Deep Reinforcement Learning in Wargaming¶
Giacomo Del Rio 和 Oleg Szehr 和 Alessandro Antonucci 和 Marco Pierbattista
Dalle Molle 人工智能研究所 (IDSIA) - SUPSI/USI, Via la Santa 1, Lugano-Viganello, 6962, Ticino, Switzerland
Matthias Sommer 和 Michael Rüegsegger
瑞士国防部科技中心 (Armasuisse Science & Technology), Feuerwerkerstrasse 39, Thun, 3602, Bern, Switzerland
摘要¶
我们研究了深度强化学习(Deep Reinforcement Learning, Deep RL)在开发自主兵棋推演智能体(Agent)方面的潜力。我们讨论了兵棋推演环境对于学习系统设计、学习框架和算法选择的相关特征。虽然深度强化学习已在各种游戏中被证明达到了超越人类的水平,但我们认为这些发现只能部分地转移到实际兵棋推演中。这是由于现实世界的限制,如财务和数据资源的可用性,以及在兵棋推演领域可能很少满足的系统架构要求。现代战争模拟环境的高度真实性通常伴随着系统延迟,导致训练时间不切实际。为了进行实证分析,我们将各种深度强化学习技术应用于流行的 Command: Modern Operations (CMO) 模拟环境,为该环境中的深度强化学习训练应用提供了概念验证。
一、引言¶
在国防建模与仿真领域,兵棋推演是一种被广泛接受的技术,可用于作战规划、人员培训、采购等[1]。兵棋推演提供了安全的试错环境,用于探索国防场景,识别哪些行动方案(CoA)导致胜利/成功,哪些导致失败/失败,通常比现实世界调查成本更低[2]。然而,传统的兵棋推演(即军事规划人员与人类对手竞争,即所谓的红队操作员)面临重大限制。因果追踪具有挑战性,结果往往取决于人类专家的主观评估。红队对既定战术和程序的典型依赖很快导致行动方案过度受限。探索更广泛的行动方案受到财务和人力资源可用性的限制。在现实世界场景和复杂模拟(以连续时空坐标、大分支因子、高系统延迟、地理分散计算和其他特征为特征)中,相对较少的已探索行动方案为整体偏向性和脆弱的决策留有空间。
近年来,自动化[3]、特别是分布式交互仿真(Distributed Interactive Simulation)[4]和人工智能(Artificial Intelligence, AI)[5]的集成显著增强了兵棋推演的能力,支持实时决策、探索更多样化和自适应的场景,以及在分散计算资源中集成计算。在这些技术中,深度强化学习(Deep RL)显示出最有前景的结果。这些增强型 AI 方法扩大了兵棋推演的战略范围,使从网络防御[6]到国际关系[7]等领域的复杂自适应场景分析成为可能。
国防模拟中越来越多使用的工具之一是 Command: Modern Operations(CMO),这是一种具有专业级功能的商用兵棋推演平台。CMO 是一款战争视频游戏,玩家在各种冲突场景中担任任务指挥官。CMO 提供全球卫星地图、广泛的军事资产、高保真物理动力学和逼真的传感器建模。其专业版包含专门为满足国防机构的作战和分析需求而设计的高级功能。这包括使用真实世界参数配置军事资产、(蒙特卡洛)模拟引擎用于战斗场景统计分析,以及提供直接访问游戏内部状态的应用程序编程接口(API)。总体而言,CMO 的高度真实性使其成为可靠场景分析和兵棋推演的自然选择。图 1 展示了一个在 CMO 中模拟的兵棋推演场景。
 图 1 在 CMO 中模拟的兵棋推演场景。
图 1 在 CMO 中模拟的兵棋推演场景。
我们的目标包括评估在 CMO 背景下应用深度强化学习的可行性,分析和发现利用现有能力改善作战结果的方法,以及应用新能力来确定采购优先级。这项工作源于 Dalle Molle 人工智能研究所(IDSIA)与瑞士国防部技术中心(Armasuisse S+T)之间的合作。
论文结构如下。第二节回顾了深度强化学习应用于兵棋推演的当前文献。第三节描述了兵棋推演在深度强化学习应用方面的主要阻碍因素。第四节讨论了在兵棋推演情况下定义有效深度强化学习算法的设计选择。第五节介绍了 CMO 模拟软件以及我们实现的更轻量的替代方案 war-sim。第六节,我们将我们的发现应用于 CMO 和 war-sim 中的简单兵棋推演场景。我们报告了 CMO 和 war-sim 中不同强化学习方案的训练性能。结论和展望在第七节。在附录中,我们收集了传统搜索算法(附录 A)、强化学习(附录 B)和深度强化学习(附录 C)的背景概念,以及关于为给定兵棋推演选择最合适强化学习算法的讨论(附录 D)。
二、相关工作¶
我们研究了开发用于分析防空场景的自主智能体的可能性,这是 CMO 具有独特模拟能力的领域。我们的工作属于更广泛的研究路线,目标是开发用于兵棋推演的 AI(参见调查 [3, 5, 8, 9])。然而,只有少数研究小组,如 DARPA 和诺斯罗普·格鲁曼公司[10],以及塞切尼伊斯特万大学[11],专注于 CMO 智能体的实际开发。
深度强化学习,即结合深度学习技术的强化学习(RL),特别是神经网络(NN)的训练,最近已成为创建游戏 AI 智能体的最先进方法。在足够数据的条件下,深度学习系统可以学习复制并在某些情况下超越各种游戏领域的人类水平性能[12, 13]。值得注意的是,DeepMind 将深度强化学习应用于 Atari 游戏[14]表明,智能体可以从零开始(白板)学习复杂的控制任务,无需先验知识或专家演示。现代深度强化学习系统通常在训练过程中结合数据生成和深度学习技术。训练通常从随机生成的行动方案开始,由深度学习系统评估和改进。随着训练进展,系统越来越多地将未来样本生成偏向更有效的行动方案,从而创建一个反馈循环,模型和数据迭代改进。这种方法消除了手动策划的人类游戏数据的需求,并解除了对训练体验数量和质量的所有约束。因此,深度强化学习智能体在各种控制和协调任务中超越了人类表现——包括基于原始像素输入的 Atari 游戏[14, 15]、无人机竞速[16]、赛车模拟[17]和通用基准[18]。深度强化学习智能体还在组合规划问题(如国际象棋或围棋)中超越了人类战术和战略能力[19]。在综合控制和战略任务(实时游戏的典型)中,深度强化学习系统(经过监督预训练)显示出相当大的潜力,在 Dota 2[20] 和星际争霸 2[21] 中达到/超越人类水平。这些环境与现代兵棋推演有相当大的相似之处,这促使我们在 CMO 背景下研究深度强化学习。在国防领域,深度强化学习已被应用于众多模拟问题,从空中战斗[22, 23]到目标跟踪[24, 25],再到兵棋推演应用[26, 27]。
据我们所知,除本研究外,唯一关于深度强化学习算法应用于 CMO 的已发表工作在[11]中介绍,其中仅使用了 PPO 算法。相比之下,我们的研究探索了更广泛的算法,从而能够与 CMO 引擎进行更复杂的集成。
三、阻碍强化学习应用于兵棋推演的因素¶
让我们首先讨论设计强化学习求解场景时应考虑的兵棋推演特征。现代兵棋推演通常旨在准确反映现实世界的战争场景,包括战术和作战层面。不可避免的抽象被定位为在兵棋推演目标的前提下保留现实世界场景的主要特征。将深度强化学习应用于现实世界场景面临特定挑战,包括从少量可用样本学习的能力、处理具有部分可观测性的高维状态和动作空间的能力,以及物理系统限制(如系统延迟和系统故障)[28]。此外,导致现实世界深度强化学习复杂性的多数挑战也应在兵棋推演中以类似形式出现。通常,这使得兵棋推演成为非常复杂的环境,构建强大的人工智能玩家成为一项具有挑战性的工作。在下文中,我们总结了现代计算机辅助兵棋推演在深度强化学习技术应用方面的阻碍因素。
A. 状态空间(State Space)¶
状态空间是游戏可能达到的所有可能状态的集合。状态空间的大小有助于确定游戏树的大小及其复杂性。对于国际象棋和围棋,估计可能的位置分别为 10^47 和 10^170。在具有连续变量的现实世界场景中(如单位坐标、速度、航向角度等),状态空间在技术上是无穷的。因此,真实的兵棋推演超出了穷尽计算的范围(但它们仍然是有限的,因为二进制计算机只能采取有限数量的状态)。一个常见的简化假设是价值函数(Value Function,即,将游戏的预期结果分配给当前状态的函数)是局部连续的:对于国际象棋和围棋这样的组合游戏,棋子的精确位置至关重要,即使是很小的变化也可能对游戏结果产生剧烈影响。相比之下,兵棋推演中的价值函数对连续变量往往不太敏感。例如,移动资产 1 厘米通常对多资产行动的结果影响很小。这种现象存在局限性,例如当离开护盾或阵地时,即使是很小的差距也不行。
† 游戏树(Game Tree)[29]定义为可到达的所有可能状态的图表示,在确定游戏复杂性方面发挥着关键作用。游戏树越大,游戏通常对计算方法越困难,从经典搜索到现代深度强化学习。
B. 动作空间(Action Space)¶
动作空间包含在游戏过程中可以执行的所有可能动作,这是评估游戏复杂性的另一个重要因素。对于围棋,动作空间大小为 361(对应 19×19 的棋盘)。对于具有连续选择的现实世界场景,动作空间在技术上是无穷的。在兵棋推演中,动作空间通常由连续和离散选择的组合组成。例如,可以选择地图上的(连续)位置或决定可发射导弹的(离散)数量。
C. 分支因子(Branching Factor)¶
分支因子是从给定状态可以到达的连续状态的数量。对于确定性游戏,分支因子受可能的动作限制,即动作空间的大小。在存在随机性(Stochasticity)或不完美信息(Imperfect Information,见下文)的情况下,分支因子可能要大得多。在这种情况下,某个动作可能会产生多个行动方案,必须在决策时考虑这些方案。兵棋推演中的分支因子可能非常大。例如,对于星际争霸,估计每轮动作总数约为 10^26[21]。
D. 规划视野(Planning Horizon)¶
游戏中执行的动作数量是游戏树的深度。通常,游戏树大小对动作数量的依赖是指数级的,使得穷尽计算即使对于中等数量的动作也是不可行的。因此,通常为算法引入规划视野(Planning Horizon),反映算法规划的最大深度。规划视野末尾的状态通常由启发式方法评估,例如传统 α/β 搜索(Alpha-Beta Search)中针对国际象棋的定制位置评估函数,或 AlphaZero 算法中的训练神经网络(Neural Network)。对于离散时间游戏,可以在对局完成后计算动作数量。对于连续时间游戏,通常引入_tick 频率_和每个_tick 的固定动作数量来离散化时间坐标。使用对人类输入频率的合理估计,这很容易导致现代兵棋推演的动作总数达到 10^4 量级[21]。
E. 随机性(Stochasticity)¶
在强化学习中,随机性(Stochasticity)是指在已知状态下执行给定动作的结果相关的随机程度[30]。这发生在状态转换取决于玩家选择和随机过程的游戏中,如轮盘赌的转动。在随机游戏中,玩家面临行动方案结果及其概率分布的考量。观察空间(Observation Space)是指玩家可见并确定知道的状态部分。如果观察仅限于游戏状态的一部分,智能体则面临不完美信息(Imperfect Information)。这种不完美意味着即使整体游戏动态是确定性的,也会产生(从玩家角度来看)随机结果。此外,在信息论中,通常将任何形式的随机性解释为更大系统的部分观察到的确定性行为的结果。例如,与随机游戏类似,在纸牌游戏中,玩家将对未知状态分配概率,其中自己的手牌可见但其他玩家的手牌不可见。在兵棋推演中,"战争迷雾"(Fog of War)通常用于描述不完美信息的常见来源,例如玩家可能只能看到己方单位和视线内的敌方单位。随机性增加了游戏的复杂性,因为给定状态-动作对的多重可能性对应于更大的分支因子。这导致了"悖论"特性,即更小的观察空间使游戏更加复杂。
国防组织的层级中存在不同级别的信息和决策权威。从低层级到高层级的转变伴随着信息抽象过程,从战场上的单个单位观察到指挥官层级的战略位置、武装力量的实力和状况。现实世界冲突中没有统一的不完美信息概念。相反,信息通过许多层的通信和处理进行过滤。因此,"战争迷雾"的形式、作用和影响在层级内部有所不同,这对于 AI 系统的设计至关重要。然而,这大大影响了强化学习算法的选择。目前,支持信息过滤的兵棋推演数量有限。
最后值得一提的是不完全信息的概念。这是缺乏关于对手目标的知识,而不是缺乏关于游戏状态的知识(不完美信息的情况)。在现实世界国防场景中,敌方目标是一个重要考虑因素。敌对行动可能服务于直接目标,但也可能是为在其他地方实现战略目标的佯攻。尽管其重要性,但在兵棋推演中很少出现不完全信息。作为一个例子,Hasbro 的 Riser 游戏是一款广泛玩的兵棋推演,具有随机性和完美但不完整的信息。
F. 动机¶
兵棋推演的高复杂性、其游戏树的大小以及资源限制方面的不可避免的限制,使得开发通用游戏智能体(类似于 AlphaStar)变得不切实际。应该考虑预设场景。深度强化学习智能体应在特定场景和对手玩法风格中进行训练(即过度拟合场景和策略)。然而,对指定场景和策略的分析具有相当的价值,详细说明如下四点。
- 智能体可以在中等资源下进行训练。这允许对时间关键场景进行在线评估,监控超越人类数量的潜在行动方案。
- 在非时间关键场景中,例如红队对抗,人工智能体可以覆盖更广的行动方案深度和广度。让蓝队操作员面对意外情况使他们能够改进策略。
-
在采购项目中,可以在特定战斗场景中模拟不同资产的表现,以决定其对武装力量的价值。基于人工智能的模拟增加了可变性,提高了分析的稳健性。
-
更广泛地说,部署人工智能智能体是迈向自动化和节约成本的一步。人工智能智能体可以在兵棋推演平台上承担角色,从而释放人力资源。
在下一节中,我们将讨论如何通过强化学习实际实现这一目标。
四、强化学习在兵棋推演环境中的应用¶
在本节中,我们讨论如何通过专门的算法和设计选择来应对上一节强调的将强化学习应用于兵棋推演场景的挑战。
让我们首先介绍一些基本概念。强化学习是一种迭代过程,智能体通过与环境的交互来学习积累奖励[31]。学习过程通常组织在几个独立的训练回合中,每个回合由智能体-环境交互组成。每个回合对应智能体任务的完整执行,例如从头到尾玩一局游戏。在每个回合的每次交互中,智能体考虑当前环境状态并执行相应的动作。环境随后转换到连续状态,授予智能体奖励。奖励在整个回合中累积。虽然环境的行为可以是随机的,但主要的底层假设是存在一个固定的概率,决定环境在不同交互中的转换和奖励。强化学习的主要思想是,在运行多个回合后,智能体适应环境的转换概率,学习最大化累积奖励。在双人游戏如国际象棋中,主动玩家扮演智能体的角色,而棋盘上的位置对应环境状态。从智能体的角度来看,对手的动作对应环境的转换。主要的底层假设被定义为马尔可夫性,表明所选动作取决于当前游戏状态(棋盘上的位置),但不取决于这个位置是如何出现的。
以下是将强化学习应用于给定场景时需要做出的设计选择的讨论。
A. 奖励(Rewards)¶
奖励信号(Reward Signal)描述了回合(Episode)期间授予的奖励序列和数量。底层强化学习任务决定了奖励信号的结构。一些简单的游戏有即时奖励(Immediate Reward),即动作的后果在其执行后直接变得明显。复杂游戏(如国际象棋和围棋)通常有回合奖励(Episodic Reward),只有在终止时才对整个决策序列进行评估(授予例如 1/0/-1 的胜负/平局奖励)。在真实兵棋推演的情况下,奖励信号由即时和回合奖励组成。换句话说,采取关于即时后果(立即奖励)次优的动作以获得更好的整体结果(更高的累积奖励)可能是有利的。在兵棋推演中,这可能发生在单位被牺牲以实现任务目标时。通常,当回合包含大量可能的行动方案时,从稀疏的行动方案空间中很难学习回合奖励信号。从工程的角度来看,通常可以灵活设计奖励信号以促进学习。例如,可以提供当前的棋子数量以促进国际象棋学习。在兵棋推演中,可以为完成子目标分配奖励,例如攻占敌方阵地。一方面,设计信息丰富的奖励信号可能是成功学习的先决条件。然而,对奖励信号的任何手动干预都会带来可能遗漏重要行动方案的偏见。一个常见且可取的方法是在训练开始时使用设计的即时奖励信号,然后随着训练的进行逐步转向回合奖励。
B. 探索与利用(Exploration & Exploitation)¶
为了学习,智能体必须获取知识,这些知识可以表示为给定状态和动作的奖励统计。这引出了一个自然的问题:智能体应该选择一个有利可图的动作还是尝试次优动作以锐化其统计估计?这个 dilemma 是强化学习的核心,有大量文献专门讨论其变体[31]。探索与利用之间的权衡存在于每个游戏树节点。由于其指数级大小,即使来自次优探索的微小损失也会显著影响训练结果。因此,对于复杂的兵棋推演,接近最优的探索至关重要,应尽可能实现。
C. 基于模型与无模型(Model-Based vs Model-Free)¶
无模型(Model-Free)强化学习智能体不了解其环境,仅从奖励信号(Reward Signal)学习[31]。它们面临的情况是动作连续执行,唯一可用的信息是观察到的状态、动作和奖励序列。相比之下,基于模型(Model-Based)的强化学习智能体拥有其环境的模型(即状态-动作-状态-奖励概率),允许它们在采取动作之前规划奖励结果。在实践中,更常见的是从环境中采样,而不是使用完整的环境模型。毫无疑问,使用额外环境模拟器的基于规划的方法学习更好的动作更快,达到比最佳无模型方法更高的性能。应该提到的是,下棋、围棋和星际争霸的头部智能体(AlphaZero、AlphaStar)是基于模型的。它们通过自我对弈(Self-Play)进行训练,其中另一个版本的学习智能体扮演环境模拟器的角色。粗略地说,为了规划其动作,AlphaZero 在虚拟棋盘上执行试探性移动,并考虑在出现的局面中它会如何回复。将基于模型的强化学习应用于兵棋推演是否可行和有益是开发强化学习方法的主要区别。目前,我们提到训练基于模型的智能体需要实例化游戏引擎的许多副本来分析有前景的行动方案。这通常需要比无模型方法更复杂的软件基础设施。
D. 训练(Training)¶
许多强化学习算法具有强大的收敛保证。例如,参见[32]中无模型 Q 学习(Q-Learning)和[33]中基于模型蒙特卡洛树搜索(Monte Carlo Tree Search, MCTS)的结果。然而,在没有先验信息的情况下训练复杂游戏的强化学习智能体(所谓的白板学习,Tabula Rasa)需要巨大的计算成本。深度强化学习将强化学习与深度学习技术相结合,以改善表示、泛化和更快的评估。在实践中,这通常会导致性能和收敛速度的显著提升。然而,对于复杂游戏,计算成本可能仍然不切实际,并且收敛保证会丢失(因为训练可能陷入糟糕的局部最优)。将白板算法 AlphaZero 应用于国际象棋和围棋的一次训练周期成本估计约为 25 万美元[9]。
星际争霸可以作为具有连续状态和动作空间的兵棋推演的参考点。AlphaStar 智能体在白板训练时表现仅为中等[21]。主要障碍在于训练过程的开始。如果智能体在复杂游戏中执行随机动作,结果将以压倒性的概率失败。在所有这些情况下,智能体收到相同的奖励,但没有获得知识的增长。监督预训练(Supervised Pre-training)是克服这一障碍的常用方法[34]。基于(人类)专家指导的纯监督学习可以在许多游戏中取得卓越表现,包括国际象棋、围棋和星际争霸。然而,监督学习受限于可用数据的数量和质量[35]。一旦数据耗尽,强化学习可以微调和改进预训练的智能体(例如,在星际争霸中达到超越人类的表现)。如果没有数据,有时可以通过在训练过程中调整奖励信号来克服入门障碍。对于许多兵棋推演,从专家对局获取足够的数据可能很困难。在这种情况下,可以基于资产数量开始训练,并在达到特定强度后才切换到回合任务级奖励。
与监督学习的情况一样,深度强化学习系统存在过拟合(Overfitting)的风险。对于兵棋推演,这可能出现在智能体"记住"完成给定任务的动作序列但在其他情况下表现不佳时。一种更微妙的过拟合形式是智能体适应特定类型对手或特定场景的战术和策略。这样的智能体受限于其行动方案的多样性,容易被更多样化的智能体利用[36]。
E. 兵棋推演是慢环境¶
兵棋推演起源于将强化学习应用于研究国防场景遥不可及的时代。其演进侧重于游戏行业的实时游戏体验,以及国防领域的模拟和准确性。从强化学习角度来看,模拟延迟和访问游戏内部操作是关键技术特性,但这在开发中关注较少。从强化学习角度来看,这通常使兵棋推演成为慢环境。
在现代兵棋推演中,训练过程包括评估大量(通常在数十亿量级)游戏状态并执行类似数量的动作。这使得快速访问游戏内部状态和精简的游戏动态实现变得至关重要。这导致了准确性与速度之间的权衡,更高的模拟准确性使环境更真实,但学习更困难。因此,兵棋推演 AI 的最佳性能(按兵棋推演的目标衡量)可以在相对准确但仍然足够快的中间环境中预期。模拟准确性高级学习技术之间的微妙权衡仍然是商业兵棋推演设计中的一个关键未解决问题。
除了兵棋推演,慢环境对现实世界强化学习构成共同挑战[28]。高环境延迟的常见原因包括物理限制,例如训练机器人[37],或奖励信号中的内在延迟,例如推荐系统,其中真正的奖励基于用户的接受[38]。解决迟缓的两种重要技术是数据存储和简化虚拟环境的应用。存储数据意味着所有训练回合的结果都被保存并重用于后续训练周期的初始化。虚拟环境模拟器应捕捉实际环境的主要方面,但允许显著更快的执行。想法是首先在虚拟环境中训练智能体,然后在真实环境中对其进行微调,参见[39]在兵棋推演中的应用。这两种技术与监督预训练密切相关,因为它们旨在"预热"学习机器以克服强化学习入门障碍。
F. 状态访问与动作执行¶
兵棋推演的复杂性也使其容易出现系统崩溃和其他形式的不稳定性。即使错误发生频率低到对人类游戏体验没有影响,但对强化学习的影响可能是 substantial。兵棋推演通常是商业软件工具,这意味着对游戏内部状态的访问有限,开发更快访问选项的机会有限,调试的机会也有限。最后,游戏状态访问和操作需要专门的 API,现成软件中可能不存在。
基于模型的强化学习系统(如 MCTS 及其衍生 AlphaZero)在动作执行前创建前瞻规划树来评估后果。为了生成规划树,算法在多个环境副本上遍历状态和动作序列。这需要维护兵棋推演的许多副本以及以非连续方式浏览规划树的能力,在不同时间实例之间跳转。跳转到非连续状态意味着必须在特定状态下加载游戏,这引入了额外的延迟,这可能成为将此类方法应用于兵棋推演的瓶颈。最后,应该提到的是,基于规划的方法特别容易受到系统不稳定性的影响。为了避免并行过程中的错误导致整个规划树丢失,错误处理和并行化机制必须在专门的软件架构中协调。
本节讨论的想法将指导我们模拟器的实验,下面介绍。
五、CMO 模拟环境¶
我们的实验基于 CMO 模拟器,它引起了国防相关专业人士和组织的高度兴趣[10]。让我们在这里报告其功能和特征的概述。
A. CMO 环境¶
CMO 的状态和动作空间包含连续和离散组件。资产可以具有离散特征(如携带弹药的数量、交战模式,即资产与敌人接触并进入战斗)和连续特征(地理位置和地形属性以及空间方向)。CMO 的游戏状态可以 XML 格式写出,简单场景的叶子节点数量级(OOM)约为 1,000。可用动作包括将资产导航到世界地图的任何坐标(连续)和弹药选择(离散)。其他可能的动作类型包括为单元分配新任务、打开或关闭可探测发射(如声纳或雷达,辐射控制)、返回基地、攻击等。可以向游戏引擎发出十个数量级的主要动作类型。
总体而言,CMO 的环境特征与复杂的星际争霸环境相似。两个环境在状态和动作空间中都包含离散和连续组件、连续时间、各种复杂单元的可用性、存在取决于单位视线的随机性和不完美信息以及许多其他特征。像星际争霸一样,将坐标粗略离散化为 360×360 经纬度网格导致非常高的分支因子(星际争霸估计为 10^26)。
CMO 使用物理精确的动力学模拟资产运动。例如,火箭运动基于考虑火箭重量和燃料的物理能量模型。CMO 中存在各种随机来源。玩家在场景开始时面临关于敌方单位位置和能力的不完美信息。如果敌方单位可见,其能力可能只是部分已知。游戏环境也是随机的:一个单位对另一个单位造成的伤害以及敌方单位探测机制(如雷达的实现)具有随机性,这影响了观察空间的大小。还存在关于对手任务目标的不确定性,即 CMO 可能携带不完整的信息。
B. CMO 高级功能¶
CMO 的专业版提供高级功能,如数据库编辑访问、战斗场景统计分析和增强的 TCP/IP LUA 脚本 API(LUA-API),提供对模拟引擎的访问。LUA-API 提供与 CMO 游戏状态和核心引擎的直接交互,例如启动/停止模拟和保存/恢复模拟状态。数据库编辑能够创建新资产并使用真实参数配置现有资产。内部 AI 引擎控制资产行为并提供基本资产能力和交互动态:根据我们的观察,这个 AI 似乎执行随机和基于规则的例程组合。专业版还支持用于多方冲突分析的多人模式。
C. CMO 作为慢环境¶
从深度强化学习的角度来看,CMO 是一个慢环境。这指的是连续动作的执行、给定状态的加载和整个游戏引擎的实例化。我们测量了通过 LUA-API 执行连续动作的延迟数量级为 1 秒。如果假设无模型强化学习在基准环境中的延迟[40, 41],这将导致在 6×9 网格世界中训练 Q 学习智能体约需 10 分钟,以及山地车基准[42]约需 1.5 小时[40]。这是假设最佳超参数(即无超参数调整)。基于模型的强化学习使用前瞻规划。频繁跳转到指定游戏状态是这种规划形式的固有特性。CMO 的 API 支持通过保存和恢复游戏状态进行游戏内状态转换;我们测量此过程延迟约为 1 秒。这使得在基于模型的强化学习中构建复杂规划树需要大量资源。在硬件资源有限的慢环境中,无模型或基于模型的方法是否能达到更高性能并不明显。
D. 训练过程¶
CMO 与星际争霸的相似性表明这两个环境可能具有相似的强化学习特性。因此,人们可能期望在训练过程中遇到类似的挑战,并在 CMO 中也利用 AlphaStar 的训练方案。然而,我们出于各种原因放弃使用 AlphaStar 型架构。首先,上述与 CMO API 缺乏稳定性相关的问题。其次,监督预训练在 AlphaStar 的训练过程中发挥了重要作用,而我們没有可用的 CMO 数据。没有预训练, AlphaStar 达到约 150 ELO 的中等表现,而纯监督智能体约为 900 ELO[20]。我们预计预训练在 CMO 中也有类似作用。第三,训练 AlphaStar 需要巨大资源[20]:"AlphaStar 联赛运行了 14 天,每个智能体使用 16 个 TPU。在训练期间,每个智能体经历了多达 200 年的实时星际争霸游戏"。因此,我们决定训练两个无模型和一个基于模型的智能体,基于已建立的强化学习算法。我们为无模型智能体采用了 DQN 和 PPO 的变体。基于模型的智能体是 AlphaZero 算法的衍生品,其规划能力基于 MCTS。尽管上述算法已建立,但 CMO 环境的延迟和不稳定性需要并行化和错误捕获技术的定制开发。
E. 更简单更快的 CMO 替代方案¶
尽管缺乏预训练数据以及 CMO 的稳定性和速度问题,我们开发了一个名为 war-sim 的轻量级基于 Python 的兵棋推演模拟器。war-sim 的代码以及 MCTS 算法实现、连接各种强化学习算法的抽象层,以及重现本文最后部分讨论的实验的脚本可在公共仓库§免费获取。与 CMO 类似,war-sim 使用基于 CartoPy 包的制图学[43]的 3D 世界地图,并利用 geographiclib 包[44]的测地曲线计算资产运动。war-sim 中只有有限数量的资产可用,没有自主操作能力,动力学模型被简化到最低限度。尽管用 Python 编写,war-sim 比 CMO 快一个数量级。表 1 比较了 CMO 和 war-sim 的一些基本特征和环境延迟。
| 特征 | CMO | war-sim |
|---|---|---|
| 资产类型 | > 100 | 2(飞机、萨姆导弹阵地) |
| 物理动力学 | 精确 | 近似 |
| 集成 AI | 是 | 否 |
| 模拟步长时间 | ~1.5 秒 | ~0.1 秒 |
| 状态恢复时间 | ~0.1 秒 | ~0.001 秒 |
| 引擎启动时间 | ~15 秒 | ~0.1 秒 |
表 1 CMO 和 war-sim 主要特征的比较。
我们使用 war-sim 环境来测试强化学习算法选择,测量性能,并将模型设置和超参数转移到 CMO 环境。war-sim 的修改版本也被用于研究多智能体空中战斗场景[22]。
六、实验¶
现代兵棋推演通常结合控制和规划练习。在本节中,我们分析了深度强化学习在三个兵棋推演场景中的表现。尽管它们很简单,但这些场景旨在覆盖典型的兵棋推演情况。根据我们的讨论,PPO、DQN 和 AlphaZero 似乎是该应用的自然候选者。
A. 设计¶
我们考虑了简单的场景,旨在研究所选强化学习算法在互补设置中的学习潜力。理想情况下,性能应在以下场景范围内进行评估:1)控制场景,重点在于准确控制单个单位的运动;2)规划场景,评估智能体评估行动方案的能力;3)战斗场景,涉及规划和控制的组合。这些场景通常具有特征性的奖励信号。在控制场景中,可以在每个模拟步长后授予奖励(因为动作通常在执行后可以立即评估),而在规划场景中,奖励信号通常是稀疏和回合制的(因为行动方案的质量只能在若干模拟步长后才能评估)。因此,战斗型场景具有结合的奖励信号,反映控制和规划练习的个别贡献。
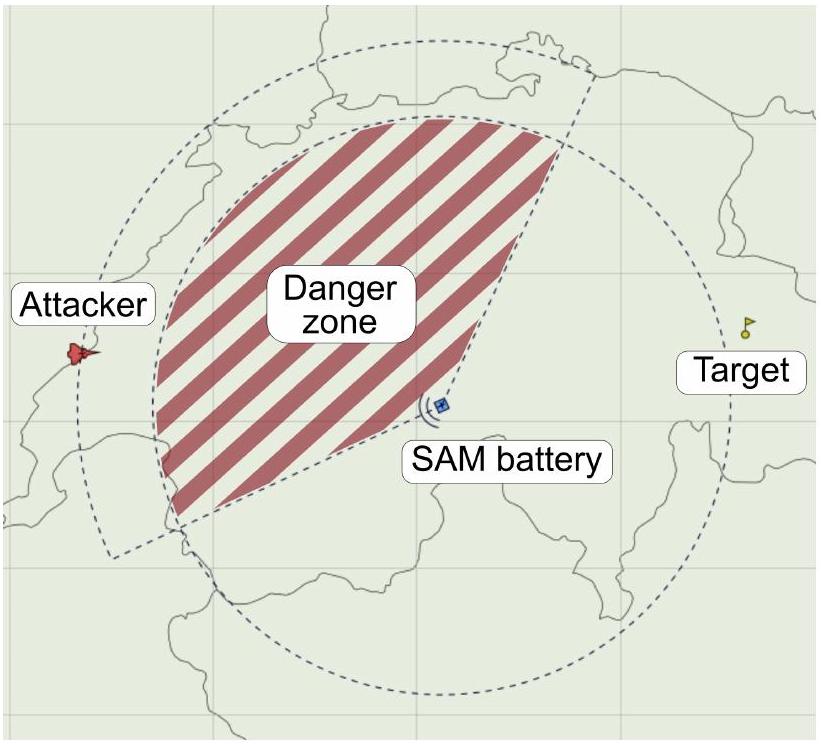
图 2 控制和规划场景:攻击者应到达目标并避开危险区域。
在控制场景中,攻击机收到命令到达给定目标坐标。在攻击者起点和目标坐标之间部署了一个地空导弹(SAM)阵地,如果攻击者进入 SAM 雷达和发射的锥形范围内,可以将其摧毁。攻击者无法向 SAM 阵地开火或使用任何对抗措施;目标是学会避开 SAM 阵地的危险雷达锥。最优策略很简单:就是飞一条避开 SAM 射程到达目标的路径。规划场景相同,但只向智能体授予回合奖励。战斗场景如图 3 所示,涉及三个单位:一架可以发射空对空(A2A)和空对地(A2L)导弹的攻击机,一个被动 SAM 阵地,以及一架主动防御机。SAM 阵地仅作为目标,不能开火。在这种情况下,防御机的行为是硬编码的:它巡逻目标,一旦攻击者出现在其雷达上,就攻击攻击者。
| 控制 | 战斗 | 规划 | |
|---|---|---|---|
| PPO | 是 | ? | ? |
| DQN | 是 | ? | ? |
| AlphaZero | 是 | 是 | ? |
表 2 根据文献,不同场景的学习算法预期收敛结果。
由于 PPO 和 DQN 在复杂控制场景上的性能在文献中有充分记录,我们在实验中省略了它们。表 2 总结了我们 war-sim 模拟器中每个场景/算法组合的预期收敛结果。该表中的正面发现对应于成功学习接近最优策略。
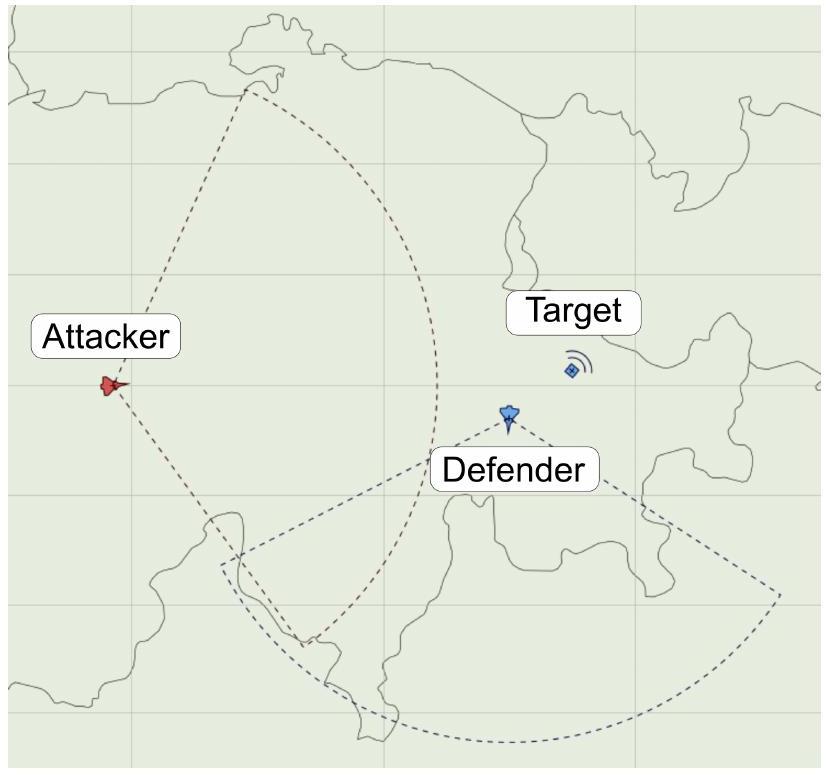
图 3 战斗场景:攻击者应摧毁目标。
为了评估模拟器属性如何影响整体学习过程,规划战斗场景在 CMO 和 war-sim 中实现为模拟器后端。出于这些实验的目的,war-sim 模拟器提供的环境动力学与 CMO 的偏差很小,但具有更低的环境延迟和更高的环境稳定性。尽管表 3 显示了 war-sim 的正面结果,但所有算法在直接 CMO 上执行时即使在简单场景中也遇到了困难。在讨论我们实验的启示之前,我们首先提供算法设计选择和配置的详细信息。
B. 环境特征与观察编码¶
CMO 和我们的复制品 war-sim 以约 0.1 秒到 1 秒的模拟时间步长推进模拟。如此细粒度的模拟将使所考虑强化学习算法的整体计算工作不切实际。因此,我们将模拟器的多个步骤聚合为一个强化学习学习步骤。更具体地说,对于规划场景,我们为强化学习的一个步骤设置 20 秒的模拟时间,而对于战斗场景,我们设置 15 秒。战斗场景的更细粒度允许攻击者优化导弹发射的时机。
我们后续的设计选择主要由场景几何形状和初步测试中观察到的结果驱动。观察以矩阵形式编码。对于控制和规划场景,我们将地图离散化为 100×100 的网格,并通过一个维度为 100 的包含攻击者位置单个 1 的方形矩阵编码攻击者。通过这种离散化,每个单元的边长约为 5 公里。该表示通过两个实数进行增强,编码飞机航向的正弦和余弦。战斗场景需要更复杂的编码。像以前一样,我们从零矩阵开始,然后根据以下规则填充:
- 对于每个资产,在单位位置放置具有特定形状的标记(参见图 4)。单位的高度决定标记的强度(填充值):高度越高,强度越高。
- 将连接每个移动单位最后四个位置的轨迹放置在网格上,并带有各自的高度编码。
- 在网格的左上角放置两个填充值为 0.5 的 3×3 方块,表示 A2L 或 A2A 导弹的可用性。
- 仅当攻击机执行错误发射动作时,即在没有可用目标在其雷达范围内时发射,才绘制一个填充值为 0.25 的 3×3 方块。
- 当单位被导弹击中时,在单位位置上方叠加一个 3×3 方块。
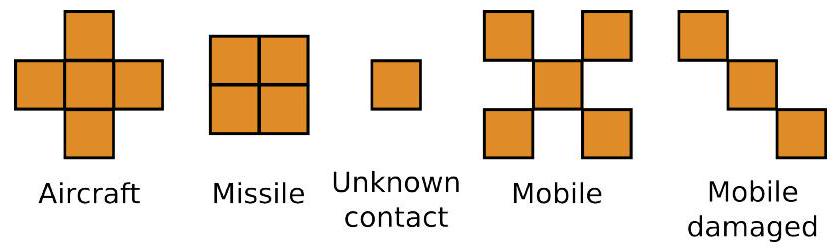
图 4 不同类型单位和接触的标记。
轨迹和标记对攻击方具有正值,而对防守方则反转(负值)。这种编码不仅包含模拟的当前状态,而且多亏了轨迹,还包含了之前观察的有限历史。一个示例如图 5 所示。
图 5 战斗场景中的观察编码(攻击机单位编码为绿色,防御机为橙色)。
C. 动作编码¶
算法可以直接选择的动作数量直接影响问题复杂性:动作越多,分支因子越大。为了减少整体计算工作量,我们选择解决问题所需的最少动作数量并不多。我们假设飞机的高度和速度是恒定的,并离散化其转弯角度。对于规划场景,我们假设飞机没有导弹,不能开火。在这种情况下,我们只考虑三个动作,分别对应左转 10°、右转 10° 和前进。对于战斗场景,我们另外考虑两个动作,对应发射 A2A 或 A2L 导弹。在这种情况下,攻击机拥有一枚 A2A 导弹和一枚 A2L 导弹。没有合适目标或没有可用弹药时不开火,但会给予负奖励。
D. 奖励¶
在规划场景中,如果攻击机到达目标,则给予正奖励。如果飞机飞出地图或被击落,则导致负奖励。此外,每个动作都伴随一个小负奖励,以确保到达目标的有效轨迹。总结规划场景我们有:
对于战斗场景我们有:
E. 算法(Algorithms)¶
对于 PPO(Proximal Policy Optimization,近端策略优化)和 DQN(Deep Q-Network,深度Q网络),我们使用了 Python 库 RLlib[45] 提供的版本。这两种算法都包含了文献中报道的最新增强功能,并提供了一些在环境故障情况下的基本恢复行为。对于 AlphaZero,我们基于[19]实现了一个自定义 Python 版本,并适应了兵棋推演环境的要求。这包括针对环境故障的特定问题并行化和容错。以下是我们 AlphaZero 实现的主要特征。有 n 个玩家进程,使用最新训练的策略进行对局。玩家通过构建具有给定扩展次数的 MCTS(Monte Carlo Tree Search,蒙特卡洛树搜索)树来选择最佳动作(规划场景中为 50,战斗场景中为 100)。玩家收集的样本存储在重放缓冲区(Replay Buffer)中。同时,学习器进程从重放缓冲区检索样本批次,并训练一个具有两个头的神经网络(Neural Network, NN):一个用于策略(Policy),一个用于价值(Value)。随着策略的改进,玩家进程产生的对局获得更高的奖励,从而改进了学习器进程,直到针对当前环境达到收敛。在评估过程中,仅使用策略头来选择动作。这具有在训练期间利用多进程的同时减少推理时间的优势。
F. 策略编码(Policy Encoding)¶
对于规划场景,一个具有两个隐藏层的前馈神经网络(Feed-Forward NN)似乎足以编码策略。对于战斗场景,我们考虑了一个卷积神经网络(Convolutional Neural Network, CNN),它提供更强的学习地图几何特征的能力。图 6 详细说明了 AlphaZero 算法中战斗场景的神经网络结构。
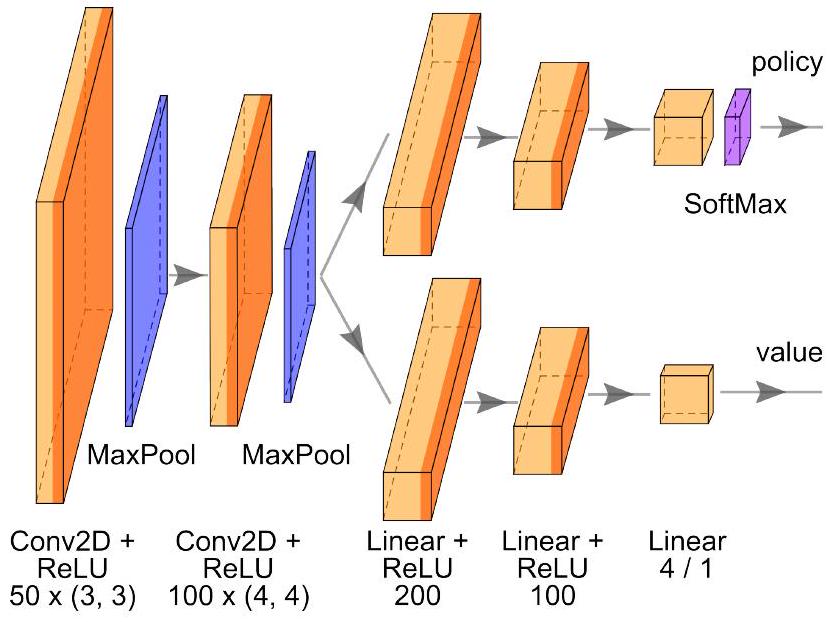
图 6 AlphaZero 算法中战斗场景策略的示例神经网络结构。
G. 连接 CMO 和 Python¶
CMO 提供基于 LUA 语言的 API,允许强化学习智能体通过 TCP/IP 连接与模拟引擎交互。LUA 的设计目标是实现轻量级、直观和类似人类的交互。为了将模拟器用作强化学习环境,我们另外设计了一个名为 cmoclient 的抽象库,它允许我们轻松生成 CMO 模拟器实例并以干净的 Python 语法发出命令。然后,场景在单独的 Python 类中实现,通过 cmoclient 库与 CMO 交互。每个类运行一个具有预定义场景文件的模拟器实例,连接到模拟器的 LUA API TCP/IP 端口,设置模拟环境,并等待强化学习训练开始。使用我们的硬件(详见下一节 VI.H),最多可以同时运行 40 个模拟。如果 CMO 与 cmoclient 之间的通信发生故障,进程被终止,之后启动一个新的引擎实例。恢复程序持续约 30 秒,这构成了重要的工作流程瓶颈。war-sim 模拟器避免了这个问题,提供无崩溃执行和低得多的延迟。在我们的场景中,这带来了更高的训练稳定性和更好的整体训练性能。
H. 配置¶
我们首先使用 war-sim 开始实验。只有在 war-sim 中训练成功后,我们才会研究 CMO 变体。在我们的实验中,超参数在 war-sim 变体上手动调整,然后转移到 CMO。我们使用了 Command 专业版 2.3.1,配置为:专用服务器,64 核处理器(AMD EPYC 7763),256GB 内存,以及 NVIDIA GeForce RTX 3090(24GB)。
I. 结果¶
我们首先总结战斗和规划场景在 war-sim 和 CMO 环境中的训练结果。我们报告两个环境中的训练结果,以展示环境特征对学习过程的强大影响。表 3 提供了我们发现的高层概述。技术细节如下。
| 规划场景 | 战斗场景 | |||
|---|---|---|---|---|
| war-sim | CMO | war-sim | CMO | |
| PPO | 否 | 否 | 否 | - |
| DQN | 否 | 否 | 是 | 否 |
| AlphaZero | 是 | 部分 | 是 | 否 |
表 3 不同实验设置中学习算法的收敛情况。
总体而言,我们观察到在 war-sim 环境中,所有场景中测试算法的学习性能更好。尽管 war-sim 和 CMO 在场景动力学方面差异很小(出于我们实验的目的),但元特征(如延迟和稳定性)的影响是 substantial。
在 war-sim 模拟器中,PPO 在控制任务上表现最强,同时在战斗和规划任务上表现最弱。参见表 2 和 3 的比较。规划战斗场景的设计特征需要高度的初始探索;缺乏探索(这在 PPO 的超参数调整中很难缓解)可以解释 PPO 在这些情况下的相当差的表现。我们观察到一些成功的 PPO 训练运行,但它们的频率不足以实现一致的收敛。总体而言,这与文献中的性能报告一致。在 war-sim 中,DQN 在规划场景中表现同样差,但在战斗场景中表现好得多。正如预期的那样,基于规划的 AlphaZero 算法在 war-sim 的规划和战斗场景中表现出最强的收敛特性和最高的奖励,在两种情况下都确定了接近最优的策略。当在 CMO 上测试时,所有算法都遇到了困难。这些困难包括在 war-sim 中已实现收敛的场景中收敛失败(例如 DQN 在战斗场景中),但也有完全算法执行失败。在规划场景中,PPO 和 DQN 算法运行成功,但没有一种实现收敛。同样,在战斗场景中,DQN 运行成功但没有收敛。由于 PPO 在 war-sim 案例中没有收敛,我们放弃在 CMO 上运行 PPO。当应用于 CMO 时,AlphaZero 的性能因保存/恢复状态期间的崩溃而下降。我们观察到 CMO 动作执行和状态加载过程中大量错误;这些错误的来源超出了 LUA 接口用户的访问范围。对于 AlphaZero,这些错误意味着学习过程仅在规划场景中部分成功,而在战斗场景中失败。鉴于 AlphaZero 在 war-sim 中成功训练,我们相信如果保存/恢复错误不发生,也可以在 CMO 中实现成功训练。
图 7 比较了 war-sim 模拟器中规划场景三种算法的学习进度。我们报告了五次独立训练运行的平均值、第十和第九十百分位。为了提供这些训练图表如何实现的额外背景,图 8 显示了以下性能指标的直方图:1)时间步长,定义为调用模拟环境的总次数;2)样本,定义为提供给神经网络的收集的训练样本总数;3)对局,定义为完成的完整对局总数。PPO 执行最大数量的对局并收集大量样本。DQN 执行约一半数量的对局,但收集的样本少一个数量级。AlphaZero 执行少一个数量级的对局,每个对局的样本也少一个数量级,但需要多一个数量级的模拟器步骤。
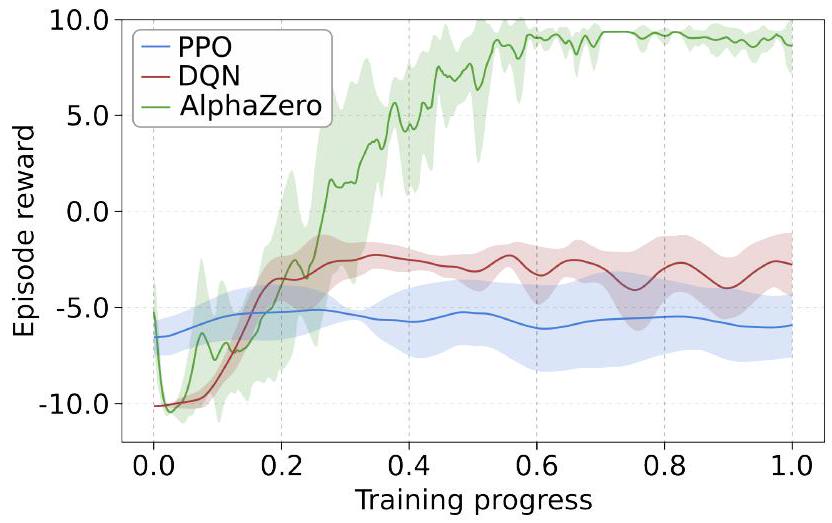
图 7 规划场景的训练进度(war-sim)。
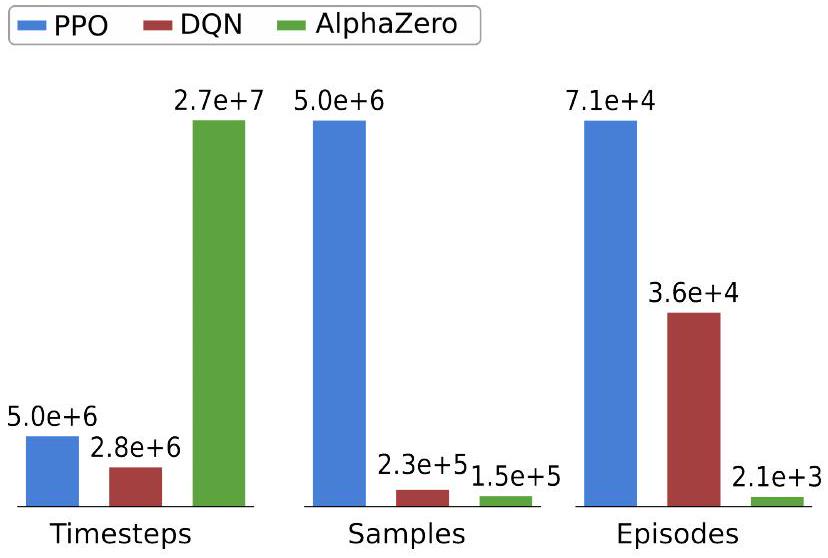
图 8 PPO、DQN 和 AlphaZero 算法在规划场景中的数据需求(war-sim)。
为了说明训练过程的结果,图 9 显示了 AlphaZero 在规划场景中获得的价值函数热图。较亮的单元格颜色表示价值函数的更高水平。价值函数引导智能体沿绕过雷达到达任务目标的最短路径移动。当智能体接近目标时,单元格颜色变得更亮,而起点下方的单元格是暗的,对应于可能导致无法返回的路径(即被 SAM 阵地击落)。最后,图 10 显示了 AlphaZero 算法在完全训练后选择的接近最优轨迹。

图 9 AlphaZero 完全训练后规划场景的价值图(war-sim)。

图 10 AlphaZero 完全训练后为规划场景生成的轨迹。
我们对战斗场景进行了类似分析。和以前一样,我们报告了五次独立训练运行的平均值、第十和第九十百分位。图 11 中的奖励比较表明,尽管 AlphaZero 表现最好,但 DQN 在计算工作量比 AlphaZero 低一个数量级的情况下可以达到良好的奖励水平。图 12 中的直方图显示,战斗和规划场景中的数据需求相似,表明这些数据消耗特性是由算法选择而非特定场景驱动的。

图 11 战斗场景的训练进度(war-sim)。
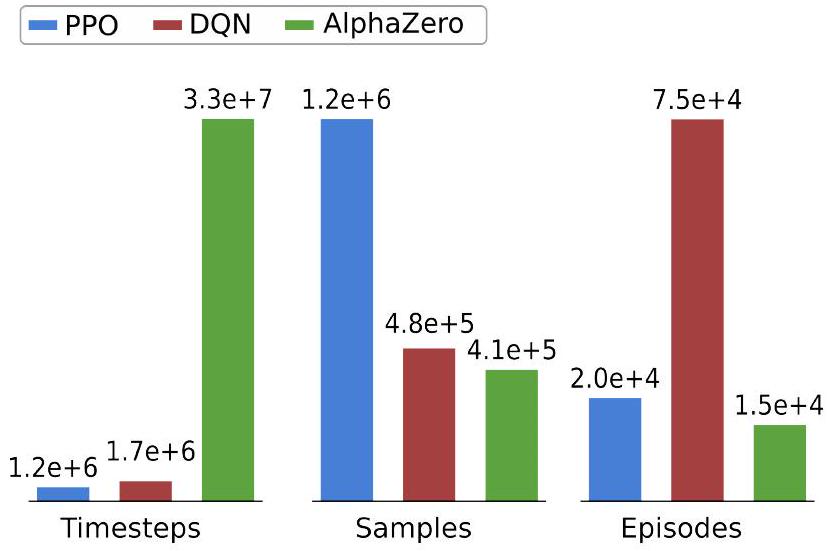
图 12 PPO、DQN 和 AlphaZero 算法在战斗场景中的数据需求(war-sim)。
在战斗场景中,蓝队和红队的最优策略并不明显。AlphaZero 的训练使我们能够识别红队避免蓝队防御措施的逼真和接近最优策略。图 13 中的热图说明了训练结果,显示红队应该在哪里发射第一枚导弹。较亮的单元格颜色表示发射导弹的预期奖励越高(指向 SAM 阵地或防御机)。图 14 显示了一个红队成功完成任务的回合摘要。在这个回合中,攻击机首先瞄准防御机。防御机反击但未击中攻击机。最后,攻击机向 SAM 阵地发射另一枚导弹将其摧毁。在这种情况下,两个目标都被摧毁,获得了最高奖励。
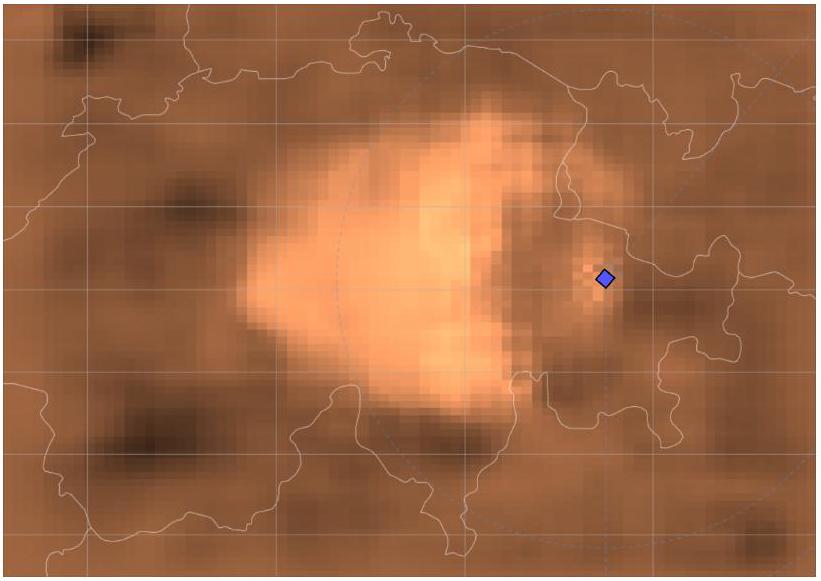
图 13 AlphaZero 完全训练后战斗环境的价值图(war-sim)。
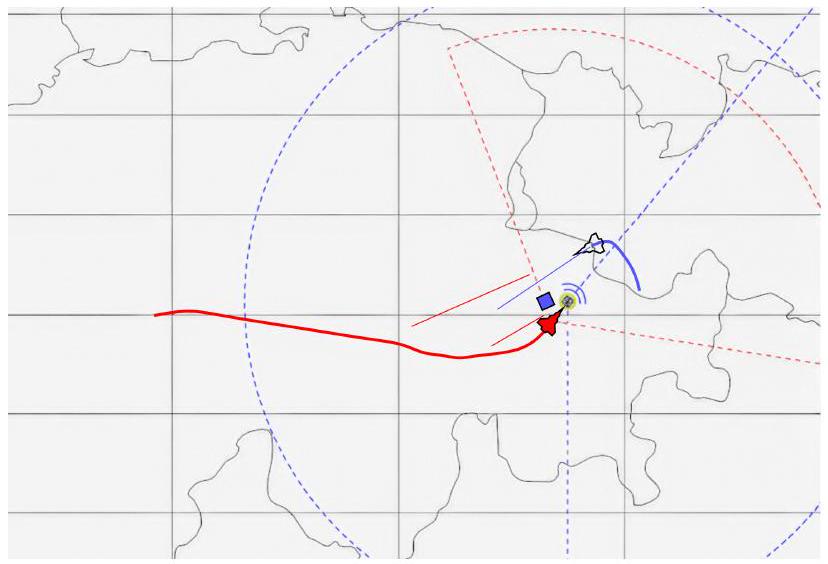
图 14 AlphaZero 完全训练后战斗场景的一个回合。
七、结论¶
我们研究了强化学习在兵棋推演中的应用。从强化学习的角度来看,兵棋推演是复杂的环境,带来若干挑战,因为状态空间和分支因子很大,即使在简单场景中,直接应用强化学习算法也会失败。我们考虑了一个流行的兵棋推演模拟器 CMO,以及它的轻量级孪生兄弟 war-sim,用于加速实验。对现有深度强化学习算法的特征进行了广泛分析,使我们选择了 PPO、DQN 和 AlphaZero。同样,我们提出了三个演示场景。使用 war-sim,AlphaZero 成功解决了所有场景,而 CMO 情况并非如此。CMO 的复杂性及其与 Python 的接口导致崩溃,阻止了稳定的学习。尽管如此,在战斗场景中,我们证明了当环境稳定并使用定制的算法实现时,强化学习可用于研究行动方案。这可以转化为更大且非平凡的场景,以发现意想不到的创新解决方案。
我们实验的结果还允许我们对 PPO、DQN 和 AlphaZero 算法在应用于兵棋推演时的行为进行一般性考虑。基于模型的算法如 AlphaZero 在有限数量的回合中产生更好质量的少量样本,而无模型 PPO 和 DQN 通过执行更多回合收集大量样本。这在规划场景中得到例证,其中 MCTS 在性能上胜过 PPO 和 DQN,但计算成本高出一个数量级:虽然这在快速环境中很方便,但在像 CMO 这样的慢模拟器中可能并不总是可行的选择。DQN 在适用性和性能之间取得了良好的平衡:作为无模型方法,它不需要为保存和恢复游戏状态而进行慢速调用,同时显示出有前景的结果,至少在奖励信号不太稀疏的场景中。
我们应该在这里指出,赋予强化学习核心假设是环境的转换概率在训练期间保持不变。对于兵棋推演,这意味着如果在一个特定状态下采取特定动作,那么统计上结果将始终相同(无论游戏的过去演变如何)。然而,这一假设在多方场景中通常不满足,这在将强化学习应用于兵棋推演时构成了一个重要的限制。如果学习智能体面临多个对手,从学习者的角度来看,其环境将表现为非平稳的,因为其他玩家的不可见动作。多方冲突通常被形式化为马尔可夫博弈,是多智能体强化学习的主题[46]。探索这一方向是必要的未来工作。除此之外,我们还将继续研究如何将强化学习算法应用于兵棋推演,可能使用不同的模拟器并定义更复杂的场景。
附录¶
A. 游戏树搜索¶
搜索。 搜索技术构成了组合双人游戏(如国际象棋)的经典方法。主要思想是评估当前玩家的所有可能动作、所有可能的回复、所有回复的回复,等等。这假设离散的状态和动作空间以及完美信息。鉴于游戏树的指数级大小,这只对简单游戏有效。更常见的是,游戏树在特定规划视野处被修剪,价值函数评估出现的叶子状态。极大极小是一种减少计算工作量的简单技术。对于每个状态,只通过规划遵循玩家的最佳动作(最大化状态价值,max)和对手的最佳应对(最小化位置价值,min)。α/β 搜索是一个实质性的改进,进一步减少了搜索工作。极大极小变体仅适用于中小规模分支因子,性能很大程度上取决于价值函数的准确性。它们构成了许多对抗规划问题的最先进方法,直到深度强化学习的出现。深度强化学习与神经网络估值相比在国际象棋中的优势仍然存在争议。
蒙特卡洛方法。 大分支因子的游戏对非自适应搜索方法构成主要挑战。随机环境和不完美信息增加了这一挑战,因为在给定状态下采取单个动作会产生不同结果,这会膨胀有效分支因子。尽管搜索算法可以扩展为在随机性下操作(参见例如[47]中的期望极大极小算法和[48, 49]中的启发式搜索方法),但计算工作的增加使它们通常不切实际。为了避免对期望值的高成本评估,蒙特卡洛搜索方法被引入,从有限的随机样本提供估计。简而言之,通过多次尝试每个可能的动作来评估状态,然后递归地,从每个生成的状态尝试每个可能的动作,直到达到规划视野。这种搜索可以产生接近最优的策略,与状态空间大小无关[50]。然而,对于复杂游戏,尝试次数和规划视野需要如此之大以至于计算变得不切实际。
B. 强化学习(Reinforcement Learning)¶
强化学习背后的主要概念转变是从执行固定策略的人工智能体转变为智能体(Agent)。为了改进策略,智能体具有自适应策略的学习必须采取明显次优的动作以探索新的行动方案。探索新动作与利用已知有利动作之间的权衡在多臂老虎机(Multi-Armed Bandit)算法中最为明显。
多臂老虎机(Multi-Armed Bandit)。 k 臂老虎机,其名称来自赌博者从 k 台老虎机中选择,是强化学习的典型例子。它描述了一个简化场景,其中动作(称为臂)不影响环境[31]。因此,k 臂老虎机不是提前规划,而是优化即时奖励(Immediate Reward)。如果应用于兵棋推演,这一限制意味着算法专注于即时结果(例如,摧毁最多敌方单位),而忽略其长期后果(例如,由于弹药不足而错失整体作战目标)。形式上,在每个时间步 t=1, ..., T,智能体选择一个动作 a∈{a1, ..., ak} 并收到随机奖励 Ra=Xa,t,其中随机变量 Xa,t 关于 a 独立且关于 t 独立同分布。经过许多回合,智能体收集每个臂的奖励统计。开发-探索困境(Exploration-Exploitation Dilemma)体现在智能体是否应该选择迄今为止有利可图的臂,或者尝试具有高统计不确定性的臂,希望揭示更高的奖励。UCB1 策略常用于控制探索和利用。它在预期奖励和置信度之间最大化权衡
其中 na 是动作 a 迄今为止被选择的次数。平均奖励 \(\bar{R}_{a}\) 强调对当前最佳动作的开发(Exploitation),而 \(c_{n, n_{a}}\) 鼓励对高方差动作的探索(Exploration)。它们的相对权重由问题特定的超参数(Hyper-parameter)w 决定。对于大类奖励分布,UCB1 策略接近最优。
蒙特卡洛方法(Monte Carlo Methods)。 蒙特卡洛方法通过在许多学习回合中采取动作和环境转换的随机样本来处理强化学习问题[41]。蒙特卡洛方法可以在无模型设置中操作,仅从经验学习,或在基于模型的情况下通过有针对性的环境交互学习。一个反复出现的概念是训练过程中维护一个表格,其中包含状态-动作对 (st, at) 的 Q 值(Q-Value)估计,以考虑回合的预期奖励。每个训练回合完成后,表格根据标准蒙特卡洛更新规则进行更新: $$ \hat{Q}{\text {new }}\left(s}, a_{t}\right) \leftarrow \hat{Q{\text {old }}\left(s}, a_{t}\right)+\alpha\left[\sum_{k=t}^{T} \gamma^{k-t} R_{a_{k}, k}-\hat{Q{\text {old }}\left(s $$}, a_{t}\right)\right], \tag{4
其中右侧的和代表新的蒙特卡洛估计,步长参数 α 权衡当前持有的估计与新估计的相关性。这种规则的主要缺点是更新只能在回合完成后执行。如果 Q 值可以在回合期间更新,这将改善对回合期间后续动作的选择并提高算法效率。时间差分方法(Temporal Difference, TD)在动作执行后立即更新 Q 值。这意味着必须在回合完成前估计回合的剩余回报 \(\sum_{k=t}^{T} R_{a_{k}, k}\)。一个常见的选择是使用贝尔曼(Bellman)估计,例如在著名的 Q 学习(Q-Learning)算法[32]中采用的。
Q 学习(Q-Learning)。 Q 表在每个时间步的每次决策后更新。在 Q 学习中,智能体按以下步骤迭代进行:i) 智能体从表中选择最佳动作 at,ii) 智能体观察奖励 Ra,t,t,并根据修改的更新规则更新 Q 表中的估计:
更新规则包含两种不同类型的估计。首先,Q 通过蒙特卡洛平均 \(\hat{Q}_{\text {new/old}}\) 估计。其次,项 \(R_{a_{t}, t}+\gamma \max _{a} \hat{Q}_{\text {old }}\left(s_{t+1}, a\right)\) 是当前回合预期总回报的(贝尔曼型)估计。
蒙特卡洛树搜索(Monte Carlo Tree Search, MCTS)。 MCTS 是一类基于模型的强化学习算法,用于在复杂环境中近似最优策略。对于任何强化学习环境,可以通过蒙特卡洛采样和搜索的组合构建接近最优的策略[50],但对于复杂的兵棋推演,模拟规模通常需要如此之大以至于计算变得不切实际。为了提高效率,MCTS 创建了一个问题特定的、受限的和非对称的决策树,而不是"暴力蒙特卡洛"[33, 51]。在 MCTS 中,每个节点保存从该节点开始的分支性能统计,树生长由专门的树策略(Tree Policy)指导(在纳入新节点和模拟现有线路之间取得平衡)。学习过程包含树策略和状态估值之间的迭代改进[52]:1)选择(Selection),即 MCTS 从当前规划树识别最相关的叶子节点;2)扩展(Expansion),即在选定节点处向树添加新叶子节点;3)模拟(Simulation),即在新节点处执行估值;4)反向传播(Backpropagation),即模拟结果通过更新所有树节点的奖励统计来改进树策略。通常,个别节点采用 UCB1 老虎机策略来指导规划树的构建[33]。得到的算法称为 UCT,如果给予足够资源,可以保证识别最优策略。
C. 深度强化学习(Deep Reinforcement Learning)¶
尽管许多经典强化学习方法具有收敛保证,但游戏中实现收敛的计算工作往往是巨大的。即使维护状态价值估计表对于复杂游戏也是不可能的(国际象棋约 10^47 个状态,围棋约 10^170 个状态)。将深度学习引入强化学习的主要目的之一是通过使用抽象表示的泛化能力来减少计算工作。粗略地说,不是评估大量附近状态(通过昂贵的模拟或临时估值),而是评估一个(深度)神经网络(Neural Network, NN),它已在相对较少的准确样本上训练。代价是失去收敛保证,因为神经网络训练可能陷入糟糕的局部最优。深度强化学习的一个重要挑战是设计训练过程以确保智能体性能持续提升。
深度 Q 学习(Deep Q-Learning)。 深度 Q 网络(Deep Q-Network, DQN)是一种无模型强化学习算法,它扩展了经典 Q 学习,用(深度)神经网络表示 Q 值。这允许学习抽象状态表示,并提取与后续奖励最相关的状态特征。虽然状态和动作空间的大小可能很大,但它们的神经网络表示通常仍然可以管理,因为状态的许多细节与即将到来的奖励无关。DQN 不是维护和更新 Q 表,而是仅对神经网络参数进行操作,在回合内更新(时间差分学习,Temporal Difference Learning)。更新规则基于梯度(Gradient),但它从 Q 学习的贝尔曼(Bellman)目标 \(R_{a_{t}, t}+\gamma \max _{a} \hat{Q}_{\text {old }}\left(s_{t+1}, a\right)\) 中获得灵感来估计新样本对 Q 的影响:
与监督学习不同,监督学习中学习目标是固定的,贝尔曼目标依赖于神经网络参数。这意味着神经网络在每个时间步变化的的目标序列上训练(导致不稳定和发散[53])。为了解决这一缺陷,DQN 使用了两个神经网络实例,每个都配备了自己的参数集。价值神经网络提供 \(\hat{Q}_{\text {old}}\) 的估计,并在每个时间步在贝尔曼目标上训练。目标神经网络提供用于计算贝尔曼目标的动作价值。目标神经网络的参数异步更新,在给定数量的回合后设置为价值神经网络的参数。DQN 使用经验回放缓冲区(Replay Buffer)[54],存储所有经历的转换 (st, at, rt+1, st+1)。这允许使用批量梯度下降(Batch Gradient Descent)算法进行神经网络训练。消除样本与当前权重的依赖并使用经验回放可以弥补上述不稳定性。DQN 设计的大量变体出现在文献中,其中最近的架构在稳定性和样本效率方面优于原始设计[53]。
近端策略梯度(Proximal Policy Gradient, PPG)。 策略梯度(Policy Gradient)算法是无模型蒙特卡洛方法,基于参数化策略集合而非直接基于 Q 值工作。它们计算策略梯度的蒙特卡洛估计,然后使用随机梯度下降(Stochastic Gradient Descent)更新策略参数。原型策略梯度方法 REINFORCE[41] 使用形式如下的梯度估计器:
其中 πθ 表示策略(由 θ 参数化),\(\hat{\mathbb{E}}_{\pi_{\theta}}[\cdot]\) 是遵循 πθ 时的预期回报的蒙特卡洛估计。REINFORCE 在每个步骤 t 完成后回顾性地更新参数:
与表格蒙特卡洛方法一样,时间差分技术可用于在回合内更新参数。在更新规则中,这导致用优势估计(Advantage Estimation)\(\hat{A}_{t}\) 替换回合的剩余回报。尽管如此,时间差分策略梯度方法的数据效率相对较差,它们对步长(在梯度下降中)的敏感性仍然是重要的不稳定来源。在同一轨迹上对 REINFORCE 损失函数 \(\operatorname{Loss}^{PG}=\hat{\mathbb{E}}_{\pi_{\theta}}\left[\log \pi_{\theta}\left(a_{t} \mid s_{t}\right) \sum_{k=t}^{T} R_{a_{k}, k}\right]\) 执行多个优化步骤在经验上会导致破坏性的过大策略更新。信任域策略优化(Trust Region Policy Optimization, TRPO[55])采用代理损失函数(Surrogate Loss Function):
受限于新策略与旧策略之间差异的约束(基于它们的预期 KL 散度,KL Divergence),以避免过大的梯度。PPO(Proximal Policy Optimization,近端策略优化)[56] 对 TRPO 目标函数中的策略比率采用裁剪程序以确保保守的参数更新。这简化了算法,去除了 KL 惩罚和自适应更新的需要。
AlphaZero。 AlphaZero 是一种 MCTS 变体[57, 58],其中原始的 UCT 设计通过使用神经网络(Neural Network)得到增强。通常,神经网络用于 1)引导树构建和 2)提供叶子节点的准确估值。在 UCT 之上使用神经网络有两个主要优势。首先,神经网络提供比 UCT 估值更快状态估值。其次,它们提供泛化能力(Generalization):为了评估"相似"状态,UCT 只能执行昂贵的模拟,而训练有素的神经网络可能"识别"相似性以进行估值。AlphaZero 训练过程包含 MCTS 和神经网络组件之间的相互改进交替。算法开始(通过监督预训练 Supervised Pre-training 或)执行 UCT 算法。一旦有足够的样本,将训练神经网络表示树策略和估值函数(Value Function)到 UCT 目标。特别地,关于点 1),树策略神经网络被训练为使用以下方式模仿根节点处 UCT 的平均动作:
其中 na 是从 s 执行动作 a 的次数,n 是模拟总数。在后续迭代中,向 UCB1 树策略添加神经网络项,引导树搜索朝向更强的行动方案:
其中 w∼√n 是权衡 UCB1 和神经网络贡献的超参数。关于点 2),价值网络减少搜索深度并避免不准确的基于rollout 的估值。像以前一样,树搜索通过在训练回合中收集奖励提供价值样本。价值网络被训练为通过 \(\operatorname{Loss}_{V}=-\left(z-V^{N N}(s)\right)^{2}\) 预测获得的估值。为了正则化预测和加速训练,通常同时覆盖 1)和 2),通过多任务网络,其损失只是 LossV 和 LossTPT 的和。
D. 关于兵棋推演算法选择¶
由于兵棋推演类型的大变化、不同的目标以及可用算法的大量选择,算法选择可能很微妙。训练结合单个单位实时控制(部队级)和全局任务规划(指挥官级)的智能体是一个挑战,因为这些任务导致不同的系统要求、算法选择、训练设置等。一个粗略的指导方针如下。
搜索。 传统搜索技术适用于具有清晰底层树结构的离散游戏。前提条件是有计算资源来研究游戏树的有意义部分,以及足够准确的价值函数来评估叶子节点。游戏树大小的指标(如状态和动作空间的大小和分支因子)应该是中等规模。对于国际象棋(分支因子~30),α/β 搜索变体容易达到超越人类的强度,但价值函数是数十年研究的结果[59]。α/β 搜索在瑞士兵棋推演"New Techno"* 上表现强劲。不断增加的分支因子通常导致搜索恶化,例如围棋表现仅为中等(分支因子~361)。蒙特卡洛搜索技术解决确定性搜索不可行的情况,例如存在大分支因子(可能由"战争迷雾"产生)。与确定性搜索相比,蒙特卡洛方法通常不太准确,但可以处理更大的复杂性。
为了在存在连续变量的情况下应用搜索技术,需要某种形式的离散化。如果通过强制变量位于指定网格上来实现这一点,网格的网格大小将是棘手的超参数。如果网格太粗,方法可能错过奖励信号;如果太细,计算工作变得无法管理。
传统搜索算法可以与深度学习组件(神经网络)结合来表示获取的知识(价值函数),并使用深度强化学习进行训练,参见下文。对于国际象棋,将 α/β 搜索与神经网络结合[60] 带来显著的性能提升[61]。与 AlphaZero 的性能比较仍然存在争议。
监督学习。 监督学习系统受限于数据的可用性和质量;在(实际罕见的情况下)有足够数据可用时,监督学习即使在非常复杂的兵棋推演中也处理得很好。监督学习智能体在围棋和星际争霸 2 等游戏中达到强人类玩家的水平[21, 62]。作为一个经验法则,监督学习系统更容易训练,比白板深度强化学习消耗更少资源。如果有适当的训练数据,建议尝试训练监督深度学习系统。深度强化学习可以在预训练系统之上应用以提高性能。
经典强化学习。 经典强化学习技术通常具有强大的收敛保证。它们的主要缺点是计算工作即使对于简单的兵棋推演也往往变得不切实际。表格强化学习方法(包括蒙特卡洛方法和特别是 Q 学习)需要离散的状态和动作空间。与搜索一样,离散化引入了难以控制的超参数。更广泛地说,精确求解兵棋推演通常是不可行的,因为它需要对整个游戏树进行统计评估。类似地,通用近似解方法(如价值迭代或基于梯度的优化)的收敛可能很慢。近似解方法自然出现在连续变量的情况下。策略梯度方法假设(连续)策略分布,并在信息可用时使用梯度方法更新它。这避免了大型动作价值表的更新,但需要适当的先验和策略学习。适当的先验构建通常可以有益于学习[31]。
深度强化学习。 将深度学习引入强化学习算法至少有两个目的。首先,深度学习提供抽象和泛化能力。对于状态,抽象允许智能体专注于与后续奖励相关的状态内容。对于动作,抽象意味着动作可以分组为实现相关操作的子程序,而不是网格型离散化。其次,昂贵的模拟可能被训练函数近似器(神经网络)的评估所取代,这允许利用状态相似性和抽象对称性,而不是暴力计算。对于经典强化学习,表格方法的衍生适用于小/离散游戏,而策略梯度方法提供了处理大/连续动作空间的实用方法。在 DQN 方面,应该指出,虽然它在街机学习环境(具有离散动作空间的 Atari 游戏)中表现良好,但在许多简单问题上失败,原因往往难以追踪。在连续控制基准测试(如 OpenAI Gym[63])中,PPO 变体通常表现出更好的性能和更好的学习稳定性[56]。另一个有趣的基准是 PPO 训练的智能体在时间关键控制问题(如无人机竞速[16] 或赛车模拟[17])中超越人类专家。对于规划问题,基于规划的方法(如结合神经网络和搜索算法)比最佳无模型方法学习更强的策略并达到更高的性能得分。一个常见的经验观察是,深度 Q 网络(DQN)和近端策略优化(PPO)在复杂规划问题(如围棋或国际象棋)上的性能迅速下降,特别是当奖励稀疏时。如今,神经 MCTS 变体在众多基准上超越无模型方法,参见通用视频游戏 AI 竞赛[18, 64] 规划赛道的性能统计,甚至街机学习环境的控制任务[65]。神经 MCTS 变体通常也比无模型方法具有更高的泛化能力,即它们在以前未见过的场景中表现更好(给定一些高级描述,如兵棋推演的规则和任务目标),其中"当今几乎每个通用游戏程序都使用某种版本的 MCTS"[66]。最后,神经网络系统可以与记忆单元结合,将上下文信息传输到连续状态序列中,使其可用于行动方案的战略规划。在兵棋推演背景下,[67] 的长短期记忆(LSTM)架构是 Dota 2[20] 和星际争霸 2[21] 中人工智能体巨大成功的背后。LSTM 架构在离散多周期规划和连续控制之间取得了高效平衡,无需显著的向前看[20, 21]。对于结合控制和战略规划的现代兵棋推演,这使 LSTM 架构成为自然选择。另一个优势是 LSTM 和神经网络架构可以模块化组合,允许创建学习层次结构以及组件的单独训练和评估。
训练、子目标和层次结构。 如果没有监督预训练的可用数据,奖励塑造技术可以是促进学习过程的替代方法。为了引导智能体实现整体任务目标,可以引入预定的子目标。子目标和奖励信号可以基于人类知识提供(例如,对单位损失施加惩罚),或自动学习[68, 69]。在现实世界国防行动中,国防场景的复杂性通过决策过程的层级组织来管理。低级机动决策由个别单位做出,而抽象任务规划目标在更高层级设定。这通过利用个体参与者之间的作战相似性来提高训练和执行效率。用层级深度强化学习系统模拟现实世界的层次结构,将整体策略分解为问题特定的子策略[70]。这些子策略配备有特定于任务的架构并以特定方式训练,在兵棋推演中提供类似的效率增益[21, 22]。AlphaStar 智能体采用神经网络层次结构,低级网络负责单位控制,而更高级别的 LSTM 模块规划行动方案以实现整体任务目标。对于复杂的兵棋推演,在没有任何形式的人类指导的情况下进行白板学习,无论是演示形式还是奖励塑造,目前都遥不可及。
软件架构。 软件架构的复杂性是选择算法时的重要考虑因素。虽然许多无模型算法可在开源仓库中获得(例如,DQN 和 PPO 已在 Python 的 RLlib 包[45] 和标准化强化学习库(例如 Gymnasium[42])中现成实现),但基于模型的系统通常需要定制开发工作。这不仅影响算法核心的开发,还影响适当的并行化、专门的错误捕获机制以及处理许多并发模拟过程。后者大大增加了为兵棋推演创建基于模型的深度强化学习系统的努力。总体而言,这使得无模型方法成为许多兵棋推演的主要实际选择。基于模型的系统以复杂基础设施和大量定制开发工作为代价瞄准更高的奖励性能。鉴于计算和时间预算,我们观察到无模型方法可以产生更好的结果,因为环境转换和实例化的延迟侵蚀了高效学习的优势另一点是,无模型智能体在执行中很快(通常以超越人类的频率做出决策),而规划智能体慢几个数量级(例如,需要数秒来选择动作)。
参考文献¶
[1] UK Ministry of Defense, Wargaming Handbook - Development, Concepts and Doctrine Centre, 2017. URL https://assets. publishing.service.gov.uk/media/5a82e90d40f0b6230269d575/doctrine_uk_wargaming_handbook.pdf. (accessed July 4, 2025).
[2] Rinaudo, C. H., Leonard, W. B., Hopson, J. E., Coumbe, T. R., Pettitt, J. A., and Darken, C., "Applying Deep Reinforcement Learning to Train AI Agents in a Wargaming Framework," SoutheastCon 2024, 2024, pp. 1131-1136. https://doi.org/10.1109/ SoutheastCon52093.2024.10500249
[3] Castro, G., Heradio, R., and Cerrada, C., "Automated Support for Battle Decision Making: A Systematic Literature Review," Military Operations Research, Vol. 27, 2022, pp. 5-23. URL https://www.jstor.org/stable/27182470
[4] Davis, P., "Distributed interactive simulation in the evolution of DoD warfare modeling and simulation," Proceedings of the IEEE, Vol. 83, No. 8, 1995, pp. 1138-1155. https://doi.org/10.1109/5.400454
[5] Rashid, A. B., Kausik, A. K., Al Hassan Sunny, A., and Bappy, M. H., "Artificial Intelligence in the Military: An Overview of the Capabilities, Applications, and Challenges," International Journal of Intelligent Systems, Vol. 2023, No. 1, 2023, p. 8676366. https://doi.org/10.1155/2023/8676366
[6] Pournelle, P., "The need for cooperation between wargaming and modeling & simulation for examining Cyber, Space, Electronic Warfare, and other topics," The Journal of Defense Modeling and Simulation, Vol. 21, No. 4, 2024, pp. 359-362. https://doi.org/10.1177/15485129221118100.
[7] Lin-Greenberg, E., Pauly, R. B., and Schneider, J. G., "Wargaming for International Relations research," European Journal of International Relations, Vol. 28, No. 1, 2022, pp. 83-109. https://doi.org/10.1177/13540661211064090
[8] Davis, P. K., and Bracken, P., "Artificial intelligence for wargaming and modeling," The Journal of Defense Modeling and Simulation, Vol. 22, No. 1, 2025, pp. 25-40. https://doi.org/10.1177/15485129211073126
[9] Goodman, J., Risi, S., and Lucas, S., "AI and Wargaming," arXiv, 2020. URL https://arxiv.org/abs/2009.08922
[10] BreakingDefense, 2020. URL https://breakingdefense.com/2020/08/darpa-wants-wargame-ai-to-never-fight-fair (accessed July 4, 2025).
[11] Dimitriu, A., Michaletzky, T. V., Remeli, V., and Tihanyi, V. R., "A Reinforcement Learning Approach to Military Simulations in Command: Modern Operations," IEEE Access, Vol. 12, 2024, pp. 77501-77513. https://doi.org/10.1109/ACCESS.2024. 3406148
[12] Andersen, P.-A., Goodwin, M., and Granmo, O.-C., "Towards safe and sustainable reinforcement learning for real-time strategy games," Information Sciences, Vol. 679, 2024, p. 120980. https://doi.org/10.1016/j.ins.2024.120980
[13] Hastie, T., Tibshirani, R., and Friedman, J., The Elements of Statistical Learning, Springer New York, 2009. URL https://link.springer.com/book/10.1007/978-0-387-84858-7.
[14] Mnih, V., Kavukcuoglu, K., Silver, D., Graves, A., Antonoglou, I., Wierstra, D., and Riedmiller, M. A., "Playing Atari with Deep Reinforcement Learning," arXiv, 2013. URL https://arxiv.org/abs/1312.5602.
[15] Mnih, V., Kavukcuoglu, K., Silver, D., Rusu, A. A., Veness, J., Bellemare, M. G., Graves, A., Riedmiller, M., Fidjeland, A. K., Ostrovski, G., Petersen, S., Beattie, C., Sadik, A., Antonoglou, I., King, H., Kumaran, D., Wierstra, D., Legg, S., and Hassabis, D., "Human-level control through deep reinforcement learning," Nature, Vol. 518, No. 7540, 2015, pp. 529-533. https://doi.org/10.1038/nature14236.
[16] Kaufmann, E., Bauersfeld, L., Loquercio, A., Müller, M., Koltun, V., and Scaramuzza, D., "Champion-level drone racing using deep reinforcement learning," Nature, Vol. 620, No. 7976, 2023, p. 982-987. https://doi.org/10.1038/s41586-023-06419-4
[17] Wurman, P. R., Barrett, S., Kawamoto, K., MacGlashan, J., Subramanian, K., Walsh, T. J., Capobianco, R., Devlic, A., Eckert, F., Fuchs, F., Gilpin, L., Khandelwal, P., Kompella, V., Lin, H., MacAlpine, P., Oller, D., Seno, T., Sherstan, C., Thomure, M. D., Aghabozorgi, H., Barrett, L., Douglas, R., Whitehead, D., Dürr, P., Stone, P., Spranger, M., and Kitano, H., "Outracing champion Gran Turismo drivers with deep reinforcement learning," Nature, Vol. 602, No. 7896, 2022, p. 223-228. https://doi.org/10.1038/s41586-021-04357-7
[18] Perez-Liebana, D., Samothrakis, S., Togelius, J., Schaul, T., and Lucas, S., "General Video Game AI: Competition, Challenges and Opportunities," Proceedings of the AAAI Conference on Artificial Intelligence, Vol. 30, No. 1, 2016. https://doi.org/10.1609/aaai.v30i1.9869
[19] Silver, D., Hubert, T., Schrittwieser, J., Antonoglou, I., Lai, M., Guez, A., Lanctot, M., Sifre, L., Kumaran, D., Graepel, T., Lillicrap, T., Simonyan, K., and Hassabis, D., "A general reinforcement learning algorithm that masters Chess, Shogi, and Go through self-play," Science, Vol. 362, No. 6419, 2018, pp. 1140-1144. https://doi.org/10.1126/science.aar6404
[20] Berner, C., Brockman, G., Chan, B., Cheung, V., Dębiak, P., Dennison, C., Farhi, D., Fischer, Q., Hashme, S., Hesse, C., Józefowicz, R., Gray, S., Olsson, C., Pachocki, J., Petrov, M., d. O. Pinto, H. P., Raiman, J., Salimans, T., Schlatter, J., Schneider, J., Sidor, S., Sutskever, I., Tang, J., Wolski, F., and Zhang, S., "Dota 2 with Large Scale Deep Reinforcement Learning," arXiv, 2019. URL https://arxiv.org/abs/1912.06680
[21] Vinyals, O., Babuschkin, I., Czarnecki, W. M., Mathieu, M., Dudzik, A., Chung, J., Choi, D. H., Powell, R., Ewalds, T., Georgiev, P., Oh, J., Horgan, D., Kroiss, M., Danihelka, I., Huang, A., Sifre, L., Cai, T., Agapiou, J. P., Jaderberg, M., Vezhnevets, A. S., Leblond, R., Pohlen, T., Dalibard, V., Budden, D., Sulsky, Y., Molloy, J., Paine, T. L., Gulcehre, C., Wang, Z., Pfaff, T., Wu, Y., Ring, R., Yogatama, D., Wünsch, D., McKinney, K., Smith, O., Schaul, T., Lillicrap, T., Kavukcuoglu, K., Hassabis, D., Apps, C., and Silver, D., "Grandmaster level in StarCraft II using multi-agent reinforcement learning," Nature, Vol. 575, No. 7782, 2019, pp. 350-354. https://doi.org/10.1038/s41586-019-1724-z.
[22] Selmonaj, A., Szehr, O., Del Rio, G., Antonucci, A., Schneider, A., and Rüegsegger, M., "Hierarchical Multi-Agent Reinforcement Learning for Air Combat Maneuvering," Proceedings of the 2023 International Conference on Machine Learning and Applications (ICMLA), IEEE, 2023, pp. 1031-1038. https://doi.org/10.1109/ICMLA58977.2023.00153
[23] Zhu, J., Kuang, M., Zhou, W., Shi, H., Zhu, J., and Han, X., "Mastering air combat game with deep reinforcement learning," Defence Technology, Vol. 34, 2024, pp. 295-312. https://doi.org/10.1016/j.dt.2023.08.019
[24] Jeong, H., Hassani, H., Morari, M., Lee, D. D., and Pappas, G. J., "Deep Reinforcement Learning for Active Target Tracking," 2021 IEEE International Conference on Robotics and Automation (ICRA), 2021, pp. 1825-1831. https://doi.org/10.1109/ ICRA48506.2021.9561258
[25] Xia, J., Luo, Y., Liu, Z., Zhang, Y., Shi, H., and Liu, Z., "Cooperative multi-target hunting by unmanned surface vehicles based on multi-agent reinforcement learning," Defence Technology, Vol. 29, 2023, pp. 80-94. https://doi.org/10.1016/j.dt.2022.09.014
[26] Shang, T., Han, K., Ma, J., and Mao, M., "Research on Self-Gaming Training Method of Wargame Based on Deep Reinforcement Learning," Proceedings of the 2019 International Conference on Artificial Intelligence and Computer Science, Association for Computing Machinery, New York, NY, USA, 2019, p. 251-254. https://doi.org/10.1145/3349341.3349411
[27] Shang, T., Ma, J., Han, K., and Yu, Y., "Research on Game Problem Under Incomplete Information Condition Based on Deep Reinforcement Learning," Proceedings of the 2019 International Conference on Artificial Intelligence and Computer Science, Association for Computing Machinery, New York, NY, USA, 2019, p. 255-257. https://doi.org/10.1145/3349341.3349412.
[28] Dulac-Arnold, G., Levine, N., Mankowitz, D. J., Li, J., Paduraru, C., Gowal, S., and Hester, T., "Challenges of real-world reinforcement learning: definitions, benchmarks and analysis," Machine Learning, Vol. 110, No. 9, 2021, pp. 2419-2468. https://doi.org/10.1007/s10994-021-05961-4
[29] Albert, M. H., Nowakowski, R. J., and Wolfe, D., Lessons in Play: An Introduction to Combinatorial Game Theory, CRC press, 2007.
[30] Fudenberg, D., and Tirole, J., Game Theory, MIT press, 1993. URL https://mitpress.mit.edu/9780262061414/game-theory/
[31] Sutton, R. S., and Barto, A. G., Reinforcement learning: An introduction, MIT press, 2018.
[32] Watkins, C. J. C. H., and Dayan, P., "Technical Note: Q-learning," Machine Learning, 1992, pp. 279-292. https://doi.org/ 10.1023/A:1022676722315
[33] Kocsis, L., and Szepesvári, C., "Bandit Based Monte-Carlo Planning," 17th European Conference on Machine Learning (ECML 2006), Springer Berlin Heidelberg, Berlin, Heidelberg, 2006, pp. 282-293. https://doi.org/10.1007/11871842_29
[34] Dong, L., Li, N., Yuan, H., and Gong, G., "Accelerating wargaming reinforcement learning by dynamic multi-demonstrator ensemble," Information Sciences, Vol. 648, 2023, p. 119534. https://doi.org/10.1016/j.ins.2023.119534
[35] Hayes-Roth, F., Waterman, D. A., and Lenat, D. B., Building expert systems, Addison-Wesley Longman Publishing Co., Inc., USA, 1983. URL https://dl.acm.org/doi/abs/10.5555/6123.
[36] Balduzzi, D., Garnelo, M., Bachrach, Y., Czarnecki, W., Perolat, J., Jaderberg, M., and Graepel, T., "Open-ended Learning in Symmetric Zero-sum Games," Proceedings of the 36th International Conference on Machine Learning, Vol. 97, PMLR, 2019, pp. 434-443. https://doi.org/10.48550/arXiv.1901.08106
[37] Hester, T., and Stone, P., "TEXPLORE: real-time sample-efficient reinforcement learning for robots," Machine Learning, Vol. 90, No. 3, 2012, pp. 385-429. https://doi.org/10.1007/s10994-012-5322-7.
[38] Hung, C.-C., Lillicrap, T., Abramson, J., Wu, Y., Mirza, M., Carnevale, F., Ahuja, A., and Wayne, G., "Optimizing Agent Behavior over Long Time Scales by Transporting Value," Nature Communications, Vol. 10, 2019, p. 5223. https://doi.org/10.1038/s41467-019-13073-w
[39] Sommer, M., Rüegsegger, M., Del Rio, G., and Szehr, O., "Deep Self-optimizing Artificial Intelligence for Tactical Analysis, Training and Optimization,", 2021. STO-MP-SAS-OCS-ORA-2021, Nato, Science and Technology Organization.
[40] Melnikov, A. A., Makmal, A., and Briegel, H. J., "Benchmarking Projective Simulation in Navigation Problems," IEEE Access, Vol. 6, 2018, pp. 64639-64648. https://doi.org/10.1109/ACCESS.2018.2876494
[41] Sutton, R. S., "Learning to predict by the methods of temporal differences," Machine learning, Vol. 3, No. 1, 1988, pp. 9-44. https://doi.org/10.1007/BF00115009
[42] Towers, M., Terry, J. K., Kwiatkowski, A., Balis, J. U., Cola, G. d., Deleu, T., Goulão, M., Kallinteris, A., KG, A., Krimmel, M., Perez-Vicente, R., Pierré, A., Schulhoff, S., Tai, J. J., Shen, A. T. J., and Younis, O. G., "Gymnasium," , Mar. 2023. URL https://zenodo.org/record/8127025. (accessed July 4, 2025).
[43] Met Office, Cartopy: a cartographic Python library with a Matplotlib interface, 2010-2017. URL http://scitools.org.uk/cartopy, (accessed July 4, 2025).
[44] Karney, C. F. F., "Algorithms for geodesics," Journal of Geodesy, Vol. 87, No. 1, 2013, pp. 43-55.https://doi.org/10.1007/s00190-012-0578-z.
[45] Liang, E., Liaw, R., Moritz, P., Nishihara, R., Fox, R., Goldberg, K., Gonzalez, J. E., Jordan, M. I., and Stoica, I., "RLlib: Abstractions for Distributed Reinforcement Learning," Proceedings of the 35th International Conference on Machine Learning, Proceedings of Machine Learning Research, Vol. 80, PMLR, 2018, pp. 3059-3068. URL https://proceedings.mlr.press/v80/ liang18b.html.
[46] Gronauer, S., and Diepold, K., "Multi-agent deep reinforcement learning: a survey," Artificial Intelligence Review, Vol. 55, No. 2, 2021, pp. 895-943. https://doi.org/10.1007/s10462-021-09996-w
[47] Michie, D., "Game-Playing and Game-Learning Automata," Advances in Programming and Non-Numerical Computation, Pergamon, 1966, pp. 183-200. https://doi.org/10.1016/B978-0-08-011356-2.50011-2
[48] Dean, T., Kaelbling, L. P., Kirman, J., and Nicholson, A., "Planning under time constraints in stochastic domains," Artificial Intelligence, Vol. 76, No. 1-2, 1995, pp. 35-74. https://doi.org/10.1016/0004-3702(94)00086-G.
[49] Hansen, E. A., and Zilberstein, S., "LAO*: A heuristic search algorithm that finds solutions with loops," Artificial Intelligence, Vol. 129, No. 1-2, 2001, pp. 35-62. https://doi.org/10.1016/S0004-3702(01)00106-0
[50] Kearns, M., Mansour, Y., and Ng, A. Y., "A Sparse Sampling Algorithm for Near-Optimal Planning in Large Markov Decision Processes," Machine Learning, Vol. 49, No. 2/3, 2002, pp. 193-208. https://doi.org/10.1023/A:1017932429737
[51] Chang, H. S., Fu, M. C., Hu, J., and Marcus, S. I., "An Adaptive Sampling Algorithm for Solving Markov Decision Processes," Operations Research, Vol. 53, No. 1, 2005, pp. 126-139. https://doi.org/10.1287/opre.1040.0145.
[52] Browne, C. B., Powley, E., Whitehouse, D., Lucas, S. M., Cowling, P. I., Rohlfshagen, P., Tavener, S., Perez, D., Samothrakis, S., and Colton, S., "A Survey of Monte Carlo Tree Search Methods," IEEE Transactions on Computational Intelligence and AI in Games, Vol. 4, No. 1, 2012, pp. 1-43. https://doi.org/10.1109/TCIAIG.2012.2186810
[53] Hessel, M., Modayil, J., van Hasselt, H., Schaul, T., Ostrovski, G., Dabney, W., Horgan, D., Piot, B., Azar, M., and Silver, D., "Rainbow: Combining improvements in deep reinforcement learning," 32nd AAAI Conference on Artificial Intelligence, AAAI Press, 2018, pp. 3215-3222. URL https://dl.acm.org/doi/10.5555/3504035.3504428.
[54] Lin, L.-J., "Self-improving reactive agents based on reinforcement learning, planning and teaching," Machine Learning, Vol. 8, No. 3-4, 1992, pp. 293-321. https://doi.org/10.1007/BF00992699
[55] Schulman, J., Levine, S., Abbeel, P., Jordan, M., and Moritz, P., "Trust Region Policy Optimization," Proceedings of the 32nd International Conference on Machine Learning, Proceedings of Machine Learning Research, Vol. 37, edited by F. Bach and D. Blei, PMLR, Lille, France, 2015, pp. 1889-1897. URL https://proceedings.mlr.press/v37/schulman15.html.
[56] Schulman, J., Wolski, F., Dhariwal, P., Radford, A., and Klimov, O., "Proximal Policy Optimization Algorithms," ArXiv, 2017. https://doi.org/10.48550/arXiv.1707.06347
[57] Anthony, T., Tian, Z., and Barber, D., "Thinking fast and slow with deep learning and tree search," Proceedings of the 31st International Conference on Neural Information Processing Systems, Curran Associates Inc., 2017, p. 5366-5376. URL https://dl.acm.org/doi/10.5555/3295222.3295288.
[58] Silver, D., Schrittwieser, J., Simonyan, K., Antonoglou, I., Huang, A., Guez, A., Hubert, T., Baker, L., Lai, M., and Bolton, A., "Mastering the game of Go without human knowledge," Nature, Vol. 550, No. 7676, 2017, pp. 354-359. https://doi.org/10.1038/nature24270.
[59] Newborn, M., Computer Chess, ACM Monograph Series, 2014.
[60] Stockfish, N., 2020. URL https://stockfishchess.org/blog/2020/introducing-nnue-evaluation. (accessed July 4, 2025).
[61] Klein, D., "Neural Networks for Chess," arXiv, 2022. https://doi.org/10.48550/arXiv.2209.01506
[62] Silver, D., Huang, A., Maddison, C. J., Guez, A., Sifre, L., van den Driessche, G., Schrittwieser, J., Antonoglou, I., Panneershelvam, V., Lanctot, M., Dieleman, S., Grewe, D., Nham, J., Kalchbrenner, N., Sutskever, I., Lillicrap, T., Leach, M., Kavukcuoglu, K., Graepel, T., and Hassabis, D., "Mastering the game of Go with deep neural networks and tree search," Nature, Vol. 529, 2016, pp. 484-503. https://doi.org/10.1038/nature16961.
[63] Duan, Y., Chen, X., Houthooft, R., Schulman, J., and Abbeel, P., "Benchmarking deep reinforcement learning for continuous control," Proceedings of the 33rd International Conference on International Conference on Machine Learning - Volume 48, JMLR.org, 2016, p. 1329-1338. https://dl.acm.org/doi/10.5555/3045390.3045531
[64] Torrado, R. R., Bontrager, P., Togelius, J., Liu, J., and Perez-Liebana, D., "Deep Reinforcement Learning for General Video Game AI," 2018 IEEE Conference on Computational Intelligence and Games (CIG), IEEE Press, 2018, p. 1-8. https://doi.org/10.1109/CIG.2018.8490422.
[65] Guo, X., Singh, S., Lee, H., Lewis, R., and Wang, X., "Deep Learning for Real-Time Atari Game Play Using Offline Monte-Carlo Tree Search Planning," Advances in Neural Information Processing Systems, Vol. 27, Curran Associates, Inc., 2014. https://papers.nips.cc/paper_files/paper/2014/hash/88bf0c64edabeeb913c378227beef8f9-Abstract.html.
[66] Genesereth, M., and Björnsson, Y., "The International General Game Playing Competition," AI Magazine, Vol. 34, No. 2, 2013, p. 107. https://doi.org/10.1609/aimag.v34i2.2475.
[67] Hochreiter, S., and Schmidhuber, J., "Long Short-Term Memory," Neural Computation, Vol. 9, No. 8, 1997, p. 1735-1780. https://doi.org/10.1162/neco.1997.9.8.1735.
[68] Schmidhuber, J., "Learning to generate subgoals for action sequences," IJCNN-91-Seattle International Joint Conference on Neural Networks, Vol. 2, 1991, p. 453. https://doi.org/10.1109/IJCNN.1991.155375
[69] Schmidhuber, J., and Wahnsiedler, R., "Planning Simple Trajectories Using Neural Subgoal Generators," From Animals to Animats 2, The MIT Press, 1993, p. 195-201. https://doi.org/10.7551/mitpress/3116.003.0027.
[70] Bakker, B., and Schmidhuber, J., "Hierarchical Reinforcement Learning Based on Subgoal Discovery and Subpolicy Specialization," Proceedings of the 8th Conference on Intelligent Autonomous Systems, 2004, pp. 438-445.