的稳定合作),但在灾害应对等任务中高度相关,因为这些任务可能同时需要多种无人机能力。总而言之,MUTA的背景根植于经典的多智能体任务分配问题,但由于无人机技术的独特约束与可能性(如高机动性、能量限制、无线通信以及蜂群/编队协调能力)而被进一步拓展。本文的动机在于系统地评估不同任务分配算法(集中式最优、分布式启发式、基于学习的方法等)在协调无人机团队时的表现,鉴于无人机蜂群在现实应用中的快速部署,这一问题愈发重要。
1.1. 任务分配中的挑战¶
在多无人机之间有效地分配任务十分困难,因为必须同时应对多个相互交织的挑战。下面我们重点列出了一些主要挑战,尤其关注那些在多无人机场景中尤为突出的方面。
- 计算复杂性与可扩展性
最优的多无人机任务分配(MUTA)本质上是一个组合优化问题,随着规模增加变得难以求解。即使是简化的分配场景(每架无人机一次只执行一个任务),在引入现实约束后也会映射为NP-hard的任务分配问题 [14]。随着无人机数量和任务数量的增加,可能的任务分配组合数呈指数级增长,使得穷举搜索不可行 [15,16]。在动态场景中这一问题更加严重,因为随着新任务的出现或条件的变化,任务分配可能需要频繁重新计算。因此,算法必须被设计为能够平滑扩展。相关的问题是通信的可扩展性:集中式分配器需要收集所有无人机的成本/效用信息,对m架无人机和n个任务,每轮通信开销为 \(\mathrm{O}(\mathrm{m} \cdot \mathrm{n})\) [15,16]。在大型无人机蜂群中,这会迅速耗尽无线带宽和处理资源 [15,16]。分布式方法缓解了单一通信瓶颈,但仍然需要智能体之间交换消息以达成任务分配共识。如果缺乏合理管理,随着机群的扩展,消息复杂度可能急剧增加。总之,确保任务分配方法在大规模多无人机团队中保持计算和通信效率是一个首要问题 [15]。
- 最优性与实时响应性
任务分配中存在解的最优性与决策速度之间的固有权衡。一方面,集中优化算法(例如整数规划求解器或穷举搜索)理论上可以找到使总成本最小化或任务奖励最大化的分配 [17]。然而,这些方法往往需要大量时间并依赖所有无人机的完整、最新信息。在快速变化的环境中,这种“最优”分配可能来得太迟而无法使用。另一方面,分布式或贪心启发式方法可以快速响应新任务或事件——有时通过本地计算在接近常数时间内完成——但它们放弃了最优性的保证 [15,16]。一个在某一时刻被认为是最优的分配,可能在短时间后就因无人机位置或任务状态的变化而变得次优。许多分布式方法(如拍卖、共识算法)优先考虑适应性和低通信开销,接受一定程度的解质量损失。挑战在于找到一种平衡方法,在无人机任务的严格时间约束下得到高质量的分配。例如,有研究使用多智能体强化学习(RL)方法协调异构无人机,实现了最小延迟的实时任务重分配,并在无人机数量扩展到数十架时仍能保持性能 [18]。此类基于学习或随时可用的算法旨在不断改进任务分配,逐步逼近最优,而不会因冗长计算而拖延任务。
- 动态与不确定环境
多无人机任务通常在动态且充满不确定性的环境中执行。在灾害响应、军事任务或环境监测等实际应用中,任务可能不可预测地到来(如新的火点需要监控、新目标被发现),并且任务需求会随着场景发展而变化。先前的最优任务分配可能会因新高优先级任务的出现或某区域突然无法进入而失效 [11,19]。因此,任务分配算法必须能够应对动态变化——它们应能在新任务出现或旧任务演变时高效地重新计算或调整分配。这可能涉及持续重规划、滚动时域优化,或智能体基于当前观测做出的局部决策。不确定性进一步加剧了规划难度:无人机可能因传感器噪声或通信延迟而对任务奖励或自身状态掌握不准。旅行时间或任务完成时间可能是随机的。因此,算法需要具备应对不完整与噪声信息的鲁棒性,或通过预先预估变化,或通过快速纠正分配来应对突发情况。例如,一些方法引入安全裕度或定期重分配触发机制来处理不确定性 [11,19]。总体来看,无人机任务的动态特性要求任务分配方法必须具备反应性与适应性,而非一次性静态规划。
- 通信约束
可靠通信是分布式无人机蜂群中的长期挑战。无人机常在带宽有限、连接不稳定或受严格视距限制的环境中运行(例如室内、地下或长距离通信)。高通信需求会严重影响任务分配算法的性能。例如,基于拍卖的方法要求无人机持续广播对任务的竞价,这在实验室或仿真环境中可能运行良好,但在实际应用中,这些消息可能丢失或延迟,导致分配次优甚至失败 [20,21]。研究表明,在完美网络条件下表现良好的算法,在存在丢包或延迟时可能完全失效。挑战在于设计通信高效的任务分配算法,要么尽量减少交换信息量,要么能够容忍延迟与丢包。一些最新进展利用仅需邻居间通信的共识协议,即便在异步更新或偶尔消息丢失的情况下也能收敛 [20,21]。另一种策略是通过将团队结构化为簇或层级,将通信限制在局部范围,从而减少消息传播距离 [20,21]。归根结底,由于无人机通常运行在无线自组网中,抗通信中断能力是任何实用的多无人机协调策略的关键要求。
- 对智能体故障的鲁棒性
在关键任务(如搜索与救援、危险区域探索)中,部分无人机失效、断电或因碰撞、能量耗尽等原因掉队是现实情况。一个鲁棒的任务分配系统必须能够动态地将失效无人机的任务重新分配给其他无人机,以便任务能够在最小退化下继续进行。集中式系统尤其脆弱:若中央控制无人机失效,可能瘫痪整个团队的协调 [22,23]。分布式方法天然地分散了决策,提高了容错性——单个无人机的故障(即便它是某些任务的领导者)也能被其他无人机检测并补偿,而不会导致整体崩溃 [22]。例如,一个称为MAGNNET的最新框架结合了多智能体深度学习与图神经网络,实现了完全分布式的任务分配;它在仿真中表现出更好的可扩展性与容错性,即便部分智能体被移除或通信间歇性中断,仍能保持良好性能 [13,22,23]。鲁棒性的另一个方面是应对任务负载的突然激增。如果大量新任务同时出现(如地震中的多个灾害点),分配算法应能平滑地重新分配负载,避免某个无人机过载 [22,23]。总之,确保在无人机故障或其他干扰下的平稳退化和快速恢复对MUTA至关重要。诸如冗余任务分配、对等监控(无人机监视彼此状态)以及实时重规划等技术都有助于构建鲁棒的分配系统。
- 公平性与负载均衡
虽然不总是主要的技术要求,但任务分配中的公平性会影响多无人机团队的长期效能。如果一两架无人机持续承担最繁重的任务,它们可能会过早耗尽电池或加速损耗,而其他无人机却处于闲置状态。在人机混合团队中,不公平的任务分配还会影响人类的信任与团队士气 [20,24]。因此,一些任务分配策略引入了负载均衡机制。例如,每架无人机的当前负载或近期任务历史可以被纳入新的分配决策中。通常存在纯粹的成本最优分配(可能过度使用最强无人机)与公平分配(更均匀地分布任务)之间的张力。已有研究提出了一些指标来明确衡量任务分配在机群中的均衡程度。在无人机网络中,平衡的方法可能延长整体任务持续时间,因为它避免了某架无人机过快耗尽能量。算法的挑战在于在保持良好性能的同时避免严重的负载不均。在实践中,适度的公平性约束(如避免在已有无人机满负载时仍将新任务分配给它,而优先选择替代无人机)就能显著提升团队的鲁棒性和持续性 [20,24]。
总之,多无人机系统的任务分配问题处于组合优化、实时系统与网络机器人学的交叉点。一个有效的解决方案必须应对规模扩展、动态变化、通信受限以及无人机运行的现实条件(如故障与能量限制)的复杂性。上述挑战常常相互矛盾——改善某一方面(如提高解的最优性)可能会恶化另一方面(如计算时间或通信负载)。研究人员的目标是设计能在这些权衡中取得平衡的算法,从而在真实条件下为无人机蜂群提供可靠且高效的任务分配。
1.2. 研究空白与目标¶
得益于过去十年的深入研究,目前已有多种多样的MUTA算法 [11,15]。然而,我们对不同方法之间的比较以及哪些方法更适合特定场景的理解仍存在重要空白。早期的MUTA研究往往为特定任务类型开发定制算法,而未能提供更广泛的比较视角。例如,有的研究提出了针对监视任务的新分配方法,另一些研究则设计了用于投递无人机网络的集中式规划器,但它们的评估各自独立,在不同的假设和环境下进行 [25,26]。这意味着直到最近,我们仍缺乏跨算法族的“横向”比较 [9,27]。研究人员很少在相同条件下直接比较集中式最优方法与分布式启发式方法,从而使实践者难以判断这些方法在各自案例之外的表现 [12,28,29]。
在现有文献中,大多数比较研究范围较窄。有些工作仅专注于某一类算法——例如,在去中心化环境下比较不同的分布式算法,而排除了集中式或基于学习的方法 [30,31]。另一些工作可能将经典的集中式算法与少数启发式方法进行比较,但在评估中往往忽视了诸如通信延迟或动态任务到达等现实问题 [9,31]。简而言之,缺乏统一的基准测试。正如Alqefari和Menai(2025)在最新综述中指出的那样,许多研究在不同的假设和指标下评估任务分配方法,使得难以得出普遍性的结论或最佳实践 [9]。例如,一篇论文可能仅以任务总完成时间来衡量成功,而另一篇则优先考虑通信开销或成功率,这使得直接比较变得复杂 [12,20]。目前尚未达成共识,无法断定哪种算法范式最适合多无人机协调,部分原因在于每种方法在特定条件下都有其优势(如静态环境中的集中式方法 vs. 高度动态环境中的分布式方法)[15,27]。
另一个研究空白是很少有评估能在一个场景中结合多个现实挑战。许多实验为孤立某一因素而简化问题,例如在静态环境中测试算法(无新任务出现)、假设完美通信或采用中等规模的团队 [9,9]。而在现实中,多无人机任务可能同时涉及这些挑战——在动态环境中执行任务的大规模团队,且伴随间歇性通信和潜在的无人机失效 [2,30]。很少有研究在这种全面条件下对算法进行压力测试 [32]。值得注意的是,大多数现有基准测试仅使用静态或轻度动态场景 [27]。很少有数据集或仿真同时考虑高频任务涌入、大规模任务负载激增以及智能体失效,并在不同算法间进行比较 [26]。因此,我们仍不清楚,例如,基于市场的方法在通信丢包且任务快速涌入时的表现如何,与基于学习或基于优化的方法在同样压力下的应对效果相比又如何 [11,32]。
本文的目标是通过对主要多无人机任务分配算法进行统一评估来填补这些空白。我们旨在在相同条件和多种场景下严格比较一组具有代表性的算法——涵盖集中式、分布式和基于学习的方法。通过这样做,我们试图回答以下问题:哪种算法最能应对高度动态的任务流?分布式方法为换取可扩展性和鲁棒性而牺牲了多少最优性?在何种团队规模或任务负载下,集中式方法会失效?此外,我们在评估中引入了实际因素(如通信限制和无人机故障),以检验各方法在理想化假设之外的鲁棒性。最终目标并不是宣布单一“赢家”,而是绘制权衡图:明确在哪些情况下某种算法更为优选。这类全面比较能够为实践者在具体多无人机应用中选择解决方案提供有价值的指导,同时也能揭示每种方法的优势及改进或融合的方向(例如,如果一种基于学习的方法总体表现良好,但在公平性或特定约束处理方面存在不足,就指向了未来的研究方向)。
总而言之,尽管MUTA算法工具箱不断丰富,但缺乏统一比较和综合测试仍使我们对何时、为何选择某种方法的理解存在空白。我们的研究通过在统一框架下对多样化算法进行基准测试来弥补这一不足,从而提供它们在相对性能、局限性以及对不同多无人机任务特征适用性的洞见。研究结果旨在既能为实际部署提供参考(通过将算法匹配到具体应用场景),又能明确指出需要进一步研究的方向(如提升算法的可扩展性或适应性)。
1.3. 本文的贡献¶
本文对多智能体任务分配(MATA)进行了系统性研究,主要贡献如下:
1、全面比较框架
我们提出了一个统一框架,用于比较集中式和分布式任务分配方法(例如Hungarian算法、拍卖算法、CBBA算法以及拍卖2-opt改进算法),涵盖静态与动态场景。本研究的实现已在GitHub上开源:https://github.com/YunzeSong/Multi-UAVs-Task-AllocationAlgorithms.git (访问日期:2025年4月18日)。
2、可复现的仿真环境
开发了一个基于Python的仿真框架,提供标准化接口,用于在不同规模(小型、中型、大型)和动态条件下评估算法。
3、多维度评估指标
建立了涵盖总成本、计算时间、收敛性、通信开销、鲁棒性与可扩展性的评估指标,并辅以清晰的可视化展示。
4、集中式与分布式权衡分析
本文分析了全局最优性与可扩展性/鲁棒性之间的权衡,特别是在动态任务到达与智能体失效情况下的表现。
2. 文献综述¶
2.1. 集中式任务分配算法¶
Hungarian算法(集中式)对应算法1。Hungarian算法是一种经典的优化算法,用于解决任务分配问题;它利用图论方法在多项式时间内找到任务分配的全局最优解 [12]。作为一种集中式方法,它需要将所有任务和智能体的成本矩阵集中到单一计算节点上进行求解。Hungarian算法常被用作任务分配的基准方法,能够确保分配方案最小化总成本。然而,它假设任务是静态已知的,对于动态任务的加入则需要反复迭代运行该算法。随着问题规模的增加,其时间复杂度约为 \(O\left(n^{3}\right)\)(其中 \(n\) 为任务/智能体的数量),在非常大规模下计算开销可能变高。此外,多智能体系统中的完全集中化意味着存在单点故障风险,并且对通信的依赖性强(全局信息需要传输到中央节点进行处理 [33])。因此,Hungarian算法非常适合作为小规模静态场景下最优解的基准,以及用于评估其他算法在成本最优性方面的差距。
算法1 Hungarian算法在最优任务分配中的应用

2.2. 分布式任务分配算法¶
Bertsekas \(\epsilon\)-Auction算法(集中式/分布式)对应算法2。Bertsekas \(\epsilon\)-auction算法是一种基于竞价机制的分配算法。其思想是让智能体对任务进行竞价,任务对应一个不断调整的“价格”。算法迭代进行:未分配的智能体同时对自己最感兴趣的任务出价,该任务暂时分配给出价最高的智能体并提高价格;这一过程持续,直到所有任务都被分配。该方法本质上是原始任务分配问题的并行松弛,可以视为对偶问题的迭代近似 [34]。Bertsekas \(\epsilon\)-auction算法可以集中实现,即由拍卖人(中央节点)收集所有智能体的出价并决定任务归属;它也适合分布式实现,即每个智能体自主出价,并通过多跳通信交换价格信息来更新各自决策 [35]。在仅利用局部信息的条件下,Bertsekas \(\epsilon\)-auction算法能够收敛,最终得到的分配使总收益的最大化接近最优解 [35]。由于每轮竞价仅涉及局部计算和简单通信,该算法易于并行化,计算效率较高(典型实现复杂度约为 \(O\left(n^{2}\right)\))。该算法也适用于动态任务:当新任务出现时,可将其视为新的拍卖品,只需让相关智能体参与新一轮竞价,而无需重新计算所有分配。因此,Bertsekas \(\epsilon\)-auction算法在集中式与分布式之间起到了桥梁作用,通过分布式竞价同时提供近似最优解与良好的可扩展性。
算法2 Bertsekas \(\epsilon\)-Auction算法在最优任务分配中的应用

CBBA(Consensus-Based Bundle Algorithm,分布式)对应算法3。CBBA是一种先进的分布式任务分配算法,它结合了市场竞价与局部一致性协商 [33]。在CBBA中,每个智能体根据自身能力和任务收益贪心地构建一组任务序列(捆绑),然后智能体之间进行通信以协商一致,通过交换各自的分配意图并根据一定规则解决冲突(多个智能体选择同一任务),直至达成无冲突的任务分配一致意见 [33]。CBBA具有以下特点 [33]:(1) 完全去中心化决策,没有中央节点,适用于大规模团队以避免随智能体数量增加而出现的集中计算与通信瓶颈;(2) 多项式时间复杂度,算法随任务和智能体数量线性或多项式增长,因此在任务/智能体规模较大时仍能运行(可扩展性良好);(3) 能处理复杂场景,如每个智能体执行多个任务(时间扩展分配)、异构智能体与任务价值等,并在一定假设下对解的质量提供保证(输出可行解并具备性能保证 [33])。CBBA适合动态任务场景,因为其迭代过程可在任务集发生变化时重新触发:当新任务加入或智能体失效时,每个智能体可更新自身任务序列并再次通信以达成新共识。这种局部自适应机制使CBBA在应对任务和环境变化时具备鲁棒性。需要注意的是,标准CBBA假设同步通信,并要求智能体在每轮广播分配意图,这可能带来一定通信开销;后续研究还提出了异步版本(ACBBA),以减少通信频率和网络负担,同时保持收敛 [33]。总体而言,CBBA是分布式任务分配算法中的主流方法,我们将其作为去中心化的基准进行评估;它无需中央控制即可获得近似最优的任务分配方案。
拍卖2-Opt改进算法(分布式捆绑/竞价算法,分布式)对应算法4。拍卖2-Opt改进算法在此被用来代表另一类分布式任务分配方法,与CBBA形成对比。具体而言,拍卖2-Opt改进算法可视为一种分布式搜索或优化算法 [36,37]:智能体通过通信参与一个分布式算法过程,该过程可能采用类似捆绑竞价、分支界定等机制来决定任务分配。例如,一种可能的实现是分布式分支定界算法,每个智能体分别探索任务分配解空间的一部分,并通过交换边界信息进行剪枝搜索,以在无中心的情况下找到全局最优或近似最优解。另一种实现可能是改进的竞价算法,或分布式拍卖变体,如在任务分组或增加复杂约束时的竞价方案。在文献中,拍卖2-Opt改进算法可能特指某些具体算法(例如某研究提出的改进捆绑算法),在本研究中我们将其作为分布式算法的广义代表 [38]。我们预计这类算法能够提升分布式分配的性能,可能在解质量上比CBBA更接近最优,或在动态场景中具备更好的自适应性。但代价可能是更大的计算和通信开销。因此,通过引入拍卖2-Opt改进算法,我们能够考察分布式算法内部的权衡,例如近似最优与开销之间的平衡。在实验中,我们将该算法与CBBA一同评估,以覆盖分布式方法的不同实现风格。
算法3 CBBA在分布式任务分配中的应用

算法4 拍卖2-Opt改进算法在分布式任务分配中的应用

2.3. 基于RL的方法¶
RL算法(基于强化学习的方法,集中式或分布式)。近年来,强化学习(RL)逐渐应用于多智能体任务分配领域,提供了一条数据驱动的解决途径 [39]。RL算法允许智能体通过与环境交互学习任务分配策略:通过持续试错与反馈积累,智能体学习如何选择任务以优化长期回报。对于单智能体,任务分配可以建模为马尔可夫决策过程(MDP),并通过深度Q网络(DQN)或策略梯度等算法进行学习;对于多智能体,可以采用集中训练、分布执行的模式,或完全分布式的多智能体RL,每个智能体作为一个学习智能体独立决策。RL方法的优势在于能够适应复杂且动态的场景,并通过学习掌握环境变化模式,使智能体在实时决策中表现出接近最优的行为 [39]。已有多项研究表明,多智能体深度RL能够使智能体自主学习通信与协作策略,从而完成任务分配 [40,41]。例如,有研究使用深度Q学习,使多个智能体学习如何交换各自观测到的任务信息并协调分配,从而实现分布式任务分配,并在仿真中表现良好 [42]。RL算法也被用于动态任务场景,例如无人集群实时接收新任务分配,以及通过多智能体RL在城市环境中进行动态任务分配 [43]。由于神经网络策略的推理速度通常很快,训练好的RL模型在大规模系统中也能在接近常数时间内完成决策,这意味着RL方法有潜力扩展到数百甚至数千个智能体 [44,45]。然而,RL方法也面临挑战:训练过程耗时,并且需要仔细设计奖励函数以引导期望行为。我们将RL方法纳入比较,以代表新兴的智能体分配策略,一方面检验其能否在不同规模和动态环境下与传统算法竞争,另一方面考察其作为一种新范式的潜力。但由于其复杂性,我们未在实验中使用RL方法。
2.4. 比较分析与研究空白¶
集中式 vs. 分布式:¶
- Hungarian算法是集中式算法,需要集中所有智能体和任务的信息以实现最优匹配,适用于小规模场景。
- Bertsekas \(\epsilon\)-auction算法既可以集中实现也可以分布式实现,通过智能体间的竞价与价格调整来决定任务分配。
- CBBA与拍卖2-Opt改进算法是典型的分布式算法,每个智能体仅与邻居通信,适用于大规模和动态环境,有效避免集中式瓶颈。
- RL方法则可以集中训练,之后分布式执行,从而实现分布式决策。
最优性 vs. 近似性:¶
- Hungarian算法能够保证找到全局最优解,但在实际应用中(尤其是动态情况下)需要不断重新计算。
- Bertsekas \(\epsilon\)-auction算法与分布式方法(CBBA/拍卖2-Opt改进算法)通常只能得到近似最优解,但由于其分布式架构,在大规模问题上更具优势。
- RL方法在训练充分时能够做出合理决策,但不保证找到最优解。此外,RL算法往往面临训练不稳定与收敛问题、高维状态与动作空间的维度灾难、对未见场景的泛化能力不足,以及依赖实践中难以成立的假设等挑战,这些限制了其在现实多无人机系统中的部署 [46]。
迭代与收敛:¶
Hungarian算法通常只需一次迭代即可找到匹配(不考虑动态因素),而Bertsekas \(\epsilon\)-auction算法、CBBA与拍卖2-Opt改进算法则依赖多次迭代与智能体间通信(需要在一定轮次内收敛或达成无冲突分配),因此收敛速度是一个重要评估指标。RL方法在推理阶段不需要迭代(模型直接给出决策),但其训练过程可能需要成千上万次迭代来调整策略。
计算与通信开销:¶
- 集中式Hungarian算法在小规模下计算效率较高,但在大规模问题中计算复杂度和通信(需要上传所有消息到中央节点)可能成为瓶颈。
- 分布式算法(拍卖、CBBA、拍卖2-Opt改进算法)通过本地分配与消息交换分散计算负担,但因此需要更多通信,在多轮迭代中开销尤为显著。
- RL方法在训练完成后推理速度很快,但训练阶段计算成本高;此外,是否采用分布式执行会影响通信开销。
3. 算法框架¶
3.1. Hungarian算法¶
Hungarian算法(集中式)。Hungarian算法的基本目标是解决以下优化问题:
其中:
- \(\quad c_{i j}\) 表示智能体 \(i\) 执行任务 \(j\) 的成本(如所需距离或时间);
- \(\quad x_{i j}\) 是决策变量,当智能体 \(i\) 被分配任务 \(j\) 时取值为1,否则为0;
- 约束条件确保每个智能体被分配到且仅分配到一个任务,每个任务也仅分配给一个智能体。
该问题被称为任务分配问题,Hungarian算法保证在多项式时间内找到全局最优解 [12,33]。
3.2. Bertsekas \(\epsilon\)-Auction算法¶
Bertsekas \(\epsilon\)-Auction算法(集中式/分布式)。每个智能体为任务出价。我们定义智能体 \(i\) 对任务 \(j\) 的“效用”为:
其中:
- \(\quad v_{i j}\) 是智能体 \(i\) 对任务 \(j\) 的原始评估(通常与成本的负值成正比,例如 \(v_{i j}=-c_{i j}\));
- \(\quad p_{j}\) 是任务 \(j\) 当前的价格。
智能体选择使效用最大的任务,每次成功竞价会使任务价格提高一个很小的正数 \(\varepsilon\)。整个过程迭代更新价格,直到所有智能体都被分配到任务 [34,35]。
3.3. CBBA¶
CBBA(基于共识的捆绑算法,分布式)。CBBA的基本思想如下:
- 对每个智能体 \(i\),预先计算其对每个任务 \(j\) 的收益(通常表示为负距离,例如 \(r_{i j}=-\|\) position \(_{i}-\) position \(_{j} \|\));
- 智能体构建一个按收益排序的任务列表(捆绑),记为 \(B_{i}\)。
随后,智能体通过局部通信交换各自的分配意图,解决智能体间对同一任务的竞争问题。从数学上难以简单写成闭式公式,但其核心在于通过通信协商使每个智能体的局部决策(贪心策略)一致收敛,最终得到一组近似最优的分配方案 [33]。
3.4. 拍卖2-Opt改进算法¶
拍卖2-Opt改进算法(分布式捆绑/竞价算法,分布式)。拍卖2-Opt改进算法可以看作是对CBBA的扩展,它通过分布式搜索和局部交换机制来改进任务分配结果,而不仅仅是通过贪心构建捆绑 [36,37]。例如,一种可能的实现是分布式分支界定算法;形式化描述如下:
并满足局部交换条件:
这表明系统在交换后总成本降低。
3.5. RL算法¶
RL算法(基于强化学习的方法,集中式或分布式)。RL方法不是直接求解数学规划模型,而是使用策略网络(例如 \(\pi(a \mid s)\))来决定“在状态 \(s\) 下采取动作 \(a\)”。其目标是最大化期望累计回报:
其中 \(r_{t}\) 可以被设计为与任务成本相关的负奖励(如旅行距离的负值),以及任务完成奖励。
尽管RL在多智能体决策和任务分配中已取得显著进展,但由于训练数据需求量大、交互轮次多以及策略收敛要求高等原因,本研究未实现RL方法 [40-42]。与拍卖、Hungarian和CBBA等经典算法相比,RL通常需要大量基于仿真的训练以形成稳定有效的策略,这极大增加了实现复杂性与计算成本。此外,设计合适的状态空间、奖励函数与训练流程本身就是非平凡的问题,超出了本文的研究范围。因此,RL被视为未来研究的有前景方向,但未纳入本次实现。
4. 实验¶
本节对四种任务分配算法(Hungarian、拍卖、CBBA、拍卖2-Opt改进算法)在三类实验条件下(静态任务、动态任务以及不利条件下的鲁棒性测试)进行了比较分析。评估指标包括总成本、完成率、响应延迟、计算时间、通信开销与公平性,重点在于通过数值结果解释算法表现的趋势与权衡。
4.1. 实验设置¶
我们的仿真框架使用Python实现,为多种任务分配算法提供了统一的评估环境,包括Hungarian算法等集中式优化方法以及其他定制化插件模块。在该二维模拟器中,智能体和任务随机分布在预定义区域内,使用欧几里得距离计算旅行成本,任务可以静态或动态出现。每种算法根据其独特的策略处理当前任务与智能体状态信息,最终输出智能体-任务分配,并记录计算时间、迭代次数等性能指标。该模块化设计不仅标准化了不同算法之间的评估过程,还便于进行直接有效的比较。
具体而言,本文所有实验均在Python (3.10)环境下进行。数值计算与数据处理使用NumPy (1.24.2)与SciPy (1.10.1)完成。智能体通信与网络拓扑使用NetworkX (3.0)建模。强化学习算法基于Stable-Baselines3 (2.0.0)实现,深度学习后端为PyTorch (2.0.0)。数据可视化与绘图使用Matplotlib (3.7.1)生成。实验环境为Ubuntu 22.04平台,配备双路Intel Xeon Gold 6338处理器。
4.2. 评估指标¶
- 总成本
总成本是主要优化指标,衡量所有智能体的总旅行距离或任务完成时间。该指标直接反映了燃料与时间等资源利用效率。
- 完成率
完成率表示成功分配并执行的任务占生成任务总数的比例。高完成率意味着算法能够处理几乎所有任务,这在应急场景或任务激增时至关重要,避免因分配遗漏导致的关键性失败。
- 响应延迟
响应延迟衡量任务发布与分配给智能体之间的时间差。延迟低意味着紧急任务能被及时响应。集中式方法可能因重新规划整个分配而带来较高延迟,而分布式或RL方法倾向于立即分配任务。
- 计算时间
计算时间量化生成分配解所需的实际时间,通常以毫秒或秒为单位。更短的计算时间支持更频繁的重规划,并提升系统在问题规模增加时的可扩展性。
- 通信消息
通信消息量化分布式算法中交换的消息数量与体量,包括竞价和共识消息。更低的开销节省带宽与能量,也体现不同方法在消息负担方面的可扩展性。
- 公平性
公平性基于智能体之间任务分配的均衡性来定义。具体而言,我们通过计算每个智能体所分配任务数量的标准差来量化公平性。标准差越小,表示任务在智能体间分布越均衡,公平性越高;标准差越大,表示差异更大,即部分智能体承担的负载远高于其他智能体。该指标为衡量多智能体系统内部任务分配均衡性提供了一种直观方式,在类似任务分配研究中被广泛采用。
4.3. 静态任务分配¶
本实验的目标是在静态任务分配环境下比较四种任务分配算法的性能。在该配置中,所有任务在初始时刻(\(\mathrm{t}=0\))均已发布,因此形成了一次性分配场景,整个任务集事先已知。此设置便于隔离分析各算法的行为与性能,避免动态或时变环境带来的复杂性。
实验场景设计涵盖不同复杂度,以确保结论在多种运行规模下均具鲁棒性和适用性。实现了三个不同规模的场景:小规模场景包含5个智能体分配10个任务,作为基线揭示算法之间的基本差异;中规模场景为15个智能体分配50个任务,提供一个更具挑战性的环境以测试算法在中等复杂度下的可扩展性和效率;大规模场景则为40个智能体分配200个任务,以展示各算法的计算效率、收敛特性与整体鲁棒性。
为保证统计意义并考虑分配过程中固有的随机性,每个场景均独立重复30轮。该重复实验有助于全面评估不同任务-智能体配置下的结果一致性与性能可靠性。假设所有智能体具备同质的通信与计算能力,并且实验环境静态,无任务可用性或智能体功能的动态变化。该控制实验设计旨在为各算法在静态任务分配问题下的相对优劣提供清晰见解。
4.4. 动态任务分配¶
基于静态任务实验的洞见,研究的下一阶段引入更复杂的动态环境,其中任务随时间到达。在这种情况下,分配算法的响应性与实时处理能力将受到考验,因为它们必须应对持续出现的新任务。不同于前述一次性分配场景,动态任务流场景要求系统持续更新并重新分配任务,从而模拟现实中的操作条件。
动态环境围绕三种不同的任务发布频率设计,以反映不同系统负载与紧急程度。在慢速场景下,每10个时间单位发布2个任务,条件相对宽松但仍具实时处理挑战;中速场景每5个时间单位发布5个任务,增加了时序压力并需要更高效的分配;快速场景则模拟最高负载,每2个时间单位发布10个任务,极大考验算法快速准确分配的能力。
总模拟时间设定为100个时间单位,确保动态任务流在足够长的周期内持续,从而揭示各分配策略的运行细节。为保证结果的统计意义与鲁棒性,每个动态场景独立重复30轮。该实验设置能够详细评估各算法在不同时间复杂度下的适应性,并为其在持续与时间敏感的环境中的表现提供更深入的见解。
4.5. 鲁棒性测试¶
在分析静态与动态环境后,我们进一步扩展实验,纳入异常条件下的鲁棒性测试。此阶段专门考察分配算法在遭遇突发事件(如任务激增与智能体失效)时的韧性,这在现实场景中十分常见。
实验重点在于评估算法在面对破坏性事件时维持功能与整体性能的能力。测试框架引入三类异常条件:第一,突发场景在仿真中途突然发布大量任务,模拟系统瞬时负载急剧增加的情况;第二,失效场景中部分智能体在运行期间随机失效,在恢复前无法处理任务,模拟间歇性功能障碍;第三,组合场景同时包含任务激增与智能体失效,模拟多重不利条件并发的极端环境。
每类异常场景均在100个时间单位内运行,确保充分观察系统的动态表现。为应对随机性并强化统计鲁棒性,每个场景独立重复20轮。该严谨实验设计全面评估了各算法在不可预测与高压条件下的鲁棒性,提供了它们在面对操作异常时的实际韧性与可靠性见解。
鲁棒性测试还引入了不可靠通信与机器人故障。在消息丢失条件下,分布式算法(拍卖、拍卖2-Opt改进算法、CBBA)表现退化:CBBA因依赖多轮共识最为敏感,导致任务分配延迟或遗漏;拍卖与拍卖2-Opt改进算法通过超时与重新竞价机制恢复,但分配质量下降。集中式Hungarian方法在机器人仍可与中心通信时保持鲁棒,但网络分区会使孤立机器人被排除。
在机器人失效场景下,所有方法的完成率均成比例下降。拍卖与拍卖2-Opt改进算法会立即重新竞价失效机器人任务,代价是更高的成本与延迟;CBBA需额外的共识迭代来重新分配任务,引入更长中断;Hungarian控制器在失效时重新计算最优分配,最小化了成本增加,但在重规划期间暂停执行。
5. 结果¶
以下各小节详细说明了不同场景下的结果,并解释了各算法在不同评估指标下的表现。
在所有实验中,总成本以米(m)计量;完成率以百分比(%)表示;响应延迟与计算时间均以秒(s)计量;通信消息以消息数量表示;公平性为无量纲数值(标准差)。
5.1. 静态任务分配¶
表1-3展示了四种任务分配算法在三个不同静态场景下的比较结果,问题规模逐渐增加。以下分析与讨论基于这三张表的数据,对比了各算法在不同规模下的有效性与效率。
表1. 小规模静态任务分配场景(5个智能体分配10个任务)的性能表现。
| 方法 | 总成本 | 完成率 | 响应延迟 | 计算时间 | 通信消息 | 公平性 |
|---|---|---|---|---|---|---|
| Hungarian | \(92.2 \pm 26\) | \(0.5 \pm 0\) | \(0 \pm 0\) | \((212.5 \pm 32.7) \times 10^{-6}\) | \(0 \pm 0\) | \(0 \pm 0\) |
| Auction | \(103.5 \pm 32.1\) | \(0.5 \pm 0\) | \(0 \pm 0\) | \((456.1 \pm 84.9) \times 10^{-6}\) | \(6.17 \pm 2.04\) | \(0 \pm 0\) |
| CBBA | \(103.6 \pm 32.5\) | \(0.5 \pm 0\) | \(0 \pm 0\) | \((214.2 \pm 19.3) \times 10^{-6}\) | \(7.2 \pm 1.73\) | \(0 \pm 0\) |
| 拍卖2-Opt改进算法 | \(98.1 \pm 27.7\) | \(0.5 \pm 0\) | \(0 \pm 0\) | \((628.5 \pm 92.3) \times 10^{-6}\) | \(10 \pm 0\) | \(0 \pm 0\) |
表2. 中规模静态任务分配场景(15个智能体分配50个任务)的性能表现。
| 方法 | 总成本 | 完成率 | 响应延迟 | 计算时间 | 通信消息 | 公平性 |
|---|---|---|---|---|---|---|
| Hungarian | \(121.7 \pm 21.6\) | \(0.3 \pm 0\) | \(0 \pm 0\) | \((2783 \pm 250) \times 10^{-6}\) | \(0 \pm 0\) | \(0 \pm 0\) |
| Auction | \(115.9 \pm 13.5\) | \(0.3 \pm 0\) | \(0 \pm 0\) | \((3199 \pm 221) \times 10^{-6}\) | \(17.4 \pm 3.14\) | \(0 \pm 0\) |
| CBBA | \(120.7 \pm 18.5\) | \(0.3 \pm 0\) | \(0 \pm 0\) | \((2804.4 \pm 37.2) \times 10^{-6}\) | \(19 \pm 2.77\) | \(0 \pm 0\) |
| 拍卖2-Opt改进算法 | \(122.8 \pm 20.9\) | \(0.3 \pm 0\) | \(0 \pm 0\) | \((4972 \pm 334) \times 10^{-6}\) | \(105 \pm 0\) | \(0 \pm 0\) |
表3. 大规模静态任务分配场景(40个智能体分配200个任务)的性能表现。
| 方法 | 总成本 | 完成率 | 响应延迟 | 计算时间 | 通信消息 | 公平性 |
|---|---|---|---|---|---|---|
| Hungarian | \(150.8 \pm 12.4\) | \(0.2 \pm 0\) | \(0 \pm 0\) | \((28,574 \pm 511) \times 10^{-6}\) | \(0 \pm 0\) | \(0 \pm 0\) |
| Auction | \(150.4 \pm 13.5\) | \(0.2 \pm 0\) | \(0 \pm 0\) | \((28,870 \pm 1020) \times 10^{-6}\) | \(45.2 \pm 6.51\) | \(0 \pm 0\) |
| CBBA | \(152.7 \pm 11.7\) | \(0.2 \pm 0\) | \(0 \pm 0\) | \((29,505 \pm 424) \times 10^{-6}\) | \(45.8 \pm 2.54\) | \(0 \pm 0\) |
| 拍卖2-Opt改进算法 | \(152.1 \pm 10.8\) | \(0.2 \pm 0\) | \(0 \pm 0\) | \((42,380 \pm 5570) \times 10^{-6}\) | \(780 \pm 0\) | \(0 \pm 0\) |
在上述条件下,集中式Hungarian算法在四种方法中产生了最低的总成本解,这与其最优分配保证相符。拍卖法与基于共识的算法(CBBA及其分布式变体——拍卖2-Opt改进算法)所得到的总成本仅比Hungarian基准略高(通常在最小值的数个百分点之内),反映出它们通过迭代竞价与协商有效逼近最优分配。
在静态任务场景中,完成率被定义为一次性分配中被成功匹配的任务数与任务总数的比值。由于每个智能体一次只能执行一个任务,当任务数超过智能体数(在静态基准中很常见)时,只有一部分任务能够在单步分配中被调度。因此,此处的完成率反映了各算法在一次性匹配中的效率,当任务数大于智能体数时通常低于 \(100 \%\)。相比之下,动态任务分配实验允许智能体在任务出现后反复接取新任务,最终能够在时间上完成所有任务。
在初始分配响应延迟方面,大多数方法均表现出极低延迟:Hungarian方法在一次性批量分配中仅需毫秒级的多项式时间优化;拍卖、CBBA与拍卖2-Opt改进算法因多轮竞价或协商而稍有延迟,但仍保持在秒级,不会显著影响执行。
在计算开销方面,Hungarian算法在静态场景下最为高效,其三次方复杂度在测试规模内仍可接受。相比之下,拍卖与拍卖2-Opt改进算法因反复竞价评估而耗时更多,CBBA则因两阶段捆绑构建与冲突解决过程增加额外开销。
通信开销呈现类似规律:集中式Hungarian方法仅需最少的信息交换(收集任务信息并广播最终分配结果);拍卖与拍卖2-Opt改进算法在每轮任务中多次交换消息(竞价、回复与通知),与竞价轮数成正比;而CBBA因其重复的共识迭代而产生更高消息量。任务分配的公平性在不同方法间较高且大致相当,因为最优或近似最优的分配通常会使任务在机器人之间近乎均衡地分布,从而实现类似的负载平衡。
5.2. 动态任务分配¶
表 4–6 总结了四种任务分配算法在不同强度的动态任务到达场景下的性能。这些表格为后续的比较分析提供了依据,用于考察每种算法在不同动态水平下的响应方式,并突出它们在不同操作压力下的优势与局限。
表 4. 小规模动态任务分配场景下四种任务分配算法的性能表现(每 10 个时间单位释放 2 个任务)。
| 方法 | 总成本 | 完成率 | 响应延迟 | 计算时间 | 通信消息数 | 公平性 |
|---|---|---|---|---|---|---|
| Hungarian | \(259.1 \pm 41.4\) | \(1 \pm 0\) | \(0 \pm 0\) | \((110.1 \pm 3.96) \times 10^{-6}\) | \(0 \pm 0\) | \(0.999 \pm 0.164\) |
| Auction | \(418.9 \pm 59.9\) | \(1 \pm 0\) | \(0 \pm 0\) | \((3382.7 \pm 52.9) \times 10^{-6}\) | \(1 \times 10^{3} \pm 0\) | \(0.713 \pm 0.162\) |
| CBBA | \(251.1 \pm 50.1\) | \(1 \pm 0\) | \(0 \pm 0\) | \((134.47 \pm 6.29) \times 10^{-6}\) | \(242.1 \pm 11\) | \(0.967 \pm 0.169\) |
| Auction 2-opt 改进算法 | \(394.7 \pm 64\) | \(1 \pm 0\) | \(0 \pm 0\) | \((3511 \pm 459) \times 10^{-6}\) | \(10 \pm 0\) | \(0.793 \pm 0.138\) |
表 5. 中等规模动态任务分配场景下四种任务分配算法的性能表现(每 5 个时间单位释放 5 个任务)。
| 方法 | 总成本 | 完成率 | 响应延迟 | 计算时间 | 通信消息数 | 公平性 |
|---|---|---|---|---|---|---|
| Hungarian | \(1144.5 \pm 45.4\) | \(0.8067 \pm 0.0375\) | \(10.02 \pm 1.51\) | \((113.7 \pm 16.7) \times 10^{-6}\) | \(0 \pm 0\) | \(1.568 \pm 0.295\) |
| Auction | \(862.1 \pm 87.2\) | \(0.4603 \pm 0.0385\) | \(15.34 \pm 1.98\) | \((472.3 \pm 60.4) \times 10^{-6}\) | \(297.1 \pm 46.9\) | \(0.96 \pm 0.166\) |
| CBBA | \(890.9 \pm 86.1\) | \(0.4753 \pm 0.0397\) | \(12.32 \pm 2.14\) | \((130.7 \pm 16.5) \times 10^{-6}\) | \(149.4 \pm 10.8\) | \(0.902 \pm 0.193\) |
| Auction 2-opt 改进算法 | \(911.5 \pm 75.5\) | \(0.4687 \pm 0.0289\) | \(16.23 \pm 2.11\) | \((506.5 \pm 83.8) \times 10^{-6}\) | \(37.63 \pm 3.53\) | \(0.905 \pm 0.191\) |
表 6. 大规模动态任务分配场景下四种任务分配算法的性能表现(每 2 个时间单位释放 10 个任务)。
| 方法 | 总成本 | 完成率 | 响应延迟 | 计算时间 | 通信消息数 | 公平性 |
|---|---|---|---|---|---|---|
| Hungarian | \(1141.1 \pm 13.8\) | \(0.4213 \pm 0.0186\) | \(20.31 \pm 1.49\) | \((1750 \pm 277) \times 10^{-6}\) | \(0 \pm 0\) | \(2.285 \pm 0.471\) |
| Auction | \(955.4 \pm 89\) | \(0.09747 \pm 0.00756\) | \(27.73 \pm 2.22\) | \((1056 \pm 154) \times 10^{-6}\) | \(140.7 \pm 4.55\) | \(0.851 \pm 0.159\) |
| CBBA | \(951.4 \pm 70.7\) | \(0.09393 \pm 0.00537\) | \(26.97 \pm 2.11\) | \((860 \pm 76.6) \times 10^{-6}\) | \(114.9 \pm 13\) | \(0.789 \pm 0.137\) |
| Auction 2-opt 改进算法 | \(939.6 \pm 97.4\) | \(0.0968 \pm 0.00748\) | \(27.41 \pm 2.36\) | \((1068.6 \pm 94.4) \times 10^{-6}\) | \(64.67 \pm 4.94\) | \(0.861 \pm 0.235\) |
在动态任务分配场景中,任务随时间逐步到达,需要持续的分配更新。集中式的 Hungarian 方法在每次任务到达时重新运行,能够通过近似最优的重新计算保持较低的总成本;但随着求解器工作量的增加,新任务的延迟逐渐明显。相比之下,Auction 和 Auction 2-opt 改进算法以分布式方式增量处理任务:机器人立即对新任务进行竞价,实现快速分配与较低延迟,但在最优性上略有牺牲。CBBA 则通过将新任务融入各自的任务包并执行共识轮次进行适应,结果及时且成本略高于基于拍卖的方法。
所有方法的完成率总体保持较高。在动态场景下公平性普遍下降:成本驱动的算法倾向于过度使用部分机器人,而 CBBA 与 Auction 2-opt 改进算法有时能通过共识缓解不均衡。从定量上看,每个机器人承担任务的方差增大,其中基于共识的算法在负载均衡方面优于贪心类方法。
通信开销表现出明显的规模依赖趋势。小规模场景下,CBBA 由于密集的全对全共识带来了最高的消息量;但随着规模扩大,Auction 与 Auction 2-opt 方法因迭代竞价过程迅速膨胀而显著增加通信需求。集中式方法则始终保持低通信量。这表明,虽然 CBBA 在小规模团队中通信开销较大,但其扩展性优于基于拍卖的方法。
5.3. 鲁棒性测试¶
图 1–3 展示了四种任务分配算法在三类不同鲁棒性测试场景下的性能表现,图 4 则展示了在包含多种并发不利事件的综合场景下的表现。这些图为后续的鲁棒性分析提供了基础,使得可以对各算法在正常与异常条件下的适应性和可靠性进行细致评估。

图 1. 四种任务分配算法在正常场景事件(无异常条件)下的功能与整体性能表现。

图 2. 四种任务分配算法在激增场景事件(突发且显著的工作负载增加)下的功能与整体性能表现。
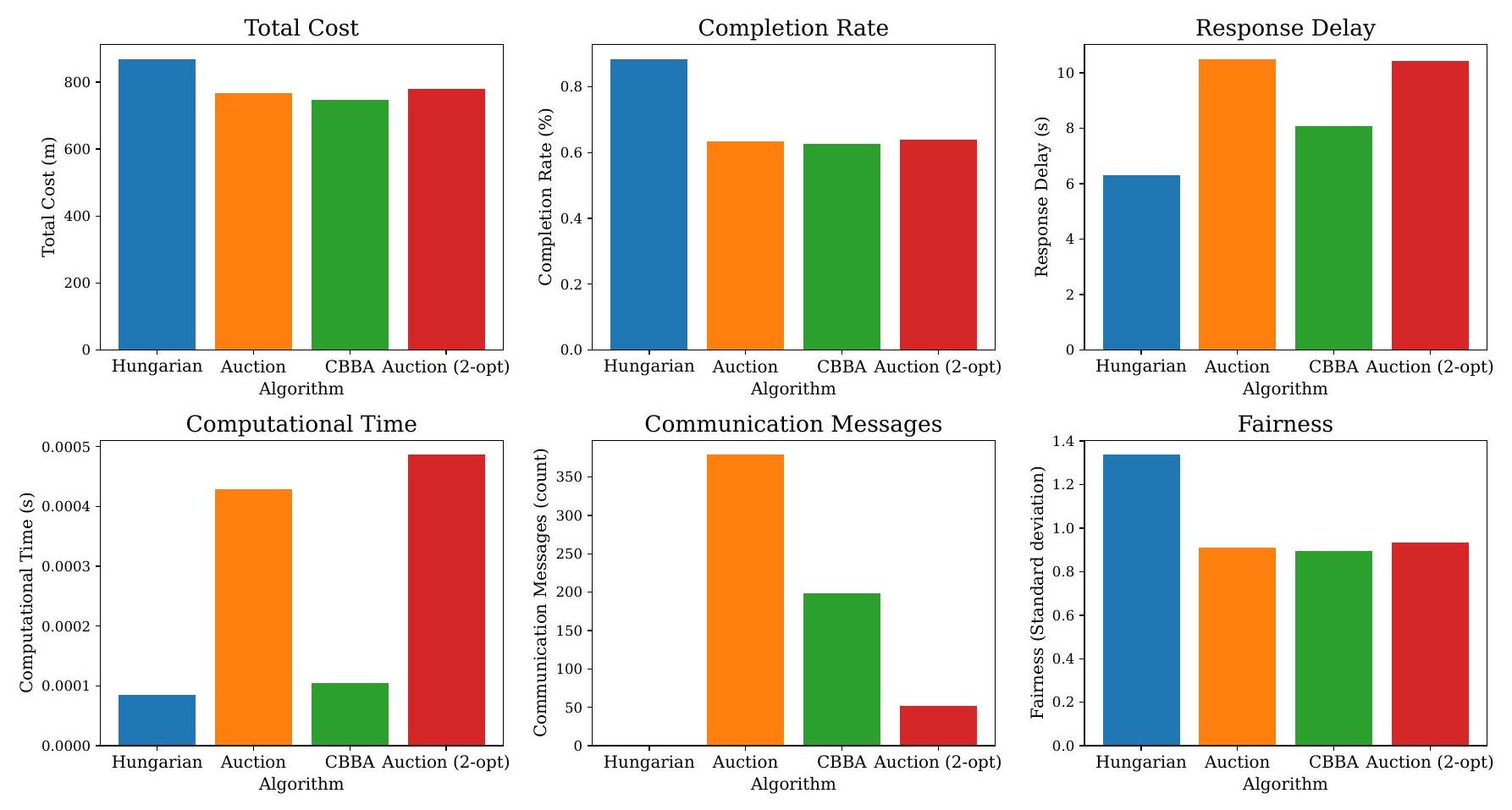
图 3. 四种任务分配算法在故障场景事件(部分智能体暂时无法处理或分配任务直至恢复)下的功能与整体性能表现。

图 4. 四种任务分配算法在综合场景事件(多种不利事件并发发生)下的功能与整体性能表现。
不利条件下,所有方法的总成本均有所增加,其中 Hungarian 方法在故障场景中最能抑制成本增长,而分布式算法则付出了中等代价。在严重的网络丢包和故障情况下,完成率下降,CBBA 受消息丢失影响最为严重,且所有方法在故障时均会丢失进行中的任务。响应延迟在干扰下加剧——分布式方法面临额外的迭代或重竞价,而 Hungarian 方法在重规划时会暂停。通信开销在不可靠网络下对于 Auction、Auction 2-opt 改进算法与 CBBA 均急剧上升,而 Hungarian 方法变化不大。公平性下降,因为故障和网络分区使幸存或仍然连接的机器人承担了更多工作负载。
5.4. 实验中的局限性与问题¶
在我们的实验中,存在若干问题。Hungarian 算法最初是为解决方阵(\(n \times n\))分配问题而设计的。当智能体与任务的数量不相等(\(n \neq m\))时,如在我们的实验中,该算法表现出一些局限性。为了解决这一点,必须在代价矩阵中填充虚拟行或列以保证其为方阵。然而,这会引入不具有实际意义的虚拟分配。因此,该算法在 \(n\) 到 \(n\) 的任务分配中通常可以得到最优解,但在 \(n\) 到 \(m\) 的任务分配中可能并非最佳方案。
关于 Bertsekas 的 \(\epsilon\)-auction 算法,它既可以解决 \(n\) 对 \(n\) 的分配问题,也可以解决 \(n\) 对 \(m\) 的问题。然而,它只能得到近似最优解,而不是全局最优解。Bertsekas 的 \(\epsilon\)-auction 算法本质上是一种基于价格调整的离散优化方法。由于任务价格是以固定的 \(\epsilon\) 增量更新的,该算法只能得到误差上界为 \(n \cdot \epsilon\) 的近似最优解。当效用值为实数时,这种离散更新机制可能会掩盖分配间的细微差异,阻止算法精确识别真正的最优解。因此,在未使用 \(\epsilon\)-scaling 的情况下,Bertsekas \(\epsilon\)-auction 算法不能保证全局最优性。Auction 2-opt 改进算法作为标准 \(\epsilon\)-auction 算法的变体,也存在相同的限制。
关于 CBBA 算法,尽管它在 \(n\) 对 \(m\) 任务分配问题上提供了很强的灵活性和分布式能力,但在这种非对称配置下也表现出一些局限性。当智能体数量显著多于任务数量时,算法容易产生不均衡的分配,即少数智能体垄断大多数任务,而其他智能体保持空闲。相反,在任务与智能体比例很高的场景中,通信开销显著增加,并且由于冲突导致的频繁任务包重构降低了收敛效率。此外,CBBA 的贪心式局部任务包构建缺乏全局路径最优性,并且对每个智能体分配任务数量的控制能力有限。
5.5. 实验总结¶
总体而言,各种算法在不利条件下都保持了其核心优劣势:Hungarian 方法保持了代价最优性,但缺乏灵活性;Auction、CBBA 和 Auction 2-opt 改进算法则以牺牲通信和成本为代价在压力下展现出灵活适应性。没有一种方法能够在所有情况下普遍优于其他方法;选择取决于任务场景中最关键的性能指标——成本、响应速度、容错性或通信效率。
6. 结论¶
本文提出了一个统一的评估框架,用于在真实无人机任务约束(如有限飞行时间、推进能量续航以及间歇性通信)下比较四种多无人机任务分配算法:集中式的 Hungarian 算法、Bertsekas \(\epsilon\)-auction 算法、基于共识的任务包算法,以及 Auction 2-opt 改进算法。通过嵌入无人机特定的代价模型(例如每个飞行段的能耗)并建模视距限制下的通信拓扑,我们的仿真捕捉了无人机蜂群在区域监视、搜索与救援、协作巡检等应用中面临的关键操作挑战。
在静态任务场景中,即所有任务已事先已知时,集中式 Hungarian 方法始终能实现最低的总飞行距离和能量消耗,使其成为小规模航测或预先规划巡检路径的自然选择。然而,随着无人机与任务数量的增长,或者飞行中出现新的航点,进行全局重规划的需求会引入不可忽视的延迟,并给地面站或主控无人机带来沉重的通信负担。
基于拍卖的启发式方法和 Auction 2-opt 改进算法通过允许每架无人机对新任务进行本地竞价,在最优性与响应性之间取得了平衡。这些方法能够以中等的计算开销获得近似最优的分配结果,使无人机能够快速响应,例如在野火监测任务中突然出现热点时。它们的分布式特性也减少了对单点控制的依赖,但需要额外的消息交换以维持一致的任务价格。
CBBA 方法则通过共识机制进一步提升了任务执行的鲁棒性:当某架无人机故障或推进能量临近耗尽时,剩余无人机通过点对点通信重新协商任务包,无需中央干预即可重新分配责任。这种鲁棒性伴随着更多的消息开销,使得 CBBA 更适用于灾难应对等高风险任务,在这些场景下可靠性需求远高于带宽节省的需求。
没有一种算法能在所有无人机任务场景下全面优于其他算法。实践者应根据任务对成本偏差的容忍度、允许的延迟、通信环境以及故障风险来选择方法。在城市峡谷中进行可靠通信的精密航测任务中,集中式方法可能足够;而在崎岖地形中快速演变的搜救场景中,则更适合基于拍卖或基于共识的方法。
展望未来,我们计划探索结合集中式规划器精确代价最小化与分布式学习策略适应性的混合架构。引入先进的公平性与负载均衡目标将有助于避免个别无人机过早耗尽电池。我们还将优化适用于带宽受限无线网络的共识协议,并在真实无人机平台上进行验证,考虑实际能量特性、异构载荷以及诸如阵风等环境扰动。
通过战略性地融合全局最优性、快速重规划与容错共识等不同协调范式的优势,我们离实现能够在未来动态空域中安全、高效、可靠执行复杂任务的自主无人机蜂群更近了一步。
Funding: This research received no external funding
Data Availability Statement: Source code and simulation data for the multi-UAV task allocation algorithms are publicly available at https://github.com/YunzeSong/Multi-UAVs-Task-AllocationAlgorithms.git (accessed 18 April 2025). For assistance, please contact the corresponding author.
Conflicts of Interest: The authors declare conflict of interest.
References¶
- Lu, X.; Song, H.; Ma, H.; Zhu, J. A Task-Driven Multi-UAV Coalition Formation Mechanism. arXiv 2024, arXiv:2403.05108. [CrossRef]
- Zhang, C.; Xu, C.; Li, G.; He, B. A distributed task allocation approach for multi-UAV persistent monitoring in dynamic environments. Sci. Rep. 2025, 15, 6437. [CrossRef] [PubMed]
- Zhou, X.; Wen, X.; Wang, Z.; Gao, Y.; Li, H.; Wang, Q.; Yang, T.; Lu, H.; Cao, Y.; Xu, C.; et al. Swarm of micro flying robots in the wild. Sci. Robot. 2022, 7, eabm5954. [CrossRef]
- Liu, J.; Li, F.; Jin, X.; Tang, Y. Distributed Task Allocation for Multi-Agent Systems: A Submodular Optimization Approach. arXiv 2024, arXiv:2412.02146. [CrossRef]
- Wang, C.; Mei, D.; Wang, Y.; Yu, X.; Sun, W.; Wang, D.; Chen, J. Task allocation for Multi-AUV system: A review. Ocean Eng. 2022, 266, 112911. [CrossRef]
- Hu, J.; Bruno, A.; Zagieboylo, D.; Zhao, M.; Ritchken, B.; Jackson, B.; Chae, J.Y.; Mertil, F.; Espinosa, M.; Delimitrou, C. To Centralize or Not to Centralize: A Tale of Swarm Coordination. arXiv 2018, arXiv:1805.01786. [CrossRef]
- Qamar, R.A.; Sarfraz, M.; Rahman, A.; Ghauri, S.A. Multi-criterion multi-UAV task allocation under dynamic conditions. J. King Saud Univ.-Comput. Inf. Sci. 2023, 35, 101734. [CrossRef]
- Lemaire, T.; Alami, R.; Lacroix, S. A distributed tasks allocation scheme in multi-UAV context. In Proceedings of the IEEE International Conference on Robotics and Automation, New Orleans, LA, USA, 26 April-1 May 2004; Volume 4, pp. 3622-3627. [CrossRef]
- Alqefari, S.; Menai, M.E.B. Multi-UAV Task Assignment in Dynamic Environments: Current Trends and Future Directions. Drones 2025, 9, 75. [CrossRef]
- Yan, S.; Feng, J.; Pan, F. A Distributed Task Allocation Method for Multi-UAV Systems in Communication-Constrained Environments. Drones 2024, 8, 342. [CrossRef]
- Alqefari, S.; Menai, M.E.B. A Hybrid Method to Solve the Multi-UAV Dynamic Task Assignment Problem. Sensors 2025, 25, 2502. [CrossRef]
- Ghauri, S.A.; Sarfraz, M.; Qamar, R.A.; Sohail, M.F.; Khan, S.A. A Review of Multi-UAV Task Allocation Algorithms for a Search and Rescue Scenario. J. Sens. Actuator Netw. 2024, 13, 47. [CrossRef]
- Ratnabala, L.; Fedoseev, A.; Peter, R.; Tsetserukou, D. MAGNNET: Multi-Agent Graph Neural Network-based Efficient Task Allocation for Autonomous Vehicles with Deep Reinforcement Learning. arXiv 2025, arXiv:2502.02311. [CrossRef]
- Durand, N.; Gianazza, D.; Gotteland, J.B.; Alliot, J.M. Metaheuristics for Air Traffic Management; John Wiley \& Sons: Hoboken, NJ, USA, 2015. [CrossRef]
- Skaltsis, G.; Shin, H.S.; Tsourdos, A. A Review of Task Allocation Methods for UAVs. J. Intell. Robot. Syst. 2023, 109, 76. [CrossRef]
- Li, T.; Shin, H.S.; Tsourdos, A. Threshold Greedy Based Task Allocation for Multiple Robot Operations. arXiv 2019, arXiv:1909.01239. [CrossRef]
- Pawełek, A.; Lichota, P. Tactical and strategic air traffic sequencing with minimum-fuel trajectories. J. Theor. Appl. Mech. 2025, 63, 27-36. [CrossRef]
- Liu, D.; Dou, L.; Zhang, R.; Zhang, X.; Zong, Q. Multi-Agent Reinforcement Learning-Based Coordinated Dynamic Task Allocation for Heterogenous UAVs. IEEE Trans. Veh. Technol. 2022, 72, 4372-4383. [CrossRef]
- Choudhury, S.; Gupta, J.K.; Kochenderfer, M.J.; Sadigh, D.; Bohg, J. Dynamic Multi-Robot Task Allocation under Uncertainty and Temporal Constraints. arXiv 2020, arXiv:2005.13109. [CrossRef]
- Rinaldi, M.; Wang, S.; Geronel, R.S.; Primatesta, S. Application of Task Allocation Algorithms in Multi-UAV Intelligent Transportation Systems: A Critical Review. Big Data Cogn. Comput. 2024, 8, 177. [CrossRef]
- Kurdi, H.A.; Aloboud, E.; Alalwan, M.; Alhassan, S.; Alotaibi, E.; Bautista, G.; How, J.P. Autonomous task allocation for multi-UAV systems based on the locust elastic behavior. Appl. Soft Comput. 2018, 71, 110-126. [CrossRef]
- Ghassemi, P.; Chowdhury, S. Decentralized Task Allocation in Multi-Robot Systems via Bipartite Graph Matching Augmented with Fuzzy Clustering. arXiv 2018, arXiv:1807.07957. [CrossRef]
- Liu, R.; Seo, M.; Yan, B.; Tsourdos, A. Decentralized task allocation for multiple UAVs with task execution uncertainties. In Proceedings of the 2020 International Conference on Unmanned Aircraft Systems (ICUAS), Athens, Greece, 1-4 September 2020; pp. 271-278. [CrossRef]
- Tereshchuk, V.; Stewart, J.; Bykov, N.; Pedigo, S.; Devasia, S.; Banerjee, A.G. An Efficient Scheduling Algorithm for Multi-Robot Task Allocation in Assembling Aircraft Structures. arXiv 2019, arXiv:1902.08905. [CrossRef]
- Sujit, P.B.; Beard, R. Distributed Sequential Auctions for Multiple UAV Task Allocation. In Proceedings of the 2007 American Control Conference, New York, NY, USA, 9-13 July 2007; pp. 3955-3960. [CrossRef]
- Chen, Y.; Chen, R.; Huang, Y.; Xiong, Z.; Li, J. Distributed Task Allocation for Multiple UAVs Based on Swarm Benefit Optimization. Drones 2024, 8, 766. [CrossRef]
- Xiao, K.; Lu, J.; Nie, Y.; Ma, L.; Wang, X.; Wang, G. A Benchmark for Multi-UAV Task Assignment of an Extended Team Orienteering Problem. arXiv 2020, arXiv:2009.00363. [CrossRef]
- Eser, M.; Yılmaz, A. Distributed Task Allocation for UAV Swarms with Limited Communication. Sak. Univ. J. Comput. Inf. Sci. 2024, 7, 187-202. [CrossRef]
- Zhang, Z.; Jiang, J.; Xu, H.; Zhang, W.A. Distributed dynamic task allocation for unmanned aerial vehicle swarm systems: A networked evolutionary game-theoretic approach. Chin. J. Aeronaut. 2024, 37, 182-204. [CrossRef]
- Raja, S.; Habibi, G.; How, J.P. Communication-Aware Consensus-Based Decentralized Task Allocation in Communication Constrained Environments. IEEE Access 2022, 10, 19753-19767. [CrossRef]
- Yue, W.; Zhang, X.; Liu, Z. Distributed cooperative task allocation for heterogeneous UAV swarms under complex constraints. Comput. Commun. 2025, 231, 108043. [CrossRef]
- Cao, M.; Nguyen, T.M.; Yuan, S.; Anastasiou, A.; Zacharia, A.; Papaioannou, S.; Kolios, P.; Panayiotou, C.G.; Polycarpou, M.M.; Xu, X.; et al. Cooperative Aerial Robot Inspection Challenge: A Benchmark for Heterogeneous Multi-UAV Planning and Lessons Learned. arXiv 2025, arXiv:2501.06566. [CrossRef]
- Johnson, L.; Ponda, S.; Choi, H.L.; How, J.P. A Consensus-Based Approach for Task Allocation in Dynamic Multi-UAV Teams. In Proceedings of the AIAA Guidance, Navigation and Control Conference, Chicago, IL, USA, 10-13 August 2009. [CrossRef]
- Bertsekas, D.P. Linear Network Optimization: Algorithms and Codes; MIT Press: Cambridge, MA, USA, 1991.
- Zavlanos, M.M.; Spesivtsev, L.; Pappas, G.J. A distributed auction algorithm for the assignment problem. In Proceedings of the 2008 47th IEEE Conference on Decision and Control, Cancun, Mexico, 9-11 December 2008; pp. 1212-1217. [CrossRef]
- Mendoza, B.; Vidal, J.M. On bidding algorithms for a distributed combinatorial auction. Multiagent Grid Syst. 2011, 7, 101-120. [CrossRef]
- Vidal, J.M. Bidding algorithms for a distributed combinatorial auction. In Proceedings of the 6th International Joint Conference on Autonomous Agents and Multiagent Systems, Honolulu, HI, USA, 14-18 May 2007; ACM: New York, NY, USA, 2007; pp. 149-156.
- Tovey, C.; Lagoudakis, M.G.; Jain, S.; Koenig, S. The Generation of Bidding Rules for Auction-Based Robot Coordination. In Multi-Robot Systems. From Swarms to Intelligent Automata Volume III; Parker, L.E., Schneider, F.E., Schultz, A.C., Eds.; Springer: Dordrecht, The Netherlands, 2005; pp. 3-14.
- Fang, Z.; Ma, T.; Huang, J.; Niu, Z.; Yang, F. Efficient Task Allocation in Multi-Agent Systems Using Reinforcement Learning and Genetic Algorithm. Appl. Sci. 2025, 15, 1905. [CrossRef]
- Foerster, J.N.; Farquhar, G.; Afouras, T.; Nardelli, N.; Whiteson, S. Counterfactual Multi-Agent Policy Gradients. In Proceedings of the AAAI Conference on Artificial Intelligence, New Orleans, LA, USA, 2-7 February 2018; Volume 32.
- Lowe, R.; Wu, Y.; Tamar, A.; Harb, J.; Abbeel, P.; Mordatch, I. Multi-Agent Actor-Critic for Mixed Cooperative-Competitive Environments. In Proceedings of the 31st Conference on Neural Information Processing Systems (NIPS 2017), Long Beach, CA, USA, 4-9 December 2017; pp. 6379-6390.
- Zhang, K.; Yang, Z.; Başar, T. Multi-Agent Reinforcement Learning: A Selective Overview of Theories and Algorithms. In Handbook of Reinforcement Learning and Control; Springer: Cham, Switzerland, 2021; pp. 321-384. [CrossRef]
- Qin, W.; Sun, Y.N.; Zhuang, Z.L.; Lu, Z.Y.; Zhou, Y.M. Multi-agent reinforcement learning-based dynamic task assignment for vehicles in urban transportation system. Appl. Soft Comput. 2021, 111, 107676. [CrossRef]
- Yu, C.; Li, M.; Wang, Z.; Jiang, J.; Cai, Q.; Lu, Z. The Surprising Effectiveness of PPO in Cooperative Multi-Agent Games. arXiv 2021, arXiv:2103.01955.
- Papoudakis, G.; Christianos, F.; Albrecht, S.V.; Gross, R. Benchmarking Multi-Agent Deep Reinforcement Learning Algorithms in Cooperative Tasks. In Proceedings of the 35th Conference on Neural Information Processing Systems (NeurIPS 2021) Track on Datasets and Benchmarks, Online, 6-14 December 2021.
- Dulac-Arnold, G.; Mankowitz, D.; Hester, T. Challenges of Real-World Reinforcement Learning. arXiv 2019, arXiv:1904.12901. [CrossRef]
Disclaimer/Publisher's Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content.