兵棋与仿真用于指挥与控制人工智能研发¶
On games and simulators as a platform for development of artificial intelligence for command and control
Vinicius G Goecks (B),Nicholas Waytowich,Derrik E Asher,Song Jun Park,Mark Mittrick,John Richardson,Manuel Vindiola,Anne Logie,Mark Dennison,Theron Trout,Priya Narayanan,Alexander Kott
DEVCOM Army Research Laboratory, USA
First published online March 9, 2022
https://doi.org/10.1177/154851292210832
摘要¶
兵棋与仿真器可以作为执行复杂多智能体、多玩家、不完全信息场景的有价值平台,这些场景与军事应用具有显著相似性:多个参与方管理资源并作出决策,以指挥资产控制地图中的特定区域或消灭对方力量。这些特性吸引了人工智能(AI)领域的关注,因为它们支持在复杂基准上开发算法,并能够对新思想进行快速迭代。AI 算法在诸如 StarCraft II 等实时战略兵棋中的成功,也吸引了军事研究界的关注,旨在将类似技术探索应用于军事对等场景。为弥合兵棋与军事应用之间的联系,本文讨论了过去和当前在如何将兵棋与仿真器结合 AI 算法以模拟军事任务某些方面方面所作的努力,以及这些技术可能对未来战场产生的影响。本文还探讨了虚拟现实与视觉增强系统的发展如何为人类与兵棋平台及其军事对等系统之间的交互开辟新的可能性。
关键词¶
人工智能,强化学习,兵棋推演,指挥与控制,人机接口,未来战场
1. 引言¶
在战争中,预判对手可能行动及其反制后果的能力是一项关键技能。\({ }^1\) 在未来战场与多域作战环境中,这一能力变得更加具有挑战性,因为作战的速度与复杂性很可能超出负责传统、主要依赖人工的指挥与控制(C2)流程的人类指挥参谋的认知能力。诸如国际象棋、扑克和围棋等策略兵棋在一定程度上抽象了 C2 的某些概念。尽管兵棋通常是使用实体地图、标记物和电子表格来计算战斗结果的手工兵棋,\({ }^2\) 但计算机兵棋及现代兵棋引擎(如 Unreal Engine(https://www.unrealengine.com/)和 Unity(https://unity.com/))已经能够自动化模拟复杂战斗及相关物理过程。
计算机兵棋和兵棋引擎不仅适合模拟军事场景,还为开发人工智能(AI)算法提供了有价值的试验平台。诸如 StarCraft II,\({ }^{3-} { }^9\) Dota \(2,{ }^{10}\) Atari,\({ }^{11-13}\) 围棋,\({ }^{14-16}\) 国际象棋,\({ }^{17,18}\) 以及无限注德州扑克(heads-up no-limit poker)\({ }^{19}\) 等兵棋,都被用作训练人工智能体的平台。兵棋产业发展出的另一项与军事领域相关的能力是虚拟现实与视觉增强系统,这些系统可能为指挥员和参谋人员提供更加直观且信息丰富的战场显示方式。
近年来,人们大力探索利用计算机兵棋与仿真引擎的能力来支持军事 C2 规划,原因在于其便于集成 AI 算法(下文将讨论相关示例)。本文所描述的工作重点在于改造不完全信息实时战略(RTS)兵棋及其对应仿真器,以模拟战场场景中的军事资产。此外,本研究旨在推动与 C2 相关的 AI 算法研发工作。这些兵棋与兵棋引擎的灵活性使其能够模拟相当广泛的地形或资产类型。此外,大多数兵棋与仿真器允许以“快于实时”的速度进行战场推演,这一特性对于基于数据的军事应用算法的快速开发与测试尤为理想。
本文结构如下。在“背景与相关工作”部分,我们阐述了基于 AI 的 C2 决策支持工具研究动机,并介绍了若干相关先前工作。特别地,我们论证了利用仿真/兵棋运行所生成的数据进行机器学习,以实现可负担 AI 解决方案的合理性。随后,我们描述两个案例研究。第一个案例中,我们介绍如何改造一个快速且流行的兵棋平台以近似模拟部分真实军事行动,并结合强化学习(RL)算法训练一个“人工指挥员”(即训练后的智能体),指挥蓝军(BLUFOR)对抗敌对红军(OPFOR)。第二个案例研究则描述了在一个更为真实的军事仿真系统中的类似探索。接着,我们讨论在将此类未来技术过渡至真实战场过程中可能面临的常见挑战及其应对方法,并总结关键发现。
本文研究的主要贡献包括两个方面:第一,我们通过实证表明,深度 RL 算法在不使用任何预编码专家知识的情况下,能够显著优于人类与基于条令的基线方法,并完全从经验中学习到有效行为。第二,我们提出并实证验证了一组在军事相关兵棋与战场仿真器中为 C2 训练 AI 算法所需的重要要素与要求。这些成果可视为为构建相关实验与开发系统的研究人员提供的初步建议。
2. 背景与相关工作¶
我们首先定义本文中使用的重要术语。兵棋在本文中被定义为一种主要为手工操作的策略兵棋,使用规则、数据与流程来模拟两个或多个对立方之间的武装冲突,\({ }^{1,20,21}\) 用于训练军事军官并规划军事行动方案(COAs)。这不同于“兵棋”,本文所称兵棋指的是一种完全自动化、用于娱乐的计算机应用程序,具有明确规则与评分系统,以武装冲突模拟作为娱乐形式。同样,“仿真器”在本文中指的是介于兵棋与兵棋之间的混合形式。仿真器是完全自动化的计算机应用程序,旨在真实模拟军事战斗与 COA 的结果,其目的并非娱乐,而是作为辅助军事规划的工具。
关于 C2,我们采用《陆军条令出版物第 3 号—作战》\({ }^{22}\) 中对指挥与控制作战职能的定义,即“相关任务与系统,使指挥员能够同步与融合所有作战力量要素。”类似地,C2 的 AI 支持方法指为辅助人类指挥员,在 C2 过程中提供附加信息或建议的 AI 系统。
过去几十年中,人们提出并研究了多种自动或半自动工具,以支持军事行动的规划与执行决策。美国国防高级研究计划局(DARPA)的 JFACC 项目于 1990 年代后期开展,\({ }^{23}\) 开发了一系列用于联合空战敏捷管理的概念与原型。当时大多数方法涉及在态势持续变化情况下,对各类空中资产的航线与活动进行持续实时优化与再优化。
同样在 1990 年代中后期,陆军资助了 CADET 项目,\({ }^{24}\) 探索将经典分层规划方法适配至对抗环境,将高层战斗草图转化为详细的同步矩阵——这是军事决策制定过程(MDMP)中的关键成果。
2000 年代初,DARPA 启动了 RAID 项目,\({ }^{25}\) 探索多种用于预测敌方作战计划以及动态提出己方战术行动的技术。在当时所探索的技术路径中,博弈求解算法表现最为成功。
在 2000 年代后期,DARPA 的 COMPOEX 项目\({ }^{26}\) 探索了多域及其极为复杂的交互作用——超越传统动能作战,涵盖政治、经济与社会效应。该项目研究通过互联的仿真子模型(主要为系统动力学模型)来辅助高级军政领导在复杂作战环境中规划与执行大规模战役。2010 年代中期,北约一研究小组\({ }^{27}\) 研究了诸如网络域等非传统作战域,探讨通过仿真方法评估网络攻击对任务的影响,并强调了网络、人类与传统物理域之间相互作用的强非线性效应。
上述研究及其他类似方法均存在一些共同且显著的弱点。它们通常需要对问题域进行严格而精确的形式化建模。一旦建立此类形式化模型,往往能够产生有效结果。然而,当需要纳入新的要素(例如新型军事资产或新战术)时,往往需要付出艰难、昂贵且耗时的人工努力来“重构”问题建模并微调求解机制。而现实世界不断涌现新的要素与实体,必须加以考虑。在 1980 年代的基于规则系统中,随着规则数量不断增加(且规则间相互作用往往不可预测),系统变得难以维护。类似地,在基于优化的方法中,为表示现实世界复杂性,需要不断手工添加变量关系与约束(维护成本极高)。在基于博弈的方法中,每个棋子合法动作及其效果的规则将随着越来越多现实因素的加入而变得极其复杂。
简而言之,面向 C2 的 AI 支持方法在问题表示构建与维护方面成本高昂。理想情况下,我们希望系统能够直接从其在真实或仿真世界中的经验中学习问题建模与求解算法,而无需(或仅需少量)人工编程。机器学习,尤其是强化学习(RL),提供了这一前景。
Walsh 等人\({ }^{28,29}\) 研究了军方如何利用机器学习算法在处理大规模数据与提升决策速度方面的能力用于军事规划与 C2。他们分析并评估了 10 种兵棋(如围棋、桥牌、StarCraft II)以及 10 种 C2 流程(如战场情报准备、作战评估、部队指挥程序)的特征。特征示例包括作战节奏、环境变化速率、问题复杂度、数据可获得性、行动结果随机性等。其主要结论指出,现实任务与许多用于开发与展示 AI 系统的兵棋环境存在显著差异,主要因为后者具有固定且明确的规则,往往被 AI 智能体反复利用。
在这些兵棋中,StarCraft II(SC2)是一款 RTS 兵棋,玩家争夺地图控制权与资源。玩家需管理资源以扩展基地、建造单位、升级单位,并同时协调数十个单位击败对手。Vinyals 等人\({ }^5\) 提出了 AlphaStar,这是首个在 SC2 全局兵棋中达到最高竞技水平的 AI 智能体。AlphaStar 在与职业比赛相同约束条件下进行对战。该 AI 通过结合自博弈 RL、多智能体学习与基于数十万专家重放数据的模仿学习实现成功。Sun 等人\({ }^4\) 提出了 TStarBot 智能体,结合 RL 与编码兵棋知识,成为首个击败 SC2 内置规则型 AI 所有难度等级的学习型智能体。Han 等人\({ }^9\) 将其扩展为 TStarBot-X,并对在有限计算资源下训练的智能体进行全面分析。在同样有限资源条件下,Wang 等人\({ }^8\) 提出 StarCraft Commander,该系统使用参数量为 AlphaStar 三分之一、训练时间约为其六分之一的模型,也达到了最高竞技水平。
OpenAI 等\({ }^{10}\) 首次实现 AI 系统击败 Dota 2 电竞世界冠军。Dota 2 是一个部分可观测的五对五 RTS 兵棋,具有高维观测与动作空间。双方争夺地图关键位置并防守各自基地。每个智能体控制具有独特能力的英雄单位,与对方及非玩家单位作战。OpenAI 通过扩展现有 RL 算法(近端策略优化 PPO\({ }^{30}\) 与广义优势估计 GAE\({ }^{31}\)),使用数千个 GPU 训练 10 个月,并采用专门神经网络架构处理长时间跨度任务,成功解决这一复杂问题。
Boron 与 Darken\({ }^{32}\) 研究了利用深度强化学习算法解决基于军事条令的模拟、完全信息、回合制、多智能体、小规模战术交战场景。该网格世界环境模拟进攻场景,RL 智能体控制同质单位移动与攻击,防御方为静态单位,战斗使用确定性与随机 Lanchester 战斗模型\({ }^{33-35}\) 解决。主要结果之一表明,通过调节奖励折扣因子,可以控制学习行为遵循不同战争原则(如集中兵力等)\({ }^{36}\)。
Asher 等人\({ }^{37}\) 将军事相关战术引入模拟的捕食者-猎物追逐任务,使深度 RL 智能体团队可通过能力修改(如诱饵、陷阱、伪装)实施多种战术。此外,该研究团队提出了测量协同的方法\({ }^{38-40}\),为将 AI 智能体整合进人机混编队伍提供框架\({ }^{41,42}\)。
关于基于现有兵棋引擎构建的仿真器,Fu 等人\({ }^{43}\) 将深度 RL 应用于防空作战 C2。基于 Unreal Engine 构建数字战场环境用于 RL 训练。训练设置包括静态与随机对手策略(攻击路线与编队固定或随机)。评估指标包括胜率、战损统计与战斗细节,并与人类专家比较。实验结果表明,深度 RL 智能体在固定与随机对手场景下均取得高于人类专家的胜率。相比之下,本文提出的是一个基于 RL 形式化设计的实时决策与规划系统,可与指挥员协同运行。
在军事仿真器方面,AlphaDogfight Trial 是 DARPA 资助的竞赛\({ }^{44}\),AI 控制模拟 F-16 战斗机与在虚拟现实模拟器中飞行的空军飞行员进行空战。冠军 Heron Systems 设计的 F-16 AI 以 5\(0^{45}\) 的比分击败经验丰富的飞行员。结果表明,基于 AI 的飞行员可提供可能超越人类能力的精确机动。此外,该 F-16 AI 展示了人机协同可能性,使人类飞行员专注高层战略,将低层繁琐战术任务交由 AI 智能体执行。
Schwartz 等人\({ }^{46}\) 描述了一种兵棋支持工具,使用遗传算法对既定己方 COA(军事场景中决策序列)提出修改建议,将问题建模为多任务及其开始时间的任务调度问题。系统整合用户输入以约束可修改任务、起始时间范围、AI 设置,并监控 AI 模拟建议。作者表明,该系统能够生成专家级 COA 建议并支持 MDMP\({ }^{47}\)。
鉴于兵棋、实时复杂战略与多智能体娱乐应用以及军事仿真器的积极成果,将这些算法扩展至军事应用整体是一个具有前景的研究方向,本研究正是对此进行探索。
3. 面向 C2 深度强化学习的兵棋与仿真¶
在本研究中,我们探讨深度强化学习(deep RL)算法是否能够支持未来多域部队的敏捷与自适应 C2,使指挥员与参谋能够迅速且有效地利用稍纵即逝的优势窗口。
为了在 C2 场景中训练 RL 智能体,需要一个运行快速且具备合适接口的仿真器,使学习算法能够运行数百万次仿真步,这通常是当前最先进深度 RL 算法所要求的。\({ }^{48,49}\) 推动我们研究 AI 在 C2 应用中的一个重要动因,是难以找到一个同时具备开发 C2 机器学习算法所需全部特性的仿真器。这些特性包括但不限于:
- 通过应用程序编程接口(API)与仿真器(即环境)进行交互,包括查询环境状态并发送由智能体计算的动作;
- 以快于实时的速度模拟智能体与环境之间的交互;
- 支持仿真并行化,用于分布式训练机器学习智能体,理想情况下可跨多个节点运行;
- 在训练过程中随机化环境条件,以学习更具鲁棒性与泛化能力的 RL 策略;
- 模拟真实作战特性,例如地形、机动性、可视性、通信、武器射程、毁伤效果、射速及其他因素,以逼近真实世界军事场景。
虽然我们未能找到一个开箱即用即可满足所有上述要求的仿真器,但基于兵棋的仿真环境,例如 StarCraft II Learning Environment(SC2LE)\({ }^3\),可以通过改造用于潜在军事 C2 应用中的 AI 算法研究。下文将分别介绍我们如何改造 SC2LE 以及军事仿真器 OpSim,使其成为开发基于 RL 的 C2 人工指挥员的主要平台。
3.1 案例研究:StarCraft II 的军事应用¶
我们开发了一个研究原型 C2 仿真与实验能力体系,其中包含使用 SC2LE \({ }^3\) 构建的模拟战场环境,并通过 RLlib \({ }^{50}\) 与深度 RL 算法接口连接。RLlib 是一个为高性能计算系统上的 RL 提供可扩展软件原语的库。
StarCraft II 为 AI 算法提供了诸多挑战,使其成为适用于兵棋推演、C2 以及其他军事应用的合适仿真环境。例如,该兵棋具有复杂的状态空间与动作空间,单局兵棋可持续数万个时间步,实时可选择数千个动作,并且由于部分可观测性(“战争迷雾”)而引入不确定性。此外,兵棋包含异构资产、某些方面类似军事 C2 的内在控制架构、具有对抗性质的嵌入式目标,以及相较于更复杂仿真系统更为平缓的实现/修改学习曲线。
DeepMind 的 SC2LE 框架\({ }^3\) 将 Blizzard Entertainment 的 StarCraft II 机器学习 API 暴露为 RL 环境。该工具提供对 StarCraft II、本地地图编辑器以及 RL 智能体与兵棋交互接口的访问,使智能体能够获取观测并发送动作。
我们使用 StarCraft II 编辑器实现了 TigerClaw——一个旅级进攻作战场景\({ }^{51}\),在 StarCraft II 仿真环境中生成战术作战场景,如图 1 所示。通过重新设计图标外观,将其替换为军事符号(MIL-STD-2525C),实现兵棋军事化,如图 2 所示。
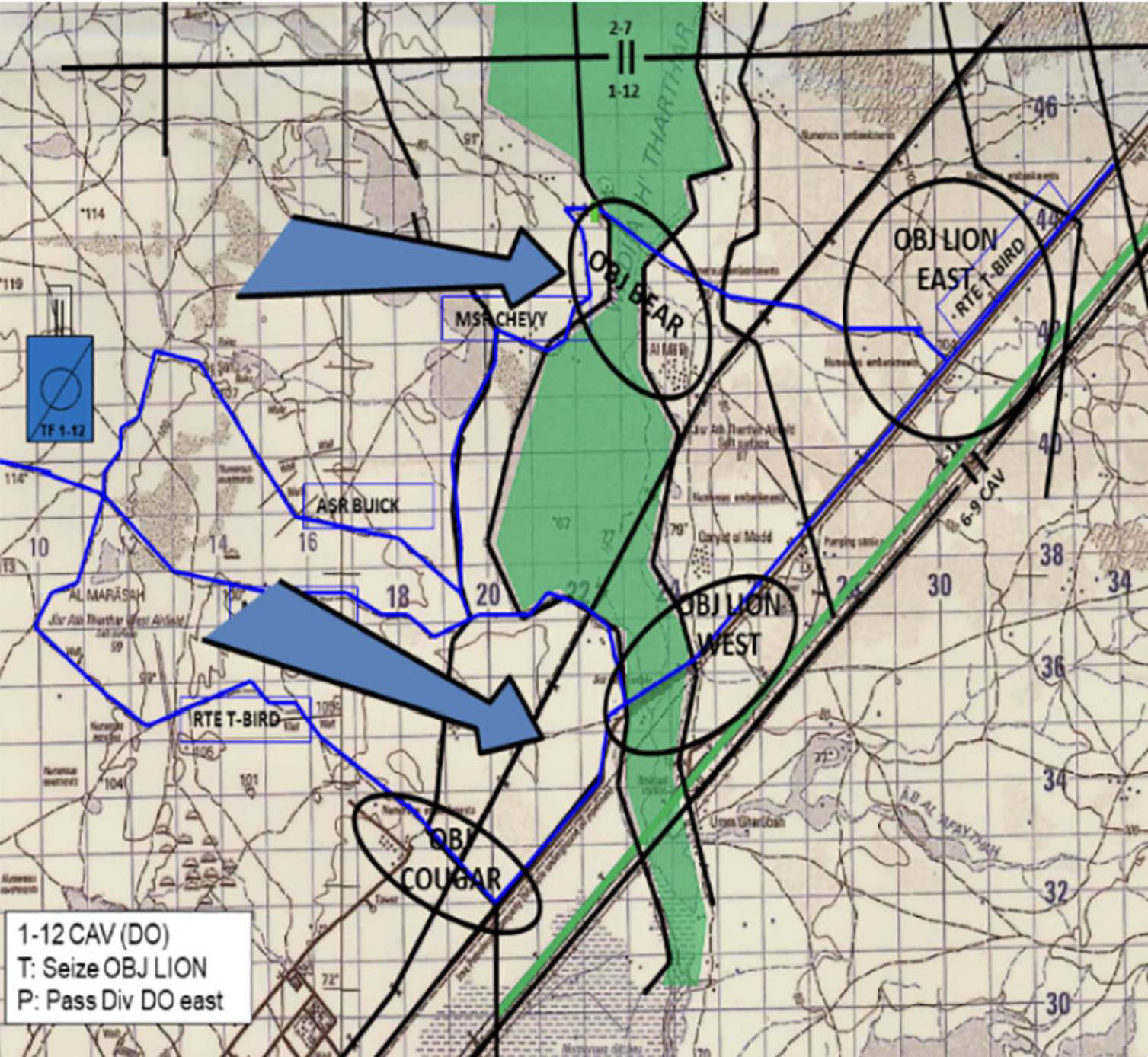
Figure 1. TigerClaw 场景中的作战区域示意图。

Figure 2. 使用 MILSTD2525 符号的 StarCraft II。
在 TigerClaw 场景中,蓝军(BLUFOR)的目标是穿越干涸河道(wadi)地形,消灭红军(Red Force),并控制特定地理位置。这些目标被编码进兵棋评分系统,用于 RL 智能体在不同神经网络架构与奖励驱动属性之间进行基线比较。以下各节介绍我们如何改造地图、单位与奖励机制以适应该军事场景。
3.1.1 地图开发¶
我们使用 StarCraft II 编辑器为 TigerClaw 场景创建了新的 Melee Map。地图尺寸为可用最大规格 256×256 瓦片,采用 StarCraft II 坐标系统。默认地表采用荒地(wasteland)瓦片集,以在视觉上接近 TigerClaw 作战区域的沙漠地形,如图 3 所示。在初始设置完成后,我们使用地形工具对地图进行修改,使其在一定程度上近似真实作战区域。关键地形特征是不可通行的干涸河道,仅在有限位置可通过。

Figure 3. 修改后的 StarCraft II 地图(左图)及其模拟真实作战区域的版本(右图)。
距离尺度转换是场景构建中的重要因素。在初始地图中,我们使用地标之间的已知距离,将 StarCraft II 内部坐标系统中的距离转换为公里以及经纬度坐标。该转换对于在单位改造过程中调整武器射程至关重要,同时也确保与其他需要地理坐标输入的内部可视化工具兼容。
3.1.2 可操作单位修改¶
为模拟 TigerClaw 场景,我们选择了 StarCraft II 中的“幻想”单位,并将其改造以近似模拟真实军事单位能力(尽管较为粗略)。首先复制原始单位,并在编辑器中修改其属性以支持该场景。第一步是修改单位外观,并替换为相应的 MIL-STD-2525C 军事符号,如表 1 所示。
Table I. TigerClaw 单位与 StarCraft II 单位映射关系。
| TigerClaw 单位 | StarCraft II 单位 |
|---|---|
| 装甲 | Siege tank(坦克模式) |
| 机械化步兵 | Hellion |
| 迫击炮 | Marauder |
| 航空力量 | Banshee |
| 炮兵 | Siege tank(攻城模式) |
| 反装甲 | Reaper |
| 步兵 | Marine |
场景中还修改了其他属性,包括武器射程、武器毁伤、单位速度与单位生命值(可承受毁伤量)。武器射程基于公开资料确定,并按地图尺度进行缩放。单位速度依据 TigerClaw 作战命令设定并固定。毁伤与生命值参数为估算值,其指导原则是维持对双方均具挑战性的冲突。由于每个 StarCraft II 单位通常仅具备一种武器,因此难以模拟连级单位所拥有的多样化武器系统。
此外,我们修改蓝军单位,使其除非被玩家或学习智能体明确指令,否则不会主动进攻或防御。对于红军(OPFOR)控制,我们采用两种策略。第一种策略是在每次仿真中执行预设的脚本化 COA(高层行动集合),单位默认攻击性属性决定其如何与蓝军交战。第二种策略是使用 StarCraft II 内置 Bot AI 控制红军执行全面进攻(在编辑器中称为“自杀式攻击”)。内置 Bot 具有 1 至 10 共十个难度等级,等级越高,智能体能力越强。1 级为基础水平,易于击败;10 级为高度复杂的 Bot,甚至使用玩家无法获得的信息(即作弊型 Bot)。此外,在实验中我们切换战争迷雾等环境因素,以研究其影响。
3.1.3 兵棋评分与奖励实现¶
奖励函数是 RL 的关键组成部分,它通过对不同情境给予正或负奖励,控制智能体对环境变化的反应。我们在 StarCraft II 中为 TigerClaw 场景实现了奖励函数,并覆盖了内部默认评分系统。默认评分系统基于单位与建筑的资源价值给予奖励。我们的新评分系统侧重于占领新领土与消灭敌方单位。
奖励机制如下:蓝军穿越干涸河道(河流)奖励 +10 分,撤退则扣除 10 分;摧毁一个红军单位奖励 +10 分,若蓝军单位被摧毁则扣除 10 分。为实现奖励函数,首先需使用 StarCraft II 地图编辑器定义地图中的不同区域与目标。区域为用户定义的地理区域,用于内部触发器计算兵棋评分,如图 4 所示。
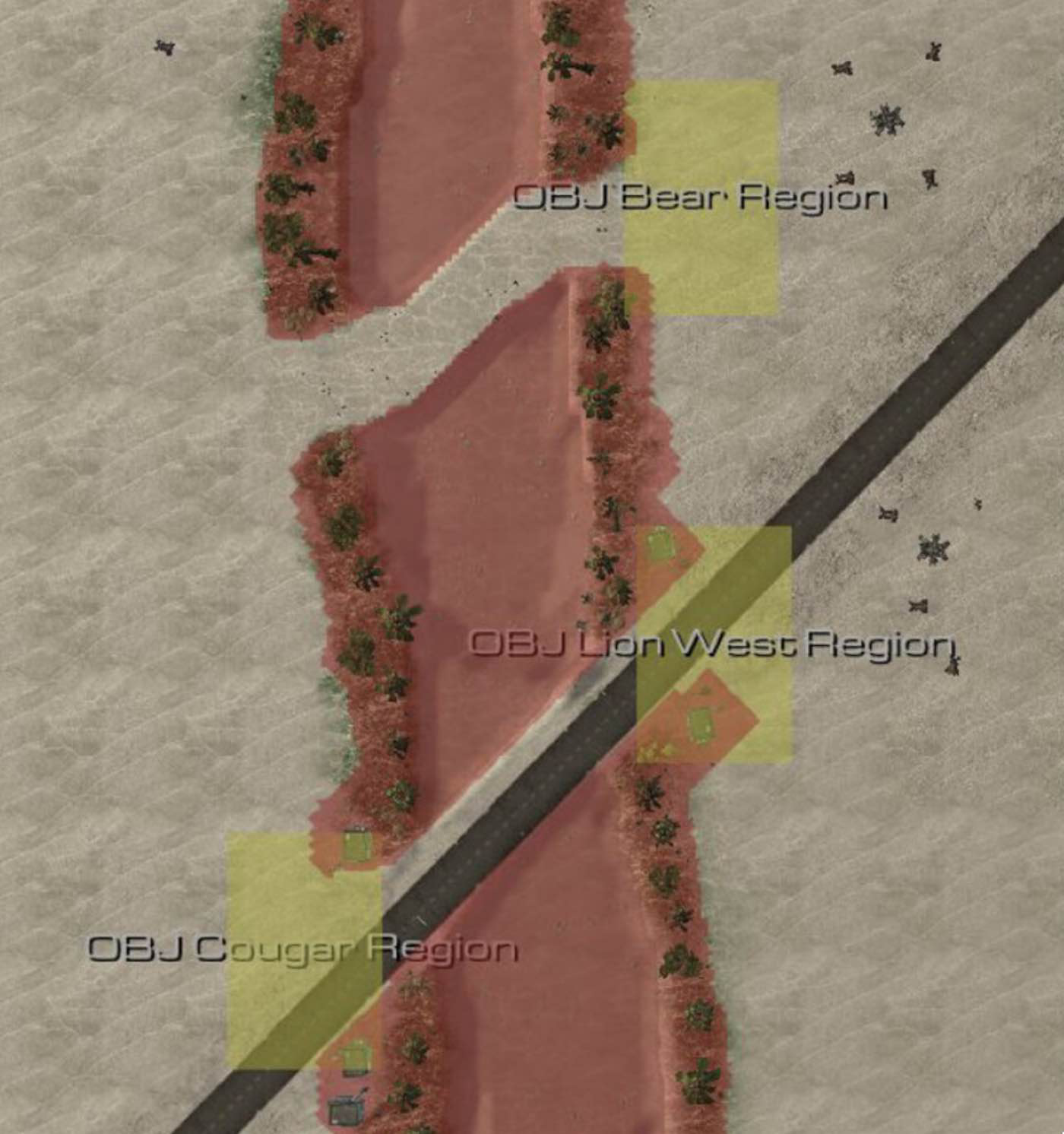
Figure 4. 自定义 TigerClaw 场景中用于奖励函数的区域与目标。
此外,还可根据 TigerClaw 或其他场景中的指挥员意图(Commander’s Intent)或预警命令集成额外奖励要素。理想情况下,奖励函数应引导智能体学习到被军事领域专家(SME)认为合理的最优行为。
3.1.4 深度强化学习结果¶
在自定义的 TigerClaw 地图、单位与奖励函数基础上,我们训练了一个多输入、多输出的深度 RL 智能体,该模型改编自 Waytowich 等人\({ }^7\) 的工作。RL 智能体采用异步优势行动者-评论家(Asynchronous Advantage Actor Critic, A3C)算法\({ }^{52}\) 进行训练。在这一战术版本的 StarCraft II 小型兵棋中,如图 5 所示,状态空间由七个尺寸为 \(64 \times 64\) 的小地图特征层以及 13 个尺寸为 \(64 \times 64\) 的屏幕特征层组成,总计 20 个 \(64 \times 64\) 的二维(2D)图像。此外,还包括 13 个非空间特征,例如玩家资源与建造队列等信息。
小地图与屏幕特征分别通过结构相同的两层卷积神经网络(顶部两行)进行处理,以提取地图全局与局部状态的视觉特征表示。非空间特征通过带非线性激活的全连接层处理。上述三部分输出随后进行拼接,形成智能体完整的状态空间表示。
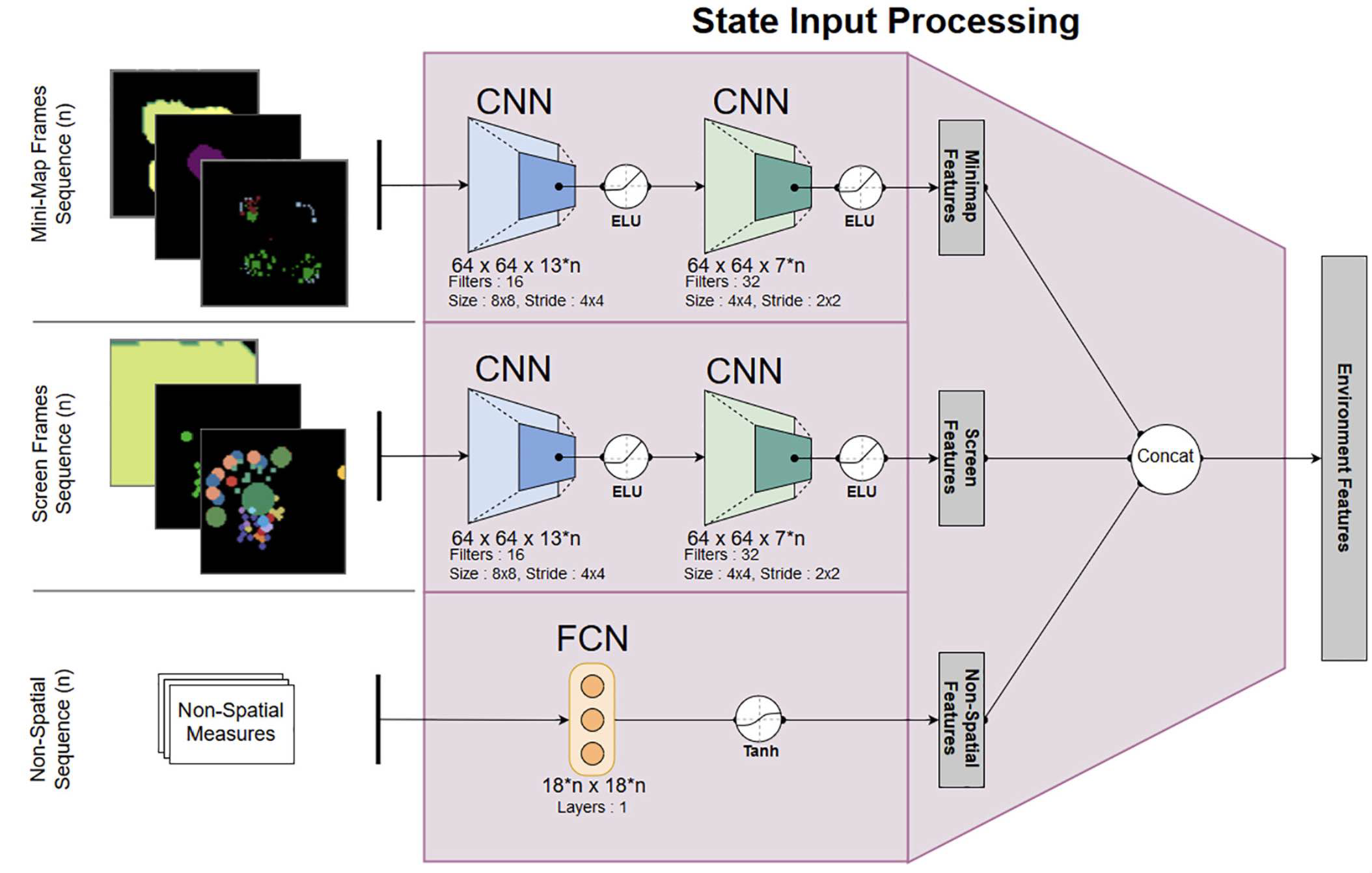
Figure 5. 自定义 TigerClaw 场景的输入处理流程。
在 StarCraft II 中,动作是复合形式的函数,需要参数并指定动作发生在屏幕上的位置。例如,“攻击”动作表示为一个函数,需要屏幕上的 \(x-y\) 攻击位置作为参数。动作空间包括动作标识符(即执行哪种动作)以及两个空间动作(\(x\) 和 \(y\)),后者表示为两个长度为 64 的实值向量,数值范围在 0 到 1 之间,代表动作应执行的屏幕坐标对。
我们使用的 A3C 智能体架构类似于 Atari-net 智能体\({ }^{12}\),这是一个从 Atari 环境改编以适用于 StarCraft II 状态与动作空间的 A3C 智能体。我们对该模型进行了一个小改动,增加了一个长短期记忆(LSTM)层\({ }^{53}\),为模型引入记忆能力,从而提升性能\({ }^{52}\)。完整的 A3C 智能体架构如图 6 所示。
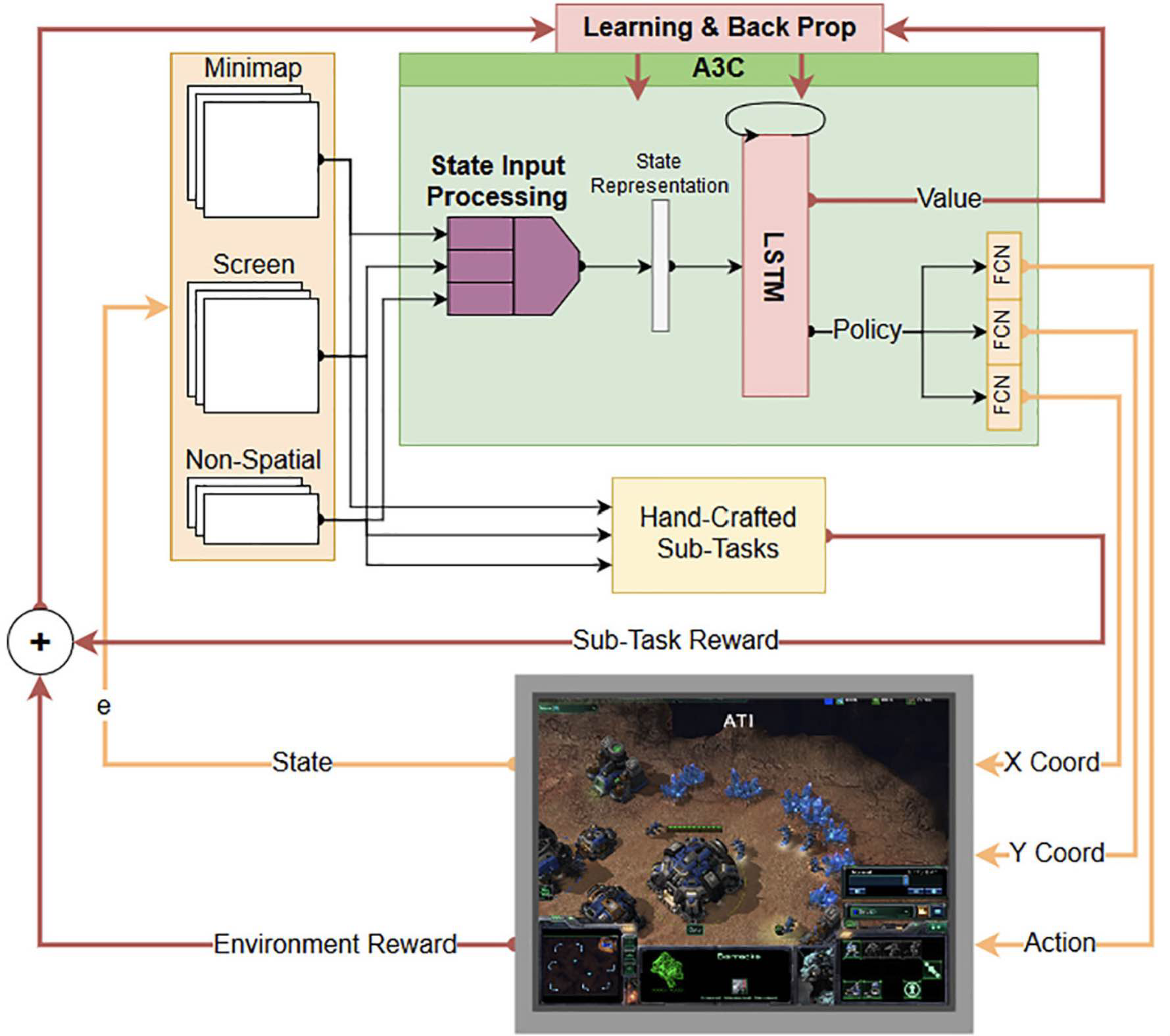
Figure 6. 完整 A3C 强化学习智能体及其与代表 TigerClaw 场景的 StarCraft II 环境连接的示意图。
训练结果表明,该 AI 指挥员不仅能够达到与人类玩家相当的表现,而且在任务表现上略优于人类,同时减少了蓝军(BLUFOR)的伤亡。
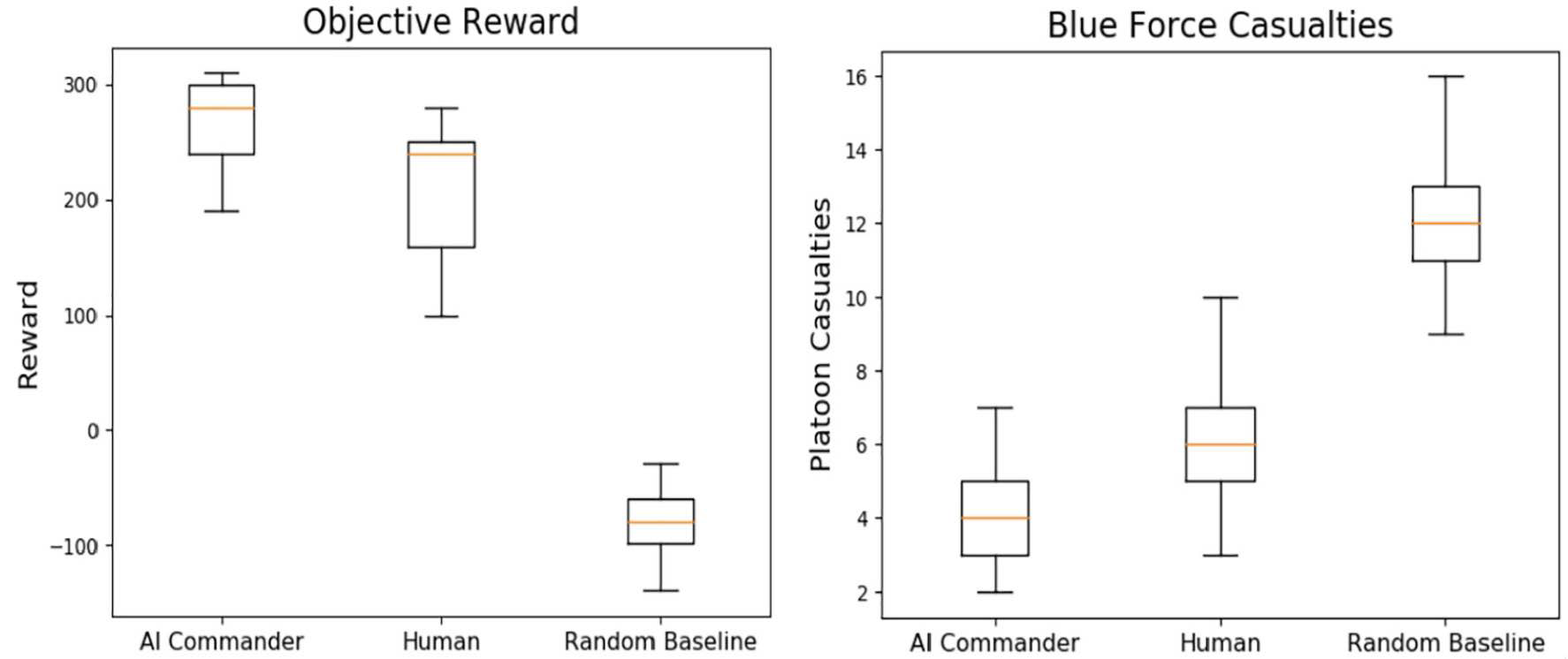
Figure 7. 训练后的 AI 指挥员(A3C 智能体)与人类及随机智能体基线的总奖励与蓝军伤亡对比。AI 指挥员获得的奖励与人类基线相当(略高),同时蓝军伤亡数量更低。
3.2 案例研究:基于 OpSim 的强化学习军事仿真¶
在前述案例研究中描述的 TigerClaw 场景同样在 OpSim\({ }^{54}\) 仿真器中实现。OpSim 是由 Cole Engineering Services Inc.(CESI)开发的决策支持工具,提供规划支持、任务演练、嵌入式训练以及任务执行监控与重规划功能。OpSim 与 SitaWare C4I C2 集成,而后者是指挥所计算环境(Command Post Computing Environment, CPCE)(CPCE 网页:https://peoc3t.army.mil/mc/cpce.php)中的关键组成部分,由 PEO C3T 部署,使各级指挥能够共享态势感知并协调作战行动,因此是一种直接连接作战任务指挥的嵌入式仿真系统。
OpSim 本质上构建为可扩展的基于面向服务架构(SOA)的仿真系统,其运行速度可超过当前先进仿真环境,例如 One Semi-Automated Forces(OneSAF)(OneSAF 网页:https://www.peostri.army.mil/OneSAF)\({ }^{55,56}\) 以及 MAGTF Tactical Warfare Simulation(MTWS)(MTWS 网页:https://coleengineering.com/capabilities/mtws)\({ }^{57}\)。OpSim 设计为可快于实际时间运行,在普通消费级硬件上可在 30 秒内运行 30 次 TigerClaw 任务复现,而若以实时串行方式运行则需 240 小时。OpSim 输出包括对蓝军计划的总体排序,评估指标包括弹药消耗、伤亡、装备损失、燃料使用等。然而,OpSim 最初并非为 AI 应用设计,因此需通过引入接口以运行 RL 算法进行改造。
我们开发了一个 OpenAI Gym\({ }^{58}\) 接口,用于暴露仿真状态并向外部智能体提供仿真控制能力,使其能够为仿真中的特定实体提供动作,以及指定在返回接口响应前应仿真的时间长度。观测空间包含 17 维特征向量,且基于各实体装备传感器的能力呈部分可观测状态。不同于 StarCraft II 环境,我们当前基于 OpSim 的人工 C2 智能体原型尚未使用图像输入或屏幕空间特征。
动作空间主要包括简单机动与交战行为,具体如下:
-
观测空间:毁伤状态、\(x\) 位置、\(y\) 位置、装备损失、武器射程、传感器射程、燃料消耗、弹药消耗、弹药总量、装备类别、最大速度、感知敌对实体、目标距离、目标方向、火力支援、受火状态、交战状态。
-
动作空间:无操作、前进、后退、右移、左移、加速、减速、朝向目标、停止、开火、请求火力支援、接敌反应。
-
奖励函数:友军受损 \((-0.5)\),友军被毁 \((-1.0)\),敌军受损 \((0.5)\),敌军被毁 \((1.0)\),每一步距目标距离 \(-0.01^* \mathrm{~km}\)。
3.2.1 实验结果¶
在 OpSim 环境中开发了两类“人工指挥员”。第一类基于 OpSim 内置的专家计划,由军事领域专家依据条令规则制定。第二类为基于 RL 的 LSTM\({ }^{53}\) 多输入、多输出深度神经网络,采用 A2C 算法\({ }^{52}\) 进行训练。OpSim 的自定义 Gym 接口支持多智能体训练,每一方均可使用规则型或学习型指挥员。
策略网络在高性能计算系统上进行训练,使用 39 个并行工作进程,在 44 小时内收集了 212,000 场仿真战斗。训练模型在某一检查点冻结策略后进行 100 次 rollout 仿真评估,此时蓝军策略的滚动平均奖励为 195,红军为 -317。图 8 提供了 100 次 rollout 仿真中条令规则型与 RL 型指挥员的对比分析结果。结果显示,在与规则型指挥员对抗时,RL 型指挥员能够降低自身伤亡(见 EXPERT 对 RL 与 RL 对 EXPERT 图)。与条令基线相比,兵力更强的蓝军 RL 指挥员将蓝军平均伤亡从约 4 降至 0.4,并将红军伤亡从 5.4 提高至 8.4。该结果通过采用仅与装甲连与战斗步兵连交战的策略实现。蓝军 RL 指挥员学会利用其最具杀伤力的 Abrams 与 Bradley 车辆,同时避免脆弱资产与红军交战,如图 9 所示为一次 rollout 开始与结束的快照。
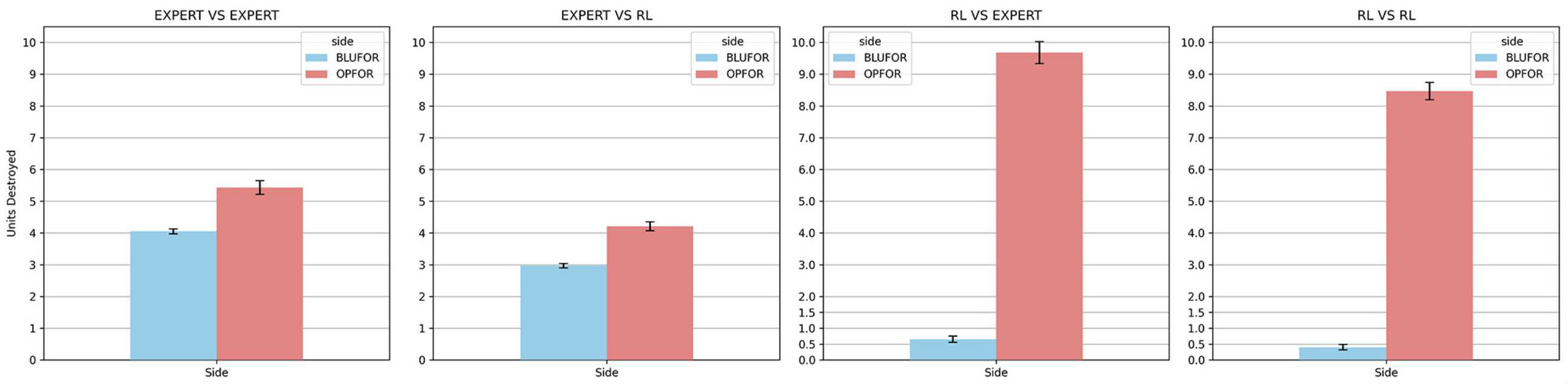
Figure 8. TigerClaw 场景中基于规则(专家)与基于强化学习(RL)指挥员的单位伤亡对比。
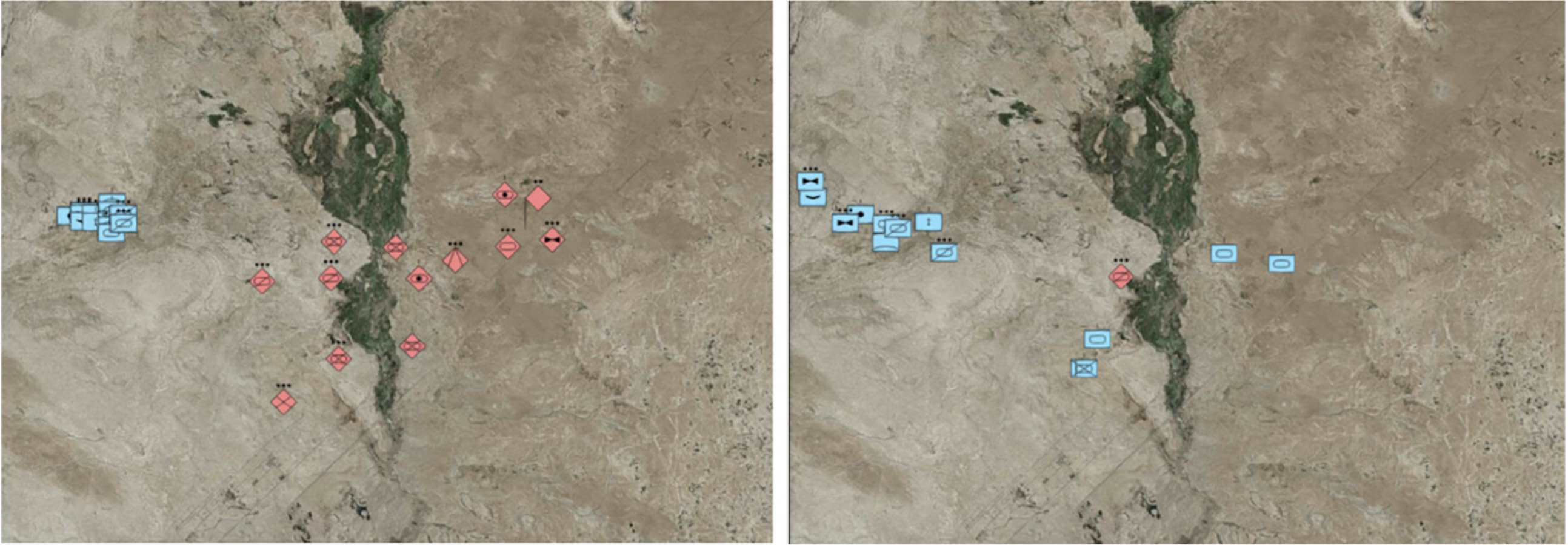
Figure 9. OpSim 中 RL 型指挥员一次 rollout 的开始(左)与结束(右)画面,展示蓝军学习到仅以最具杀伤力单位交战并保护脆弱资产的策略。
4. 面向 C2 的 AI 系统开发的发现与讨论¶
我们的研究强调了在军事相关兵棋与战场仿真器中为 C2 开发 AI 算法训练系统时若干关键要素,包括仿真速度、可扩展性与适应性、RL 智能体对仿真动力学的利用、训练数据多样性、人类操作员如何与 AI 系统交互,以及 RL 智能体超越人类与条令基线的能力。
首先,对于改造后的兵棋与战场仿真器,仿真速度是关键因素。RL 算法通常需要从环境中获取数百万甚至数十亿\({ }^{48,49}\) 数据样本以训练高性能策略,因此快速仿真循环至关重要。在 StarCraft II 实验中,我们使用 35 个 CPU 工作进程,每天可运行 800 万训练步或 12,800 场战斗,但仍不足,因为智能体需要超过 4000 万训练步才能获得令人满意的结果。由于仿真通常持续数日,另一个重要因素是可扩展性。过去十年计算能力的提升推动了 RL 发展,因此 AI 研究仿真器需支持大规模分布式计算。适应性同样重要,仿真器应允许实验设计者灵活建模所需军事任务,包括地形、资产与战争迷雾。
第二,在仿真器中训练 RL 智能体时,由于奖励驱动算法的探索特性,学习型智能体有时会利用仿真动力学漏洞,学习到不现实且通常非设计者预期的行为以最大化奖励\({ }^{59}\)。这种利用往往在训练期间难以察觉,仅在事后仔细分析策略行为时才被发现。例如,在早期实验中,我们发现智能体利用仿真缺陷使装甲单位穿越不可通行地形。从这一意义上讲,RL 亦可作为检测并强化仿真器的一种工具。
第三,在训练流程方面,应包含多样化训练数据,例如不同地形、资产与位置,使学习型人工指挥员能够形成更鲁棒与泛化的策略,以应对现实中的多样性。训练场景应包含多少多样性仍是开放研究问题。在训练过程中,定期将学习型智能体与规则型或条令型指挥员,或其他学习型人工指挥员对抗进行评估,有助于性能提升。训练完成并在测试案例中评估后,我们发现可视化工具对于发现人工指挥员是否学习到非预期行为至关重要,但仍需更丰富工具以深入理解其决策与计划细节。
另一个挑战在于操作界面往往难以获得最终用户认可。为此,可借鉴兵棋产业的头戴式显示设备(HMD),使用户能够在虚拟现实(VR)、增强现实(AR)与混合现实(MR)环境(统称 XR)中交互。陆军已通过 Synthetic Training Environment(STE)(STE 网页:https://asc.army.mil/web/portfolio-item/synthetic-training-environmentste/)与 Integrated Visual Augmentation System(IVAS)(IVAS 网页:https://www.peosoldier.army.mil/Program-Offices/Project-Manager-Integrated-Visual-Augmentation-System/)投资 XR 技术,但高度依赖兵棋产业的技术进步。事实上,许多军事 XR 项目基于 Unity 或 Unreal 引擎开发。本项目已开始将 StarCraft II 仿真的实时数据接入网络化 XR 环境\({ }^{60}\),目标是允许多名分布式用户在沉浸式平台中查看 AI 生成的 COA,并与 AI 及其他人类决策者实时协同交互。
最后,我们发现 RL 至少在所探索的一组案例中,在未获取任何先验人类知识的情况下,能够超越人类与条令基线。这在任务复杂度提高、人类规则难以明确指定时尤为重要。然而,关于所学习策略是否具有人类特征,或是否需要具有人类特征,仍存在开放问题。另一个担忧是,强化学习策略在场景末获得更高奖励时可能愿意牺牲资产,这可能并非人类指挥员可接受的决策。我们通过在奖励函数中对资产损失进行惩罚来缓解该问题,但由于奖励函数还包含其他目标,实际平衡这一设计并不简单\({ }^{59}\)。
5. 结论¶
提升 AI 算法能力对于任务指挥员跟上战争日益增长的速度与复杂性至关重要。我们认为,在未来战场与多域作战场景中,有必要开发敏捷且自适应的 AI 支持工具,其核心假设是:如果 C2 流程仍主要依赖人工操作,未来的信息流与作战节奏很可能超出现有人员编制的能力范围。这包括利用 AI 算法对来自多源的战场信息进行分析,从而准确识别并利用新出现的优势窗口。
在本研究中,我们通过两个案例研究,探索了如何建模部分真实的任务场景,并利用现有(经适当改造的)现成深度 RL 算法训练人工指挥员。我们表明,这类训练得到的算法在不使用任何预编码专家知识的情况下,能够超越人类与基于条令的基线方法,并完全通过经验学习有效行为。此外,我们提出并实证验证了一组在军事相关兵棋与战场仿真器中开发 AI 算法训练系统所需的重要要素与要求,使其成为开展 C2 强化学习工具研究与开发的可行平台。相关工作、StarCraft II 与 OpSim 案例研究的部分内容亦发表于 DEVCOM 陆军研究实验室报告 ARL-TR-9192\({ }^{51}\)。
经费支持¶
作者声明本研究、撰写及/或发表本文获得如下资助支持:本研究由陆军研究实验室资助,并部分在合作协议(W911NF-20-2-0114)框架下完成。本文所包含的观点与结论仅代表作者本人,不应被解释为代表陆军研究实验室或美国政府的官方政策(无论明示或暗示)。美国政府有权为政府用途复制与分发本文重印本,无论其中是否包含版权声明。
ORCID iD¶
Vinicius G Goecks (ID) https://orcid.org/0000-0002-4481-671X
References¶
- Caffrey MB Jr. On wargaming. Newport, Rhode Island: U.S. Naval War College Press.
- Perla PP. The art of wargaming: a guide for professionals and hobbyists. Annapolis, Maryland: Naval Institute Press, 1990.
- Vinyals O, Ewalds T, Bartunov S, et al. StarCraft II: a new challenge for reinforcement learning. arXiv preprint 1708.04782, 2017.
- Sun P, Sun X, Han L, et al. TStarBots: defeating the cheating level builtin AI in StarCraft II in the full game. Corr 2018; abs/180907193.
- Vinyals O, Babuschkin I, Czarnecki WM, et al. Grandmaster level in StarCraft II using multi-agent reinforcement learning. Nature 2019; 575: 350-354. Crossref. PubMed. Web of Science.
- Waytowich N, Barton SL, Lawhern V, et al. Grounding natural language commands to StarCraft II game states for narration-guided reinforcement learning. In: Artificial intelligence and machine learning for multi-domain operations applications, vol. 11006. International Society for Optics and Photonics, p.110060S.
- Waytowich N, Barton SL, Stump E, et al. A narration-based reward shaping approach using grounded natural language commands. In: International conference on machine learning (ICML), workshop on imitation, intent and interaction, 2019.
- Wang X, Song J, Qi P, et al. SCC: an efficient deep reinforcement learning agent mastering the game of StarCraft II. arXiv preprint Arxiv:201213169, 2020.
- Han L, Xiong J, Sun P, et al. TStarBot-X: an open-sourced and comprehensive study for efficient league training in StarCraft II full game. arXiv preprint Arxiv:201113729, 2020.
- Berner C, Brockman G, Chan B, et al. Dota 2 with large scale deep reinforcement learning. Corr 2019; abs/19120 6680.
- Mnih V, Kavukcuoglu K, Silver D, et al. Playing Atari with deep reinforcement learning. arXiv preprint Arxiv:13125602, 2013.
- Mnih V, Kavukcuoglu K, Silver D, et al. Human-level control through deep reinforcement learning. Nature 2015; 518: 529-533. Crossref. PubMed. Web of Science.
- Hessel M, Modayil J, van Hasselt H, et al. Rainbow: combining improvements in deep reinforcement learning. Proc AAAI Conf Artif Intell 2018; 32: 3215-3222.
- Silver D, Huang A, Maddison CJ, et al. Mastering the game of Go with deep neural networks and tree search. Nature 2016; 529: 484-489. Crossref. PubMed. Web of Science.
- Silver D, Schrittwieser J, Simonyan K, et al. Mastering the game of Go without human knowledge. Nature 2017; 550: 354-359. Crossref. PubMed. Web of Science.
- Schrittwieser J, Antonoglou I, Hubert T, et al. Mastering Atari, Go, chess and shogi by planning with a learned model. Nature 2020; 588: 604-609. Crossref. PubMed. Web of Science.
- Campbell M, Hoane AJ Jr, Hsu Fh. Deep blue. Artif Intell 2002; 134: 57-83. Crossref. Web of Science.
- Hsu FH. Behind deep blue: building the computer that defeated the world chess champion. Princeton, NJ: Princeton University Press, 2002.
- Brown N, Sandholm T. Superhuman AI for heads-up no-limit poker: libratus beats top professionals. Science 2018; 359: 418-424. Crossref. PubMed. Web of Science.
- Gortney WE. Department of defense dictionary of military and associated terms. Technical report, Joint Chiefs of Staff, Washington, DC, 2010.
- Burns S, Della Volpe D, Babb R, et al. War gamers handbook: a guide for professional war gamers. Technical report, US Naval War College, Newport, RI, 2015. Crossref.
- Army U. Army doctrine publication no. 3-0: operations. Washington, DC: Headquarters, Department of the Army, 2019.
- Kott A. Advanced technology concepts for command and control. Bloomington, IN: Xlibris Corporation, 2004.
-
Kott A, Ground L, Budd R, et al. Toward practical knowledge-based tools for battle planning and scheduling. In: The Eighteenth national conference on artificial intelligence (AAAI-02) was held July 28 - August 1, 2002, at the Shaw conference center in Edmonton, Alberta, Canada pp. 894-899. Menlo Park, CA: American Association for Artificial Intelligence.
-
Ownby M, Kott A. Reading the mind of the enemy: predictive analysis and command effectiveness. Technical report, Solers Inc., Arlington, VA, 2006.
- Kott A, Corpac PS. COMPOEX technology to assist leaders in planning and executing campaigns in complex operational environments. Technical report, Defense Advanced Research Projects Agency, Arlington, VA, 2007.
- Kott A, Ludwig J, Lange M. Assessing mission impact of cyberattacks: toward a model-driven paradigm. IEEE Sec Priv 2017; 15: 65-74. Crossref. Web of Science.
- Walsh M, Menthe L, Geist E, et al. Exploring the feasibility and utility of machine learning-assisted command and control: volume 1, findings and recommendations. Santa Monica, CA: RAND Corporation, 2021.
- Walsh M, Menthe L, Geist E, et al. Exploring the feasibility and utility of machine learning-assisted command and control: volume 2 , supporting technical analysis. Santa Monica, CA: RAND Corporation, 2021.
- Schulman J, Wolski F, Dhariwal P, et al. Proximal policy optimization algorithms. arXiv preprint Arxiv:170706347, 2017.
- Schulman J, Moritz P, Levine S, et al. High-dimensional continuous control using generalized advantage estimation. arXiv preprint Arxiv:150602438, 2015.
- Boron J, Darken C. Developing combat behavior through reinforcement learning in wargames and simulations. In: 2020 IEEE conference on games (CoG), Osaka, Japan, 24-27 August 2020, pp. 728-731. New York: IEEE.
- Lanchester FW. Aircraft in warfare: the dawn of the fourth arm. London: Constable Limited, 1916.
- Washburn A. Lanchester systems. Technical report, Naval Postgraduate School, Monterey, CA, 2000.
- MacKay NJ. Lanchester combat models. arXiv preprint Math/0606300, 2006.
- Corps UM. Marine Corps doctrinal publication 1-0. Washington, DC: Marine Corps Operations, 2011.
- Asher DE, Zaroukian E, Barton SL. Adapting the predator-prey game theoretic environment to Army tactical edge scenarios with computational multiagent systems. arXiv preprint Arxiv:180705806, 2018. Crossref.
- Asher D, Garber-Barron M, Rodriguez S, et al. Multi-agent coordination profiles through state space perturbations. In: 2019 international conference on computational science and computational intelligence (CSCI), Las Vegas, NV, 5-7 December 2019, pp. 249-252. New York: IEEE.
- Zaroukian E, Rodriguez SS, Barton SL, et al. Algorithmically identifying strategies in multi-agent game-theoretic environments. In: Artificial intelligence and machine learning for multi-domain operations applications, 14-18 April 2019, Baltimore, Maryland, United States, vol. 11006, p. 1100614. Bellingham, WA: SPIE.
- Asher DE, Zaroukian E, Perelman B, et al. Multi-agent collaboration with ergodic spatial distributions. In: Artificial intelligence and machine learning for multidomain operations applications II, 27 April-9 May 2020, Online Only, California, United States, vol. 11413. Bellingham, WA: SPIE, p. 114131N.
- Barton SL, Waytowich NR, Asher DE. Coordination-driven learning in multi-agent problem spaces. arXiv preprint Arxiv:180904918, 2018.
- Barton SL, Asher D. Reinforcement learning framework for collaborative agents interacting with soldiers in dynamic military contexts. In: Next-generation analyst VI, 15-19 April 2018, Orlando, Florida, United States, vol. 10653, pp. 106503. Bellingham, WA: SPIE.
- Fu Q, Fan CL, Song Y, et al. Alpha C2 - an intelligent air defense commander independent of human decision-making. IEEE Access 2020; 8: 87504-87516. Crossref. Web of Science.
- AlphaDogfight trials go virtual for final event, https://www.darpa.mil/news-events/2020-08-07 (accessed 17 May 2021).
- AlphaDogfight trials foreshadow future of human-machine symbiosis, https://www.darpa.mil/news-events/2020-08-26 (accessed 17 May 2021).
- Schwartz PJ, O'Neill DV, Bentz ME, et al. AI-enabled wargaming in the military decision making process. In: Artificial intelligence and machine learning for multidomain operations applications II, vol. 11413, 27 April-9 May 2020, Online Only, California, United States, p. 114130H. Bellingham, WA: SPIE.
- Reese PP. Military decisionmaking process: lessons and best practices. Technical report, Center for Army Lessons Learned, Fort Leavenworth, KS, 2015.
- Espeholt L, Soyer H, Munos R, et al. IMPALA: scalable distributed deep-RL with importance weighted actor-learner architectures. In: International conference on machine learning, 10-15 July 2018, Stockholmsmässan, Stockholm Sweden, pp. 1407-1416. PMLR.
- Kapturowski S, Ostrovski G, Dabney W, et al. Recurrent experience replay in distributed reinforcement learning. In: International conference on learning representations. New Orleans, Louisiana, United States, 6-9 May 2019. ICLR.
- Liang E, Liaw R, Nishihara R, et al. RLlib: abstractions for distributed reinforcement learning. In: Dy J, Krause A (eds) Proceedings of the 35th international conference on machine learning, proceedings of machine learning research, vol. 80. 10-15 July 2018, Stockholmsmässan, Stockholm Sweden, PMLR, pp. 30533062.
- Narayanan P, Vindiola M, Park S, et al. First-year report of ARL director's strategic initiative (FY20-23): Artificial Intelligence (AI) for Command and Control (C2) of Multi Domain Operations. Technical Report ARL-TR-9192. Adelphi, MD: Adelphi Laboratory Center, DEVCOM Army Research Laboratory (US), 2021.
- Mnih V, Badia AP, Mirza M, et al. Asynchronous methods for deep reinforcement learning. In: Volume 48: International conference on machine learning, 20-22 June 2016, New York, USA, pp. 1928-1937. PMLR.
- Hochreiter S, Schmidhuber J. Long short-term memory. Neur Comput 1997; 9: 1735-1780. Crossref. PubMed. Web of Science.
- Surdu JR, Haines GD, Pooch UW. OpSim: a purpose-built distributed simulation for the mission operational environment. Simul Ser 1999; 31: 69-74.
- Wittman RL Jr, Harrison CT. OneSAF: a product line approach to simulation development. Technical report, MITRE Corp., Orlando, FL, 2001.
- Parsons D, Surdu J, Jordan B. OneSAF: a next generation simulation modeling the contemporary operating environment. In: Proceedings of Euro-simulation interoperability workshop. 27-29 June 2005, Toulouse, France, Citeseer.
- Blais CL. Marine air ground task force (MAGTF) tactical warfare simulation (MTWS). In: Proceedings of winter simulation conference, Lake Buena Vista, FL, 1114 December 1994, pp. 839-844. New York: IEEE.
- Brockman G, Cheung V, Pettersson L, et al. OpenAI Gym. arXiv preprint Arxiv:160601540, 2016.
- Amodei D, Olah C, Steinhardt J, et al. Concrete problems in AI safety. arXiv preprint Arxiv:160606565, 2016.
- Dennison MS, Trout TT. The accelerated user reasoning for operations, research, and analysis (AURORA) cross-reality common operating picture. Technical Report, Combat Capabilities Development Command, Adelphi, MD, 2020.
作者简介¶
Vinicius G Goecks 是 DEVCOM 陆军研究实验室人类研究与工程局的一名博士后研究员,致力于开发能够从人类交互中学习的新型机器学习算法。他获得美国德克萨斯农工大学(Texas A&M University)的航空航天工程博士与硕士学位,以及巴西南马托格罗索联邦大学(Universidade Federal de Mato Grosso do Sul)的电气工程学士学位。
Nicholas Waytowich 是 DEVCOM 陆军研究实验室的机器学习研究科学家,目前驻扎于马里兰州阿伯丁试验场(Aberdeen Proving Grounds)。他于 2010 年获得北佛罗里达大学机械工程学士学位,于 2013 年获得电气与计算机工程硕士学位,并于弗吉尼亚州 Old Dominion University 获得生物医学工程博士学位。他运用多种机器学习技术,其专长与研究兴趣包括强化学习、人机回路学习(human-in-the-loop learning)、多智能体建模,以及通过利用人类交互提升 AI 的性能与计算效率。
Derrik E Asher 是 DEVCOM 陆军研究实验室计算与信息科学局的一名研究心理学家。他是陆军“利用学习实现与士兵智能交互的智能体(Agents Leveraging Learning for Intelligent Engagement with Soldiers, ALLIES)”研究项目的首席研究员。
Song Jun Park 是隶属于陆军未来司令部(Army Futures Command)的 DEVCOM 陆军研究实验室计算与信息科学局高级计算分支的研究人员。
Mark Mittrick 自 2003 年起任职于位于阿伯丁试验场的美国陆军研究实验室,担任计算机科学家。在此之前,他于 2003 年获得 Wilkes University 计算机科学学士学位,并在工作期间于 2009 年获得 Towson University 硕士学位。他在计算机科学领域撰写并合著了多篇技术报告。
John Richardson 是美国陆军作战能力发展司令部(DEVCOM)陆军研究实验室的计算机科学家。
Manuel Vindiola 是 DEVCOM 陆军研究实验室计算与信息科学局的认知科学家,参与陆军的计算科学、强化学习与类脑计算(neuromorphic computing)研究。
Anne Logie 是隶属于陆军未来司令部的 DEVCOM 陆军研究实验室研究人员。
Mark Dennison 是美国 DEVCOM 陆军研究实验室西部分部的跨现实(cross-reality)研究人员,支持军事信息科学核心能力建设。他负责一个应用研究项目,旨在为陆军网络跨职能团队提供跨现实通用作战图景(common operating picture)。他获得加利福尼亚大学欧文分校(University of California, Irvine)的心理学博士学位、认知神经科学硕士学位以及心理学学士学位。
Mark Dennison 是美国 DEVCOM 陆军研究实验室西部分部的跨现实研究人员,支持军事信息科学核心能力建设。他负责一个应用研究项目,旨在为陆军网络跨职能团队提供跨现实通用作战图景。他获得加利福尼亚大学欧文分校的心理学博士学位、认知神经科学硕士学位以及心理学学士学位。
Theron Trout 是隶属于陆军未来司令部的 DEVCOM 陆军研究实验室研究人员。
Priya Narayanan 是 DEVCOM 陆军研究实验室计算与信息科学局的研究机械工程师。她负责“面向多域作战(MDO)C2 的 AI”项目,这是 ARL 主任战略倡议的一部分,旨在为陆军开发下一代 AI 赋能的指挥与控制系统。
Alexander Kott 是陆军研究实验室(ARL)的首席科学家,该实验室隶属于美国陆军未来司令部。此前,他曾担任美国国防高级研究计划局(DARPA)的项目经理。他于 1989 年在宾夕法尼亚州匹兹堡大学(University of Pittsburgh)获得博士学位。