使用 Claude Code:会话管理与 100 万上下文¶
Claude Code 1M context 上线之后,他们发现一件让产品团队挠头的事——同样的 Claude Code,不同人用法差到不像同一个产品。有人开一个 session 用一整天,有人每条 prompt 都开新 session,有人疯狂用 compact,有人完全不知道有 rewind 这回事。
1M context 把这种差异放大了。
来自Claude的Thariq 之所以要写以下这篇文章,正是因为他每天都在心里跑下面这个决策树。和普通用户,差别到底在哪里呢?


文章的译文如下:
在我最近与 Claude Code 用户的交流中,一个主题反复出现:100 万 token 的上下文窗口是一把双刃剑。
它让 Claude Code 能够更长时间地自主运行,并且更可靠地处理任务,但如果你不有意识地管理会话,它也会为上下文污染打开大门。
会话管理比以往任何时候都更重要,而围绕它似乎也有很多疑问。你是在终端里一直保留一个会话,还是两个?每次提问都重新开始一个新会话?什么时候该用 compact、rewind 或 subagents?什么会导致一次糟糕的 compact?
这里面有出人意料的许多细节,而这些细节确实会深刻影响你使用 Claude Code 的体验;几乎所有这些问题,都归结于你如何管理自己的上下文窗口。
关于上下文、压缩与上下文腐化的快速入门¶

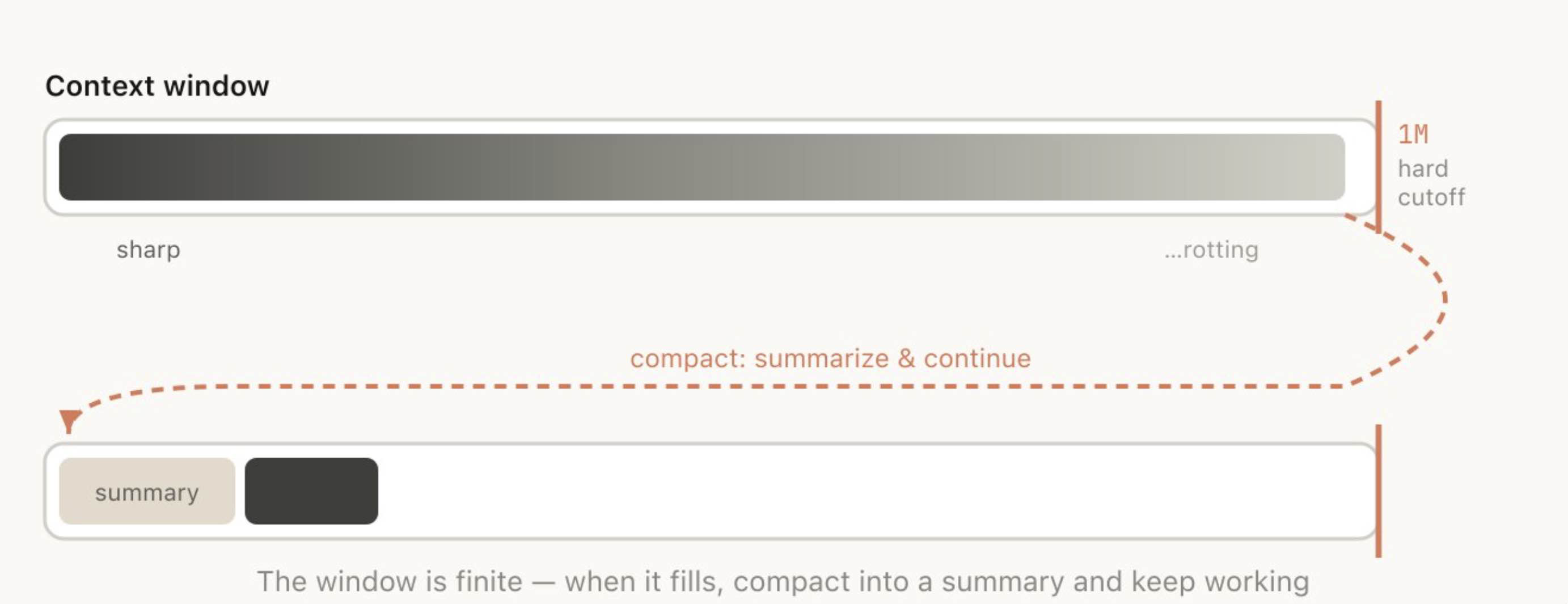
上下文窗口(context window)是指模型在生成下一次响应时,能够一次性“看到”的全部内容。它包括你的系统提示词、到目前为止的对话、每一次工具调用及其输出,以及每一个被读取过的文件。Claude Code 的上下文窗口大小为 100 万 token。
遗憾的是,使用上下文会带来一个轻微代价,这通常被称为上下文腐化(context rot)。所谓上下文腐化,是指随着上下文不断增长,模型性能会逐渐下降,因为注意力会被分散到更多 token 上,而更早期、与当前任务无关的内容也开始干扰当前任务。对于我们的 100 万上下文模型,我们观察到上下文腐化大约会在 30 万到 40 万 token 左右开始出现,但这高度依赖于具体任务,不能作为绝对规则。
上下文窗口是有硬性上限的,因此当你接近上下文窗口末尾时,就需要把你一直在处理的任务总结成一个更短的描述,并在一个新的上下文窗口中继续工作。我们把这个过程称为压缩(compaction)。你也可以主动触发压缩。
每一轮都是一个分叉点¶
假设你刚刚让 Claude 做了一件事,而它已经完成了;此时你的上下文里已经包含了一些信息(工具调用、工具输出、你的指令),接下来你实际上有很多选择:
- Continue —— 在同一个会话里继续发送下一条消息
- /rewind(esc esc) —— 跳回到之前的某条消息,并从那里重新尝试
- /clear —— 开启一个新会话,通常会带上你根据刚才所得提炼出来的简要说明
- Compact —— 总结当前会话内容,再基于总结继续进行
- Subagents —— 将下一段工作委派给一个拥有独立干净上下文的代理,并只把结果拉回主会话
虽然最自然的做法通常是直接继续,但另外四种选择的存在,正是为了帮助你管理上下文。

什么时候该开启一个新会话¶
新的 100 万上下文窗口意味着你现在可以更可靠地完成更长的任务,比如让它从零开始构建一个全栈应用。但仅仅因为模型还没有耗尽上下文,并不意味着你就不应该开启一个新会话。
我们的一般经验法则是:当你开始一个新任务时,你也应该开启一个新会话。
一个灰色地带是:你可能想处理一些彼此相关的任务,其中有一部分上下文仍然有必要保留,但并不是全部都需要。
例如,为你刚刚实现的某个功能撰写文档。虽然你也可以开启一个新会话,但 Claude 就不得不重新读取你刚才实现过的那些文件,这会更慢,也更贵。由于写文档通常不是一个对“智能敏感度”特别高的任务,所以为了不重复读取相关文件,多保留一些上下文,往往是值得的。
用回退代替纠错¶
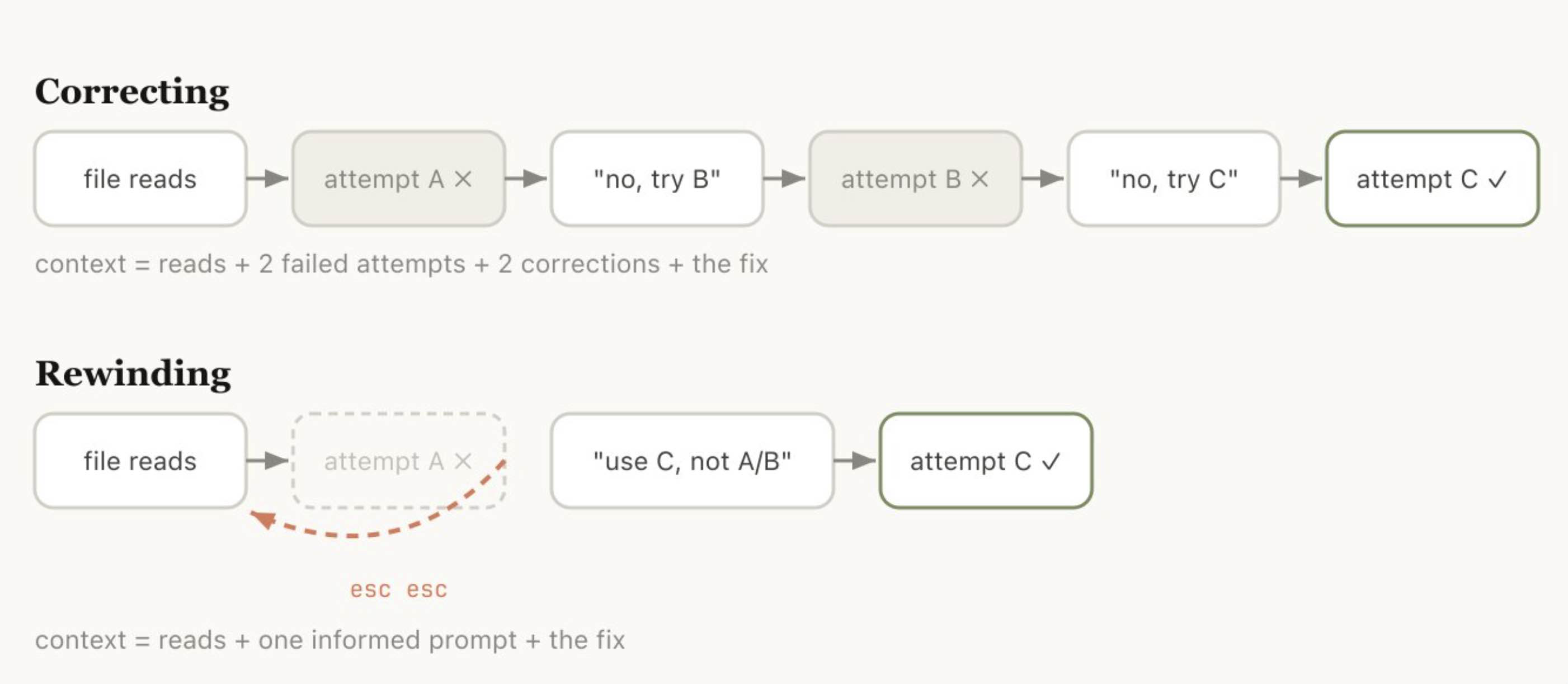
如果非要我挑一个最能体现良好上下文管理习惯的动作,那就是 rewind。
在 Claude Code 中,双击 Esc(或运行 /rewind)可以让你跳回到之前任意一条消息,并从那里重新发出提示。该位置之后的消息都会从上下文中被移除。
rewind 往往是比“直接纠正”更好的方式。比如,Claude 读了 5 个文件,尝试了一种方法,但没有成功。你的本能可能是输入:“这个不行,改试试 X。” 但更好的做法,其实是回退到刚读完文件之后,然后把你刚学到的信息重新组织成提示词。例如:“不要用方案 A,foo 模块并没有暴露那个接口——直接走方案 B。”
你也可以使用 “summarize from here”,让 Claude 对当前阶段的经验教训做一个总结,并生成一条交接消息。这有点像是让未来那个试错失败后的 Claude,给过去的自己留下一封信。
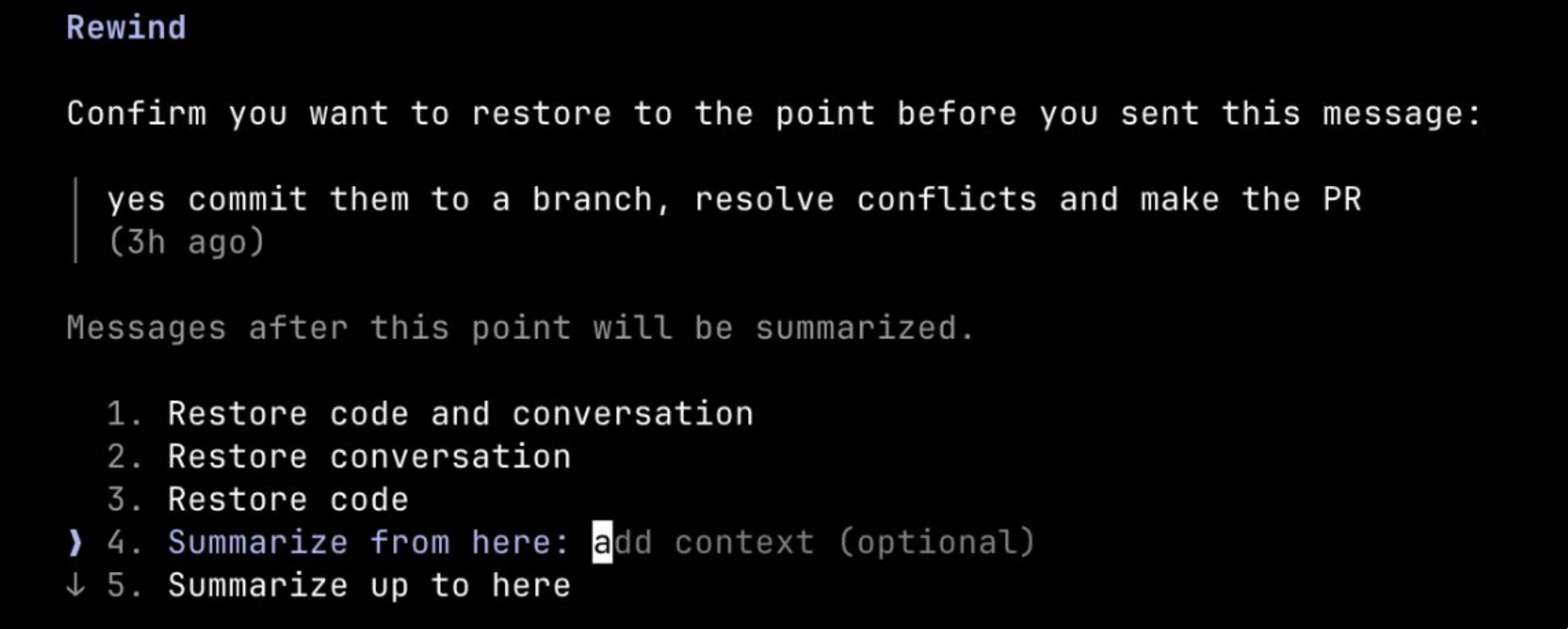
压缩与全新会话的区别¶
当一个会话变得很长时,你有两种方式来“减重”:/compact 或 /clear(然后重新开始)。它们看起来相似,但行为方式其实非常不同。
Compact 是让模型对目前为止的对话做一个总结,然后用这个总结替换原来的历史记录。这个过程会有信息损失,因为你是在让 Claude 自己判断什么重要;但它的好处是你不需要自己动笔,而且 Claude 有时反而会更全面地把重要结论或关键文件纳入总结。你也可以通过附加说明来引导它,比如:/compact focus on the auth refactor, drop the test debugging。
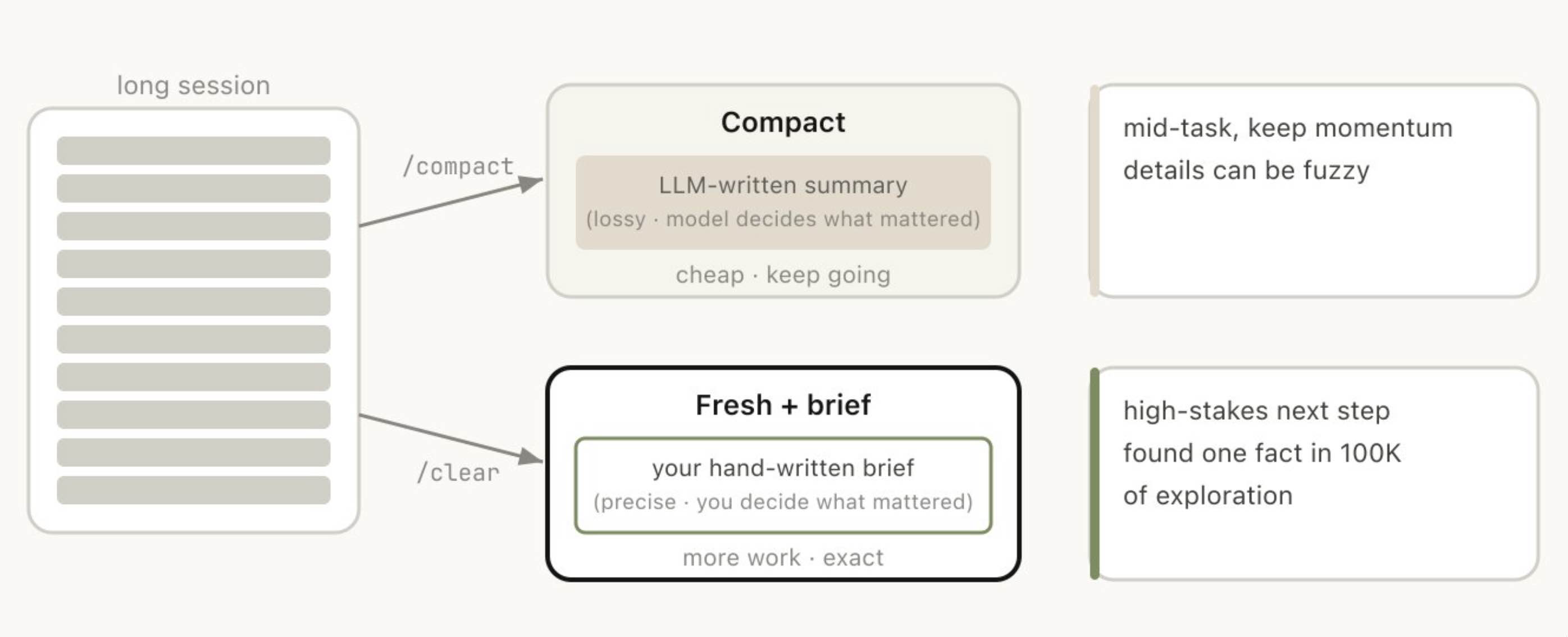
而使用 /clear 时,是由你自己写下哪些内容重要(“我们正在重构认证中间件,约束条件是 X,关键文件是 A 和 B,我们已经排除了方案 Y”),然后再从一个干净的新会话开始。它更费力,但最终得到的上下文是由你亲自决定什么相关、什么不相关。
什么会导致糟糕的 compact?¶
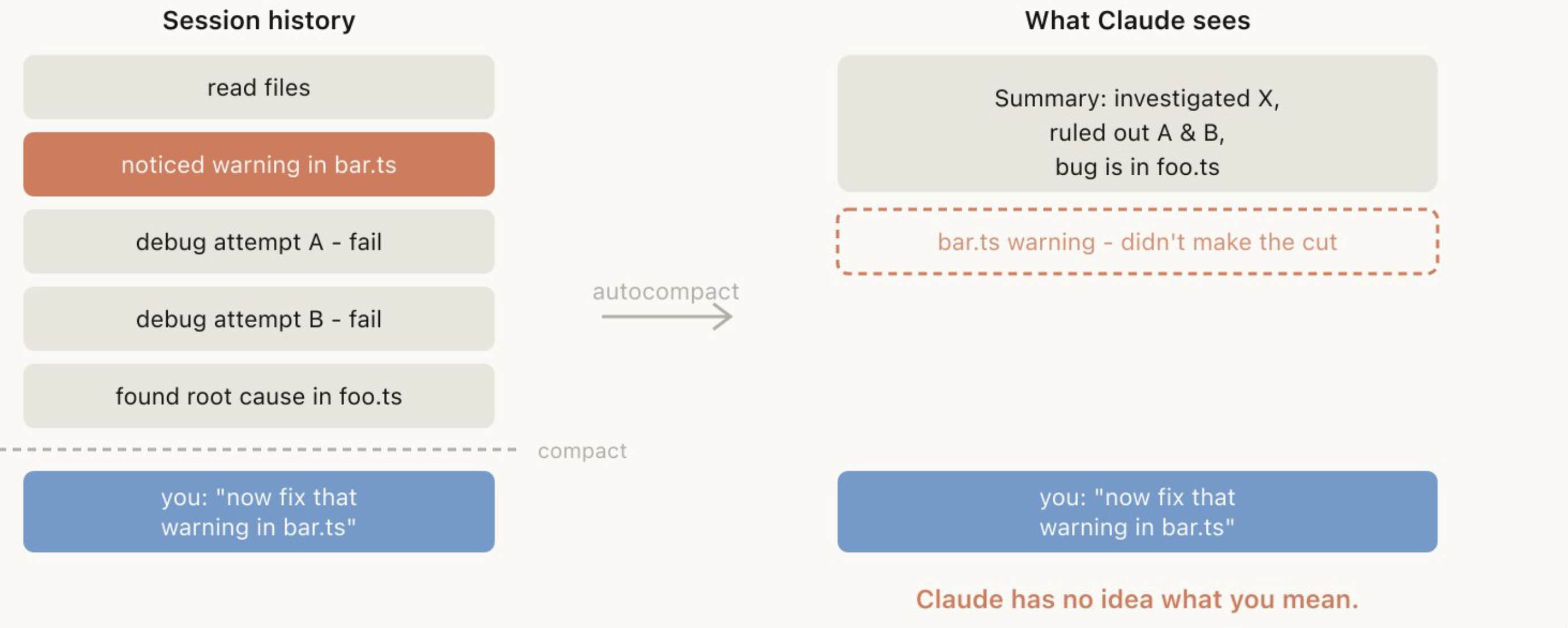
如果你经常运行很长的会话,可能已经注意到有些时候 compact 的效果会特别差。很多情况下,我们发现糟糕的 compact 往往出现在:模型无法预测你的工作接下来会转向哪里。
例如,自动 compact 在一次很长的调试会话之后触发了,它总结了这整个排查过程;结果你下一条消息却是:“现在去修复我们在 bar.ts 里看到的另一个 warning。”
但因为刚才整个会话的重心都在调试主问题上,所以那个“另一个 warning”很可能在总结里被丢掉了。
这尤其棘手,因为由于上下文腐化,模型在执行 compact 时,往往正处于它“最不聪明”的阶段。好在有了 100 万上下文,你有更多时间在真正需要之前主动执行 /compact,并明确告诉它你接下来想做什么。
Subagents 与全新的上下文窗口¶
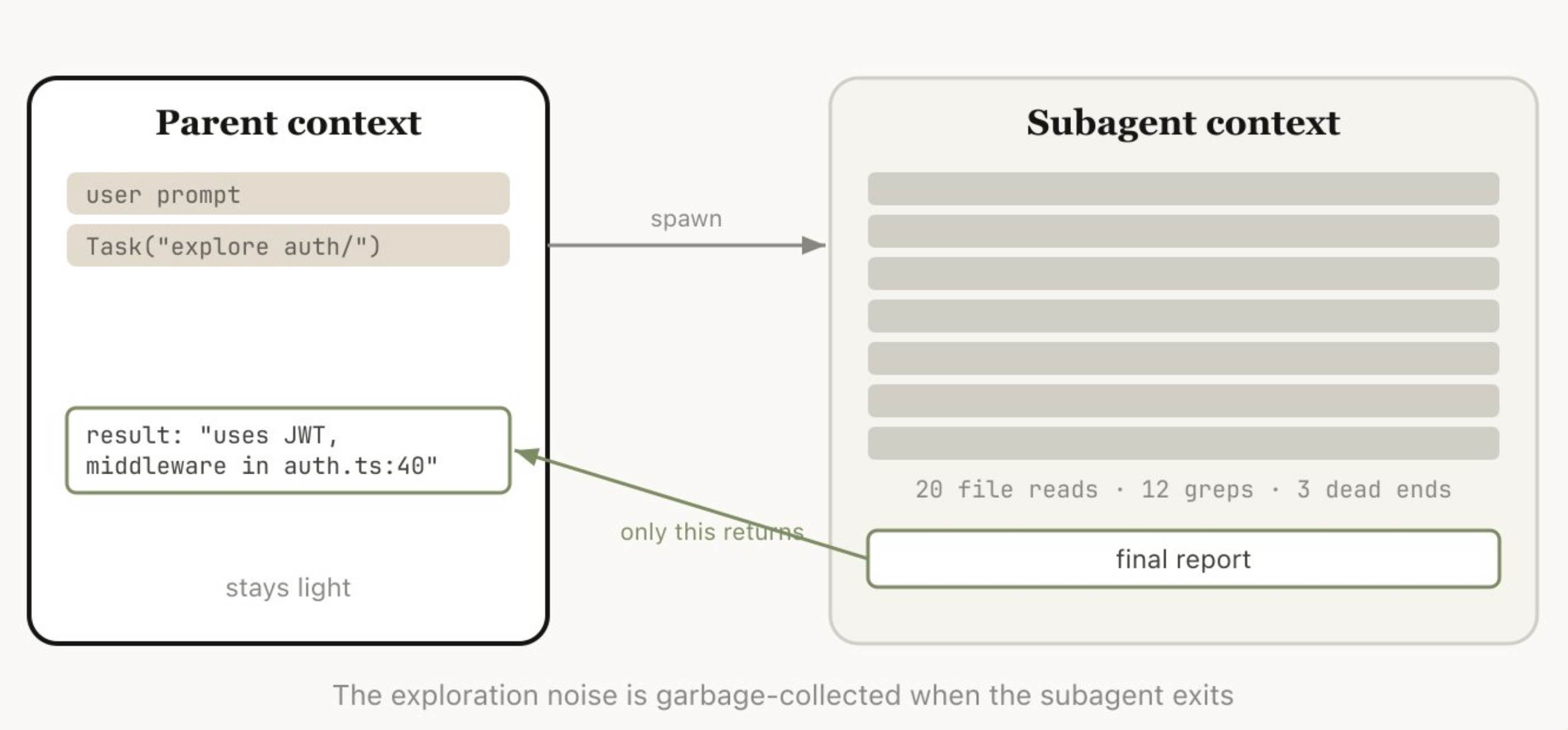
Subagents 本质上也是一种上下文管理方式。它适用于这样一种情况:你事先就知道,接下来某一块工作会产生大量中间输出,而这些输出之后你并不需要再次使用。
当 Claude 通过 Agent 工具创建一个 subagent 时,这个 subagent 会获得一个全新的独立上下文窗口。它可以完成自己所需的全部工作,然后把结果综合整理后再返回给主代理,因此只有最终报告会回到父会话中。
我们常用的心理判断标准是:我之后还会需要这些工具输出本身,还是我只需要结论?
虽然 Claude Code 会自动调用 subagents,但你有时也可以明确要求它这样做。例如,你可以告诉它:
- “启动一个 subagent,根据下面这个 spec 文件来验证这项工作的结果”
- “分出一个 subagent 去阅读另一个代码库,并总结它是如何实现 auth flow 的,然后你再按同样方式实现”
- “分出一个 subagent,根据我的 git 改动为这个功能写文档”
总结¶
总之,当 Claude 完成一轮响应、而你正准备发送下一条消息时,你其实正站在一个决策点上。
随着时间推移,我们预计 Claude 会越来越擅长自己处理这些事情;但就目前而言,这仍然是你可以主动引导 Claude 输出效果的重要方式之一。
