ZMQ guide
ØMQ - The Guide
ZMQ作为一个通信协议的核心优势¶
ZMQ 常被称作“带增强功能的套接字 (Sockets on Steroids)” 或 “并发框架 (Concurrency Framework)”,它的优势主要体现在以下几个方面:
- 智能的通信模式 (Intelligent Communication Patterns)
ZMQ 不像原始的 TCP 套接字那样只提供点对点的字节流,而是封装了多种强大的、经过验证的通信模式。开发者可以直接使用这些模式,而无需自己手动实现复杂的逻辑。最经典的模式包括:
- 发布/订阅 (Publish/Subscribe): 一个发布者向多个订阅者广播消息,订阅者可以根据主题进行过滤。非常适合事件分发和数据广播。
- 请求/响应 (Request/Reply): 经典的客户端/服务端模式,但 ZMQ 对其进行了增强,可以轻松构建出负载均衡的、异步的服务集群。
-
管道/推送拉取 (Pipeline/Push/Pull): 用于构建分布式的数据处理管道。上游节点通过
PUSH推送任务,下游节点通过PULL拉取任务进行处理,可以很方便地实现任务分发和结果汇总。 -
无中心代理架构 (Brokerless Architecture)
与 RabbitMQ、Kafka 等传统的消息中间件不同,ZMQ 通常不需要一个专门的、中心的代理服务器 (Broker)。节点之间可以直接建立连接通信。这带来了几个好处:
- 低延迟: 消息直接从发送方传递到接收方,减少了中间环节的延迟。
- 高可用性: 消除了单点故障(Broker 宕机的风险)。
-
简化部署: 系统架构更简单,运维成本更低。
-
高性能与低延迟
ZMQ 底层由 C++ 实现,对性能进行了极致优化。它通过批量处理消息、减少内存拷贝、无锁数据结构等技术,实现了非常高的吞吐量和微秒级的低延迟,这对于性能敏感的应用至关重要。
- 简化网络编程
ZMQ 自动处理了很多棘手的网络问题,让开发者可以专注于业务逻辑:
- 自动重连: 如果连接因网络问题断开,ZMQ 会在后台自动尝试重新连接。
- 消息分帧: ZMQ 能明确地处理消息边界,你接收到的永远是一个完整的消息,而不会是半个或多个粘连在一起的消息。
-
连接管理: 开发者无需关心底层的连接建立、维护和关闭的复杂细节。
-
多语言支持与跨平台 (Polyglot)
ZMQ 拥有极其丰富的语言绑定,无论你的团队使用 C++, Python, Java, C#, Go, Ruby 还是其他语言,都可以找到成熟的库来使用 ZMQ,非常适合构建异构的分布式系统。
- 支持多种传输协议
ZMQ 可以在多种底层传输协议上运行,开发者可以根据需要灵活选择:
tcp: 用于跨机器的可靠连接。ipc: 用于同一台机器上的进程间通信,效率非常高。inproc: 用于同一进程内不同线程间的通信,几乎是零拷贝,速度极快。multicast: 用于多播/广播场景。
ZMQ的典型应用场景¶
基于以上优势,ZMQ 特别适用于以下应用领域:
- 分布式系统与微服务
ZMQ 是构建微服务架构的理想工具。服务之间可以通过 Request/Reply 模式进行通信,通过 Publish/Subscribe 模式进行事件通知,实现服务发现和配置分发。其无中心代理的特性非常适合去中心化的微服务理念。
- 金融交易系统
在量化交易和高频交易领域,延迟是决定成败的关键。ZMQ 的微秒级低延迟和高吞吐能力,使其成为传递市场行情、执行交易指令的绝佳选择。
- 科学计算与高性能计算 (HPC)
在需要大规模并行计算的场景中,可以使用 ZMQ 的 Push/Pull 模式来构建一个任务分发系统。一个主节点将计算任务 PUSH 到一个由大量计算节点组成的集群中,计算节点 PULL 任务并处理,最后将结果汇总。
- 物联网 (IoT)
成千上万的传感器和设备需要将数据上报到数据中心。ZMQ 的 Publish/Subscribe 模式可以让设备作为发布者,数据收集服务作为订阅者。其轻量级和低资源消耗的特性也适合在嵌入式设备上运行。
- 数据管道与日志聚合
可以使用 ZMQ 构建一个高效的日志收集管道。应用服务器上的日志代理通过 PUSH 将日志条目发送出去,远端的日志聚合服务通过 PULL 接收这些日志进行处理和存储。
- 高性能的进程间/线程间通信 (IPC/ITC)
当你在同一台服务器上需要让多个进程或一个进程内的多个线程高速交换数据时,使用 ZMQ 的 ipc 或 inproc 传输协议会比传统的文件、管道或系统消息队列等方式更加高效和方便。
总之,ZMQ 是一个强大的网络通信工具箱,它并非要取代所有的通信技术,而是为那些需要高性能、高并发、灵活拓扑结构的复杂分布式系统提供了一套优雅而强大的解决方案。
当然,ZMQ 在工业界和开源社区中都有许多经典且优秀的应用案例。这些案例充分展示了 ZMQ 在不同场景下的强大能力,其中很多著名项目你可能每天都在使用,但没有意识到其底层是由 ZMQ 驱动的。
代表性案例¶
Jupyter Notebook / IPython:无处不在的科学计算平台¶
- 应用场景: 连接用户在浏览器中操作的前端界面与后台执行代码的计算内核(Kernel)。
- 技术解析: 这是 ZMQ 最经典、最广为人知的应用之一。Jupyter 的架构完美地利用了 ZMQ 的多种通信模式:
- 请求/响应 (Req/Rep): 用户在浏览器单元格中执行代码,前端通过一个
REQ套接字发送执行请求;后端的内核通过一个REP套接字接收请求、执行代码并返回结果。 - 发布/订阅 (Pub/Sub): 内核将代码执行过程中的所有“副作用”——例如
print输出、图表生成、警告信息等——通过一个PUB套接-字广播出去;前端则通过一个SUB套接字订阅并接收这些信息,实时显示给用户。 - 心跳机制: 还使用一对
REQ/REP套接字来维持一个简单的心跳,以检测内核是否仍然存活。
- 请求/响应 (Req/Rep): 用户在浏览器单元格中执行代码,前端通过一个
- 价值体现: ZMQ 的多模式、解耦和跨语言特性,使得 Jupyter 可以轻松实现一个语言无关的、前后端分离的、可交互的计算环境。你可以用同一个浏览器前端,连接到 Python 内核、R 内核或 Julia 内核。
CERN (欧洲核子研究组织):处理顶级科研数据¶
- 应用场景: 在大型强子对撞机 (LHC) 等实验中,用于控制系统、数据采集和监控信息的分发。
- 技术解析: LHC 每秒产生海量的数据,对数据传输的性能、吞吐量和可靠性要求极高。ZMQ 在这里的角色是:
- 数据分发: 将来自成千上万个探测器的数据和状态信息,通过
PUB/SUB模式高效地分发给不同的监控和存储系统。 - 控制信令: 使用
REQ/REP或PUSH/PULL模式向实验设备发送控制命令和配置参数。
- 数据分发: 将来自成千上万个探测器的数据和状态信息,通过
- 价值体现: ZMQ 的高性能、低延迟和无中心代理架构,使其能够在这种极端环境下稳定工作,确保宝贵的实验数据被可靠地收集和处理。
金融高频交易 (HFT):追求极致的速度¶
- 应用场景: 在金融市场中分发实时行情数据、传递交易指令和执行状态。
- 技术解析: 在高频交易中,哪怕是微秒级的延迟都可能导致巨大的经济损失。ZMQ 在这个领域的应用是其核心优势的终极体现:
- 行情广播: 交易所或数据提供商通过
PUB套接字,以极低的延迟向成百上千个交易客户端广播市场行情数据(股票报价、期货深度等)。 - 指令下单: 交易策略程序通过
REQ或PUSH套接字,将交易指令以最快的速度发送到交易网关执行。
- 行情广播: 交易所或数据提供商通过
- 价值体现: ZMQ 的微秒级延迟和高吞吐能力,使其成为构建这类对速度要求苛刻的系统的首选技术之一。
微软 Azure:云平台的内部通信 ☁️¶
- 应用场景: 在 Azure 云平台的某些内部组件和服务中,用于实现服务间的消息通信和协调。
- 技术解析: 像 Azure 这样的超大规模云平台,内部包含了无数个微服务。ZMQ 曾被用于这些服务之间需要高性能、低耦合通信的场景。例如,一个服务的多个实例可以通过
PUSH/PULL模式来处理一个任务队列,或者通过PUB/SUB来订阅平台范围内的状态变更事件。 - 价值体现: ZMQ 的灵活性和高性能,使其能够作为大型复杂系统中的“通信粘合剂”,构建出可靠且可扩展的内部基础设施。
这些案例共同说明了 ZMQ 的核心价值:它是一个高性能的并发工具箱,专门用于解决那些需要灵活拓扑、低延迟、高吞-吐量的分布式系统通信问题。
以下由 ZMQ 的原作者之一 Pieter Hintjens 撰写
第1章 - 基础知识¶
改造世界¶
如何解释 ZeroMQ?我们中的一些人会从它所做的所有精彩事情开始说起。它是增强版的套接字。它就像带路由的邮箱。它很快! 有些人试图分享他们的顿悟时刻,那种“啪—砰—轰”的顿悟范式转变的瞬间,一切都变得显而易见。事情变得更简单了。复杂性消失了。它打开了思路。 还有些人试图通过比较来解释。它更小、更简单,但依然看起来熟悉。 就个人而言,我喜欢记住为什么我们要做 ZeroMQ,因为这很可能就是你,读者,现在所处的位置。
编程是披着艺术外衣的科学,因为我们大多数人不了解软件的物理学,而这通常几乎不会被教授。软件的物理学不是算法、数据结构、语言和抽象。这些只是我们制作、使用、丢弃的工具。软件的真正物理学是人的物理学——具体来说,是我们面对复杂性时的局限,以及我们希望协作分块解决大问题的愿望。这就是编程的科学:制造人们能够轻松理解和使用的构建模块,人们便能协作解决最大的问题。
我们生活在一个互联的世界,现代软件必须在这个世界中导航。因此,明天最大的解决方案的构建模块是连接的、海量并行的。代码“强大且沉默”已经不够了。代码必须与代码对话。代码必须健谈、社交、互联良好。代码必须像人脑一样运行,数万亿个独立的神经元彼此发送信息,一个没有中央控制、没有单点故障的超大规模并行网络,却能解决极其复杂的问题。代码的未来看起来像人脑绝非偶然,因为每个网络的终端,在某种程度上,都是人脑。
如果你有线程、协议或网络方面的经验,你会意识到这几乎是不可能的。这是一个梦想。即使是连接几个程序通过几个套接字,在处理现实情况时也是极其棘手的。数万亿?成本将是难以想象的。连接计算机如此困难,以至于提供此类软件和服务已成为数十亿美元的产业。
所以我们生活在一个布线技术远远领先于我们使用能力的世界。上世纪80年代我们经历了一场软件危机,当时像 Fred Brooks 这样的顶尖软件工程师认为不存在“银弹”,能够“承诺在生产率、可靠性或简单性方面提升一个数量级”。
Brooks 忽略了自由开源软件,它解决了那场危机,使我们能高效地共享知识。今天我们面临另一场软件危机,但鲜少谈论。只有最大、最富有的公司能负担得起构建连接应用。虽然有云,但它是专有的。我们的数据和知识正从个人电脑消失,进入我们无法访问、无法竞争的云端。谁拥有我们的社交网络?这就像大型机与个人电脑革命的逆转。
政治哲学部分留待另一本书论述。重点是,虽然互联网提供了大规模连接代码的潜力,但现实是大多数人无法触及,因此许多有趣的大问题(健康、教育、经济、交通等)依然未解,因为无法连接代码,也就无法连接那些能合作解决问题的大脑。
解决连接代码挑战的尝试很多。有成千上万的 IETF 规范,每个解决部分难题。对于应用开发者,HTTP 也许是唯一简单有效的解决方案,但它可能使问题更糟,鼓励开发者和架构师用大型服务器和瘦弱、愚蠢的客户端思维。
因此如今人们仍使用原始的 UDP 和 TCP、专有协议、HTTP 和 Websockets 连接应用。这依然痛苦、缓慢、难以扩展,本质上是集中式的。分布式 P2P 架构多为娱乐用途而非工作应用。有多少应用使用 Skype 或 Bittorrent 交换数据?
这让我们回到编程科学。要改造世界,我们需要做两件事。第一,解决“如何连接任何代码到任何代码,任何地点”的通用问题。第二,将其封装成最简单的构建模块,使人们能轻松理解和使用。
听起来荒谬地简单。或许确实如此。这就是关键所在。
起始假设¶
我们假设你至少使用 ZeroMQ 3.2 版本。假设你用的是 Linux 或类似系统。假设你或多或少能读懂 C 代码,因为示例默认用它。假设当我们写常量如 PUSH 或 SUBSCRIBE 时,你能理解如果编程语言需要,实际叫做 ZMQ_PUSH 或 ZMQ_SUBSCRIBE。
获取示例¶
示例代码存放在一个公开的GitHub 仓库中。获取所有示例最简单的办法是克隆此仓库:
接着浏览 examples 子目录。你会找到按语言分类的示例。如果你使用的语言缺少示例,欢迎提交翻译。正是许多人的贡献让本文档如此有用。所有示例均采用 MIT/X11 许可证。
有求必应¶
那么我们从一些代码开始。当然,我们先从一个 Hello World 示例开始。我们将创建一个客户端和一个服务器。客户端发送“Hello”给服务器,服务器回复“World”。下面是用 C 写的服务器端代码,它在 5555 端口打开一个 ZeroMQ 套接字,读取请求,并对每个请求回复“World”:
hwserver: Hello World server in C
//
// Hello World server in C++
// Binds REP socket to tcp://*:5555
// Expects "Hello" from client, replies with "World"
//
#include <zmq.hpp>
#include <string>
#include <iostream>
#ifndef _WIN32
#include <unistd.h>
#else
#include <windows.h>
#define sleep(n) Sleep(n)
#endif
int main () {
// Prepare our context and socket
static const int kNumberOfThreads = 2;
zmq::context_t context (kNumberOfThreads);
zmq::socket_t socket (context, zmq::socket_type::rep);
socket.bind ("tcp://*:5555");
while (true) {
zmq::message_t request;
// Wait for next request from client
auto result = socket.recv (request, zmq::recv_flags::none);
assert(result.value_or(0) != 0); // Check if bytes received is non-zero
std::cout << "Received Hello" << std::endl;
// Pretend to do some 'work'
sleep(1);
// Send reply back to client
constexpr std::string_view kReplyString = "World";
zmq::message_t reply (kReplyString.length());
memcpy (reply.data (), kReplyString.data(), kReplyString.length());
socket.send (reply, zmq::send_flags::none);
}
return 0;
}
Figure 2 - Request-Reply
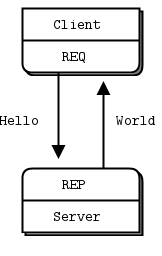
REQ-REP 套接字对是步调一致的。客户端循环中先调用 zmq_send(),然后调用 zmq_recv()(如果只需要一次,也可以只执行一次)。如果执行其他顺序(例如连续发送两条消息),send 或 recv 调用将返回错误码 -1。同样,服务端按顺序调用 zmq_recv(),然后调用 zmq_send(),频率根据需要而定。
ZeroMQ 使用 C 作为参考语言,这也是我们示例中主要使用的语言。如果你在线阅读本文,示例下方的链接会带你查看其他编程语言的翻译。下面对比一下用 C++ 写的同一个服务器:
hwserver: Hello World server in C++
//
// Hello World server in C++
// Binds REP socket to tcp://*:5555
// Expects "Hello" from client, replies with "World"
//
#include <zmq.hpp>
#include <string>
#include <iostream>
#ifndef _WIN32
#include <unistd.h>
#else
#include <windows.h>
#define sleep(n) Sleep(n)
#endif
int main () {
// Prepare our context and socket
static const int kNumberOfThreads = 2;
zmq::context_t context (kNumberOfThreads);
zmq::socket_t socket (context, zmq::socket_type::rep);
socket.bind ("tcp://*:5555");
while (true) {
zmq::message_t request;
// Wait for next request from client
auto result = socket.recv (request, zmq::recv_flags::none);
assert(result.value_or(0) != 0); // Check if bytes received is non-zero
std::cout << "Received Hello" << std::endl;
// Pretend to do some 'work'
sleep(1);
// Send reply back to client
constexpr std::string_view kReplyString = "World";
zmq::message_t reply (kReplyString.length());
memcpy (reply.data (), kReplyString.data(), kReplyString.length());
socket.send (reply, zmq::send_flags::none);
}
return 0;
}
你可以看到 ZeroMQ 的 API 在 C 和 C++ 中非常相似。在像 PHP 或 Java 这样的语言中,我们可以封装得更多,代码会变得更加易读:
hwserver: Hello World server in PHP
<?php
/*
* Hello World server
* Binds REP socket to tcp://*:5555
* Expects "Hello" from client, replies with "World"
* @author Ian Barber <ian(dot)barber(at)gmail(dot)com>
*/
$context = new ZMQContext(1);
// Socket to talk to clients
$responder = new ZMQSocket($context, ZMQ::SOCKET_REP);
$responder->bind("tcp://*:5555");
while (true) {
// Wait for next request from client
$request = $responder->recv();
printf ("Received request: [%s]\n", $request);
// Do some 'work'
sleep (1);
// Send reply back to client
$responder->send("World");
}
hwserver: Hello World server in Java
package guide;
//
// Hello World server in Java
// Binds REP socket to tcp://*:5555
// Expects "Hello" from client, replies with "World"
//
import org.zeromq.SocketType;
import org.zeromq.ZMQ;
import org.zeromq.ZContext;
public class hwserver
{
public static void main(String[] args) throws Exception
{
try (ZContext context = new ZContext()) {
// Socket to talk to clients
ZMQ.Socket socket = context.createSocket(SocketType.REP);
socket.bind("tcp://*:5555");
while (!Thread.currentThread().isInterrupted()) {
byte[] reply = socket.recv(0);
System.out.println(
"Received " + ": [" + new String(reply, ZMQ.CHARSET) + "]"
);
Thread.sleep(1000); // Do some 'work'
String response = "world";
socket.send(response.getBytes(ZMQ.CHARSET), 0);
}
}
}
}
The server in other languages:
(略)
Here’s the client code:
hwclient: Hello World client in C++
//
// Hello World client in C++
// Connects REQ socket to tcp://localhost:5555
// Sends "Hello" to server, expects "World" back
//
#include <zmq.hpp>
#include <string>
#include <iostream>
int main ()
{
// Prepare our context and socket
zmq::context_t context (1);
zmq::socket_t socket (context, zmq::socket_type::req);
std::cout << "Connecting to hello world server..." << std::endl;
socket.connect ("tcp://localhost:5555");
// Do 10 requests, waiting each time for a response
for (int request_nbr = 0; request_nbr != 10; request_nbr++) {
zmq::message_t request (5);
memcpy (request.data (), "Hello", 5);
std::cout << "Sending Hello " << request_nbr << "..." << std::endl;
socket.send (request, zmq::send_flags::none);
// Get the reply.
zmq::message_t reply;
socket.recv (reply, zmq::recv_flags::none);
std::cout << "Received World " << request_nbr << std::endl;
}
return 0;
}
现在这看起来过于简单,似乎不够真实,但正如我们已经了解到的,ZeroMQ 套接字拥有超能力。你可以同时向这个服务器抛出成千上万个客户端,它仍然会快乐且快速地运行。为了好玩,试着先启动客户端,然后再启动服务器,看看它依然是如何工作的,然后想一想这意味着什么。
让我们简单解释这两个程序实际在做什么。它们创建了一个 ZeroMQ 上下文用于操作,以及一个套接字。别担心这些词的含义,你会慢慢理解。服务器将其 REP(回复)套接字绑定到 5555 端口。服务器在循环中等待请求,并每次响应一个回复。客户端发送请求并从服务器读取回复。
如果你杀掉服务器(Ctrl-C)然后重启它,客户端不会正常恢复。从崩溃进程中恢复并不那么容易。构建一个可靠的请求-回复流程足够复杂,我们将在第4章 - 可靠的请求-回复模式中详细讲解。
幕后发生了很多事情,但对我们程序员来说重要的是代码简洁明了,且即使在高负载下也很少崩溃。这就是请求-回复模式,可能是使用 ZeroMQ 最简单的方式。它对应于 RPC 和经典的客户端/服务器模型。
关于字符串的一点小提示¶
ZeroMQ 对你发送的数据一无所知,唯一知道的是它的字节大小。这意味着你有责任以安全的方式格式化数据,以便应用程序能够正确读取。对于对象和复杂数据类型,这项工作通常由像 Protocol Buffers 这样的专用库来完成。但即使是字符串,也需要你注意。
在 C 语言及其他一些语言中,字符串以空字节(null byte)结尾。我们可以发送带有额外空字节的字符串,比如“HELLO”:
然而,如果你从其他语言发送字符串,通常不会包含那个空字节。例如,当我们用 Python 发送同样的字符串时,代码如下:
那么实际发送到网络上的就是一个长度(对于较短的字符串占用一个字节)和字符串内容的各个字符。
Figure 3 - A ZeroMQ string

如果你用 C 程序读取这些数据,你会得到一个看起来像字符串的东西,并且可能偶然表现得像字符串(如果幸运的话,这五个字节后面正好跟着一个无害的空字节),但它并不是一个合规的字符串。当你的客户端和服务器对字符串格式理解不一致时,会得到奇怪的结果。
当你在 C 中从 ZeroMQ 接收字符串数据时,绝不能相信它是安全终止的。每次读取字符串时,都应该分配一个额外多一个字节的新缓冲区,复制字符串,并用空字节正确终止。
所以我们要定下规则:ZeroMQ 字符串是指定长度的,传输时*不含*结尾的空字节。在最简单的情况下(我们示例中会这样做),ZeroMQ 字符串恰好对应一个 ZeroMQ 消息帧,表现如上图所示——一个长度和一些字节。
下面是我们在 C 中接收 ZeroMQ 字符串并将其作为有效 C 字符串传递给应用程序时需要做的操作:
// Receive ZeroMQ string from socket and convert into C string
// Chops string at 255 chars, if it's longer
static char *
s_recv (void *socket) {
char buffer [256];
int size = zmq_recv (socket, buffer, 255, 0);
if (size == -1)
return NULL;
if (size > 255)
size = 255;
buffer [size] = '\0';
/* use strndup(buffer, sizeof(buffer)-1) in *nix */
return strdup (buffer);
}
这就形成了一个方便的辅助函数,秉持着编写可复用代码的精神,让我们写一个类似的 s_send 函数,用来以正确的 ZeroMQ 格式发送字符串,并将其打包成一个可复用的头文件。
结果就是 zhelpers.h,它让我们能用更简洁、更优雅的方式用 C 写 ZeroMQ 应用。这个源码比较长,只对 C 开发者有趣,所以可以慢慢阅读。
关于命名约定的说明¶
在 zhelpers.h 及本指南后续示例中使用的前缀 s_ 表示静态方法或变量。
版本报告¶
ZeroMQ 有多个版本,且你遇到的问题很可能已经在较新版本中修复。因此,准确了解你实际链接的是哪个版本的 ZeroMQ 是一个有用的小技巧。
下面是一个能实现该功能的小程序:
version: ZeroMQ version reporting in C++
//
// Report 0MQ version
//
#include "zhelpers.hpp"
int main ()
{
s_version ();
return EXIT_SUCCESS;
}
发送消息¶
第二个经典模式是一对多的数据分发,其中服务器向一组客户端推送更新。来看一个例子,推送天气更新,包括邮编、温度和相对湿度。我们将生成随机值,就像真实的气象站那样。
这是服务器端。我们为这个应用使用端口 5556:
wuserver: Weather update server in C++
//
// Weather update server in C++
// Binds PUB socket to tcp://*:5556
// Publishes random weather updates
//
#include <zmq.hpp>
#include <stdio.h>
#include <stdlib.h>
#include <time.h>
#if (defined (WIN32))
#include <zhelpers.hpp>
#endif
#define within(num) (int) ((float) num * random () / (RAND_MAX + 1.0))
int main () {
// Prepare our context and publisher
zmq::context_t context (1);
zmq::socket_t publisher (context, zmq::socket_type::pub);
publisher.bind("tcp://*:5556");
publisher.bind("ipc://weather.ipc"); // Not usable on Windows.
// Initialize random number generator
srandom ((unsigned) time (NULL));
while (1) {
int zipcode, temperature, relhumidity;
// Get values that will fool the boss
zipcode = within (100000);
temperature = within (215) - 80;
relhumidity = within (50) + 10;
// Send message to all subscribers
zmq::message_t message(20);
snprintf ((char *) message.data(), 20 ,
"%05d %d %d", zipcode, temperature, relhumidity);
publisher.send(message, zmq::send_flags::none);
}
return 0;
}
这个更新流没有开始也没有结束,就像一个永不停息的广播。
下面是客户端程序,它监听这条更新流,抓取与指定邮编相关的所有信息,默认是纽约市,因为那是开始任何冒险的绝佳地点:
wuclient: Weather update client in C++
//
// Weather update client in C++
// Connects SUB socket to tcp://localhost:5556
// Collects weather updates and finds avg temp in zipcode
//
#include <zmq.hpp>
#include <iostream>
#include <sstream>
int main (int argc, char *argv[])
{
zmq::context_t context (1);
// Socket to talk to server
std::cout << "Collecting updates from weather server...\n" << std::endl;
zmq::socket_t subscriber (context, zmq::socket_type::sub);
subscriber.connect("tcp://localhost:5556");
// Subscribe to zipcode, default is NYC, 10001
const char *filter = (argc > 1)? argv [1]: "10001 ";
subscriber.set(zmq::sockopt::subscribe, filter);
// Process 100 updates
int update_nbr;
long total_temp = 0;
for (update_nbr = 0; update_nbr < 100; update_nbr++) {
zmq::message_t update;
int zipcode, temperature, relhumidity;
subscriber.recv(update, zmq::recv_flags::none);
std::istringstream iss(static_cast<char*>(update.data()));
iss >> zipcode >> temperature >> relhumidity ;
total_temp += temperature;
}
std::cout << "Average temperature for zipcode '"<< filter
<<"' was "<<(int) (total_temp / update_nbr) <<"F"
<< std::endl;
return 0;
}
Figure 4 - Publish-Subscribe
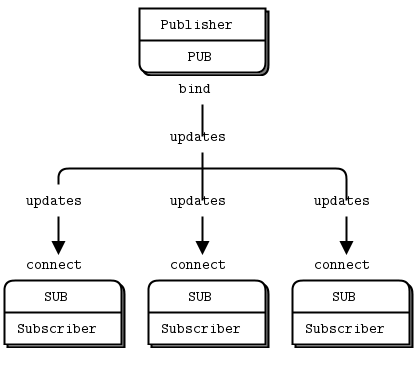
请注意,当你使用 SUB 套接字时,必须通过 zmq_setsockopt() 和 SUBSCRIBE 设置订阅,就像这段代码中那样。如果不设置任何订阅,就收不到任何消息。这是初学者常犯的错误。订阅者可以设置多个订阅,这些订阅是叠加的。也就是说,只要更新匹配任意一个订阅,订阅者就会收到。订阅者也可以取消特定订阅。订阅通常是可打印字符串,但不总是如此。具体工作方式请参见 zmq_setsockopt()。
PUB-SUB 套接字对是异步的。客户端循环调用 zmq_recv()(如果只需要一次,也可只调用一次)。尝试向 SUB 套接字发送消息会导致错误。同样,服务端根据需要频繁调用 zmq_send(),但绝不能对 PUB 套接字调用 zmq_recv()。
理论上,对于 ZeroMQ 套接字,哪端连接哪端绑定无所谓。但实际上存在未文档化的差异,稍后会讲。现在建议让 PUB 端绑定,SUB 端连接,除非你的网络设计无法做到。
关于 PUB-SUB 套接字,还有一点很重要:你无法准确知道订阅者何时开始接收消息。即使你先启动订阅者,等待一段时间后再启动发布者,订阅者总会错过发布者发送的最初几条消息。这是因为订阅者连接发布者需要一定(虽短但非零)的时间,而发布者可能已开始发送消息。
这个“慢加入者”现象困扰了很多人,我们将详细说明。记住 ZeroMQ 做的是异步 I/O,即在后台操作。假设有两个节点按以下顺序执行:
- 订阅者连接到某个端点,开始接收并计数消息。
- 发布者绑定到某个端点,立即发送 1000 条消息。
那么订阅者很可能收不到任何消息。你会怀疑设置了错误的过滤器,重新尝试,仍然收不到消息。
建立 TCP 连接需要双向握手,耗时数毫秒,具体取决于网络和节点之间跳数。在此期间,ZeroMQ 可能发送了许多消息。举例说明,假设建立连接耗时 5 毫秒,链路带宽为每秒 100 万条消息。在订阅者连接发布者的这 5 毫秒内,发布者仅用 1 毫秒就发送了 1000 条消息。
在第2章 - 套接字和模式中,我们将讲解如何同步发布者和订阅者,使发布者只有在订阅者真正连接并准备好后才开始发布数据。延迟发布者的简单粗暴方法是睡眠等待,但不要在真实应用中这么做,因为这既脆弱又不优雅且缓慢。你可以用睡眠来验证问题,然后等到第2章 - 套接字和模式了解正确的解决方案。
另一种选择是不做同步,假设发布的数据流是无限且无起点无终点的,也假设订阅者不关心它启动前发生的事情。这就是我们构建天气客户端示例的方法。
因此客户端订阅它选择的邮编,收集该邮编的 100 条更新。若邮编随机分布,服务器会发送大约一千万条更新。你可以先启动客户端,再启动服务器,客户端依然正常工作。服务器可以随时停止重启,客户端仍持续运行。当客户端收集到 100 条更新后,会计算平均值,打印结果,然后退出。
关于发布-订阅(pub-sub)模式的一些要点:
- 订阅者可以连接多个发布者,每次调用一次 connect。数据随后会交错(“公平排队”)到达,确保没有单个发布者消息淹没其他发布者。
- 如果发布者没有连接的订阅者,它会直接丢弃所有消息。
- 如果你使用 TCP,且某个订阅者处理较慢,消息会在发布者端排队。稍后我们将讨论如何使用“高水位线”保护发布者。
- 从 ZeroMQ 3.x 版本开始,使用连接协议(
tcp:@<*>@*或ipc:@<>@)时,过滤发生在发布者端。使用epgm:@<//>@协议时,过滤发生在订阅者端。在 ZeroMQ 2.x 版本中,所有过滤都发生在订阅者端。
下面是在我的笔记本电脑(2011 年的 Intel i5,性能尚可但不算特别)上接收并过滤 1000 万条消息所需的时间:
$ time wuclient
Collecting updates from weather server...
Average temperature for zipcode '10001 ' was 28F
real 0m4.470s
user 0m0.000s
sys 0m0.008s
分而治之¶
Figure 5 - Parallel Pipeline
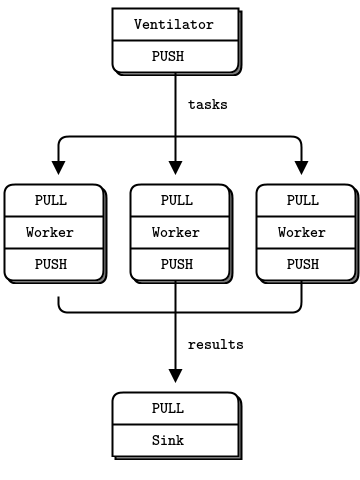
作为最后一个示例(你肯定已经看腻了丰富的代码,想回去深入探讨比较抽象规范的语言学讨论),让我们做一点超级计算。然后喝杯咖啡。我们的超级计算应用是一个相当典型的并行处理模型。它包括:
- 一个发送器(ventilator),产生可以并行处理的任务
- 一组处理任务的工作者
- 一个汇集工作者处理结果的汇聚点(sink)
实际上,工作者运行在超高速计算机上,可能使用 GPU(图形处理单元)来完成复杂计算。下面是发送器代码。它生成 100 个任务,每个任务是一条消息,告诉工作者休眠若干毫秒:
taskvent: Parallel task ventilator in C++
//
// Task ventilator in C++
// Binds PUSH socket to tcp://localhost:5557
// Sends batch of tasks to workers via that socket
//
#include <zmq.hpp>
#include <stdlib.h>
#include <stdio.h>
#include <unistd.h>
#include <iostream>
#define within(num) (int) ((float) num * random () / (RAND_MAX + 1.0))
int main (int argc, char *argv[])
{
zmq::context_t context (1);
// Socket to send messages on
zmq::socket_t sender(context, ZMQ_PUSH);
sender.bind("tcp://*:5557");
std::cout << "Press Enter when the workers are ready: " << std::endl;
getchar ();
std::cout << "Sending tasks to workers...\n" << std::endl;
// The first message is "0" and signals start of batch
zmq::socket_t sink(context, ZMQ_PUSH);
sink.connect("tcp://localhost:5558");
zmq::message_t message(2);
memcpy(message.data(), "0", 1);
sink.send(message);
// Initialize random number generator
srandom ((unsigned) time (NULL));
// Send 100 tasks
int task_nbr;
int total_msec = 0; // Total expected cost in msecs
for (task_nbr = 0; task_nbr < 100; task_nbr++) {
int workload;
// Random workload from 1 to 100msecs
workload = within (100) + 1;
total_msec += workload;
message.rebuild(10);
memset(message.data(), '\0', 10);
sprintf ((char *) message.data(), "%d", workload);
sender.send(message);
}
std::cout << "Total expected cost: " << total_msec << " msec" << std::endl;
sleep (1); // Give 0MQ time to deliver
return 0;
}
这是工作者程序。它接收一条消息,休眠相应的秒数,然后发送完成信号:
taskwork: Parallel task worker in C++
//
// Task worker in C++
// Connects PULL socket to tcp://localhost:5557
// Collects workloads from ventilator via that socket
// Connects PUSH socket to tcp://localhost:5558
// Sends results to sink via that socket
//
#include "zhelpers.hpp"
#include <string>
int main (int argc, char *argv[])
{
zmq::context_t context(1);
// Socket to receive messages on
zmq::socket_t receiver(context, ZMQ_PULL);
receiver.connect("tcp://localhost:5557");
// Socket to send messages to
zmq::socket_t sender(context, ZMQ_PUSH);
sender.connect("tcp://localhost:5558");
// Process tasks forever
while (1) {
zmq::message_t message;
int workload; // Workload in msecs
receiver.recv(&message);
std::string smessage(static_cast<char*>(message.data()), message.size());
std::istringstream iss(smessage);
iss >> workload;
// Do the work
s_sleep(workload);
// Send results to sink
message.rebuild();
sender.send(message);
// Simple progress indicator for the viewer
std::cout << "." << std::flush;
}
return 0;
}
这是汇聚点(sink)程序。它收集这 100 个任务的结果,然后计算整个处理过程耗时,从而确认如果有多个工作者,它们确实是并行运行的:
tasksink: Parallel task sink in C++
//
// Task sink in C++
// Binds PULL socket to tcp://localhost:5558
// Collects results from workers via that socket
//
#include <zmq.hpp>
#include <time.h>
#include <sys/time.h>
#include <iostream>
int main (int argc, char *argv[])
{
// Prepare our context and socket
zmq::context_t context(1);
zmq::socket_t receiver(context,ZMQ_PULL);
receiver.bind("tcp://*:5558");
// Wait for start of batch
zmq::message_t message;
receiver.recv(&message);
// Start our clock now
struct timeval tstart;
gettimeofday (&tstart, NULL);
// Process 100 confirmations
int task_nbr;
int total_msec = 0; // Total calculated cost in msecs
for (task_nbr = 0; task_nbr < 100; task_nbr++) {
receiver.recv(&message);
if (task_nbr % 10 == 0)
std::cout << ":" << std::flush;
else
std::cout << "." << std::flush;
}
// Calculate and report duration of batch
struct timeval tend, tdiff;
gettimeofday (&tend, NULL);
if (tend.tv_usec < tstart.tv_usec) {
tdiff.tv_sec = tend.tv_sec - tstart.tv_sec - 1;
tdiff.tv_usec = 1000000 + tend.tv_usec - tstart.tv_usec;
}
else {
tdiff.tv_sec = tend.tv_sec - tstart.tv_sec;
tdiff.tv_usec = tend.tv_usec - tstart.tv_usec;
}
total_msec = tdiff.tv_sec * 1000 + tdiff.tv_usec / 1000;
std::cout << "\nTotal elapsed time: " << total_msec << " msec\n" << std::endl;
return 0;
}
一个批次的平均耗时是 5 秒。当我们启动 1、2 或 4 个工作者时,汇聚点得到的结果如下:
- 1 个工作者:总耗时 5034 毫秒。
- 2 个工作者:总耗时 2421 毫秒。
- 4 个工作者:总耗时 1018 毫秒。
让我们更详细地看看这段代码的几个方面:
- 工作者连接上游的发送器(ventilator)和下游的汇聚点(sink)。这意味着你可以任意增加工作者。如果工作者绑定自己的端点,你就需要(a)更多的端点,(b)每增加一个工作者都要修改发送器和/或汇聚点。我们称发送器和汇聚点是架构中的稳定部分,工作者是动态部分。
- 我们必须同步批次开始时所有工作者都已启动并运行。这是 ZeroMQ 中一个常见的陷阱,且没有简单的解决方案。
zmq_connect方法需要一定时间。因此当一组工作者连接到发送器时,第一个成功连接的工作者会在其他工作者也在连接的短时间内收到大量消息。如果你不以某种方式同步批次开始,系统根本不会并行运行。尝试去掉发送器中的等待,看看会发生什么。 - 发送器的 PUSH 套接字均匀地分发任务给工作者(假设它们都在批次开始之前连接好了)。这称为负载均衡,我们会更详细地讨论。
- 汇聚点的 PULL 套接字均匀收集来自工作者的结果。这称为公平排队。
Figure 6 - Fair Queuing
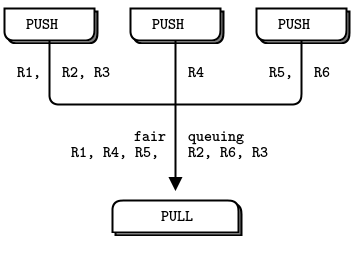
流水线模式同样会出现“慢加入者”现象,因此有人指责 PUSH 套接字负载均衡不当。如果你使用 PUSH 和 PULL,且某个工作者收到的消息远多于其他工作者,那是因为该工作者的 PULL 套接字比其他套接字更快连接,抢先接收了大量消息,而其他工作者尚未连接成功。如果你需要真正的负载均衡,建议参考第3章 - 高级请求-回复模式中的负载均衡模式。
使用 ZeroMQ 编程¶
看过一些示例后,你一定迫不及待地想在某些应用中使用 ZeroMQ。开始之前,先深呼吸,放轻松,思考一些基本建议,能帮你避免很多压力和困惑。
- 逐步学习 ZeroMQ。它只是一个简单的 API,但背后隐藏着无限可能。慢慢接受这些可能性,逐个掌握。
- 写优雅的代码。丑陋的代码掩盖问题,也让别人难以帮你。你可能习惯了无意义的变量名,但读你代码的人不会。使用真正有意义的词汇作为名字,避免表达“我太粗心,没告诉你这个变量到底是做什么的”。保持一致的缩进和整洁的排版。写好代码,你的世界会更舒适。
- 边做边测。程序不工作时,你应该知道是哪五行代码出了问题。尤其是在玩 ZeroMQ 魔法时,前几次尝试几乎不会成功。
- 当发现程序表现不如预期,把代码拆分成块,逐一测试,找出不工作的部分。ZeroMQ 允许你写模块化代码,善加利用。
- 根据需要做抽象(类、方法等)。如果大量复制粘贴代码,也会复制粘贴错误。
正确获取上下文¶
ZeroMQ 应用总是先创建一个上下文,然后用它创建套接字。在 C 语言中是调用 zmq_ctx_new()。你应该在进程中只创建并使用一个上下文。从技术上讲,上下文是单进程中所有套接字的容器,并作为 inproc 套接字的传输机制,inproc 是连接同一进程中线程的最快方式。如果运行时一个进程有两个上下文,它们就像是两个独立的 ZeroMQ 实例。如果你明确需要这样,也可以,但否则请记住:
在进程开始时调用一次 zmq_ctx_new(),在进程结束时调用一次 zmq_ctx_destroy()。
如果你使用 fork() 系统调用,应在 fork 之后、子进程代码开始时调用 zmq_ctx_new()。一般来说,你希望在子进程中做有趣的(ZeroMQ)工作,在父进程中做枯燥的进程管理。
优雅退出¶
有品位的程序员有着与职业杀手相同的座右铭:完成工作后务必清理干净。像 Python 这样的语言使用 ZeroMQ 时,资源会自动释放。但使用 C 时,你必须在用完对象后小心释放,否则会导致内存泄漏、应用不稳定,甚至带来坏的“业力”。
内存泄漏是一回事,但 ZeroMQ 对应用退出的方式非常挑剔。原因技术性且复杂,但归根结底,如果你留下未关闭的套接字,zmq_ctx_destroy() 函数会永远挂起。即使关闭了所有套接字,如果有待连接或待发送的数据,zmq_ctx_destroy() 默认也会无限等待,除非你在关闭套接字前将其 LINGER 设置为零。
我们需要关注的 ZeroMQ 对象包括消息、套接字和上下文。幸运的是,至少在简单程序中,这很简单:
- 尽量使用
zmq_send()和zmq_recv(),避免直接操作zmq_msg_t对象。 - 如果使用
zmq_msg_recv(),用完后务必调用zmq_msg_close()释放消息。 - 如果频繁打开和关闭套接字,可能意味着你需要重新设计应用。在某些情况下,套接字句柄只有销毁上下文时才会释放。
- 程序退出时,先关闭套接字,然后调用
zmq_ctx_destroy()销毁上下文。
以上是 C 语言开发的情况。在具有自动对象销毁的语言中,套接字和上下文会在离开作用域时自动销毁。如果使用异常,必须在类似“final”块中做清理,与其他资源相同。
多线程工作则更复杂。下一章我们将讲多线程,但考虑到有些人尽管被警告,还是会贸然尝试,下面给出在多线程 ZeroMQ 应用中优雅退出的简明指南。
首先,不要试图在多个线程中使用同一个套接字。请不要解释为什么你觉得这样很有趣,只是请不要这么做。接着,你需要关闭所有有未完成请求的套接字。正确的做法是设置较低的 LINGER 值(1 秒),然后关闭套接字。如果你的语言绑定在销毁上下文时不自动这样做,建议提交补丁。
最后,销毁上下文。这会导致所有附加线程(即共享同一上下文的线程)中阻塞的接收、轮询或发送操作返回错误。捕获该错误,然后在那个线程中设置 linger,关闭套接字并退出。切勿销毁同一个上下文两次。主线程中的 zmq_ctx_destroy 会阻塞,直到它知道的所有套接字安全关闭。
就这样!这很复杂且令人头疼,任何值得信赖的语言绑定作者都会自动完成这些步骤,使得手动关闭套接字的“舞蹈”变得不必要。
为什么我们需要 ZeroMQ¶
既然你已经见识了 ZeroMQ 的实际应用,接下来让我们回到“为什么”这个问题。
如今,许多应用由跨越某种网络(无论是局域网还是互联网)的组件组成。因此,很多应用开发者最终都涉及某种消息传递。有些开发者使用消息队列产品,但大多数时候他们自己实现,使用 TCP 或 UDP。这些协议本身不难用,但从 A 发送几个字节到 B,与以任何可靠方式做消息传递之间有巨大差别。
让我们看看使用原始 TCP 连接各部分时面临的典型问题。任何可复用的消息传递层都需要解决以下全部或大部分问题:
- 我们如何处理 I/O?应用是阻塞 I/O 还是后台处理?这是关键设计决策。阻塞 I/O 会导致架构难以扩展,但后台 I/O 正确实现非常困难。
- 如何处理动态组件,即暂时消失的部分?我们是否正式划分“客户端”和“服务器”,并要求服务器不能消失?如果想连接服务器与服务器怎么办?我们是否尝试每隔几秒重连?
- 我们如何在线路上表示消息?如何设计数据帧,使写读方便,避免缓冲区溢出,对小消息高效,同时又适应超大体积视频(比如戴派对帽跳舞的猫)?
- 如何处理无法立即交付的消息?特别是等待组件重新上线时?是丢弃消息、存数据库还是存内存队列?
- 消息队列存哪里?如果读取队列的组件很慢,导致队列积压怎么办?策略是什么?
- 如何处理消息丢失?是等待新数据、请求重发,还是构建某种可靠层保证消息不丢失?如果可靠层崩溃怎么办?
- 如果要用不同的网络传输,比如多播替代 TCP 单播,或者 IPv6,是否要重写应用,还是传输层有抽象?
- 如何路由消息?能否将同一消息发送给多个节点?能否将回复发回原请求者?
- 如何为其他语言编写 API?是重新实现线协议,还是封装库?如果是前者,如何保证高效稳定的协议栈?如果是后者,如何保证互操作?
- 如何表示数据,保证不同架构间可读?是否强制特定数据类型编码?这应是消息系统的职责还是更高层的职责?
- 如何处理网络错误?是等待重试、静默忽略还是中止?
拿一个典型开源项目比如 Hadoop Zookeeper,看看 src/c/src/zookeeper.c 中的 C API 代码。2013 年 1 月我读这段代码时,有 4200 行不明所以的内容,其中包含一个未文档化的客户端/服务器网络通信协议。我看到它很高效,因为用了 poll 替代 select。但实际上,Zookeeper 应该使用通用消息层和明确定义的线协议。让团队一次又一次重造这个轮子实在极其浪费。
那如何做可复用的消息层?既然这么多项目都需要这项技术,为什么大家还都在代码中驱动 TCP 套接字,反复解决上述问题?
事实证明,构建可复用消息系统非常困难,这也是为何很少有自由开源项目尝试,而商业消息产品复杂、昂贵、不灵活且脆弱。2006 年,iMatix 设计了 AMQP,为自由开源开发者提供了首个可复用的消息系统方案。AMQP 比许多设计更优,但仍相对复杂、昂贵且脆弱。学习使用需要数周,构建稳定架构则需要数月,尤其在遇到复杂场景时更易崩溃。
Figure 7 - Messaging as it Starts

大多数消息项目,比如 AMQP,试图以可复用的方式解决这份长长的问题清单,方法是发明一个新概念——“代理(broker)”,负责寻址、路由和排队。这导致形成一个客户端/服务器协议,或在某种未文档化协议之上封装一组 API,使应用能够与该代理通信。代理对于降低大型网络的复杂性非常有用。但在像 Zookeeper 这样的产品中引入基于代理的消息系统反而会适得其反。它意味着增加一个额外的大型设备,并产生新的单点故障。代理很快会成为瓶颈和新的风险点。如果软件支持,我们可以添加第二、第三、第四个代理,并设计故障切换方案。人们确实这么做,但这会带来更多的活动部件、更高的复杂性和更多故障点。
而且,基于代理的架构需要专门的运维团队。你得日夜监控代理,一旦它们表现异常就得“揍它们一顿”。你需要硬件设备,还需要备份设备,还需要专人管理这些设备。只有在大型应用中,这种架构才值得采用,尤其是由多个团队历经多年共同构建、包含许多活动部件的系统。
Figure 8 - Messaging as it Becomes

因此,中小型应用开发者陷入困境。要么避开网络编程,做出不具备扩展性的单体应用;要么投入网络编程,做出脆弱、复杂且难以维护的应用;要么押注某个消息产品,最终得到依赖昂贵且易损坏技术的可扩展应用。没有真正好的选择,这或许也是消息传递技术大多停留在上世纪、引发强烈情绪的原因:用户抱怨,卖支持和授权的却乐不可支。
我们需要的是一种能够完成消息传递功能、且极其简单廉价的方案,能在任何应用中几乎零成本地工作。它应该是一个仅需链接的库,无需其他依赖。没有额外部件,也就没有额外风险。它应该能在任何操作系统上运行,支持任何编程语言。
这就是 ZeroMQ:一个高效、可嵌入的库,解决应用在网络上实现良好弹性所需的绝大部分问题,且成本极低。
具体来说:
- 它异步处理 I/O,在后台线程中执行。这些线程使用无锁数据结构与应用线程通信,因此并发的 ZeroMQ 应用无需锁、信号量或其他等待状态。
- 组件可以动态加入或离开,ZeroMQ 会自动重连。这意味着你可以任意顺序启动组件。你可以构建“面向服务的架构”(SOA),服务可随时加入或退出网络。
- 它会在需要时自动排队消息。它智能地将消息推送到尽可能靠近接收方的位置,再进行排队。
- 它提供处理过载队列(称为“高水位线”)的方法。队列满时,ZeroMQ 会自动阻塞发送方,或丢弃消息,具体取决于你使用的消息模式(即所谓的“模式”)。
- 它让应用能通过任意传输方式通信:TCP、多播、进程内、进程间。你无需修改代码即可切换传输方式。
- 它安全处理慢速或阻塞的接收方,采用依赖于消息模式的不同策略。
- 它支持多种消息路由模式,如请求-回复和发布-订阅。这些模式定义了你的网络拓扑结构。
- 它允许你用单调用创建代理,进行消息排队、转发或捕获。代理能降低网络互连复杂性。
- 它精确传递完整消息,使用简单的线协议帧格式。你发送 10k 消息,就会收到 10k 消息。
- 它不对消息格式做任何强制要求。消息是大小从零到数 GB 不等的二进制大对象。当你需要表示数据时,可在其之上使用其他产品,如 msgpack、Google 的 Protocol Buffers 等。
- 它智能处理网络错误,在合理情况下自动重试。
- 它降低你的碳足迹。用更少 CPU 做更多事,意味着你的设备更省电,旧设备能用更久。奥巴马会喜欢 ZeroMQ。
实际上,ZeroMQ 不止于此。它对网络应用开发方式有颠覆性影响。表面上,它是基于套接字的 API,你调用 zmq_recv() 和 zmq_send()。但消息处理很快成为主循环,你的应用很快分解为一组消息处理任务。它优雅自然,且可扩展:每个任务映射到一个节点,节点通过任意传输方式互通。一个进程中的两个节点(节点即线程)、一台机器上的两个节点(节点即进程)、一个网络上的两个节点(节点即设备)——一切相同,无需修改应用代码。
套接字的可扩展性¶
让我们看看 ZeroMQ 的可扩展性是如何体现的。下面是一个 shell 脚本,它先启动天气服务器,然后并行启动一堆客户端:
当客户端运行时,我们使用 top 命令查看活跃进程,看到类似如下的情况(在一台四核机器上):
PID USER PR NI VIRT RES SHR S %CPU %MEM TIME+ COMMAND
7136 ph 20 0 1040m 959m 1156 R 157 12.0 16:25.47 wuserver
7966 ph 20 0 98608 1804 1372 S 33 0.0 0:03.94 wuclient
7963 ph 20 0 33116 1748 1372 S 14 0.0 0:00.76 wuclient
7965 ph 20 0 33116 1784 1372 S 6 0.0 0:00.47 wuclient
7964 ph 20 0 33116 1788 1372 S 5 0.0 0:00.25 wuclient
7967 ph 20 0 33072 1740 1372 S 5 0.0 0:00.35 wuclient
让我们稍作思考这里发生了什么。天气服务器只有一个套接字,但它却能并行向五个客户端发送数据。实际上,可能有成千上万个并发客户端。服务器应用并不“看到”它们,也不直接与它们通信。所以 ZeroMQ 套接字就像一个小服务器,默默接受客户端请求,并以网络能承受的最快速度向它们推送数据。而且它是一个多线程服务器,充分挤压你的 CPU 性能。
从 ZeroMQ v2.2 升级到 ZeroMQ v3.2¶
兼容性变更¶
这些变更不会直接影响现有应用代码:
- 发布-订阅(pub-sub)过滤现在在发布者端进行,而非订阅者端。这在许多 pub-sub 用例中显著提升性能。v3.2 版本的发布者和订阅者可以与 v2.1/v2.2 版本安全混用。
- ZeroMQ v3.2 增加了许多新 API 方法(如
zmq_disconnect()、zmq_unbind()、zmq_monitor()、zmq_ctx_set()等)。
不兼容变更¶
以下是对应用程序和语言绑定影响较大的主要方面:
- 发送/接收方法变更:
zmq_send()和zmq_recv()采用了不同且更简单的接口,旧功能改由zmq_msg_send()和zmq_msg_recv()提供。症状:编译错误。解决方案:修正代码。 - 这两个方法成功时返回正值,失败时返回 -1。v2.x 版本成功时总返回 0。症状:程序实际正常但显示错误。解决方案:严格判断返回值是否为 -1,而非非零。
zmq_poll()现在等待的是毫秒,而非微秒。症状:应用停止响应(实际上响应速度慢 1000 倍)。解决方案:在所有zmq_poll调用中使用下文定义的ZMQ_POLL_MSEC宏。ZMQ_NOBLOCK现改名为ZMQ_DONTWAIT。症状:编译时找不到ZMQ_NOBLOCK宏。ZMQ_HWM套接字选项拆分为ZMQ_SNDHWM和ZMQ_RCVHWM。症状:编译时找不到ZMQ_HWM宏。- 大多数但非全部
zmq_getsockopt()选项改为整数值。症状:运行时zmq_setsockopt和zmq_getsockopt返回错误。 - 移除
ZMQ_SWAP选项。症状:编译时找不到ZMQ_SWAP。解决方案:重设计使用该功能的代码。
推荐的兼容宏¶
对于希望兼容 v2.x 和 v3.2 版本运行的应用(如语言绑定),我们的建议是尽可能模拟 v3.2 行为。下面是一些 C 宏定义,帮助你的 C/C++ 代码兼容这两个版本(摘自 CZMQ):
#ifndef ZMQ_DONTWAIT
# define ZMQ_DONTWAIT ZMQ_NOBLOCK
#endif
#if ZMQ_VERSION_MAJOR == 2
# define zmq_msg_send(msg,sock,opt) zmq_send (sock, msg, opt)
# define zmq_msg_recv(msg,sock,opt) zmq_recv (sock, msg, opt)
# define zmq_ctx_destroy(context) zmq_term(context)
# define ZMQ_POLL_MSEC 1000 // zmq_poll is usec
# define ZMQ_SNDHWM ZMQ_HWM
# define ZMQ_RCVHWM ZMQ_HWM
#elif ZMQ_VERSION_MAJOR == 3
# define ZMQ_POLL_MSEC 1 // zmq_poll is msec
#endif
警告:不稳定的范式!¶
传统的网络编程基于一个普遍假设:一个套接字对应一个连接,一个对端。虽然存在多播协议,但这些较为少见。当我们假设“一个套接字 = 一个连接”时,我们以特定方式扩展架构。我们创建逻辑线程,每个线程处理一个套接字、一个对端。我们将智能和状态放在这些线程里。
在 ZeroMQ 宇宙中,套接字是通往快速后台通信引擎的门,这些引擎会自动管理整套连接。你看不到、无法操作、无法打开关闭或附加状态到这些连接上。无论你使用阻塞发送或接收,还是轮询,你只能与套接字通信,而非它管理的连接。连接是私有且不可见的,这正是 ZeroMQ 可扩展性的关键。
这是因为你的代码与套接字通信后,可以无需改动地处理任意数量、任意网络协议的连接。一个存在于 ZeroMQ 内部的消息模式比存在于应用代码中的消息模式具有更低的扩展成本。
因此,一般假设不再适用。当你阅读示例代码时,大脑会试图将其映射到已知知识。你读到“socket”时会想“啊,那代表了与另一个节点的连接”,这其实是错的。你读到“thread”时又会想“啊,线程代表了与另一个节点的连接”,这同样是错误的。
如果你是第一次阅读本指南,明白这一点:直到你真正写几天(或三四天)ZeroMQ 代码之前,你可能会感到困惑,特别是面对 ZeroMQ 带来的简洁时,你可能会试图用传统假设套用它,但那行不通。然后你会迎来顿悟和信任的时刻,那种“啪—砰—轰”的禅宗范式转变,一切变得清晰。