面向近距离空战中人工智能智能体战术的全局可解释性¶
Emre Saldiran , Mehmet Hasanzade (D), Gokhan Inalhan (D) 和 Antonios Tsourdos (D)
英国克兰菲尔德大学航空、交通与制造学院,Bedford MK43 0AL;a.tsourdos@cranfield.ac.uk (A.T.)
发表日期: 2024年5月21日
摘要¶
本文探讨了一种针对利用强化学习训练的空战智能体的可解释性系统的开发,从而回应了空战这一动态而复杂领域中的关键需求。空战具有安全关键性,不仅要求性能提升,还需要对人工智能(AI)的决策过程进行深入理解。尽管AI已广泛应用于空战,但对AI智能体决策的全面解释仍存在缺口,而这对于实现有效整合和建立对其行为的信任至关重要。我们的研究构建了一个专门为空战环境下训练的智能体设计的可解释性系统。该系统结合强化学习与奖励分解方法,对智能体在各种战术情境下的决策进行阐释。这种透明性使人们能够细致理解智能体的行为,从而揭示其战略偏好与作战模式。研究结果表明,该系统能够有效识别智能体在不同空战场景中的战术优势与劣势。这一认知对于调试和优化智能体性能至关重要,并确保AI智能体在预期环境下的最优运行。研究所得的见解凸显了可解释性在提升AI技术融入空战系统中的关键作用,从而有助于更为知情的战术决策,并推动空战策略的潜在发展。
关键词: 空战;可解释性;强化学习;奖励分解
1. 引言¶
近年来,人工智能(AI)驱动的自主系统(Autonomous Systems, ASs)在现实场景中的应用迅速增长,展现出了高度复杂和新颖的行为。这一扩展涵盖了不同领域,包括大型空战飞行器 [1] 和较小的自主远程驾驶航空系统(Remotely Piloted Aircraft Systems, RPASs)[2],它们利用AI提升操作自主性与效能。然而,这些进展突显了自主系统中对可解释性的关键需求 [3]。可解释性的重要性不仅在于帮助用户理解,还在于建立用户、开发者与政策制定者之间的信任。此外,在安全关键应用(如自主空战智能体)中,可解释性的作用更为重要。如文献 [4,5] 所示,可解释性与验证、认证和适应性一道,是AI驱动自主系统可信性的支柱之一,尤其是在高风险安全关键环境下。可解释性的作用在于向用户呈现AI行为背后的理由,使其能够建立更高质量的心理模型。形式上,心理模型是“人们基于其现实世界经验所构建的内部表征” [6]。通过提供对AI行为动机的洞察,可解释性使用户能够构建更高质量的心理模型,从而促进更高效的人机协作。尽管可解释性AI方法在医疗、司法和金融等领域取得了显著进展 [7],但其在AI驱动的空战智能体中的应用仍相对未被深入探索。在空战环境中,飞行员需要在高度动态且充满挑战的环境下进行高频率的连续决策。可解释性能够通过辅助发现和优化新战术来提升AI在空战中的整合程度,同时也能增强对AI应用的整体信任。
本研究的主要目标是回应AI驱动自主系统(ASs)在可解释性上的关键需求,特别是在空战等高风险安全关键环境中。本研究的立足点在于,尽管AI已显著提升了各领域的操作能力,但其在空战等复杂场景中的应用仍因缺乏决策透明性与可解释性而受到制约。总体目标是通过开发能够使AI行为可理解和可靠的方法,来提升信任度与人机协作效率。通过聚焦于这一方面,本研究旨在为可信AI这一更广泛的研究领域做出贡献,而可信AI正是当前自主技术快速发展的时代中的核心关注点。
随着人工智能(AI)的不断进步,对可信和透明的AI系统的需求愈发凸显。可解释人工智能(Explainable Artificial Intelligence, XAI)作为一个关键领域应运而生,旨在弥补AI决策过程中透明性与可理解性之间的差距。采用深度学习(Deep Learning, DL)方法的一类AI系统在其核心使用多层神经网络(Neural Network, NN)来解决一些最复杂的问题,从分类到自动驾驶。然而,透明性的缺失源于这些深度神经网络的使用及其固有的“黑箱”特性。为了解决这些问题,已经发展出一些方法,例如 [8] 提出的LIME方法,它能够为AI系统做出的某一分类预测提供局部解释。该解释展示了每个特征对结果分类的贡献,从而为用户提供了有关AI系统偏好的洞察。与LIME方法类似,[9] 提出了SHAPLEY,它利用Shapley值识别单个特征对模型输出的贡献。在解释视觉类AI系统方面也取得了一些进展,如显著性图(saliency map)[10] 和 GradCAM [11]。
深度学习方法的最新成功也惠及了强化学习(Reinforcement Learning, RL)这一AI分支。深度强化学习方法在多种应用中表现出巨大成功,从玩Atari和棋类游戏 [12,13] 到复杂的现实机器人应用,包括手部操作 [14]、无人机空中特技飞行 [15] 以及冠军级别的无人机竞速 [16]。
利用强化学习生成空战战术已在文献中被广泛研究。空战战术是指飞行员在即时交战过程中为获得对敌优势而执行的特定机动或动作。 [17] 的一项重要研究探索了深度确定性策略梯度(Deep Deterministic Policy Gradient, DDPG)在训练RL智能体中的应用,从而在视距内(Within-Visual-Range, WVR)空战中取得了显著的性能提升。另一项研究 [18] 深入探讨了多智能体强化学习(Multi-Agent Reinforcement Learning, MARL)在建模涉及多架飞机的复杂合作空战策略中的应用,展示了RL在复杂场景中的潜力。文献 [19] 使用分层强化学习(Hierarchical Reinforcement Learning, HRL)将战斗任务分解为可管理的子任务,从而简化了训练与决策过程。文献 [20] 研究了基于模型的强化学习(model-based RL)在加快收敛和提高样本效率方面的有效性,从而改善了空战智能体在动态环境中的表现。最后,文献 [21] 应用了先进的深度强化学习技术——近端策略优化(Proximal Policy Optimization, PPO)与软演员-评论家(Soft Actor-Critic, SAC)并比较了它们的性能。基于深度强化学习方法开发空战智能体也在DARPA AlphaDogFight试验中得到探索 [1]。
尽管深度强化学习方法取得了巨大成功,但它们同样因神经网络的黑箱特性而存在可解释性不足的问题。近年来,解释这些RL智能体行动背后的动机逐渐受到关注。然而,该领域尚未成熟到能够对不同解释类型形成统一的定义和分类。多篇综述采用不同方法对可解释强化学习(Explainable RL, XRL)方法进行分类 [22-24]。这些分类大体可以分为解释的范围与来源两个方面。范围包括全局可解释性与局部可解释性,来源则包括内在可解释性与外在可解释性。此外,还存在策略简化方法,即将深度神经网络简化为决策树或线性回归模型 [25,26]。然而,策略简化方法往往牺牲性能来换取可解释性。当决策树深度增加以匹配性能时,其规模也会变得过大,从而抵消可解释性的优势。局部解释是对给定状态下智能体当前行为的解释,而全局解释则对更广泛的状态提供解释。内在解释是来自模型本身的解释,如决策树;而外在方法则在模型之外提供解释。
因果解释方法被提出以回答“如果……会怎样”的问题,从而提供关于行为与结果状态或事件之间关系的洞察。然而,这些方法依赖于对因果模型的理解,即将特定行为与其结果联系起来 [27]。关于在连续状态博弈中发现因果结构的研究已有所开展,但这种方法要求在解释方法中理解环境模型,示例解释揭示了游戏微分方程中的关系 [28]。将因果解释应用于空战背景中面临特别的挑战,这是由于状态空间的高维性与动态性,以及多智能体之间相互作用带来的复杂性,每个智能体还遵循不同的策略。
在文献 [29] 中,作者提出了“预期结果”的概念,其中信念图(belief map)与Q函数一同训练以实现解释目的。尽管文中给出了数学证明,说明信念图能够真实表征用于决策的Q函数,但该研究未能解释其与直接模拟Q函数的区别,以及如何真正为智能体的决策过程提供解释。此外,该方法仅限于表格化环境,因此不适用于空战环境中的连续动态。
HIGHLIGHTS方法被提出用于总结智能体行为,以帮助人们评估这些智能体的能力 [30]。该总结性解释通过计算状态重要性值得出,状态重要性值表示在多个仿真运行中每个状态下最高与最低Q值的差异,旨在通过关键状态的简要片段提供全局解释。这一方法已应用于显著性图 [31] 和奖励分解 [32],并通过用户研究验证其有效性。在 [32] 中,作者强调了奖励分解在传达智能体偏好方面的有效性,同时指出HIGHLIGHTS方法的贡献有限。研究还提到,当观察动态视频而非静态图像时,辨别奖励分解变得更加困难 [31,32]。尽管基于状态的全局策略总结方法能够对智能体行为提供一定洞察,但其解释受限于随机初始化仿真运行中访问的有限独特状态数量。此外,这类解释往往带有轶事性质,因此不能被视为智能体整体策略的代表。
影响预测器(influence predictor)的概念在 [33] 中被定义,其中针对每种奖励类型单独训练一个网络,并使用奖励值的绝对值作为输入。一项人工评估研究表明,与每个状态仅提供Q值相比,参与者认为影响预测器显著更有用。论文还得出结论,尽管所提出的方法提高了参与者的理解,但所研究的解释方法中没有一种能够获得较高的信任评分。
奖励分解方法被提出用于通过将标量奖励值拆分为语义上有意义的奖励类型,从而解释智能体的决策过程,这使得可以分析各奖励类型对给定状态下所选动作的贡献 [34,35]。奖励分解已被证明在离散状态与动作空间场景中有效提升非AI专家的理解与信任,特别是在简单棋类游戏中 [36]。然而,这些应用主要限于简单游戏。在 [32,33,36] 中进行的人类评估研究表明,以分解奖励的形式展示智能体的期望值能够帮助用户形成更好的心理模型,并更好地评估智能体的偏好。这些研究还得出结论,解释方法并不存在“一刀切”的方案,而是依赖于具体的环境与任务。
本研究的主要目标是开发一个专门为空战中利用强化学习训练的AI智能体设计的可解释性框架。该系统旨在揭示AI智能体的决策过程,从而展现其在不同战术情境下的偏好与作战模式。通过这种方式,研究力求识别AI战术的优势与劣势,从而实现更有效的调试与性能优化。最终目标是确保AI智能体不仅能实现最优性能,还能以一种可解释、可理解的方式运行,从而弥合先进AI能力与其在空战环境中实际应用之间的鸿沟。
我们在可解释强化学习(Explainable Reinforcement Learning, XRL)研究中的贡献体现在以下几个方面。首先,我们通过战术区域将局部解释扩展为全局解释,从而在不同空战场景下提供智能体决策过程的更广阔视角。其次,我们引入了一种奖励分解的可视化解释方法,为智能体的决策过程提供了一种创新的视觉解读手段。第三,通过将我们的方法应用于空战环境,我们展示了其在识别主导奖励类型及其在战术区域中的相对贡献方面的有效性,从而揭示了智能体的决策过程。我们基于战术区域的全局解释方法使得对智能体优先级与决策理由有了更深入的理解。可视化解释方法则进一步增强了这种理解,使复杂的偏好模式更易于获取与解释。通过在空战领域应用这些方法,我们展示了其适用性,并突出了潜在的优化方向与人类期望的契合点。这一系列工作为XRL领域带来了重要进展,提供了强有力的工具来解释、调试和优化复杂动态环境中的AI智能体。
本文余下部分组织如下:第2节提供背景信息,详细介绍空战环境,包括其状态空间、动作空间与奖励函数,并概述深度Q网络(Deep Q Network, DQN)、奖励分解方法及训练细节。第3节深入讨论可解释性,包括局部解释、战术区域内的全局解释、全局解释在空战环境中的应用,以及全局可视化解释方法。最后,第4节给出讨论,第5节给出本文结论。
2. 方法论¶
在如空战这般复杂的领域中融入可解释性,需要对主题有全面的理解。这需要一种系统工程的视角,聚焦于三个关键方面:首先,设计语义上有意义的奖励函数,从而确保其能够反映人类直观理解的目标;其次,构建能够近似飞行员感知能力的状态空间,从而实现飞行员能够识别的自然环境表征;第三,精简动作空间以减轻计算负担,从而使得决策不仅高效,而且在认知上具有合理性。这一全面策略旨在弥合AI决策过程与人类理解之间的鸿沟,从而提升系统在现实空战场景中的可用性与有效性。
在本节中,我们介绍了用于开发和验证框架的方法论,以解释强化学习(Reinforcement Learning, RL)智能体在空战仿真中的决策过程。我们首先回顾了先前的研究,这些研究启发我们致力于创建可解释的空战RL智能体。在已有知识的基础上,我们定义了空战仿真环境,该环境能够用于AI智能体的训练与评估。这包括对状态空间、动作空间以及专门设计的奖励函数的全面解释,以促进系统的可解释性。我们给出了深度Q网络(Deep Q Network, DQN)训练算法的细节,使智能体能够通过与环境交互学习最优策略。此外,我们将奖励分解的概念融入DQN算法,以解释智能体的决策过程,并提供对其偏好的更好理解。我们还提供了训练细节,包括参数设置、环境条件以及为保证可复现性而使用的开源库参考。图1所示的流程图展示了本研究所遵循的方法论,从而说明了在开发可解释强化学习空战智能体过程中不同阶段的顺序步骤与相互联系。以下的可视化表示提供了所采取步骤的高层概览。

图1. 可解释强化学习智能体开发过程的总体概览。
2.1. 背景¶
对空战自主性的追求推动了人工智能(AI)应用的重大进展,特别是通过强化学习(Reinforcement Learning, RL)训练能够执行复杂机动的智能体。从历史上看,由于空战环境的动态性和非线性特征,对灵活机动飞机的控制一直是一个相当大的挑战。自20世纪中期以来,已有大量研究致力于制定解决格斗交战问题的战术 [37]。一些研究提出了基于规则的技术,也称为知识编码方法,在这种方法中,专家利用其经验为不同场景生成特定的反制机动 [38]。该系统采用基于规则的方法从预先建立的清单中选择机动动作,这也被称为基本飞行动作(Basic Flight Maneuver, BFM)。选择是通过考虑编码的专家条件语句来完成的。一项具有里程碑意义的研究 [39] 表明,这类机动的精确控制可以通过现代控制理论有效实现,即采用嵌套的非线性动态反演(Nonlinear Dynamic Inversion, NDI)和高阶滑模(Higher-Order Sliding Mode, HOSM)技术。这一发现为在仿真环境中利用离散动作形式的简化基本飞行动作来控制飞机运动奠定了基础。
在这些基础见解的启发下,我们的研究进一步创建了一个复杂的三维环境,以训练RL智能体在机动中表现出色。飞行的复杂动力学与空战的复杂性相结合,需要一个既受控又逼真的平台,使智能体能够学习并优化其策略。通过开发这一3D训练环境,我们能够生成轨迹图,如图2所示,展示了智能体有效导航和执行战斗战术的能力。然而,我们的先前研究 [40] 揭示了RL智能体性能的不一致性。尽管从对称的初始条件开始,在与自身对抗时,智能体在不同空战区域中表现出了不一致的优势,如图3所示。这些发现促使我们探索如何将可解释性融入这些RL智能体的决策过程中。

图2. 一个空战智能体对抗智能体的示例对局,起始于3000米间隔的中立位置,速度为 \(150 \mathrm{~m} / \mathrm{s}\)。

图3. 随着起始位置变化的胜利评估。初始速度为 \(150 \mathrm{~m} / \mathrm{s}\)。绿色、灰色和红色分别代表胜利、平局和失败。
为应对这一AI驱动的空战战术生成问题中的可解释性挑战,我们认识到需要将操作环境从三维简化为二维。这一战略性简化不仅降低了计算负担,更重要的是增强了智能体决策过程的清晰度与可解释性。通过聚焦于二维环境并使用较小的离散动作集,我们旨在揭示AI在空战场景中所采用的潜在策略与逻辑。本文将深入探讨在这一简化二维背景下引入可解释性框架的方法论与意义,从而为理解智能体的战术推理提供洞察,并在不同的空战战术区域中透明化其操作逻辑。
2.2. 空战环境¶
本节介绍空战环境的一个子部分。该子部分包括简化的飞机数学模型,以降低计算量。此外,还涵盖了状态空间、动作空间与奖励函数的选择,以促进空战智能体的可解释性。
空战环境中使用的飞机数学模型采用了简化的三自由度(3DOF)飞机动力学 [41],并增加了可变速度,其表示如下:
其中,\(\Delta V_{c}\) 和 \(\Delta \chi_{c}\) 分别为指令速度增量与航向角增量;\(K_{V}\) 和 \(K_{\chi}\) 分别为速度与航向角增益;\(V\) 和 \(\chi\) 分别为速度与航向角状态;\(x\) 和 \(y\) 表示惯性坐标系下的位置状态。这些变量的几何表示如图4所示。我们使用航空航天符号表示坐标系,其中 \(X\) 轴指向上方,\(Y\) 轴指向右方。根据右手定则,\(\chi\) 从 \(X\) 轴起始为0,并按顺时针方向增加。速度向量 \(\mathbf{V}\) 上的上标 agent 和 target 分别表示自身飞机和目标飞机的速度向量,单位为米/秒。LOS 表示视线(Line of Sight)向量,定义为从自身飞机质心 \((x, y)^{\text{agent}}\) 指向目标飞机质心 \((x, y)^{\text{target}}\) 的向量,单位为米。变量 ATA 与 AA 的定义将在下一小节给出。文献 [39] 中讨论的先进控制技术允许更精细的飞机控制,从而使这一简化模型能够表征广泛的机动。通过调节控制输入 \(\Delta V_{c}\) 与 \(\Delta \chi_{c}\),可以构造复杂的空战机动。用于模拟真实飞机的模型参数的限制与取值在训练细节部分中给出。
2.2.1. 状态空间¶
在文献中,不同的状态空间被用于RL智能体的训练。在DARPA竞赛中,除了飞机之间的相对位置和角度之外,还已知敌机的角速度 [19]。在 [21] 中,他们使用了相同的状态空间,但排除了目标飞机的欧拉角信息。在本文中,与我们之前的研究 [40,42] 类似,我们使用了更小的状态空间,以模拟人类飞行员有限的感知能力,从而创建一个更真实、更具相关性的可解释性环境。状态空间仅包含相对测量信息,不包含目标飞机的特定信息。

图4. 天线指向角(Antenna Train Angle, ATA)、态势角(Aspect Angle, AA)和视线向量(Line of Sight, LOS)的几何表示。
在定义状态空间之前,我们介绍空战环境中常用的角度和其他测量量。LOS向量、ATA角、AA角和速度向量的几何表示如图4所示。
视线(Line of Sight, LOS)向量定义为从智能体飞机质心 \((x, y)^{\text {agent }}\) 指向目标飞机质心 \((x, y)^{\text {target }}\) 的向量。该测量量表示目标与智能体飞机的距离。LOS向量在惯性坐标系下定义,并被旋转到智能体飞机的局部机体坐标系下,其中 \(x\) 轴与智能体速度向量对齐,公式如下:
其中,\(\chi^{\text {agent }}\) 是智能体的航向角,\((L O S_{x}, L O S_{y})\) 是惯性坐标系中LOS向量的分量,\((d_{x}, d_{y})\) 是在智能体局部坐标系下定义的LOS向量分量,LOS为该向量的模。
天线指向角(Antenna Train Angle, ATA)定义为从智能体飞机速度向量 \(\mathbf{V}^{\text {agent }}\) 起始到LOS向量的夹角,按顺时针方向增加。该量表示智能体飞机指向目标飞机的程度。若ATA角为 \(0^{\circ}\),则表示智能体飞机正对目标飞机;若为 \(180^{\circ}\),则表示其正背向目标飞机。ATA角公式为:
其中,\(\mathbf{V}^{\text {agent }}\) 与LOS分别表示智能体速度向量与LOS向量。
态势角(Aspect Angle, AA)定义为从LOS向量到目标飞机速度向量 \(\mathbf{V}^{\text {target }}\) 的夹角,按顺时针方向增加。该量表示目标飞机指向智能体的程度。若AA角为 \(0^{\circ}\),则表示目标飞机背向智能体;若为 \(180^{\circ}\),则表示目标飞机正对智能体。AA角公式为:
其中,\(\mathbf{V}^{\text {target }}\) 表示目标速度向量。
最后,相对航向角定义为从智能体速度向量到目标速度向量的夹角。该量表示每架飞机的相对速度方向。相对航向角公式为:
结合以上所有公式,状态空间写作如下:
2.2.2. 低层动作¶
我们可以利用简单的低层动作(例如向前加速和在右转时减速)来构造复杂的空战机动。为此,我们定义了八个离散动作。此外,还加入了一个“不做任何动作”,表示速度和方向保持不变,从而总共形成九个动作。完整的动作空间如表1所示。在每次迭代中,智能体从动作空间列表中选择一个编号,相应的航向角增量和速度增量命令会输入飞机模型。这些动作由表2中给出的速度增量和航向角的最大值和最小值组合而成,分别对应于公式 (1) 和 (2)。动作列表写作:
其中每个元素对应于表1中的动作。
表1. 动作空间
| No | 机动动作 | 航向 | 速度 |
|---|---|---|---|
| 1 | 右转加速 | 1 | 1 |
| 2 | 右转保持 | 1 | 0 |
| 3 | 右转减速 | 1 | -1 |
| 4 | 左转加速 | -1 | 1 |
| 5 | 左转保持 | -1 | 0 |
| 6 | 左转减速 | -1 | -1 |
| 7 | 保持加速 | 0 | 1 |
| 8 | 保持 | 0 | 0 |
| 9 | 保持减速 | 0 | -1 |
2.2.3. 奖励函数¶
奖励函数是智能体在环境中评估其动作及其有效性的重要工具,它在决定智能体空战能力方面发挥着关键作用。因此,必须谨慎设计奖励函数,以增强模型的学习与适应过程。奖励函数的设计是塑造RL智能体行为的关键因素,它通过整合环境状态的不同方面(例如结合ATA角和LOS距离,以鼓励智能体在优化接近性的同时保持对目标的视觉接触)为复杂性提供潜力。然而,过于复杂的公式可能会削弱系统的可解释性,因为由此驱动的期望行为可能难以解释。基于这一认识,我们必须设计一种语义上有意义的奖励函数,以确保其对系统可解释性的贡献,同时还能有效促进智能体的能力发展。挑战在于平衡这些考量,确保奖励函数既能引导智能体朝着理想行为发展,又能保持直观可理解,从而增强整体系统的可解释性。
在本研究中,我们设计了一个由三个主要参数组成的综合奖励函数,以准确刻画交战飞机之间的态势动态。这三个参数包括 \(ATA\) 角、\(AA\) 角以及LOS向量,如图4所示。
\(ATA\) 角衡量了我方飞机相对于指向对手的LOS向量的朝向。它评估了智能体飞机的进攻位置,其中 \(ATA\) 角接近零表示最佳交战对准,我方飞机正对敌机。
\(AA\) 角衡量了目标飞机相对于LOS向量的朝向。该指标对于判断目标飞机相对我方飞机的姿态至关重要。较小的 \(AA\) 角表示我方处于敌机后方的最佳进攻位置;而较大的 \(AA\) 值(接近180度)则表示不利位置,敌机正对我方,从而需采取防御姿态。
LOS参数量化了两架飞机之间的距离,是武器交战可行性的关键指标。它确保目标飞机处于适合攻击的范围内,但又不至于过近以致威胁到我方飞机。
总的标量奖励计算为各单项奖励的线性组合之和:
其中 \(w_{i}\) 为每个奖励类型的权重,且这些权重之和 \(\sum w_{i}\) 等于1。一个示例奖励函数在权重 \(w_{1}=0.4, w_{2}=0.4, w_{3}=0.2\) 的情况下如图5所示。

图5. 随空战状态变化的ATA、AA和LOS奖励函数值。
2.3. 深度Q网络¶
我们使用深度Q网络(Deep Q Network, DQN)来训练我们的RL智能体 [43]。DQN是一种结合深度神经网络与Q学习的强化学习算法 [44],Q学习是一种在马尔可夫决策过程中学习最优策略的常用方法。DQN的关键思想是利用深度神经网络近似Q函数,而Q函数通过贝尔曼方程计算。贝尔曼方程将状态-动作对的最优Q值表示为即时奖励与下一状态-动作对折扣Q值之和:
其中,\(\mathbb{E}\) 表示期望回报,\(s\) 为当前状态,\(a\) 为所选动作,\(r\) 为即时奖励,\(\gamma \in[0,1]\) 为折扣因子,\(s^{\prime}\) 为下一状态,\(a^{\prime}\) 为下一状态中选择的动作。DQN算法使用经验回放和目标网络来稳定学习过程并改进Q值函数的收敛性。Q值函数通过最小化预测Q值与目标Q值之间的均方误差进行学习。DQN的损失函数定义为:
其中,\(y=\left(r+\gamma \max _{a^{\prime}} Q^{-}\left(s^{\prime}, a^{\prime} ; \theta^{-}\right)\right)\) 为更新后的目标值,\(\mathcal{D}\) 为回放缓冲区。\(\theta\) 和 \(\theta^{-}\) 分别为当前Q函数与目标Q函数的神经网络参数。神经网络参数使用随机梯度下降的ADAM优化器 [45] 更新,更新公式为:
其中,\(\alpha\) 为学习率,\(\nabla_{\theta} L(\theta)\) 为损失函数关于 \(\theta\) 的梯度。
训练完成后,智能体的策略被构造为选择最大化期望回报的动作:
DQN算法的完整描述如算法1所示。公式 (13) 的状态空间、表1的动作空间以及公式 (18) 的奖励函数用于通过DQN训练空战智能体。奖励权重与飞机模型的数值在训练细节部分给出。

算法1 解析
DQN算法的总体思路可以用“利用深度学习的感知能力,并通过两大创新机制解决强化学习中的训练稳定性问题”来概括。
具体来说,其思路分为以下三个核心层面:
1. 核心基础:用神经网络替代传统Q表
传统的Q学习算法使用一张表(Q-Table)来存储每个状态下每个动作的Q值。但当状态空间非常大时(比如处理像素级的游戏画面),这张表会变得无限大,根本无法存储和查询。
- DQN的思路:放弃Q表,转而训练一个深度神经网络(Q网络)。这个网络接收环境的“状态”(如游戏截图)作为输入,直接输出每个可选动作的Q值。这利用了深度学习强大的特征提取和函数拟合能力,解决了“维度灾难”问题。
2. 关键创新一:经验回放 (Experience Replay)
直接用智能体与环境实时交互的数据来训练神经网络,会遇到两个问题:一是数据前后高度相关(连续的游戏帧非常相似),二是每个经验只用一次就丢弃,造成数据浪费。
- DQN的思路:建立一个“经验回放池”。智能体与环境交互产生的经验(状态、动作、奖励、新状态)先存入池中。训练时,随机从池中抽取一小批经验来学习。这样做带来了两大好处:
- 打破数据相关性:随机采样打乱了数据的时间顺序,使样本满足独立同分布的假设,让神经网络训练更稳定。
- 提高数据利用率:一条经验可以被反复抽取和学习,提升了学习效率。
3. 关键创新二:目标网络 (Target Network)
在更新Q网络时,我们需要一个“目标Q值”作为监督信号。如果计算这个目标Q值的网络就是我们正在更新的那个Q网络,就会产生一个“追逐自己尾巴”的问题:目标在不断变动,导致训练过程非常不稳定,容易发散。
- DQN的思路:引入一个结构完全相同但参数更新滞后的“目标网络”。在计算目标Q值时,使用这个相对固定的目标网络。而我们主要训练的Q网络则负责追赶这个稳定的目标。目标网络的参数会周期性地、缓慢地从主Q网络复制而来。这相当于将不稳定的“追逐”问题,变成了稳定的“逼近”问题,极大地提升了训练的稳定性。
综上,DQN的总体思路就是,将强化学习的Q学习框架与深度神经网络相结合,并创造性地引入了“经验回放”和“目标网络”这两个关键机制,有效解决了直接结合所带来的训练不稳定问题,最终实现了一个能够在高维度状态空间(如视觉输入)中成功学习复杂策略的强大算法。
算法流程详解
算法流程详解¶
整个算法可以分为两个主要阶段:初始化 和 主循环(智能体与环境交互和学习)。
第一部分:初始化 (第1-4行)¶
在训练开始前,需要准备好几个关键组件:
-
第1行:初始化经验回放池 (Replay Memory)
- 创建一个内存空间
D,用来存储智能体的“经验”。每条经验是一个四元组(状态, 动作, 奖励, 下一个状态)。这个池子有固定的大小N。 - 作用:打破数据之间的连续相关性。如果智能体学一步就更新一次网络,那么数据前后关联性太强,训练会不稳定。有了经验池,我们可以随机抽取一批旧经验来学习,就像人类“回忆”过去的事情一样,这样训练更有效。
- 创建一个内存空间
-
第2行:初始化Q网络
- 创建一个深度神经网络
Q,并随机初始化它的权重参数θ。这个网络用来预测在某个状态下,执行某个动作的Q值。
- 创建一个深度神经网络
-
第3行:初始化目标网络 (Target Network)
- 创建另一个结构完全相同但参数独立的神经网络
Q⁻,称为“目标网络”。 - 作用:在计算目标Q值时(即第18行),如果使用一个不断变化的网络来估算目标,会导致训练目标不稳定,就像追逐一个移动的目标一样。因此,我们用一个“旧的”、固定一段时间的Q网络(即目标网络)来计算目标值,让学习过程更稳定。开始时,它的权重
θ⁻直接从Q网络复制而来。
- 创建另一个结构完全相同但参数独立的神经网络
-
第4行:初始化环境状态
- 将环境(比如游戏)重置到初始状态
s₀。
- 将环境(比如游戏)重置到初始状态
第二部分:主循环 (第5-22行)¶
这是一个持续进行的循环,智能体在环境中不断地探索、行动、学习,直到达到设定的训练步数 T。
-
第5行:开始主循环
-
第6-11行:ε-贪心策略 (Epsilon-Greedy Strategy) - 如何选择动作
- 这是为了平衡“探索”(Exploration)和“利用”(Exploitation)。
- 第6行:生成一个0到1之间的随机数。如果这个数小于
ε(epsilon),就执行“探索”。 - 第7-8行:“探索”意味着不按当前最优策略来,而是完全随机地选择一个动作。这有助于智能体发现新的、可能更好的策略。
- 第9-10行:“利用”意味着如果随机数不小于
ε,就按照当前Q网络的判断,选择能产生最高Q值的那个动作aₜ。这是当前学到的最优策略。 ε的值通常会随着训练的进行而逐渐减小,意味着早期多探索,后期多利用。
-
第12行:与环境交互
- 智能体在环境中执行选定的动作
aₜ,环境会反馈一个新的状态sₜ₊₁和一个即时奖励rₜ。
- 智能体在环境中执行选定的动作
-
第13行:存储经验
- 将刚刚发生的这一幕
(sₜ, aₜ, rₜ, sₜ₊₁)作为一个经验存入回放池D中。
- 将刚刚发生的这一幕
-
第14-19行:从经验池中学习
- 第14行:从回放池
D中随机抽取一小批(minibatch)旧的经验。 - 第15-19行:计算目标Q值
yⱼ。这是学习的关键,即我们希望Q网络预测的值应该是什么。- 如果下一个状态
sⱼ₊₁是终止状态(比如游戏结束),那么未来的总回报就是当前得到的奖励rⱼ。 - 如果不是终止状态,目标值
yⱼ由两部分组成:当前奖励rⱼ+ 未来最大回报的折现值。未来的最大回报由目标网络Q⁻预测得出,γ(gamma) 是一个0到1之间的折扣因子,表示未来的奖励没有当前的奖励重要。
- 如果下一个状态
- 第14行:从回放池
-
第20行:更新Q网络
- 计算“损失”(Loss),即Q网络对当前状态和动作的预测值
Q(sⱼ, aⱼ; θ)与我们刚刚计算出的“目标值”yⱼ之间的差距(通常是均方误差)。 - 通过梯度下降算法,调整Q网络的权重
θ,使得它的预测值向着目标值靠近。
- 计算“损失”(Loss),即Q网络对当前状态和动作的预测值
-
第21行:更新目标网络
- 训练不是每一步都更新目标网络,而是周期性地(比如每隔几百或几千步)将Q网络的权重
θ"软更新"(或直接复制)到目标网络Q⁻的权重θ⁻上。这里的公式θ⁻ = τθ + (1-τ)θ⁻是一种软更新,τ是一个很小的数,意味着每次只把一小部分新学到的知识融合到目标网络中。
- 训练不是每一步都更新目标网络,而是周期性地(比如每隔几百或几千步)将Q网络的权重
-
第22行:循环结束
综上,简单来说,DQN算法就是让一个智能体在一个虚拟环境中“玩耍”。它通过ε-贪心策略来决定是尝试新动作还是做自己认为最好的动作。每次行动后,它会把经历存到经验回放池。训练时,它会像“看录像”一样随机抽取过去的经历来学习,并利用一个独立的目标网络来稳定学习目标,最终通过梯度下降更新自己的“大脑”(Q网络),从而变得越来越“聪明”。
2.4. 奖励分解¶
在传统的强化学习方法中,奖励信号通常表示为一个标量值,如公式 (18) 所示。这种表示方式缺乏区分不同奖励类型贡献的细粒度,从而忽略了从各奖励类型中生成的显式可解释性。奖励分解通过为每种奖励类型采用独立的深度Q网络(DQN)来解决这一限制。这一方法能够精确评估各奖励类型对智能体决策过程的贡献。借助奖励分解,我们可以通过比较不同状态下各奖励类型的Q值来展示一种奖励类型相对于另一种奖励类型的重要性。动作的选择首先通过对与不同奖励类型相关的各DQN的Q值求和,然后选择具有最高累计Q值的动作。这一方法有效避免了 [46] 中指出的“公地悲剧”问题。
描述最优分解Q值的贝尔曼方程写作即时奖励与下一状态-动作对折扣Q值之和:
其中符号 \(\mathbb{E}, s, a, s^{\prime}, a^{\prime}\) 与DQN中定义一致,\(c\) 为奖励分量索引,\(Q_{c}\) 表示仅考虑奖励类型 \(r_{c}\) 的Q值。
我们采用双DQN训练方法,以避免原始DQN算法中过度乐观的价值估计 [47]。分解DQN的损失函数定义为:
其中,更新的目标值 \(y_{c}\) 定义为:
不同于原始DQN,目标Q值函数使用的下一状态动作 \(a^{\prime}\) 定义为:
即不再使用目标Q值函数中的最佳动作,而是使用原始Q值函数在下一状态 \(s^{\prime}\) 中选择的动作。神经网络权重使用ADAM优化器 [45] 更新,更新公式为:
训练完成后,给定状态-动作对的Q值计算为:
对于每个分量级别的Q值,动作-价值对计算为:
其中,\(k\) 表示可用动作总数。选择动作的策略函数定义为:
遵循策略 \(\pi(s)\) 的总Q值写作:
最终,遵循策略 \(\pi(s)\) 的分量级别Q值写作:
遵循策略 \(\pi(s)\) 的这些分量级Q值函数的向量定义为:
其中 \(n\) 表示分解考虑的分量总数。公式 (33) 中的向量元素表示当智能体在状态 \(s\) 遵循策略 \(\pi(s)\) 时,每种奖励类型 \(r_{c}\) 的期望结果。通过分析与相应奖励类型相关的Q值,我们能够推断出智能体在语义上有意义的奖励类型方面的期望,从而提供其决策过程背后逻辑的洞察。
奖励分解的双DQN算法的完整描述如算法2所示。带奖励分解的双DQN算法在训练时使用了与前文DQN部分所描述的相同状态空间、动作空间和奖励函数。

算法2解析
算法2是一个更高级的强化学习算法,名为“带奖励分解的双重深度Q网络(Double Deep Q-Network with Reward Decomposition)”。
这个算法在经典的DQN基础上集成了两个重要的改进:奖励分解 (Reward Decomposition) 和 双重DQN (Double DQN),旨在解决更复杂的问题并提升训练的稳定性和效果。
核心思想
1. 奖励分解 (Reward Decomposition)
在很多复杂的任务中,智能体获得的奖励可能由多个不同的子目标或来源构成。例如,在一个游戏中,奖励可能同时来自于“得分”、“生存”和“收集物品”。
- 传统DQN的局限:传统DQN将所有来源的奖励加在一起,学习一个单一的、总的Q值函数。这样做可能会让学习变得困难,因为网络需要弄清楚一个复杂的、混合的奖励信号。
- 此算法的思路:将总奖励信号分解成多个独立的组成部分(
C个)。然后,为每一个奖励部分c单独训练一个对应的Q网络Q_c和目标网络Q_c⁻。- 好处:这让每个网络可以专注于学习一个更简单、更明确的子任务。在做决策时,再将所有网络的Q值加起来,得到一个总的Q值来指导行动。这被称为“信度分配”(Credit Assignment),即更容易判断哪个行为对哪个子目标有贡献。
2. 双重DQN (Double DQN)
- 传统DQN的局限:在计算目标Q值时,传统DQN使用同一个目标网络来“选择”未来最好的动作并“评估”该动作的价值(
max Q⁻)。这会导致一个被称为“最大化偏差”的问题,即Q值被系统性地过高估计,从而影响策略的质量。 - 此算法的思路:将“动作选择”和“价值评估”解耦。
- 用主Q网络(
Q_c)来选择在下一个状态下最好的动作a'。 - 用目标网络(
Q_c⁻)来评估这个被选定动作的价值。 - 这样做可以有效减轻Q值的过高估计问题,使学习过程更稳定、更准确。
- 用主Q网络(
算法流程详解
第一部分:初始化 (第1-7行)
- 第1行:确定奖励信号被分解成了
C个部分。 - 第2行:初始化一个标准的经验回放池
D。 - 第3-6行:这是一个循环,为每一个奖励部分
c分别进行初始化:- 第4行:创建一个主Q网络
Q_c,并随机初始化其权重θ_c。 - 第5行:创建一个目标网络
Q_c⁻,并将其权重θ_c⁻初始化为主Q网络的权重。
- 第4行:创建一个主Q网络
- 第7行:初始化环境的起始状态
s₀。
第二部分:主循环 (第8-29行)
这是一个持续 T 步的训练循环。
-
第9-14行:动作选择
- 采用标准的ε-贪心策略进行探索或利用。
- 关键点(第13行):在“利用”(即选择最优动作)时,智能体会计算所有主Q网络
Q_c对每个动作的Q值之和 (Σ_c Q_c),然后选择那个能使总Q值最大的动作a_t。这意味着决策是基于对总体回报的综合考量。
-
第15-16行:与环境交互并存储经验
- 执行动作,获得新的状态
s_{t+1}和奖励r_t(这里的奖励实际上是一个包含C个分量的向量r_{t,c}),然后将这个完整的转换存入经验回放池D。
- 执行动作,获得新的状态
-
第17-25行:学习与更新(核心部分)
- 从经验池
D中随机采样一小批数据。 - 第18-25行:这是一个循环,对每一个奖励部分
c单独进行学习。- 第19-23行:计算目标Q值
y_j,c。- 第22行(最关键的一步):如果不是终止状态,目标值由当前奖励分量
r_{j,c}加上未来的折扣回报组成。未来的回报是这样计算的:- 动作选择:首先,用所有主Q网络 (
Q_k) 对下一个状态s_{j+1}进行评估,将它们的Q值相加 (Σ_k Q_k),找出能使总Q值最大的动作a'。 - 价值评估:然后,用第
c个目标网络Q_c⁻来评估这个被选出的动作a'的价值。 - 这就是双重DQN机制的体现:主网络们(全体)负责“选动作”,目标网络(单个)负责“算价值”。
- 动作选择:首先,用所有主Q网络 (
- 第22行(最关键的一步):如果不是终止状态,目标值由当前奖励分量
- 第24行:计算损失,即第
c个主网络Q_c的预测值与目标值y_j,c的差距,然后通过梯度下降更新Q_c的权重θ_c。
- 第19-23行:计算目标Q值
- 从经验池
-
第26-29行:更新所有目标网络
- 周期性地、缓慢地将每个主Q网络
Q_c的权重更新到对应的目标网络Q_c⁻上。
- 周期性地、缓慢地将每个主Q网络
综上该算法的总体思路可以总结为:
- 分解问题:通过将复杂的奖励信号分解为多个简单的子信号,并为每个子信号训练一个专属的Q网络,从而降低学习难度。
- 稳定学习:通过采用双重DQN机制,即“主网络选动作,目标网络评估价值”,来避免对Q值的过高估计,使得整个学习过程更加稳定和精确。
最终,该算法能够比标准DQN或双重DQN更有效地处理具有复杂或多目标奖励结构的任务。
2.5. 训练细节¶
在本节中,我们全面提供实际的训练细节,以帮助结果的可复现性。微调后的超参数以及训练回合的初始化策略被完整给出。一个智能体需要探索广泛的情境以提升其能力。我们在每个训练回合开始时随机设置两架飞机的相对朝向、速度和距离。这确保了智能体在训练过程中能够探索整个状态空间。空战环境中使用的飞机参数如表2所示。
表2. 飞机模型参数
| 符号 | 定义 | 数值 | 单位 |
|---|---|---|---|
| \(K_{V}\) | 速度增益 | 2 | - |
| \(K_{\chi}\) | 航向角增益 | 0.6 | - |
| \(\Delta V_{c}\) | 指令速度增量 | [-10, 10] | m/s |
| \(\Delta \chi_{c}\) | 指令航向角增量 | [-20, 20] | 度 |
| \(V\) | 速度状态 | [100, 250] | \(\mathrm{m} / \mathrm{s}\) |
| \(\chi\) | 航向角状态 | [-180, 180] | 度 |
除了表2中模型参数所规定的约束外,我们还随机初始化了相对距离,其范围为 -1000 到 1000 米。训练过程中的回合回报以及Q值分量如图6所示。RL智能体使用 [48] 的DQN实现进行训练,并针对奖励分解进行了必要的修改。
状态空间向量 \(\mathbf{s}\) 使用如下向量归一化到 \([-1,1]\) 区间以保持稳定性:
我们在得到最终输入的状态空间向量之前,先对公式 (13) 中的元素逐项除法:
在实验中选择了一个平衡的权重配置,其中ATA和AA奖励具有相同权重,而LOS的权重较低。距离值 \(d_{1}, d_{2}\) 来自DARPA AlphaDog挑战赛 [1,49]。这些权重的具体取值如表3所示,并在图5中给出。总奖励通过对单项奖励的加权平均计算得到:
表3. 环境参数
| 符号 | 数值 |
|---|---|
| \(w_{1}\) | 0.4 |
| \(w_{2}\) | 0.4 |
| \(w_{3}\) | 0.2 |
| \(d_{1}\) | 500 |
| \(d_{2}\) | 1000 |
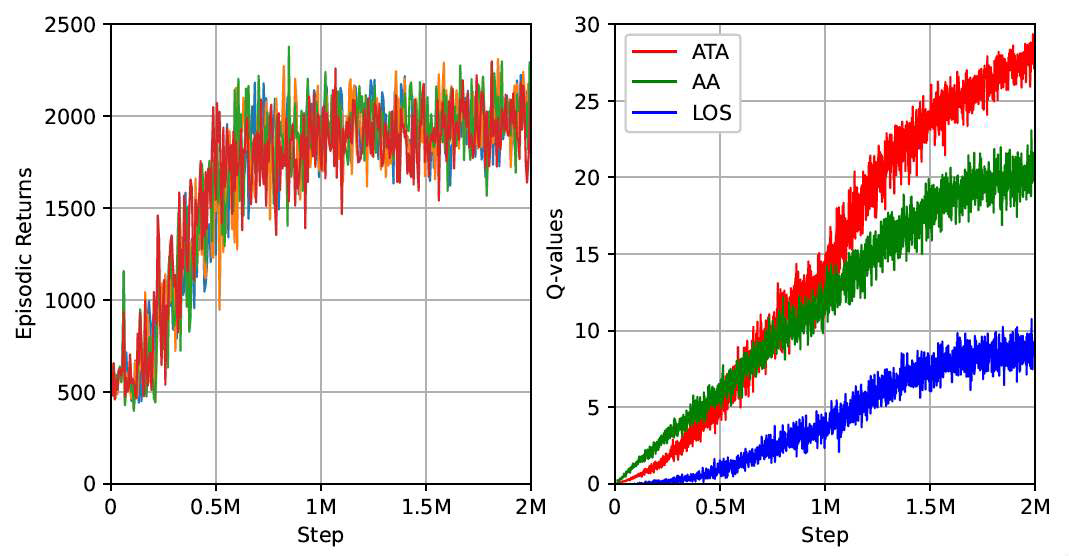
图6. (左)多次训练的回合回报。(右)多次训练的Q值分量比较。
我们运行了超参数优化,以减少回合回报信号和分量级Q值 \(Q_{c}^{\pi}\) 信号的波动,如图6所示。本研究中训练时使用的超参数在表4中列出,以帮助读者复现结果。
表4. 实验超参数
| 超参数 | 数值 |
|---|---|
| 总步数 | 2,000,000 |
| 学习率 | \(1 \times 10^{-4}\) |
| 缓冲区大小 | 1,000,000 |
| 折扣因子 ( \(\gamma\) ) | 0.99 |
| 目标网络更新率 ( \(\tau\) ) | 1.0 |
| 目标网络更新频率 | 10,000 |
| 批大小 | 64 |
| 初始 \(\epsilon_{\text {start}}\) | 1 |
| 终止 \(\epsilon_{\text {end}}\) | 0.05 |
| 探索比例 | 0.35 |
| 学习开始步数 | 10,000 |
| 训练频率 | 8 |
在本节中,我们涵盖了背景信息,包括空战环境的细节、智能体在该环境下使用DQN的训练、结合奖励分解的DQN扩展方法,以及用于复现的训练细节。在下一节中,我们将以这些背景信息为基础展开可解释性研究。我们将从局部解释开始,扩展到结合战术区域的全局解释与全局解释的可视化,并将这些概念应用于空战环境。
3. 可解释性¶
在人工智能快速发展的领域中,系统不仅要具备最优性能,还需具备可解释性和透明性,这一需求已成为核心关注点。
在复杂领域(如空战)中尤为如此,AI智能体的决策过程必须既有效又可理解。AI中的可解释性概念旨在弥合这一差距,从而提供对智能体行动的“如何”与“为什么”的洞察。根据范围的不同,解释大致可分为局部解释和全局解释。局部解释尝试回答“为什么在该状态下此动作更优?”或“每种奖励类型对所选动作的贡献有多大?”。然而,在观看动态视频时,局部解释更难跟踪 [32],而动态视频正是空战的本质,其状态变化极快。与之相对,全局解释则在更广泛的情境下提供对智能体决策的洞察。它尝试回答的问题是:“在状态空间的不同区域,哪些奖励类型占主导地位?”以及“在该区域中,每种奖励类型的相对贡献是多少?”。除了局部和全局的文本解释之外,解释还可以以视觉形式呈现,例如通过显著图 [10],其中视觉解释展示哪些像素对分类对象更为重要。回答这些问题或可视化智能体的期望,有助于揭示其决策过程。在本节中,我们经常使用“奖励类型”一词并附带其名称。需要注意的是,这些解释来自公式 (33) 所给的分量级Q值,它们在设计上与语义上有意义的奖励类型相关联。这种关联使我们能够在解释中直接将其称为 \(X\) 奖励类型,因为奖励分解的目的正是利用这种关系生成洞察。例如,当我们说某个 \(X\) 奖励类型更高时,这表明与奖励类型 \(X\) 相关的Q值 \(Q_{c}\) 更高。在本节中我们始终一致地应用并重复这一术语,以帮助澄清解释。
提供解释的目标不仅在于提升用户对智能体的理解,从而增强对智能体的信任。它还在于识别智能体决策过程中的潜在缺陷,并充当预警机制,在智能体的推理偏离用户期望或公认规范时提醒用户。这与文献 [50] 中的观点相反,后者认为基于价值的解释在本质上存在问题。然而,提供能够帮助识别智能体不当行为的解释仍然至关重要,这凸显了解释的主要目标不仅仅是详述一个最优执行的智能体的内部机制,而是提升理解与监督,尤其是在智能体的期望偏离预期或理想结果时。
为增强用户对空战智能体的信任,我们开发了局部、全局和可视化的解释方法。我们提供了如何解读解释结果的示例,从而展示了我们方法在理解智能体决策过程中的有效性。
首先,我们通过奖励分解引入了局部解释,提供对决策过程的微观视角。局部解释通过展示精心挑选的语义上有意义的奖励类型的贡献,来回答“为什么在该状态下此动作更优?”这一问题,从而提供定性解释。同时,通过展示每种奖励类型的相对贡献,来回答“每种奖励类型对所选动作的贡献有多大?”这一问题,从而提供定量解释。这些信息可用于理解智能体的偏好,或检测智能体与用户期望之间的不一致。
其次,我们在奖励分解的基础上给出了基于战术区域的全局解释方法的数学基础,从而提供更广阔的视角来分析不同奖励类型的主导性。我们的方法试图通过分析预定义战术区域内各奖励类型的平均贡献,来回答“在状态空间的不同区域,哪种奖励类型占主导地位?”这一关键问题。
随后,我们通过比较各战术区域中每种奖励类型的相对贡献,回答“在该区域中,每种奖励类型的相对贡献是多少?”这一问题。
第三,我们在空战环境中引入了基于战术区域的全局解释。我们描述了用于空战的战术区域,并在这些区域中分析了主导奖励类型。此外,我们扩展了空战文献中定义的战术区域,使其涵盖全部四个象限,从而展示了解释如何揭示智能体在对称相同区域中的期望差异。
第四,我们引入了一种可视化解释方法,其中我们采用颜色编码来表示与智能体期望相关的ATA-AA-LOS奖励类型,这些期望由 \(Q_{c}\) 表示,从而生成颜色编码的奖励类型图。这些可视化结果为基于战术区域的全局解释提供了直观洞察。通过对公式 (33) 中智能体的期望进行颜色编码,我们开发了一种可视化全局解释方法,从而揭示智能体在空战多样化场景中期望的变化。
3.1. 局部解释¶
在我们之前的研究 [42] 中,我们利用带有奖励分解的双DQN将可解释性引入空战智能体。训练完成后,得到了三个与奖励类型ATA、AA和LOS相关的Q值函数 \(Q_{c}\)。这些Q值函数是智能体策略(公式 (30))的内在组成部分。智能体策略的框图如图7所示。

图7. 智能体策略和生成的分量级Q值 \(Q_{c}\) 的框图。Q值与奖励类型的对应关系为 \(Q_{1} \sim r_{A T A}, Q_{2} \sim r_{A A}, Q_{3} \sim r_{L O S}\)。
可解释性通过公式 (33) 所给的Q值实现。与语义上有意义的奖励类型ATA、AA和LOS(公式 (18))相关联的Q值直接提供了几何和战术关系,因此易于理解。回顾一下,Q值表示智能体在遵循其策略时期望获得的回报。利用分解Q值进行局部可解释性的框图如图8所示。

图8. 利用从智能体策略获得的Q值生成的局部解释框图。
我们通过查看所选动作的Q值最大贡献 \(\arg \max _{c} Q_{c}^{\pi}\) 来回答“为什么在该状态下此动作更优?”这一问题。对于“每种奖励类型对所选动作的贡献有多大?”这一问题,则可以直接通过公式 (33) 给出的分量级Q值向量获得答案。
在图9中,我们展示了可解释性接口的一个快照,显示了智能体对每个动作的期望 \(Q_{c}\) 以及与之相关的奖励类型。利用这些信息,我们能够回答这样的问题:为什么当敌机在射程内且位于前方时,智能体选择减速并右转?对此问题的回答是,智能体选择该动作是因为在ATA和AA奖励类型上的期望高于LOS奖励类型,即它认为该动作将使其更好地对准目标飞机,同时保持在目标后方。我们还可以进一步获得每种奖励类型对所选动作期望的贡献量化结果。

图9. 训练后的RL智能体仿真快照。左上图为俯视图,右上图为蓝方智能体机体坐标系下的视角,每个绿色圆圈半径为1000米。下图为分解奖励柱状图,黑色 \(x\) 标记表示所选动作,其余 \(x\) 标记表示如果仅基于各奖励类型最大值所选择的动作。
我们注意到,智能体对各奖励类型的期望,即使是对非最优动作,其结果也与最优动作相似。这表明智能体对所有可能动作的期望非常接近。我们发现这一结果出乎意料,因为我们原本预期加速并右转的动作应当有相对较低的期望值,毕竟该机动会使蓝机处于更防御的位置,从而有效地置于红机前方。
尽管利用奖励分解的局部解释能够通过展示智能体在每种奖励类型上的分解期望来提供其决策过程的洞察,但在空战这种动态变化的环境中,这些值难以跟踪和理解。我们观察到,在多次仿真中,相邻时间状态下智能体在各奖励类型上的期望会发生突然变化。为了提供更为宏观的智能体期望概览,我们将基于奖励分解的局部解释扩展为结合战术区域的全局解释。
3.2. 基于战术区域的全局解释¶
局部奖励分解所提供的解释并不能揭示智能体在相邻区域的偏好。智能体对每种奖励类型的期望可能在时间和空间上相近的状态之间显著变化。为了对智能体的决策过程提供更为宏观的解释,我们在局部奖励分解的基础上进行了扩展,提出了基于战术区域的全局解释方法。相比局部解释中提出的“为什么在该状态下此动作更优?”,全局解释提出的问题是“在状态空间的不同区域,哪种奖励类型占主导地位?”。在更定量的层面上,相比于“每种奖励类型对所选动作的贡献有多大?”,我们提出的问题是“在该区域中,每种奖励类型的相对贡献是多少?”。通过识别主导奖励类型并评估预定义战术区域内各奖励类型的相对贡献,我们强调了智能体期望的变化及其行动所受的主要奖励驱动。该解释结果使用户能够更好地审视智能体的行为,或为飞行员在不同战术区域的偏好提供参考。
我们首先通过定义战术区域和与各奖励类型相关的分解Q值来形式化我们的解释方法:
- 设 \(\mathcal{T}=\left\{T_{1}, T_{2}, \ldots, T_{m}\right\}\) 表示环境中的战术区域集合,其中 \(j=1, \ldots, m\) 标识每个战术区域 \(T_{j}\)。
- 公式 (33) 中的 \(\mathbf{Q}^{\pi}\) 表示分解Q值函数的向量。
- \(c\) 为所选奖励分量。
首先,当智能体遵循其策略 \(\pi(s)\) 时,我们计算在战术区域 \(T_{j}\) 内每个 \(Q_{c}^{\pi}(s)\) 的相对贡献,如下所示:
相对贡献函数计算了特定奖励类型的期望(见公式 (32))在遵循策略 \(\pi\) 时,相对于所有奖励类型总期望(见公式 (31))的比例。该度量解释了每种奖励类型在多大程度上影响了策略 \(\pi\) 下最优动作的选择,从而揭示在给定战术区域内每种奖励类型的期望回报。将状态空间划分为有意义且可管理的战术区域,使我们能够从期望的角度理解智能体的决策过程。
然后,我们定义一个决策函数 \(F\),它为每个战术区域分配最具主导性的奖励类型,从而识别在每个区域内期望最高的奖励类型。给定公式 (33) 中定义的遵循策略 \(\pi(s)\) 的分解Q值向量,决策函数 \(F\) 将每个战术区域映射到与主导奖励类型对应的分量,其定义为:
该决策函数旨在阐明哪种奖励类型在特定战术区域中主要影响所选择的动作。通过考虑相对贡献的绝对值,我们的方法能够同时适应负奖励与回合性奖励,从而扩展其适用性,不仅限于连续形态的奖励。这一调整保证了方法在不同奖励场景下的多样性,从而增强了我们对跨战术区域动作选择的理解。
该框架定量评估了不同奖励类型在各战术区域中对智能体决策过程的影响,从而为智能体的期望提供了洞察。决策函数通过识别战术区域 \(T_{j}\) 内与主导奖励类型 \(r_{c}\) 对应的分量 \(c\),阐明了“在状态空间的不同区域,哪种奖励类型占主导地位”。决策函数揭示了动作选择受 \(Q_{c}\) 最大化或最小化的期望驱动,这取决于相关奖励是正值还是负值。这一区别至关重要:正定义的 \(Q_{c}\) 表明智能体倾向于选择最大化该奖励回报的动作,而负定义的 \(Q_{c}\) 表明智能体选择的动作旨在避免不利结果。这种方法不仅回答了各区域主导奖励类型的问题,还为理解智能体与各奖励类型相关的期望提供了洞察。通过将用户定义的语义上有意义的奖励类型与用户定义的战术区域相结合,我们改进了智能体决策过程的可解释性,从而更深入地理解其偏好。该方法不仅澄清了智能体行为背后的逻辑依据,还支持了可解释人工智能的目标,即在与局部奖励分解所提供的详细但范围有限的解释相比时,使复杂的智能体偏好对用户而言更为可理解和相关。这一全局视角丰富了我们对AI决策过程的理解,从而以一种用户可以直接理解的方式聚焦于情境与偏好。
3.3. 空战战术区域的全局解释¶
空战环境由于其固有的复杂性和战略重要性,非常适合应用基于战术区域的全局解释方法。空战中的不同战术区域允许通过分解奖励对智能体行为进行清晰的分析,从而为不同战术情境下的决策过程提供洞察。
为了将基于战术区域的全局解释方法应用于空战环境,我们首先定义了战术区域,即进攻、防御、中立和迎头,这些定义源自空战文献 [17,51]。与现有文献不同,我们将战术区域扩展为四个不同的象限,如图 10 所示。引入这一扩展是为了在得到不一致结果(如图 3 所示)后,进一步分析智能体在对称空战区域中的期望。
在定义战术区域之后,我们通过明确每个战术区域的状态划分标准来界定其边界。进攻区域定义为 ATA 角小于或等于 90 度,且不符合迎头区域的条件。该区域表明智能体采取了进攻性姿态,旨在从有利角度攻击对手。迎头区域定义为 ATA 角小于或等于 45 度且 AA 大于或等于 135 度,表明直接的正面交战方式。相反,防御区域定义为 ATA 和 AA 角均大于 90 度,表明智能体处于更易受到对手动作影响的位置,可能侧重规避机动。最后,中立区域定义为 ATA 大于 90 度且 AA 小于 90 度,表示双方都没有明显进攻优势的情况。各区域的示意图见图 10。
 图 10. 空战几何划分为进攻、防御、中立和迎头区域,均位于一个象限中。
图 10. 空战几何划分为进攻、防御、中立和迎头区域,均位于一个象限中。
基于上述分类,我们定义了空战的战术区域集合和与特定奖励类型相关的分解 Q 值集合,如公式 (18) 所示:\(Q_{1} \sim r_{A T A}, Q_{2} \sim r_{A A}, Q_{3} \sim r_{L O S}\)。设 \(\mathcal{T}=\left\{T_{\text {offensive }}, T_{\text {defensive }}, T_{\text {neutral }}, T_{\text {head-on }}\right\}\) 为战术区域集合,\(\mathbf{Q}^{\pi}=\left\{Q_{1}^{\pi}, Q_{2}^{\pi}, Q_{3}^{\pi}\right\}\) 为空战环境中的分量级 Q 值函数向量。基于上述战术区域定义和公式 (13) 中的状态向量,我们进一步定义了与每个战术区域对应的状态集合如下:
其中,\(T_{\text {head-on }}, T_{\text {offensive }}, T_{\text {defensive }}, T_{\text {neutral }}\) 直接表示对应于每个战术区域的状态集合。函数 \(\operatorname{ATA}(s), \mathrm{AA}(s), \operatorname{LOS}(s)\) 为选择函数,返回给定状态 \(s\) 的相应值,如公式 (13) 中定义。
根据公式 (37) 和 (38),我们计算了图 10 所示所有战术区域和象限的主导奖励类型及其相对贡献。表 5 给出了在 LOS 为 2000 m 时,各战术区域的主导奖励类型和各奖励类型的相对贡献。需要强调的是,该智能体的训练中 ATA 和 AA 奖励的权重为 0.4,LOS 奖励的权重为 0.2。
在将基于战术区域的全局解释方法应用于空战环境的过程中,我们揭示了智能体决策过程中的细微差别。以下示例说明了该分析的实际意义,包括识别特定区域内的主导奖励类型、探索对称战术区域中智能体期望的变化,以及利用这些知识对智能体的策略进行调试和重新校准。每个示例都展示了我们对智能体决策过程理解的深度。
表 5. LOS = 2000 m 时战术区域奖励主导性
| 战术区域 | 主导奖励类型 | 相对贡献 | |
|---|---|---|---|
| 第一象限 | |||
| 迎头 | ATA | [0.388, 0.315, 0.298] | |
| 进攻 | ATA | [0.476, 0.330, 0.195] | |
| 防御 | ATA | [0.414, 0.288, 0.298] | |
| 中立 | AA | [0.386, 0.511, 0.103] | |
| 第二象限 | |||
| 迎头 | ATA | [0.384, 0.341, 0.276] | |
| 进攻 | ATA | [0.486, 0.315, 0.199] | |
| 防御 | ATA | [0.434, 0.195, 0.370] | |
| 中立 | ATA | [0.461, 0.380, 0.159] | |
| 第三象限 | |||
| 迎头 | ATA | [0.398, 0.310, 0.292] | |
| 进攻 | ATA | [0.458, 0.355, 0.188] | |
| 防御 | ATA | [0.400, 0.298, 0.302] | |
| 中立 | AA | [0.366, 0.539, 0.095] | |
| 第四象限 | |||
| 迎头 | ATA | [0.423, 0.285, 0.292] | |
| 进攻 | ATA | [0.508, 0.271, 0.220] | |
| 防御 | ATA | [0.387, 0.241, 0.371] | |
| 中立 | ATA | [0.462, 0.395, 0.143] |
本示例对第一象限的结果进行了分析。在迎头、进攻和防御区域,ATA 被识别为主导奖励类型。由于 ATA 衡量的是我方飞机正对目标的程度,这一结果表明在这些战术区域中,智能体选择的动作是基于最大化 ATA 奖励的期望。这意味着智能体期望其动作能够使其与目标飞机保持更好的对准。此外,在中立区域,主导奖励类型转变为 AA,这表明智能体期望其选择的动作能够使其更有利地处于目标飞机之后。进一步分析各战术区域内每种奖励的相对贡献揭示了更为细致的推理。在迎头和防御区域,AA 和 LOS 奖励各自贡献了约 \(30\%\)。然而,从迎头区域过渡到防御区域时,ATA 奖励的贡献额外增加了 \(7\%\)。这一变化表明,虽然智能体在迎头区域对所有奖励类型的期望较为接近,从而认识到其在该位置上的战术劣势,但在防御区域中,智能体认为提升 ATA 奖励的动作更为关键,以改善其进攻态势并增加命中可能性。这一关于主导奖励类型及其相对贡献的洞察强调了该框架如何利用智能体的期望来解释其决策过程,同时也表明训练过程中使用的奖励权重并未完全传递到训练后的智能体中。
第一和第三象限在空战情境中代表对称几何,其中第一象限中智能体飞机位于视线左侧,第三象限中位于右侧,而目标飞机则处于相反位置。分析这些象限内的战术区域揭示了智能体期望的显著差异。具体而言,在第一和第三象限的中立区域,AA 奖励都是主要的,但两者之间每种奖励的相对贡献却不同。这种对称区域间的相对贡献变化表明,即便在几何完全相同的场景下,智能体的期望也可能存在差异。这类差异指向了智能体策略中可能的不一致性以及训练过程中的不平衡,可能源自随机初始化过程。将主导奖励及其相对贡献作为解释工具,可以通过对智能体策略的直接分析识别这些不一致性,从而避免依赖大量仿真。这种方法为智能体的决策过程提供了清晰的观察窗口,突出了可能需要改进或调整的领域。
跨战术区域的主导奖励评估为调试智能体和识别其期望与人类操作员期望之间的差异提供了一种重要机制。以第一象限的防御区域为例,其中 ATA 奖励占主导;但与此相对,人类操作员可能预期更高的 AA 奖励偏好,暗示出一种更为谨慎的策略,即侧重于在目标之后机动,而不是直接正面对抗。同样,在第一象限的中立区域 AA 奖励的突出地位也值得注意。在这种双方都没有明显位置优势的情况下,AA 奖励占主导可能表明一种更偏防御的姿态,暗示智能体在该战术模糊区域采取了较少进攻性的策略。这些示例说明了以主导奖励为核心的分析如何 pinpoint 智能体期望与用户期望的偏差,从而为进一步调查和改进提供线索。这种跨战术区域的奖励主导性与分布的分析方法,结合与人类飞行员期望的对比,建立了一个稳健的调试与对齐框架。通过突出智能体期望与人类操作员预期不一致的领域,该方法允许对智能体战术进行关键性评估与调整,从而确保其动作与既定的战术原则和人类经验保持一致。
3.4. 全局可视化解释¶
可视化解释方法提供了一个更为细致和定性的视角来理解智能体的决策过程,因此能够提供超越战术区域全局解释方法中“每个区域平均奖励主导性”的更深入见解。该方法通过颜色编码的方式直观呈现智能体在状态空间中的期望值,从而揭示智能体期望中的微妙变化和模式,这些变化和模式可能在聚合数据中并不明显。该方法使用基于归一化 Q 值的颜色编码热力图。通过将不同 Q 值分量的相对重要性映射到颜色光谱,该方法能够即时提供关于智能体在不同战术区域中的决策过程的直观洞察。这种可视化表示不仅增强了我们对智能体决策过程的理解,还便于识别改进空间,从而支持更有针对性的性能优化与对齐。由于颜色编码的固有限制,该方法目前最多仅能可视化三种奖励类型。
下式描述了基于策略 \(\pi(s)\) 在不同状态 \(s\) 下生成颜色编码可视化解释的过程。具体而言,某一状态下的分量级 Q 值(\(Q_{1}^{\pi}(s), Q_{2}^{\pi}(s), Q_{3}^{\pi}(s)\))会相对于这三者的最大绝对值进行归一化。此归一化确保 Q 值分量的每个贡献均按比例表示,其中最大贡献分量被缩放为 1。归一化后的值被映射到 RGB 色彩空间,每个分量对应一个基色(红、绿或蓝)。
这种映射将数值数据转化为视觉形式,使我们能够直观理解各 Q 值分量在任一状态下对智能体决策过程的相对影响。通过该方法,可视化能够直接传达智能体的优先期望,从而揭示其决策过程并突出潜在改进方向。由于分子与分母都取绝对值,该可视化方法对奖励的符号不敏感,因此同样适用于正奖励和负奖励场景。这确保了无论训练所用的奖励结构如何,该方法都能提供有价值的信息。类似于全局战术区域解释方法在空战中的应用,Q 值、奖励类型与颜色编码的关系如下:
图 11 中展示的可视化解释与表 5 中的定量数据对比后,体现了清晰的一致性。例如,在右上方的第一象限,ATA(红色表示)在进攻和迎头区域中均为主导奖励类型,与表 5 的结果一致。在防御区域中,可以观察到所有奖励类型的贡献较为均衡,但 ATA(红色)略占优势。相反,在中立区域,AA 奖励类型(绿色表示)更为突出,强调了其在表中所识别的主导地位。虽然该分析重点放在第一象限,但在整个颜色图上也展现了类似的一致性,进一步验证了可视化解释与表格化解释在智能体决策过程中的一致性。

图 11. 各战术区域的颜色编码奖励贡献。固定 LOS 2000 m 采样。
这种可视化解释的效用在识别智能体期望与预期对称结果不一致的状态空间区域时尤为明显。作为示例,状态空间在固定 LOS 距离 500、1000、1500 和 2000 m 下进行采样,同时改变 ATA 和 AA 的值,如图 12 所示。结果显示,随着飞机间距离的减小,智能体在对称象限中的期望差异逐渐减弱。这一观察表明,随着战斗场景距离的拉近,智能体的期望趋于收敛,从而突出了空间动态对其决策过程的影响。

图 12. 各战术区域的颜色编码奖励贡献。在多个 LOS 状态下采样。
我们使用公式 (43) 的颜色编码来呈现智能体在 ATA、AA 和 LOS 状态定义的轨迹上的期望变化。需要注意的是,公式 (9)-(11) 中定义的 ATA、AA 和 LOS 状态与公式 (18) 中定义的 ATA、AA 和 LOS 奖励类型不同。虽然奖励函数由这些状态导出,但状态本身代表的是智能体所处的空间域,而奖励类型则是智能体用来训练其策略的信号。我们比较了对称初始状态下的仿真结果,这些状态均位于中立区域。在第一次仿真中,两架飞机的航向设置为初始 ATA 状态为 -135 度、AA 状态为 45 度,对应于第二象限的中立区域。第二次仿真则以 ATA 状态为 135 度、AA 状态为 -45 度开始,对应于第四象限的中立区域。在两次仿真中,两架飞机相距 1000 m,初始速度设置为 \(150 \mathrm{~m} / \mathrm{s}\)。红色目标飞机沿直线飞行,用于演示。
在初始仿真中(见图 13),从俯视图的轨迹分析可以看出智能体向目标飞机机动的过程。在 0 到 10 秒之间,智能体执行了一个急剧的左转,然后加速以缩短距离并准备交战,同时缓慢调整航向。底部图中显示,在这一阶段内,各个 \(Q\) 值对所选动作的相对贡献起初大致相同。随着急转动作的进行,ATA 奖励类型逐渐成为主导,并在 8 秒后稳定下来,表明与目标飞机的对准是所选动作的主要驱动因素。右上方图显示,智能体加速并接近目标飞机,LOS 状态值从 2000 m 减少到 1000 m,期间 LOS 奖励类型的贡献逐渐增加。这说明智能体的期望随着距离缩小而正确转向 LOS 奖励。总体而言,该仿真表明智能体在战术上采取了平衡:一方面通过 ATA 提升进攻对准,另一方面通过 LOS 奖励缩短距离以保持或进入交战范围。

图 13. 基于 ATA-AA-LOS 状态定义的轨迹中 Q 值对决策过程的贡献,初始状态位于第二象限中立区域。左上为俯视图,右上为颜色编码的三维图(坐标轴为 ATA-AA-LOS 状态),下方为最优动作对应的各 Q 值。轨迹上的数字表示经过的时间(秒)。
然而,在第二次仿真中,尽管初始状态在几何上对称,智能体在急剧右转后却没有接近目标飞机(见图 14)。底部图显示,在前 10 秒内智能体的期望与第一次仿真类似。10 秒之后,LOS 奖励的期望下降,虽然智能体的期望与 LOS 状态的变化保持一致,但它并没有选择加速动作。

图 14. 基于 ATA-AA-LOS 状态定义的轨迹中 Q 值对决策过程的贡献,初始状态位于第四象限中立区域。左上为俯视图,右上为颜色编码的三维图(坐标轴为 ATA-AA-LOS 状态),下方为最优动作对应的各 Q 值。轨迹上的数字表示经过的时间(秒)。
在 20 秒时刻的局部奖励分解快照(见图 15)显示,汇总的期望值在减速动作上最高,且主要由 AA 奖励主导,这与图 14 底部图一致。然而,与 LOS 奖励相关的 Q 值在“加速左转”动作上最高。这种在飞机相距较远时同时出现“减速”和“加速”两种相互矛盾的动作,揭示了智能体策略存在问题。如果没有奖励分解方法,这类解释将难以获得。

图 15. 训练后的 RL 智能体仿真快照。左上为俯视图,右上为蓝方机体坐标系视角(绿色圆圈半径为 1000 m),下方为分解奖励柱状图。黑色 \(x\) 表示选择的动作,其他 \(x\) 表示如果仅根据各奖励类型的最大值所选的动作。
与前例类似,本节也给出了一个基于轨迹的解释,展示了智能体在空战交战过程中的动态决策过程。在该仿真中,蓝方飞机位于 \((-500,500)\),红方飞机位于 \((500,500)\),初始航向为 -90 度,初始速度设置为 \(150 \mathrm{~m}/\mathrm{s}\)。需要强调的是,该智能体是针对随机运动的飞机训练的,每个回合的初始状态随机生成,各奖励类型的 Q 值代表智能体在给定状态下遵循策略的期望回报。结果见图 16。
从俯视图(左上)可以观察到,蓝方飞机在前 5 秒保持航向不变,并在 5–10 秒之间执行急左转朝向目标。下方图中显示,在保持航向阶段 AA 奖励值上升,随后 ATA 奖励值(红线)上升,表明智能体期望通过机动先将自己置于目标后方,然后完成对准。右上角的颜色编码三维图也支持这一结论:最初轨迹呈白色,表示所有奖励类型期望相近;约 5 秒时变为绿色,表示 AA 奖励占优;到 10 秒时变为橙色,表示 ATA 和 AA 奖励期望接近。

图 16. AI 对战 AI 仿真结果。左上为俯视图,右上为颜色编码的三维图(坐标轴为 ATA-AA-LOS 状态),下方为最优动作对应的各 Q 值。轨迹上的数字表示经过的时间(秒)。
在 10–20 秒期间,蓝方飞机通过保持航向锁定目标来缩短距离,执行了纯追击机动。20–30 秒间,红方飞机右转使蓝方飞机航迹超前,进入滞后追击,导致 ATA Q 值期望下降。此后蓝方飞机急右转调整航向并加速继续追击,而红方也最大化速度试图摆脱。由于两架飞机动力学完全相同,之后双方都无法获得优势,仿真在 55 秒结束,两机进入速率战。需要指出的是,尽管仿真从对称进攻态势开始,且两机均由相同智能体驱动,蓝方依然比红方保持了更好的进攻态势。与前例类似,这表明在空战研究中测试对称几何场景的重要性。
在本节中,我们展示了多种解释方法,包括局部解释、结合战术区域的全局解释、全局解释的可视化及其在空战环境中的应用。下一节将进行讨论与总结,归纳研究发现并提出未来研究方向。
4. 讨论¶
大多数空战领域的研究集中在利用基于策略的强化学习方法开发最优智能体,而这类方法通常不提供生成全局内在解释的机制。这在实际操作中是一个显著的限制,因为在需要理解 AI 决策背后逻辑的场景中,信任与人机协作的有效性至关重要。相比之下,我们的研究提出了一种新颖的解释方法,将基于值的深度 Q 网络(Deep Q Network)中的奖励分解扩展为结合战术区域的全局解释,从而将内在的局部解释推广到全局层面。我们的研究不仅展示了智能体在多种空战场景中的成功应用,还能够生成全面且有意义的解释,使用户更容易理解。
本研究提出的新型可解释性方法,填补了可解释强化学习(XRL)中的关键空白。它为动态、持续变化的环境提供了生成全局内在解释的机制,而传统的局部解释方法在这类环境中往往不足。通过将状态空间划分为具有语义意义的战术区域,我们的方法提升了解释的相关性和可理解性,从而能够更广泛地评估智能体的决策过程。这种划分显著提高了用户的理解能力,而无需进行大量的仿真。
此外,我们的方法在快速且可靠的决策至关重要的领域具有重要的实际意义。它通过为 AI 驱动的决策提供清晰的解释,提高了作战准备度,从而改善了协调与战略规划能力。同时,本研究确立的原则也可以推广到其他复杂且动态的环境中,例如自动驾驶和机器人导航。在这些领域中,理解 AI 在不同情境下的行为同样至关重要。
更广泛地说,本研究显著推动了 XRL 的发展。它不仅为 AI 系统在高风险环境中的深度融合提供了方法,也为未来跨领域的可解释 AI 研究奠定了基础。本研究提出的解释方法有助于构建更稳健、透明和可信赖的 AI 系统,从而推动其在关键及面向公众的应用中的采用。
5. 结论¶
本文在可解释强化学习(XRL)领域的贡献在于:通过创新性地引入战术区域,将局部解释方法扩展到全局层面,并提出了一种针对分解奖励的可视化解释方法。我们通过将其应用于复杂且动态的空战环境,展示了这些方法在揭示智能体决策过程细微差异方面的有效性。研究结果表明,通过分析不同战术区域中的主导奖励类型及其分布,可以更深入地理解智能体的决策过程,并识别潜在的改进空间。颜色编码的奖励可视化技术进一步增强了我们对智能体期望的直观理解,即使在传统解释可能不足的情境下也能提供有力支持。这些贡献不仅推动了 XRL 研究的前沿发展,也在高风险领域 AI 系统的设计与评估中具有重要实践价值,强调了可解释性在信任、透明性和与人类战略目标保持一致性方面的重要性。
未来工作包括将结合战术区域的全局解释方法扩展到其他强化学习架构。另一个研究方向是开展大规模的用户实证研究,以验证所提出方法的有效性。这些研究将进一步提升 XRL 在复杂动态环境中的应用价值,从而推动高性能、透明且可信赖的自主系统的发展。
引用: Saldiran, E.; Hasanzade, M.; Inalhan, G.; Tsourdos, A. 面向近距离空战中人工智能智能体战术的全局可解释性. Aerospace 2024, 11, 415. https://doi.org/10.3390/aerospace11060415
版权: © 2024 作者。许可方为 MDPI, Basel, Switzerland。本文章为开放获取文章,遵循 Creative Commons Attribution (CC BY) license 条款。
Author Contributions: Conceptualization, E.S., M.H. and G.I.; methodology, E.S., M.H. and G.I.; software, E.S.; validation, E.S.; formal analysis, E.S.; investigation, E.S., M.H. and G.I.; resources, G.I.; data curation, E.S.; writing-original draft preparation, E.S.; writing-review and editing, E.S., M.H., G.I. and A.T.; visualization, E.S.; supervision, G.I. and A.T.; project administration, G.I.; funding acquisition, G.I. All authors have read and agreed to the published version of the manuscript.
Funding: This research received no external funding. Data Availability Statement: Data are contained within the article. Conflicts of Interest: The authors declare no conflicts of interest.
缩写
本文中使用的缩写如下:
| 缩写 | 全称 |
|---|---|
| AA | 视角角度(Aspect Angle) |
| AI | 人工智能(Artificial Intelligence) |
| ATA | 天线指向角(Antenna Train Angle) |
| DQN | 深度Q网络(Deep Q Network) |
| LOS | 视线(Line of Sight) |
| Q value | 质量值(Quality Value) |
| RL | 强化学习(Reinforcement Learning) |
| RPAS | 遥控驾驶航空器系统(Remotely Piloted Aircraft Systems) |
| XRL | 可解释强化学习(Explainable Reinforcement Learning) |
References¶
- Defense Advanced Research Projects Agency (DARPA). AlphaDogfight Trials Foreshadow Future of Human-Machine Symbiosis. 2020. Available online: https://www.darpa.mil/news-events/2020-08-26 (accessed on 10 March 2023).
- Aibin, M.; Aldiab, M.; Bhavsar, R.; Lodhra, J.; Reyes, M.; Rezaeian, F.; Saczuk, E.; Taer, M.; Taer, M. Survey of RPAS autonomous control systems using artificial intelligence. IEEE Access 2021, 9, 167580-167591. [CrossRef]
- Kaur, D.; Uslu, S.; Rittichier, K.J.; Durresi, A. Trustworthy artificial intelligence: A review. ACM Comput. Surv. (CSUR) 2022, 55, 1-38. [CrossRef]
- Gunning, D.; Vorm, E.; Wang, Y.; Turek, M. DARPA's explainable AI (XAI) program: A retrospective. Appl. Lett. 2021, 2, e61. [CrossRef]
- European Commission; Directorate-General for Communications Networks, Content and Technology. Ethics Guidelines for Trustworthy AI; European Commission: Brussels, Belgium, 2019. [CrossRef]
- Norman, D.; Gentner, D.; Stevens, A. Mental models. Some Observations on Mental Models. In Human-Computer Interaction: A Multidisciplinary Approach; Morgan Kaufmann Publishers Inc.: San Francisco, CA, USA, 1983; pp. 7-14.
- Burkart, N.; Huber, M.F. A survey on the explainability of supervised machine learning. J. Artif. Intell. Res. 2021, 70, 245-317. [CrossRef]
- Ribeiro, M.T.; Singh, S.; Guestrin, C. "Why should i trust you?" Explaining the predictions of any classifier. In Proceedings of the 22nd ACM SIGKDD International Conference on Knowledge Discovery and Data Mining, San Francisco, CA, USA, 13-17 August 2016; pp. 1135-1144.
- Lundberg, S.M.; Lee, S.I. A unified approach to interpreting model predictions. Adv. Neural Inf. Process. Syst. 2017, 31, 4768-4777.
- Simonyan, K.; Vedaldi, A.; Zisserman, A. Deep inside convolutional networks: Visualising image classification models and saliency maps. arXiv 2013, arXiv:1312.6034.
- Selvaraju, R.R.; Cogswell, M.; Das, A.; Vedantam, R.; Parikh, D.; Batra, D. Grad-cam: Visual explanations from deep networks via gradient-based localization. In Proceedings of the IEEE International Conference on Computer Vision, Venice, Italy, 22-29 October 2017; pp. 618-626.
- Mnih, V.; Kavukcuoglu, K.; Silver, D.; Graves, A.; Antonoglou, I.; Wierstra, D.; Riedmiller, M. Playing atari with deep reinforcement learning. arXiv 2013, arXiv:1312.5602.
- Silver, D.; Huang, A.; Maddison, C.J.; Guez, A.; Sifre, L.; Van Den Driessche, G.; Schrittwieser, J.; Antonoglou, I.; Panneershelvam, V.; Lanctot, M.; et al. Mastering the game of Go with deep neural networks and tree search. Nature 2016, 529, 484-489. [CrossRef]
- Andrychowicz, O.M.; Baker, B.; Chociej, M.; Jozefowicz, R.; McGrew, B.; Pachocki, J.; Petron, A.; Plappert, M.; Powell, G.; Ray, A.; et al. Learning dexterous in-hand manipulation. Int. J. Robot. Res. 2020, 39, 3-20. [CrossRef]
- Kaufmann, E.; Loquercio, A.; Ranftl, R.; Müller, M.; Koltun, V.; Scaramuzza, D. Deep drone acrobatics. arXiv 2020, arXiv:2006.05768.
- Kaufmann, E.; Bauersfeld, L.; Loquercio, A.; Müller, M.; Koltun, V.; Scaramuzza, D. Champion-level drone racing using deep reinforcement learning. Nature 2023, 620, 982-987. [CrossRef]
- Kong, W.; Zhou, D.; Yang, Z.; Zhao, Y.; Zhang, K. UAV autonomous aerial combat maneuver strategy generation with observation error based on state-adversarial deep deterministic policy gradient and inverse reinforcement learning. Electronics 2020, 9, 1121. [CrossRef]
- Zhang, J.; Yang, Q.; Shi, G.; Lu, Y.; Wu, Y. UAV cooperative air combat maneuver decision based on multi-agent reinforcement learning. J. Syst. Eng. Electron. 2021, 32, 1421-1438. [CrossRef]
- Pope, A.P.; Ide, J.S.; Mićović, D.; Diaz, H.; Rosenbluth, D.; Ritholtz, L.; Twedt, J.C.; Walker, T.T.; Alcedo, K.; Javorsek, D. Hierarchical reinforcement learning for air-to-air combat. In Proceedings of the 2021 International Conference on Unmanned Aircraft Systems (ICUAS), Athens, Greece, 15-18 June 2021; pp. 275-284.
- Mottice, D.A. Team Air Combat Using Model-Based Reinforcement Learning. Master of Science Thesis, Air Force Institute of Technology, Wright-Patterson AFB, OH, USA, 2022.
- Yoo, J.; Seong, H.; Shim, D.H.; Bae, J.H.; Kim, Y.D. Deep Reinforcement Learning-based Intelligent Agent for Autonomous Air Combat. In Proceedings of the 2022 IEEE/AIAA 41st Digital Avionics Systems Conference (DASC), Portsmouth, VA, USA, 18-22 September 2022; pp. 1-9.
- Heuillet, A.; Couthouis, F.; Díaz-Rodríguez, N. Explainability in deep reinforcement learning. Knowl.-Based Syst. 2021, \(214,106685\). [CrossRef]
- Puiutta, E.; Veith, E.M. Explainable reinforcement learning: A survey. In Proceedings of the International Cross-Domain Conference for Machine Learning and Knowledge Extraction, Dublin, Ireland, 25-28 August 2020; pp. 77-95.
- Krajna, A.; Brcic, M.; Lipic, T.; Doncevic, J. Explainability in reinforcement learning: Perspective and position. arXiv 2022, arXiv:2203.11547.
- Coppens, Y.; Efthymiadis, K.; Lenaerts, T.; Nowé, A.; Miller, T.; Weber, R.; Magazzeni, D. Distilling deep reinforcement learning policies in soft decision trees. In Proceedings of the IJCAI 2019 Workshop on Explainable Artificial Intelligence, Macao, China, 10-16 August 2019; pp. 1-6.
- Verma, A.; Murali, V.; Singh, R.; Kohli, P.; Chaudhuri, S. Programmatically interpretable reinforcement learning. In Proceedings of the International Conference on Machine Learning, PMLR, Stockholm, Sweden, 10-15 July 2018; pp. 5045-5054.
- Madumal, P.; Miller, T.; Sonenberg, L.; Vetere, F. Explainable reinforcement learning through a causal lens. In Proceedings of the AAAI Conference on Artificial Intelligence, New York, NY, USA, 7-12 February 2020; Volume 34, pp. 2493-2500.
- Yu, Z.; Ruan, J.; Xing, D. Explainable reinforcement learning via a causal world model. arXiv 2023, arXiv:2305.02749
- Yau, H.; Russell, C.; Hadfield, S. What did you think would happen? Explaining agent behaviour through intended outcomes. Adv. Neural Inf. Process. Syst. 2020, 33, 18375-18386.
- Amir, D.; Amir, O. Highlights: Summarizing agent behavior to people. In Proceedings of the 17th International Conference on Autonomous Agents and Multiagent Systems, Stockholm, Sweden, 10-15 July 2018; pp. 1168-1176.
- Huber, T.; Weitz, K.; André, E.; Amir, O. Local and global explanations of agent behavior: Integrating strategy summaries with saliency maps. Artif. Intell. 2021, 301, 103571. [CrossRef]
- Septon, Y.; Huber, T.; André, E.; Amir, O. Integrating policy summaries with reward decomposition for explaining reinforcement learning agents. In Proceedings of the International Conference on Practical Applications of Agents and Multi-Agent Systems, Guimaraes, Portugal, 12-14 July 2023; pp. 320-332.
- Alabdulkarim, A.; Riedl, M.O. Experiential Explanations for Reinforcement Learning. arXiv 2022, arXiv:2210.04723.
- Erwig, M.; Fern, A.; Murali, M.; Koul, A. Explaining deep adaptive programs via reward decomposition. In Proceedings of the IJCAI/ECAI Workshop on Explainable Artificial Intelligence, Stockholm, Sweden, 13-19 July 2018.
- Juozapaitis, Z.; Koul, A.; Fern, A.; Erwig, M.; Doshi-Velez, F. Explainable reinforcement learning via reward decomposition. In Proceedings of the IJCAI/ECAI Workshop on Explainable Artificial Intelligence, Macao, China, 10-16 August 2019.
- Anderson, A.; Dodge, J.; Sadarangani, A.; Juozapaitis, Z.; Newman, E.; Irvine, J.; Chattopadhyay, S.; Fern, A.; Burnett, M. Explaining reinforcement learning to mere mortals: An empirical study. arXiv 2019, arXiv:1903.09708.
- Isaacs, R. Games of Pursuit; Rand Corporation: Santa Monica, CA, USA, 1951.
- Burgin, G.H. Improvements to the Adaptive Maneuvering Logic Program; Technical Report; NASA: Moffett Field, CA, USA, 1986.
- Ure, N.K.; Inalhan, G. Autonomous control of unmanned combat air vehicles: Design of a multimodal control and flight planning framework for agile maneuvering. IEEE Control Syst. Mag. 2012, 32, 74-95.
- Hasanzade, M.; Saldiran, E.; Guner, G.; Inalhan, G. Analyzing RL Agent Competency in Air Combat: A Tool for Comprehensive Performance Evaluation. In Proceedings of the 2023 IEEE/AIAA 42nd Digital Avionics Systems Conference (DASC), Barcelona, Spain, 1-5 October 2023; pp. 1-6.
- McGrew, J.S.; How, J.P.; Williams, B.; Roy, N. Air-combat strategy using approximate dynamic programming. J. Guid. Control. Dyn. 2010, 33, 1641-1654. [CrossRef]
- Saldiran, E.; Hasanzade, M.; Inalhan, G.; Tsourdos, A. Explainability of AI-Driven Air Combat Agent. In Proceedings of the 2023 IEEE Conference on Artificial Intelligence (CAI), Santa Clara, CA, USA, 5-6 June 2023; pp. 85-86.
- Mnih, V.; Kavukcuoglu, K.; Silver, D.; Rusu, A.A.; Veness, J.; Bellemare, M.G.; Graves, A.; Riedmiller, M.; Fidjeland, A.K.; Ostrovski, G.; et al. Human-level control through deep reinforcement learning. Nature 2015, 518, 529-533. [CrossRef] [PubMed]
- Watkins, C.J.; Dayan, P. Q-learning. Mach. Learn. 1992, 8, 279-292. [CrossRef]
- Kingma, D.P.; Ba, J. Adam: A method for stochastic optimization. arXiv 2014, arXiv:1412.6980.
- Russell, S.J.; Zimdars, A. Q-decomposition for reinforcement learning agents. In Proceedings of the 20th International Conference on Machine Learning (ICML-03), Washington, DC, USA, 21-24 August 2003; pp. 656-663.
- Van Hasselt, H.; Guez, A.; Silver, D. Deep reinforcement learning with double q-learning. In Proceedings of the AAAI Conference on Artificial Intelligence, Phoenix, AZ, USA, 12-17 February 2016; Volume 30.
- Huang, S.; Dossa, R.F.J.; Ye, C.; Braga, J.; Chakraborty, D.; Mehta, K.; Araújo, J.G. CleanRL: High-quality Single-file Implementations of Deep Reinforcement Learning Algorithms. J. Mach. Learn. Res. 2022, 23, 1-18.
- Pope, A.P.; Ide, J.S.; Mićović, D.; Diaz, H.; Twedt, J.C.; Alcedo, K.; Walker, T.T.; Rosenbluth, D.; Ritholtz, L.; Javorsek, D. Hierarchical Reinforcement Learning for Air Combat at DARPA's AlphaDogfight Trials. IEEE Trans. Artif. Intell. 2022, 4, 1371-1385. [CrossRef]
- Rietz, F.; Magg, S.; Heintz, F.; Stoyanov, T.; Wermter, S.; Stork, J.A. Hierarchical goals contextualize local reward decomposition explanations. Neural Comput. Appl. 2023, 35, 16693-16704. [CrossRef]
- Park, H.; Lee, B.Y.; Tahk, M.J.; Yoo, D.W. Differential game based air combat maneuver generation using scoring function matrix. Int. J. Aeronaut. Space Sci. 2016, 17, 204-213. [CrossRef]
Disclaimer/Publisher's Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content.